Jetzt kann er Hello World kompilieren, aber in diesem Artikel möchte ich nicht über das Parsen und die interne Struktur des Compilers sprechen, sondern über einen so wichtigen Teil wie die byteweise Zusammenstellung der exe-Datei.
Start
Willst du einen Spoiler? Unser Programm wird 2048 Bytes sein.
Normalerweise besteht die Arbeit mit exe-Dateien darin, deren Struktur zu untersuchen oder zu ändern. Die ausführbaren Dateien selbst werden von den Compilern gebildet, und dieser Prozess scheint für Entwickler etwas magisch.
Aber jetzt werden wir versuchen, es zu beheben!
Um unser Programm zu erstellen, benötigen wir einen HEX-Editor (ich persönlich habe HxD verwendet).
Nehmen wir zunächst den Pseudocode:
Quelle
func MessageBoxA(u32 handle, PChar text, PChar caption, u32 type) i32 ['user32.dll']
func ExitProcess(u32 code) ['kernel32.dll']
func main()
{
MessageBoxA(0, 'Hello World!', 'MyApp', 64)
ExitProcess(0)
}
Die ersten beiden Zeilen geben Funktionen an, die aus WinAPI- Bibliotheken importiert wurden . Die MessageBoxA- Funktion zeigt ein Dialogfeld mit unserem Text an und ExitProcess informiert das System über das Ende des Programms.
Es macht keinen Sinn, die Hauptfunktion separat zu betrachten, da sie die oben beschriebenen Funktionen verwendet.
DOS-Header
Zunächst müssen wir den richtigen DOS-Header generieren. Dies ist ein Header für DOS-Programme und sollte den Start von exe unter Windows nicht beeinflussen.
Ich habe mehr oder weniger wichtige Felder notiert, der Rest ist mit Nullen gefüllt.
IMAGE_DOS_HEADER-Struktur
Struct IMAGE_DOS_HEADER
{
u16 e_magic // 0x5A4D "MZ"
u16 e_cblp // 0x0080 128
u16 e_cp // 0x0001 1
u16 e_crlc
u16 e_cparhdr // 0x0004 4
u16 e_minalloc // 0x0010 16
u16 e_maxalloc // 0xFFFF 65535
u16 e_ss
u16 e_sp // 0x0140 320
u16 e_csum
u16 e_ip
u16 e_cs
u16 e_lfarlc // 0x0040 64
u16 e_ovno
u16[4] e_res
u16 e_oemid
u16 e_oeminfo
u16[10] e_res2
u32 e_lfanew // 0x0080 128
}
Am wichtigsten ist, dass dieser Header das Feld e_magic enthält, was bedeutet, dass dies eine ausführbare Datei ist, und e_lfanew, das den Versatz des PE-Headers vom Anfang der Datei angibt (in unserer Datei beträgt dieser Versatz 0x80 = 128 Byte).
Großartig, jetzt, da wir die DOS-Header-Struktur kennen, schreiben wir sie in unsere Datei.
(1) RAW-DOS-Header (Offset 0x00000000)

4D 5A 80 00 01 00 00 00 04 00 10 00 FF FF 00 00
40 01 00 00 00 00 00 00 40 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 80 00 00 00
Fertig, die ersten 64 Bytes wurden geschrieben. Jetzt müssen Sie 64 weitere hinzufügen, dies ist der sogenannte DOS-Stub (Stub). Beim Start unter DOS muss der Benutzer benachrichtigt werden, dass das Programm nicht für die Ausführung in diesem Modus ausgelegt ist.
, , .
, (Offset) .
, 0x00000000, 64 (0x40 16- ), 0x00000040 ..
Im Allgemeinen ist dies jedoch ein kleines DOS-Programm, das eine Zeile druckt und das Programm beendet.
Schreiben wir unseren Stub in eine Datei und betrachten ihn genauer.
(2) RAW DOS Stub (Offset 0x00000040)

0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68
69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F
74 20 62 65 20 72 75 6E 20 69 6E 20 44 4F 53 20
6D 6F 64 65 2E 0D 0A 24 00 00 00 00 00 00 00 00
Und jetzt der gleiche Code, aber in zerlegter Form
Asm DOS Stub
0000 push cs ; Code Segment(CS) ( )
0001 pop ds ; Data Segment(DS) = CS
0002 mov dx, 0x0E ; DS+DX, $( )
0005 mov ah, 0x09 ; ( )
0007 int 0x21 ; 0x21
0009 mov ax, 0x4C01 ; 0x4C ( )
; 0x01 ()
000c int 0x21 ; 0x21
000e "This program cannot be run in DOS mode.\x0D\x0A$" ;
Das funktioniert so: Zuerst druckt der Stub eine Zeile, die besagt, dass das Programm nicht gestartet werden kann, und beendet dann das Programm mit Code 1. Dies unterscheidet sich von der normalen Beendigung (Code 0).
Der Stub-Code kann sich geringfügig unterscheiden (von Compiler zu Compiler). Ich habe gcc und delphi verglichen, aber die allgemeine Bedeutung ist dieselbe.
Es ist auch lustig, dass die Stichleitung mit \ x0D \ x0D \ x0A $ endet. Der Grund für dieses Verhalten ist höchstwahrscheinlich, dass C ++ die Datei standardmäßig im Textmodus öffnet. Infolgedessen wird das Zeichen \ x0A durch die Sequenz \ x0D \ x0A ersetzt. Als Ergebnis erhalten wir 3 Bytes: 2 Bytes Wagenrücklauf (0x0D), was bedeutungslos ist, und 1 für Zeilenvorschub (0x0A). Im Binärmodus (std :: ios :: binary) tritt diese Ersetzung nicht auf.
Um die Richtigkeit des Schreibens der Werte zu überprüfen, verwende ich Far mit dem ImpEx-Plugin:

NT-Header
Nach 128 (0x80) Bytes gelangten wir zum NT-Header (IMAGE_NT_HEADERS64), der auch den PE-Header (IMAGE_OPTIONAL_HEADER64) enthält. Trotz des Namens ist IMAGE_OPTIONAL_HEADER64 erforderlich, jedoch unterschiedlich für x64- und x86-Architekturen.
IMAGE_NT_HEADERS64-Struktur
Struct IMAGE_NT_HEADERS64
{
u32 Signature // 0x4550 "PE"
Struct IMAGE_FILE_HEADER
{
u16 Machine // 0x8664 x86-64
u16 NumberOfSections // 0x03
u32 TimeDateStamp //
u32 PointerToSymbolTable
u32 NumberOfSymbols
u16 SizeOfOptionalHeader // IMAGE_OPTIONAL_HEADER64 ()
u16 Characteristics // 0x2F
}
Struct IMAGE_OPTIONAL_HEADER64
{
u16 Magic // 0x020B PE64
u8 MajorLinkerVersion
u8 MinorLinkerVersion
u32 SizeOfCode
u32 SizeOfInitializedData
u32 SizeOfUninitializedData
u32 AddressOfEntryPoint // 0x1000
u32 BaseOfCode // 0x1000
u64 ImageBase // 0x400000
u32 SectionAlignment // 0x1000 (4096 )
u32 FileAlignment // 0x200
u16 MajorOperatingSystemVersion // 0x05 Windows XP
u16 MinorOperatingSystemVersion // 0x02 Windows XP
u16 MajorImageVersion
u16 MinorImageVersion
u16 MajorSubsystemVersion // 0x05 Windows XP
u16 MinorSubsystemVersion // 0x02 Windows XP
u32 Win32VersionValue
u32 SizeOfImage // 0x4000
u32 SizeOfHeaders // 0x200 (512 )
u32 CheckSum
u16 Subsystem // 0x02 (GUI) 0x03 (Console)
u16 DllCharacteristics
u64 SizeOfStackReserve // 0x100000
u64 SizeOfStackCommit // 0x1000
u64 SizeOfHeapReserve // 0x100000
u64 SizeOfHeapCommit // 0x1000
u32 LoaderFlags
u32 NumberOfRvaAndSizes // 0x16
Struct IMAGE_DATA_DIRECTORY [16]
{
u32 VirtualAddress
u32 Size
}
}
}
Mal sehen, was in dieser Struktur gespeichert ist:
Beschreibung IMAGE_NT_HEADERS64
Signature — PE
IMAGE_FILE_HEADER x86 x64.
Machine — x64
NumberOfSections — ( )
TimeDateStamp —
SizeOfOptionalHeader — IMAGE_OPTIONAL_HEADER64, IMAGE_OPTIONAL_HEADER32.
Characteristics — , , (EXECUTABLE_IMAGE) 2 RAM (LARGE_ADDRESS_AWARE), ( ) (RELOCS_STRIPPED | LINE_NUMS_STRIPPED | LOCAL_SYMS_STRIPPED).
SizeOfCode — ( .text)
SizeOfInitializedData — ( .rodata)
SizeOfUninitializedData — ( .bss)
BaseOfCode —
SectionAlignment —
FileAlignment —
SizeOfImage —
SizeOfHeaders — (IMAGE_DOS_HEADER, DOS Stub, IMAGE_NT_HEADERS64, IMAGE_SECTION_HEADER[IMAGE_FILE_HEADER.NumberOfSections]) FileAlignment
Subsystem — GUI Console
MajorOperatingSystemVersion, MinorOperatingSystemVersion, MajorSubsystemVersion, MinorSubsystemVersion — exe, . 5.2 Windows XP (x64).
SizeOfStackReserve — . 1 , 1. Rust , C++ .
SizeOfStackCommit — 4 . .
SizeOfHeapReserve — . 1 .
SizeOfHeapCommit — 4 . SizeOfStackCommit, .
IMAGE_DATA_DIRECTORY — . , , 16 . .
, , . :
Export(0) — . DLL. .
Import(1) — DLL. VirtualAddress = 0x3000 Size = 0xB8. , .
Resource(2) — (, , ..)
.
IMAGE_FILE_HEADER x86 x64.
Machine — x64
NumberOfSections — ( )
TimeDateStamp —
SizeOfOptionalHeader — IMAGE_OPTIONAL_HEADER64, IMAGE_OPTIONAL_HEADER32.
Characteristics — , , (EXECUTABLE_IMAGE) 2 RAM (LARGE_ADDRESS_AWARE), ( ) (RELOCS_STRIPPED | LINE_NUMS_STRIPPED | LOCAL_SYMS_STRIPPED).
SizeOfCode — ( .text)
SizeOfInitializedData — ( .rodata)
SizeOfUninitializedData — ( .bss)
BaseOfCode —
SectionAlignment —
FileAlignment —
SizeOfImage —
SizeOfHeaders — (IMAGE_DOS_HEADER, DOS Stub, IMAGE_NT_HEADERS64, IMAGE_SECTION_HEADER[IMAGE_FILE_HEADER.NumberOfSections]) FileAlignment
Subsystem — GUI Console
MajorOperatingSystemVersion, MinorOperatingSystemVersion, MajorSubsystemVersion, MinorSubsystemVersion — exe, . 5.2 Windows XP (x64).
SizeOfStackReserve — . 1 , 1. Rust , C++ .
SizeOfStackCommit — 4 . .
SizeOfHeapReserve — . 1 .
SizeOfHeapCommit — 4 . SizeOfStackCommit, .
IMAGE_DATA_DIRECTORY — . , , 16 . .
, , . :
Export(0) — . DLL. .
Import(1) — DLL. VirtualAddress = 0x3000 Size = 0xB8. , .
Resource(2) — (, , ..)
.
Nachdem wir uns nun angesehen haben, woraus der NT-Header besteht, werden wir ihn analog zu den anderen bei 0x80 auch in eine Datei schreiben.
(3) RAW NT-Header (Offset 0x00000080)
50 45 00 00 64 86 03 00 F4 70 E8 5E 00 00 00 00
00 00 00 00 F0 00 2F 00 0B 02 00 00 3D 00 00 00
13 00 00 00 00 00 00 00 00 10 00 00 00 10 00 00
00 00 40 00 00 00 00 00 00 10 00 00 00 02 00 00
05 00 02 00 00 00 00 00 05 00 02 00 00 00 00 00
00 40 00 00 00 02 00 00 00 00 00 00 02 00 00 00
00 00 10 00 00 00 00 00 00 10 00 00 00 00 00 00
00 00 10 00 00 00 00 00 00 10 00 00 00 00 00 00
00 00 00 00 10 00 00 00 00 00 00 00 00 00 00 00
00 30 00 00 B8 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
Als Ergebnis erhalten wir diese Art von IMAGE_FILE_HEADER-, IMAGE_OPTIONAL_HEADER64- und IMAGE_DATA_DIRECTORY-Headern:

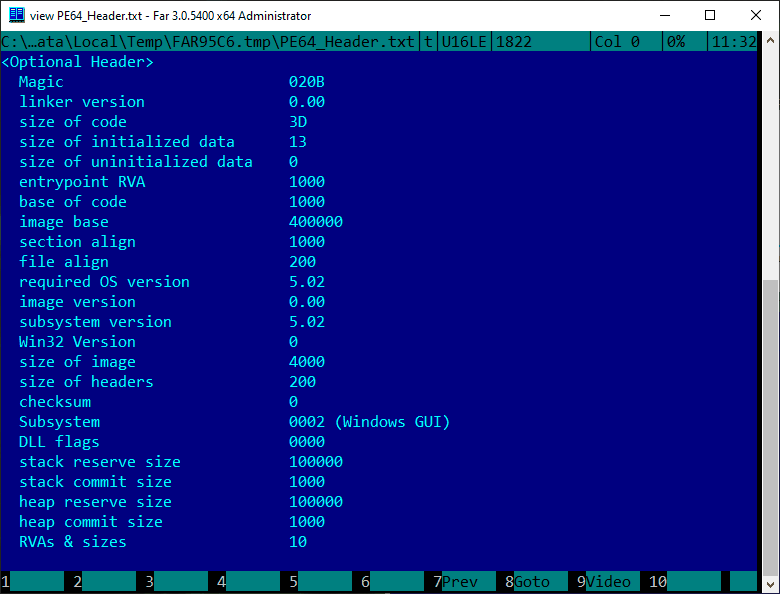

Als Nächstes beschreiben wir alle Abschnitte unserer Anwendung gemäß der IMAGE_SECTION_HEADER-Struktur
IMAGE_SECTION_HEADER-Struktur
Struct IMAGE_SECTION_HEADER
{
i8[8] Name
u32 VirtualSize
u32 VirtualAddress
u32 SizeOfRawData
u32 PointerToRawData
u32 PointerToRelocations
u32 PointerToLinenumbers
u16 NumberOfRelocations
u16 NumberOfLinenumbers
u32 Characteristics
}
Beschreibung von IMAGE_SECTION_HEADER
Name — 8 ,
VirtualSize —
VirtualAddress — SectionAlignment
SizeOfRawData — FileAlignment
PointerToRawData — FileAlignment
Characteristics — (, , , , .)
VirtualSize —
VirtualAddress — SectionAlignment
SizeOfRawData — FileAlignment
PointerToRawData — FileAlignment
Characteristics — (, , , , .)
In unserem Fall haben wir 3 Abschnitte.
Warum Virtual Address (VA) bei 1000 beginnt und nicht bei Null, weiß ich nicht, aber alle Compiler, die ich in Betracht gezogen habe, tun dies. Als Ergebnis sind 1000 + 3 Abschnitte * 1000 (SectionAlignment) = 4000, die wir in SizeOfImage geschrieben haben. Dies ist die Gesamtgröße unseres Programms im virtuellen Speicher. Wird wahrscheinlich verwendet, um Speicherplatz für ein Programm im Speicher zuzuweisen.
Name | RAW Addr | RAW Size | VA | VA Size | Attr
--------+---------------+---------------+-------+---------+--------
.text | 200 | 200 | 1000 | 3D | CER
.rdata | 400 | 200 | 2000 | 13 | I R
.idata | 600 | 200 | 3000 | B8 | I R
Dekodierung von Attributen:
I - Initialisierte Daten, initialisierte Daten
U - Nicht initialisierte Daten, nicht initialisierte Daten
C - Code, enthält ausführbaren Code
E - Ausführen, ermöglicht die Ausführung von
R - Lesecode, ermöglicht das Lesen von Daten aus Abschnitt
W - Schreiben, ermöglicht das Schreiben von Daten in Abschnitt
.text (.code) - speichert ausführbaren Code (das Programm selbst), CE-Attribute
.rdata (.rodata) - speichert schreibgeschützte Daten, z. B. Konstanten, Zeichenfolgen usw., IR-Attribute
.data - speichert Daten, die gelesen und geschrieben werden können, z. B. statische oder globale Variablen. IRW-Attribute
.bss - Speichert nicht initialisierte Daten wie statische oder globale Variablen. Darüber hinaus hat dieser Abschnitt normalerweise eine RAW-Größe von Null und eine VA-Größe ungleich Null, sodass kein Speicherplatz in der Datei belegt wird. URW
.idata- Attribute - Ein Abschnitt mit Funktionen, die aus anderen Bibliotheken importiert wurden. IR-Attribute
Ein wichtiger Punkt, die Abschnitte müssen aufeinander folgen. Darüber hinaus sowohl in der Datei als auch im Speicher. Zumindest als ich ihre Reihenfolge willkürlich änderte, wurde das Programm nicht mehr ausgeführt.
Nachdem wir wissen, welche Abschnitte unser Programm enthalten wird, werden wir sie in unsere Datei schreiben. Hier endet der Versatz bei 8 und die Aufnahme beginnt in der Mitte der Datei.
(4) RAW-Abschnitte (Offset 0x00000188)

2E 74 65 78 74 00 00 00
3D 00 00 00 00 10 00 00 00 02 00 00 00 02 00 00
00 00 00 00 00 00 00 00 00 00 00 00 20 00 00 60
2E 72 64 61 74 61 00 00 13 00 00 00 00 20 00 00
00 02 00 00 00 04 00 00 00 00 00 00 00 00 00 00
00 00 00 00 40 00 00 40 2E 69 64 61 74 61 00 00
B8 00 00 00 00 30 00 00 00 02 00 00 00 06 00 00
00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 40
Die nächste Eintragsadresse ist 00000200, was dem Feld SizeOfHeaders des PE-Headers entspricht. Wenn wir einen weiteren Abschnitt hinzufügen würden, und dies sind plus 40 Bytes, würden unsere Header nicht in 512 (0x200) Bytes passen und müssten 512 + 40 = 552 Bytes verwenden, die durch FileAlignment ausgerichtet sind, dh 1024 (0x400) Bytes. Und alles, was von 0x228 (552) bis zur Adresse 0x400 übrig bleibt, muss mit etwas gefüllt werden, besser natürlich mit Nullen.
Werfen wir einen Blick darauf, wie ein Block von Abschnitten in Far aussieht:
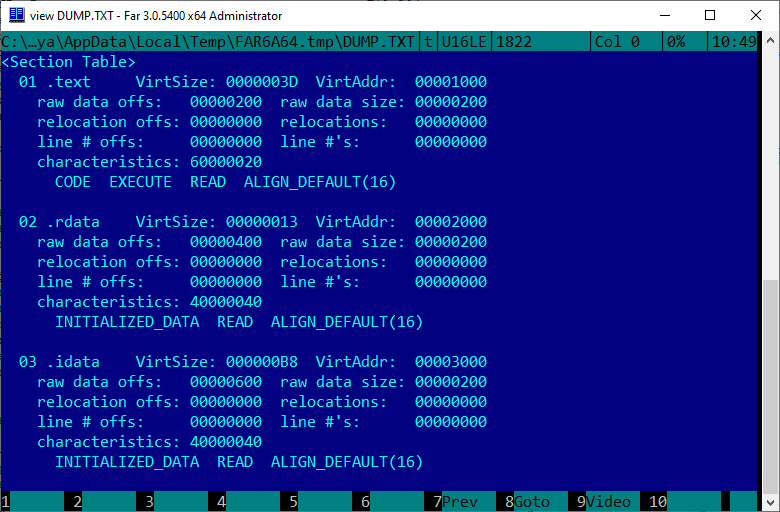
Als Nächstes schreiben wir die Abschnitte selbst in unsere Datei, aber es gibt eine Nuance.
Wie Sie dem SizeOfHeaders-Beispiel entnehmen können, können wir nicht einfach den Header schreiben und mit dem nächsten Abschnitt fortfahren. Da wir zum Aufzeichnen einer Überschrift wissen müssen, wie lange alle Überschriften zusammen dauern werden. Daher müssen wir entweder im Voraus berechnen, wie viel Speicherplatz benötigt wird, oder leere (Null-) Werte schreiben und nach dem Schreiben aller Header ihre tatsächliche Größe zurückgeben und notieren.
Daher werden Programme in mehreren Durchgängen kompiliert. Beispielsweise folgt der Abschnitt .rdata nach dem Abschnitt .text, während die virtuelle Adresse der Variablen in .rdata nicht ermittelt werden kann. Wenn der Abschnitt .text um mehr als 0x1000 (SectionAlignment) Bytes wächst, belegt er die Adressen 0x2000 des Bereichs. Dementsprechend befindet sich der Abschnitt .rdata nicht mehr bei 0x2000, sondern bei 0x3000. Und wir müssen zurückgehen und die Adressen aller Variablen im Abschnitt .text, der vor .rdata steht, neu berechnen.
Aber in diesem Fall habe ich bereits alles berechnet, sodass wir die Codeblöcke sofort aufschreiben werden.
Textabschnitt
Asm-Segment .text
0000 push rbp
0001 mov rbp, rsp
0004 sub rsp, 0x20
0008 mov rcx, 0x0
000F mov rdx, 0x402000
0016 mov r8, 0x40200D
001D mov r9, 0x40
0024 call QWORD PTR [rip + 0x203E]
002A mov rcx, 0x0
0031 call QWORD PTR [rip + 0x2061]
0037 add rsp, 0x20
003B pop rbp
003C ret
Speziell für dieses Programm sind die ersten 3 Zeilen, genau wie die letzten 3, optional.
Die letzten 3 werden nicht einmal ausgeführt, da das Programm bei der zweiten Aufruffunktion beendet wird.
Aber sagen wir mal, wenn es nicht die Hauptfunktion, sondern eine Unterfunktion wäre, sollte es so gemacht werden.
Die ersten 3 sind in diesem Fall zwar wünschenswert, aber wünschenswert. Wenn wir beispielsweise nicht MessageBoxA, sondern printf verwenden würden, würden wir ohne diese Zeilen einen Fehler erhalten.
Gemäß der Aufrufkonvention für 64-Bit-MSDN-Systeme werden die ersten 4 Parameter in den Registern RCX, RDX, R8, R9 übergeben. Wenn sie dort passen und beispielsweise keine Gleitkommazahl sind. Und der Rest wird durch den Stapel geleitet.
Wenn wir theoretisch zwei Argumente an eine Funktion übergeben, müssen wir sie durch Register führen und zwei Stellen im Stapel für sie reservieren, damit die Funktion die Register bei Bedarf auf den Stapel schieben kann. Wir sollten auch nicht erwarten, dass diese Register in ihrem ursprünglichen Zustand an uns zurückgegeben werden.
Das Problem mit der printf-Funktion ist also, dass, wenn wir nur 1 Argument an sie übergeben, immer noch alle 4 Stellen im Stapel überschrieben werden, obwohl anscheinend nur eine um die Anzahl der Argumente überschrieben werden muss.
Wenn Sie nicht möchten, dass sich das Programm seltsam verhält, reservieren Sie immer mindestens 8 Byte * 4 Argumente = 32 (0x20) Byte, wenn Sie mindestens 1 Argument an die Funktion übergeben.
Betrachten Sie einen Codeblock mit Funktionsaufrufen
MessageBoxA(0, 'Hello World!', 'MyApp', 64)
ExitProcess(0)
Zuerst übergeben wir unsere Argumente:
rcx = 0
rdx = die absolute Adresse der Zeichenfolge im Speicher ImageBase + Sections [". Rdata"]. VirtualAddress + Versatz der Zeichenfolge vom Anfang des Abschnitts, die Zeichenfolge wird auf Byte Null gelesen
r8 = ähnlich der vorherigen
r9 = 64 (0x40) MB_ICONINFORMATION , Informationssymbol
Und dann gibt es einen Aufruf der MessageBoxA-Funktion, mit der nicht alles so einfach ist. Der Punkt ist, dass Compiler versuchen, die kürzestmöglichen Befehle zu verwenden. Je kleiner die Befehlsgröße ist, desto mehr solche Befehle passen in den Cache des Prozessors, desto weniger Cache-Fehler, Überladungen und desto schneller ist das Programm. Weitere Informationen zu Befehlen und zum Innenleben des Prozessors finden Sie in den Entwicklerhandbüchern für Intel 64- und IA-32-Architekturen.
Wir könnten die Funktion an der vollständigen Adresse aufrufen, aber das würde mindestens dauern (1 Opcode + 8 Adresse = 9 Bytes), und bei einer relativen Adresse dauert der Aufrufbefehl nur 6 Bytes.
Schauen wir uns diese Magie genauer an: rip + 0x203E ist nichts anderes als ein Funktionsaufruf an der durch unseren Offset angegebenen Adresse.
Ich schaute ein wenig nach vorne und fand die Adressen der Offsets heraus, die wir brauchen. Für MessageBoxA ist es 0x3068 und für ExitProcess ist es 0x3098.
Es ist Zeit, Magie in Wissenschaft zu verwandeln. Jedes Mal, wenn ein Opcode auf den Prozessor trifft, berechnet er seine Länge und fügt ihn der aktuellen Befehlsadresse (RIP) hinzu. Wenn wir RIP in einem Befehl verwenden, gibt diese Adresse daher das Ende des aktuellen Befehls / den Beginn des nächsten an.
Beim ersten Aufruf zeigt der Versatz das Ende des Aufrufbefehls an, dies ist 002A. Vergessen Sie nicht, dass sich diese Adresse im Speicher in den Versatzabschnitten [". Text"] befindet. VirtualAddress, d. H. 0x1000. Daher beträgt der RIP für unseren Anruf 102A. Die Adresse, die wir für MessageBoxA benötigen, lautet 0x3068. Betrachten Sie 0x3068 - 0x102A = 0x203E . Für die zweite Adresse ist alles dasselbe wie 0x1000 + 0x0037 = 0x1037, 0x3098 - 0x1037 = 0x2061 .
Es sind diese Offsets, die wir in den Assembler-Befehlen gesehen haben.
0024 call QWORD PTR [rip + 0x203E]
002A mov rcx, 0x0
0031 call QWORD PTR [rip + 0x2061]
0037 add rsp, 0x20
Schreiben wir den Textabschnitt in unsere Datei und fügen der Adresse 0x400 Nullen hinzu:
(5) RAW-Textabschnitt (Offset 0x00000200-0x00000400)
55 48 89 E5 48 83 EC 20 48 C7 C1 00 00 00 00 48
C7 C2 00 20 40 00 49 C7 C0 0D 20 40 00 49 C7 C1
40 00 00 00 FF 15 3E 20 00 00 48 C7 C1 00 00 00
00 FF 15 61 20 00 00 48 83 C4 20 5D C3 00 00 00
........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
4 . FileAlignment. 0x000003F0, 0x00000400, . 1024 , ! .
Abschnitt Daten
Dies ist vielleicht der einfachste Abschnitt. Wir werden hier nur zwei Zeilen einfügen und 512 Bytes mit Nullen versehen.
.rdata
0400 "Hello World!\0"
040D "MyApp\0"
(6) RAW .rdata-Abschnitt (Offset 0x00000400-0x00000600)
48 65 6C 6C 6F 20 57 6F 72 6C 64 21 00 4D 79 41
70 70 00 00 00 00 00 00 00 00 00 00 00 00 00 00
........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
.Idatenabschnitt
Nun, hier ist der letzte Abschnitt, der importierte Funktionen aus Bibliotheken beschreibt.
Das erste, was uns erwartet, ist die neue Struktur IMAGE_IMPORT_DESCRIPTOR
IMAGE_IMPORT_DESCRIPTOR-Struktur
Struct IMAGE_IMPORT_DESCRIPTOR
{
u32 OriginalFirstThunk (INT)
u32 TimeDateStamp
u32 ForwarderChain
u32 Name
u32 FirstThunk (IAT)
}
Beschreibung IMAGE_IMPORT_DESCRIPTOR
OriginalFirstThunk — , Import Name Table (INT)
Name — ,
FirstThunk — , Import Address Table (IAT)
Name — ,
FirstThunk — , Import Address Table (IAT)
Zuerst müssen wir 2 importierte Bibliotheken hinzufügen. Erinnern:
func MessageBoxA(u32 handle, PChar text, PChar caption, u32 type) i32 ['user32.dll']
func ExitProcess(u32 code) ['kernel32.dll']
(7) RAW IMAGE_IMPORT_DESCRIPTOR (Offset 0x00000600)
58 30 00 00 00 00 00 00 00 00 00 00 3C 30 00 00
68 30 00 00 88 30 00 00 00 00 00 00 00 00 00 00
48 30 00 00 98 30 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00
Wir verwenden 2 Bibliotheken und sagen, dass wir die Auflistung abgeschlossen haben. Die letzte Struktur ist mit Nullen gefüllt.
INT | Time | Forward | Name | IAT
--------+--------+----------+--------+--------
0x3058 | 0x0 | 0x0 | 0x303C | 0x3068
0x3088 | 0x0 | 0x0 | 0x3048 | 0x3098
0x0000 | 0x0 | 0x0 | 0x0000 | 0x0000
Fügen wir nun die Namen der Bibliotheken selbst hinzu:
Bibliotheksnamen
063 "user32.dll\0"
0648 "kernel32.dll\0"
(8) RAW-Bibliotheksnamen (Offset 0x0000063C)
75 73 65 72
33 32 2E 64 6C 6C 00 00 6B 65 72 6E 65 6C 33 32
2E 64 6C 6C 00 00 00 00
Als nächstes beschreiben wir die user32-Bibliothek:
(9) RAW user32.dll (Offset 0x00000658)
78 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 78 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 4D 65 73 73 61 67
65 42 6F 78 41 00 00 00
Das Feld Name der ersten Bibliothek zeigt auf 0x303C. Wenn wir etwas höher schauen, sehen wir, dass sich unter der Adresse 0x063C eine Bibliothek "user32.dll \ 0" befindet.
Hinweis: Denken Sie daran, dass der Abschnitt .idata dem Dateiversatz 0x0600 und dem Speicherversatz 0x3000 entspricht. Für die erste Bibliothek ist INT 3058, was bedeutet, dass es in der Datei um 0x0658 versetzt wird. An dieser Adresse sehen wir den Eintrag 0x3078 und die zweite Null. Das Ende der Liste kennzeichnen. 3078 bezieht sich auf 0x0678 Dies ist die RAW-Zeichenfolge
"00 00 4D 65 73 73 61 67 65 42 6F 78 41 00 00 00"
Die ersten 2 Bytes sind für uns nicht von Interesse und gleich Null. Und dann gibt es eine Zeile mit dem Namen der Funktion, die mit Null endet. Das heißt, wir können es als "\ 0 \ 0MessageBoxA \ 0" darstellen.
In diesem Fall bezieht sich der IAT auf eine Struktur ähnlich der IAT-Tabelle, in die jedoch nur die Funktionsadressen geladen werden, wenn das Programm gestartet wird. Beispielsweise hat der erste Eintrag 0x3068 im Speicher einen anderen Wert als 0x0668 in der Datei. Es wird die Adresse der MessageBoxA-Funktion geben, die vom System geladen wird, auf die wir über den Aufruf im Programmcode verweisen.
Und das letzte Puzzleteil, der Kernel32. Und vergessen Sie nicht, SectionAlignment Nullen hinzuzufügen.
(10) RAW-Kernel32.dll (Offset 0x00000688-0x00000800)

A8 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 A8 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 45 78 69 74 50 72
6F 63 65 73 73 00 00 00 00 00 00 00 00 00 00 00
........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Wir überprüfen, ob Far die von uns importierten Funktionen korrekt identifizieren konnte:
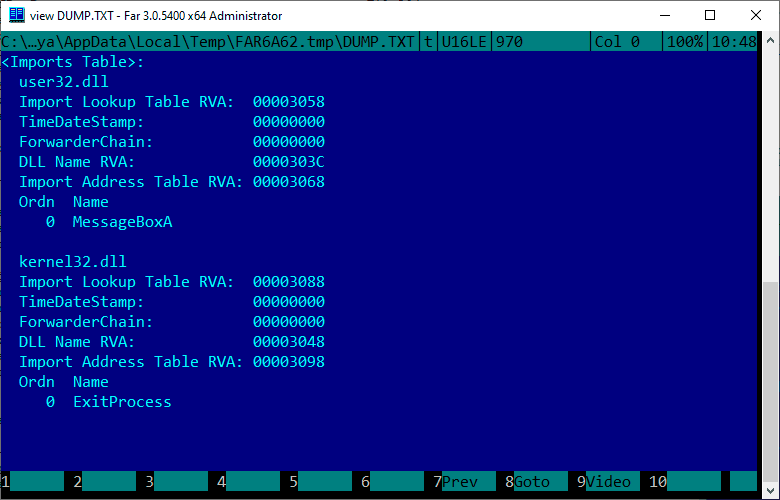
Großartig! Alles war in Ordnung, jetzt kann unsere Datei ausgeführt werden.
Trommelwirbel…
Das endgültige

Herzlichen Glückwunsch, wir haben es geschafft!
Die Datei belegt 2 KB = Header 512 Bytes + 3 Abschnitte mit 512 Bytes.
Die Nummer 512 (0x200) ist nichts anderes als die FileAlignment, die wir im Header unseres Programms angegeben haben.
Zusätzlich:
Wenn Sie etwas tiefer gehen möchten, können Sie die Aufschrift "Hello World!" Vergessen Sie nicht, die Adresse der Zeile im Programmcode (Abschnitt .text) zu ändern. Die Adresse im Speicher lautet 0x00402000, aber die Datei hat die umgekehrte Bytereihenfolge 00 20 40 00.
Oder die Suche ist etwas komplizierter. Fügen Sie dem Code einen weiteren MessageBox-Aufruf hinzu. Dazu müssen Sie den vorherigen Anruf kopieren und die relative Adresse (0x3068 - RIP) darin neu berechnen.
Fazit
Der Artikel erwies sich als ziemlich zerknittert, er würde natürlich aus 3 separaten Teilen bestehen: Überschriften, Programm, Importtabelle.
Wenn jemand seine Exe zusammengestellt hat, war meine Arbeit nicht umsonst.
Ich denke darüber nach, bald eine ELF-Datei auf ähnliche Weise zu erstellen. Wäre ein solcher Artikel interessant?)
Links:
- Intel 64- und IA-32-Architekturen Software-Entwicklerhandbücher
Befehls- und Prozessorarchitekturhandbuch.
- PE (Portable Executable): On Stranger Tides
Ausgezeichneter Artikel zur exe-Dateistruktur. - Microsoft Documentation Repository
Hier finden Sie Informationen zu Headern, Strukturen, Typen und deren Beschreibung