- Eingebettete Geräte und IoT.
- Datenanalyse.
- Daten von einem System auf ein anderes übertragen.
- Datenarchivierung und (oder) Packen von Daten in Container.
- Datenspeicherung in einer externen oder temporären Datenbank.
- Ein Ersatz für eine Unternehmensdatenbank, die zu Demonstrations- oder Testzwecken verwendet wird.
- Training, Beherrschung der praktischen Techniken des Arbeitens mit einer Datenbank durch Anfänger.
- Prototyping und Erforschung experimenteller Erweiterungen der SQL-Sprache.
Weitere Gründe für die Verwendung dieser Datenbank finden Sie in der SQLite-Dokumentation . In diesem Artikel wird die Verwendung von SQLite in der Python-Entwicklung beschrieben. Daher ist es für uns besonders wichtig, dass dieses DBMS, dargestellt durch das Modul , in der Standardbibliothek der Sprache enthalten ist. Das heißt, es stellt sich heraus, dass Sie für die Arbeit mit SQLite aus Python-Code keine Client-Server-Software installieren müssen und den Betrieb eines Dienstes, der für die Arbeit mit dem DBMS verantwortlich ist, nicht unterstützen müssen. Sie müssen lediglich das Modul importieren und im Programm verwenden, nachdem Sie das relationale Datenbankverwaltungssystem erhalten haben.
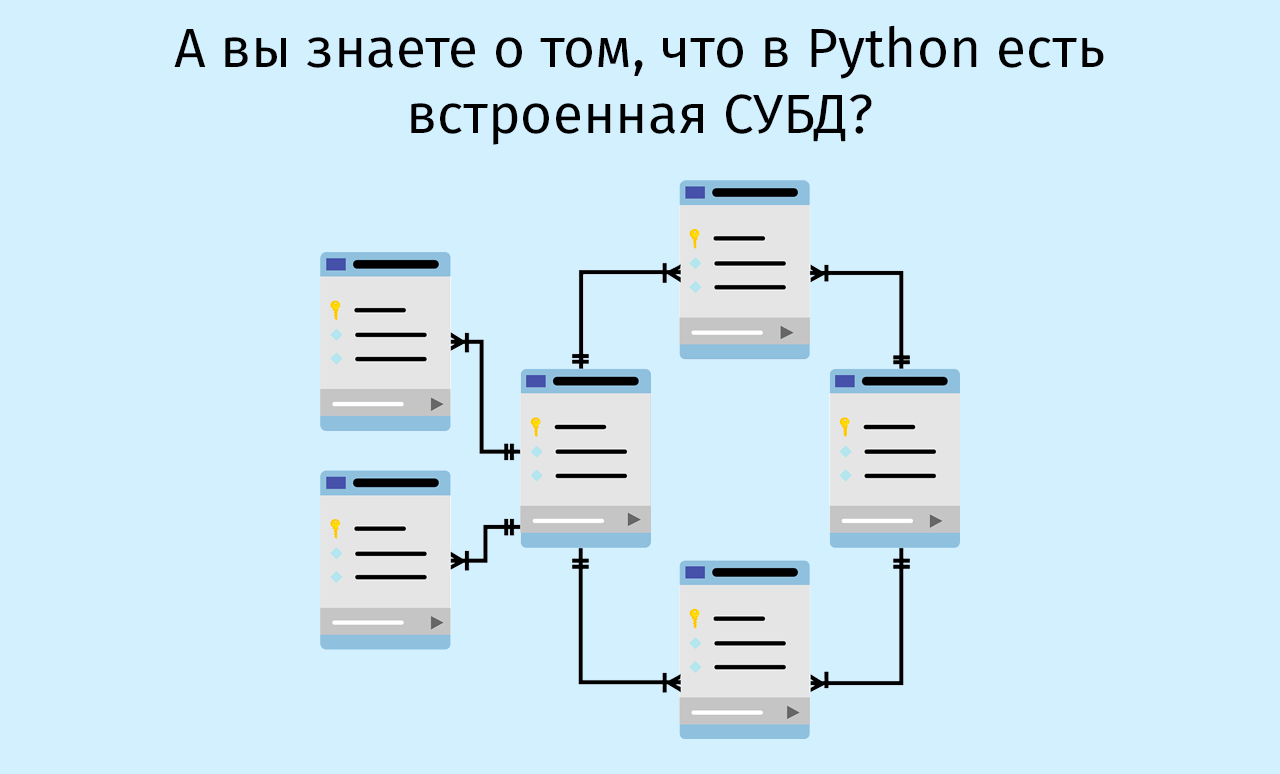
sqlite3sqlite3
Modulimport
Oben habe ich gesagt, dass SQLite ein in Python integriertes DBMS ist. Dies bedeutet, dass es ausreicht, das entsprechende Modul zu importieren, ohne es zuvor mit einem Befehl wie zu installieren, um damit zu arbeiten
pip install. Der SQLite-Importbefehl sieht folgendermaßen aus:
import sqlite3 as sl
Herstellen einer Verbindung zur Datenbank
Um eine Verbindung zu einer SQLite-Datenbank herzustellen, müssen Sie sich nicht um die Installation von Treibern, die Vorbereitung von Verbindungszeichenfolgen und andere solche Dinge kümmern. Sie können ganz einfach und schnell eine Datenbank erstellen und ein Verbindungsobjekt dazu erhalten:
con = sl.connect('my-test.db')
Durch Ausführen dieser Codezeile erstellen wir eine Datenbank und stellen eine Verbindung dazu her. Der Punkt hier ist, dass die Datenbank, zu der wir eine Verbindung herstellen, noch nicht existiert, sodass das System automatisch eine neue leere Datenbank erstellt. Wenn die Datenbank bereits erstellt wurde (vorausgesetzt, dies stammt
my-test.dbaus dem vorherigen Beispiel), müssen Sie zum Herstellen einer Verbindung nur genau denselben Code verwenden.

Neu erstellte Datenbankdatei
Eine Tabelle erstellen
Erstellen wir nun eine Tabelle in unserer neuen Datenbank:
with con:
con.execute("""
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
""")
Hier wird beschrieben, wie Sie der Datenbank eine Tabelle
USERmit drei Spalten hinzufügen . Wie Sie sehen, ist SQLite zwar ein sehr einfaches Datenbankverwaltungssystem, verfügt jedoch über alle grundlegenden Funktionen, die Sie von einem herkömmlichen relationalen Datenbankverwaltungssystem erwarten würden. Wir sprechen über die Unterstützung von Datentypen, einschließlich - Typen, die einen Wert zulassen null, Unterstützung für Primärschlüssel und automatische Inkrementierung.
Wenn dieser Code wie erwartet funktioniert (der obige Befehl gibt jedoch nichts zurück), steht uns eine Tabelle zur Verfügung, die für die weitere Arbeit bereit ist.
Einfügen von Datensätzen in eine Tabelle
Fügen
USERwir einige Datensätze in die gerade erstellte Tabelle ein. Dies gibt uns unter anderem den Beweis, dass die Tabelle tatsächlich mit dem obigen Befehl erstellt wurde.
Stellen wir uns vor, wir müssen der Tabelle mit einem Befehl mehrere Datensätze hinzufügen. In SQLite ist dies sehr einfach:
sql = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(1, 'Alice', 21),
(2, 'Bob', 22),
(3, 'Chris', 23)
]
Hier müssen wir einen SQL-Ausdruck mit Fragezeichen (
?) als Platzhalter definieren. Da wir über ein Datenbankverbindungsobjekt verfügen, können wir nach Vorbereitung des Ausdrucks und der Daten Datensätze in die Tabelle einfügen:
with con:
con.executemany(sql, data)
Nach dem Ausführen dieses Codes werden keine Fehlermeldungen empfangen, was bedeutet, dass die Daten erfolgreich zur Tabelle hinzugefügt wurden.
Ausführen von Datenbankabfragen
Jetzt ist es Zeit herauszufinden, ob die Befehle, die wir gerade ausgeführt haben, korrekt funktioniert haben. Lassen Sie uns eine Datenbankabfrage ausführen und versuchen,
USEReinige Daten aus der Tabelle abzurufen . Zum Beispiel - wir erhalten Aufzeichnungen über Benutzer, deren Alter 22 Jahre nicht überschreitet:
with con:
data = con.execute("SELECT * FROM USER WHERE age <= 22")
for row in data:
print(row)
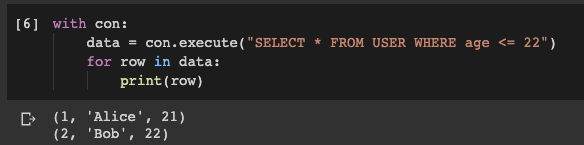
Das Ergebnis der Ausführung einer Abfrage in der Datenbank
Wie Sie sehen, haben wir es geschafft, das zu bekommen, was benötigt wurde. Und es war sehr einfach.
Obwohl SQLite ein einfaches DBMS ist, bietet es eine äußerst breite Unterstützung. Daher können Sie mit den meisten SQL-Clients damit arbeiten.
Ich benutze DBeaver. Schauen wir uns an, wie es aussieht.
Herstellen einer Verbindung zur SQLite-Datenbank vom SQL-Client (DBeaver)
Ich verwende den Google Colab-Clouddienst und möchte eine Datei
my-test.dbauf meinen Computer herunterladen . Wenn Sie mit SQLite auf einem Computer experimentieren, bedeutet dies, dass Sie mit dem SQL-Client eine Verbindung herstellen können, ohne die Datenbankdatei von irgendwoher herunterladen zu müssen.
Im Fall von DBeaver müssen Sie zum Herstellen einer Verbindung mit der SQLite-Datenbank eine neue Verbindung erstellen und SQLite als Datenbanktyp auswählen.
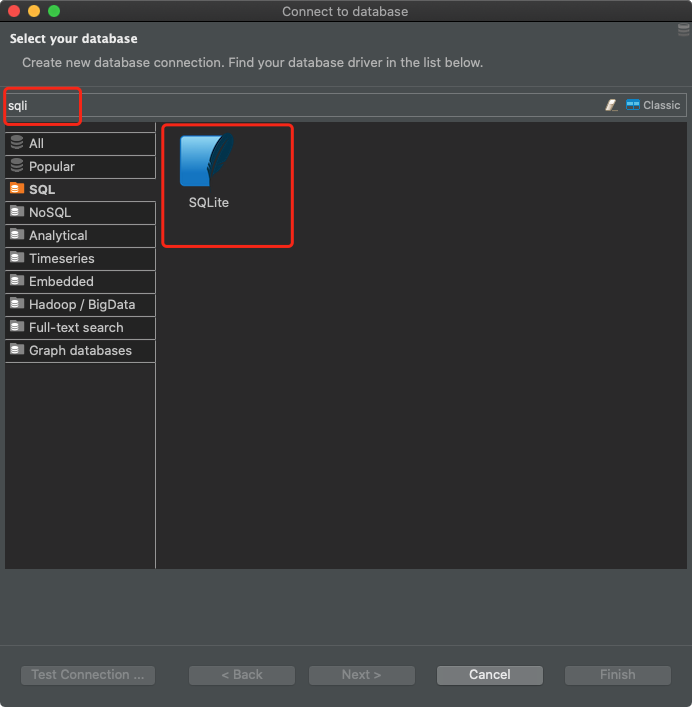
Vorbereiten der Verbindung in DBeaver
Als Nächstes müssen Sie die Datenbankdatei suchen.
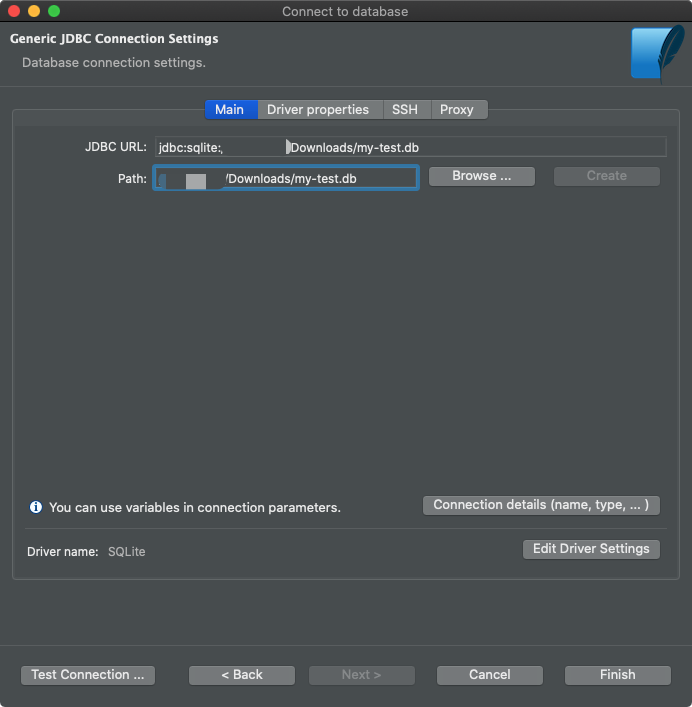
Verbinden der Datenbankdatei
Danach können Sie SQL-Abfragen für die Datenbank ausführen. Hier gibt es nichts Besonderes, das sich von der Arbeit mit regulären relationalen Datenbanken unterscheidet.
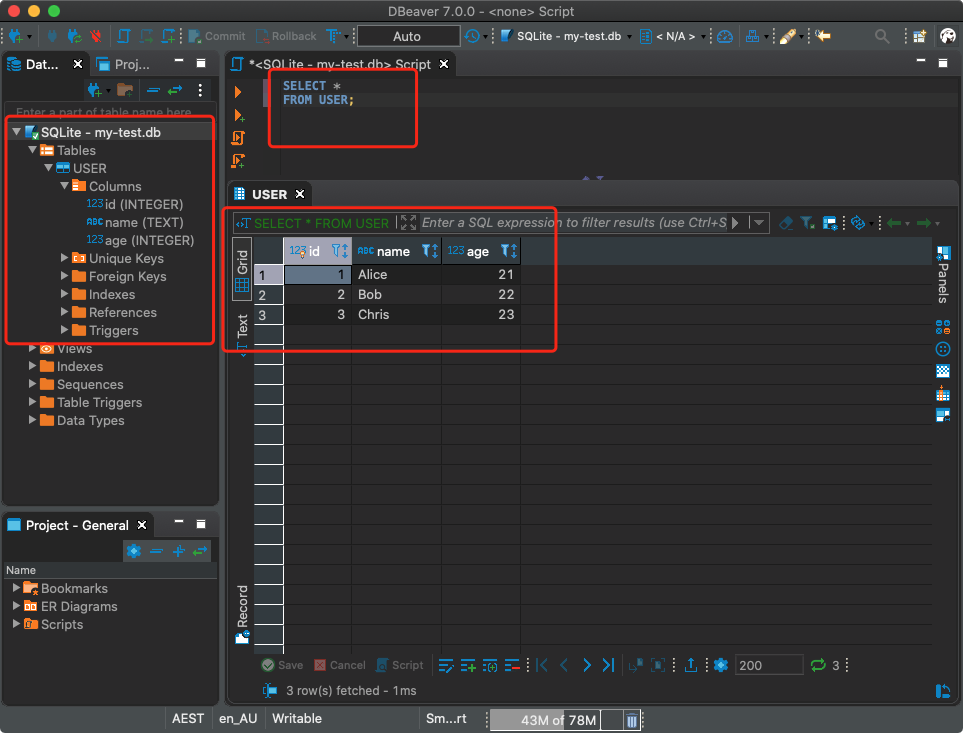
Ausführen von Datenbankabfragen
Integration mit Pandas
Denken Sie, dass wir hier unser Gespräch über die SQLite-Unterstützung in Python abschließen? Nein, wir haben noch viel zu besprechen. Da SQLite ein Standard-Python-Modul ist, lässt es sich problemlos in Pandas-Datenrahmen integrieren.
Deklarieren wir den Datenrahmen:
df_skill = pd.DataFrame({
'user_id': [1,1,2,2,3,3,3],
'skill': ['Network Security', 'Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science', 'Machine Learning']
})
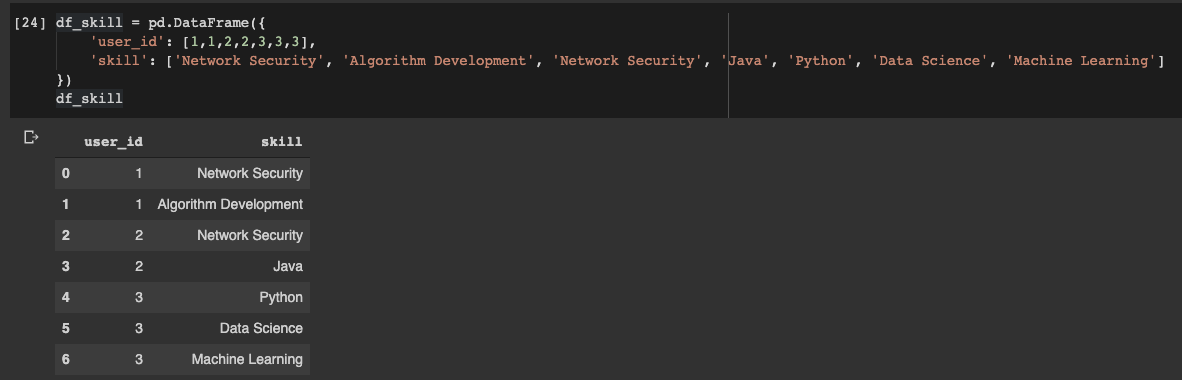
Pandas-Datenrahmen
Um einen Datenrahmen in der Datenbank zu speichern, können Sie einfach die folgende Methode verwenden
to_sql():
df_skill.to_sql('SKILL', con)
Das ist alles! Wir müssen nicht einmal vorher eine Tabelle erstellen. Die Datentypen und Merkmale der Felder werden automatisch basierend auf den Merkmalen des Datenrahmens konfiguriert. Natürlich können Sie bei Bedarf alles selbst anpassen.
Nehmen wir nun an, wir müssen die Vereinigung der Tabellen
USERund erhalten SKILLund die Daten in datafreym pandas schreiben. Es ist auch sehr einfach:
df = pd.read_sql('''
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
''', con)
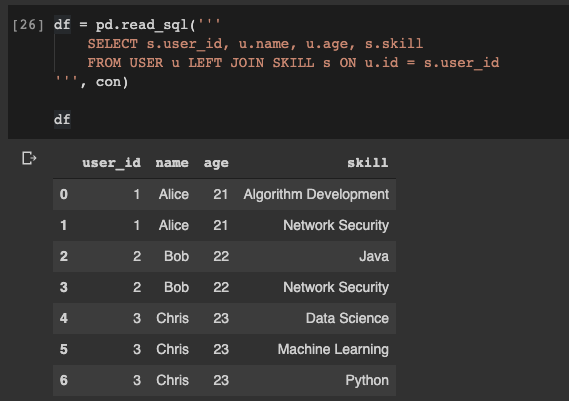
Lesen von Daten aus einer Datenbank in einen Pandas-Datenrahmen
Großartig! Schreiben wir nun, was wir haben, an eine neue Tabelle mit dem Namen
USER_SKILL:
df.to_sql('USER_SKILL', con)
Natürlich können Sie mit dieser Tabelle mit dem SQL-Client arbeiten.
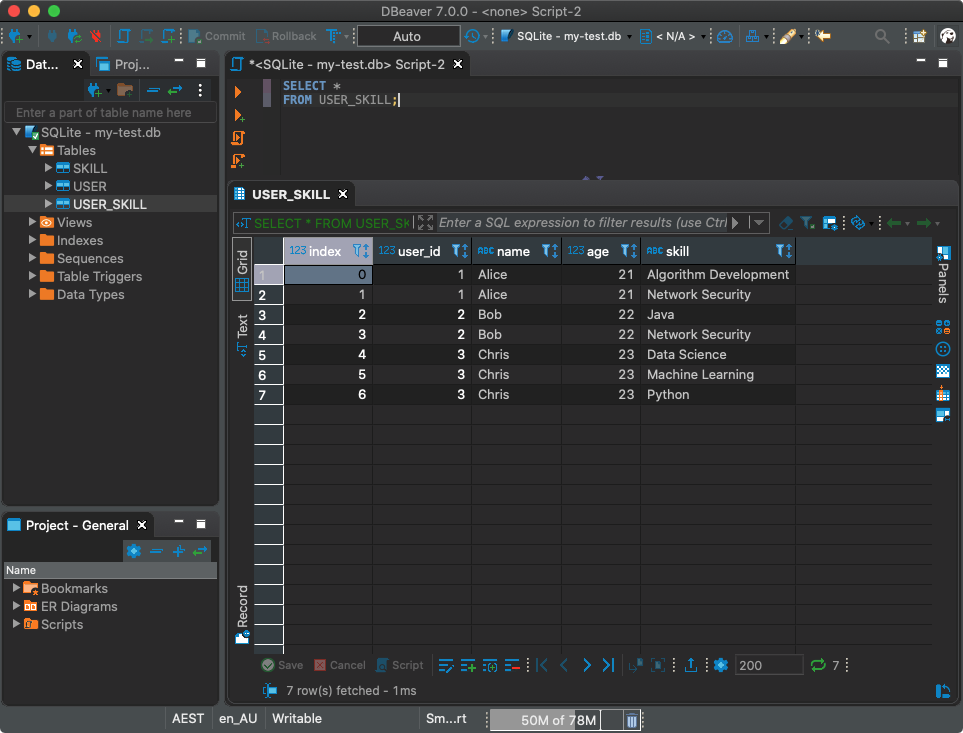
Verwenden eines SQL-Clients zum Arbeiten mit einer Datenbank
Ergebnis
Es gibt sicherlich viele angenehme Überraschungen in Python, die Sie möglicherweise nicht bemerken, wenn Sie nicht speziell danach suchen. Niemand hat solche Funktionen speziell versteckt, aber aufgrund der Tatsache, dass viele Dinge in Python integriert sind, können Sie einige dieser Funktionen einfach nicht beachten oder, nachdem Sie von irgendwoher davon erfahren haben, sie einfach vergessen.
Hier habe ich darüber gesprochen, wie man die in Python integrierte Bibliothek verwendet
sqlite3, um Datenbanken zu erstellen und damit zu arbeiten. Natürlich unterstützen solche Datenbanken nicht nur das Hinzufügen von Daten, sondern auch das Ändern und Löschen von Informationen. Ich glaube, Sie, nachdem Sie davon erfahren haben sqlite3, werden alles selbst erleben.
Das sehr wichtige ist, dass SQLite einen großartigen Job mit Pandas macht. Es ist sehr einfach, Daten aus der Datenbank zu lesen, indem sie in Datenrahmen platziert werden. Das Speichern des Inhalts von Datenrahmen in einer Datenbank ist nicht weniger einfach. Dies macht die Verwendung von SQLite noch einfacher.
Ich lade alle, die bisher gelesen haben, ein, selbst nach interessanten Python-Funktionen zu suchen!
Den Code, den ich in diesem Artikel demonstriert habe, finden Sie hier .
Verwenden Sie SQLite in Ihren Python-Projekten?
