Ich arbeite derzeit bei ManyChat. In der Tat ist dies ein Startup - neu, ehrgeizig und schnell wachsend. Und als ich gerade in das Unternehmen eintrat, stellte sich die klassische Frage: "Was sollte ein junges Startup jetzt vom DBMS- und Datenbankmarkt nehmen?"
In diesem Artikel werde ich auf der Grundlage meines Vortrags beim Online-Festival RIT ++ 2020 diese Frage beantworten. Eine Videoversion des Berichts ist auf YouTube verfügbar .
Bekannte Datenbanken von 2020
Es ist 2020, ich habe mich umgesehen und drei Arten von Datenbanken gesehen.
Der erste Typ sind klassische OLTP-Datenbanken : PostgreSQL, SQL Server, Oracle, MySQL. Sie wurden vor langer Zeit geschrieben, sind aber immer noch relevant, da sie der Entwicklergemeinde vertraut sind.
Der zweite Typ basiert auf "Null" . Sie versuchten, sich von den klassischen Mustern zu entfernen, indem sie sich von SQL, traditionellen Strukturen und ACID entfernten, indem sie Inline-Sharding und andere attraktive Funktionen hinzufügten. Dies sind beispielsweise Cassandra, MongoDB, Redis oder Tarantool. Alle diese Lösungen wollten dem Markt etwas grundlegend Neues bieten und besetzten ihre Nische, weil sie sich bei bestimmten Aufgaben als äußerst praktisch erwiesen. Diese Basen werden mit dem Überbegriff NOSQL bezeichnet.
Die "Nullen" sind vorbei, sie haben sich an NOSQL-Datenbanken gewöhnt und die Welt hat aus meiner Sicht den nächsten Schritt getan - zu verwalteten Datenbanken . Diese Datenbanken haben denselben Kern wie klassische OLTP-Datenbanken oder neue NoSQL-Datenbanken. Sie benötigen jedoch keinen DBA und DevOps und laufen auf verwalteter Hardware in den Clouds. Für einen Entwickler ist dies "nur eine Basis", die irgendwo funktioniert, aber wie es auf dem Server installiert ist, wer den Server eingerichtet und wer ihn aktualisiert, interessiert niemanden.
Beispiele für solche Basen:
- AWS RDS ist ein verwalteter Wrapper über PostgreSQL / MySQL.
- DynamoDB ist ein AWS-Analogon einer dokumentbasierten Datenbank, ähnlich wie Redis und MongoDB.
- Amazon Redshift ist eine verwaltete Analysebasis.
Im Kern handelt es sich hierbei um alte Basen, die jedoch in einer verwalteten Umgebung erstellt wurden, ohne dass mit Hardware gearbeitet werden muss.
Hinweis. Die Beispiele beziehen sich auf die AWS-Umgebung, ihre Gegenstücke sind jedoch auch in Microsoft Azure, Google Cloud oder Yandex.Cloud vorhanden.

So was ist neu? Im Jahr 2020 nichts davon.
Serverloses Konzept
Was 2020 wirklich neu auf dem Markt ist, sind serverlose oder serverlose Lösungen.
Ich werde versuchen zu erklären, was dies am Beispiel einer regulären Dienst- oder Backend-Anwendung bedeutet.
Um eine reguläre Backend-Anwendung bereitzustellen, kaufen oder mieten wir einen Server, kopieren den Code darauf, veröffentlichen den Endpunkt außerhalb und zahlen regelmäßig für Miete, Strom und Rechenzentrumsdienste. Dies ist das Standardlayout.
Gibt es einen anderen Weg? Mit serverlosen Diensten können Sie.
Was ist der Schwerpunkt dieses Ansatzes: Es gibt keinen Server, es gibt nicht einmal eine virtuelle Instanz in der Cloud. Kopieren Sie zum Bereitstellen des Dienstes den Code (die Funktionen) in das Repository und veröffentlichen Sie den Endpunkt außerhalb. Dann zahlen wir nur für jeden Aufruf dieser Funktion und ignorieren die Hardware, auf der sie ausgeführt wird, vollständig.
Ich werde versuchen, diesen Ansatz in Bildern zu veranschaulichen.
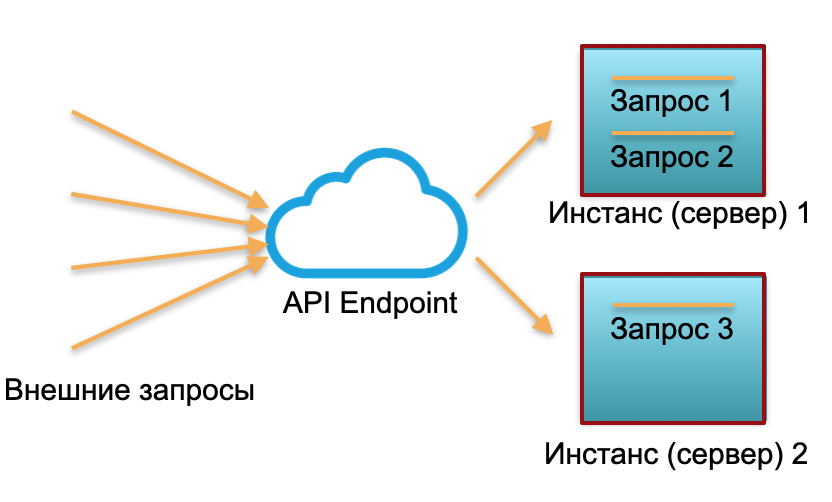
Klassische Bereitstellung . Wir haben einen Service mit einer bestimmten Last. Wir lösen zwei Instanzen aus: physische Server oder Instanzen in AWS. Externe Anfragen werden an diese Instanzen gesendet und dort verarbeitet.
Wie Sie auf dem Bild sehen können, werden die Server unterschiedlich genutzt. Eine ist zu 100% ausgelastet, es gibt zwei Anforderungen und eine ist nur zu 50% teilweise inaktiv. Wenn nicht drei, sondern 30 Anfragen eingehen, wird das gesamte System die Last nicht bewältigen und langsamer werden.

Serverlose Bereitstellung... In einer Umgebung ohne Server verfügt ein solcher Dienst über keine Instanzen oder Server. Es gibt einen Pool aufgewärmter Ressourcen - kleine vorbereitete Docker-Container mit bereitgestelltem Funktionscode. Das System empfängt externe Anforderungen und für jede von ihnen löst das serverlose Framework einen kleinen Container mit Code aus: Es verarbeitet diese bestimmte Anforderung und beendet den Container.
Eine Anfrage - ein angehobener Container, 1000 Anfragen - 1000 Container. Die Bereitstellung auf Eisenservern ist bereits die Arbeit eines Cloud-Anbieters. Es wird vom serverlosen Framework vollständig ausgeblendet. In diesem Konzept zahlen wir für jeden Anruf. Zum Beispiel kam ein Anruf pro Tag - wir haben für einen Anruf bezahlt, eine Million kam in einer Minute - wir haben für eine Million bezahlt. Oder in einer Sekunde passiert dies auch.
Das Konzept der Veröffentlichung einer Funktion ohne Server ist für einen zustandslosen Dienst geeignet. Wenn Sie einen (Status-) Statusdienst benötigen, fügen Sie dem Dienst eine Datenbank hinzu. In diesem Fall schreibt und liest jede statefull-Funktion beim Arbeiten mit state mit state einfach aus der Datenbank. Darüber hinaus aus einer Datenbank eines der drei am Anfang des Artikels beschriebenen Typen.
Was ist die gemeinsame Einschränkung all dieser Grundlagen? Dies sind die Kosten eines ständig genutzten Cloud- oder Iron-Servers (oder mehrerer Server). Es spielt keine Rolle, ob wir eine klassische Datenbank verwenden oder verwaltet werden, ob wir Devops und einen Administrator haben oder nicht, wir zahlen immer noch rund um die Uhr für die Miete von Hardware, Strom und Rechenzentren. Wenn wir eine klassische Basis haben, zahlen wir für Master und Slave. Wenn es sich um eine hoch ausgelastete Sharded-Basis handelt, zahlen wir für 10, 20 oder 30 Server und zahlen ständig.
Das Vorhandensein permanent reservierter Server in der Kostenstruktur wurde zuvor als notwendiges Übel angesehen. Gewöhnliche Datenbanken haben auch andere Schwierigkeiten, wie z. B. Beschränkungen der Anzahl der Verbindungen, Skalierungsbeschränkungen, geoverteilter Konsens - sie können in bestimmten Datenbanken irgendwie gelöst werden, aber nicht alle auf einmal und nicht ideal.
Serverlose Datenbank - Theorie
Frage 2020: Kann die Datenbank auch serverlos gemacht werden? Jeder hat von dem serverlosen Backend gehört ... aber versuchen wir auch, die Datenbank serverlos zu machen?
Das klingt seltsam, weil eine Datenbank ein Statefull-Dienst ist, der für eine serverlose Infrastruktur nicht sehr geeignet ist. Gleichzeitig ist der Status der Datenbank sehr groß: Gigabyte, Terabyte und sogar Petabyte in Analysedatenbanken. Es ist nicht so einfach, es in leichten Docker-Containern anzuheben.
Andererseits bestehen fast alle modernen Datenbanken aus einer Vielzahl von Logik und Komponenten: Transaktionen, Integritätsverhandlungen, Prozeduren, relationale Abhängigkeiten und viel Logik. Ein Großteil der Datenbanklogik ist ein relativ kleiner Zustand. Gigabyte und Terabyte werden direkt nur von einem kleinen Teil der Datenbanklogik verwendet, die mit der direkten Ausführung von Abfragen verbunden ist.
Dementsprechend die Idee: Wenn ein Teil der Logik eine zustandslose Ausführung zulässt, warum nicht die Basis in Stateful- und Stateless-Teile zerlegen?
Serverlos für OLAP-Lösungen
Lassen Sie uns anhand praktischer Beispiele sehen, wie eine in Stateful- und Stateless-Teile geschnittene Datenbank aussehen könnte.
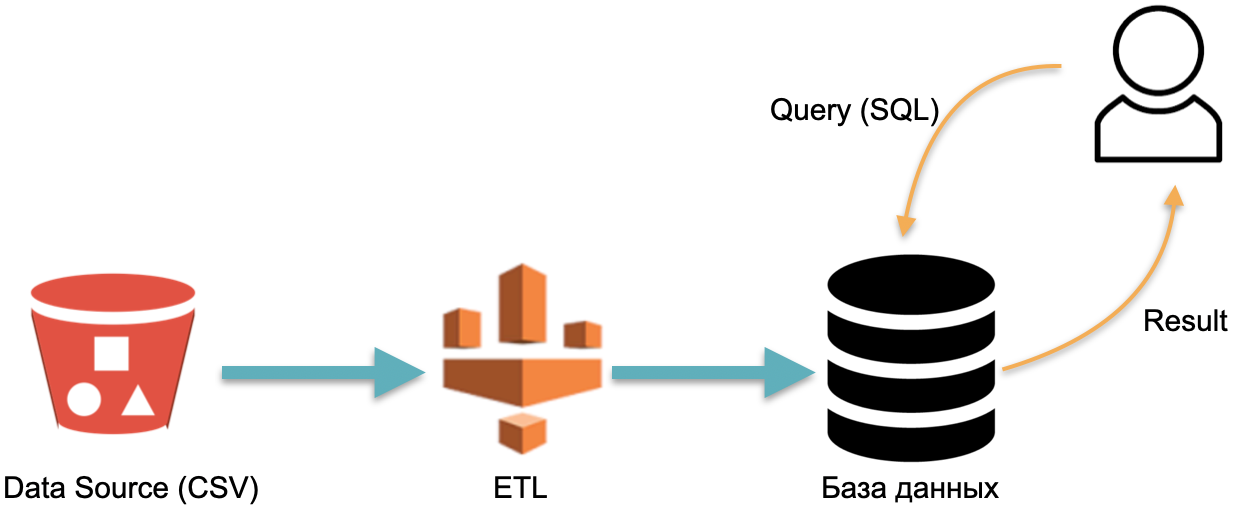
Zum Beispiel haben wir eine analytische Datenbank : externe Daten (roter Zylinder links), einen ETL-Prozess, der Daten in die Datenbank lädt, und einen Analysten, der SQL-Abfragen an die Datenbank sendet. Dies ist die klassische Funktionsweise eines Data Warehouse.
In diesem Schema wird ETL gemäß Konvention einmal ausgeführt. Dann müssen Sie die ganze Zeit für die Server bezahlen, auf denen die Datenbank mit mit ETL überfluteten Daten ausgeführt wird, damit Sie etwas zum Auslösen von Anforderungen haben.
Schauen wir uns einen alternativen Ansatz an, der in AWS Athena Serverless implementiert ist. Es gibt keine permanent dedizierte Hardware, auf der die heruntergeladenen Daten gespeichert sind. Stattdessen:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
In dieser Architektur zahlen wir nur für den Ausführungsprozess der Anfrage. Keine Anfragen - keine Kosten.
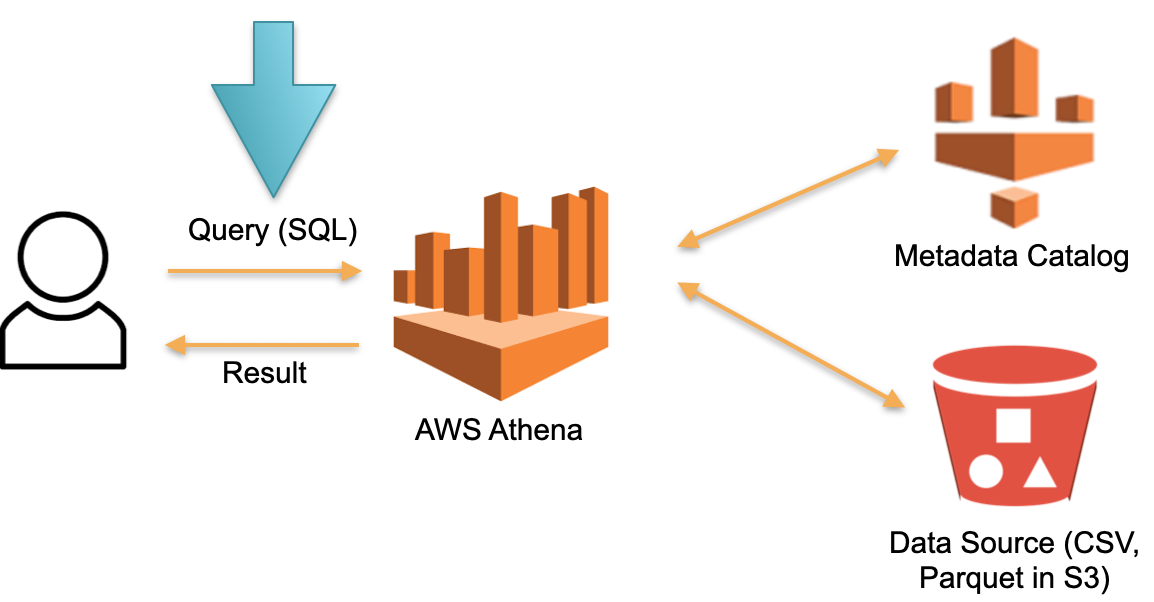
Dies ist ein funktionierender Ansatz und wird nicht nur in Athena Serverless, sondern auch in Redshift Spectrum (unter AWS) implementiert.
Das Beispiel von Athena zeigt, dass die Serverless-Datenbank mit realen Abfragen mit Dutzenden und Hunderten von Terabyte Daten arbeitet. Hunderte von Terabyte erfordern Hunderte von Servern, aber wir müssen nicht dafür bezahlen - wir bezahlen für Anfragen. Die Geschwindigkeit jeder Anfrage ist im Vergleich zu speziellen Analysedatenbanken wie Vertica (sehr) langsam, aber wir zahlen nicht für Ausfallzeiten.
Eine solche Datenbank ist nützlich für seltene Ad-hoc-Analyseabfragen. Zum Beispiel, wenn wir uns spontan dazu entschließen, eine Hypothese für eine gigantische Datenmenge zu testen. Athena ist perfekt für diese Fälle. Für regelmäßige Anfragen ist ein solches System teuer. In diesem Fall zwischenspeichern Sie die Daten in einer speziellen Lösung.
Serverlos für OLTP-Lösungen
Im vorherigen Beispiel wurden OLAP-Aufgaben (analytisch) berücksichtigt. Schauen wir uns nun die OLTP-Aufgaben an.
Stellen Sie sich skalierbares PostgreSQL oder MySQL vor. Lassen Sie uns eine regulär verwaltete Instanz PostgreSQL oder MySQL mit minimalen Ressourcen auslösen. Wenn mehr Last auf der Instanz eintrifft, verbinden wir zusätzliche Replikate, auf die wir einen Teil der Leselast verteilen. Wenn es keine Anforderungen und keine Last gibt, deaktivieren wir die Replikate. Die erste Instanz ist der Master und der Rest sind Replikate.
Diese Idee ist in einer Datenbank namens Aurora Serverless AWS implementiert. Das Prinzip ist einfach: Anfragen von externen Anwendungen werden von der Proxy-Flotte akzeptiert. Bei zunehmender Last werden Rechenressourcen aus vorgewärmten Mindestinstanzen zugewiesen - die Verbindung ist so schnell wie möglich. Das Trennen von Instanzen ist dasselbe.
Innerhalb von Aurora gibt es das Konzept der Aurora Capacity Unit, ACU. Dies ist (bedingt) eine Instanz (Server). Jede spezifische ACU kann Master oder Slave sein. Jede Kapazitätseinheit verfügt über einen eigenen RAM, Prozessor und eine minimale Festplatte. Dementsprechend sind ein Master, der Rest sind schreibgeschützte Repliken.
Die Anzahl dieser in Betrieb befindlichen Aurora-Kapazitätseinheiten ist konfigurierbar. Die Mindestmenge kann eins oder null sein (in diesem Fall funktioniert die Basis nicht, wenn keine Anforderungen vorliegen).

Wenn die Basis Anforderungen empfängt, erhöht die Proxy-Flotte die Aurora CapacityUnits und erhöht so die produktiven Ressourcen des Systems. Durch die Möglichkeit, Ressourcen zu erhöhen und zu verringern, kann das System Ressourcen "jonglieren": Einzelne ACUs werden automatisch angezeigt (durch neue ersetzt) und alle relevanten Aktualisierungen für die entfernten Ressourcen bereitgestellt.
Die Aurora Serverless Base kann die Leselast skalieren. Aber die Dokumentation sagt es nicht direkt. Es könnte sich so anfühlen, als könnten sie einen Multi-Master abholen. Es gibt keine Magie.
Diese Basis ist gut geeignet, um nicht viel Geld für Systeme mit unvorhersehbarem Zugriff auszugeben. Wenn wir beispielsweise MVP- oder Visitenkarten-Marketing-Websites erstellen, erwarten wir normalerweise keine konstante Belastung. Dementsprechend zahlen wir mangels Zugang nicht für Instanzen. Wenn eine Last unerwartet auftritt, z. B. nach einer Konferenz oder einer Werbekampagne, eine Menschenmenge die Website besucht und die Last dramatisch zunimmt, übernimmt Aurora Serverless diese Last automatisch und verbindet schnell die fehlenden Ressourcen (ACU). Dann geht die Konferenz weiter, jeder vergisst den Prototyp, die Server (ACU) gehen aus und die Kosten fallen auf Null - es ist praktisch.
Diese Lösung ist nicht für stabile Hochlasten geeignet, da sie die Schreiblast nicht skalieren kann. Alle diese Verbindungen und Unterbrechungen von Ressourcen erfolgen zum Zeitpunkt des sogenannten "Skalierungspunkts" - dem Zeitpunkt, zu dem die Datenbank nicht von der Transaktion gehalten wird, werden temporäre Tabellen nicht gespeichert. Während einer Woche tritt der Skalierungspunkt möglicherweise nicht auf, und die Basis arbeitet mit denselben Ressourcen und kann einfach nicht erweitert oder verkleinert werden.
Es gibt keine Magie - dies ist normales PostgreSQL. Das Hinzufügen und Trennen von Autos ist jedoch teilweise automatisiert.
Serverlos von Natur aus
Aurora Serverless ist eine alte Basis, die für die Cloud neu geschrieben wurde, um die individuellen Vorteile von Serverless zu nutzen. Und jetzt erzähle ich Ihnen von der Basis, die ursprünglich für die Cloud geschrieben wurde, für den Ansatz ohne Server - Serverless-by-Design. Es wurde sofort ohne die Annahme entwickelt, dass es auf physischen Servern ausgeführt wird.
Diese Basis heißt Schneeflocke. Es hat drei Schlüsselblöcke.
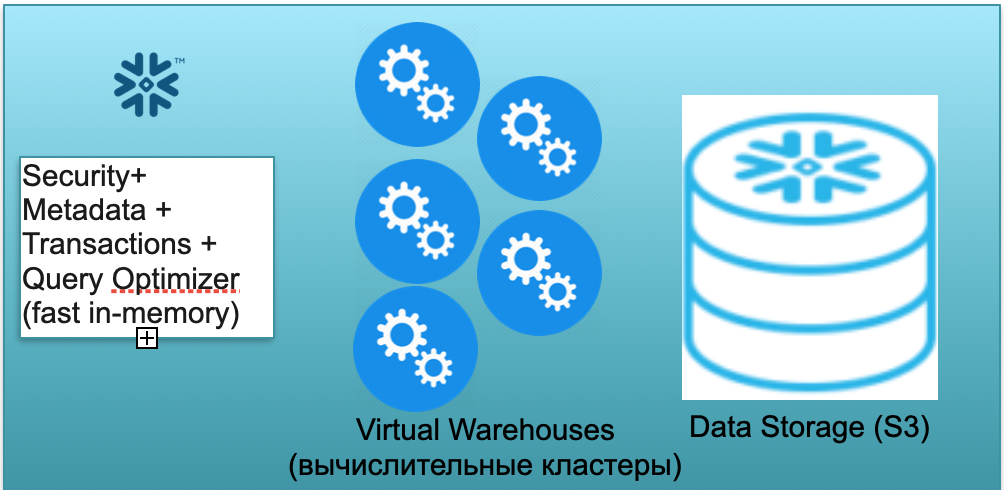
Der erste ist ein Block von Metadaten. Es handelt sich um einen schnellen In-Memory-Dienst, der Probleme mit Sicherheit, Metadaten, Transaktionen und Abfrageoptimierung löst (siehe Abbildung links).
Der zweite Block ist eine Reihe von virtuellen Rechenclustern für Berechnungen (in der Abbildung - eine Reihe von blauen Kreisen).
Der dritte Block ist ein S3-basiertes Speichersystem. S3 ist der dimensionslose Objektspeicher von AWS, ähnlich der dimensionslosen Dropbox für Unternehmen.
Werfen wir einen Blick darauf, wie Snowflake unter der Annahme eines Kaltstarts funktioniert. Das heißt, die Datenbank ist da, die Daten werden in sie geladen, es gibt keine Arbeitsabfragen. Wenn dementsprechend keine Abfragen an die Datenbank vorliegen, haben wir einen schnellen In-Memory-Metadatendienst (erster Block) ausgelöst. Und wir haben einen S3-Speicher, in dem Tabellendaten gespeichert sind, unterteilt in sogenannte Mikropartitionen. Der Einfachheit halber: Wenn die Tabelle Deals enthält, sind Micro-Lots die Tage der Deals. Jeder Tag ist eine separate Mikrobatch, eine separate Datei. Und wenn die Datenbank in diesem Modus arbeitet, zahlen Sie nur für den von den Daten belegten Speicherplatz. Darüber hinaus ist die Rate pro Sitz sehr gering (insbesondere angesichts der erheblichen Kompression). Der Metadatendienst funktioniert ebenfalls ständig, benötigt jedoch nicht viele Ressourcen, um Abfragen zu optimieren, und der Dienst kann als Shareware betrachtet werden.
Stellen wir uns nun vor, ein Benutzer kommt zu unserer Datenbank und löst eine SQL-Abfrage aus. Die SQL-Abfrage wird sofort zur Verarbeitung an den Metadatendienst gesendet. Dementsprechend analysiert dieser Dienst beim Empfang einer Anforderung die Anforderung, die verfügbaren Daten und die Benutzerberechtigung und erstellt, wenn alles in Ordnung ist, einen Anforderungsverarbeitungsplan.
Als Nächstes initiiert der Dienst den Start des Rechenclusters. Ein Rechencluster ist ein Cluster von Servern, die Berechnungen durchführen. Das heißt, dies ist ein Cluster, der 1 Server, 2 Nord, 4, 8, 16, 32 enthalten kann - so viele, wie Sie möchten. Sie werfen eine Anfrage und der Start dieses Clusters beginnt sofort darunter. Es dauert wirklich Sekunden.
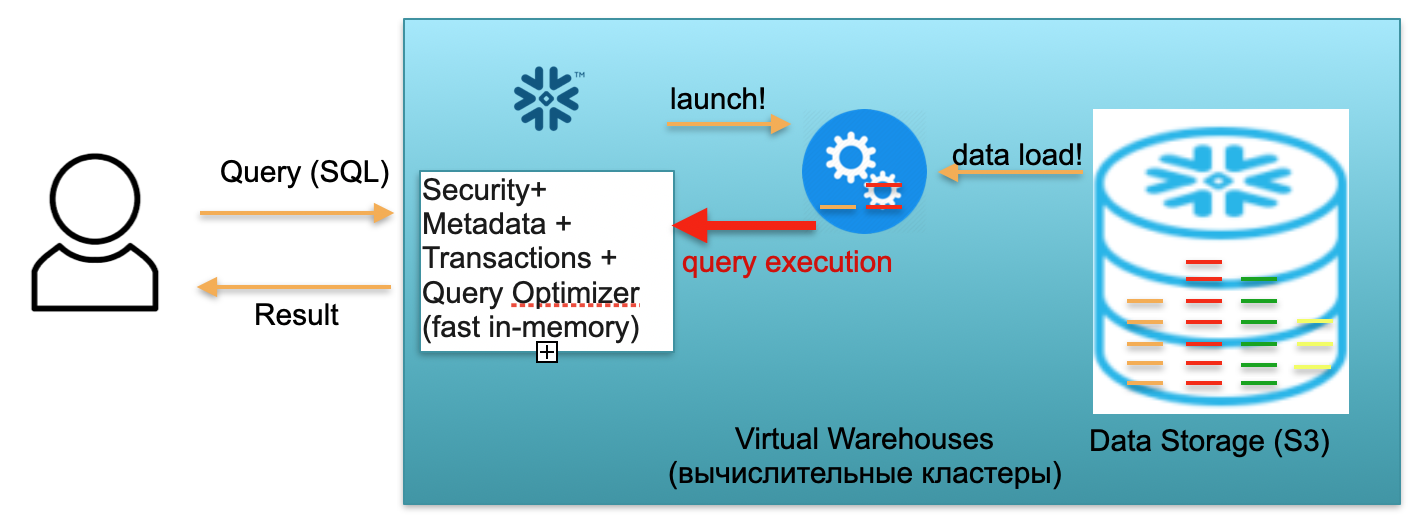
Nach dem Start des Clusters werden Mikropartitionen von S3 in den Cluster kopiert, die zur Verarbeitung Ihrer Anforderung erforderlich sind. Stellen Sie sich vor, Sie benötigen zum Ausführen einer SQL-Abfrage zwei Partitionen aus einer Tabelle und eine aus der zweiten. In diesem Fall werden nur die drei erforderlichen Partitionen in den Cluster kopiert und nicht alle Tabellen als Ganzes. Deshalb und gerade weil sich alles im Rahmen eines Rechenzentrums befindet und über sehr schnelle Kanäle verbunden ist, erfolgt der gesamte Pumpvorgang sehr schnell: in Sekunden, sehr selten - in Minuten, wenn es sich nicht um monströse Anfragen handelt ... Dementsprechend werden Mikropartitionen in einen Rechencluster kopiert, und nach Abschluss wird eine SQL-Abfrage auf diesem Rechencluster ausgeführt. Das Ergebnis dieser Abfrage kann eine Zeile, mehrere Zeilen oder eine Tabelle sein - sie werden an den Benutzer gesendet.damit es heruntergeladen, in seinem BI-Tool angezeigt oder auf andere Weise verwendet werden kann.
Jede SQL-Abfrage kann nicht nur Aggregate aus zuvor geladenen Daten lesen, sondern auch neue Daten in die Datenbank laden / bilden. Das heißt, es kann sich um eine Abfrage handeln, die beispielsweise neue Datensätze in eine andere Tabelle einfügt, was zum Auftreten einer neuen Partition im Rechencluster führt, die wiederum automatisch in einem einzelnen S3-Speicher gespeichert wird.
Das oben beschriebene Szenario, vom Eintreffen eines Benutzers bis zum Erhöhen des Clusters, Laden von Daten, Ausführen von Abfragen und Erhalten von Ergebnissen, wird mit der Rate pro Minute bezahlt, die bei Verwendung des erhöhten virtuellen Computerclusters Virtual Warehouse anfällt. Die Rate variiert je nach AWS-Zone und Clustergröße, beträgt jedoch im Durchschnitt einige US-Dollar pro Stunde. Eine Gruppe von vier Autos ist doppelt so teuer wie eine Gruppe von zwei Autos, und von acht Autos ist doppelt so teuer. Verfügbare Optionen von 16, 32 Autos, abhängig von der Komplexität der Anfragen. Sie zahlen jedoch nur für die Minuten, in denen der Cluster tatsächlich funktioniert, denn wenn keine Anforderungen vorliegen, nehmen Sie Ihre Hände ab und nach 5 bis 10 Minuten Wartezeit (ein konfigurierbarer Parameter) geht er von selbst aus, setzt Ressourcen frei und wird frei.
Das Szenario ist ziemlich real: Wenn Sie eine Anfrage stellen, wird der Cluster relativ gesehen in einer Minute angezeigt, es zählt eine weitere Minute, dann fünf Minuten bis zum Herunterfahren, und Sie zahlen als Ergebnis für sieben Minuten des Betriebs dieses Clusters und nicht für Monate und Jahre.
Das erste Szenario, das mit Snowflake in einem Einzelbenutzerszenario beschrieben wurde. Stellen wir uns nun vor, dass es viele Benutzer gibt, was einem realen Szenario näher kommt.
Nehmen wir an, wir haben viele Analysten und Tableau-Berichte, die unsere Datenbank ständig mit einer großen Anzahl einfacher analytischer SQL-Abfragen bombardieren.
Nehmen wir außerdem an, wir haben geniale Data Scientists, die versuchen, monströse Dinge mit Daten zu tun, mit Dutzenden von Terabytes zu arbeiten, Milliarden und Billionen von Datenzeilen zu analysieren.
Für die beiden oben beschriebenen Lasttypen können Sie mit Snowflake mehrere unabhängige Rechencluster mit unterschiedlichen Kapazitäten anheben. Darüber hinaus arbeiten diese Rechencluster unabhängig voneinander, jedoch mit gemeinsamen konsistenten Daten.
Für eine große Anzahl von leichten Abfragen können Sie 2-3 kleine Cluster mit herkömmlicher Größe und jeweils 2 Maschinen erstellen. Dieses Verhalten ist unter anderem mit automatischen Einstellungen realisierbar. Das heißt, Sie sagen: „Schneeflocke, heben Sie einen kleinen Haufen auf. Wenn die Belastung mehr als einen bestimmten Parameter erhöht, erhöhen Sie einen ähnlichen zweiten, dritten Wert. Wenn die Last nachlässt, löschen Sie die zusätzlichen. " Unabhängig davon, wie viele Analysten kommen und sich Berichte ansehen, verfügt jeder über genügend Ressourcen.
Wenn die Analysten schlafen und niemand die Berichte betrachtet, können die Cluster gleichzeitig vollständig gelöscht werden, und Sie zahlen nicht mehr für sie.
Gleichzeitig können Sie bei umfangreichen Abfragen (von Data Scientists) einen sehr großen Cluster pro bedingten 32 Computern erstellen. Dieser Cluster wird auch nur für die Minuten und Stunden in Rechnung gestellt, wenn Ihre riesige Anfrage dort ausgeführt wird.
Die oben beschriebene Funktion ermöglicht die Aufteilung in Cluster nicht nur in 2, sondern auch in mehr Lasttypen (ETL, Überwachung, Materialisierung von Berichten, ...).
Fassen wir die Schneeflocke zusammen. Die Basis kombiniert eine schöne Idee und eine praktikable Implementierung. Bei ManyChat verwenden wir Snowflake, um alle uns vorliegenden Daten zu analysieren. Wir haben nicht drei Cluster wie im Beispiel, sondern 5 bis 9 unterschiedlicher Größe. Wir haben bedingte 16-Maschinen, 2-Maschinen, es gibt auch superkleine 1-Maschinen für einige Aufgaben. Sie verteilen die Ladung erfolgreich und ermöglichen es uns, viel zu sparen.
Die Basis skaliert erfolgreich die Lese- und Schreibarbeitslast. Dies ist ein großer Unterschied und ein großer Durchbruch im Vergleich zu derselben "Aurora", die nur die Leselast gezogen hat. Mit Snowflake können diese Rechencluster Workloads skalieren und schreiben. Das heißt, wie bereits erwähnt, verwenden wir in ManyChat mehrere Cluster. Kleine und superkleine Cluster werden hauptsächlich für ETL zum Laden von Daten verwendet. Und Analysten leben bereits von mittelgroßen Clustern, die von der ETL-Last absolut nicht betroffen sind, sodass sie sehr schnell arbeiten.
Dementsprechend ist die Basis für OLAP-Aufgaben gut geeignet. Gleichzeitig ist es leider noch nicht für OLTP-Workloads anwendbar. Erstens ist diese Basis säulenförmig mit allen sich daraus ergebenden Konsequenzen. Zweitens ist der Ansatz selbst, wenn Sie für jede Anforderung bei Bedarf einen Rechencluster auslösen und ihn mit Daten verschütten, leider für OLTP-Workloads immer noch nicht schnell genug. Sekunden auf OLAP-Aufgaben zu warten ist normal, aber für OLTP-Aufgaben ist es nicht akzeptabel, 100 ms wären besser und noch besser - 10 ms.
Ergebnis
Eine serverlose Datenbank ist möglich, indem die Datenbank in zustandslose und zustandsbehaftete Teile unterteilt wird. Sie müssen bemerkt haben, dass in allen angegebenen Beispielen der Stateful-Teil relativ gesehen Mikropartitionen in S3 speichert und Stateless ein Optimierer ist, der mit Metadaten arbeitet und Sicherheitsprobleme behandelt, die als eigenständiges Lightweight behandelt werden können Staatenlose Dienste.
Das Ausführen von SQL-Abfragen kann auch als Light-State-Dienste betrachtet werden, die im serverlosen Modus angezeigt werden können, z. B. Snowflake-Rechencluster, nur die benötigten Daten herunterladen, die Abfrage ausführen und "ausgehen".
Serverlose Datenbanken auf Produktionsebene stehen bereits zur Verfügung und funktionieren. Diese serverlosen Datenbanken sind bereits für OLAP-Aufgaben bereit. Leider werden sie für OLTP-Aufgaben verwendet ... mit Nuancen, da es Einschränkungen gibt. Dies ist einerseits ein Minus. Auf der anderen Seite ist dies eine Gelegenheit. Vielleicht finden einige der Leser einen Weg, die OLTP-Basis ohne die Einschränkungen von Aurora vollständig serverlos zu machen.
Hoffe du fandest es interessant. Serverlos ist die Zukunft :)