
Das Mail.ru Cloud Solutions- Teamübersetzte einen gekürzten Aufsatz von Kevin Wu , in dem erörtert wird, was die Pharma- und Gesundheitsbranche mit künstlicher Intelligenz und maschinellem Lernen bereits erreicht hat und wann neue Technologien bei der Suche nach Medikamenten helfen von allen Krankheiten.
Warum es so scheint, als gäbe es keinen Fortschritt
Einige Leute drücken ihre Frustration über das Leben so aus: "Wenn dies die Zukunft ist, wo ist dann mein Jetpack?" Auf den ersten Blick erscheint eine solche Sehnsucht nach einer Retro-Zukunft in einer Zeit allgegenwärtiger Computer, programmierbarer Zellen und einer wiederauflebenden Weltraumforschung seltsam . Aber für einige hält sich dieser nostalgische Futurismus überraschend gut. Sie halten an Vorhersagen fest, die im Nachhinein seltsam aussehen, und ignorieren die verblüffende Realität, die niemand hätte vorhersagen können.
Wer hätte gedacht, dass wir dank tiefem Lernen die Eigenschaften von Medikamenten vorhersagen können, die es noch nicht gibt? Dies ist für die Pharmaindustrie von größter Bedeutung.
In Bezug auf künstliche Intelligenz können Beschwerden ungefähr so klingen: „Seit der Erfindung des neuronalen AlexNet-Netzwerks sind fast acht Jahre vergangen [ ca. Übersetzer : Im Jahr 2012 veröffentlichte Aleksey Krizhevsky das Design des AlexNet-Faltungsnetzwerks, das den ImageNet-Wettbewerb mit großem Abstand gewann. Wo ist also mein selbstfahrendes Auto? " In der Tat scheint es, dass die Erwartungen von Mitte 2010 nicht erfüllt wurden. Unter den Pessimisten gewinnen Prognosen für die nächste Stagnation in der KI-Forschung an Dynamik .
Der Zweck dieses Aufsatzes ist es, den bedeutenden Fortschritt des maschinellen Lernens in der realen Herausforderung der Wirkstoffforschung zu diskutieren. Ich möchte Sie an ein anderes altes Sprichwort erinnern, diesmal von KI-Forschern. Um es leicht umzuformulieren, es klingt so: "KI heißt KI, bis es funktioniert, dann ist es nur Software."
Was bis vor einigen Jahren als Spitzenforschung im Bereich des maschinellen Lernens galt, wird heute oft als „nur Datenwissenschaft “ (oder sogar Analytik) bezeichnet - und revolutioniert die Pharmaindustrie. Es besteht eine solide Chance, dass der Einsatz von Deep Learning zur Entdeckung von Drogen unser Leben dramatisch zum Besseren verändern wird.
Computer Vision und Deep Learning in der biomedizinischen Bildgebung
Sobald Wissenschaftler Zugang zu Computern hatten und die Möglichkeit hatten, dort Bilder hochzuladen, versuchten sie sofort, diese zu verarbeiten. Grundsätzlich handelt es sich um biomedizinische Bilder: Röntgenbilder, Ultraschall- und MRT-Ergebnisse. In den Tagen der guten alten KI bedeutete die Verarbeitung normalerweise das manuelle Ableiten logischer Anweisungen auf der Grundlage einfacher Attribute wie Konturen und Helligkeit.
In den 1980er Jahren kam es zu einer Verlagerung hin zu überwachten Algorithmen für maschinelles Lernenaber sie verließen sich immer noch auf handgefertigte Tags. Einfache überwachte Lernmodelle (wie lineare Regression oder Polynomanpassung) werden auf Merkmalen trainiert, die mit Algorithmen wie SIFT (Scale Invariant Feature Transformation) und HOG (Histogram of Directed Gradients) extrahiert wurden. Es sollte nicht überraschen, dass die Entwicklungen, die heute zur praktischen Anwendung von Deep Learning geführt haben, vor Jahrzehnten begonnen haben.
Faltungsneurale Netze wurden erstmals 1995 von Law und Kollegen für die Analyse biomedizinischer Bilder verwendetstellten ein Modell zur Erkennung von Krebstumoren in der Lunge anhand von Fluorogrammen vor. Ihre Methode war ein wenig anders als die, die wir heute gewohnt sind. Die Ableitung des Ergebnisses dauerte ungefähr 15 Sekunden, aber das Konzept war im Wesentlichen dasselbe - mit Lernen durch Backpropagation bis zu den Faltungskernen des neuronalen Netzwerks. Ihr Modell umfasste zwei verborgene Schichten, während die heutigen beliebten Deep-Network-Architekturen häufig einhundert oder mehr Schichten aufweisen.
Schneller Vorlauf bis 2012. Faltungs-Neuronale Netze sorgten mit der Einführung des AlexNet-Systems für Furore, was zu einem Leistungssprung des mittlerweile berühmten ImageNet-Datensatzes führte. Der Erfolg von AlexNet, einem Netzwerk mit fünf Faltungsschichten und drei eng gekoppelten Schichten, die auf Spiel-GPUs trainiert wurden, ist im maschinellen Lernen so berühmt geworden, dass die Leute jetzt über „Momente von ImageNet “in verschiedenen Nischen des maschinellen Lernens und der KI.
Beispiel: "Die Verarbeitung natürlicher Sprache hat möglicherweise ihren ImageNet-Moment mit der Entwicklung großer Transformatoren im Jahr 2018 überlebt" oder "Reinforcement Learning wartet noch auf seinen ImageNet-Moment".
Fast zehn Jahre sind seit AlexNet vergangen. Computer Vision und Deep Learning-Modelle verbessern sich allmählich. Anwendungen sind über die Klassifizierung hinausgegangen. Heute haben sie gelernt, wie man Bilder segmentiert, die Tiefe schätzt und 3D-Szenen aus mehreren 2D-Bildern automatisch rekonstruiert. Und dies ist keine vollständige Liste ihrer Fähigkeiten.
Deep Learning für die biomedizinische Bildgebungsanalyse ist zu einem heißen Forschungsgebiet geworden. Ein Nebeneffekt ist eine unvermeidliche Zunahme des Lärms. Veröffentlicht im Jahr 2019ungefähr 17.000 wissenschaftliche Artikel über tiefes Lernen . Natürlich sind nicht alle lesenswert. Es ist wahrscheinlich, dass viele Forscher Modelle in ihren bescheidenen Datensätzen zu stark anpassen.
Die meisten von ihnen haben keine Beiträge zur Grundlagenforschung oder zum maschinellen Lernen geleistet. Die Leidenschaft für tiefes Lernen hat akademische Forscher erfasst, die zuvor aus gutem Grund kein Interesse daran gezeigt hatten. Es kann das tun, was klassische Computer-Vision-Algorithmen tun (siehe den universellen Approximationssatz von Tsybenko und Hornik), und oft schneller und besser, wodurch Ingenieure vor dem mühsamen manuellen Entwurf jeder neuen Anwendung geschützt werden.
Eine seltene Gelegenheit, "vernachlässigte" Krankheiten zu bekämpfen
Dies bringt uns zum heutigen Thema der Wirkstoffforschung - einer Branche, die vor einer guten Umstellung steht. Pharmaunternehmen und ihre Auftragnehmer wiederholen gerne die enormen Kosten für die Markteinführung eines neuen Arzneimittels. Diese Kosten sind hauptsächlich auf die Tatsache zurückzuführen, dass viele Medikamente lange Zeit zum Studieren und Testen benötigen, bevor sie konsumiert werden.
Die Kosten für die Entwicklung eines neuen Arzneimittels können 2,5 Milliarden US-Dollar oder mehr erreichen . Aufgrund der hohen Kosten und der relativ geringen Rentabilität wird manchmal eine Reihe von Arbeiten zu bestimmten Arzneimittelklassen in den Hintergrund gedrängt .
Es führt auch zu einem Anstieg der Inzidenz in der treffend genannten Kategorie der "vernachlässigten Krankheiten", einschließlich einer überproportionalen Anzahl von Tropenkrankheiten.die Menschen in den ärmsten Ländern betreffen und als nachteilig für die Behandlung gelten, sowie seltene Krankheiten mit niedrigen Inzidenzraten. Relativ wenige Menschen leiden an jedem von ihnen, aber die Gesamtzahl der Menschen mit allen seltenen Krankheiten ist ziemlich groß. Es wird geschätzt, dass etwa 300 Millionen Menschen. Und selbst diese Zahl kann aufgrund der düsteren Einschätzung von Experten unterschätzt werden: Etwa 30% derjenigen, die an einer seltenen Krankheit leiden, werden nicht älter als fünf Jahre.
" Langer Schwanz»Seltene Krankheiten haben ein erhebliches Potenzial, das Leben einer großen Anzahl von Menschen zu verbessern, und hier kommen maschinelles Lernen und Big Data zum Einsatz. Der blinde Fleck für seltene (verwaiste) Krankheiten, für die keine offiziell genehmigte Behandlung vorliegt, eröffnet kleinen Teams von Biologen und Entwicklern des maschinellen Lernens die Möglichkeit zur Innovation.
Ein solches Startup in Salt Lake City, Utah, versucht genau das zu tun. Die Gründer von Recursion Pharmaceuticals betrachten den Mangel an Arzneimitteln für seltene Krankheiten als eine Lücke in der Pharmaindustrie. Sie erhalten riesige Datenmengen, indem sie die Ergebnisse von Mikroskopie und Labortests analysieren. Mit Hilfe neuronaler Netze ist es möglich, die Merkmale von Krankheiten zu identifizieren und Behandlungsmethoden zu suchen.
Bis Ende 2019 hatte das Unternehmen Tausende von Experimenten durchgeführt und über 4 Petabyte an Informationen gesammelt. Sie haben eine kleine Teilmenge dieser Daten (46 GB) für den NeurIps 2019-Wettbewerb veröffentlicht. Sie können sie von der RxRx-Website herunterladen und selbst herumspielen .
Der in diesem Artikel beschriebene Workflow basiert größtenteils auf Informationen aus den White Papers [ pdf ] von Recursion Pharmaceuticals. Dieser Ansatz kann jedoch durchaus Inspiration für andere Bereiche liefern.
Weitere Startups auf diesem Gebiet sind Bioage Labs (Alterungskrankheiten), Notable Labs (Onkologie) und TwoXAR.(verschiedene Krankheiten, für die es keine Behandlungsmöglichkeiten gibt). In der Regel beschäftigen sich junge Startups mit innovativen Datenverarbeitungstechniken und wenden neben oder anstelle von Deep Learning mit Computer Vision eine Vielzahl von Methoden des maschinellen Lernens an.
Als nächstes beschreibe ich den Bildanalyseprozess und wie tiefes Lernen in den Workflow zur Entdeckung seltener Krankheiten passt. Wir werden uns einen Prozess auf hoher Ebene ansehen, der auf eine Vielzahl anderer Bereiche der Wirkstoffforschung anwendbar ist.
Zum Beispiel kann es leicht verwendet werden, um Krebsmedikamente auf ihre Wirkung auf die Tumorzellmorphologie zu untersuchen. Vielleicht sogar, um die Reaktion von Zellen bestimmter Patienten auf verschiedene Arzneimitteloptionen zu analysieren. Dieser Ansatz verwendet Konzepte aus der nichtlinearen Hauptkomponentenanalyse, semantisches Hashing [ pdf ] und gute alte Bildklassifikation des Faltungsnetzwerks.
Klassifizierung in morphologisches Rauschen
Biologie ist ein Chaos. Daher ist die Multiparameter-Mikroskopie mit hohem Durchsatz für Zellbiologen eine Quelle ständiger Frustration. Die resultierenden Bilder unterscheiden sich stark von einem Experiment zum nächsten. Schwankungen der Temperatur, der Expositionszeit, der Menge der Reagenzien und anderer Faktoren führen zu Änderungen, die nicht mit dem untersuchten Phänotyp oder der Arzneimittelwirkung zusammenhängen, und daher zu Fehlern bei den erhaltenen Ergebnissen.
Vielleicht funktioniert die Klimatisierung in einem Labor im Sommer und Winter unterschiedlich? Vielleicht hat jemand neben den Objektträgern zu Mittag gegessen, bevor er sie in das Mikroskop eingeführt hat? Vielleicht hat sich der Lieferant eines der Inhaltsstoffe des Kulturmediums geändert? Oder hat der Lieferant seinen eigenen Lieferanten gewechselt? Eine Vielzahl von Variablen beeinflusst das Ergebnis eines Experiments. Das Verfolgen und Hervorheben von unbeabsichtigtem Lärm ist eine der größten Herausforderungen bei der datengesteuerten Wirkstoffentdeckung.
Bilder unter dem Mikroskop können in denselben Experimenten sehr unterschiedlich sein. Die Helligkeit des Bildes, die Form der Zellen, die Form der Organellen und viele andere Eigenschaften ändern sich aufgrund der entsprechenden physiologischen Effekte oder zufälligen Fehler.
Die Bilder in der folgenden Abbildung werden also von denselben erhaltenein öffentlich verfügbarer Satz von mikroskopischen Aufnahmen von metastasierten Krebszellen, zusammengestellt von Scott Wilkinson und Adam Marcus. Variationen in Sättigung und Morphologie sollten die Unsicherheit der experimentellen Daten widerspiegeln. Sie entstehen durch das Einbringen von Verzerrungen in die Verarbeitung. Es ist eine Art Analogon der Augmentation, mit dem Forscher tiefe neuronale Netze bei Klassifizierungsproblemen regulieren. Daher sollte es nicht überraschen, dass die Möglichkeit, große Modelle auf große Datensätze zu verallgemeinern, eine logische Wahl für die Suche nach physiologisch bedeutsamen Merkmalen in einem Meer von Rauschen ist.
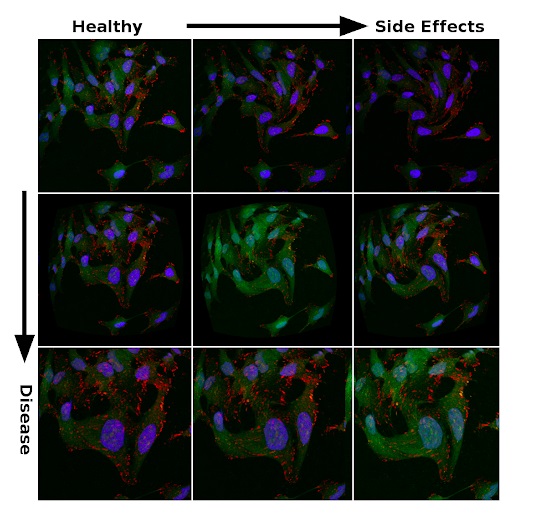
Anzeichen von Wirksamkeit der Behandlung und Nebenwirkungen bei verrauschten Daten
Die Hauptursache für seltene Krankheiten ist normalerweise eine genetische Mutation. Um Modelle zu erstellen, um eine Heilung für diese Krankheiten zu finden, ist es notwendig, die Auswirkungen einer Vielzahl von Mutationen und ihre Beziehung zu verschiedenen Phänotypen zu verstehen. Um mögliche Behandlungen für eine bestimmte seltene Krankheit effektiv zu vergleichen, werden neuronale Netze basierend auf Tausenden verschiedener Mutationen trainiert.
Diese Mutationen können durch Unterdrückung der Genexpression unter Verwendung kleiner störender RNAs nachgeahmt werden(siRNA). Es ist ein bisschen so, als würden Babys Ihre Knöchel packen: Selbst wenn Sie schnell laufen können, sinkt Ihre Geschwindigkeit dramatisch, wenn Ihre Nichte oder Ihr Neffe an jedem Bein hängen. siRNA funktioniert auf ähnliche Weise: Eine kleine Sequenz störender RNAs haftet an den entsprechenden Teilen der Messenger-RNA bestimmter Gene und verhindert deren vollständige Expression.
Durch das Lernen aus Tausenden von Mutationen anstelle eines singulären zellulären Modells einer bestimmten Krankheit lernt das neuronale Netzwerk, Phänotypen in einem mehrdimensionalen verborgenen Raum zu codieren. Der resultierende Code ermöglicht es, Arzneimittel anhand ihrer Fähigkeit zu bewerten, den Krankheitsphänotyp einem gesunden Phänotyp näher zu bringen, der jeweils durch einen mehrdimensionalen Satz von Koordinaten dargestellt wird. Ebenso können die Nebenwirkungen von Arzneimitteln in die codierte Darstellung des Phänotyps eingebettet werden, und Arzneimittel werden nicht nur auf das Verschwinden von Krankheitssymptomen, sondern auch auf die Minimierung schädlicher Nebenwirkungen untersucht.

Das Diagramm zeigt die Wirkung der Behandlung auf das zelluläre Modell der Krankheit (dargestellt durch einen roten Punkt). Die Behandlung ist die Bewegung des codierten Phänotyps näher an den gesunden Phänotyp (blauer Punkt). Dies ist eine vereinfachte 3D-Darstellung der phänotypischen Codierung in einem mehrdimensionalen verborgenen Raum.
Die für diesen Workflow verwendeten Deep-Learning-Modelle sind anderen Klassifizierungsproblemen mit einem großen Datensatz sehr ähnlich, obwohl Sie es gewohnt sind, mit einer kleinen Anzahl von Kategorien zu arbeiten, wie in CIFAR-10-Datensätzen und CIFAR-100, Sie werden sich nicht sofort an die Tausenden verschiedener Klassifizierungsmarken gewöhnen.
Diese bildbasierte Methode zur Wirkstoffentdeckung funktioniert auch gut mit derselben DenseNet- oder ResNet-Architektur mit Hunderten von Schichten, wodurch eine optimale Leistung für Datensätze wie ImageNet erzielt wird.
Schichtaktivierungswerte, die in einem mehrdimensionalen Raum codiert sind, spiegeln den Phänotyp, die Pathogenese der Krankheit, die Beziehungen zwischen Behandlungen, Nebenwirkungen und andere Krankheiten wider. Daher können alle diese Faktoren durch Verschiebung im codierten Raum analysiert werden. Dieser phänotypische Code kann einer speziellen Regularisierung unterzogen werden (z. B. durch Minimierung der Kovarianz zwischen verschiedenen Aktivierungen von Schichten), um Codierungskorrelationen zu verringern, oder für andere Zwecke.
Die folgende Abbildung zeigt ein vereinfachtes Modell. Schwarze Pfeile stehen für die Operationen Faltung + Pooling. Blaue Linien stehen für enge Verbindungen. Der Einfachheit halber wurde die Anzahl der Schichten reduziert und Restverbindungen sind nicht gezeigt.
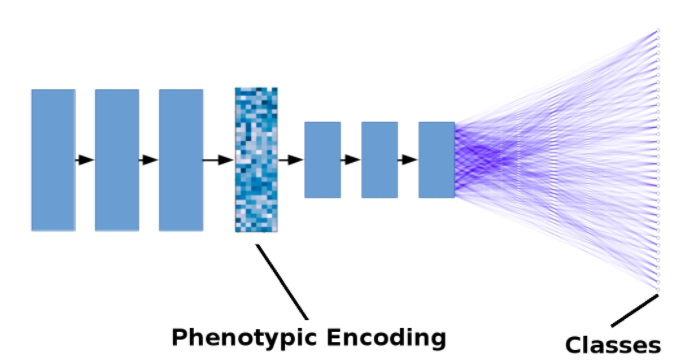
Vereinfachte Darstellung eines Deep-Learning-Modells für die Wirkstoffentdeckung
Die Zukunft des Deep Learning in der Wirkstoffforschung und in der Pharmaindustrie
Die hohen Kosten für die Markteinführung neuer Medikamente haben dazu geführt, dass sich Pharmaunternehmen häufig für Markttreffer entschieden haben, anstatt Medikamente für schwere Krankheiten zu erforschen. Kleinere Datenanalyseteams in Startups sind besser für Innovationen in diesem Bereich gerüstet, während vernachlässigte und seltene Krankheiten die Möglichkeit bieten, in den Markt einzutreten und den Wert des maschinellen Lernens zu demonstrieren.
Die Wirksamkeit dieses Ansatzes wurde nachgewiesen. Wir sehen bedeutende Forschungsfortschritte und mehrere Medikamente befinden sich bereits in der ersten Phase klinischer Studien. Dies erreichen beispielsweise Teams von nur wenigen hundert Wissenschaftlern und Ingenieuren in Unternehmen wie Recursion Pharmaceuticals. Andere Startups sind in unmittelbarer Nähe: TwoXAR hat mehrere Medikamentenkandidaten, die präklinische Studien in anderen Kategorien von Krankheiten durchlaufen.
Es ist zu erwarten, dass der Deep-Learning- und Computer-Vision-Ansatz für die Arzneimittelentwicklung erhebliche Auswirkungen auf große Pharmaunternehmen und das Gesundheitswesen im Allgemeinen haben wird. Wir werden bald sehen, wie sich dies auf die Entwicklung neuer Therapien für häufige Krankheiten (einschließlich Herzkrankheiten und Diabetes) sowie auf seltene Krankheiten auswirken wird, die bis heute nicht sichtbar sind.
Was gibt es sonst noch zu diesem Thema zu lesen: