
Ich war schon immer fasziniert von Systemausfällen und den Kuriositäten ihres Verhaltens, insbesondere wenn sie unter normalen Bedingungen arbeiten. Ich habe kürzlich eine der Präsentationsfolien von Ian Goodfellow gesehen, die ich sehr lustig fand. Ein zufälliges visuelles Rauschen wurde einem trainierten neuronalen Netzwerk zugeführt, und sie erkannte es als eines der Objekte, die sie kannte. Hier stellen sich sofort viele Fragen. Werden verschiedene trainierte neuronale Netze dasselbe Objekt sehen? Was ist das maximale Maß an Vertrauen in das neuronale Netzwerk, dass dieses zufällige Rauschen tatsächlich ein erkanntes Objekt ist? Und was "sieht" das neuronale Netz dort eigentlich?
Aus meiner Neugier heraus wurde dieser Eintrag geboren. Glücklicherweise sind solche Experimente mit PyTorch sehr einfach durchzuführen.... Um zu veranschaulichen, warum das neuronale Netzwerk Objekte auf bestimmte Weise klassifiziert, verwende ich das Interpretierbarkeits- Framework des Captum- Modells . Der Code kann von Github heruntergeladen werden .
Bedeutung von Fragen
Sie können fragen, warum diese Fragen wichtig sind. In vielen Fällen erstellen Entwickler Modelle nicht von Grund auf neu. Sie wählen Plattformen und vorgefertigte Netzwerke aus dem Modellzoo als Ausgangspunkte. Dies spart Zeit - Sie müssen keine Daten sammeln und das neuronale Netzwerk erstmalig trainieren. Dies bedeutet jedoch auch, dass an unerwarteten Orten unerwartete Probleme auftreten können. Je nachdem, wie dieses Modell verwendet wird, können dabei Sicherheitsprobleme auftreten.
Vorgebildete Modelle
Vorgefertigte Modelle sind einfach zu handhaben und können schnell Daten zur Klassifizierung einreichen. In diesem Fall müssen Sie keine Modelle definieren und trainieren - all dies wurde bereits vor Ihnen durchgeführt und sie können sofort nach der Bereitstellung verwendet werden. Vorgefertigte Modelle aus der Torchvision-Bibliothek werden anhand einer Reihe von Bildern aus der Imagenet- Datenbank trainiert , die in 1000 Kategorien unterteilt sind... Es ist wichtig, sich daran zu erinnern, dass diese Schulung das Identifizieren eines einzelnen Objekts in einem Bild und nicht das Parsen komplexer Bilder mit verschiedenen Objekten beinhaltete. Im zweiten Fall können Sie ebenfalls interessante Ergebnisse erzielen, dies ist jedoch ein völlig anderes Thema. Das Herunterladen von vorgefertigten Modellen aus der Torchvision-Bibliothek ist sehr einfach. Sie müssen nur das ausgewählte Modell importieren, indem Sie den vorab trainierten Parameter auf True setzen. Ich habe auch einen Bewertungsmodus in die Modelle aufgenommen, da es während der Tests keine Lernkurve gibt.
Zuerst habe ich eine Codezeile, die cuda oder cpu verwendet, je nachdem, ob eine GPU verfügbar ist. Für solch einfache Tests ist keine GPU erforderlich, aber da ich eine habe, verwende ich sie.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Eine Liste der vorgefertigten Modelle von Torchvision finden Sie hier . Ich wollte nicht alle vorab trainierten neuronalen Netze verwenden, das ist schon zu viel. Ich habe die folgenden fünf ausgewählt:
- vgg16
- resnet18
- alexnet
- Densenet
- Anfang
Ich habe keine spezielle Methode zur Auswahl neuronaler Netze verwendet. Beispielsweise werden Vgg16 und Inception häufig in verschiedenen Beispielen verwendet, und sie sind alle unterschiedlich.
So erstellen Sie Bilder mit Rauschen
Wir brauchen eine Möglichkeit, automatisch Bilder zu erzeugen, die Rauschen enthalten und in neuronale Netze eingespeist werden können. Zu diesem Zweck habe ich eine Kombination aus den Bibliotheken Numpy und PIL verwendet und eine kleine Funktion geschrieben, die ein mit zufälligem Rauschen gefülltes Bild zurückgibt.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
Am Ende haben Sie ungefähr Folgendes:

Bilder konvertieren
Danach müssen wir unsere Bilder in Tensor konvertieren und normalisieren. Der folgende Code kann nicht nur für zufälliges Rauschen verwendet werden, sondern auch für jedes Bild, das vorab trainierten neuronalen Netzen zugeführt werden soll (aus diesem Grund verwendet der Code die Werte Resize und CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageWir bekommen Vorhersagen
Nachdem die transformierten Bilder vorbereitet wurden, ist es einfach, Vorhersagen aus dem entfalteten Modell zu erhalten. In diesem Fall wird angenommen, dass die Funktion xform_image image_xform zurückgibt. In dem Code, den ich zum Testen verwendet habe, habe ich die Arbeit zwischen diesen beiden Funktionen aufgeteilt, aber hier habe ich sie zur leichteren Bezugnahme zusammengestellt. Wir müssen das transformierte Bild im Wesentlichen dem Netzwerk zuführen, die Softmax-Funktion ausführen, die Topk-Funktion verwenden, um die Punktzahl und die vorhergesagte Label-ID zu erhalten, um das beste Ergebnis zu erzielen.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
Ergebnisse
Nun sehen wir, wie man verrauschte Bilder erzeugt und sie einem vorab trainierten Netzwerk zuführt. Was sind die Ergebnisse? Für diesen Test habe ich beschlossen, 1000 verrauschte Bilder zu generieren, sie durch 5 ausgewählte vorab trainierte Netzwerke zu führen und sie zur schnellen Analyse in einen Pandas- Datenrahmen zu stopfen . Die Ergebnisse waren interessant und etwas unerwartet.
| vgg16 | resnet18 | alexnet | Densenet | Anfang | |
|---|---|---|---|---|---|
| Anzahl | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| bedeuten | 0,226978 | 0,328249 | 0,147289 | 0,409413 | 0,020204 |
| std | 0,067972 | 0,071808 | 0,038628 | 0,148315 | 0,016490 |
| Mindest | 0,074922 | 0,127953 | 0,061019 | 0,139161 | 0,005963 |
| 25% | 0,178240 | 0,278830 | 0,120568 | 0,291042 | 0,011641 |
| 50% | 0,223623 | 0,324111 | 0,143090 | 0,387705 | 0,015880 |
| 75% | 0,270547 | 0,373325 | 0,171139 | 0,511357 | 0,022519 |
| max | 0,438011 | 0,580559 | 0,328568 | 0,868025 | 0,198698 |
Wie Sie sehen können, haben einige der neuronalen Netze entschieden, dass dieses Rauschen tatsächlich etwas mit einem ziemlich hohen Maß an Vertrauen darstellt. Resnet18 und Densenet erreichten beide einen Höchstwert von 50%. Das ist alles schön und gut, aber was genau "sehen" diese Netzwerke im Rauschen? Interessanterweise "fanden" verschiedene Netzwerke dort unterschiedliche Objekte. Jedes der Netzwerke sah etwas anderes. Resnet18 war sich zu 100% sicher, dass es sich um eine Qualle handelte, während Inception im Gegenteil nur sehr wenig Vertrauen in Vorhersagen hatte, obwohl sie gleichzeitig viel mehr Objekte als jedes andere Netzwerk sah.
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Nur zum Spaß habe ich mich entschlossen zu sehen, welche Art von Signatur Microsoft unter das Rauschbild setzen wird, das ich dem Anfang dieses Eintrags näher gebracht habe. Für den Test habe ich mich für den einfachsten Weg entschieden und PowerPoint aus Office 365 verwendet. Das Ergebnis ist interessant, da PowerPoint im Gegensatz zu Imagenet-Modellen, die versuchen, ein einzelnes Objekt zu erkennen, versucht, mehrere Objekte zu erkennen, um eine genaue Beschreibung des Bildes zu erstellen.
Das Bild zeigt einen Elefanten, Menschen, groß, Ball.
Das Ergebnis hat mich nicht enttäuscht. Aus meiner Sicht wurde das Bild des Geräusches als Zirkus erkannt.
Perspektiven
Dies führt uns zu einer anderen Frage: Was sieht das neuronale Netzwerk, das den Eindruck erweckt, dass Rauschen ein Objekt ist? Bei der Suche nach einer Antwort können wir ein Modellinterpretationswerkzeug verwenden, mit dem wir grob verstehen können, was das Netzwerk "sieht". Captum ist ein Modellinterpretationsframework für PyTorch. Ich habe hier nichts Besonderes gemacht, ich habe nur den Code aus den Tutorials auf ihrer Website verwendet. Ich habe gerade den Parameter internal_batch_size mit dem Wert 50 hinzugefügt, da meine GPU ohne ihn sehr schnell keinen Speicher mehr hat.
Für die Visualisierungen habe ich zwei gradientenbasierte Attributionen und eine okklusionsbasierte Attribution verwendet. Mit diesen Visualisierungen versuchen wir zu verstehen, was für den Klassifikator wichtig war, und „sehen“, was das Netzwerk sieht. Ich habe auch mein vorab trainiertes Resnet-Modell verwendet. Sie können jedoch den Code ändern und andere vorab trainierte Modelle verwenden.
Bevor ich mich dem Rauschen zuwandte, nahm ich das Bild der Kamille als Demonstration des Renderprozesses, da seine Zeichen leicht zu erkennen sind.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)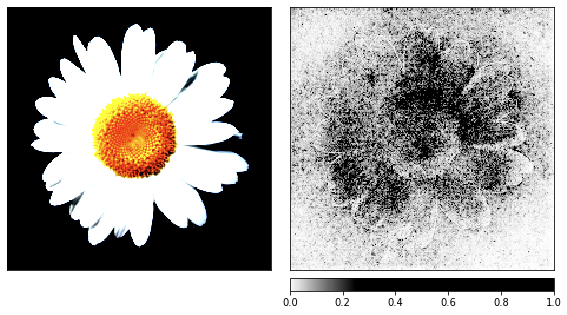
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

Rauschvisualisierung
Wir haben die vorherigen Bilder basierend auf der Kamille generiert, und jetzt ist es Zeit zu sehen, wie die Dinge mit zufälligem Rauschen funktionieren.
Ich benutze das vorgefertigte resnet18-Netzwerk und mit diesem Bild ist sie zu 40% sicher, dass sie eine Qualle sieht. Ich werde den Code nicht wiederholen, der Code zum Rendern ist der gleiche wie der oben angegebene.


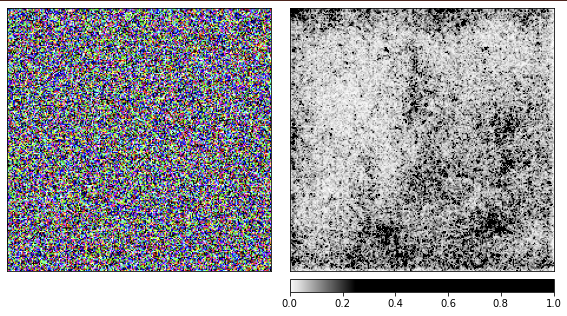

Aus den Visualisierungen geht hervor, dass wir Menschen niemals verstehen werden, warum das Netzwerk hier eine Qualle sieht. Einige Bereiche des Bildes sind als wichtiger markiert, aber sie sind überhaupt nicht so definiert, wie wir es im Beispiel der Kamille gesehen haben. Im Gegensatz zur Kamille sind Quallen amorph und unterscheiden sich in der Transparenz.
Sie fragen sich vielleicht, wie das Rendern der Verarbeitung eines echten Bildes einer Qualle aussehen würde? Mein Code ist auf Github veröffentlicht und es wird einfach sein, mit seiner Hilfe eine Antwort auf diese Frage zu erhalten.
Fazit
Anhand dieser Aufzeichnung ist leicht zu erkennen, wie einfach es ist, neuronale Netze zu täuschen, indem man ihnen unerwartete Eingaben zuführt. Zu ihrer Ehre werden wir sagen, dass sie ihre Arbeit gemacht und das beste Ergebnis erzielt haben, das sie konnten. Aus den Ergebnissen der Arbeit geht auch hervor, dass es in solchen Fällen nicht ausreicht, Optionen nur mit geringem Vertrauen herauszufiltern, da einige Optionen ein ziemlich hohes Vertrauen hatten. Wir müssen nach Situationen Ausschau halten, in denen reale Systeme so leicht ausfallen. Wir sollten uns nicht über unerwartete Daten im System wundern - und das tun Sicherheitsexperten schon seit geraumer Zeit.