Aber wie genau funktioniert die Objektverfolgung? Es gibt viele Deep Learning-Lösungen für dieses Problem, und heute möchte ich über eine gemeinsame Lösung und die Mathematik dahinter sprechen.
In diesem Artikel werde ich versuchen, Ihnen in einfachen Worten und Formeln Folgendes zu erzählen:
- YOLO ist ein großartiger Objektdetektor
- Kalman-Filter
- Mahalanobis Entfernung
- Deep SORT
YOLO ist ein großartiger Objektdetektor
Sie müssen sofort eine sehr wichtige Notiz machen, an die Sie sich erinnern müssen - Objekterkennung ist keine Objektverfolgung. Für viele wird dies keine Neuigkeit sein, aber oft verwechseln die Leute diese Konzepte. Mit einfachen Worten:
Objekterkennung ist einfach die Definition von Objekten im Bild / Rahmen. Das heißt, ein Algorithmus oder ein neuronales Netzwerk definiert ein Objekt und zeichnet seine Position und Begrenzungsrahmen (Parameter von Rechtecken um Objekte) auf. Bisher ist nicht von anderen Frames die Rede, und der Algorithmus arbeitet nur mit einem.
Beispiel:
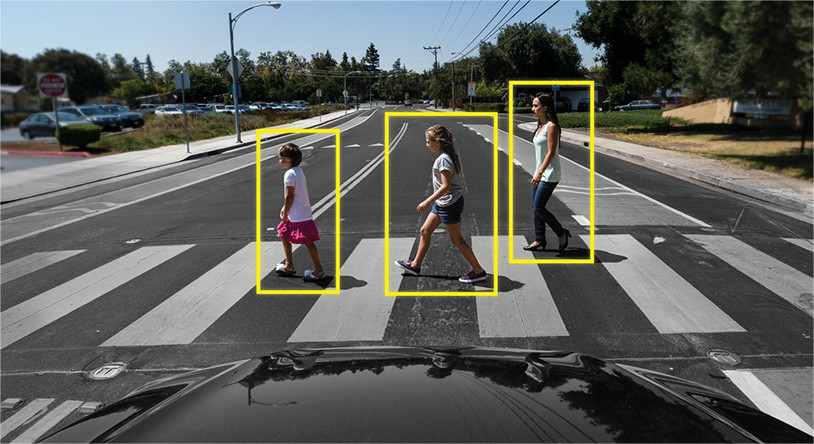
Objektverfolgung ist eine ganz andere Sache. Hier besteht die Aufgabe nicht nur darin, Objekte im Frame zu identifizieren, sondern auch Informationen aus vorherigen Frames so zu verknüpfen, dass das Objekt nicht verloren geht oder einzigartig wird.
Beispiel:

Das heißt, Object Tracker enthält die Objekterkennung zum Bestimmen von Objekten und andere Algorithmen zum Verstehen, welches Objekt in einem neuen Frame zu welchem des vorherigen Frames gehört.
Daher spielt die Objekterkennung eine sehr wichtige Rolle bei der Verfolgungsaufgabe.
Warum YOLO? Ja, da YOLO als effizienter als viele andere Algorithmen zur Identifizierung von Objekten angesehen wird. Hier ist ein kleines Diagramm zum Vergleich der
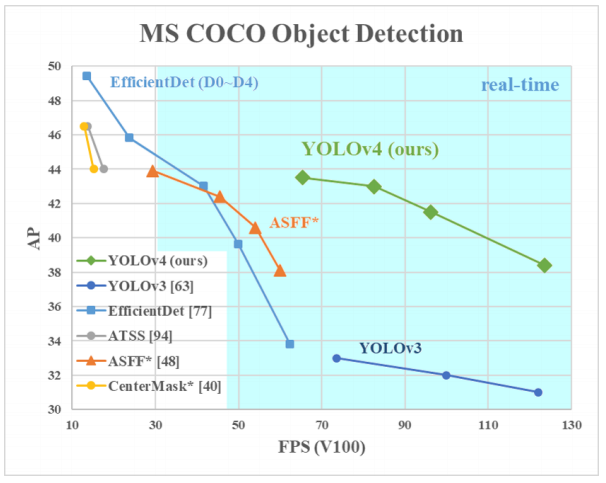
Entwickler von YOLO: Hier sehen wir uns YOLOv3-4 an, da es sich um die neuesten Versionen handelt und effizienter als die vorherigen sind.
Architekturen verschiedener Objektdetektoren
Es gibt also mehrere neuronale Netzwerkarchitekturen, mit denen Objekte definiert werden können. Sie werden im Allgemeinen als "zweistufig" wie RCNN, schnelles RCNN und schnelleres RCNN und "einstufig" wie YOLO kategorisiert.
Die oben aufgeführten "zweistufigen" neuronalen Netze verwenden die sogenannten Regionen im Bild, um zu bestimmen, ob sich ein bestimmtes Objekt in dieser Region befindet.
Normalerweise sieht es so aus (für ein schnelleres RCNN, das das schnellste der beiden aufgeführten Tier-Systeme ist):
- Bild / Rahmen wird dem Eingang zugeführt
- Der Frame wird über CNN ausgeführt, um Feature-Maps zu erstellen
- Ein separates neuronales Netzwerk definiert Regionen mit einer hohen Wahrscheinlichkeit, Objekte in ihnen zu finden
- Dann werden diese Regionen unter Verwendung von RoI-Pooling komprimiert und dem neuronalen Netzwerk zugeführt, das die Klasse des Objekts in den Regionen bestimmt

Diese neuronalen Netze haben jedoch zwei Hauptprobleme: Sie betrachten nicht das gesamte Bild, sondern nur einzelne Regionen und sind relativ langsam.
Was ist so cool an YOLO? Die Tatsache, dass diese Architektur keine zwei Probleme von oben hat, und sie hat wiederholt ihre Wirksamkeit bewiesen.
Im Allgemeinen unterscheidet sich die YOLO-Architektur in den ersten Blöcken in Bezug auf die "Logik der Blöcke" nicht wesentlich von anderen Detektoren, dh ein Bild wird der Eingabe zugeführt, dann werden Feature-Maps mit CNN erstellt (obwohl YOLO sein eigenes CNN namens Darknet-53 verwendet), dann diese Feature-Maps werden auf eine bestimmte Weise analysiert (dazu später mehr), wobei die Positionen und Größen der Begrenzungsrahmen und die Klassen, zu denen sie gehören, angegeben werden.

Aber was sind Hals, dichte Vorhersage und spärliche Vorhersage?
Wir haben uns etwas früher mit Sparse Prediction befasst - es ist nur eine Wiederholung der Funktionsweise von zweistufigen Algorithmen: Sie definieren Regionen einzeln und klassifizieren diese Regionen dann.
Hals (oder "Hals") ist ein separater Block, der erstellt wird, um Informationen aus separaten Ebenen aus den vorherigen Blöcken (wie in der obigen Abbildung gezeigt) zu aggregieren, um die Genauigkeit der Vorhersage zu erhöhen. Wenn Sie daran interessiert sind, können Sie die Begriffe "Path Aggregation Network", "Spatial Attention Module" und "Spatial Pyramid Pooling" googeln.
Und schließlich unterscheidet sich YOLO von allen anderen Architekturen durch einen Block namens (in unserem Bild oben) Dense Prediction. Wir werden uns etwas mehr darauf konzentrieren, da dies eine sehr interessante Lösung ist, die es YOLO gerade ermöglicht hat, in der Effizienz der Objekterkennung führend zu werden.
YOLO (Sie schauen nur einmal) hat die Philosophie, das Bild einmal zu betrachten und für diese eine Betrachtung (dh einen Durchlauf des Bildes durch ein neuronales Netzwerk) alle erforderlichen Objektdefinitionen vorzunehmen. Wie kommt es dazu?
Bei der Ausgabe der Arbeit von YOLO möchten wir normalerweise Folgendes:
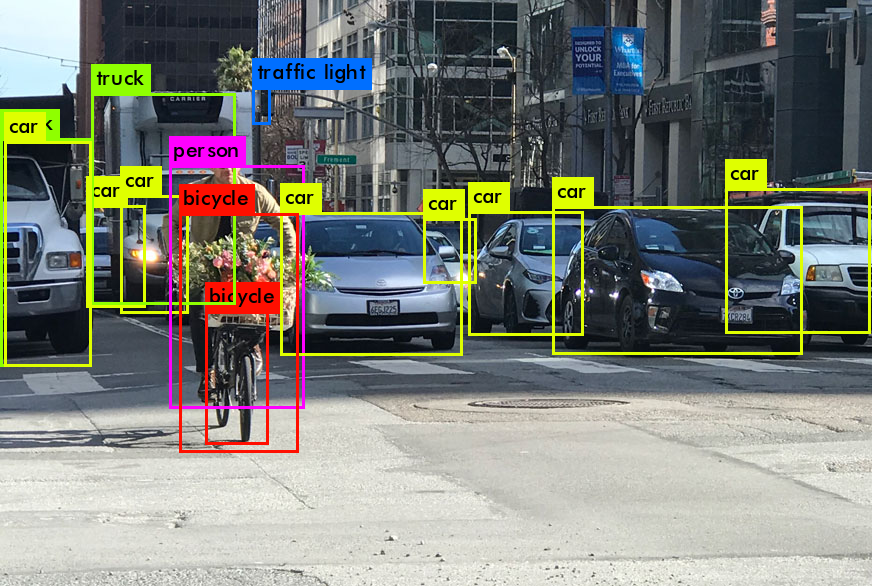
Was macht YOLO, wenn es aus Daten lernt (in einfachen Worten):
Schritt 1: Normalerweise werden die Bilder vor dem Training des neuronalen Netzwerks auf eine Größe von 416 x 416 umgeformt, damit sie stapelweise eingespeist werden können (um das Lernen zu beschleunigen) ).
Schritt 2: Teilen Sie das Bild (vorerst mental) in Zellen der Größe a x a . In YOLOv3-4 ist es üblich, sich in Zellen mit einer Größe von 13 x 13 zu teilen (wir werden etwas später über verschiedene Maßstäbe sprechen, um dies klarer zu machen).

Konzentrieren wir uns nun auf diese Zellen, in die wir das Bild / den Rahmen unterteilt haben. Solche Zellen, sogenannte Gitterzellen, sind das Herzstück der YOLO-Idee. Jede Zelle ist ein "Anker", an dem Begrenzungsrahmen angebracht sind. Das heißt, mehrere Rechtecke werden um die Zelle herum gezeichnet, um das Objekt zu definieren (da nicht klar ist, welche Form das Rechteck am besten geeignet ist, werden sie gleichzeitig in mehreren und unterschiedlichen Formen gezeichnet), und ihre Positionen, Breite und Höhe werden relativ zur Mitte dieser Zelle berechnet.
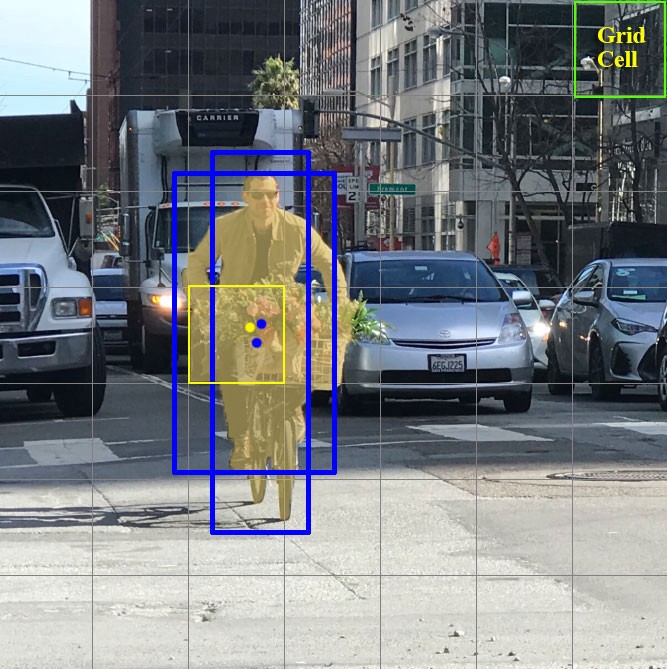
Wie werden diese Begrenzungsrahmen um den Käfig gezogen? Wie wird ihre Größe und Position bestimmt? Hier kommt die Technik der Ankerboxen (in der Übersetzung - Ankerboxen oder "Ankerrechtecke") ins Spiel. Sie werden ganz am Anfang entweder vom Benutzer selbst festgelegt oder ihre Größe wird basierend auf den Größen der Begrenzungsrahmen bestimmt, die sich in dem Datensatz befinden, auf dem YOLO trainiert (K-Mittel-Clustering und IoU werden verwendet, um die am besten geeigneten Größen zu bestimmen). Normalerweise gibt es 3 verschiedene Ankerkästen, die um (oder innerhalb) einer Zelle gezeichnet werden:

Warum wird das gemacht? Es wird jetzt klar, wenn wir diskutieren, wie YOLO lernt.
Schritt 3. Das Bild aus dem Datensatz wird durch unser neuronales Netzwerk ausgeführt (beachten Sie, dass zusätzlich zum Bild im Trainingsdatensatz die Positionen und Größen der realen Begrenzungsrahmen für die Objekte darauf angegeben sein müssen. Dies wird als "Anmerkung" bezeichnet und erfolgt meist manuell ).
Lassen Sie uns nun darüber nachdenken, was wir am Ausgang brauchen.
Für jede Zelle müssen wir zwei grundlegende Dinge verstehen:
- Welche der 3 um den Käfig gezogenen Ankerkästen passt am besten zu uns und wie können wir sie ein wenig optimieren, damit sie gut zum Objekt passt
- Welches Objekt befindet sich in dieser Ankerkiste und ist es überhaupt dort?
Was soll dann die Ausgabe von YOLO sein?
1. An der Ausgabe für jede Zelle möchten wir erhalten:

2. Die Ausgabe sollte die folgenden Parameter enthalten:
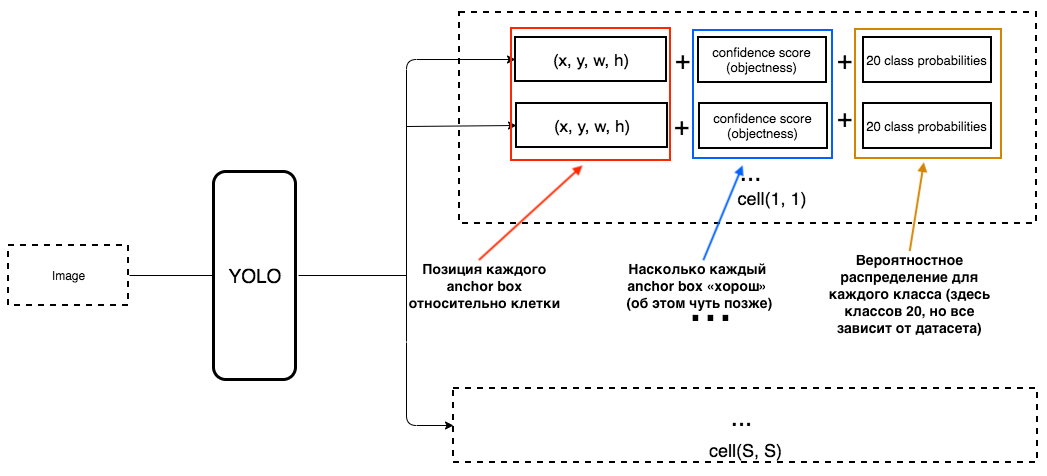
Wie wird die Objektivität bestimmt? Tatsächlich wird dieser Parameter während des Trainings unter Verwendung der IoU-Metrik bestimmt. Die IoU-Metrik funktioniert folgendermaßen:
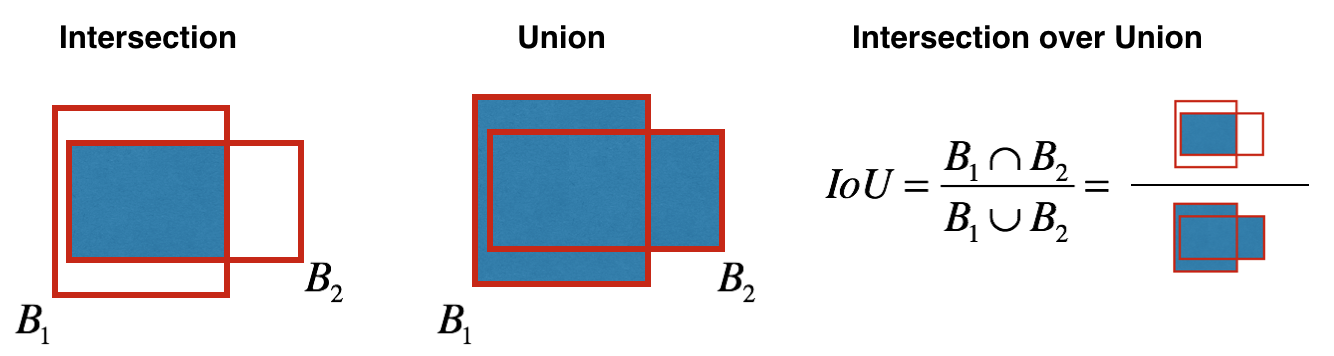
Zu Beginn können Sie einen Schwellenwert für diese Metrik festlegen. Wenn Ihr vorhergesagter Begrenzungsrahmen über diesem Schwellenwert liegt, hat er eine Objektivität von eins, und alle anderen Begrenzungsrahmen mit geringerer Objektivität werden ausgeschlossen. Wir benötigen diesen Wert der Objektivität, wenn wir die Gesamtvertrauensbewertung (inwieweit wir sicher sind, dass sich das benötigte Objekt innerhalb des vorhergesagten Rechtecks befindet) für jedes bestimmte Objekt berechnen.
Und jetzt beginnt der Spaß. Stellen wir uns vor, wir sind die Schöpfer von YOLO und wir müssen sie trainieren, um Menschen im Rahmen / Bild zu erkennen. Wir geben das Bild aus dem Datensatz an YOLO weiter, wo zu Beginn eine Merkmalsextraktion erfolgt, und am Ende erhalten wir eine CNN-Ebene, die uns über alle Zellen informiert, in die wir unser Bild "unterteilt" haben. Und wenn diese Schicht uns eine "Lüge" über die Zellen im Bild erzählt, müssen wir einen großen Verlust haben, damit er später reduziert werden kann, wenn die folgenden Bilder in das neuronale Netzwerk eingespeist werden.
Um es klar auszudrücken, gibt es ein sehr einfaches Diagramm, wie YOLO diese letzte Ebene erstellt:
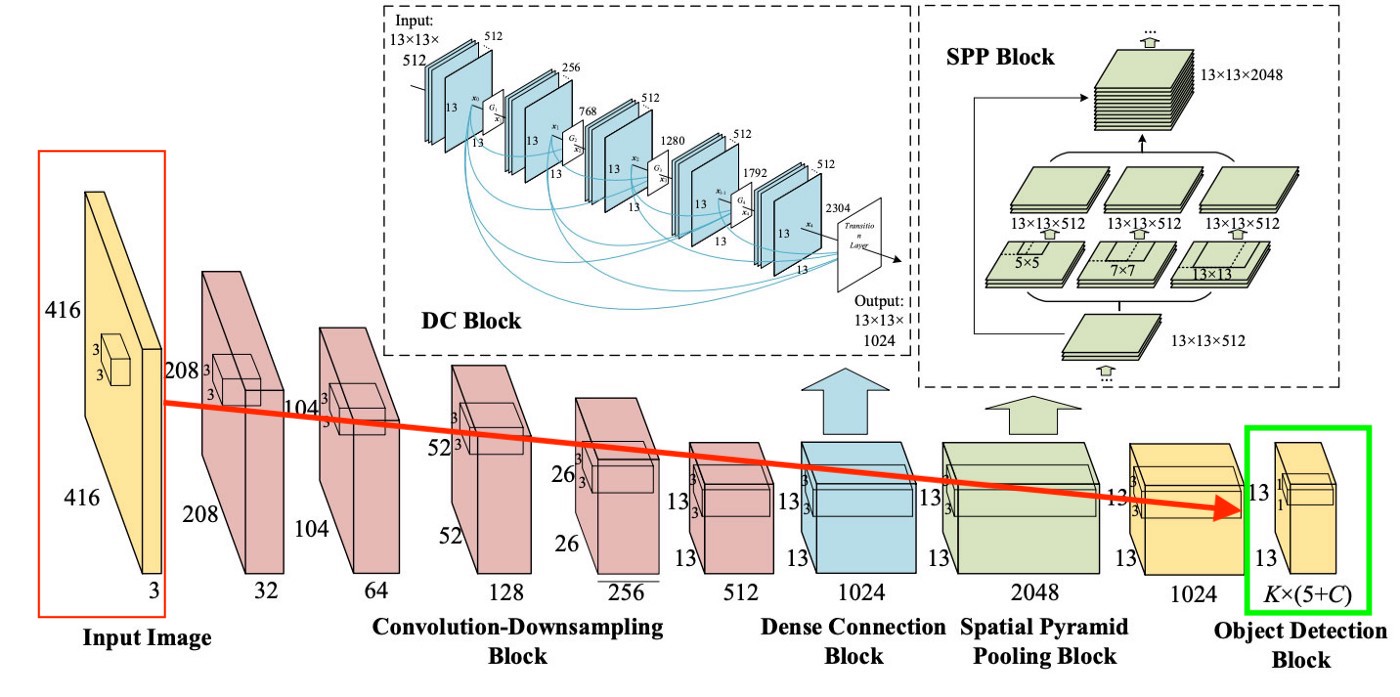
Wie wir auf dem Bild sehen können, ist diese Ebene 13 x 13 (für Bilder beträgt die Originalgröße 416 x 416), um über "jede Zelle" im Bild zu sprechen. Aus dieser letzten Schicht werden die gewünschten Informationen erhalten.
YOLO sagt 5 Parameter voraus (für jede Ankerbox für eine bestimmte Zelle):

Zum besseren Verständnis gibt es eine gute Visualisierung zu diesem Thema:

Wie Sie aus diesem Bild ersehen können, besteht die Aufgabe von YOLO darin, diese Parameter so genau wie möglich vorherzusagen, um das Objekt im Bild so genau wie möglich zu bestimmen. Und der Konfidenzwert, der für jeden vorhergesagten Begrenzungsrahmen bestimmt wird, ist eine Art Filter, um völlig ungenaue Vorhersagen herauszufiltern. Für jeden vorhergesagten Begrenzungsrahmen multiplizieren wir seine IoU mit der Wahrscheinlichkeit, dass dies ein bestimmtes Objekt ist (die Wahrscheinlichkeitsverteilung wird während des Trainings des neuronalen Netzwerks berechnet), nehmen die bestmögliche Wahrscheinlichkeit und wenn die Zahl nach der Multiplikation einen bestimmten Schwellenwert überschreitet, können wir diesen vorhergesagten belassen Begrenzungsrahmen im Bild.
Wenn wir nur Begrenzungsrahmen mit einem hohen Konfidenzwert vorhergesagt haben, sehen unsere Vorhersagen (falls visualisiert) möglicherweise folgendermaßen aus:

Wir können jetzt die NMS-Technik (Non-Max Suppression) verwenden, um Begrenzungsrahmen so herauszufiltern, dass z Von einem Objekt gab es nur einen vorhergesagten Begrenzungsrahmen.

Sie sollten auch wissen, dass YOLOv3-4 auf 3 verschiedenen Skalen vorhergesagt wird. Das heißt, das Bild ist in 64 Gitterzellen, 256 Zellen und 1024 Zellen unterteilt, um auch kleine Objekte zu sehen. Für jede Gruppe von Zellen wiederholt der Algorithmus die erforderlichen Aktionen während der Vorhersage / des Lernens, die oben beschrieben wurden.
In YOLOv4 wurden viele Techniken verwendet, um die Modellgenauigkeit zu erhöhen, ohne zu viel Geschwindigkeit zu verlieren. Für die Vorhersage selbst wurde die dichte Vorhersage jedoch wie in YOLOv3 belassen. Wenn Sie daran interessiert sind, was die Autoren auf magische Weise getan haben, um die Genauigkeit zu erhöhen, ohne an Geschwindigkeit zu verlieren, gibt es einen ausgezeichneten Artikel über YOLOv4 .
Ich hoffe, ich konnte ein wenig darüber vermitteln, wie YOLO im Allgemeinen funktioniert (genauer gesagt, die letzten beiden Versionen, dh YOLOv3 und YOLOv4), und dies wird Sie dazu bringen, dieses Modell in Zukunft zu verwenden oder etwas mehr über seine Arbeit zu erfahren.
Nachdem wir herausgefunden haben, welches das vielleicht beste neuronale Netzwerk für die Objekterkennung ist (in Bezug auf Geschwindigkeit / Qualität), gehen wir nun dazu über, wie wir Informationen über unsere spezifischen YOLO-Objekte zwischen Videobildern zuordnen können. Wie kann das Programm verstehen, dass die Person im vorherigen Frame dieselbe Person ist wie im neuen?
Deep SORT
Um diese Technologie zu verstehen, müssen Sie zunächst einige mathematische Aspekte verstehen - Mahalonobis-Abstand und Kalman-Filter.
Mahalonobis-Abstand Schauen
wir uns ein sehr einfaches Beispiel an, um intuitiv zu verstehen, wie groß der Maholonobis-Abstand ist und warum er benötigt wird. Viele Menschen wissen wahrscheinlich, wie groß die euklidische Entfernung ist. Normalerweise ist dies die Entfernung von einem Punkt zum anderen im euklidischen Raum:
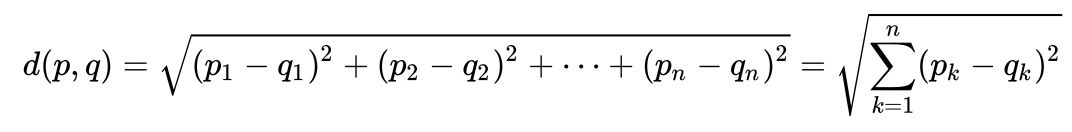

Nehmen wir an, wir haben zwei Variablen - X1 und X2. Für jeden von ihnen haben wir viele Dimensionen.
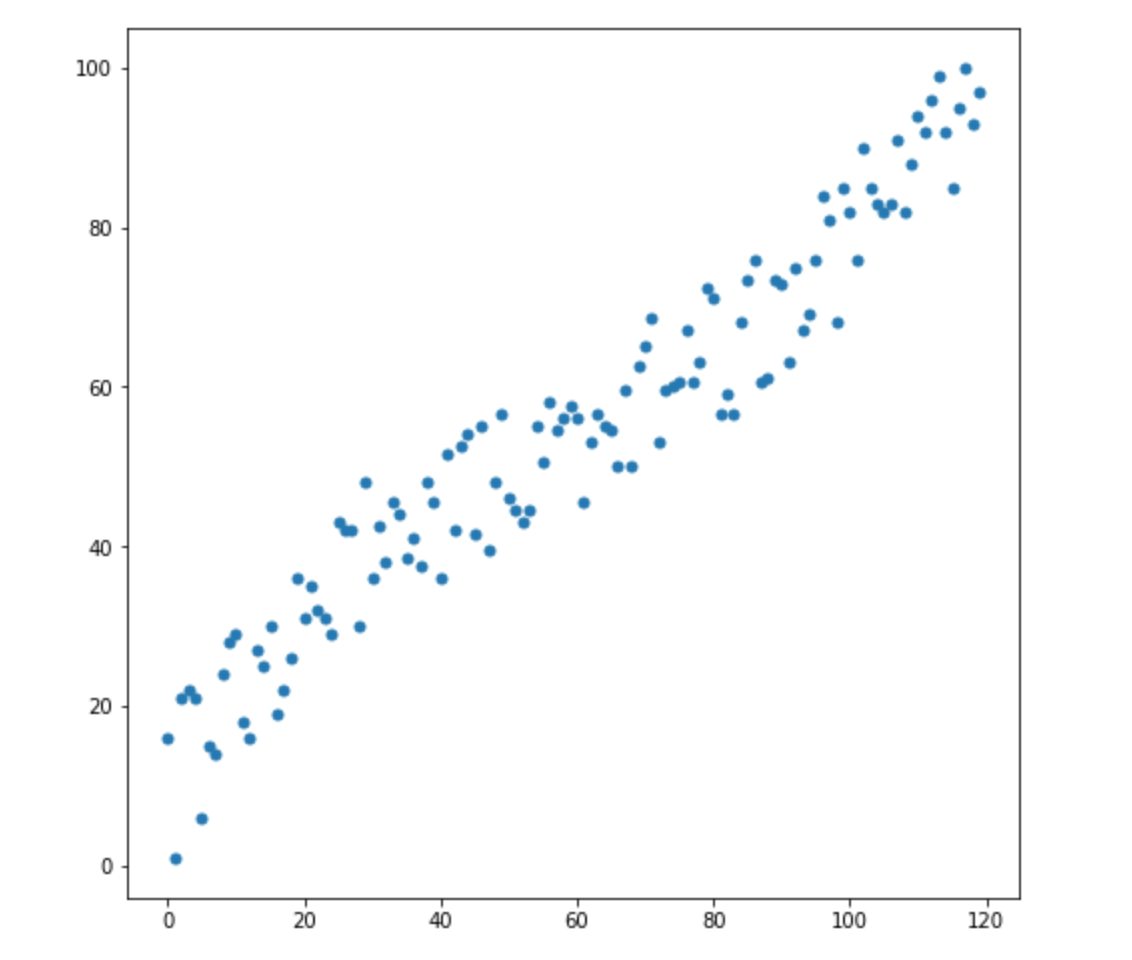
Nehmen wir an, wir haben zwei neue Dimensionen:
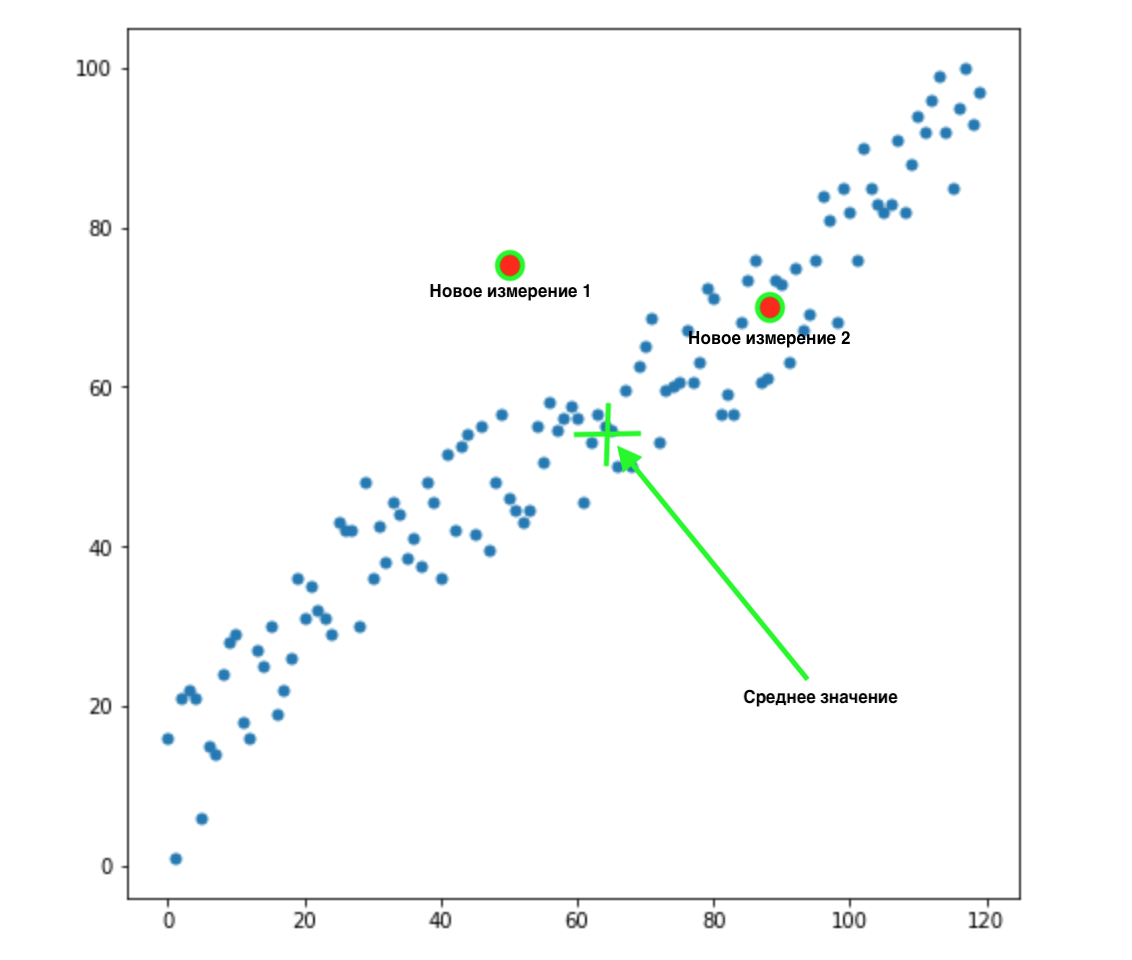
Woher wissen wir, welcher dieser beiden Werte für unsere Verteilung am besten geeignet ist? Für das Auge ist alles klar - Punkt 2 passt zu uns. Der euklidische Abstand zum Mittelwert ist jedoch für beide Punkte gleich. Dementsprechend wird eine einfache euklidische Entfernung zum Mittelwert für uns nicht funktionieren.
Wie wir aus dem obigen Bild sehen können, sind die Variablen miteinander korreliert und ziemlich stark. Wenn sie nicht miteinander korrelierten oder viel weniger korrelierten, konnten wir unsere Augen schließen und für bestimmte Aufgaben die euklidische Distanz anwenden, aber hier müssen wir die Korrelation korrigieren und berücksichtigen.
Genau damit kann die Mahalonobis-Distanz umgehen. Da Datensätze normalerweise mehr als zwei Variablen enthalten, verwenden wir anstelle der Korrelation eine Kovarianzmatrix:
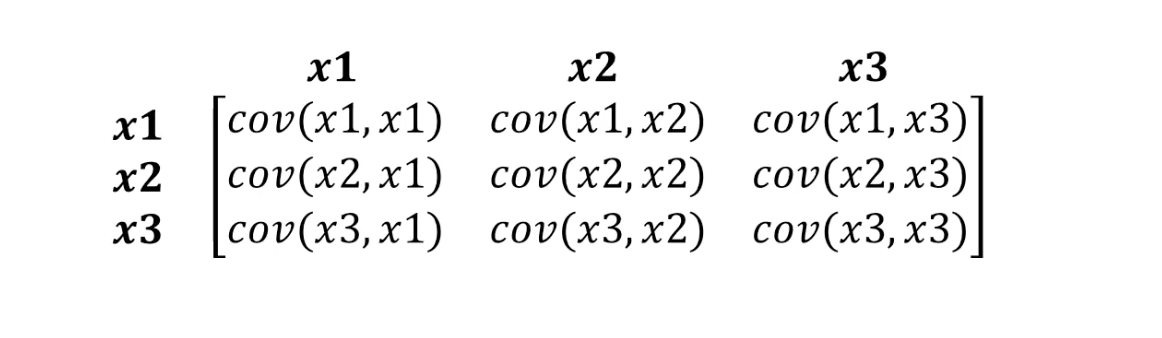
Was Mahalonobis Distanz tatsächlich bewirkt:
- Befreien Sie sich von variabler Kovarianz
- Macht die Varianz von Variablen gleich 1
- Dann wird der übliche euklidische Abstand für die transformierten Daten verwendet.
Schauen wir uns die Formel an, wie der Mahalonobis-Abstand berechnet wird: Mal

sehen, was die Komponenten unserer Formel bedeuten:
- Dieser Unterschied ist der Unterschied zwischen unserem neuen Punkt und den Mitteln für jede Variable
- S ist die Kovarianzmatrix, über die wir etwas früher gesprochen haben.
Eine sehr wichtige Sache kann aus der Formel verstanden werden. Wir multiplizieren tatsächlich mit der invertierten Kovarianzmatrix. In diesem Fall ist es umso wahrscheinlicher, dass wir den Abstand verkürzen, je höher die Korrelation zwischen den Variablen ist, da wir mit der Umkehrung der größeren multiplizieren - dh der kleineren Zahl (wenn in einfachen Worten).
Wir werden wahrscheinlich nicht auf die Details der linearen Algebra eingehen. Alles, was wir verstehen müssen, ist, dass wir den Abstand zwischen Punkten so messen, dass die Varianz unserer Variablen und die Kovarianz zwischen ihnen berücksichtigt werden.
Kalman Filter
Um zu erkennen, dass dies eine coole, bewährte Sache ist, die in so vielen Bereichen angewendet werden kann, reicht es zu wissen, dass der Kalman-Filter in den 1960er Jahren verwendet wurde. Ja, ja, ich weise darauf hin - den Flug zum Mond. Es wurde dort an mehreren Stellen angewendet, einschließlich der Arbeit mit Hin- und Rückflugwegen. Der Kalman-Filter wird auch häufig bei der Zeitreihenanalyse auf den Finanzmärkten sowie bei der Analyse von Indikatoren verschiedener Sensoren in Fabriken, Unternehmen und vielen anderen Orten verwendet. Ich hoffe, ich habe es geschafft, Sie ein wenig zu faszinieren, und wir werden den Kalman-Filter und seine Funktionsweise kurz beschreiben. Ich rate Ihnen auch, diesen Artikel über Habré zu lesen, wenn Sie mehr darüber erfahren möchten.
Kalman Filter
, . , , .
, . 4 . , 72 .
3 :
1) (Kalman Gain):

, - ( ).
2) , ( , ), , .

3) (), :
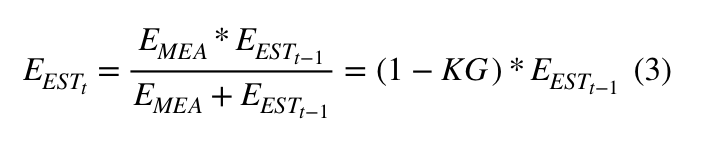
, :
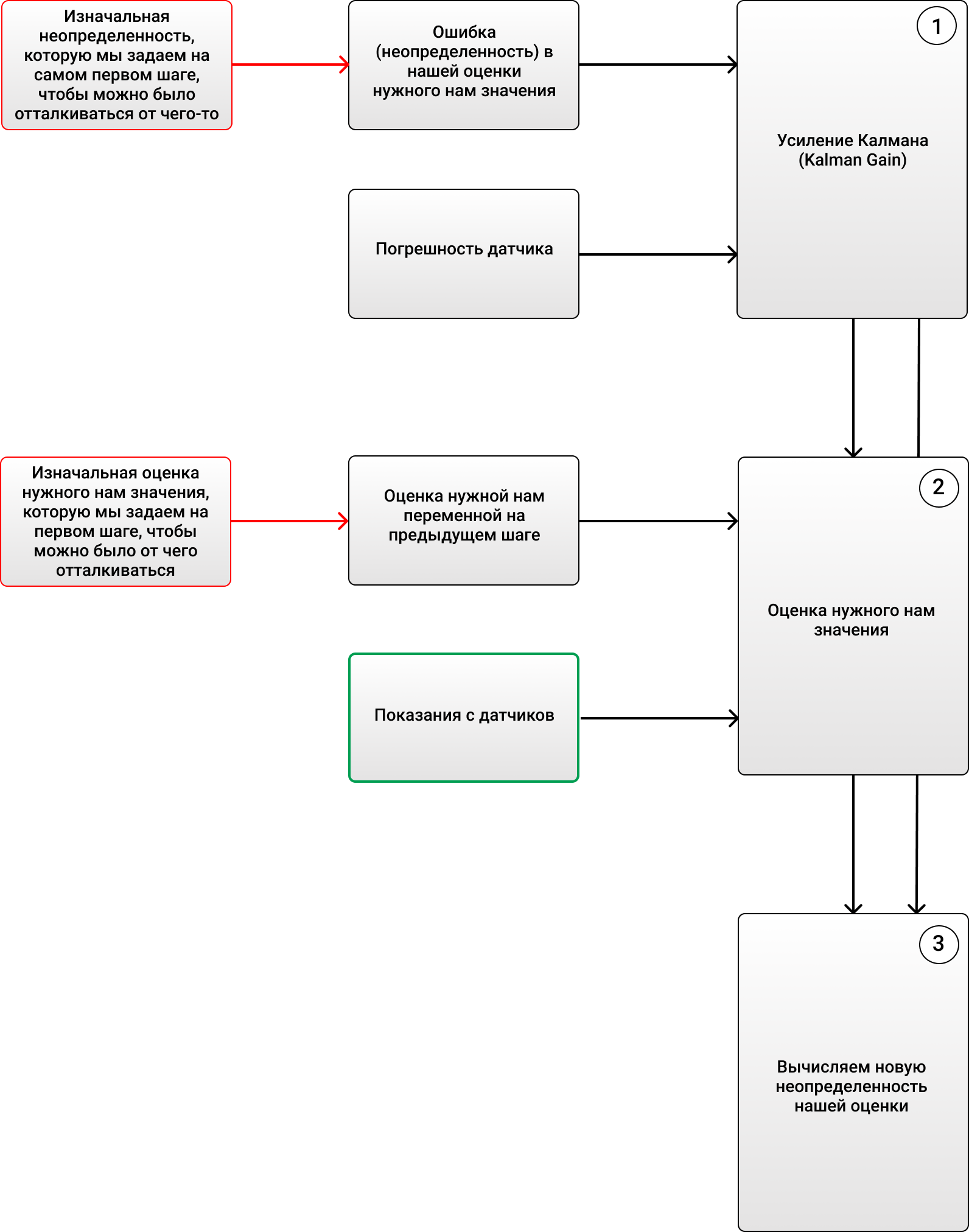
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
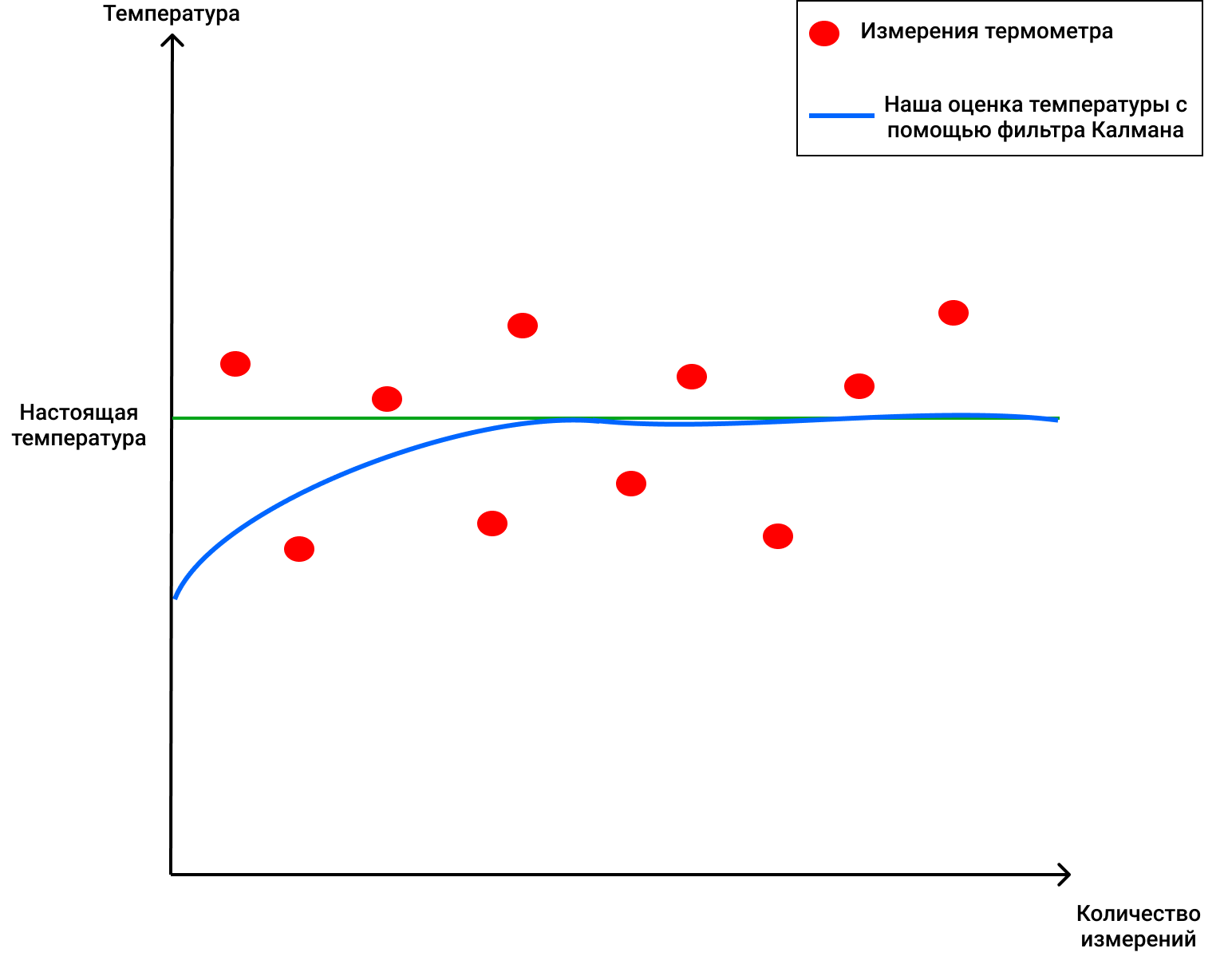
, !
, , , , , ( , ).
, . 4 . , 72 .
3 :
1) (Kalman Gain):
, - ( ).
2) , ( , ), , .
3) (), :
, :
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
, !
, , , , , ( , ).
DeepSORT - endlich!
Jetzt wissen wir also, wie hoch der Kalman-Filter und die Mahalonobis-Entfernung sind. Die DeepSORT-Technologie verknüpft diese beiden Konzepte einfach miteinander, um Informationen von einem Frame in einen anderen zu übertragen, und fügt eine neue Metrik hinzu, die als Erscheinungsbild bezeichnet wird. Zunächst werden mithilfe der Objekterkennung Position, Größe und Klasse eines Begrenzungsrahmens bestimmt. Dann können Sie im Prinzip den ungarischen Algorithmus anwenden, um bestimmte Objekte mit Objekt-IDs zu verknüpfen, die zuvor im Frame waren und mithilfe von Kalman-Filtern verfolgt wurden - und alles wird super, wie im ursprünglichen SORT... Die DeepSORT-Technologie ermöglicht es jedoch, die Erkennungsgenauigkeit zu verbessern und die Anzahl der Umschaltungen zwischen Objekten zu verringern, wenn beispielsweise eine Person im Rahmen eine andere Person kurz behindert und nun die Person, die behindert wurde, als neues Objekt betrachtet wird. Wie macht sie das?
Sie fügt ihrer Arbeit ein cooles Element hinzu - das sogenannte "Erscheinungsbild" von Menschen, die im Rahmen erscheinen (Erscheinungsbild). Dieses Erscheinungsbild wurde von einem separaten neuronalen Netzwerk trainiert, das von den Autoren von DeepSORT erstellt wurde. Sie verwendeten ungefähr 1.100.000 Bilder von über 1000 verschiedenen Personen, um das neuronale Netzwerk korrekt vorherzusagenDie ursprüngliche SORT hat ein Problem - da das Erscheinungsbild des Objekts dort nicht verwendet wird, weist der Algorithmus dieser Person eine andere ID zu, wenn das Objekt mehrere Frames abdeckt (z. B. eine andere Person oder eine Spalte innerhalb eines Gebäudes) wobei das sogenannte "Gedächtnis" von Objekten in der ursprünglichen SORT eher kurzlebig ist.
Jetzt haben Objekte zwei Eigenschaften - ihre Bewegungsdynamik und ihr Aussehen. Für die Dynamik haben wir Indikatoren, die mit dem Kalman-Filter gefiltert und vorhergesagt werden - (u, v, a, h, u ', v', a ', h'), wobei u, v die X-Position des vorhergesagten Rechtecks ist und Y, a ist das Seitenverhältnis des vorhergesagten Rechtecks, h ist die Höhe des Rechtecks und die Ableitungen in Bezug auf jeden Wert. Für das Aussehen wurde ein neuronales Netzwerk trainiert, das die Struktur hatte:
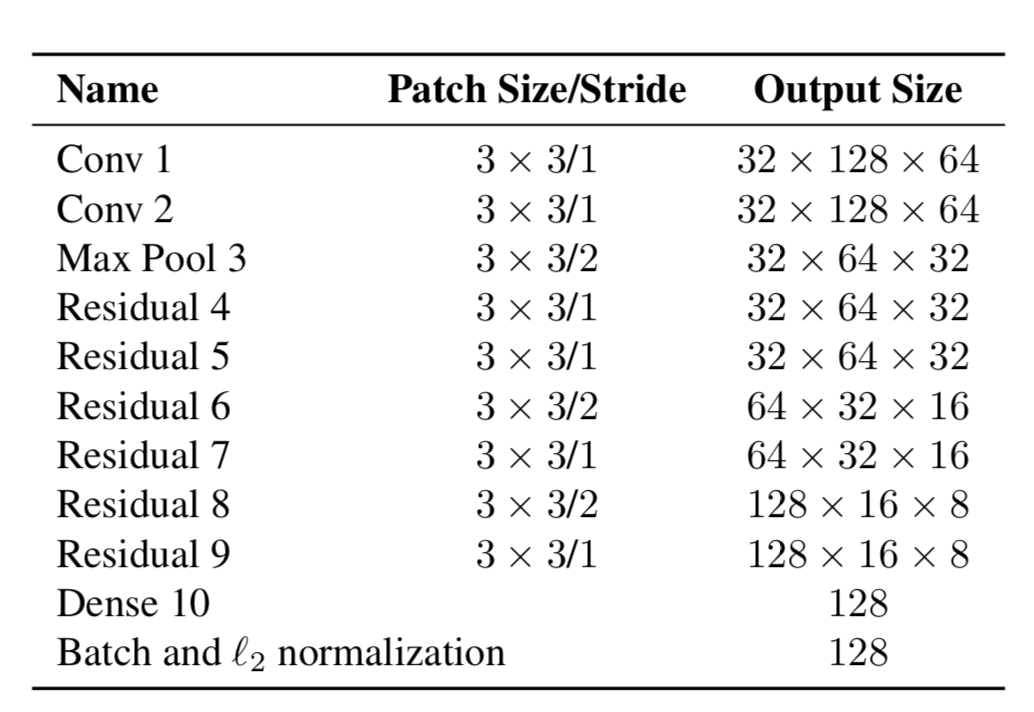
Am Ende wurde ein Merkmalsvektor mit einer Größe von 128 x 1 erzeugt. Anstatt den Abstand zwischen bestimmten Objekten mit YOLO und Objekten, denen wir bereits im Frame gefolgt sind, zu berechnen und dann eine bestimmte ID einfach mit dem Mahalonobis-Abstand zuzuweisen, erstellten die Autoren eine neue Metrik zur Berechnung des Abstands, einschließlich beide Vorhersagen unter Verwendung von Kalman-Filtern und "Cosinus-Abstand", wie es anders genannt wird, der Otiai-Koeffizient.
Infolgedessen beträgt der Abstand zwischen einem bestimmten YOLO-Objekt und dem vom Kalman-Filter vorhergesagten Objekt (oder einem Objekt, das bereits zu den in den vorherigen Frames beobachteten Objekten gehört):

Wobei Da der äußere Ähnlichkeitsabstand und Dk der Mahalonobis-Abstand ist. Ferner wird diese hybride Entfernung im ungarischen Algorithmus verwendet, um bestimmte Objekte mit vorhandenen IDs korrekt zu sortieren.
Daher hat eine einfache zusätzliche Metrik Da dazu beigetragen, einen neuen, eleganten DeepSORT-Algorithmus zu erstellen, der bei vielen Problemen verwendet wird und beim Objektverfolgungsproblem sehr beliebt ist.
Der Artikel erwies sich als ziemlich gewichtig, danke an diejenigen, die bis zum Ende gelesen haben! Ich hoffe, ich konnte Ihnen etwas Neues erzählen und Ihnen helfen, die Funktionsweise von Object Tracking auf YOLO und DeepSORT zu verstehen.