Wiederholen, aber jedes Mal auf eine neue Art - ist das nicht Kunst?
Stanislav Jerzy Lec aus dem Buch "Uncombed Thoughts"
Das Wörterbuch definiert die Replikation als den Prozess, bei dem zwei (oder mehr) Datensätze in einem konsistenten Zustand gehalten werden. Was der "konsistente Status von Datensätzen" ist, ist eine separate große Frage. Lassen Sie uns die Definition auf einfachere Weise neu formulieren: Der Prozess des Änderns eines Datensatzes, der als Replikat bezeichnet wird, als Reaktion auf Änderungen in einem anderen Datensatz, der als Master bezeichnet wird. Die Sets sind nicht unbedingt gleich.

Die Unterstützung der Datenbankreplikation ist eine der wichtigsten Aufgaben des Administrators: Fast jede Datenbank von Bedeutung verfügt über ein Replikat oder sogar über mehrere.
Zu den Replikationsaufgaben gehören mindestens
- Unterstützung der Sicherungsdatenbank bei Verlust der Hauptdatenbank;
- Reduzieren der Belastung der Basis aufgrund der Übertragung eines Teils der Anforderungen an Replikate;
- Übertragung von Daten an Archiv- oder Analysesysteme.
In diesem Artikel werde ich über die Replikationstypen und die Aufgaben sprechen, die jeder Replikationstyp löst.
Es gibt drei Ansätze zur Replikation:
- Blockieren Sie die Replikation auf Speichersystemebene.
- Physische Replikation auf DBMS-Ebene;
- Logische Replikation auf DBMS-Ebene.
Blockieren Sie die Replikation
Bei der Blockreplikation wird jeder Schreibvorgang nicht nur auf der primären Festplatte, sondern auch auf der Sicherung ausgeführt. Somit entspricht ein Volume auf einem Array einem gespiegelten Volume auf einem anderen Array, wobei das Hauptvolume mit einer Byte-Genauigkeit wiederholt wird:
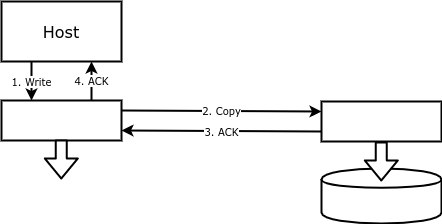
Zu den Vorteilen einer solchen Replikation gehören die einfache Einrichtung und Zuverlässigkeit. Daten können entweder von einem Festplattenarray oder von etwas (einem Gerät oder einer Software) zwischen dem Host und der Festplatte auf eine entfernte Festplatte geschrieben werden.
Festplatten-Arrays können durch Optionen zum Aktivieren der Replikation ergänzt werden. Der Optionsname hängt vom Array-Hersteller ab:
| Hersteller | Warenzeichen
|
|---|---|
| EMV | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror - synchrone Replikation
Global Mirror - asynchrone Replikation |
| Hitachi | Getreue Kopie |
| Hewlett Packard | Kontinuierlicher Zugriff |
| Huawei | Hyperreplikation |
Wenn das Festplattenarray keine Daten replizieren kann, kann ein Agent zwischen dem Host und dem Array installiert werden, der gleichzeitig in zwei Arrays schreibt. Ein Agent kann entweder ein eigenständiges Gerät (EMC VPLEX) oder eine Softwarekomponente (HPE PeerPersistence, Windows Server Storage Replica, DRBD) sein. Im Gegensatz zu einem Festplattenarray, das nur mit demselben Array oder zumindest mit einem Array desselben Herstellers arbeiten kann, kann ein Agent mit völlig unterschiedlichen Festplattengeräten arbeiten.
Der Hauptzweck der Blockreplikation besteht darin, Fehlertoleranz bereitzustellen. Wenn die Datenbank verloren geht, können Sie sie mit dem gespiegelten Volume neu starten.
Die Blockreplikation ist aufgrund ihrer Vielseitigkeit großartig, aber Vielseitigkeit hat ihren Preis.
Erstens kann kein Server ein gespiegeltes Volume verarbeiten, da sein Betriebssystem keine Schreibvorgänge steuern kann. Aus Sicht eines Beobachters erscheinen die Daten auf dem gespiegelten Volumen von selbst. Im Katastrophenfall (Ausfall des Primärservers oder des gesamten Rechenzentrums, in dem sich der Primärserver befindet) sollten Sie die Replikation stoppen, die Bereitstellung des primären Volumes aufheben und das gespiegelte Volume bereitstellen. Sie sollten die Replikation so bald wie möglich in die entgegengesetzte Richtung neu starten.
Bei Verwendung eines Agenten werden alle diese Aktionen vom Agenten ausgeführt, was die Konfiguration vereinfacht, aber die Umschaltzeit nicht verkürzt.
Zweitens kann das DBMS selbst auf dem Sicherungsserver erst gestartet werden, nachdem die Festplatte bereitgestellt wurde. In einigen Betriebssystemen, beispielsweise in Solaris, wird der Speicher für den Cache während der Zuweisung markiert, und die Markierungszeit ist proportional zur Größe des zugewiesenen Speichers, dh der Start der Instanz erfolgt nicht sofort. Außerdem ist der Cache nach dem Neustart leer.
Drittens stellt das DBMS nach dem Start auf dem Sicherungsserver fest, dass die Daten auf der Festplatte inkonsistent sind, und Sie müssen viel Zeit für die Wiederherstellung mithilfe von Redo-Protokollen aufwenden: Wiederholen Sie zunächst die Transaktionen, deren Ergebnisse im Protokoll gespeichert wurden, für die jedoch keine Zeit zum Speichern in den Datendateien vorhanden war. Führen Sie dann ein Rollback der Transaktionen durch, für die zum Zeitpunkt des Fehlers keine Zeit zum Abschließen vorhanden war.
Die Blockreplikation kann nicht für den Lastenausgleich verwendet werden. Ein ähnliches Schema wird verwendet, um den Datenspeicher mit dem gespiegelten Volume auf demselben Array wie das primäre zu aktualisieren. EMC und HP nennen dieses Schema BCV, nur EMC steht für Business Continuance Volume und HP steht für Business Copy Volume. IBM hat für diesen Fall keine spezielle Marke. Dieses Schema wird als "gespiegeltes Volume" bezeichnet.

Im Array werden zwei Volumes erstellt und Schreibvorgänge werden für beide synchron ausgeführt (A). Zu einem bestimmten Zeitpunkt bricht der Spiegel (B), dh die Volumina werden unabhängig. Das gespiegelte Volume wird auf einem Server bereitgestellt, der für Speicheraktualisierungen vorgesehen ist, und auf diesem Server wird eine Datenbankinstanz ausgelöst. Die Instanz benötigt genauso viel Zeit wie bei einer Blockreplikationswiederherstellung. Diese Zeit kann jedoch erheblich reduziert werden, indem der Spiegel außerhalb der Spitzenzeiten unterbrochen wird. Der Punkt ist, dass das Aufbrechen des Spiegels in seinen Folgen einer abnormalen Beendigung des DBMS gleichkommt und die Wiederherstellungszeit bei einer abnormalen Beendigung wesentlich von der Anzahl der aktiven Transaktionen zum Zeitpunkt des Absturzes abhängt. Die zum Entladen vorgesehene Datenbank steht sowohl zum Lesen als auch zum Schreiben zur Verfügung. Alle Blockkennungen,Spiegel, die nach der Unterbrechung sowohl auf dem Haupt- als auch auf dem gespiegelten Volume geändert wurden, werden in einem speziellen Bereich von Block Change Tracking (BCT) gespeichert.
Nach dem Ende des Uploads wird das gespiegelte Volume nicht gemountet (C), der Spiegel wird wiederhergestellt, und nach einer Weile holt das gespiegelte Volume das Haupt-Volume wieder ein und wird zu seiner Kopie.
Physische Replikation
Protokolle (Redo-Protokoll oder Write-Ahead-Protokoll) enthalten alle Änderungen, die an den Datenbankdateien vorgenommen werden. Die Idee hinter der physischen Replikation besteht darin, dass Änderungen aus den Protokollen erneut in eine andere Datenbank (Replikat) übernommen werden und die Daten im Replikat somit die Daten im Master byteweise replizieren.
Die Möglichkeit, Datenbankprotokolle zum Aktualisieren eines Replikats zu verwenden, wurde in der 1996 veröffentlichten Version von Oracle 7.3 veröffentlicht. Bereits in der Version von Oracle 8i wurde die Übermittlung von Protokollen von der Hauptdatenbank an das Replikat automatisiert und als DataGuard bezeichnet. Die Technologie erwies sich als so gefragt, dass der physische Replikationsmechanismus heute in fast allen modernen DBMS vorhanden ist.
| DBMS | Replikationsoption
|
|---|---|
| Orakel | Aktiver DataGuard |
| IBM DB2 | HADR |
| Microsoft SQL Server | Protokollversand / Immer an |
| PostgreSQL | Protokollversand / Streaming-Replikation |
| MySQL | Alibaba physische InnoDB-Replikation |
Die Erfahrung zeigt, dass, wenn der Server nur verwendet wird, um das Replikat auf dem neuesten Stand zu halten, etwa 10% der Verarbeitungsleistung des Servers, auf dem die Hauptbasis ausgeführt wird, ausreichen.
DBMS-Protokolle dürfen nicht außerhalb dieser Plattform verwendet werden. Ihr Format ist nicht dokumentiert und kann ohne vorherige Ankündigung geändert werden. Daher die ganz natürliche Anforderung, dass eine physische Replikation nur zwischen Instanzen derselben Version desselben DBMS möglich ist. Daher die möglichen Einschränkungen des Betriebssystems und der Prozessorarchitektur, die sich auch auf das Format des Protokolls auswirken können.
Die physische Replikation unterliegt natürlich keinen Einschränkungen für Speichermodelle. Darüber hinaus können sich die Dateien in der Replikatdatenbank auf eine völlig andere Weise befinden als in der Quellendatenbank. Sie müssen lediglich die Entsprechung zwischen den Volumes beschreiben, auf denen sich diese Dateien befinden.
Mit Oracle DataGuard können Sie einige der Dateien aus der Replikatdatenbank löschen. In diesem Fall werden Änderungen in den Protokollen, die sich auf diese Dateien beziehen, ignoriert.
Die physische Datenbankreplikation bietet gegenüber der Speicherreplikation viele Vorteile:
- Die übertragene Datenmenge ist geringer, da nur Protokolle übertragen werden, keine Datendateien. Experimente zeigen eine 5-7-fache Abnahme des Verkehrs;
- : - , ; , ;
- , . , .
Die Möglichkeit, Daten von einem Replikat zu lesen, wurde 2007 mit der Veröffentlichung von Oracle 11g eingeführt. Dies wird durch den Beinamen "active" angezeigt, der dem Namen der DataGuard-Technologie hinzugefügt wurde. Andere DBMS können ebenfalls von einem Replikat lesen, dies spiegelt sich jedoch nicht im Namen wider.
Das Schreiben von Daten in ein Replikat ist nicht möglich, da Änderungen Byte für Byte vorgenommen werden und das Replikat keine wettbewerbsfähige Ausführung seiner Anforderungen bieten kann. Oracle Active DataGuard in neueren Versionen ermöglicht das Schreiben in das Replikat, dies ist jedoch nichts anderes als "Zucker": Tatsächlich werden die Änderungen auf der Hauptbasis ausgeführt, und der Client wartet darauf, dass sie auf das Replikat übertragen werden.
Wenn eine Datei in der Hauptdatenbank beschädigt ist, können Sie einfach die entsprechende Datei aus dem Replikat kopieren (lesen Sie das Administratorhandbuch sorgfältig durch, bevor Sie dies mit Ihrer Datenbank tun!). Die Datei auf dem Replikat ist möglicherweise nicht mit der Datei in der Hauptdatenbank identisch. Tatsache ist, dass beim Erweitern der Datei neue Blöcke mit nichts gefüllt werden, um die Geschwindigkeit zu erhöhen, und dass ihr Inhalt versehentlich ist. Die Basis verwendet möglicherweise nicht den gesamten Speicherplatz im Block (z. B. ist möglicherweise freier Speicherplatz im Block vorhanden), aber der Inhalt des verwendeten Speicherplatzes stimmt mit dem Byte überein.
Die physische Replikation kann entweder synchron oder asynchron sein. Bei der asynchronen Replikation gibt es immer eine bestimmte Reihe von Transaktionen, die auf der Hauptbasis abgeschlossen wurden, die Standby-Basis jedoch noch nicht erreicht haben. Wenn bei einem Übergang zur Standby-Basis die Hauptbasis ausfällt, gehen diese Transaktionen verloren. Bei der synchronen Replikation bedeutet der Abschluss des Festschreibungsvorgangs, dass alle Protokolldatensätze, die sich auf diese Transaktion beziehen, für das Replikat festgeschrieben wurden. Es ist wichtig zu verstehen, dass das Abrufen eines Protokollreplikats nicht bedeutet, dass die Änderungen auf die Daten angewendet werden. Wenn die Hauptdatenbank verloren geht, gehen Transaktionen nicht verloren. Wenn die Anwendung jedoch Daten in die Hauptdatenbank schreibt und sie aus dem Replikat liest, besteht die Möglichkeit, die alte Version dieser Daten abzurufen.
In PostgreSQL ist es möglich, die Replikation so zu konfigurieren, dass das Festschreiben erst abgeschlossen wird, nachdem die Änderungen auf die Replikatdaten angewendet wurden (Option
synchronous_commit = remote_apply). In Oracle können Sie das gesamte Replikat oder einzelne Sitzungen so konfigurieren, dass Abfragen nur ausgeführt werden, wenn das Replikat nicht hinter der Hauptdatenbank zurückbleibt ( STANDBY_MAX_DATA_DELAY=0). Es ist jedoch immer noch besser, die Anwendung so zu gestalten, dass das Schreiben in die Hauptdatenbank und das Lesen von Replikaten in verschiedenen Modulen ausgeführt werden.
Bei der Suche nach einer Antwort auf die Frage, welcher Modus synchron oder asynchron gewählt werden soll, helfen uns Oracle-Vermarkter. DataGuard bietet drei Modi, von denen jeder einen der Parameter - Datensicherheit, Leistung, Verfügbarkeit - auf Kosten der anderen maximiert:
- Maximale Leistung: Die Replikation ist immer asynchron.
- Maximum protection: ; , commit ;
- Maximum availability: ; , , , .
Trotz der unbestreitbaren Vorteile der Datenbankreplikation gegenüber der Blockreplikation zögern Administratoren in vielen Unternehmen, insbesondere in Unternehmen mit alten Zuverlässigkeitstraditionen, die Blockreplikation immer noch sehr. Dafür gibt es zwei Gründe.
Erstens wird bei der Replikation mit einem Festplattenarray der Datenverkehr nicht über das Datenübertragungsnetzwerk (LAN), sondern über das Speicherbereichsnetzwerk geleitet. In Infrastrukturen, die vor langer Zeit aufgebaut wurden, sind SANs häufig viel zuverlässiger und leistungsfähiger als Datennetze.
Zweitens ist die synchrone Replikation mittels eines DBMS in jüngster Zeit zuverlässig geworden. In Oracle gelang der Durchbruch in der 2007 erschienenen Version 11g, und in anderen DBMS trat die synchrone Replikation noch später auf. Natürlich sind 10 Jahre nach den Maßstäben der Informationstechnologie nicht so kurz, aber wenn es um Datensicherheit geht, orientieren sich einige Administratoren immer noch am Prinzip „Was auch immer passiert“ ...
Logische Replikation
Alle Änderungen in der Datenbank erfolgen durch Aufrufe der API, z. B. durch Ausführen von SQL-Abfragen. Die Idee, dieselbe Abfolge von Abfragen auf zwei verschiedenen Grundlagen auszuführen, scheint sehr verlockend. Für die Replikation müssen Sie zwei Regeln einhalten:
- , , . D, A B.
- , , . B , , C.
Die Replikation von Befehlen (anweisungsbasierte Replikation) ist beispielsweise in MySQL implementiert. Leider führt dieses einfache Schema aus zwei Gründen nicht zu identischen Datensätzen.
Erstens sind nicht alle APIs deterministisch. Wenn eine SQL-Abfrage beispielsweise die Funktion now () oder sysdate () enthält, die die aktuelle Uhrzeit zurückgibt, werden auf verschiedenen Servern unterschiedliche Ergebnisse zurückgegeben, da die Abfragen nicht gleichzeitig ausgeführt werden. Darüber hinaus können unterschiedliche Zustände von Triggern und gespeicherten Funktionen, unterschiedliche Gebietsschemas, die die Sortierreihenfolge beeinflussen, und vieles mehr zu Unterschieden führen.
Zweitens kann die parallele befehlsbasierte Replikation nicht ordnungsgemäß angehalten und neu gestartet werden.
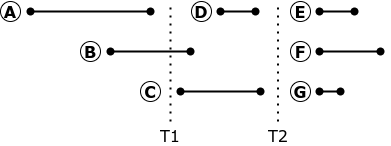
Wenn die Replikation zum Zeitpunkt T1 gestoppt wird, sollte Transaktion B abgebrochen und zurückgesetzt werden. Wenn Sie die Replikation neu starten, kann die Ausführung von Transaktion B das Replikat in einen anderen Zustand als den Status der Quellendatenbank bringen: An der Quelle wurde Transaktion B vor dem Ende von Transaktion A gestartet. Dies bedeutet, dass die von Transaktion A vorgenommenen Änderungen nicht angezeigt wurden. Die
Replikation von Anforderungen kann gestoppt werden und Neustart nur zum Zeitpunkt T2, wenn keine aktiven Transaktionen in der Datenbank vorhanden sind. Natürlich gibt es auf einer stark belasteten Industriebasis keine solchen Momente.
In der Regel werden bei der logischen Replikation deterministische Abfragen verwendet. Der Determinismus der Anfrage wird durch zwei Eigenschaften bereitgestellt:
- Die Abfrage aktualisiert (oder fügt ein oder löscht) einen einzelnen Datensatz und identifiziert ihn anhand seines Primärschlüssels (oder eindeutigen Schlüssels).
- Alle Anforderungsparameter werden explizit in der Anforderung selbst festgelegt.
Im Gegensatz zur anweisungsbasierten Replikation wird dieser Ansatz als zeilenbasierte Replikation bezeichnet.
Angenommen, wir haben eine Mitarbeitertabelle mit den folgenden Daten:
| ICH WÜRDE | Name | Abteilung | Gehalt
|
|---|---|---|---|
| 3817 | Ivanov Ivan Ivanovich | 36 | 1800 |
| 2274 | Petrov Petr Petrovich | 36 | 1600 |
| 4415 | Kuznetsov Semyon Andreevich | 41 | 2100 |
Die folgende Operation wurde für diese Tabelle ausgeführt:
update employee set salary = salary*1.2 where dept=36;Um Daten korrekt zu replizieren, werden im Replikat die folgenden Abfragen ausgeführt:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;Abfragen führen zu demselben Ergebnis wie auf der ursprünglichen Basis, entsprechen jedoch nicht den ausgeführten Abfragen.
Die Replikatbasis ist offen und steht nicht nur zum Lesen, sondern auch zum Schreiben zur Verfügung. Auf diese Weise kann das Replikat zum Ausführen eines Teils der Abfragen verwendet werden, einschließlich zum Erstellen von Berichten, für die zusätzliche Tabellen oder Indizes erstellt werden müssen.
Es ist wichtig zu verstehen, dass ein logisches Replikat nur dann der ursprünglichen Basis entspricht, wenn keine zusätzlichen Änderungen daran vorgenommen werden. Wenn beispielsweise im obigen Beispiel in der Replik Sidorovs Abteilung zu 36 hinzugefügt wird, erhält er keine Beförderung, und wenn Ivanov von Abteilung 36 versetzt wird, erhält er eine Beförderung, egal was passiert.
Die logische Replikation bietet eine Reihe von Funktionen, die bei anderen Replikationstypen nicht vorhanden sind:
- Einrichten eines Satzes replizierter Daten auf Tabellenebene (für die physische Replikation - auf Datei- und Tabellenbereichsebene, für die Blockreplikation - auf Volume-Ebene);
- Erstellen komplexer Replikationstopologien - zum Beispiel Konsolidieren mehrerer Datenbanken zu einer oder bidirektionalen Replikation;
- Verringerung der Menge der übertragenen Daten;
- Replikation zwischen verschiedenen Versionen des DBMS oder sogar zwischen dem DBMS verschiedener Hersteller;
- Datenverarbeitung während der Replikation, einschließlich Umstrukturierung, Anreicherung und Aufbewahrung des Verlaufs.
Es gibt auch Nachteile, bei denen die logische Replikation die physische Replikation nicht ersetzen kann:
- Alle replizierten Daten müssen Primärschlüssel haben.
- Die logische Replikation unterstützt nicht alle Datentypen. Beispielsweise können Probleme mit BLOBs auftreten.
- : , ;
- ;
- , , – , .
Die letzten beiden Nachteile schränken die Verwendung eines logischen Replikats als Fehlertoleranzwerkzeug erheblich ein. Wenn eine Abfrage in der Hauptdatenbank mehrere Zeilen gleichzeitig ändert, kann das Replikat erheblich verzögert werden. Die Möglichkeit, Rollen zu wechseln, erfordert bemerkenswerte Anstrengungen von Entwicklern und Administratoren.
Es gibt verschiedene Möglichkeiten, die logische Replikation zu implementieren. Jede dieser Methoden implementiert einen Teil der Funktionen und den anderen nicht:
- Replikation durch Trigger;
- Verwenden von DBMS-Protokollen;
- Verwendung von CDC-Software (Change Data Capture);
- angewandte Replikation.
Replikation auslösen
Trigger ist eine gespeicherte Prozedur, die bei jeder Aktion zum Ändern von Daten automatisch ausgeführt wird. Der Trigger, der aufgerufen wird, wenn sich jeder Datensatz ändert, hat Zugriff auf den Schlüssel dieses Datensatzes sowie auf die alten und neuen Feldwerte. Bei Bedarf kann der Trigger neue Zeilenwerte in einer speziellen Tabelle speichern, von der ein spezieller Prozess auf der Replikatseite sie liest. Die Menge an Code in Triggern ist groß, daher gibt es eine spezielle Software, die solche Trigger generiert, z. B. "Merge Replication" - eine Komponente von Microsoft SQL Server oder Slony-I - ein separates Produkt für die PostgreSQL-Replikation.
Stärken der Trigger-Replikation:
- Unabhängigkeit von den Versionen der Hauptbasis und der Nachbildung;
- umfangreiche Datenkonvertierungsfunktionen.
Nachteile:
- Belastung der Hauptbasis;
- hohe Replikationslatenz.
Verwenden von DBMS-Protokollen
Das DBMS selbst kann auch logische Replikationsfunktionen bereitstellen. Protokolle sind die Datenquelle, genau wie bei der physischen Replikation. Die Informationen zur Byteänderung werden auch durch Informationen zu den geänderten Feldern (zusätzliche Protokollierung in Oracle,
wal_level = logicalin PostgreSQL) sowie zum Wert des eindeutigen Schlüssels ergänzt, auch wenn er sich nicht ändert. Infolgedessen steigt das Volumen der Datenbankprotokolle - nach verschiedenen Schätzungen von 10 auf 15%.
Die Replikationsfunktionen hängen von der Implementierung in einem bestimmten DBMS ab. Wenn Sie in Oracle einen logischen Standby-Modus erstellen können, können Sie in PostgreSQL oder Microsoft SQL Server mithilfe der integrierten Plattformtools ein komplexes System gegenseitiger Abonnements und Veröffentlichungen bereitstellen. Darüber hinaus bietet das DBMS eine integrierte Überwachung und Steuerung der Replikation.
Die Nachteile dieses Ansatzes umfassen eine Zunahme des Protokollvolumens und eine mögliche Zunahme des Verkehrs zwischen Knoten.
CDC verwenden
Es gibt eine ganze Klasse von Software, mit der die logische Replikation organisiert werden kann. Diese Software heißt CDC, Datenerfassung ändern. Hier ist eine Liste der bekanntesten Plattformen dieser Klasse:
- Oracle GoldenGate (2009 von GoldenGate übernommen);
- IBM InfoSphere Data Replication (früher InfoSphere CDC; noch früher DataMirror Transformation Server, 2007 von DataMirror übernommen);
- VisionSolutions DoubleTake / MIMIX (früher Vision Replicate1);
- Qlik Data Integration Platform (ehemals Attunity);
- Informatica PowerExchange CDC;
- Debezium;
- StreamSets Data Collector ...
Die Aufgabe der Plattform besteht darin, die Datenbankprotokolle zu lesen, Informationen zu transformieren, Informationen auf ein Replikat zu übertragen und anzuwenden. Wie bei der Replikation über das DBMS selbst sollte das Protokoll Informationen zu den geänderten Feldern enthalten. Mit einer zusätzlichen Anwendung können Sie komplexe Transformationen der replizierten Daten im laufenden Betrieb durchführen und recht komplexe Replikationstopologien erstellen.
Starke Seiten:
- die Fähigkeit, zwischen verschiedenen DBMS zu replizieren, einschließlich des Ladens von Daten in Berichtssysteme;
- die breitesten Möglichkeiten der Datenverarbeitung und -transformation;
- Minimaler Verkehr zwischen Knoten - Die Plattform schneidet unnötige Daten ab und kann den Verkehr komprimieren.
- integrierte Funktionen zur Überwachung des Replikationsstatus.
Es gibt nicht viele Nachteile:
- Erhöhung des Protokollvolumens wie bei der logischen Replikation mittels eines DBMS;
- Neue Software ist schwer zu konfigurieren und / oder mit teuren Lizenzen.
Es sind CDC-Plattformen, die traditionell verwendet werden, um Data Warehouses von Unternehmen nahezu in Echtzeit zu aktualisieren.
Angewandte Replikation
Schließlich ist eine andere Art der Replikation die Bildung von Änderungsvektoren direkt auf der Clientseite. Der Client muss deterministische Abfragen ausgeben, die sich auf einen einzelnen Datensatz auswirken. Dies kann durch Verwendung einer speziellen Datenbankbibliothek wie Borland Database Engine (BDE) oder Hibernate ORM erreicht werden.
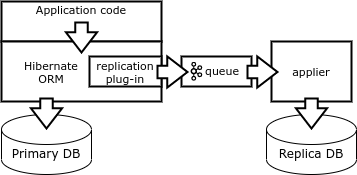
Wenn die Anwendung die Transaktion abgeschlossen hat, schreibt das ORM-Plugin für den Ruhezustand den Änderungsvektor in die Warteschlange und führt die Transaktion in der Datenbank aus. Ein spezieller Replikatorprozess subtrahiert Vektoren von der Warteschlange und führt Transaktionen in der Replikatbasis durch.
Dieser Mechanismus eignet sich zum Aktualisieren von Berichtssystemen. Es kann auch verwendet werden, um Fehlertoleranz bereitzustellen. In diesem Fall muss die Anwendung jedoch die Steuerung des Replikationsstatus implementieren.
Traditionell - Stärken und Schwächen dieses Ansatzes:
- die Fähigkeit, zwischen verschiedenen DBMS zu replizieren, einschließlich des Ladens von Daten in Berichtssysteme;
- die Fähigkeit, Daten zu verarbeiten und zu transformieren, Zustandsüberwachung usw.;
- Minimaler Verkehr zwischen Knoten - Die Plattform schneidet unnötige Daten ab und kann den Verkehr komprimieren.
- vollständige Unabhängigkeit von der Datenbank - sowohl vom Format als auch von den internen Mechanismen.
Die Vorteile dieser Methode sind unbestreitbar, es gibt jedoch zwei sehr schwerwiegende Nachteile:
- Einschränkungen der Anwendungsarchitektur;
- eine riesige Menge an nativem Replikationscode.
Also was ist besser?
Es gibt keine eindeutige Antwort auf diese und viele andere Fragen. Ich hoffe jedoch, dass die folgende Tabelle Ihnen dabei hilft, die richtige Wahl für jede spezifische Aufgabe zu treffen:
| Speicherblockreplikation | Blockieren Sie die Replikation durch den Agenten | Physische Replikation | Logische DBMS-Replikation | CDC |
|
||
|---|---|---|---|---|---|---|---|
| X | X | X/7..X/5 | X/7..X/5 | ≤X/10 | ≤X/10 | ≤X/10 | |
| 5 … | 5 … | 1..10 | 1..10 | 1..2 | 1..2 | 1..2 | |
| + | + | +++ | + | ∅ | ∅ | ∅ | |
| ∅ | ∅ | RO | R/W | R/W | R/W | R/W | |
| - | -
broadcast |
-
broadcast |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
|
| ∅ | ∅ | – | – – | – – – | – – | ∅ | |
| + + + | + + | + + | + + | – | + | – – – | |
| – – | – – | – | – | ∅ | – – – | ∅ | |
| ∅ | + | + + | + + | + + | + + + | + + + |
- , ; .
- , .
- , .
- .
- , , .
- CDC , / .
- .