
Freunde, hallo alle zusammen! Mein Name ist Kolya Arkhipov, ich bin verantwortlich für Forschung und Entwicklung im Delivery Club.
Unser Team löst wissenschaftsintensive Aufgaben innerhalb der FoodTech-Plattform: Wir entwickeln Komponenten basierend auf Algorithmen und Daten, von denen es viele auf der DC-Plattform gibt. Bei der Lösung sind wir sowohl von der Geschäfts- als auch von der Entwicklungsseite mit vielen Unsicherheiten konfrontiert.
Das Material erwies sich als umfangreich und, wie ich hoffe, nützlich für Sie. Daher empfehle ich, eine Teekanne einzulegen und köstlichen Kaffee zu kochen. Ich habe dies selbst getan, während ich an diesem Artikel gearbeitet habe.
Heute werde ich Ihnen von dem Rennen erzählen, das unser Team im vergangenen Jahr bestanden hat. Die Analogie entstand von selbst - wir arbeiten in einem sehr dynamischen Unternehmen, dem Marktführer FoodTech in Russland. Wir entwickeln schnell verschiedene Geschäftsbereiche und es treibt wirklich! Wir sind nicht nur erfolgreich ins Ziel gekommen, sondern haben auch viele Einblicke in das Rennen erhalten. Das möchte ich mit Ihnen teilen.
Der Artikel erschien nach dem Bericht auf der RIT ++ 2020- Konferenz . Für diejenigen, die Video lieben, suchen Sie es am Ende des Artikels.
Kocht der Wasserkocher schon? Super! Also, was wird heute diskutiert:
- F & E und Unsicherheit. Was wir konfrontiert haben.
- Experimente. Wie und warum führen wir sie im Kampf?
- Messbarkeit. Lassen Sie uns die Auswahl der Metriken diskutieren und mit Risiken arbeiten.
- Autonomie. Wie wir bei DC Tech das GIST-Framework und den Inner Source-Ansatz angepasst haben.
Grünes Licht, Kupplung, zuerst - lass uns gehen.
F & E und Unsicherheit
In einigen Unternehmen befasst sich das Forschungs- und Entwicklungsteam mit der Grundlagenforschung neuer Technologien. Der Zweck einer solchen Forschung kann sowohl die Entwicklung aktueller Prozesse als auch völlig neue Geschäftsbereiche sein. Zum Beispiel war Blockchain vor einigen Jahren eine solche Technologie.
Wir sprechen sofort über etwas anderes. Bei Forschung und Entwicklung im Delivery Club geht es darum, angewandte Probleme zu lösen. Unser Geschäft wächst schnell, die Anzahl der Bestellungen wächst und die meisten unserer internen Prozesse basieren auf Daten und Algorithmen. Mit zunehmender Menge an Eingabedaten sind einige Algorithmen nicht mehr effektiv, und die Komponenten, die gestern zu uns passten, sind heute oft nicht mehr funktionsfähig.
Wie Sie vielleicht vermutet haben, sind solche Probleme oft schwach deterministisch und gehen daher mit vielen Unsicherheiten von allen Seiten einher. Lassen Sie uns die wichtigsten hervorheben:

Schauen wir uns genauer an, was uns bevorsteht und ob dies wirklich Schwierigkeiten sind.
Wie man das Ziel erreicht
Wir verstehen das Geschäftsziel immer klar - in welche Richtung wir uns bewegen wollen, wohin wir gehen müssen. Es ist jedoch keineswegs immer sofort klar, wie man dieses Ziel bei Forschungsaufgaben angeht. Welche Strategie sollte angewendet werden: durch Experimente oder eine umfassende Einführung des Features sofort? Umgebungen mit Simulationen bauen oder im Kampf experimentieren? Die Auswahl ist groß - die Augen laufen hoch.
Was genau ist es wert, getan zu werden?
Okay, wir verstehen das Geschäftsziel und haben vereinbart, welche Strategie wir verfolgen werden. Es ist Zeit, sich für eine Reihe von Funktionen zu entscheiden, die wir zur Arbeit bringen werden. Wie man sie auswählt, was in welcher Reihenfolge in den Rückstand aufgenommen werden soll: Sie müssen nicht nur bestimmen, „was genau es wert ist, getan zu werden“, sondern auch, wer über das maximale Fachwissen in unserem Bereich verfügt.
Wann wir unser Ziel erreichen können Das
Timing ist definitiv sehr wichtig für das Geschäft. Die Recherche ist cool und unterhaltsam. Sie können nach neuen Funktionen in den Daten suchen, nach Algorithmen suchen und interessante Notizen von unseren Kollegen in anderen Ländern lesen. Für Unternehmen ist es jedoch wichtig zu verstehen, wann das Ziel erreicht wird, da eine zur falschen Zeit eingeführte Funktion oft einfach nicht benötigt wird - der FoodTech-Markt ist jetzt so dynamisch.
Warum braucht jemand meinen Code überhaupt?
Die letzte Unsicherheit, die jedoch keineswegs signifikant ist, besteht darin, Entwickler zu motivieren. F & E ist größtenteils eine experimentelle Entwicklung, daher wurzelt unser Code nicht immer in der Produktion. Zuerst waren wir sehr verärgert, weil wir nicht verstanden haben, warum wir das Feature erstellt haben, und das von ganzem Herzen, und das Unternehmen entscheidet, dass es nicht funktioniert und abgesägt werden muss. Fragen - warum mache ich das? Warum sollte jemand meinen Code brauchen? - erschien ziemlich oft bei uns. Dabei haben wir erkannt, wie wir damit arbeiten können und sollten, und jetzt sind wir sicher, dass dies eine der kritischsten Unsicherheiten ist, die zuerst überwunden werden müssen.
Nachdem wir so viele anständige Unebenheiten gefüllt hatten, sammelten wir alle unsere Probleme an einem Ort und stellten fest, dass uns zum Glück drei Prozesse an der Schnittstelle dieser Unsicherheiten fehlen.
Schematisch im Bild unten.
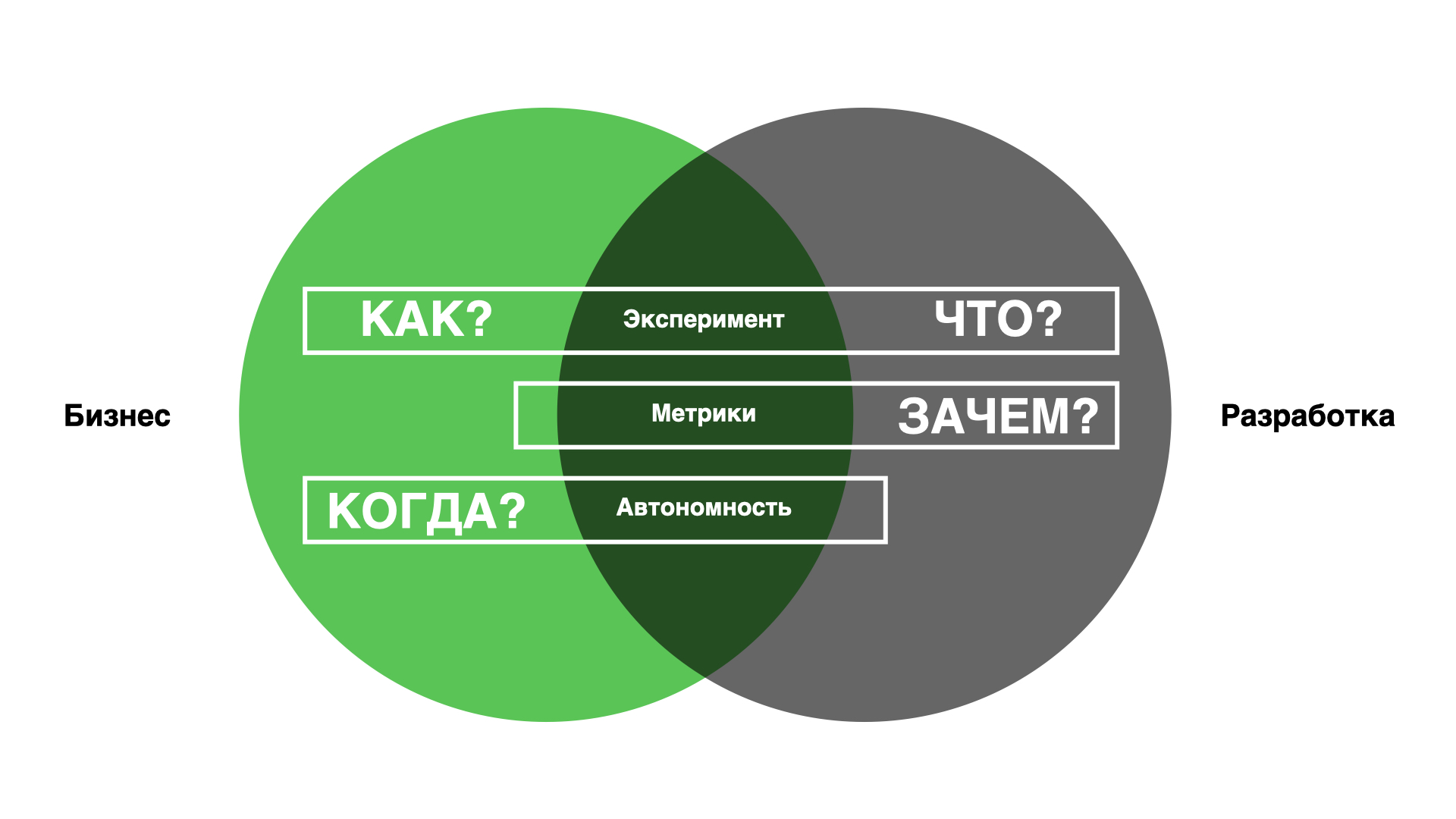
Experimente werden die Fragen beantworten, wie man Ziele erreicht und was genau zu tun ist. Mithilfe von Metriken kann die Frage, ob dieser Code wirklich in Produktion bleiben soll, sehr klar und transparent beantwortet werden. Volle Autonomie wird dazu beitragen, die Fristen zu bewerten und einzuhalten.
Wir stoppen nicht. Kupplung, zweiter Gang, wir gewinnen schnell an Fahrt.
Experimente
Betrachten Sie eine benutzerdefinierte Plattform für die automatische Zuweisung von Kurieren. Sie hat eine ziemlich einfache Aufgabe - drei Marktteilnehmer zusammenzubringen: unsere Partner, Logistiker (dh ihre Kuriere) und Kunden, damit alle Teilnehmer zufrieden sind. Das heißt, wenn eine Bestellung eintrifft, müssen wir einen Kurier auswählen, der genau zu dem Zeitpunkt ins Restaurant kommt, zu dem das Restaurant die Zubereitung des Gerichts beendet, es schnell abholt und dem Kunden heiß und lecker zu dem von uns versprochenen Zeitpunkt liefert.
Sieht ziemlich einfach aus, und hier könnte man sagen - genug Theorie! Es ist Zeit, zu echten Starts überzugehen.
Ich stimme Ihnen zu, aber lassen Sie uns noch ein wenig über den Prozess der Experimente nachdenken. Schauen wir uns das ganze Bild an.
- - — . — , , .
- — . . — , .
- — Just In Time. , : , , . , , , . , FoodTech- : , . , .
Schauen wir uns genauer an, welcher Prozess sich unter der Haube des Produktinkrements befindet.

3.1 Hypothese. Es kann in Worten formuliert oder schematisch dargestellt werden. Die Hauptsache ist, klar zu rechtfertigen, warum es überhaupt funktionieren sollte. Das heißt, das Experiment muss theoretisch ausgebildet sein.
3.14 Entwicklung. Ich werde hier nicht näher darauf eingehen. Weitere Details zu unserer Entwicklung finden Sie in diesem Artikel . Wir verwenden Scrum, zweiwöchige Iterationen mit allen erforderlichen Aktivitäten.
3.2 Vorbereitung. Als nächstes müssen Sie ein Experiment vorbereiten. Das heißt, wir müssen uns für das Geosegment oder die Zielgruppe entscheiden, mit der wir während dieses Experiments kommunizieren möchten. Wählen Sie auch das Segment aus, mit dem wir die Ergebnisse vergleichen möchten.
3.3 Experiment. Als nächstes starten wir das Experiment selbst. Ein wichtiger Punkt: Wir vereinbaren bereits vor dem Start die Geschäftsmetriken, die wir überwachen werden. Lassen Sie uns heute die Diskussion über technische Metriken verlassen, die uns sagen, dass das Experiment gestartet und technisch stabil ist. Wir werden mehr über Geschäftsindikatoren sprechen. Wir werden die roten Fahnen definitiv beheben - dies sind einige Schwellenwerte, die wir während unseres Experiments nicht überschreiten sollten.
3.4 Analyse. Wir haben viele coole, einzigartige Daten gesammelt, die nur wir haben. Es wäre seltsam, keine nützlichen Informationen daraus zu extrahieren, dh vernünftige Schlussfolgerungen über die Gültigkeit der getesteten Hypothese zu ziehen und neue Dinge über das Publikum unseres Dienstes hervorzuheben.
3.5 Fazit.Wahrscheinlich der wichtigste Punkt in diesem Prozess. In unserem Fall drückt der Ausgang immer drei Tasten:
- Rollout des Experiments weiter auf die nächste Geografie oder das nächste Segment des Publikums;
- Rollback, wenn etwas schief gelaufen ist;
- fortsetzen. Es gibt Fälle, in denen wir den Einfluss von Faktoren Dritter sehen, die wir nicht berücksichtigt haben, und daher können wir keine eindeutige Schlussfolgerung ziehen. In diesen Fällen beschließen wir, fortzufahren.
Echtes Experiment
Es ist endlich Zeit zu sehen, wie dies anhand eines realen Beispiels funktioniert. Bist du schon müde Der Spaß beginnt.
Zurück zur Plattform für die automatische Zuweisung. Zuvor haben wir vorgeschlagen, dass der Just In Time-Ansatz für uns sehr cool ist, um die Lieferzeit zu verkürzen. Wir werden es mit der aktuellen Zuweisungsstrategie vergleichen, die wir als gierigen Algorithmus bezeichnen.
Zunächst werden wir die Hypothese begründen.
Gieriger Algorithmus
Sein Hauptmerkmal ist die sofortige Verschreibung. Sobald die Bestellung auf der Plattform eintrifft, suchen wir den für diese Bestellung am besten geeigneten Kurier unseres Partners, ernennen unverzüglich einen Termin und informieren den Kurier über diese Bestellung. Infolgedessen optimieren wir die Zeit für die Suche nach einem Kurier. Dieser Ansatz ist jedoch nicht immer effektiv, da sich die Situation in einer Minute ändern kann: Eine neue Bestellung kommt an oder ein anderer Kurier wird freigegeben. Der Algorithmus reagiert nicht mehr darauf. Unten ist eine Illustration.
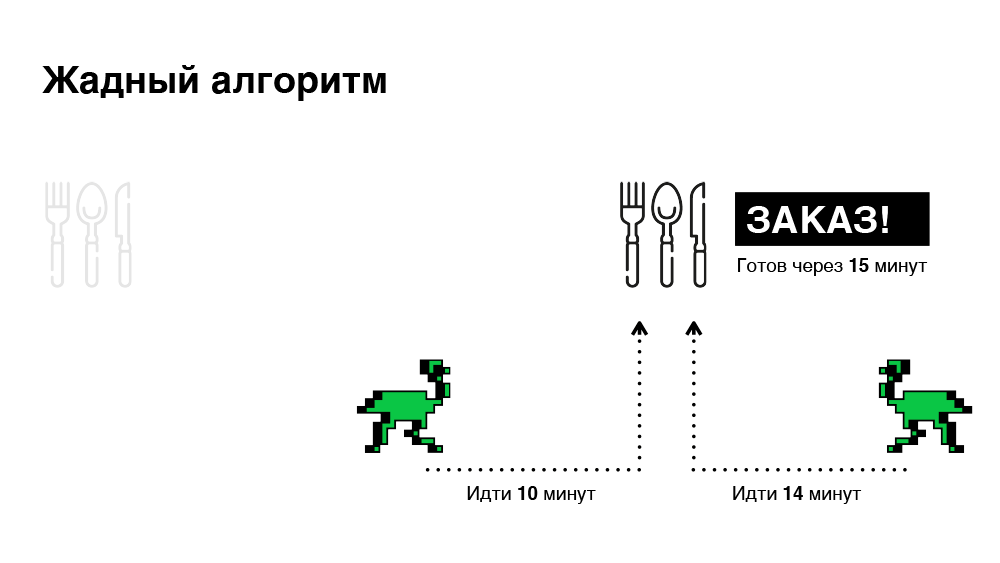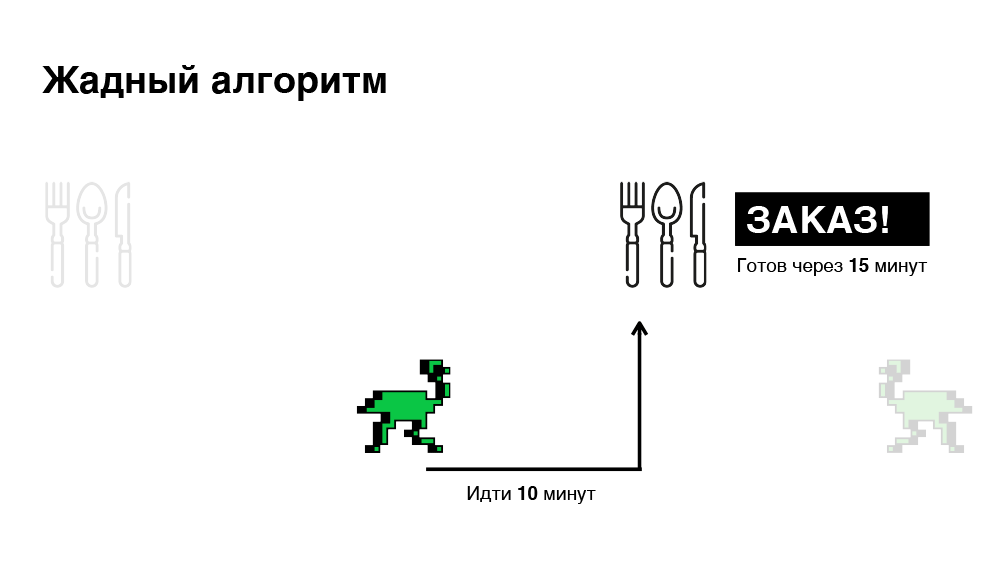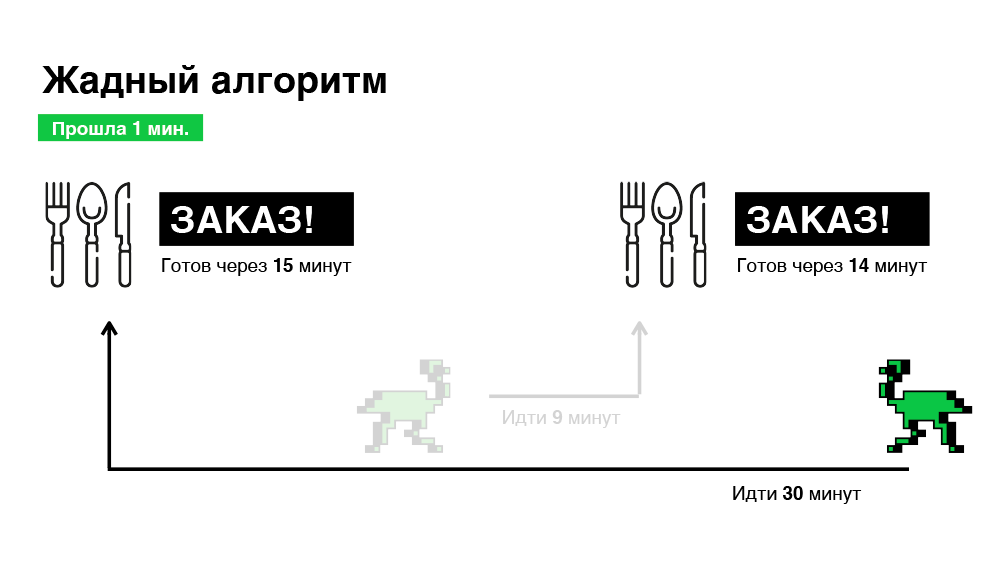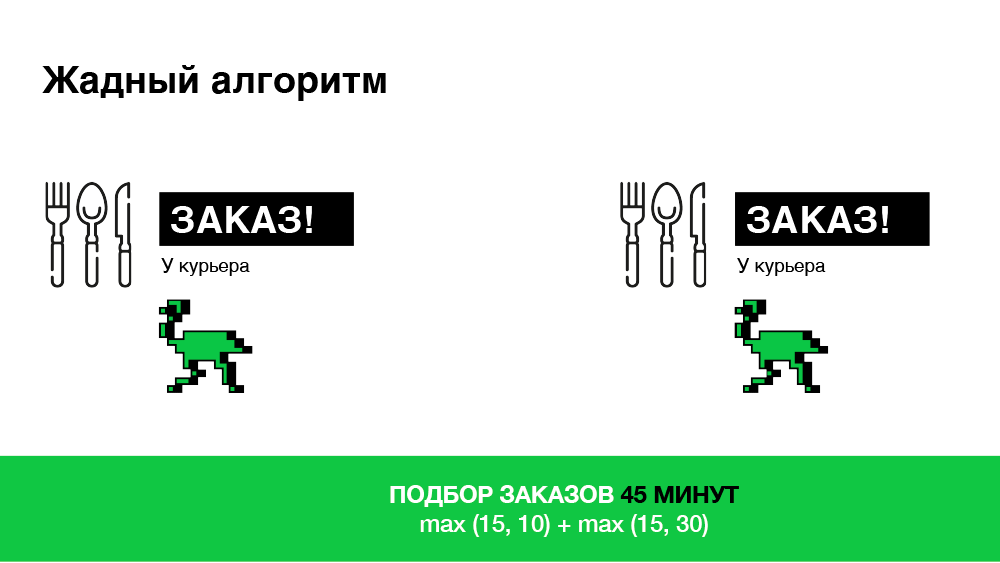
In diesem Beispiel haben wir insgesamt 45 Minuten Zeit, um zwei Bestellungen auszuwählen. Es scheint, wir können es besser machen.
Gerade rechtzeitig
Die Aufgabe dieses Algorithmus besteht darin, genau den Kurier auszuwählen, der genau zum Zeitpunkt der Bestellung im Restaurant ankommt. Was wird es uns geben? Dies wird letztendlich die Lieferzeit verkürzen, da:
- Der Kurier verbringt weniger Zeit im Restaurant.
- Wir werden den Kurier optimaler wählen.
Technisch ist dies ziemlich einfach zu implementieren. Wenn eine Bestellung eintrifft, wählen wir sofort einen Kurier, erzählen ihm jedoch nichts über die Bestellung, vereinbaren so einen "virtuellen Termin" und geben uns Zeit, unsere Wahl zu ändern. Und wir werden endgültig entscheiden (ob die Bestellung an den Kurier weitergeleitet werden soll), wenn der Weg zum Restaurant der verbleibenden Zeit für die Vorbereitung der Bestellung entspricht. Schematisch - in der Abbildung unten.
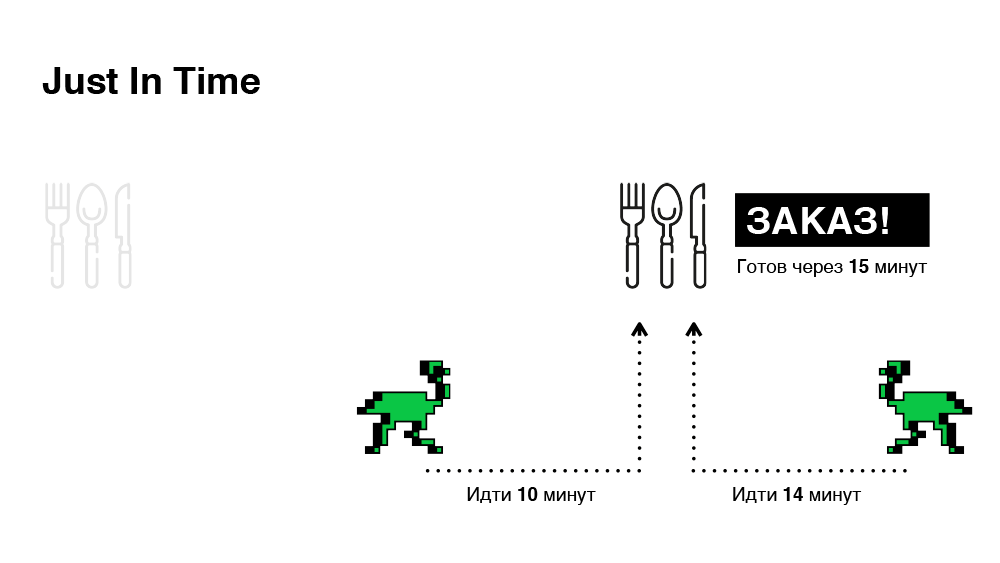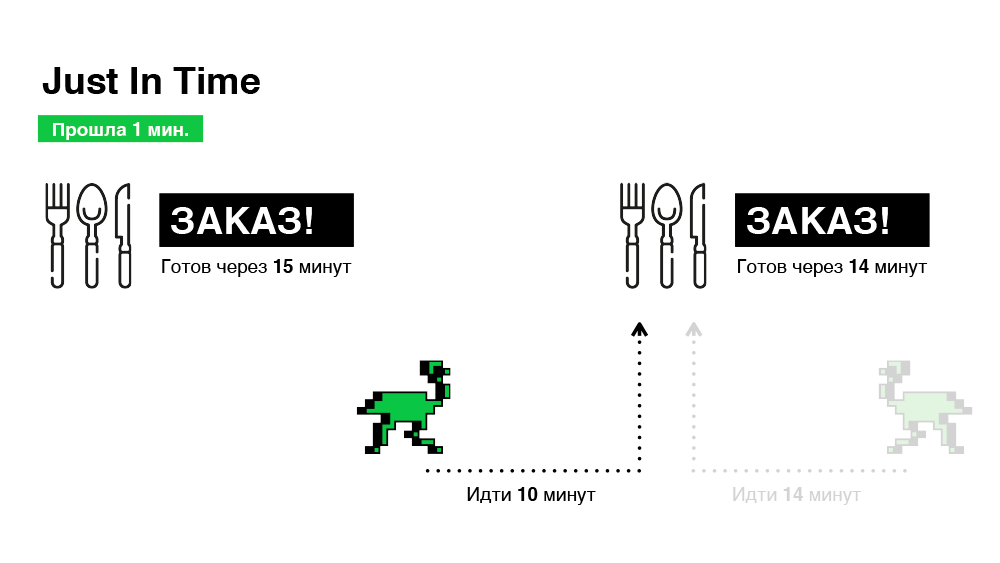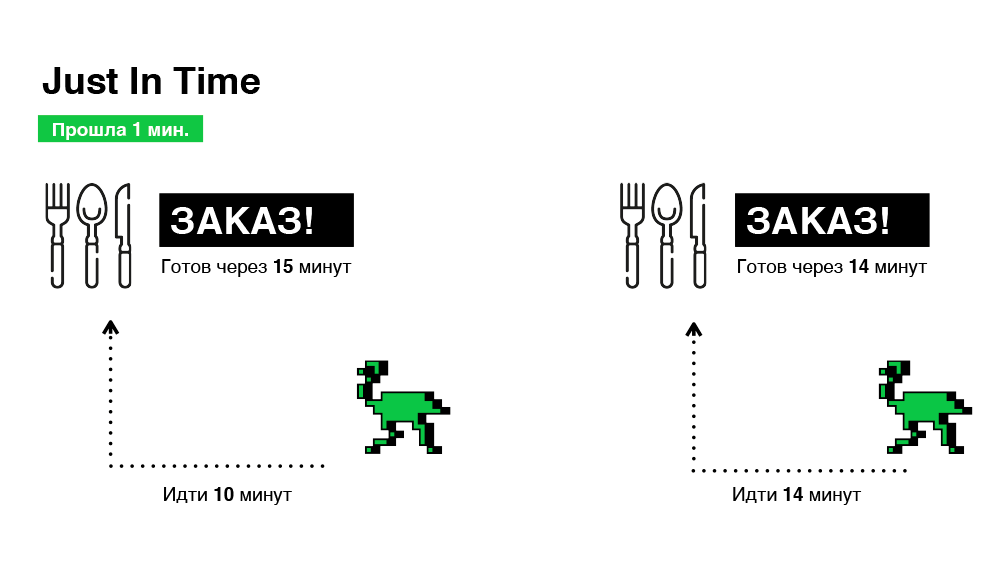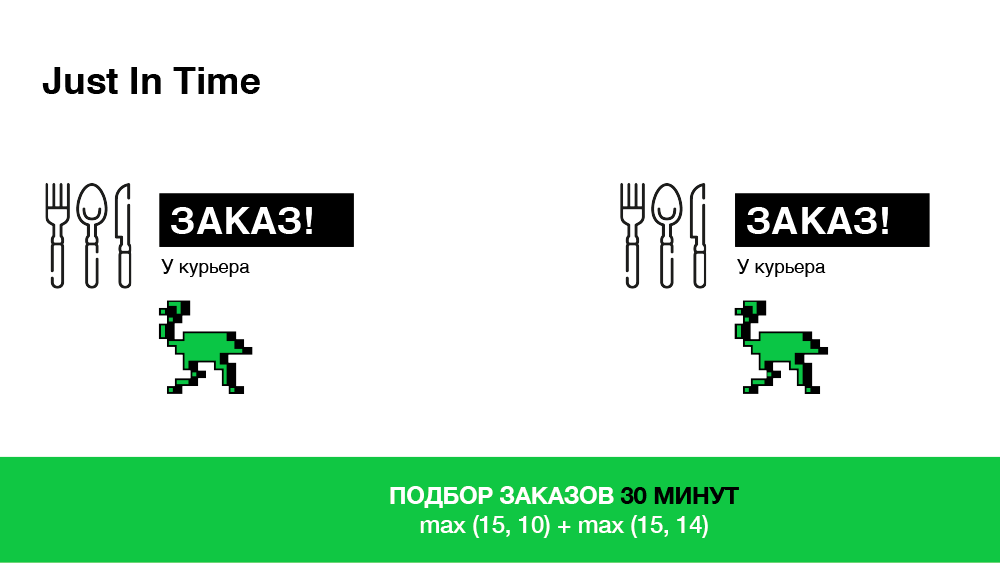
Daher wählen wir Bestellungen in nur 30 Minuten aus, ein Drittel weniger als im vorherigen Fall.
Meiner Meinung nach ist die Hypothese gerechtfertigt, wir nehmen sie in die Entwicklung auf. Wie vereinbart werden wir den Entwicklungsprozess nicht im Detail betrachten.
Fahren wir mit der Vorbereitung des Experiments fort
Was muss in unserem Fall vorbereitet werden? Nicht so sehr: der Zeitraum des A / B-Tests, die Geographie des Experiments und die, mit der wir vergleichen werden. Wir haben uns für eine bestimmte Stadt entschieden und die Bedingungen ausgewählt, um die Auswirkungen einer Terminstrategie auf die zweite zu minimieren.
Wir werden auf jeden Fall mit dem Unternehmen über rote Fahnen und Reaktionen darauf verhandeln. Die roten Fahnen sind Schwellenwerte für Geschäftsmetriken, die wir während des Experiments nicht überschreiten möchten. Wenn gekreuzt, dann ist dies in der überwältigenden Anzahl von Experimenten ein Rollback. Es gibt jedoch Ausnahmen, wenn wir sicher wissen, dass die Kreuzung nicht wegen uns stattgefunden hat, sondern das Ergebnis anderer Faktoren war. In diesem Fall können wir manchmal entscheiden, das Experiment fortzusetzen.
Was muss noch vorbereitet werden? Stimmen Sie mit unseren Kollegen aus dem Kontrollraum überein, die in Echtzeit beobachten, dass bei Bestellungen alles in Ordnung ist. Für sie wird unsere Änderung sichtbar sein, denn bevor wir dem Kurier sofort einen Auftrag erteilt haben, aber jetzt tun wir dies nicht, geben wir uns etwas Zeit, um unsere Meinung zu ändern. Deshalb sollten Kollegen vor den geplanten Experimenten gewarnt werden.
Okay, lass uns weitermachen. Ein Experiment vorbereitet, durchgeführt und die Ergebnisse erhalten. Und hier kommt der lustige Teil - die Analyse.
Experimentanalyse
Wir waren uns einig, die Gesamtlieferzeit zu verbessern, und plötzlich gab es vier Zeitpläne. Es lohnt sich hier zu erklären. Wenn Sie ein Experiment starten, ist es wichtig, nicht eine Schlüsselmetrik zu betrachten, sondern mehrere Geschäftsindikatoren, die für das Geschäft kritisch sind. In diesem Fall können wir das Risiko einer erfolglosen Hypothese, die sich auf reale Prozesse auf der Plattform auswirkt, erheblich reduzieren. Seien wir ehrlich, wir haben zu Beginn unserer Experimente solche Fehler gemacht, die manchmal zu wirklich unangenehmen Konsequenzen führten. Aber Fehler sind gut, wir lernen daraus.
Werfen wir einen Blick auf die Ergebnisse. Wir werden die Diagramme ohne bestimmte Werte zeigen, da der Zweck des Artikels keine detaillierte Analyse der Effizienz des Just In Time-Algorithmus ist. Wir möchten uns bei der Durchführung von Experimenten stärker auf unseren Ansatz konzentrieren. Aus dem gleichen Grund werden wir uns nicht mit der Theorie der Durchführung von A / B-Tests und der Bestimmung der statistischen Signifikanz der Ergebnisse befassen. Dies ist ein großes Thema für die nächste Veröffentlichung und vielleicht sogar für den gesamten Zyklus.
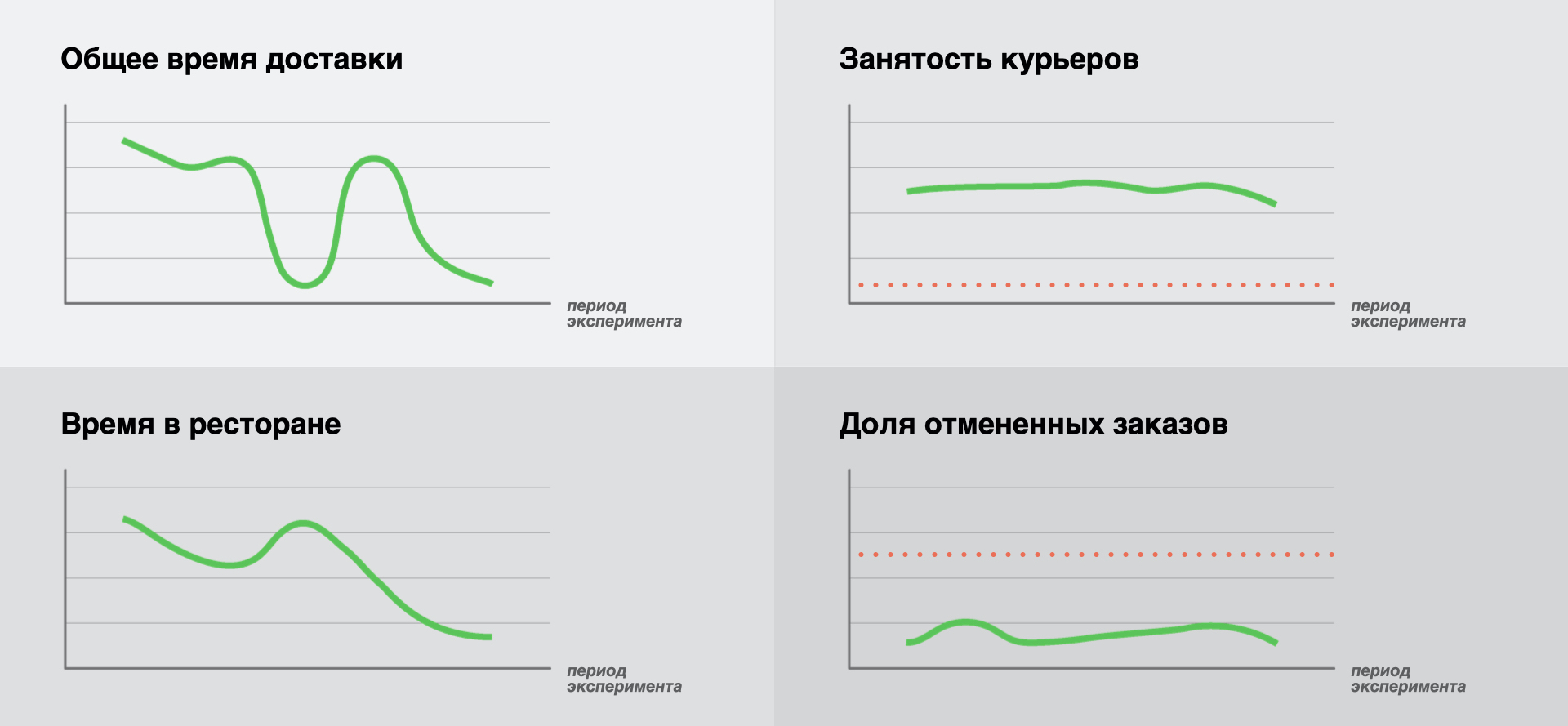
- « ». , , . , . , — , . , . , , . , . , , (/), — , , . -, .
- « ». . , , , . , . , .
- « » « ». : . .
Infolgedessen haben wir eine Abnahme der Schlüsselmetrik (1), eine Abnahme einer sehr wichtigen Metrik (2), stabile Werte der beiden anderen Schlüsselmetriken (3, 4), die roten Fahnen leuchten nicht. Dies ermöglicht es uns, auf den Erfolg des Experiments und die Gültigkeit der getesteten Hypothese zu schließen.
Klasse! Sind Sie zur nächsten Hypothese übergegangen? Es ist fantastisch unterhaltsam und wurde entwickelt, um das Leben aller zu verbessern! Aber nein, das ist noch nicht alles. Es bleibt vielleicht einer der wichtigsten Schritte, die wir nicht vergessen sollten. Hiermit drücken Sie eine der drei Tasten:
- Ausrollen
- Rollback
- Fortsetzen
Während des Experimentierprozesses muss das Team einen Kollegen haben, dessen Rolle darin besteht, die Funktion vollständig zu übernehmen, und der eine dieser drei Tasten drückt. Zu Beginn hatten wir Fälle, in denen wir diesen Schritt vergessen hatten. Infolgedessen erhielten wir mehrere Dutzend gleichzeitig gestartete Experimente ohne verständlichen Status für jeden von ihnen. Sie gaben positive Ergebnisse, wurden jedoch nicht vollständig eingeführt, was für das Geschäft unwirksam ist. Außerdem mussten wir erhebliche Ressourcen aufwenden, um uns an die Details zu erinnern und die Dinge in Ordnung zu bringen. Aber wir lernen wieder aus Fehlern.
Reale Experimente
Lassen Sie uns kurz darauf eingehen, warum wir sofort im Kampf experimentieren. Diesem Ansatz stehen normalerweise analytische Simulationsumgebungen entgegen, die auf der Grundlage historischer Daten mit einer gewissen Genauigkeit beantworten können, was „es wäre“, wenn wir eine solche Funktion implementieren würden.
Warum haben wir uns für den ersten Ansatz entschieden? Zwei Gründe.
- -, .
, , . , - , , . — .
. .
? , , , — . , , , , , . , .
Es lohnt sich, hier ehrlich zu sein, dass dies ein ziemlich riskanter Ansatz ist. Das Risiko, das Publikum, die Kunden und das Geschäft zu enttäuschen. Dieser Artikel befasst sich hauptsächlich mit der Reduzierung solcher Risiken: Wählen Sie Metriken (mehrere) sorgfältig und genau aus und überwachen Sie sie in Echtzeit. Falls etwas schief geht, schalten wir das Experiment sofort aus.
- Das zweite ist natürlich die Geschwindigkeit. Experimente unter Kampfbedingungen zeigen die Ergebnisse viel genauer und schneller.
Bevor wir weiter laufen, wollen wir einige kleine Siege korrigieren.

Ein transparenter Experimentierprozess gibt uns die Antwort auf die Frage, wie ein Ziel erreicht werden kann. Und indem wir Tests sofort unter realen Bedingungen durchführen, beginnen wir, unser Publikum besser zu verstehen. Infolgedessen verfügt das Entwicklungsteam über ausreichend Fachwissen, um bestimmte Funktionen zur Lösung eines Geschäftsproblems vorzuschlagen.
Nicht schlecht, aber das ist noch nicht alles. Jetzt ist es an der Zeit, mehr über Messbarkeit zu sprechen. Und währenddessen schalten wir den dritten ein, Gas auf den Boden, der Wind pfeift.
Messbarkeit
Warum brauchen wir überhaupt Metriken? In erster Linie, um eine Hypothese zu bestätigen oder die Auswirkung einer fehlgeschlagenen Annahme zu verringern. Selbst theoretisch fundierte Hypothesen schießen nicht immer. Und wenn sie schießen, manchmal im Knie.
- -, FoodTech, : , , , .
- -, , , . , , , . ! , , , . , , -.
Unsere Erfahrung zeigt, dass ein gutes Rezept ist, wenn es mehrere Metriken gibt. Eine Zielmetrik - Verbesserung; und noch ein paar Schlüssel - wir dürfen sie nicht fallen lassen.
Einführung eines einheitlichen Überwachungsbereichs, in den sowohl das Geschäft als auch die Entwicklung hineinschauen. Es muss nicht ein Werkzeug sein, wir verwenden zwei: Metabase und Grafana, aber in Zukunft planen wir, eines davon auszuwählen. Am wichtigsten ist, dass es einen einzigen Bereich gibt, in dem Kollegen aus Wirtschaft und Entwicklung nachsehen. Und achten Sie darauf, rote Fahnen zu identifizieren.
Rote Flaggen
Ja, dies sind einige Schwellenwerte für Metriken, die wir während des Experiments nicht überschreiten sollten. Es lohnt sich, dem Unternehmen zuzustimmen, wenn Reaktionen gekreuzt wurden, und Warnungen zu veröffentlichen.
Und noch ein kleiner Sieg: Wir beantworteten die Frage „Warum braucht jemand meinen Code überhaupt?“. Vergessen wir sie nicht!

Ich möchte Sie daran erinnern, dass diese Unsicherheit seitens der Entwicklung darin besteht, dass wir nicht immer verstanden haben, warum unser Code nicht in Produktion blieb, und ehrlich gesagt waren wir darüber traurig. Durch den Peer-to-Peer-Immersionsansatz von der Entwicklung bis hin zu Geschäftsmetriken haben wir nicht nur unser Verständnis für Kundenlösungen verbessert, sondern uns auch durch die Fokussierung auf das Endergebnis eine gewisse Dynamik bei der Lösung von Geschäftsproblemen verschafft.
Okay, wir haben Experimente und transparente Prozesse, Metriken und Messbarkeit herausgefunden. Vor uns liegt die Ziellinie, wir schalten die vierte ein und mit maximaler Geschwindigkeit bis zum Sieg.
Autonomie
All dies funktioniert nur dann so gut wie möglich, wenn wir sowohl von der Geschäfts- als auch von der Entwicklungsseite autonom werden.
KERN
Unter Autonomie verstehen wir hier die minimale Abhängigkeit bei der Entscheidungsfindung. Was haben wir auf der Geschäftsseite getan, um Entscheidungen schnell zu treffen und nicht in Genehmigungsprozessen zu ertrinken? Wir haben das GIST-Framework implementiert.
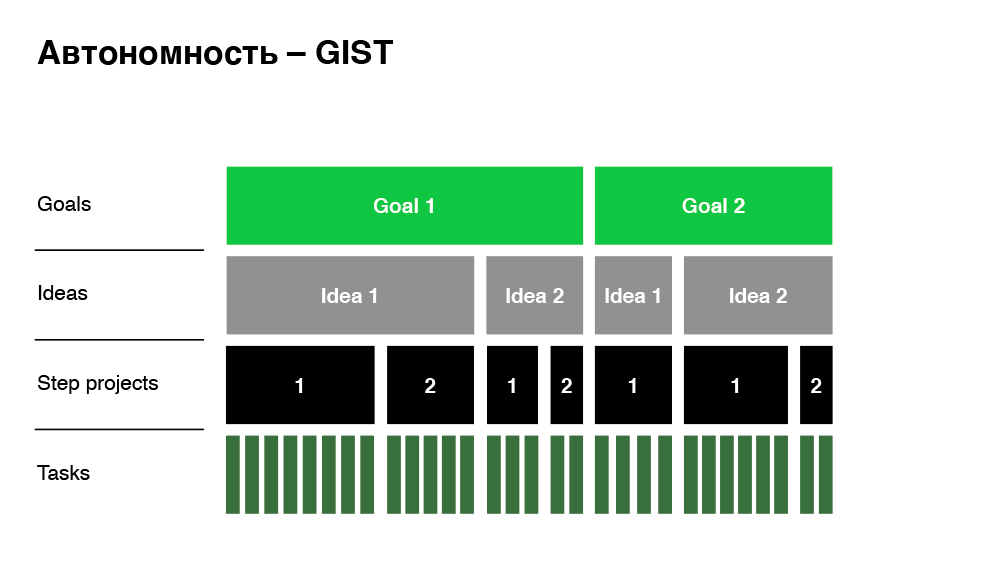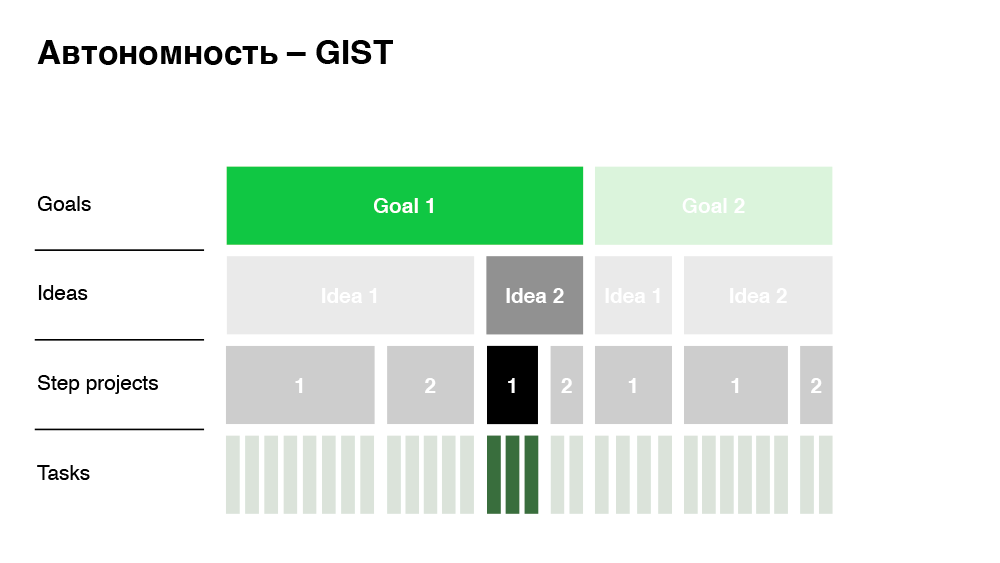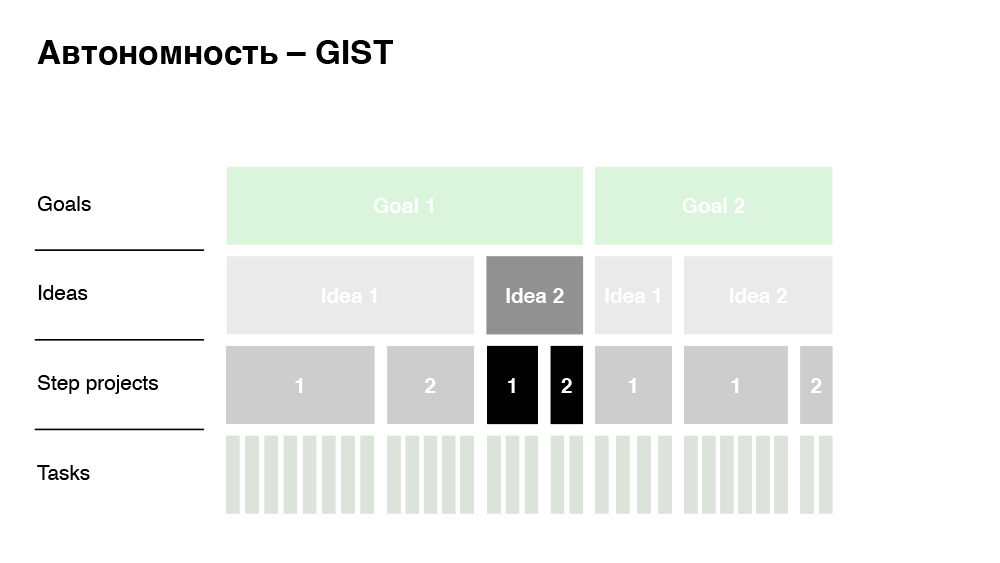
Dieser Ansatz ist Ziele, Ideen, Schritt-Projekte, Aufgaben. Das Unternehmen hat klare Geschäftsziele, die das Management allen Mitarbeitern transparent mitteilt. Um diese Ziele zu erreichen, werfen die Mitarbeiter Ideen ein. Es kann ein Dutzend oder eine Idee geben. Es ist wichtig, dass eine Idee noch kein Projekt ist. Dies sind einige der Ansätze, die ich implementieren möchte. Schritt-Projekt - das sind bereits Projekte: ziemlich große Funktionen, die diese Ideen umsetzen. In unserem Just In Time-Beispiel ist das Ziel genau das Step-Projekt. Auf der letzten Ebene befinden sich die Aufgaben, an die wir gewöhnt sind - dies ist bereits ein zerlegtes Step-Projekt, das auf die Arbeitskosten geschätzt wird.
Wie hilft Ihnen der Ansatz, Autonomie zu erreichen? Wenn wir vorschlagen, diese Funktion (Just In Time) zu erstellen, sieht das Unternehmen transparent:
- Die Größe und die Kosten für die Implementierung der Funktion.
- Welche Idee setzt er um?
- Was ist das spezifische Ziel des Unternehmens (Auswirkungen).
Dann müssen wir es nur noch mit dem benachbarten Step-Projekt nach denselben Kriterien vergleichen: Kosten, Auswirkungen. Wir halten ein Meeting ab (sie sind regelmäßig bei uns), diskutieren, priorisieren und treffen eine Entscheidung.
Es sieht sehr einfach und unkompliziert aus. In unserem Fall ist es so und es funktioniert: Das Unternehmen trifft Entscheidungen schnell, wir sind glücklich. Dies ist jedoch nur der erste Schritt in Richtung Autonomie, denn auch von der Entwicklungsseite sollten wir nicht blockiert werden.
Innere Quelle
Es ist wie Open Source, nur innerhalb des Unternehmens. Die Delivery Club-Architektur besteht aus Microservices, mittlerweile gibt es mehr als hundert davon. Um eine Funktion zu erstellen, müssen häufig nicht nur die Komponenten geändert werden, für die unser Team verantwortlich ist, sondern auch die benachbarten Dienste. Und hier haben wir zwei Möglichkeiten:
- Verbessern Sie den Rückstand anderer Teams und stimmen Sie zu, dass die Jungs sie schaffen werden.
- Mach es selbst.

In unserer Anpassung funktioniert der Prozess wie folgt. Es gibt eine große Just In Time-Funktion, die drei Gruppen von Diensten betrifft:
- eine Auto-Assignment-Plattform, für die F & E verantwortlich ist,
- Logistikplattform,
- Komponenten der Interaktion mit Partnern (Restaurants und Geschäfte).
Wir machen das:
- Sammeln aller Aufgaben im Rückstand des Forschungs- und Entwicklungsteams;
- Wir priorisieren und verteilen innerhalb des Teams, welche der Jungs welche der Komponenten verfeinern werden.
- Wir stimmen mit den technischen Leitern der Teams aus Logistik- und Partnerbereichen über die Nuancen der Implementierung überein.
- wir entwickeln uns weiter, Kollegen führen eine Überprüfung durch;
- dann testen wir uns;
- Wir geben den Service-Eigentümern bereits die Möglichkeit, in die Produktion einzusteigen.
Nach dem Start der Produktion bleiben diese Verbesserungen im Verantwortungsbereich der Teams, die diese Services besitzen.
Um ganz ehrlich zu sein, ist der Ansatz nicht perfekt und birgt Risiken. Das wichtigste ist das Timing. In den meisten Fällen ändern wir Komponenten 2- bis 2,5-mal länger als die Servicebesitzer.
Der Vorteil liegt aber auch auf der Hand: Er überwiegt bei weitem die geringe Verzögerung bei der Implementierung - die Vorhersehbarkeit. Hierbei ist zu beachten, dass andere Teams ihren eigenen Rückstand und ihre eigenen Prioritäten haben und unsere Aufgaben meistens nicht „dringend“ übernehmen können. Daher ist unsere Geschäftsfrist realistisch und wird nicht durch mögliche Änderungen der Prioritäten in anderen Teams beeinflusst.
Also, Glückwunsch - fertig, Sieg!

Wir haben das GIST-Framework für eine schnelle und transparente Entscheidungsfindung und den Inner Source-Ansatz für Autonomie in der Entwicklung implementiert, und jetzt sind alle Teile des Puzzles zusammengesetzt. Es ist Zeit zum Abschluss, es war ein interessantes Rennen, danke für deine Teilnahme! Fassen wir zusammen.
Schlussfolgerungen
- Ein Experiment ist ein transparentes und effektives Werkzeug, um ein Ziel zu erreichen.
- Wir führen es in einer realen Umgebung durch und untersuchen unser Publikum, wodurch wir Änderungen jedes Mal nützlicher vornehmen und verstehen können, warum nicht alle Funktionen in der Produktion bleiben sollten.
- Um Chaos zu vermeiden, benötigen Sie jedoch einen klaren Prozess, die Verteilung der Rollen und die Ernennung einer verantwortlichen Person.
- In der aktiven Phase des Experiments und während der Analyse lohnt es sich, mehrere wichtige Metriken gleichzeitig zu überwachen und nicht zu vergessen, eine Schlussfolgerung zu ziehen (in unserem Fall drücken Sie eine der drei Tasten).
- Schnelle Entscheidungen und Autonomie in der Entwicklung tragen dazu bei, Ergebnisse zu erzielen und das Team zu motivieren.
Videoaufzeichnung des Berichts von der RIT ++ 2020- Konferenz .
Das ist alles, danke, dass du bei diesem Rennen mit mir zusammen bist. Ich bin sicher, dass wir ganz am Anfang stehen und dass noch große Herausforderungen vor uns liegen. Ich werde sie gerne teilen, bis bald!