
Dieser Text ist eine Übersetzung des Blogposts Multi-Target in Albumentations vom 27. Juli 2020. Der Autor ist auf Habré , aber ich war zu faul, um den Text ins Russische zu übersetzen. Und diese Übersetzung wurde auf seine Bitte hin angefertigt.
Ich habe alles, was ich kann, ins Russische übersetzt, aber einige Fachbegriffe auf Englisch klingen natürlicher. Sie bleiben in dieser Form. Wenn Ihnen eine angemessene Übersetzung in den Sinn kommt, kommentieren und korrigieren Sie sie.
Die Bildvergrößerung ist eine interpretierte Regularisierungstechnik. Sie konvertieren vorhandene markierte Daten in neue Daten und erhöhen dadurch die Größe des Datasets.

Sie können Albumentationen in PyTorch , Keras , Tensorflow oder einem anderen Framework verwenden, das ein Bild als Numpy-Array verarbeiten kann.
Die Bibliothek eignet sich am besten für Standardaufgaben wie Klassifizierung, Segmentierung, Erkennung von Objekten und Schlüsselpunkten. Etwas seltener sind Probleme, wenn jedes Element der Trainingsprobe nicht ein, sondern viele verschiedene Objekte enthält.
Für diese Art von Situationen wurde die Multi-Target-Funktionalität hinzugefügt.
Situationen, in denen dies nützlich sein könnte:
- Siamesische Netzwerke
- Frames im Video verarbeiten
- Image2image-Aufgaben
- Multilabel semantic segmentation
- Instance segmentation
- Panoptic segmentation
- Kaggle . Kaggle Grandmaster, Kaggle Masters, Kaggle Expert.
- , Deepfake Challenge , Albumentations .
- PyTorch ecosystem
- 5700 GitHub.
- 80 . .
In den letzten drei Jahren haben wir an Funktions- und Leistungsoptimierungen gearbeitet.
Im Moment konzentrieren wir uns auf Dokumentation und Tutorials.
Mindestens einmal pro Woche fordern Benutzer an, Transformationsunterstützung für mehrere Segmentierungsmasken hinzuzufügen.
Wir haben es schon lange gehabt.
In diesem Artikel werden Beispiele für die Arbeit mit mehreren Zielen in Albumentationen vorgestellt.
Szenario 1: Ein Bild, eine Maske
Der häufigste Anwendungsfall ist die Bildsegmentierung. Sie haben ein Bild und eine Maske. Sie möchten eine Reihe von räumlichen Transformationen auf sie anwenden, und sie müssen dieselbe Menge sein.
In diesem Code verwenden wir HorizontalFlip und ShiftScaleRotate .
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT,
scale_limit=0.3,
rotate_limit=(10, 30),
p=0.5)
], p=1)
transformed = transform(image=image, mask=mask)
image_transformed = transformed['image']
mask_transformed = transformed['mask']-> Link zu gistfile1.py

Szenario 2: Ein Bild und mehrere Masken

Bei einigen Aufgaben können mehrere Beschriftungen vorhanden sein, die demselben Pixel entsprechen. Wenden
wir HorizontalFlip , GridDistortion , RandomCrop an .
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.GridDistortion(p=0.5),
A.RandomCrop(height=1024, width=1024, p=0.5),
], p=1)
transformed = transform(image=image, masks=[mask, mask2])
image_transformed = transformed['image']
mask_transformed = transformed['masks'][0]
mask2_transformed = transformed['masks'][1]-> Link zu gistfile1.py
Szenario 3: Mehrere Bilder, Masken, Schlüsselpunkte und Felder

Sie können räumliche Transformationen auf mehrere Ziele anwenden.
In diesem Beispiel haben wir zwei Bilder, zwei Masken, zwei Kästchen und zwei Sätze von Schlüsselpunkten. Wenden
wir eine Folge von HorizontalFlip und ShiftScaleRotate an .
import albumentations as A
transform = A.Compose([A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT, scale_limit=0.3, p=0.5)],
bbox_params=albu.BboxParams(format='pascal_voc', label_fields=['category_ids']),
keypoint_params=albu.KeypointParams(format='xy'),
additional_targets={
"image1": "image",
"bboxes1": "bboxes",
"mask1": "mask",
'keypoints1': "keypoints"},
p=1)
transformed = transform(image=image,
image1=image1,
mask=mask,
mask1=mask1,
bboxes=bboxes,
bboxes1=bboxes1,
keypoints=keypoints,
keypoints1=keypoints1,
category_ids=["face"]
)
image_transformed = transformed['image']
image1_transformed = transformed['image1']
mask_transformed = transformed['mask']
mask1_transformed = transformed['mask1']
bboxes_transformed = transformed['bboxes']
bboxes1_transformed = transformed['bboxes1']
keypoints_transformed = transformed['keypoints']
keypoints1_transformed = transformed['keypoints1']
→ Link zu gistfile1.py

F: Ist es möglich, mit mehr als zwei Bildern zu arbeiten?
A: Sie können so viele Bilder aufnehmen, wie Sie möchten.
F: Sollte die Anzahl der Bilder, Masken, Kästchen und Schlüsselpunkte gleich sein?
A: Sie können N Bilder, M Masken, K Schlüsselpunkte und B Felder haben. N, M, K und B können unterschiedlich sein.
F: Gibt es Situationen, in denen die Multi-Target-Funktionalität nicht oder nicht wie erwartet funktioniert?
A: Im Allgemeinen können Sie Multi-Target für eine Reihe von Bildern unterschiedlicher Größe verwenden. Einige Transformationen hängen von der Eingabe ab. Sie können beispielsweise keinen Zuschnitt zuschneiden, der größer als das Bild selbst ist. Ein anderes Beispiel: MaskDropout , das von der Originalmaske abhängen kann. Wie er sich verhalten wird, wenn wir eine Reihe von Masken haben, ist nicht klar. In der Praxis sind sie äußerst selten.
F: Wie viele Transformationen können miteinander kombiniert werden?
A : Sie können Transformationen auf verschiedene Arten zu einer komplexen Pipeline kombinieren.
Die Bibliothek enthält über 30 räumliche Transformationen . Sie alle unterstützen Bilder und Masken, die meisten Unterstützungsboxen und Schlüsselpunkte.
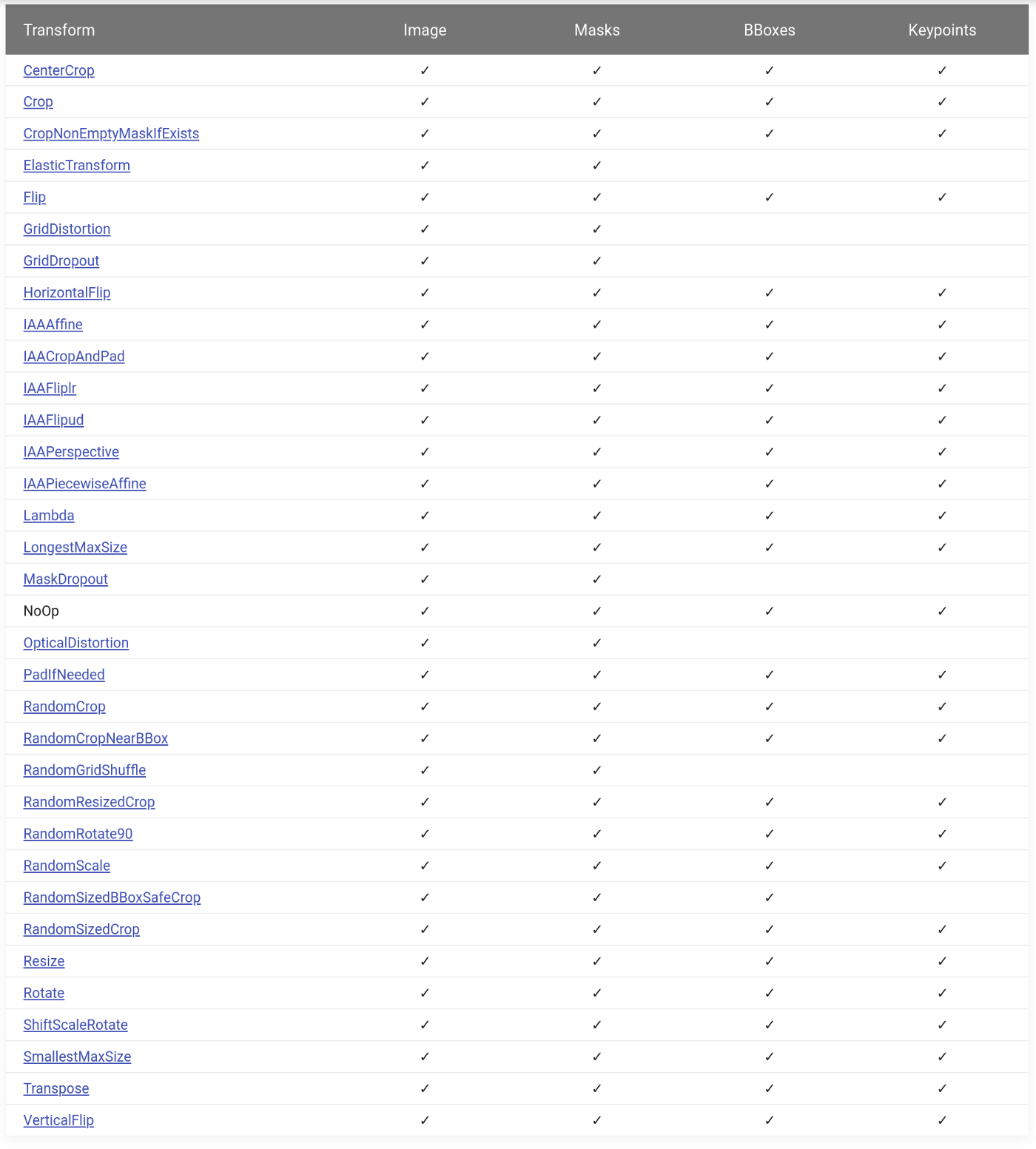
→ Link zur Quelle
Sie können mit über 40 Transformationen kombiniert werden , die die Pixelwerte eines Bildes ändern. Zum Beispiel: RandomBrightnessContrast , Bluroder etwas Exotischeres wie RandomRain .
Zusätzliche Dokumentation
- Vollständiges Umrechnungsblatt
- Maskentransformationen für Segmentierungsaufgaben
- Erweiterung der Objekterkennung für Begrenzungsrahmen
- Schlüsselpunkttransformationen
- Synchrone Konvertierung von Masken, Boxen und Schlüsselpunkten
- Mit welcher Wahrscheinlichkeit werden Transformationen in der Pipeline angewendet?
Fazit
Die Arbeit an einem Open-Source-Projekt ist herausfordernd, aber sehr aufregend. Ich möchte dem Entwicklungsteam danken:
und alle Mitwirkenden, die dazu beigetragen haben, die Bibliothek zu erstellen und auf den aktuellen Stand zu bringen.