In unserem Unternehmen arbeiten wir aktiv an der automatischen Abstraktion von Dokumenten. Dieser Artikel enthielt nicht alle Details und den Code, sondern beschrieb die wichtigsten Ansätze und Ergebnisse am Beispiel eines neutralen Datensatzes: 30.000 Fußball-Sportnachrichten, die über das Sport-Express-Informationsportal gesammelt wurden.
Zusammenfassung kann also als die automatische Erstellung einer Zusammenfassung (Titel, Zusammenfassung, Anmerkung) des Originaltextes definiert werden. Es gibt zwei signifikant unterschiedliche Ansätze für dieses Problem: extraktiv und abstrakt.
Extraktive Zusammenfassung
Der extraktive Ansatz besteht darin, die "wichtigsten" Informationsblöcke aus dem Quelltext zu extrahieren. Ein Block kann aus einzelnen Absätzen, Sätzen oder Schlüsselwörtern bestehen.

Die Methoden dieses Ansatzes sind durch das Vorhandensein einer Bewertungsfunktion für die Bedeutung des Informationsblocks gekennzeichnet. Indem wir diese Blöcke in der Reihenfolge ihrer Wichtigkeit einordnen und eine zuvor festgelegte Anzahl von ihnen auswählen, bilden wir die endgültige Zusammenfassung des Textes.
Kommen wir zur Beschreibung einiger extraktiver Ansätze.
Extraktive Summierung basierend auf dem Auftreten gebräuchlicher Wörter
Dieser Algorithmus ist sehr einfach zu verstehen und weiter zu implementieren. Hier arbeiten wir nur mit Quellcode, und im Großen und Ganzen müssen wir kein Extraktionsmodell trainieren. In meinem Fall repräsentieren die abgerufenen Informationsblöcke bestimmte Textsätze.
Im ersten Schritt zerlegen wir den Eingabetext in Sätze und teilen jeden Satz in Token (separate Wörter) auf, führen eine Lemmatisierung für sie durch (bringen das Wort in die "kanonische" Form). Dieser Schritt ist erforderlich, damit der Algorithmus Wörter kombiniert, deren Bedeutung identisch ist, deren Wortform sich jedoch unterscheidet.
Dann setzen wir die Ähnlichkeitsfunktion für jedes Satzpaar. Sie wird als Verhältnis der Anzahl der in beiden Sätzen vorkommenden gemeinsamen Wörter zu ihrer Gesamtlänge berechnet... Als Ergebnis erhalten wir die Ähnlichkeitskoeffizienten für jedes Satzpaar.
Nachdem wir zuvor Sätze eliminiert haben, die keine gemeinsamen Wörter mit anderen haben, erstellen wir ein Diagramm, in dem die Eckpunkte die Sätze selbst sind, deren Kanten das Vorhandensein gemeinsamer Wörter in ihnen anzeigen.
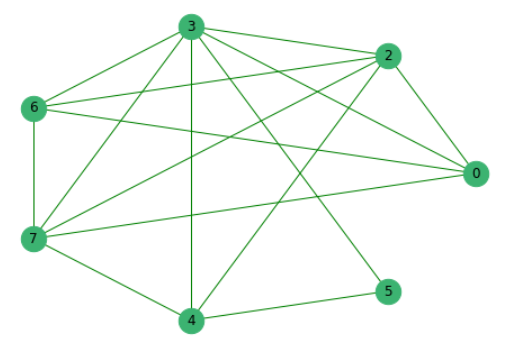
Als nächstes ordnen wir alle Vorschläge nach ihrer Wichtigkeit.

Wenn Sie mehrere Sätze mit den höchsten Koeffizienten auswählen und sie dann nach der Anzahl ihrer Vorkommen im Text sortieren, erhalten Sie die endgültige Zusammenfassung.
Extraktive Summierung basierend auf trainierten Vektordarstellungen
Zuvor gesammelte Volltextnachrichtendaten wurden verwendet, um den nächsten Algorithmus zu erstellen.
Wir teilen die Wörter in allen Texten in Token auf und kombinieren sie zu einer Liste. Insgesamt enthielten die Texte 2.270.778 Wörter, von denen 114.247 einzigartig waren.
Unter Verwendung des beliebten Word2Vec-Modells finden wir die Vektordarstellung für jedes einzelne Wort. Das Modell weist jedem Wort zufällige Vektoren zu und korrigiert dann bei jedem Lernschritt „Studieren des Kontexts“ ihre Werte. Die Dimension des Vektors, der sich an das Merkmal des Wortes "erinnern" kann, können Sie beliebig einstellen. Basierend auf dem Volumen des verfügbaren Datensatzes nehmen wir Vektoren, die aus 100 Zahlen bestehen. Ich stelle auch fest, dass Word2Vec ein retrainierbares Modell ist, mit dem Sie neue Daten an die Eingabe senden und auf ihrer Grundlage die vorhandenen Vektordarstellungen von Wörtern korrigieren können.
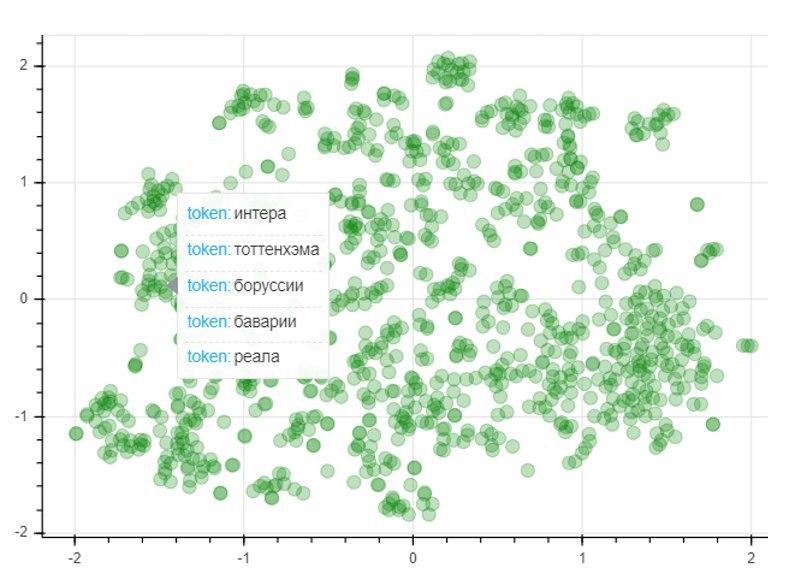
Um die Qualität des Modells zu beurteilen, verwenden wir die T-SNE-Methode zur Reduzierung der Dimensionalität, mit der iterativ eine Vektorabbildung für 1000 am häufigsten verwendete Wörter in einem zweidimensionalen Raum erstellt wird. Das resultierende Diagramm stellt die Position von Punkten dar, von denen jeder einem bestimmten Wort so entspricht, dass Wörter mit ähnlicher Bedeutung nahe beieinander liegen und im Gegenteil unterschiedliche. Auf der linken Seite des Diagramms befinden sich die Namen der Fußballvereine, und die Punkte in der unteren linken Ecke stehen für die Vor- und Nachnamen der Fußballspieler und -trainer:
Nachdem Sie die trainierten Vektordarstellungen von Wörtern erhalten haben, können Sie mit dem Algorithmus selbst fortfahren. Wie im vorherigen Fall haben wir bei der Eingabe einen Text, den wir in Sätze aufteilen. Durch Tokenisieren jedes Satzes erstellen wir Vektordarstellungen für sie. Dazu nehmen wir das Verhältnis der Summe der Vektoren für jedes Wort im Satz zur Länge des Satzes. Zuvor trainierte Wortvektoren helfen uns hier. Wenn das Wörterbuch kein Wort enthält, wird dem aktuellen Satzvektor ein Nullvektor hinzugefügt. Somit neutralisieren wir den Einfluss des Auftretens eines neuen Wortes, das nicht im Wörterbuch enthalten ist, auf den allgemeinen Vektor des Satzes.
Als nächstes erstellen wir eine Satzähnlichkeitsmatrix, die die Kosinusähnlichkeitsformel für jedes Satzpaar verwendet.
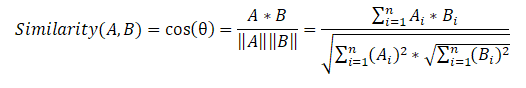
In der letzten Phase erstellen wir basierend auf der Ähnlichkeitsmatrix auch ein Diagramm und führen eine Rangfolge der Sätze nach Wichtigkeit durch. Wie im vorherigen Algorithmus erhalten wir eine Liste der sortierten Sätze nach ihrer Bedeutung im Text.

Am Ende werde ich die Hauptstufen der Algorithmusimplementierung schematisch darstellen und noch einmal beschreiben (für den ersten extraktiven Algorithmus ist die Reihenfolge der Aktionen genau dieselbe, außer dass wir keine Vektordarstellungen von Wörtern finden müssen und die Ähnlichkeitsfunktion für jedes Satzpaar basierend auf dem Erscheinungsbild von common berechnet wird Wörter):

- Teilen Sie den Eingabetext in separate Sätze auf und verarbeiten Sie diese.
- Suchen Sie nach einer Vektordarstellung für jeden Satz.
- Berechnen und Speichern der Ähnlichkeit zwischen Satzvektoren in einer Matrix.
- Transformation der resultierenden Matrix in ein Diagramm mit Sätzen in Form von Eckpunkten und Ähnlichkeitsschätzungen in Form von Kanten zur Berechnung des Satzrangs.
- Auswahl der Vorschläge mit der höchsten Punktzahl für den endgültigen Lebenslauf.
Vergleich von extraktiven Algorithmen
Unter Verwendung des Flask-Mikroframeworks (ein Tool zum Erstellen minimalistischer Webanwendungen ) wurde ein Testwebdienst entwickelt, um die Ausgabe von Extraktionsmodellen am Beispiel einer Vielzahl von Quellnachrichtentexten visuell zu vergleichen. Ich analysierte die von beiden Modellen generierte Zusammenfassung (extrahierte die 2 wichtigsten Sätze) für 100 verschiedene Sportnachrichtenartikel.

Basierend auf den Ergebnissen des Vergleichs der Ergebnisse der Ermittlung der relevantesten Angebote beider Modelle kann ich die folgenden Empfehlungen für die Verwendung der Algorithmen geben:
- . , . , .
- . , , , . , , , .
Abstrakte Zusammenfassung
Der abstrakte Ansatz unterscheidet sich erheblich von seinem Vorgänger und besteht darin, eine Zusammenfassung mit der Erstellung eines neuen Textes zu erstellen, wodurch das primäre Dokument sinnvoll zusammengefasst wird.
Die Hauptidee dieses Ansatzes besteht darin, dass das Modell eine vollständig eindeutige Zusammenfassung erstellen kann, die möglicherweise Wörter enthält, die nicht im Originaltext enthalten sind. Modellinferenz ist eine Nacherzählung des Textes, die näher an der manuellen Zusammenstellung einer Zusammenfassung des Textes durch Personen liegt.
Lernphase
Ich werde nicht auf die mathematische Rechtfertigung des Algorithmus eingehen, alle mir bekannten Modelle basieren auf der "Encoder-Decoder" -Architektur, die wiederum aus wiederkehrenden LSTM-Schichten aufgebaut ist (das Prinzip ihrer Arbeit finden Sie hier ). Ich werde kurz die Schritte zum Decodieren der Testsequenz beschreiben.
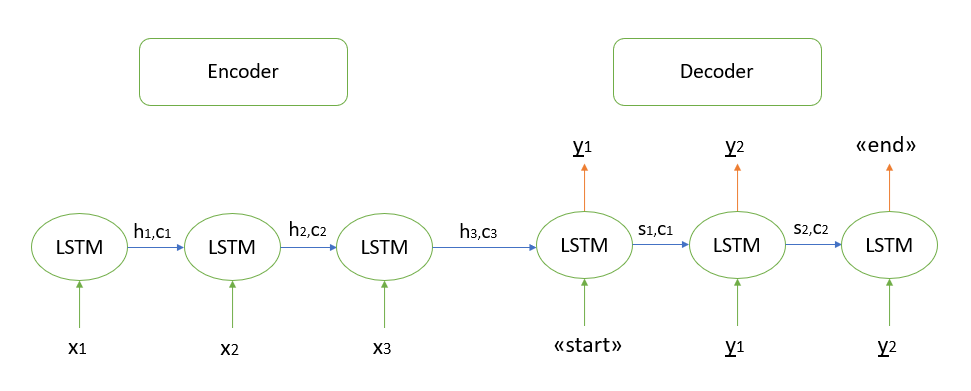
- Wir codieren die gesamte Eingabesequenz und initialisieren den Decoder mit den internen Zuständen des Codierers
- Übergeben Sie das "Start" -Token als Eingabe an den Decoder
- Wir starten den Decoder mit den internen Zuständen des Codierers für einen Zeitschritt, als Ergebnis erhalten wir die Wahrscheinlichkeit des nächsten Wortes (Wort mit der maximalen Wahrscheinlichkeit).
- Übergeben Sie das ausgewählte Wort beim nächsten Zeitschritt als Eingabe an den Decoder und aktualisieren Sie die internen Zustände
- Wiederholen Sie die Schritte 3 und 4, bis Sie das "End" -Token generieren
Weitere Details zur "Encoder-Decoder" -Architektur finden Sie hier .
Abstrakte Zusammenfassung implementieren
Um ein komplexeres abstraktes Modell zum Extrahieren von zusammenfassenden Inhalten zu erstellen, sind sowohl vollständige Nachrichtentexte als auch deren Überschriften erforderlich. Die Überschrift der Nachrichten dient als Zusammenfassung, da sich das Modell an lange Textsequenzen „nicht gut erinnert“.
Beim Bereinigen von Daten verwenden wir Kleinbuchstabenübersetzungen und verwerfen nicht russischsprachige Zeichen. Die Lemmatisierung von Wörtern, das Entfernen von Präpositionen, Partikeln und anderen nicht informativen Teilen der Sprache wirkt sich negativ auf die endgültige Ausgabe des Modells aus, da die Beziehung zwischen Wörtern in einem Satz verloren geht.
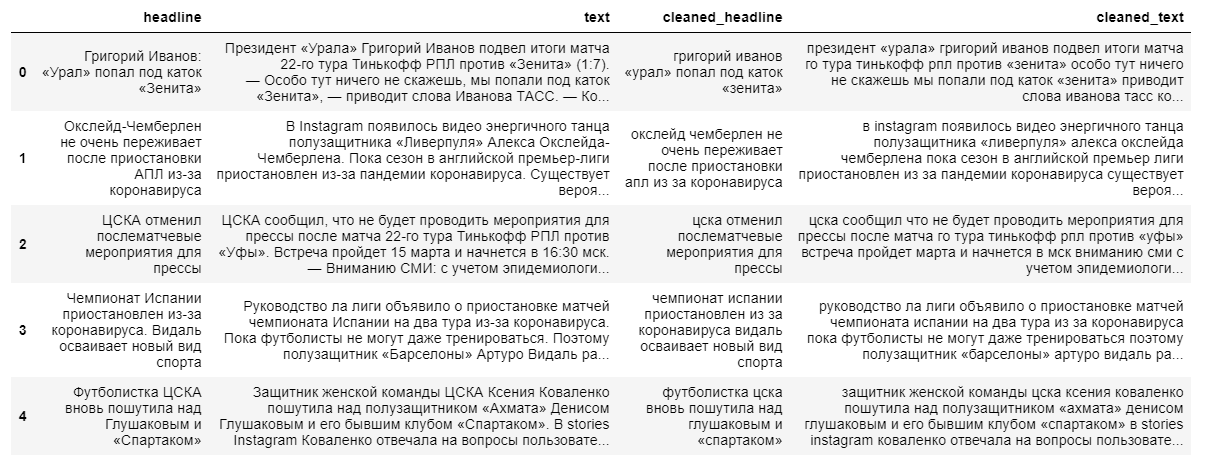
Als nächstes teilen wir die Texte und ihre Titel in Trainings- und Testbeispiele im Verhältnis 9 zu 1 auf, wonach wir sie (zufällig) in Vektoren umwandeln.
Im nächsten Schritt erstellen wir das Modell selbst, das die Vektoren der übertragenen Wörter liest und ihre Verarbeitung unter Verwendung von 3 wiederkehrenden Schichten des LSTM-Codierers und 1 Schicht des Decodierers durchführt.
Nach der Initialisierung des Modells trainieren wir es mit einer Cross-Entropy-Loss-Funktion, die die Diskrepanz zwischen dem tatsächlichen Zieltitel und dem von unserem Modell vorhergesagten Titel anzeigt.

Schließlich geben wir das Modellergebnis für den Trainingssatz aus. Wie Sie in den Beispielen sehen können, enthalten die Ausgangstexte und Zusammenfassungen Ungenauigkeiten, da seltene Wörter vor dem Erstellen des Modells verworfen wurden (wir verwerfen sie, um das Lernen zu vereinfachen).

Die Modellausgabe in dieser Phase lässt zu wünschen übrig. Das Modell „erinnert sich erfolgreich an einige Namen von Vereinen und Spielern“, hat aber den Kontext selbst praktisch nicht erfasst.
Trotz des moderneren Ansatzes zur Wiederaufnahme der Extraktion ist dieser Algorithmus den zuvor erstellten Extraktionsmodellen immer noch sehr unterlegen. Um die Qualität des Modells zu verbessern, ist es zwar möglich, das Modell auf einem größeren Datensatz zu trainieren. Um jedoch eine wirklich gute Modellausgabe zu erzielen, ist es meiner Meinung nach erforderlich, die Architektur der verwendeten neuronalen Netze zu ändern oder möglicherweise vollständig zu ändern.
Welcher Ansatz ist also besser?
Zusammenfassend werde ich die wichtigsten Vor- und Nachteile der überprüften Ansätze zum Extrahieren einer Zusammenfassung auflisten:
1. Extraktiver Ansatz:
Vorteile:
- Das Wesen des Algorithmus ist intuitiv
- Relativ einfache Implementierung
Nachteile:
- Die Qualität von Inhalten kann in vielen Fällen schlechter sein als die von Menschen handgeschriebenen Inhalte
2. Abstrakter Ansatz:
Vorteile:
- Ein gut implementierter Algorithmus kann ein Ergebnis erzielen, das dem manuellen Schreiben von Lebensläufen am nächsten kommt
Nachteile:
- Schwierigkeiten bei der Wahrnehmung der wichtigsten theoretischen Ideen des Algorithmus
- Hohe Arbeitskosten bei der Implementierung des Algorithmus
Es gibt keine eindeutige Antwort auf die Frage, welcher Ansatz den endgültigen Lebenslauf am besten bildet. Es hängt alles von der spezifischen Aufgabe und den Zielen des Benutzers ab. Beispielsweise ist ein Extraktionsalgorithmus höchstwahrscheinlich besser geeignet, um den Inhalt mehrseitiger Dokumente zu generieren, wobei das Extrahieren relevanter Sätze tatsächlich die Idee eines großen Textes korrekt vermitteln kann.
Meiner Meinung nach gehört die Zukunft abstrakten Algorithmen. Trotz der Tatsache, dass sie derzeit schlecht entwickelt sind und bei einer bestimmten Ausgabequalität nur zur Erstellung kleiner Zusammenfassungen (1-2 Sätze) verwendet werden können, lohnt es sich, einen Durchbruch bei neuronalen Netzwerkmethoden zu erwarten. In Zukunft sind sie in der Lage, Inhalte für absolut jede Textgröße zu erstellen, und vor allem wird der Inhalt selbst der manuellen Erstellung eines Lebenslaufs durch einen Experten auf einem bestimmten Gebiet so nahe wie möglich kommen.
Veklenko Vlad, Systemanalyst,
Codex-Konsortium