Um zu verstehen, wie B-Tree-Indizes entstanden sind, stellen wir uns eine Welt ohne sie vor und versuchen, ein typisches Problem zu lösen. Auf dem Weg werden wir die Probleme diskutieren, mit denen wir konfrontiert werden, und Möglichkeiten, sie zu lösen.

Einführung
In der Welt der Datenbanken gibt es zwei gängige Methoden zum Speichern von Informationen:
- Basierend auf logbasierten Strukturen.
- Basierend auf Seiten.
Der Vorteil der ersten Methode besteht darin, dass Sie Daten einfach und schnell lesen und speichern können. Neue Informationen können nur bis zum Ende der Datei geschrieben werden (sequentielle Aufzeichnung), was eine hohe Aufnahmegeschwindigkeit gewährleistet. Diese Methode wird von Basen wie Leveldb, Rocksdb, Cassandra verwendet.
Die zweite Methode (seitenbasiert) teilt die Daten in Blöcke fester Größe auf und speichert sie auf der Festplatte. Diese Teile werden "Seiten" oder "Blöcke" genannt. Sie enthalten Datensätze (Zeilen, Tupel) aus Tabellen.
Diese Methode der Datenspeicherung wird von MySQL, PostgreSQL, Oracle und anderen verwendet. Und da es sich um Indizes in MySQL handelt, werden wir diesen Ansatz berücksichtigen.
Datenspeicherung in MySQL
Daher werden alle Daten in MySQL als Seiten auf der Festplatte gespeichert. Die Seitengröße wird durch die Datenbankeinstellungen geregelt und beträgt standardmäßig 16 KB.
Jede Seite enthält 38 Byte Header und eine 8-Byte-Endung (wie in der Abbildung gezeigt). Der für die Datenspeicherung zugewiesene Speicherplatz ist nicht vollständig belegt, da MySQL auf jeder Seite für zukünftige Änderungen freien Speicherplatz lässt.
Im weiteren Verlauf der Berechnungen werden wir die Serviceinformationen vernachlässigen, vorausgesetzt, alle 16 KB der Seite sind mit unseren Daten gefüllt. Wir werden nicht weiter auf die Organisation von InnoDB-Seiten eingehen. Dies ist ein Thema für einen separaten Artikel. Mehr dazu lesen Sie hier .

Da wir uns oben darauf geeinigt haben, dass Indizes beispielsweise noch nicht existieren, erstellen wir eine einfache Tabelle ohne Indizes (MySQL erstellt zwar weiterhin einen Index, berücksichtigt diesen jedoch bei den Berechnungen nicht):
CREATE TABLE `product` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` CHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`category_id` INT NOT NULL,
`price` INT NOT NULL,
) ENGINE=InnoDB;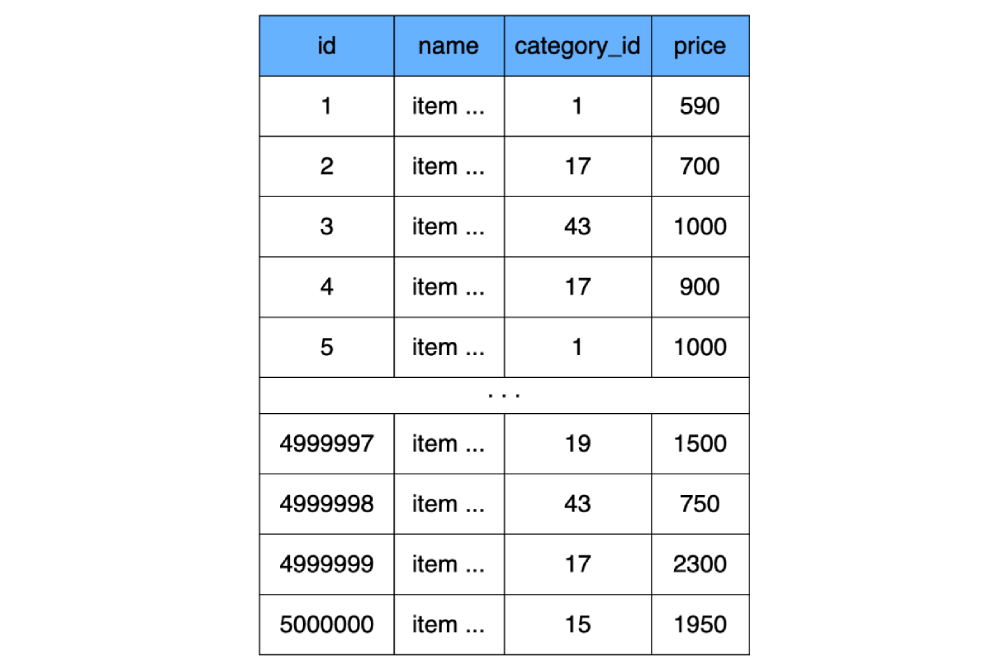
und führen Sie die folgende Anforderung aus:
SELECT * FROM product WHERE price = 1950;MySQL öffnet die Datei, in der die Daten aus der Tabelle gespeichert sind,
productund beginnt, alle Datensätze (Zeilen) auf der Suche nach den erforderlichen zu durchlaufen, wobei das Feld priceaus jeder gefundenen Zeile mit dem Wert in der Abfrage verglichen wird . Aus Gründen der Übersichtlichkeit erwäge ich speziell die Option mit einem vollständigen Scan der Datei, sodass die Fälle, in denen MySQL Daten aus dem Cache empfängt, für uns nicht geeignet sind.
Welche Probleme können wir damit haben?
Festplatte
Da wir alles auf einer Festplatte gespeichert haben, schauen wir uns das Gerät an. Die Festplatte liest und schreibt Daten in Sektoren (Blöcken). Die Größe eines solchen Sektors kann zwischen 512 Byte und 8 KB liegen (abhängig von der Festplatte). Mehrere aufeinanderfolgende Sektoren können zu Clustern zusammengefasst werden.
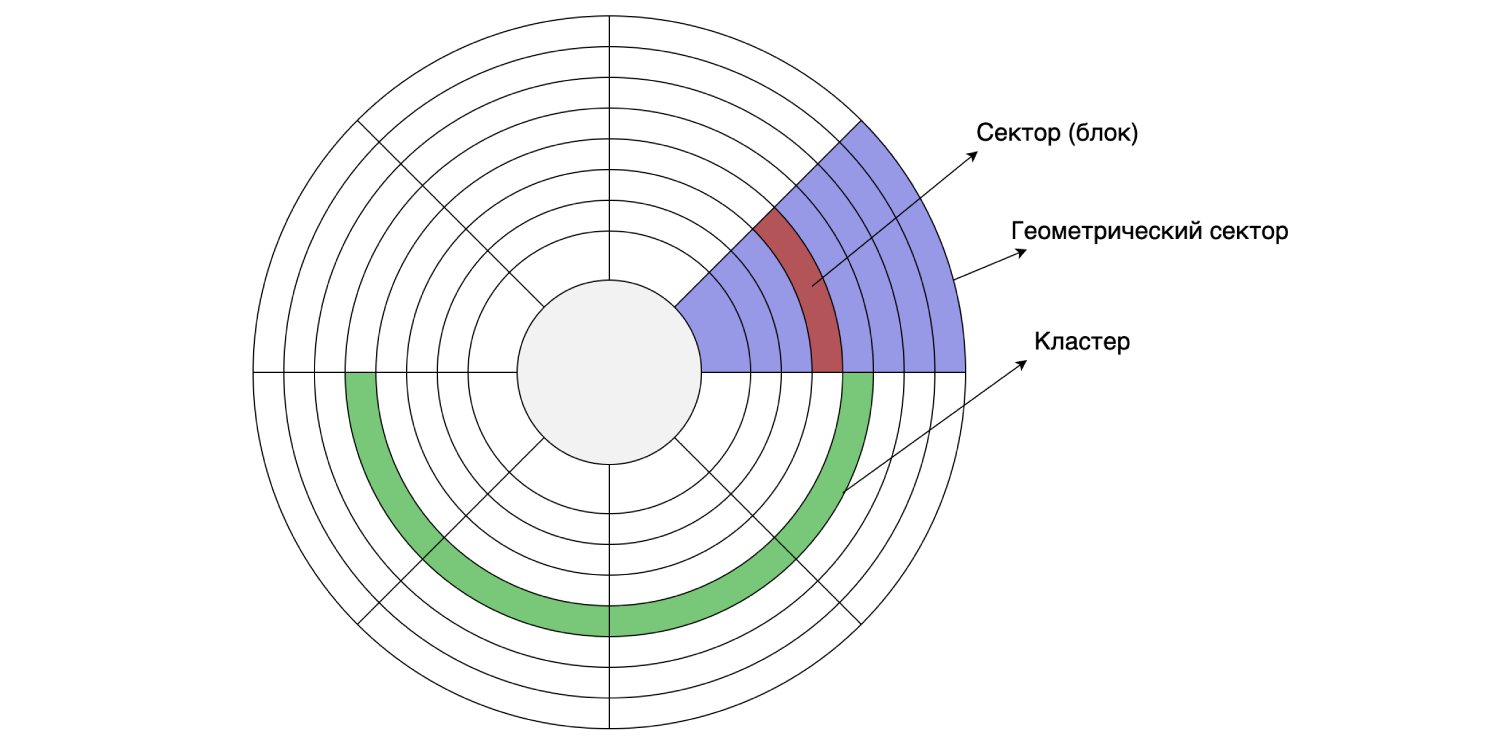
Die Clustergröße kann beim Formatieren / Partitionieren der Festplatte festgelegt werden, dh sie erfolgt programmgesteuert. Angenommen, die Sektorgröße auf der Festplatte beträgt 4 KB, und das Dateisystem ist mit einer Clustergröße von 16 KB partitioniert: Ein Cluster besteht aus vier Sektoren. Wie wir uns erinnern, speichert MySQL Daten standardmäßig auf 16 KB-Seiten auf der Festplatte, sodass eine Seite in einen Festplattencluster passt.
Berechnen wir, wie viel Platz unser Produktschild einnimmt, vorausgesetzt, es enthält 500.000 Artikel. Wir haben drei Vier-Byte - Felder
id, priceund category_id. Lassen Sie uns zustimmen, dass das Namensfeld für alle Datensätze bis zum Ende gefüllt ist (alle 100 Zeichen) und jedes Zeichen 3 Bytes benötigt. (3 * 4) + (100 * 3) = 312 Bytes - so viel wiegt eine Zeile unserer Tabelle, und multipliziert mit 500.000 Zeilen erhalten wir das Tabellengewicht von product156 Megabyte.
Zum Speichern dieses Etiketts sind daher 9750 Cluster auf der Festplatte erforderlich (9750 Seiten mit 16 KB).
Beim Speichern auf der Festplatte werden freie Cluster verwendet, was dazu führt, dass Cluster einer Platte (Datei) über die gesamte Festplatte "verschmiert" werden (dies wird als Fragmentierung bezeichnet). Das Lesen solcher Speicherblöcke, die sich zufällig auf der Festplatte befinden, wird als zufälliges Lesen bezeichnet. Dieser Messwert ist langsamer, da Sie den Festplattenkopf viele Male bewegen müssen. Um die gesamte Datei zu lesen, müssen wir über die gesamte Festplatte springen, um die erforderlichen Cluster zu erhalten.
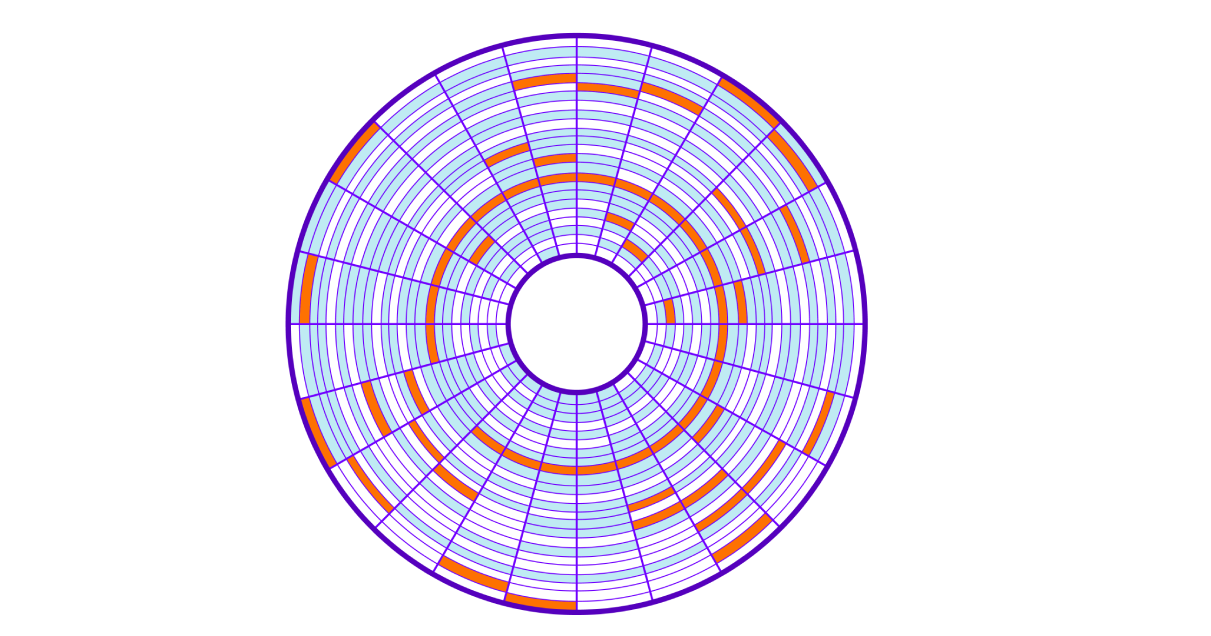
Kehren wir zu unserer SQL-Abfrage zurück. Um alle Zeilen zu finden, muss der Server alle 9750 Cluster lesen, die auf der Festplatte verteilt sind, und es wird viel Zeit in Anspruch nehmen, den Lesekopf der Festplatte zu bewegen. Je mehr Cluster wir unsere Daten verwenden, desto langsamer wird sie durchsucht. Außerdem verstopft unser Betrieb das E / A-System des Betriebssystems.
Letztendlich erhalten wir eine niedrige Lesegeschwindigkeit; Das Betriebssystem "anhalten" und das E / A-System verstopfen. und führen Sie viele Vergleiche durch, indem Sie die Abfragebedingungen für jede Zeile überprüfen.
Mein eigenes Fahrrad
Wie können wir dieses Problem alleine lösen?
Wir müssen herausfinden, wie wir die Tabellensuche verbessern können
product. Erstellen wir eine weitere Tabelle, in der nur das Feld priceund der Link zum Datensatz (Bereich auf der Festplatte) in unserer Tabelle gespeichert werden product. Nehmen wir in der Regel gleich an, dass beim Hinzufügen von Daten zu einer neuen Tabelle die Preise in sortierter Form gespeichert werden.
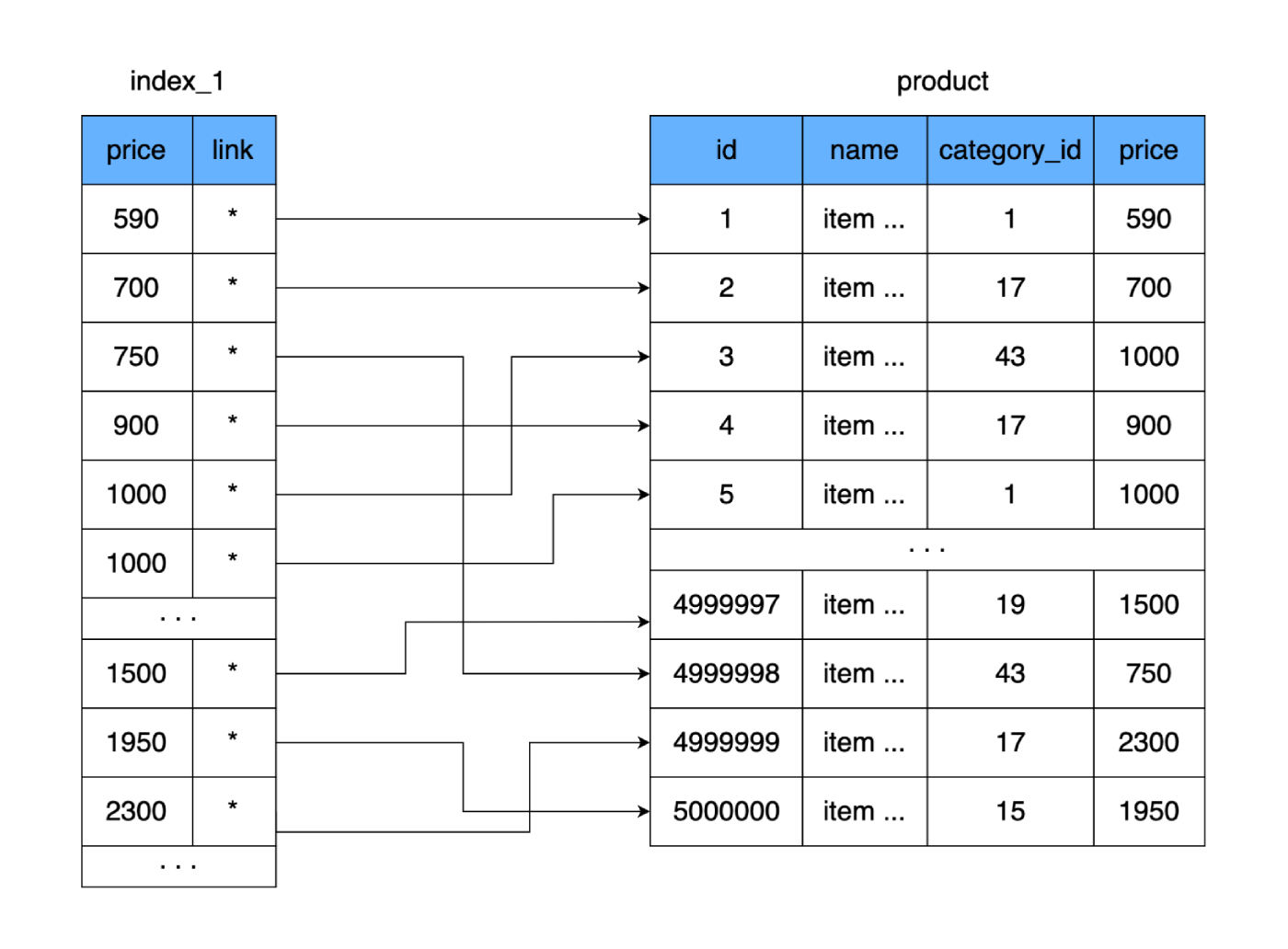
Was gibt es uns? Die neue Tabelle wird wie die Haupttabelle Seite für Seite (in Blöcken) auf der Festplatte gespeichert. Es enthält den Preis und einen Link zur Haupttabelle. Berechnen wir, wie viel Platz eine solche Tabelle einnimmt. Der Preis beträgt 4 Byte, und der Verweis auf die Haupttabelle (Adresse) beträgt ebenfalls 4 Byte. Für 500.000 Zeilen wiegt unsere neue Tabelle nur 4 MB. Auf diese Weise passen viel mehr Zeilen aus der neuen Tabelle auf eine Datenseite, und es werden weniger Seiten benötigt, um alle unsere Preise zu speichern.
Wenn für eine vollständige Tabelle 9750 Festplattencluster erforderlich sind (oder im schlimmsten Fall 9750 Festplattensprünge), passt die neue Tabelle nur für 250 Cluster. Aufgrund dessen wird die Anzahl der verwendeten Cluster auf der Festplatte stark reduziert und damit der Zeitaufwand für das zufällige Lesen. Selbst wenn wir unsere gesamte neue Tabelle lesen und die Werte vergleichen, um den richtigen Preis zu finden, werden im schlimmsten Fall 250 Sprünge über die Cluster der neuen Tabelle benötigt. Nachdem wir die erforderliche Adresse gefunden haben, lesen wir einen weiteren Cluster, in dem sich die vollständigen Daten befinden. Ergebnis: 251 Lesevorgänge gegenüber dem Original 9750. Der Unterschied ist signifikant.
Um nach einer solchen Tabelle zu suchen, können Sie beispielsweise beispielsweise den binären Suchalgorithmus verwenden (da die Liste sortiert ist). Dadurch sparen Sie noch mehr Lese- und Vergleichsvorgänge.
Nennen wir unsere zweite Tabelle einen Index.
Hurra! Wir haben unseren eigenen
Aber hören Sie auf: Wenn die Tabelle wächst, wird auch der Index immer größer, und schließlich kehren wir zum ursprünglichen Problem zurück. Die Suche wird wieder lange dauern.
Ein weiterer Index
Und wenn Sie einen weiteren Index über dem vorhandenen erstellen?
Nur dieses Mal werden wir nicht jeden Wert des Feldes aufschreiben
price, sondern einen Wert einer ganzen Seite (einem Block) aus dem Index zuordnen. Das heißt, es wird eine zusätzliche Indexebene angezeigt, die auf das Dataset des vorherigen Index verweist (die Seite auf der Festplatte, auf der die Daten des ersten Index gespeichert sind).
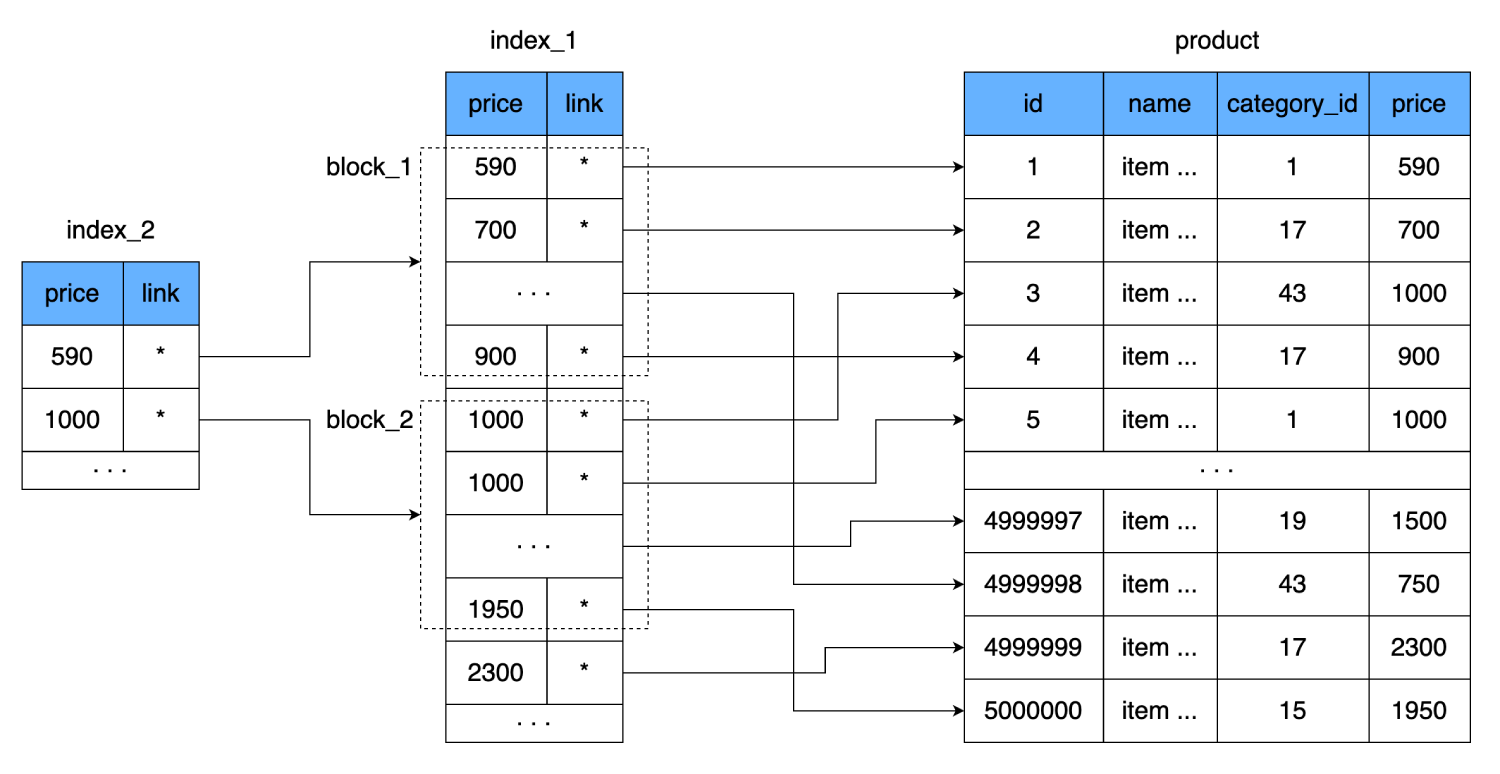
Dadurch wird die Anzahl der Messwerte weiter reduziert. Eine Zeile unseres Index benötigt 8 Bytes, dh wir können 2000 solcher Zeilen auf eine 16-Kilobyte-Seite passen. Der neue Index enthält einen Link zum Block mit 2000 Zeilen des ersten Index und dem Preis, ab dem dieser Block beginnt. Eine solche Zeile benötigt ebenfalls 8 Bytes, ihre Anzahl ist jedoch stark reduziert: statt 500.000 nur 250. Sie passen sogar in einen Festplattencluster. Um den erforderlichen Preis zu finden, können wir also genau bestimmen, in welchem Block von 2000 Zeilen er sich befindet. Und im schlimmsten Fall, um den gleichen Rekord zu finden, haben wir:
- Lassen Sie uns einen Lesevorgang aus dem neuen Index durchführen.
- Nachdem wir 250 Zeilen durchlaufen haben, finden wir aus dem zweiten Index einen Link zum Datenblock.
- Wir betrachten einen Cluster, der 2000 Zeilen mit Preisen und Links zur Haupttabelle enthält.
- Nachdem wir diese 2000 Zeilen überprüft haben, werden wir den erforderlichen ein und weiteren Zeitsprung über die Festplatte finden, um den letzten Datenblock zu lesen.
Wir werden insgesamt 3 Cluster-Sprünge bekommen.
Diese Ebene wird aber früher oder später auch mit vielen Daten gefüllt sein. Deshalb müssen wir alles wiederholen, was wir getan haben, und immer wieder ein neues Level hinzufügen. Das heißt, wir benötigen eine solche Datenstruktur zum Speichern des Index, die mit zunehmender Größe des Index neue Ebenen hinzufügt und die Daten unabhängig voneinander zwischen ihnen ausgleicht.
Wenn wir die Tabellen so umdrehen, dass der letzte Index oben und die Haupttabelle mit den Daten unten ist, erhalten wir eine Struktur, die einem Baum sehr ähnlich ist.
Die B-Tree-Datenstruktur funktioniert nach einem ähnlichen Prinzip, daher wurde sie für diese Zwecke ausgewählt.
B-Bäume in Kürze
Die in MySQL am häufigsten verwendeten Indizes sind B-Baum- Indizes (Balanced Search Tree) .
Die allgemeine Idee eines B-Baums ähnelt unseren Indextabellen. Die Werte werden der Reihe nach gespeichert und alle Blätter des Baumes befinden sich im gleichen Abstand von der Wurzel.
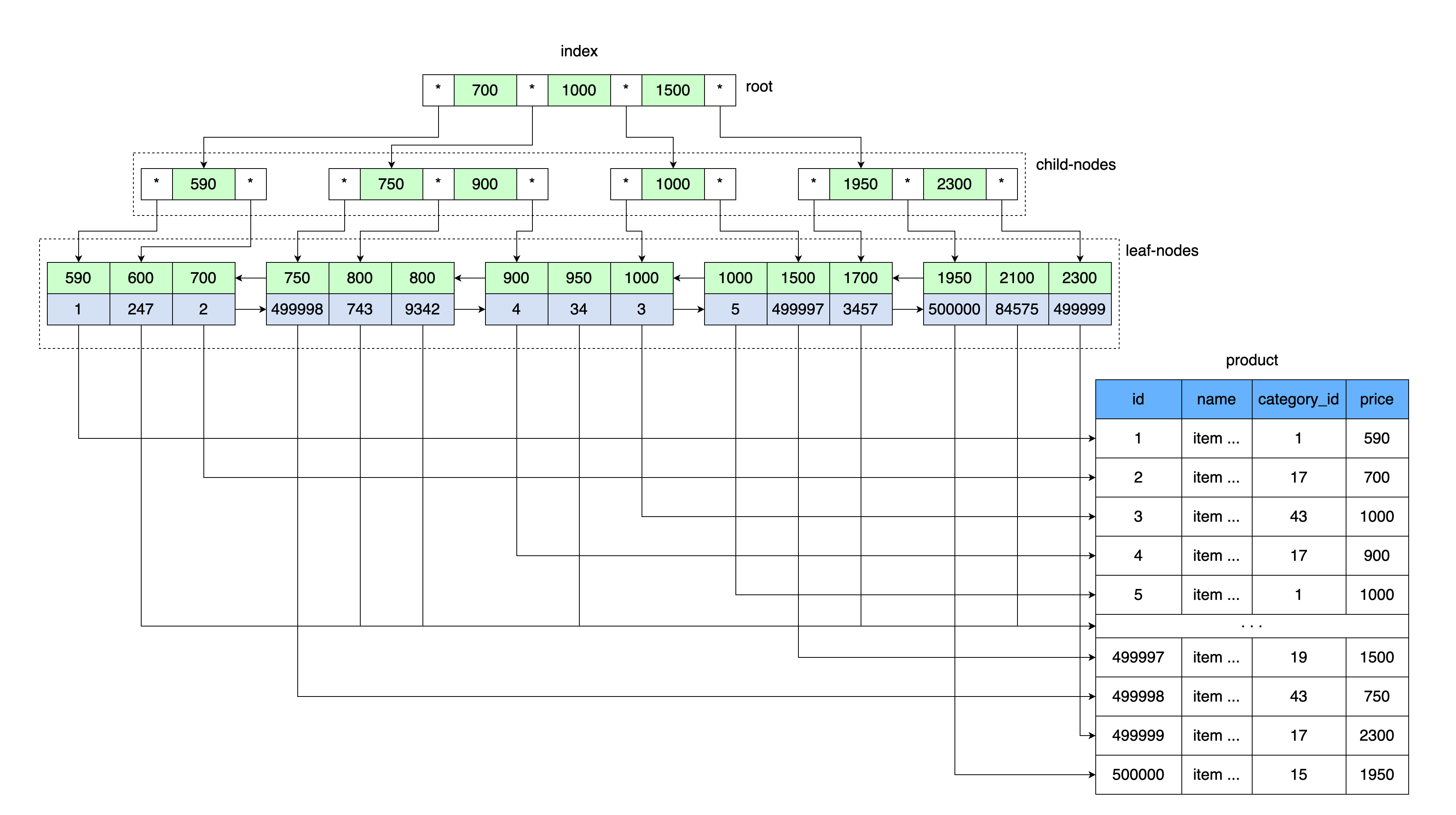
So wie unsere Tabelle mit einem Index einen Preiswert und eine Verknüpfung zu einem Datenblock gespeichert hat, der einen Wertebereich mit diesem Preis enthält, werden im Stammverzeichnis des B-Baums der Preiswert und eine Verknüpfung zu einem Speicherbereich auf der Festplatte gespeichert.
Zunächst wird die Seite gelesen, die die Wurzel des B-Baums enthält. Ferner gibt es nach Eingabe des Tastenbereichs einen Zeiger auf den gewünschten untergeordneten Knoten. Die Seite des untergeordneten Knotens wird gelesen, von wo aus der Link zum Datenblatt dem Schlüsselwert entnommen wird, und die Seite mit den Daten wird von diesem Link gelesen.
B-Baum in InnoDB
Insbesondere verwendet InnoDB eine B + -Baumdatenstruktur.
Jedes Mal, wenn Sie eine Tabelle erstellen, erstellen Sie automatisch einen B + -Baum, da MySQL einen solchen Index für den Primär- und Sekundärschlüssel speichert.
Sekundärschlüssel speichern zusätzlich die Werte des Primärschlüssels (Clusterschlüssels) als Referenz auf die Datenzeile. Folglich wächst der Sekundärschlüssel um die Größe des Primärschlüsselwerts.
Darüber hinaus verwenden B + -Bäume zusätzliche Verknüpfungen zwischen untergeordneten Knoten, wodurch die Suchgeschwindigkeit über einen Wertebereich erhöht wird. Lesen Sie mehr über die Struktur von b + Tree - Indizes in InnoDB hier .
Zusammenfassen
Ein B-Tree-Index bietet einen großen Vorteil bei der Suche nach Daten über einen Wertebereich, indem die Menge der von der Festplatte gelesenen Informationen drastisch reduziert wird. Er nimmt nicht nur an der Suche nach Bedingungen teil, sondern auch an Sortierungen, Verknüpfungen und Gruppierungen. Lesen Sie, wie MySQL Indizes verwendet hier .
Die meisten Abfragen an die Datenbank sind nur Abfragen, um Informationen nach Wert oder nach einem Wertebereich zu finden. Daher ist in MySQL der am häufigsten verwendete Index ein B-Tree-Index.
Der B-Tree-Index hilft auch beim Abrufen von Daten. Da der Primärschlüssel (Clustered-Index) und der Wert der Spalte, auf der der Nicht-Clustered-Index basiert (Sekundärschlüssel), in den Indexblättern gespeichert sind, können Sie nicht mehr auf die Haupttabelle für diese Daten zugreifen und sie aus dem Index entnehmen. Dies wird als Deckungsindex bezeichnet. Weitere Informationen zu gruppierten und nicht gruppierten Indizes finden Sie in diesem Artikel .
Indizes werden ebenso wie Tabellen auf der Festplatte gespeichert und belegen Speicherplatz. Jedes Mal, wenn Sie der Tabelle Informationen hinzufügen, muss der Index auf dem neuesten Stand gehalten werden, um die Richtigkeit aller Verknüpfungen zwischen Knoten zu überwachen. Dies verursacht einen Overhead beim Schreiben von Informationen, was der Hauptnachteil von B-Tree-Indizes ist. Wir opfern die Schreibgeschwindigkeit, um die Lesegeschwindigkeit zu erhöhen.
- MySQL . 3-
: ,
: 2018 - blog.jcole.us/innodb
- dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html