
Diese Seen ( Data Lakes ) werden tatsächlich zum Standard für Unternehmen und Konzerne, die versuchen, alle ihnen zur Verfügung stehenden Informationen zu nutzen. Open-Source-Komponenten sind häufig eine attraktive Option bei der Entwicklung von Seen mit großen Datenmengen. Wir werden uns die allgemeinen Architekturmuster ansehen, die zum Erstellen eines Datensees für Cloud- oder Hybridlösungen erforderlich sind, und eine Reihe kritischer Details hervorheben, auf die Sie bei der Implementierung von Schlüsselkomponenten achten müssen.
Datenflussdesign
Ein typischer logischer Datenseefluss umfasst die folgenden Funktionsblöcke:
- Datenquellen;
- Daten empfangen;
- Speicherknoten;
- Datenverarbeitung und -anreicherung;
- Datenanalyse.
In diesem Zusammenhang sind Datenquellen typischerweise Streams oder Sammlungen von Rohereignisdaten (z. B. Protokolle, Klicks, IoT-Telemetrie, Transaktionen).
Das Hauptmerkmal solcher Quellen ist, dass die Rohdaten in ihrer ursprünglichen Form gespeichert werden. Das Rauschen in diesen Daten besteht normalerweise aus doppelten oder unvollständigen Datensätzen mit redundanten oder fehlerhaften Feldern.
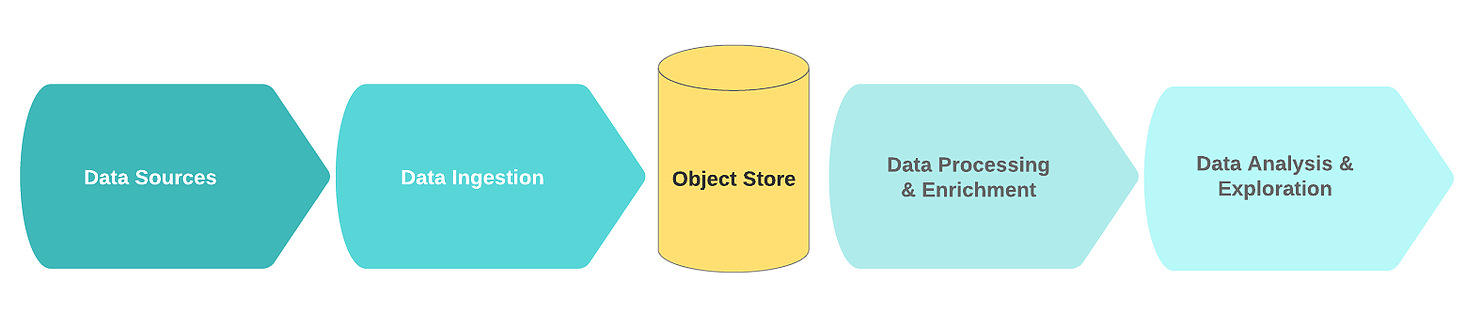
In der Aufnahmephase stammen Rohdaten aus einer oder mehreren Datenquellen. Der Empfangsmechanismus wird meistens in Form einer oder mehrerer Nachrichtenwarteschlangen mit einer einfachen Komponente implementiert, die auf die primäre Bereinigung und Speicherung von Daten abzielt. Um einen effizienten, skalierbaren und konsistenten Datensee zu erstellen, wird empfohlen, zwischen einfacher Datenbereinigung und komplexeren Datenanreicherungsaufgaben zu unterscheiden. Eine gute Faustregel ist, dass für Bereinigungsaufgaben Daten aus einer einzigen Quelle in einem Schiebefenster erforderlich sind.
Versteckter Text
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
Nachdem die Daten empfangen und bereinigt wurden, werden sie im verteilten Dateisystem gespeichert (um die Fehlertoleranz zu verbessern). Daten werden häufig in Tabellenform geschrieben. Wenn neue Informationen in den Speicherknoten geschrieben werden, kann der Datenkatalog mit Schema und Metadaten mithilfe eines Offline-Crawlers aktualisiert werden. Der Start des Crawlers wird normalerweise durch ein Ereignis ausgelöst, beispielsweise wenn ein neues Objekt im Speicher ankommt. Repositorys werden normalerweise in ihre Kataloge integriert. Sie entladen das zugrunde liegende Schema, damit auf die Daten zugegriffen werden kann.
Dann gehen die Daten in einen speziellen Bereich, der "Golddaten" gewidmet ist. Ab diesem Zeitpunkt können die Daten durch andere Prozesse angereichert werden.
Versteckter Text
, , .
Während des Anreicherungsprozesses werden die Daten zusätzlich entsprechend der Geschäftslogik geändert und bereinigt. Infolgedessen werden sie in einem strukturierten Format in einem Data Warehouse oder einer Datenbank gespeichert, mit der Informationen, Analysen oder ein Trainingsmodell schnell abgerufen werden können.
Schließlich ist die Verwendung von Daten Analyse und Forschung. Hier werden die extrahierten Informationen durch Visualisierungen, Dashboards und Berichte in Geschäftsideen umgewandelt. Diese Daten sind auch eine Quelle für Prognosen mithilfe von maschinellem Lernen, deren Ergebnis dazu beiträgt, bessere Entscheidungen zu treffen.
Plattformkomponenten
Die Cloud-Infrastruktur von Data Lake erfordert eine robuste und im Fall von Hybrid-Cloud-Systemen eine einheitliche Abstraktionsschicht, mit deren Hilfe Rechenaufgaben ohne die Einschränkungen von API-Anbietern bereitgestellt, koordiniert und ausgeführt werden können.
Kubernetes ist ein großartiges Werkzeug für diesen Job. Sie können damit verschiedene Dienste und Rechenaufgaben eines Datensees zuverlässig und kostengünstig effizient bereitstellen, organisieren und ausführen. Es bietet eine einheitliche API, die sowohl lokal als auch in jeder öffentlichen oder privaten Cloud funktioniert.
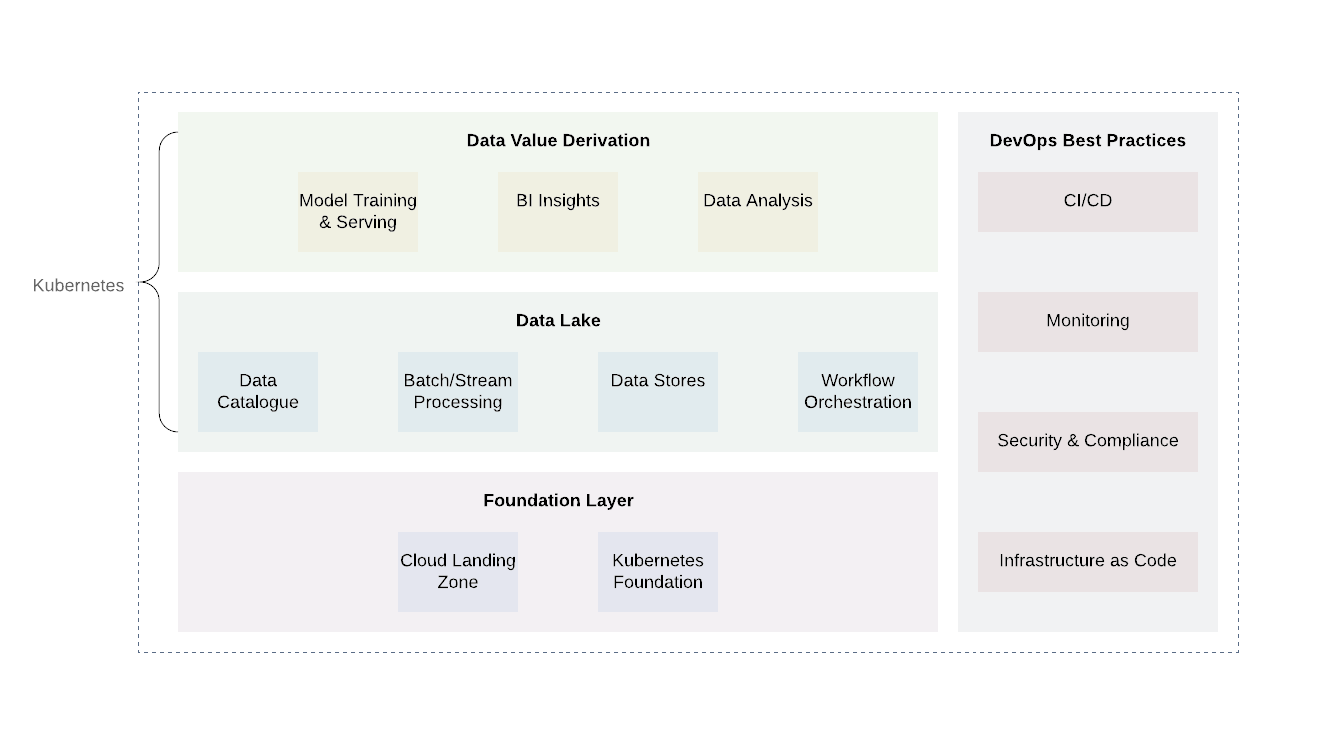
Die Plattform kann grob in mehrere Schichten unterteilt werden. In der Basisschicht stellen wir Kubernetes oder ein gleichwertiges Produkt bereit. Die Basisschicht kann auch verwendet werden, um Rechenaufgaben außerhalb der Domäne des Datensees zu erledigen. Bei der Verwendung von Cloud-Anbietern wäre es vielversprechend, die bereits etablierten Praktiken von Cloud-Anbietern anzuwenden (Protokollierung und Überwachung, Entwurf eines minimalen Zugriffs, Scannen und Berichten von Sicherheitslücken, Netzwerkarchitektur, IAM-Architektur usw.). Dadurch wird das erforderliche Sicherheitsniveau erreicht und andere Anforderungen erfüllt ...
Über der Basisebene befinden sich zwei zusätzliche Ebenen - der Datensee selbst und die Wertausgabepegel. Diese beiden Ebenen sind für die Grundlage der Geschäftslogik sowie der Datenverarbeitungsprozesse verantwortlich. Obwohl es für diese beiden Ebenen viele Technologien gibt, wird sich Kubernetes aufgrund seiner Flexibilität zur Unterstützung einer Vielzahl von Computeraufgaben erneut als gute Option erweisen.
Die Data Lake-Schicht umfasst alle erforderlichen Dienste für den Empfang ( Kafka , Kafka Connect ), das Filtern, die Anreicherung und Verarbeitung ( Flink and Spark ) sowie das Workflow-Management ( Airflow ). Darüber hinaus umfasst es Datenspeicher und verteilte Dateisysteme ( HDFS)) sowie RDBMS- und NoSQL-Datenbanken .
Die oberste Ebene ist das Abrufen von Datenwerten. Grundsätzlich ist dies die Höhe des Verbrauchs. Es enthält Komponenten wie Visualisierungstools zum Verständnis von Business Intelligence und Data Mining-Tools ( Jupyter Notebooks ). Ein weiterer wichtiger Prozess, der auf dieser Ebene stattfindet, ist das maschinelle Lernen anhand von Trainingsmustern aus einem Datensee.
Es ist wichtig zu beachten, dass ein wesentlicher Bestandteil jedes Datensees die Implementierung gängiger DevOps-Praktiken ist: Infrastruktur als Code, Beobachtbarkeit, Prüfung und Sicherheit. Sie spielen eine wichtige Rolle bei der Lösung alltäglicher Probleme und müssen auf jeder einzelnen Ebene angewendet werden, um Standardisierung, Sicherheit und Benutzerfreundlichkeit zu gewährleisten.
, — , opensource-.
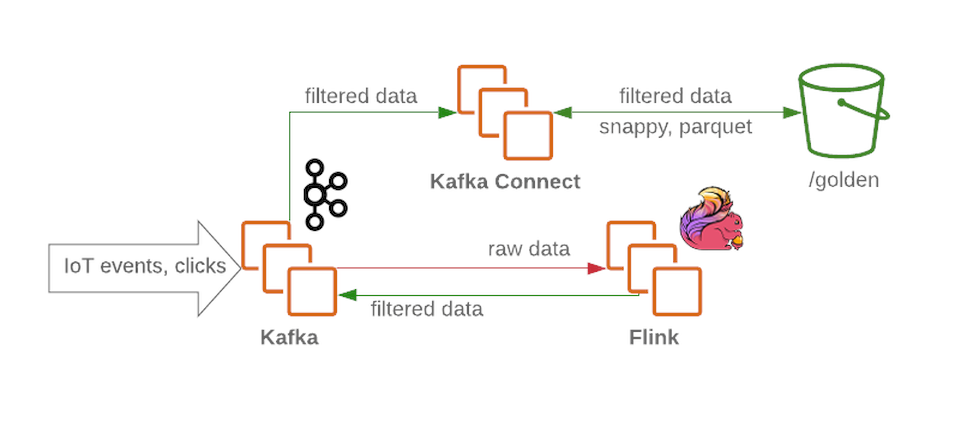
Der Kafka- Cluster empfängt ungefilterte und unverarbeitete Nachrichten und fungiert als Empfangsknoten im Datensee. Kafka liefert zuverlässig Nachrichten mit hohem Durchsatz. Ein Cluster enthält normalerweise mehrere Abschnitte für Rohdaten, verarbeitete Daten (für Streaming) und nicht zugestellte oder fehlerhafte Daten.
Flink akzeptiert eine Nachricht von einem Rohdatenknoten von Kafka , filtert die Daten und bereichert sie bei Bedarf vorab. Die Daten werden dann an Kafka zurückgegeben (in einem separaten Abschnitt für gefilterte und umfangreiche Daten). Im Falle eines Fehlers oder wenn sich die Geschäftslogik ändert, können diese Nachrichten erneut aufgerufen werden, weil dass sie in gespeichert sindKafka . Dies ist eine gängige Lösung für Streaming-Prozesse. In der Zwischenzeit schreibt Flink alle fehlerhaften Nachrichten zur weiteren Analyse in einen anderen Abschnitt.
Mit Kafka Connect können wir Daten in den erforderlichen Datenspeicher-Backends (wie der Goldzone in HDFS ) speichern . Kafka Connect lässt sich einfach skalieren und hilft Ihnen dabei, die Anzahl gleichzeitiger Prozesse schnell zu erhöhen, indem Sie den Durchsatz bei hoher Arbeitsbelastung erhöhen:
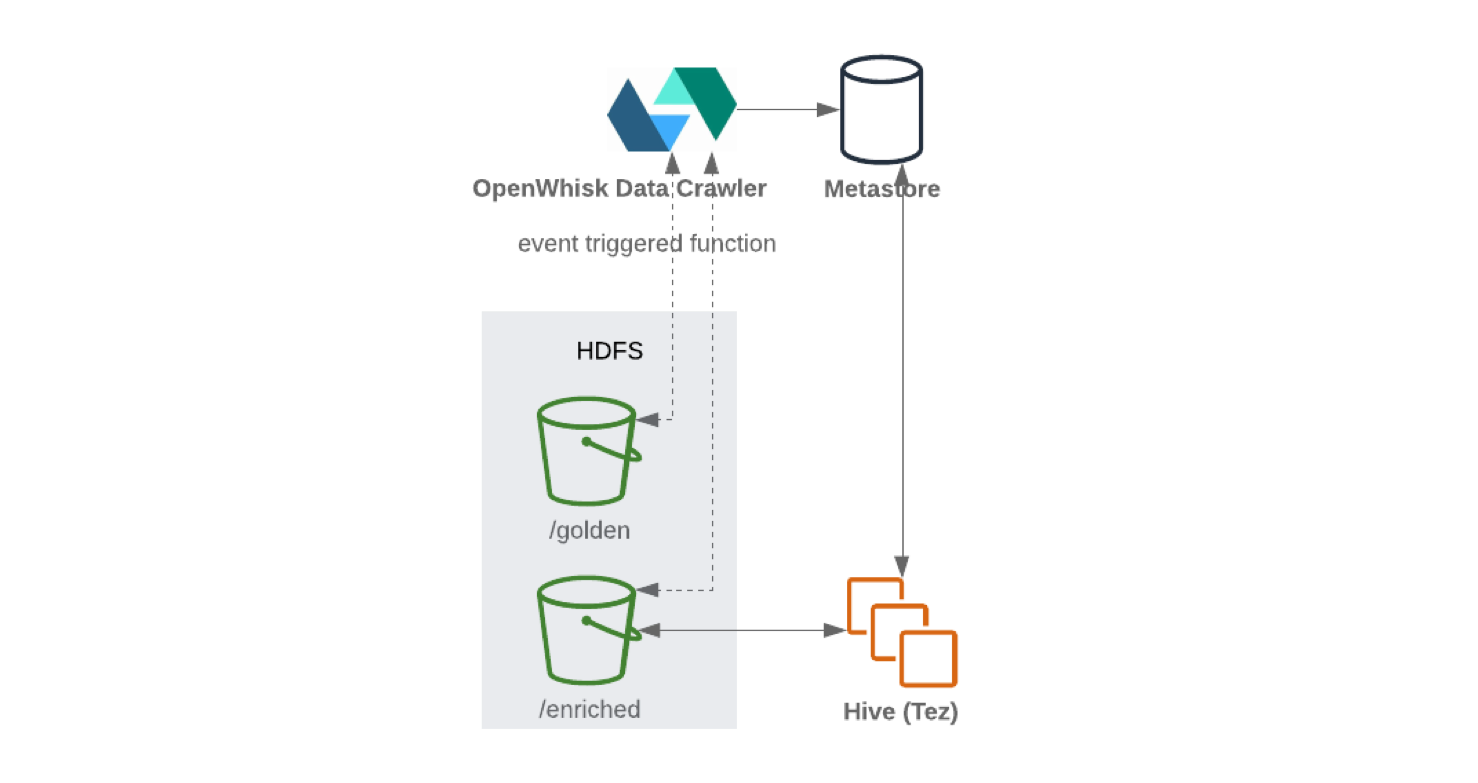
Beim Schreiben von Kafka Connect in HDFS wird empfohlen, eine Inhaltsaufteilung durchzuführen, um eine effiziente Datenverarbeitung zu gewährleisten (je weniger Daten gescannt werden müssen, desto weniger Anforderungen und Antworten). Nachdem die Daten in HDFS geschrieben wurden, aktualisiert die serverlose Funktionalität (wie OpenWhisk oder Knative ) regelmäßig den Metadaten- und Schemaparameterspeicher . Auf das aktualisierte Schema kann daher über eine SQL-ähnliche Schnittstelle (z. B. Hive oder Presto ) zugegriffen werden .
Apache Airflow kann für nachfolgende Datenflüsse und die Verwaltung des ETL- Prozesses verwendet werden . Benutzer können mehrstufige Piplines mit Python- und DAG- Objekten ( Directed Acyclic Graph ) ausführen . Der Benutzer kann Abhängigkeiten definieren, komplexe Prozesse programmieren und Aufgaben über eine grafische Oberfläche verfolgen. Apache Airflow kann auch alle externen Daten verarbeiten. Zum Beispiel, um Daten über eine externe API zu empfangen und in einem dauerhaften Speicher zu speichern. Funken angetrieben von Apache Airflow
Durch ein spezielles Plug-In kann es regelmäßig gefilterte Rohdaten gemäß den Geschäftszielen anreichern und Daten für die Forschung durch Datenwissenschaftler und Geschäftsanalysten vorbereiten. Data Scientists können JupyterHub verwenden , um mehrere Jupyter-Notebooks zu verwalten . Daher lohnt es sich, Spark zu verwenden, um Mehrbenutzerschnittstellen für die Arbeit mit Daten, deren Erfassung und Analyse zu konfigurieren.

Für maschinelles Lernen können Sie Frameworks wie Kubeflow verwenden und die Skalierbarkeit von Kubernetes nutzen . Die resultierenden Trainingsmodelle können an das System zurückgegeben werden.
Wenn wir das Puzzle zusammensetzen, erhalten wir ungefähr Folgendes:

Operational Excellence
Wir haben gesagt, dass die Prinzipien von DevOps und DevSecOps wesentliche Bestandteile eines Datensees sind und niemals übersehen werden sollten. Mit viel Leistung geht eine Menge Verantwortung einher, insbesondere wenn sich alle strukturierten und unstrukturierten Daten über Ihr Unternehmen an einem Ort befinden.
Die Grundprinzipien lauten wie folgt:
- Benutzerzugriff einschränken;
- Überwachung;
- Datenverschlüsselung;
- Serverlose Lösungen;
- Verwenden von CI / CD-Prozessen.
Die Prinzipien von DevOps und DevSecOps sind wesentliche Bestandteile eines Datensees und sollten niemals übersehen werden. Mit viel Leistung geht eine Menge Verantwortung einher, insbesondere wenn sich alle strukturierten und unstrukturierten Daten über Ihr Unternehmen an einem Ort befinden.
Eine der empfohlenen Methoden besteht darin, den Zugriff nur auf bestimmte Dienste durch Zuweisen entsprechender Rechte zuzulassen und den direkten Benutzerzugriff zu verweigern, damit Benutzer keine Daten ändern können (dies gilt auch für Befehle). Eine vollständige Überwachung durch Protokollierungsaktionen ist ebenfalls wichtig, um Daten zu schützen.
Die Datenverschlüsselung ist ein weiterer Mechanismus zum Schutz von Daten. Gespeicherte Daten können mit einem Schlüsselverwaltungssystem ( KMS) verschlüsselt werden). Dadurch werden Ihr Speichersystem und der aktuelle Status verschlüsselt. Die Übertragungsverschlüsselung kann wiederum mithilfe von Zertifikaten für alle Schnittstellen und Endpunkte von Diensten wie Kafka und ElasticSearch erfolgen .
Bei Suchmaschinen, die möglicherweise nicht den Sicherheitsrichtlinien entsprechen, ist es besser, serverlose Lösungen zu bevorzugen . Es ist auch notwendig, manuelle Bereitstellungen und Situationsänderungen in einer beliebigen Komponente des Datensees aufzugeben. Jede Änderung muss von der Quellcodeverwaltung stammen und eine Reihe von CI- Tests bestehen, bevor sie auf dem Produktdatensee bereitgestellt wird ( Rauchtests , Regression usw.).
Epilog
Wir haben die grundlegenden Entwurfsprinzipien einer Open-Source-Data-Lake-Architektur behandelt. Wie so oft ist die Wahl des Ansatzes nicht immer offensichtlich und kann durch unterschiedliche Geschäfts-, Budget- und Zeitanforderungen bestimmt werden. Die Nutzung der Cloud-Technologie zur Erstellung von Data Lakes, egal ob es sich um eine Hybrid- oder eine All-Cloud-Lösung handelt, ist ein aufkommender Trend in der Branche. Dies liegt an der Vielzahl von Vorteilen, die dieser Ansatz bietet. Es hat ein hohes Maß an Flexibilität und schränkt die Entwicklung nicht ein. Es ist wichtig zu verstehen, dass ein flexibles Arbeitsmodell erhebliche wirtschaftliche Vorteile mit sich bringt, sodass Sie die angewandten Prozesse kombinieren, skalieren und verbessern können.