Lass uns in Ordnung gehen. Und sofort ein kleiner Haftungsausschluss: Der Artikel wurde basierend auf meiner Rede bei Ya Subbotnik Pro für Front-End-Entwickler geschrieben. Wenn Sie ein Backend-Entwickler sind, entdecken Sie möglicherweise nichts Neues für sich. Hier werde ich versuchen, meine Erfahrungen mit Frontend in einem großen Unternehmen zusammenzufassen und zu erklären, warum und wie wir Node.js verwenden.
Definieren wir, was wir in diesem Artikel als Frontend betrachten. Lassen Sie uns Streitigkeiten über Aufgaben beiseite legen und uns auf das Wesentliche konzentrieren.
Frontend ist der Teil der Anwendung, der für die Anzeige verantwortlich ist. Es kann anders sein: Browser, Desktop, Mobile. Aber es gibt immer ein wichtiges Merkmal - das Frontend benötigt Daten. Ohne ein Backend, das diese Daten bereitstellt, sind sie nutzlos. Hier ist eine ziemlich klare Grenze. Das Backend weiß, wie man zu Datenbanken geht, Geschäftsregeln auf die empfangenen Daten anwendet und das Ergebnis an das Frontend weitergibt, das die Daten empfängt, vorlegt und dem Benutzer Schönheit verleiht.
Wir können sagen, dass das Backend konzeptionell vom Frontend benötigt wird, um Daten zu empfangen und zu speichern. Beispiel: Eine typische moderne Site mit einer Client-Server-Architektur. Der Client im Browser (um es als dünn zu bezeichnen, die Sprache dreht sich nicht mehr) klopft auf dem Server, auf dem das Backend ausgeführt wird. Und natürlich gibt es überall Ausnahmen. Es gibt komplexe Browseranwendungen, die keinen Server benötigen (wir werden diesen Fall nicht berücksichtigen), und es muss ein Frontend auf dem Server ausgeführt werden - das sogenannte Server Side Rendering oder SSR. Beginnen wir damit, denn dies ist der einfachste und verständlichste Fall.
SSR
Die ideale Welt für das Backend sieht folgendermaßen aus: HTTP-Anforderungen mit Daten kommen am Eingang der Anwendung an, und am Ausgang erhalten wir eine Antwort mit neuen Daten in einem praktischen Format. Zum Beispiel JSON. HTTP-APIs sind einfach zu testen und zu verstehen, wie sie entwickelt werden. Das Leben nimmt jedoch Anpassungen vor: Manchmal reicht API allein nicht aus.
Der Server sollte mit vorgefertigtem HTML antworten, um es dem Suchmaschinen-Crawler zuzuführen, eine Vorschau mit Meta-Tags zum Einfügen in das soziale Netzwerk zu rendern oder, was noch wichtiger ist, die Reaktion auf schwachen Geräten zu beschleunigen. Genau wie in alten Zeiten, als wir Web 2.0 in PHP entwickelt haben.
Alles ist bekannt und wurde schon lange beschrieben, aber der Client hat sich geändert - zwingende clientseitige Template-Engines sind dazu gekommen. Im modernen Web regiert JSX den Ball, dessen Vor- und Nachteile lange diskutiert werden können, aber eines kann nicht geleugnet werden - beim Server-Rendering kann man nicht auf JavaScript-Code verzichten.
Es stellt sich heraus, wann Sie SSR durch Back-End-Entwicklung implementieren müssen:
- Verantwortungsbereiche sind gemischt. Backend-Programmierer beginnen, für das Rendern verantwortlich zu sein.
- Sprachen sind gemischt. Backend-Programmierer beginnen mit JavaScript.
Der Ausweg besteht darin, die SSR vom Backend zu trennen. Im einfachsten Fall nehmen wir eine JavaScript-Laufzeit, setzen eine selbstgeschriebene Lösung oder ein Framework (Next, Nuxt usw.) darauf, das mit der von uns benötigten JavaScript-Vorlagen-Engine funktioniert, und leiten den Datenverkehr durch diese. Ein bekanntes Muster in der modernen Welt.
Daher haben wir Front-End-Entwicklern bereits ein wenig Zugriff auf den Server gewährt. Kommen wir zu einem wichtigeren Thema.
Daten empfangen
Eine beliebte Lösung ist das Erstellen generischer APIs. Diese Rolle wird am häufigsten von API Gateway übernommen, das eine Vielzahl von Mikrodiensten abfragen kann. Aber auch hier treten Probleme auf.
Erstens das Problem der Teams und Verantwortungsbereiche. Eine moderne Großanwendung wird von vielen Teams entwickelt. Jedes Team konzentriert sich auf seine Geschäftsdomäne, verfügt über einen eigenen Microservice (oder sogar mehrere) im Backend und eigene Displays auf dem Client. Wir werden nicht auf das Problem der Mikrofronts und der Modularität eingehen, dies ist ein separates komplexes Thema. Angenommen, die Clientansichten sind vollständig getrennt und befinden sich als Mini-SPA (Single Page Application) innerhalb einer großen Site.
Jedes Team hat Front-End- und Back-End-Entwickler. Jeder arbeitet an seiner eigenen Anwendung. API Gateway kann ein Knackpunkt sein. Wer ist dafür verantwortlich? Wer fügt neue Endpunkte hinzu? Ein dediziertes API-Superteam, das immer damit beschäftigt ist, Probleme für alle anderen im Projekt zu lösen? Was kostet ein Fehler? Der Fall dieses Gateways wird das gesamte System herunterfahren.
Zweitens das Problem redundanter / unzureichender Daten. Schauen wir uns an, was passiert, wenn zwei verschiedene Frontends dieselbe generische API verwenden.

Diese beiden Frontends sind sehr unterschiedlich. Sie benötigen unterschiedliche Datensätze und unterschiedliche Release-Zyklen. Die Variabilität der Versionen des mobilen Frontends ist maximal, daher sind wir gezwungen, die API mit maximaler Abwärtskompatibilität zu entwerfen. Die Variabilität des Webclients ist gering. Tatsächlich müssen wir nur eine frühere Version unterstützen, um die Anzahl der Fehler zum Zeitpunkt der Veröffentlichung zu verringern. Aber selbst wenn die "generische" API nur Web-Clients bedient, besteht immer noch das Problem redundanter oder unzureichender Daten.
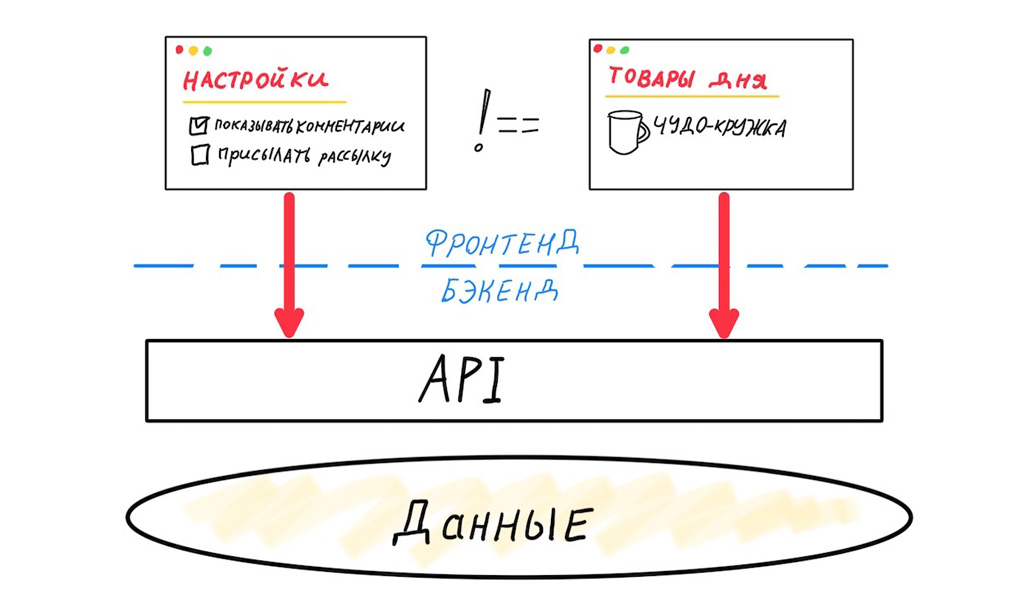
Für jede Zuordnung ist ein separater Datensatz erforderlich, der mit einer optimalen Abfrage abgerufen werden kann.
In diesem Fall funktioniert eine universelle API für uns nicht, wir müssen die Schnittstellen trennen. Dies bedeutet, dass Sie für jedes ein eigenes API-Gateway benötigenVorderes Ende. Das Wort "each" bezeichnet hier eine eindeutige Zuordnung, die mit einem eigenen Datensatz arbeitet.

Wir können die Erstellung einer solchen API einem Backend-Entwickler anvertrauen, der mit dem Frontend arbeiten und seine Wünsche umsetzen muss, oder, was viel interessanter und in vielerlei Hinsicht effektiver ist, die Implementierung der API dem Frontend-Team übertragen muss. Dadurch werden die Kopfschmerzen aufgrund der SSR-Implementierung beseitigt: Sie müssen keine Schicht mehr installieren, die auf der API klopft. Alles wird in eine Serveranwendung integriert. Durch die Steuerung des SSR können wir außerdem alle erforderlichen Primärdaten zum Zeitpunkt des Renderns auf der Seite ablegen, ohne zusätzliche Anforderungen an den Server zu stellen.
Diese Architektur wird als Backend For Frontend oder BFF bezeichnet. Die Idee ist einfach: Auf dem Server wird eine neue Anwendung angezeigt, die auf Clientanforderungen wartet, Backends abfragt und die optimale Antwort zurückgibt. Und natürlich wird diese Anwendung vom Front-End-Entwickler gesteuert.

Mehr als ein Server im Backend? Kein Problem!

Unabhängig davon, welche Backend-Entwicklung für Kommunikationsprotokolle bevorzugt wird, können wir auf bequeme Weise mit dem Webclient kommunizieren. REST, RPC, GraphQL - wir wählen uns.
Aber ist GraphQL nicht die Lösung für das Problem, Daten in einer einzigen Abfrage abzurufen? Vielleicht müssen Sie keine Zwischendienste umzäunen?
Leider ist eine effektive Arbeit mit GraphQL ohne eine enge Zusammenarbeit mit Backend-Entwicklern, die die Entwicklung effizienter Datenbankabfragen übernehmen, nicht möglich. Durch die Auswahl einer solchen Lösung verlieren wir erneut die Kontrolle über die Daten und kehren zu unserem Ausgangspunkt zurück.

Es ist natürlich möglich, aber nicht interessant (für ein Frontend).
Nun, lassen Sie uns BFF implementieren. Natürlich in Node.js. Warum? Wir benötigen eine einzige Sprache auf dem Client und dem Server, um die Erfahrung von Front-End-Entwicklern und JavaScript für die Arbeit mit Vorlagen wiederzuverwenden. Was ist mit anderen Laufzeitumgebungen?

GraalVM und andere exotische Lösungen sind der Leistung von V8 unterlegen und zu spezifisch. Deno ist immer noch ein Experiment und wird nicht in der Produktion verwendet.
Und einen Moment. Node.js ist eine überraschend gute Lösung für die Implementierung von API Gateway. Die Knotenarchitektur ermöglicht einen Single-Thread-JavaScript-Interpreter in Kombination mit libuv, einer asynchronen E / A-Bibliothek, die wiederum einen Thread-Pool verwendet.
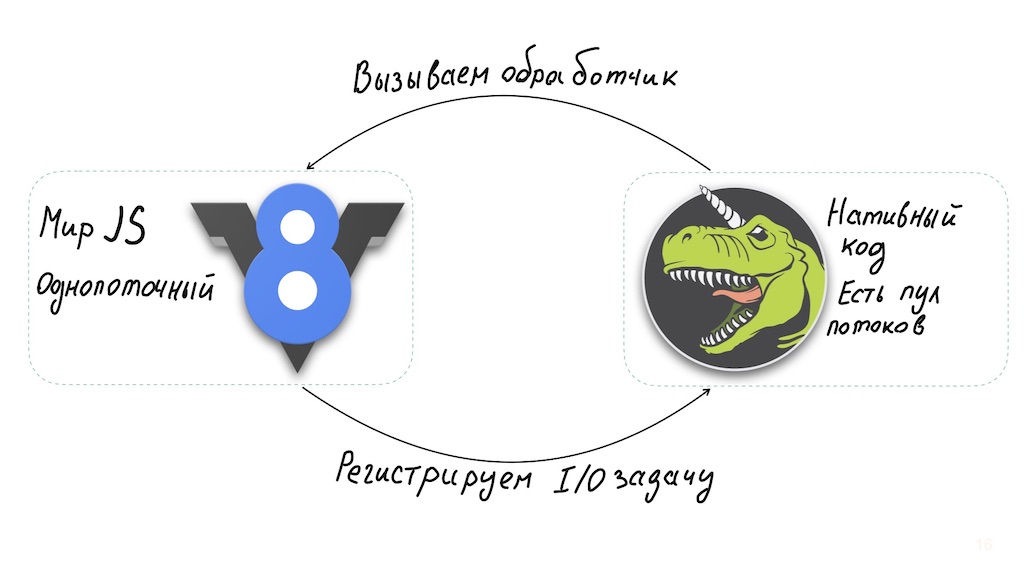
Lange Berechnungen auf der JavaScript-Seite beeinträchtigten die Systemleistung. Sie können dies umgehen: Führen Sie sie in separaten Workern aus oder bringen Sie sie auf die Ebene nativer Binärmodule.
Im Basisfall ist Node.js jedoch nicht für CPU-intensive Vorgänge geeignet und funktioniert gleichzeitig hervorragend mit asynchronen E / A-Vorgängen und bietet eine hohe Leistung. Das heißt, wir erhalten ein System, das unabhängig vom Benutzer immer schnell reagieren kannwie beschäftigt das Backend ist. Sie können mit dieser Situation umgehen, indem Sie den Benutzer sofort benachrichtigen, auf das Ende des Vorgangs zu warten.
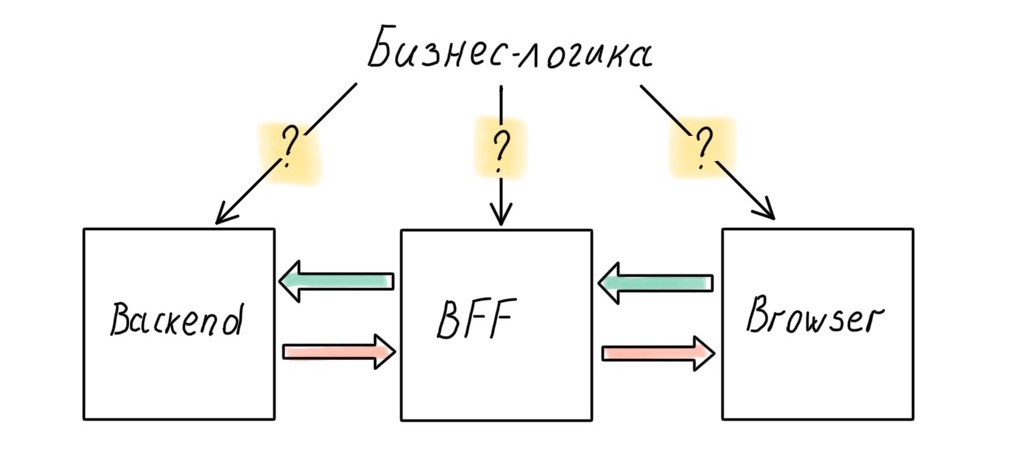
Speicherort der Geschäftslogik
Unser System besteht jetzt aus drei großen Teilen: Backend, Frontend und BFF dazwischen. Es stellt sich eine vernünftige Frage (für einen Architekten): Wo soll die Geschäftslogik aufbewahrt werden?

Natürlich möchte ein Architekt Geschäftsregeln nicht über alle Ebenen des Systems hinweg verschmieren, es sollte eine Quelle der Wahrheit geben. Und diese Quelle ist das Backend. Wo sonst können Richtlinien auf hoher Ebene gespeichert werden, wenn nicht in dem Teil des Systems, der den Daten am nächsten liegt?

In Wirklichkeit funktioniert dies jedoch nicht immer. Beispielsweise tritt ein Geschäftsproblem auf, das auf BFF-Ebene effizient und schnell umgesetzt werden kann. Perfektes Systemdesign ist großartig, aber Zeit ist Geld. Manchmal muss man die Sauberkeit der Architektur opfern und die Schichten beginnen zu lecken.
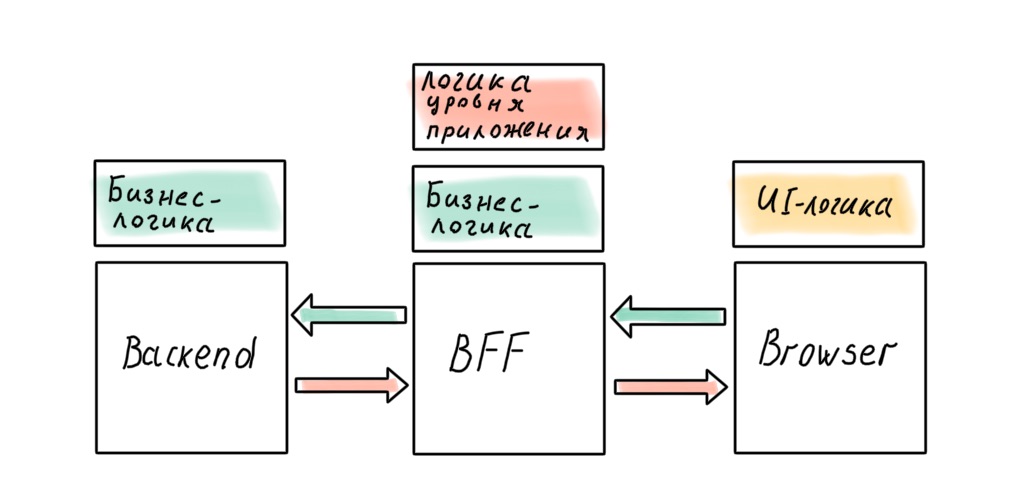
Können wir die perfekte Architektur erhalten, indem wir die BFF zugunsten eines "vollständigen" Node.js-Backends fallen lassen? Es scheint, dass in diesem Fall keine Lecks auftreten.
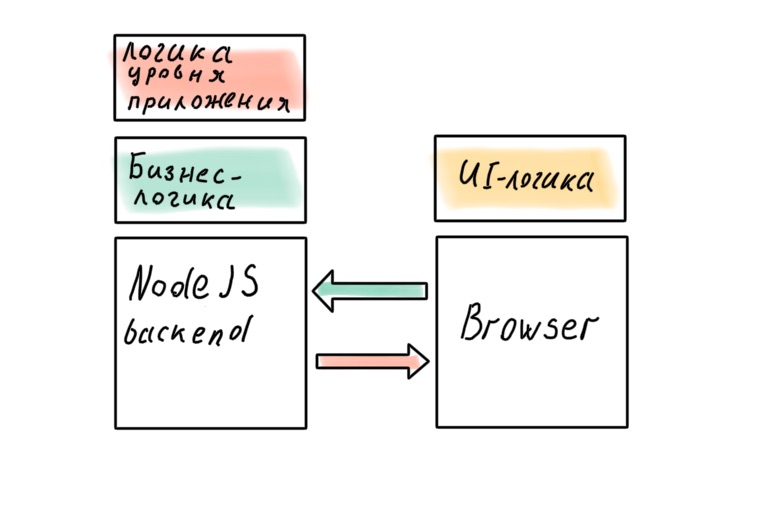
Ist keine Tatsache. Es wird Geschäftsregeln geben, deren Übertragung auf den Server die Reaktionsfähigkeit der Schnittstelle beeinflusst. Sie können dem bis zuletzt widerstehen, aber höchstwahrscheinlich werden Sie es nicht vollständig vermeiden können. Logik auf Anwendungsebene wird auch den Client durchdringen: In modernen SPA wird sie zwischen Client und Server verschmiert, selbst wenn eine BFF vorliegt.

Unabhängig davon, wie sehr wir uns bemühen, wird die Geschäftslogik das API-Gateway auf Node.js infiltrieren. Lassen Sie uns diese Schlussfolgerung korrigieren und zur köstlichsten Implementierung übergehen!
Großer Schlammball
Die beliebteste Lösung für Node.js-Anwendungen in den letzten Jahren ist Express. Bewährt, aber zu niedrig und bietet keine guten architektonischen Ansätze. Das Hauptmuster ist Middleware. Eine typische Anwendung im Express wie ein großer Schlammklumpen (er ist nicht namengebend und antipattern ).
const express = require('express');
const app = express();
const {createReadStream} = require('fs');
const path = require('path');
const Joi = require('joi');
app.use(express.json());
const schema = {id: Joi.number().required() };
app.get('/example/:id', (req, res) => {
const result = Joi.validate(req.params, schema);
if (result.error) {
res.status(400).send(result.error.toString()).end();
return;
}
const stream = createReadStream( path.join('..', path.sep, `example${req.params.id}.js`));
stream
.on('open', () => {stream.pipe(res)})
.on('error', (error) => {res.end(error.toString())})
});Alle Ebenen sind gemischt, in einer Datei befindet sich ein Controller, auf dem alles vorhanden ist: Infrastrukturlogik, Validierung, Geschäftslogik. Es ist schmerzhaft, damit zu arbeiten, Sie möchten solchen Code nicht pflegen. Können wir Code auf Unternehmensebene in Node.js schreiben?

Dies erfordert eine Codebasis, die einfach zu warten und zu entwickeln ist. Mit anderen Worten, Sie brauchen Architektur.
Node.js Anwendungsarchitektur (endlich)
"Das Ziel der Softwarearchitektur ist es, den menschlichen Aufwand für den Aufbau und die Wartung eines Systems zu reduzieren."
Robert "Onkel Bob" Martin
Architektur besteht aus zwei wichtigen Dingen: Schichten und den Verbindungen zwischen ihnen. Wir müssen unsere Anwendung in Ebenen aufteilen, Lecks von einer zur anderen verhindern, die Hierarchie der Ebenen und die Verbindungen zwischen ihnen richtig organisieren.
Schichten
Wie teile ich meine Anwendung in Ebenen auf? Es gibt einen klassischen dreistufigen Ansatz: Daten, Logik, Präsentation.
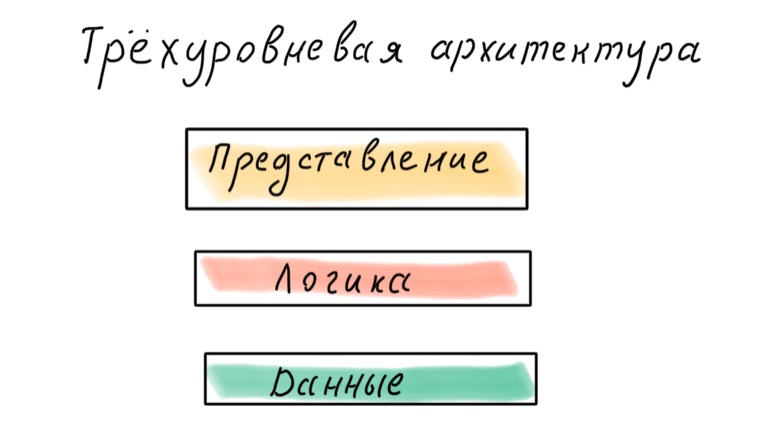
Dieser Ansatz gilt heute als veraltet. Das Problem ist, dass Daten die Basis sind. Dies bedeutet, dass die Anwendung abhängig von der Darstellung der Daten in der Datenbank und nicht von den Geschäftsprozessen, an denen sie beteiligt sind, entworfen wird.
Bei einem moderneren Ansatz wird davon ausgegangen, dass die Anwendung über eine dedizierte Domänenschicht verfügt, die mit Geschäftslogik arbeitet und reale Geschäftsprozesse im Code darstellt. Wenn wir uns jedoch der klassischen Arbeit von Eric Evans Domain-Driven Design zuwenden , finden wir dort das folgende Schema der Anwendungsschicht:

Was ist hier los? Es scheint, dass die Basis einer von DDD entworfenen Anwendung eine Domäne sein sollte - Richtlinien auf hoher Ebene, die wichtigste und wertvollste Logik. Unter dieser Schicht befindet sich jedoch die gesamte Infrastruktur: Datenzugriffsschicht (DAL), Protokollierung, Überwachung usw. Das heißt, Richtlinien von viel geringerer Ebene und von geringerer Bedeutung.
Die Infrastruktur steht im Mittelpunkt der Anwendung, und ein banaler Austausch des Loggers kann zu einer Erschütterung der gesamten Geschäftslogik führen.
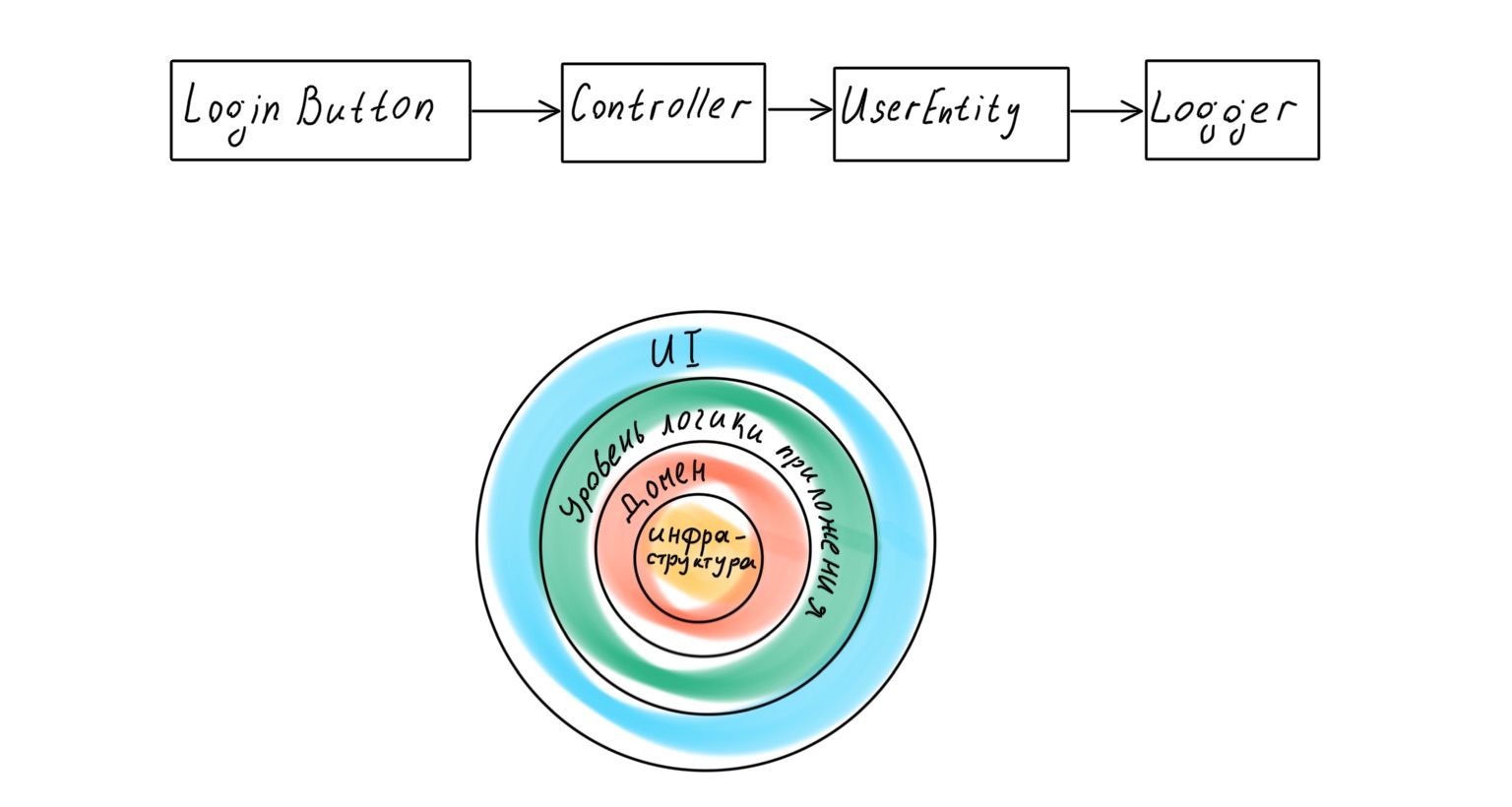
Wenn wir uns erneut an Robert Martin wenden, stellen wir fest, dass er in dem Buch Clean Architecture eine andere Ebenenhierarchie in der Anwendung postuliert, wobei die Domäne im Mittelpunkt steht.
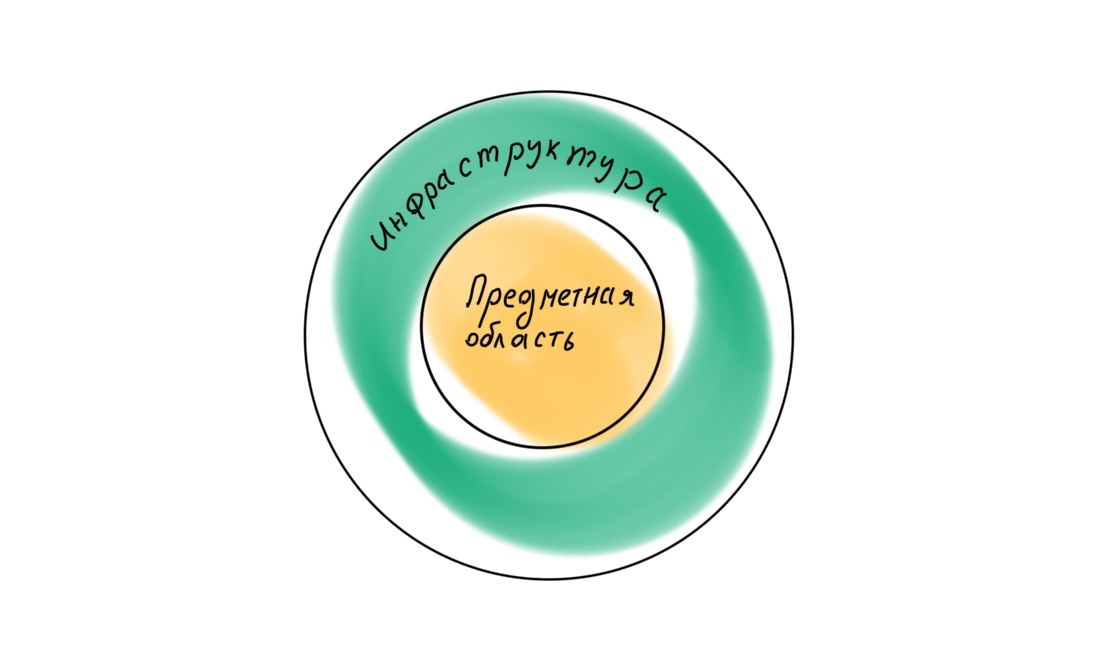
Dementsprechend sollten alle vier Ebenen unterschiedlich angeordnet sein:
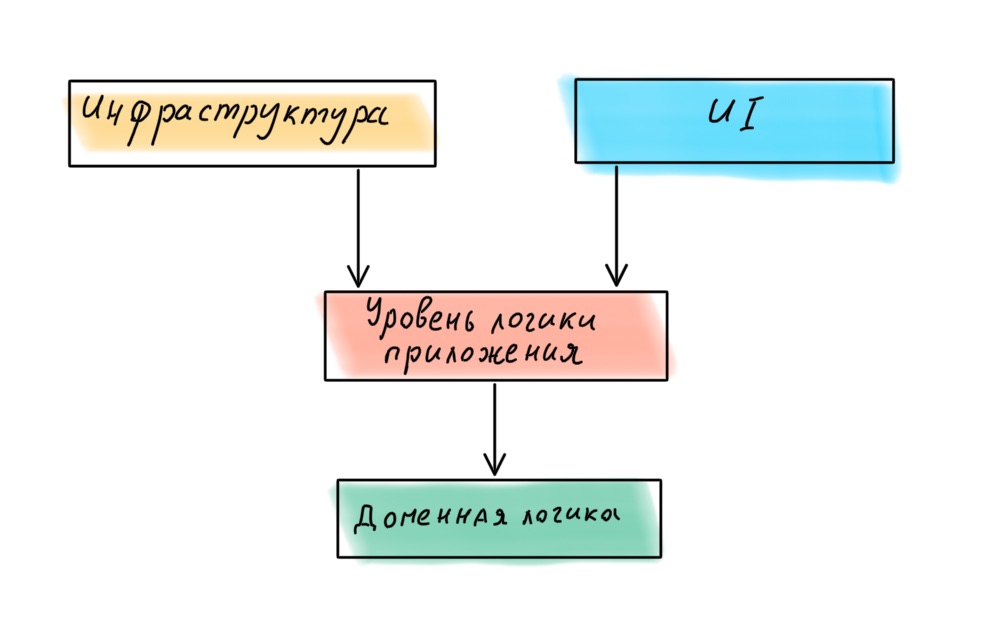
Wir haben die Ebenen ausgewählt und ihre Hierarchie definiert. Kommen wir nun zu den Verbindungen.
Verbindungen
Kehren wir zum Beispiel mit dem Benutzerlogikaufruf zurück. Wie kann die direkte Abhängigkeit von der Infrastruktur beseitigt werden, um die richtige Schichthierarchie sicherzustellen? Es gibt eine einfache und bekannte Möglichkeit, Abhängigkeiten umzukehren - Schnittstellen.

Jetzt hängt die High-Level-UserEntity nicht mehr vom Low-Level-Logger ab. Im Gegenteil, es schreibt den Vertrag vor, der implementiert werden muss, um den Logger in das System aufzunehmen. In diesem Fall muss der Logger ausgetauscht werden, um eine neue Implementierung zu verbinden, die denselben Vertrag einhält. Eine wichtige Frage ist, wie man es verbindet?
import {Logger} from ‘../core/logger’;
class UserEntity {
private _logger: Logger;
constructor() {
this._logger = new Logger();
}
...
}
...
const UserEntity = new UserEntity();Die Schichten sind starr miteinander verbunden. Es besteht ein Zusammenhang mit der Dateistruktur und -implementierung. Wir benötigen Dependency Inversion, was wir mit Dependency Injection tun werden.
export class UserEntity {
constructor(private _logger: ILogger) { }
...
}
...
const logger = new Logger();
const UserEntity = new UserEntity(logger);Jetzt weiß die "Domain" UserEntity nichts mehr über die Implementierung des Loggers. Es stellt einen Vertrag zur Verfügung und erwartet, dass die Implementierung diesem Vertrag entspricht.
Das manuelle Generieren von Instanzen von Infrastruktureinheiten ist natürlich nicht die angenehmste Sache. Wir brauchen eine Root-Datei, in der wir alles vorbereiten, wir müssen die erstellte Instanz des Loggers irgendwie durch die gesamte Anwendung ziehen (es ist vorteilhaft, eine zu haben, nicht viele). Ermüdend. Und hier kommen IoC-Container ins Spiel und können diese Bollerplate-Arbeit übernehmen.
Wie könnte die Verwendung eines Containers aussehen? Zum Beispiel so:
export class UserEntity {
constructor(@Inject(LOGGER) private readonly _logger: ILogger){ }
}Was ist hier los? Wir haben die Magie der Dekorateure verwendet und die Anweisung geschrieben: „Wenn Sie eine Instanz von UserEntity erstellen, fügen Sie in das private Feld _logger eine Instanz der Entität ein, die sich im IoC-Container unter dem LOGGER-Token befindet. Es wird erwartet, dass es der ILogger-Schnittstelle entspricht. " Und dann erledigt der IoC-Container alles selbst.
Wir haben die Ebenen ausgewählt und entschieden, wie wir sie lösen möchten. Es ist Zeit, ein Framework zu wählen.
Frameworks und Architektur
Die Frage ist einfach: Wenn wir Express für ein modernes Framework verlassen, erhalten wir eine gute Architektur? Werfen wir einen Blick auf Nest:
- geschrieben in TypeScript,
- Aufbauend auf Express / Fastify besteht Kompatibilität auf Middleware-Ebene.
- erklärt die Modularität der Logik,
- stellt einen IoC-Container bereit.
Es scheint alles zu haben, was wir hier brauchen! Sie haben auch das Konzept einer Anwendung als Middleware-Kette verlassen. Aber was ist mit guter Architektur?
Abhängigkeitsinjektion im Nest
Versuchen wir, den Anweisungen zu folgen . Da in Nest der Begriff Entität normalerweise auf ORM angewendet wird, benennen Sie UserEntity in UserService um. Der Logger wird vom Framework bereitgestellt, daher wird stattdessen der abstrakte FooService eingefügt.
import {FooService} from ‘../services/foo.service’;
@Injectable()
export class UserService {
constructor(
private readonly _fooService: FooService
){ }
}Und ... anscheinend sind wir einen Schritt zurückgetreten! Es gibt eine Injektion, aber keine Inversion, die Abhängigkeit
zielt auf die Implementierung ab, nicht auf die Abstraktion.
Versuchen wir es zu beheben. Option Nummer eins:
@Injectable()
export class UserService {
constructor(
private _fooService: AbstractFooService
){ } }Wir beschreiben und exportieren diesen abstrakten Service irgendwo in der Nähe:
export {AbstractFooService};FooService verwendet jetzt AbstractFooService. Als solches registrieren wir es manuell im IoC.
{ provide: AbstractFooService, useClass: FooService }Zweite Option. Versuchen wir den zuvor beschriebenen Ansatz mit Schnittstellen. Da es in JavaScript keine Schnittstellen gibt, ist es nicht mehr möglich, die erforderliche Entität zur Laufzeit mithilfe von Reflection aus IoC zu ziehen. Wir müssen explizit angeben, was wir brauchen. Wir werden dafür den @ Inject-Dekorator verwenden.
@Injectable()
export class UserService {
constructor(
@Inject(FOO_SERVICE) private readonly _fooService: IFooService
){ } }Und registrieren Sie sich per Token:
{ provide: FOO_SERVICE, useClass: FooService }Wir haben den Rahmen gewonnen! Aber zu welchen Kosten? Wir haben ziemlich viel Zucker ausgeschaltet. Dies ist verdächtig und legt nahe, dass Sie nicht die gesamte Anwendung in einem Framework bündeln sollten. Wenn ich Sie noch nicht überzeugt habe, gibt es andere Probleme.
Ausnahmen
Nest wird mit Ausnahmen geflasht. Darüber hinaus schlägt er vor, das Auslösen von Ausnahmen zu verwenden, um die Logik des Anwendungsverhaltens zu beschreiben.
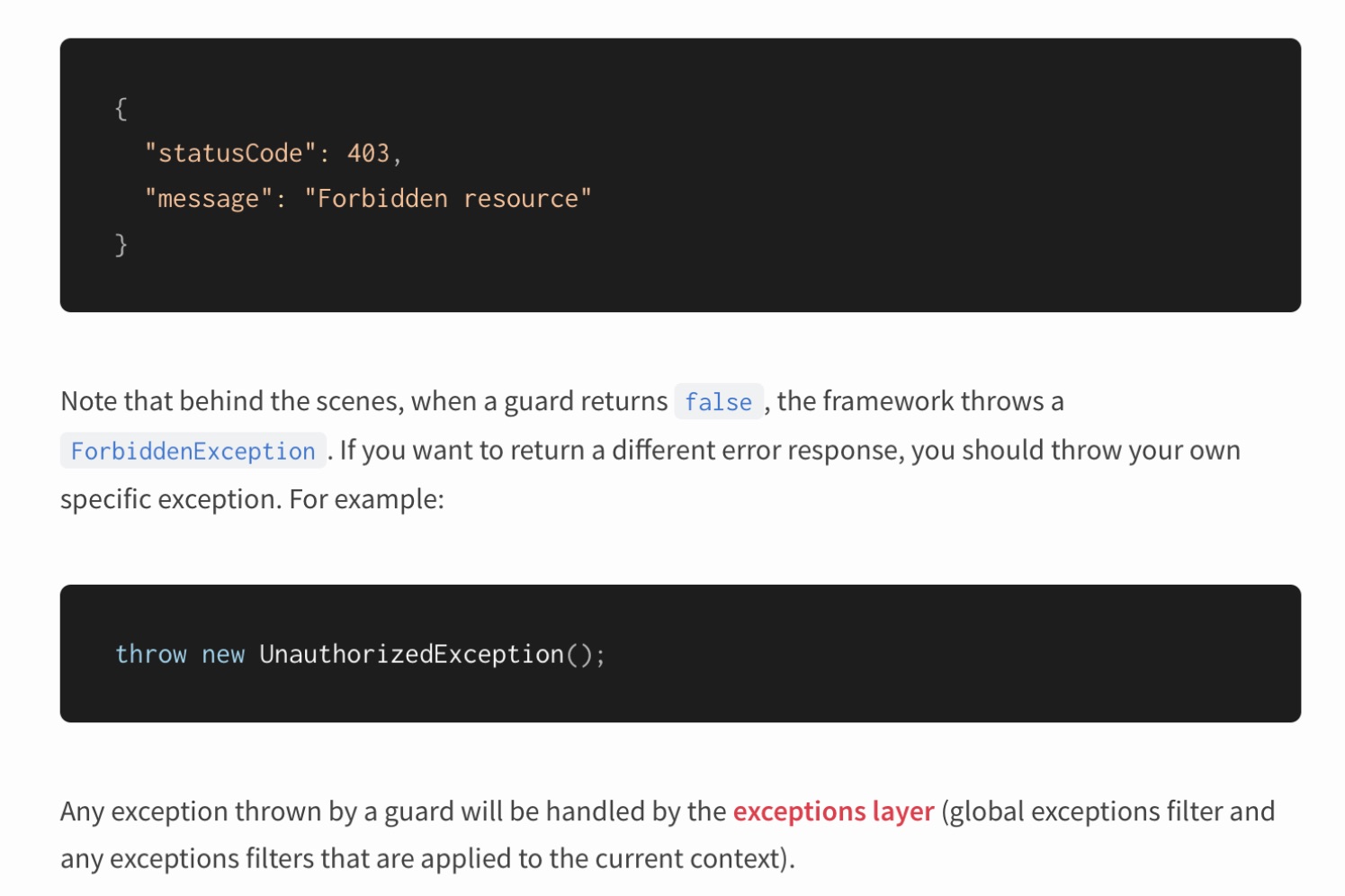
Ist hier architektonisch alles in Ordnung? Wenden wir uns noch einmal den Leuchten zu:
"Wenn der Fehler das erwartete Verhalten ist, sollten Sie keine Ausnahmen verwenden."Ausnahmen deuten auf eine Ausnahmesituation hin. Beim Schreiben von Geschäftslogik müssen wir vermeiden, Ausnahmen auszulösen. Schon aus dem Grund, dass weder JavaScript noch TypeScript garantieren, dass die Ausnahme behandelt wird. Darüber hinaus verschleiert es den Ausführungsfluss. Wir beginnen mit der Programmierung im GOTO-Stil, was bedeutet, dass der Leser bei der Untersuchung des Verhaltens des Codes durch das gesamte Programm springen muss.
Martin Fowler

Es gibt eine einfache Faustregel, die Ihnen hilft zu verstehen, ob die Verwendung von Ausnahmen legal ist:
"Funktioniert der Code, wenn ich alle Ausnahmebehandlungsroutinen entferne?" Wenn die Antwort Nein lautet, werden möglicherweise Ausnahmen unter nicht außergewöhnlichen Umständen verwendet. "Ist es möglich, dies in der Geschäftslogik zu vermeiden? Ja! Es ist notwendig, das Auslösen von Ausnahmen zu minimieren und das Ergebnis komplexer Operationen bequem zurückzugeben. Verwenden Sie entweder die Monade Entweder , die einen Container in einem Erfolgs- oder Fehlerzustand bereitstellt (ein Konzept, das Promise sehr nahe kommt).
Der pragmatische Programmierer
const successResult = Result.ok(false);
const failResult = Result.fail(new ConnectionError())Leider können wir innerhalb der von Nest bereitgestellten Entitäten oft nicht anders handeln - wir müssen Ausnahmen werfen. So funktioniert das Framework, und dies ist eine sehr unangenehme Funktion. Und wieder stellt sich die Frage: Vielleicht sollten Sie die Anwendung nicht mit einem Framework flashen? Vielleicht ist es möglich, das Framework und die Geschäftslogik in verschiedene Architekturebenen zu unterteilen?
Lass uns das Prüfen.
Nestentitäten und architektonische Schichten
Die harte Wahrheit des Lebens: Alles, was wir mit Nest schreiben, kann in einer Schicht gestapelt werden. Dies ist die Anwendungsschicht.
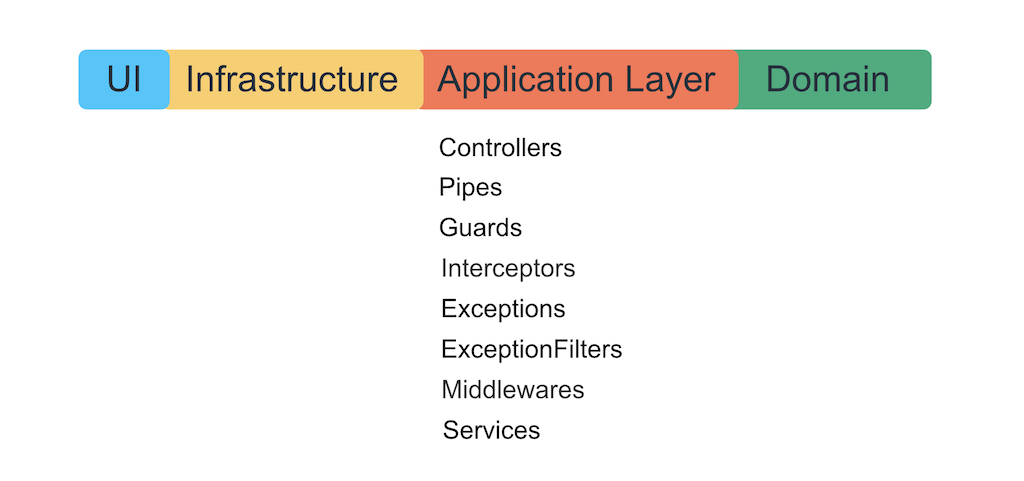
Wir möchten nicht, dass das Framework tiefer in die Geschäftslogik eintaucht, damit es mit seinen Ausnahmen, Dekorateuren und IoC-Containern nicht hineinwächst. Die Autoren des Frameworks werden herausfinden, wie großartig es ist, Geschäftslogik mit ihrem Zucker zu schreiben, aber ihre Aufgabe ist es, Sie für immer an sich selbst zu binden. Denken Sie daran, dass ein Framework nur eine Möglichkeit ist, Logik auf Anwendungsebene bequem zu organisieren, die Infrastruktur und die Benutzeroberfläche damit zu verbinden.

"Ein Framework ist ein Detail."
Robert "Onkel Bob" Martin
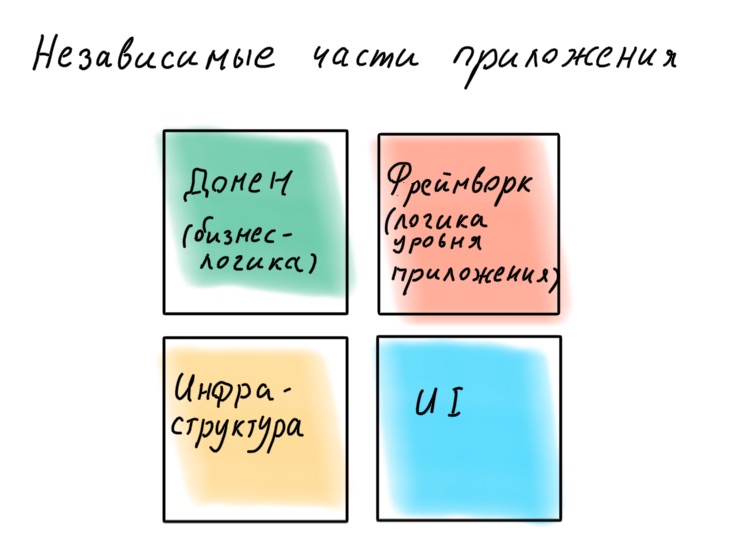
Es ist besser, eine Anwendung als Konstruktor zu entwerfen, in dem es einfach ist, Komponenten auszutauschen. Ein Beispiel für eine solche Implementierung ist die hexagonale Architektur ( Port- und Adapterarchitektur ). Die Idee ist interessant: Der Domänenkern mit der gesamten Geschäftslogik bietet Ports für die Kommunikation mit der Außenwelt. Alles, was benötigt wird, wird extern über Adapter angeschlossen.
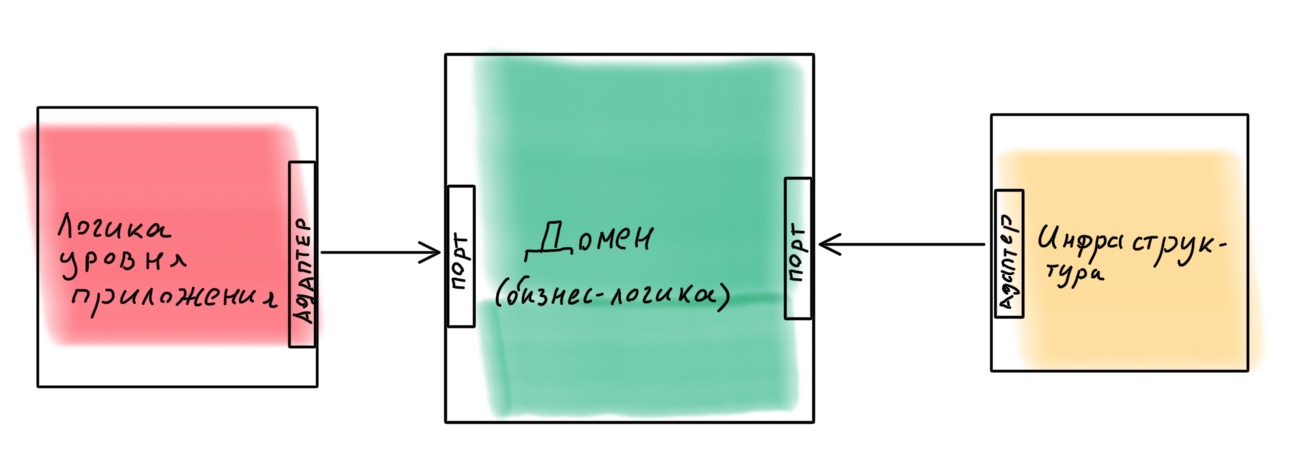
Ist es realistisch, eine solche Architektur in Node.js mit Nest als Framework zu implementieren? Ziemlich. Ich habe eine Lektion mit einem Beispiel gemacht, wenn Sie interessiert sind - Sie können es hier finden .
Fassen wir zusammen
- Node.js ist gut für BFFs. Du kannst mit ihr leben.
- Es gibt keine vorgefertigten Lösungen.
- Frameworks sind nicht wichtig.
- Wenn Ihre Architektur zu komplex wird und Sie auf die Eingabe stoßen, haben Sie möglicherweise das falsche Werkzeug ausgewählt.
Ich empfehle diese Bücher:
- Robert Martin, "Saubere Architektur",
- Vaughn Vernon, Domain-Driven Design Distilled,
- Khalil Stemmler, khalilstemmler.com,
- Martin Fowler, martinfowler.com/architecture.