
Eine der Aufgaben einer phonoskopischen Untersuchung besteht darin, die Authentizität und Authentizität einer Audioaufnahme festzustellen - mit anderen Worten, Anzeichen von Bearbeitung, Verzerrung und Veränderung der Aufnahme zu identifizieren. Wir hatten die Aufgabe, es durchzuführen, um die Echtheit der Aufzeichnungen festzustellen - um festzustellen, dass kein Einfluss auf die Aufzeichnungen ausgeübt wurde. Aber wie kann man Tausende und sogar Hunderttausende von Audioaufnahmen analysieren?
Zu unserer Rettung kommen KI-Methoden sowie ein Hilfsprogramm für die Arbeit mit Audio, über das wir in einem Artikel auf der NewTechAudit-Website "PROCESSING AUDIO WITH FFMPEG" gesprochen haben .
Wie erscheinen Änderungen im Audio? Wie können Sie eine geänderte Datei von einer unberührten Datei unterscheiden?
Es gibt mehrere solcher Anzeichen. Am einfachsten ist es, Informationen zum Bearbeiten einer Datei zu identifizieren und das Datum ihrer Änderung zu analysieren. Diese Methoden lassen sich leicht über das Betriebssystem selbst implementieren, daher werden wir uns nicht mit diesen Methoden befassen. Änderungen können jedoch von einem qualifizierten Benutzer vorgenommen werden, der die Informationen zum Bearbeiten ausblenden oder ändern kann. In diesem Fall werden komplexere Methoden verwendet, z. B.:
- Verschiebung von Konturen;
- Ändern des Spektralprofils des aufgezeichneten Audios;
- das Auftreten von Pausen;
- und viele andere.
Und all diese komplizierten Sondierungsmethoden werden von speziell ausgebildeten Experten durchgeführt - Phonoskopikern, die spezielle Software wie Praat, Speech Analyzer SIL und ELAN verwenden. Die meisten davon werden bezahlt und erfordern ausreichend hohe Qualifikationen, um die Ergebnisse zu verwenden und zu interpretieren.
Experten analysieren Audio unter Verwendung eines Spektralprofils, nämlich durch Analyse seiner Cepstralkoeffizienten. Wir werden die Erfahrung von Experten nutzen und gleichzeitig den vorgefertigten Code verwenden, um ihn an unsere Aufgabe anzupassen.
Es können also viele Änderungen vorgenommen werden. Wie wählen wir aus?
Von den möglichen Arten von Änderungen, die an Audiodateien vorgenommen werden können, sind wir daran interessiert, ein Teil aus dem Audio auszuschneiden oder ein Teil auszuschneiden und dann das Originalteil durch ein Stück derselben Dauer zu ersetzen - die sogenannten Schnitt- / Kopieränderungen. Das Bearbeiten von Dateien im Hinblick auf Rauschunterdrückung, Ändern der Tonfrequenz und andere birgt nicht das Risiko, Informationen zu verbergen.
Und wie werden wir denselben Schnitt / dieselbe Kopie identifizieren? Sollten sie mit etwas verglichen werden?
Es ist sehr einfach - mit Hilfe des FFmpeg-Dienstprogramms werden wir einen Teil einer zufälligen Dauer aus der Datei ausschneiden und an einer zufälligen Stelle die klein-cepstralen Spektrogramme des Originals und der "cut" -Datei vergleichen.
Code zur Anzeige:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' Wir bereiten einen Datensatz aus der Quelle vor und schneiden Dateien mit dem Befehl FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav Dabei sind STARTTIME und ENDTIME der Anfang und das Ende des geschnittenen Fragments. Und mit dem Befehl:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavFügen Sie den Teil der Datei hinzu, um part_1.wav mit den Originalteilen einzufügen (Informationen zum Umschließen von FFmpeg-Befehlen in Python finden Sie in unserem Artikel zu FFmpeg).
Hier sind die Originaldateien, deren Kreidespektrogramm aus dem Audio von 0,2 bis 2,5 Sekunden herausgeschnitten wurde, und das Kreidespektrogramm von Dateien, die aus dem Audio von 0,2 bis 2,5 Sekunden herausgeschnitten und dann in die Audiofragmente einer ähnlichen Dauer dieser Audiodatei eingefügt wurden:
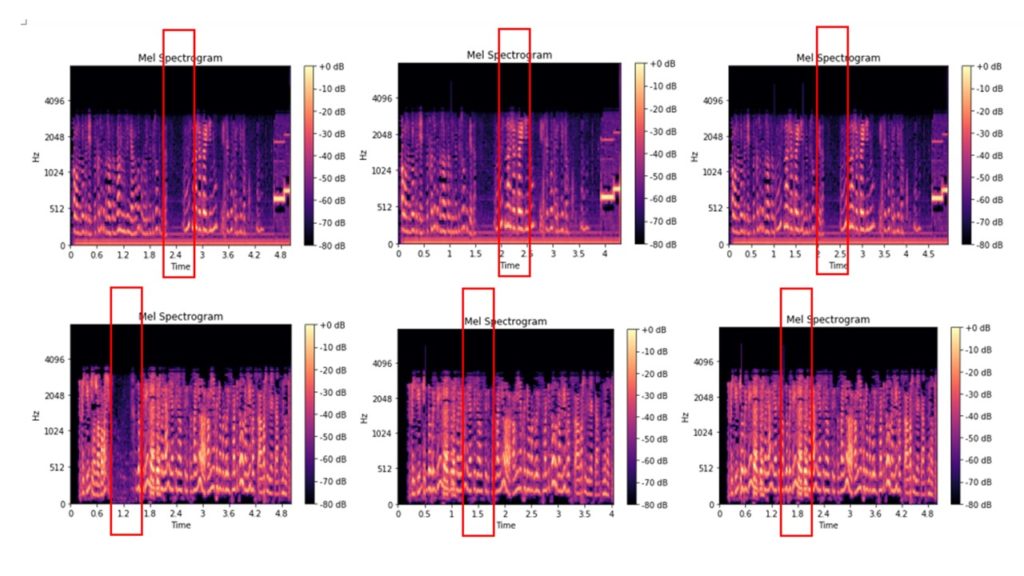
Einige Bilder sind auch optisch unterscheidbar, andere sehen fast gleich aus. Wir verteilen die resultierenden Bilder in Ordnern und verwenden sie als Eingabedaten, um das Modell für die Bildklassifizierung zu trainieren. Ordnerstruktur:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # Für uns spielt es keine Rolle, ob die geänderte Audiodatei hinzugefügt oder gekürzt wurde - wir teilen alle Ergebnisse in gute, dh Dateien ohne Änderungen und schlechte auf. Damit lösen wir das klassische Problem der binären Klassifikation. Wir werden anhand neuronaler Netze klassifizieren und den Code für die Arbeit mit einem neuronalen Netz anhand von Beispielen für die Arbeit mit dem Keras-Paket verwenden.
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)Nachdem das Modell trainiert wurde, führen wir die Klassifizierung mit seiner Hilfe durch
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'Am Ausgang erhalten wir die Klassifizierung der Audiodatei - 'original' / 'korrupt', d. H. die Datei unverändert und die Dateien, an denen die Änderungen vorgenommen wurden.
Wir haben erneut bewiesen, dass komplex aussehende Dinge einfach erledigt werden können - wir haben nicht den schwierigsten Mechanismus von KI-Methoden verwendet, vorgefertigte Lösungen und das Audio auf Änderungen überprüft. Nun, wir waren die Experten des Detektivs.