
Journaling ist eines der Dinge, an die man sich nur erinnert, wenn sie kaputt gehen. Und das ist überhaupt keine Kritik. Der Punkt ist, dass Protokolle als solche kein Geld verdienen. Sie bieten Einblicke in die Programme (oder haben sie durchgeführt) und helfen dabei, Dinge am Laufen zu halten, mit denen wir Geld verdienen. In kleinem Maßstab (oder während der Entwicklung) können die erforderlichen Informationen durch einfaches Anzeigen von Nachrichten in erhalten werden
stdout... Sobald Sie jedoch zu einem verteilten System wechseln und diese Nachrichten sofort zusammenfassen müssen, müssen Sie sie an ein zentrales Repository senden, wo sie den größten Nutzen bringen. Dieser Bedarf ist umso relevanter, wenn Sie mit Containern auf einer Plattform wie Kubernetes arbeiten, auf der Prozesse und lokaler Speicher kurzlebig sind.
Ein vertrauter Ansatz zur Verarbeitung von Protokollen
Seit den Anfängen von Containern und der Veröffentlichung des Zwölf-Faktoren-Manifests hat sich bei der Verarbeitung von von Containern erzeugten Protokollen ein bestimmtes allgemeines Muster gebildet:
- verarbeitet Ausgangsnachrichten an
stdoutoderstderr, -
containerd(Docker) leitet Standard-Streams an Dateien außerhalb von Containern weiter. - und der Log Forwarder Tail liest diese Dateien (d. h. erhält die letzten Zeilen von ihnen) und sendet die Daten an die Datenbank.
Der beliebte Log Forwarder Fluentd ist ein CNCF- Projekt (wie Containerd). Im Laufe der Zeit wurde es zum De-facto-Standard für das Lesen, Transformieren, Übertragen und Indizieren von Protokollen. Wenn Sie einen Kubernetes- Cluster auf GKE mit verbundenem Cloud Logging (ehemals Stackdriver) erstellen, erhalten Sie fast das gleiche Muster - nur mit der fließenden Variante von Google.
Es war dieses Muster, das entstand, als Olark (die Firma, für die der Autor des Artikels arbeitet - ca. Transl.)begann vor vier Jahren als GKE mit der Migration von Diensten auf K8s. Und als wir die Protokollierung als Service übertroffen haben, wurde dieses Muster befolgt und unser eigenes Protokollaggregationssystem erstellt, das in der Lage ist, 15 bis 20.000 Zeilen pro Sekunde bei Spitzenlast zu verarbeiten.
Es gibt Gründe, warum dieser Ansatz gut funktioniert und warum die 12-Faktor-Prinzipien die Ausgabe von Protokollen in Standard-Streams direkt empfehlen . Tatsache ist, dass die Anwendung sich keine Gedanken über das Protokollrouting machen muss und Container während der Entwicklung oder in der Produktion leicht "beobachtbar" sind (wir sprechen von Beobachtbarkeit) . Und wenn Ihr Protokollierungssystem kaputt geht, besteht zumindest die Möglichkeit, dass die Protokolle auf den Hostdatenträgern des Clusterknotens verbleiben.
Der Nachteil dieses Ansatzes besteht darin, dass das Tailing von Protokollen im Hinblick auf die CPU-Auslastung relativ teuer ist . Wir haben begonnen, darauf zu achten, nachdem sich bei der nächsten Optimierung des Protokollierungssystems herausstellte, dass fluentd 1/8 des gesamten Kontingents an CPU-Anforderungen in der Produktion verbraucht:
- Dies ist teilweise auf die Clustertopologie zurückzuführen: fluentd wird auf jedem Knoten gehostet, um lokale Dateien zu überwachen (wie DaemonSet in der K8-Sprache), Sie haben Quad-Core-Knoten und Sie müssen 50% des Kerns für die Verarbeitung von Protokollen reservieren, und ... nun, Sie haben die Idee.
- Ein weiterer Teil der Ressourcen wird für die Textverarbeitung aufgewendet, die wir auch fließend zuweisen. Wer würde die Gelegenheit verpassen, verschleierte Protokolleinträge zu bereinigen?
- Der Rest geht an inotifywait , das Dateien auf der Festplatte überwacht, Lesevorgänge verarbeitet und den Überblick behält.
Wir wollten wissen, wie viel das alles kostet: Es gibt andere Möglichkeiten, Protokolle an fluentd zu senden. Zum Beispiel können Sie den Forward-Port verwenden (wir sprechen über die Verwendung von type
forwardin source- ca. Transl.). Wird es billiger sein?
Praktisches Experiment
Um die Kosten für das Abrufen von Protokolllinien mithilfe von Tailing zu isolieren, habe ich einen kleinen Prüfstand zusammengestellt . Es enthält die folgenden Komponenten:
- Python-Programm zum Erstellen einer bestimmten Anzahl von Protokollschreibern mit konfigurierbarer Nachrichtenhäufigkeit und -größe;
- Datei für Docker Compose läuft:
- fließend für die Verarbeitung von Protokollen,
- cAdvisor zur Überwachung des fließenden Behälters,
- Prometheus für das Sammeln von cAdvisor-Metriken,
- Grafana zur Datenvisualisierung in Prometheus.
Hinweise zu diesem Diagramm:
- Protokollschreiber generieren Nachrichten in einem einheitlichen JSON-Format (das auch Containerd verwendet) und können sie entweder in Dateien schreiben oder an den fließenden Forward-Port weiterleiten.
- Beim Schreiben in Dateien wird eine Klasse verwendet
RotatingFileHandler, um die Clusterbedingungen besser zu simulieren. - Fluentd ist so konfiguriert, dass alle Datensätze "durchgeworfen" werden
nullund keine regulären Ausdrücke verarbeitet oder Datensätze auf Tags überprüft werden. Daher wird seine Hauptaufgabe darin bestehen, die Protokollzeilen zu erhalten. - , Prometheus cAdvisor, fluentd.
Die Auswahl der zu vergleichenden Parameter erfolgte eher subjektiv. Ich habe ein weiteres Dienstprogramm zum Schätzen des Protokollvolumens geschrieben, das von Knoten aus unserem Cluster generiert wird. Es überrascht nicht, dass es sehr unterschiedlich ist: von mehreren zehn Zeilen pro Sekunde bis zu 500 oder mehr an den am stärksten frequentierten Knoten.
Dies ist eine weitere Problemquelle: Wenn Sie ein DaemonSet verwenden, muss fluentd so konfiguriert werden, dass es die am stärksten ausgelasteten Knoten im Cluster verarbeitet. Im Prinzip kann das Ungleichgewicht vermieden werden, indem den Hauptprotokollgeneratoren geeignete Beschriftungen zugewiesen werden und weiche Anti-Affinitätsregeln verwendet werden , um sie gleichmäßig zu verteilen. Dies geht jedoch über den Rahmen dieses Artikels hinaus. Zunächst wollte ich verschiedene Mechanismen der "Zustellung" von Protokollen vergleichenbei einer Last von 500/1000 Zeilen pro Sekunde mit 1 bis 10 Protokollschreibern.
Testergebnisse
Frühe Tests zeigten, dass Zeilen pro Sekunde den Hauptbeitrag zur CPU-Auslastung beim Tailing leisten , unabhängig davon, wie viele Protokolldateien wir beobachtet haben. Die beiden folgenden Grafiken vergleichen die Last mit 1000 p / s von einem Protokollschreiber und von 10. Es ist ersichtlich, dass sie fast gleich sind:
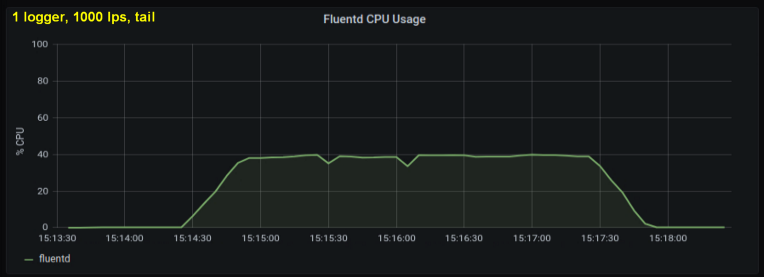
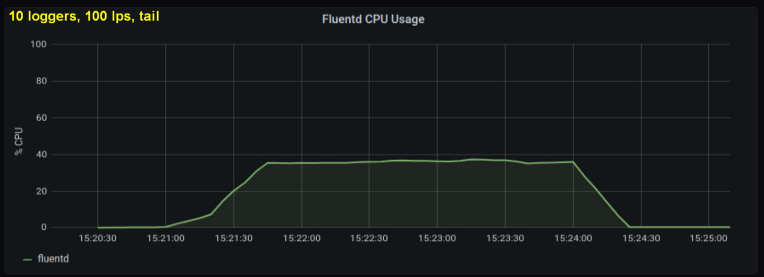
Ein kleiner Exkurs: Ich habe die entsprechende Grafik hier nicht eingefügt, aber auf meinem Computer stellte sich heraus, dass zehn Protokollprozesse durchgeführt wurden Das Schreiben von 100 Zeilen pro Sekunde hat einen höheren Gesamtdurchsatz als ein einzelner Prozess, der 1000 Zeilen pro Sekunde schreibt. Dies kann an den Besonderheiten meines Codes liegen - ich habe mich nicht absichtlich mit diesem Thema befasst.
Auf jeden Fall habe ich erwartet, dass die Anzahl der geöffneten Protokolldateien ein wesentlicher Faktor ist, aber es stellte sich heraus, dass dies die Ergebnisse nicht wirklich beeinflusst. Eine andere solche unbedeutende Variable ist die Länge der Zeichenfolge. Der obige Test verwendete eine Standardzeichenfolgenlänge von 100 Zeichen. Ich habe zehnmal längere Läufe mit Zeilen durchgeführt, aber dies hatte keinen merklichen Einfluss auf die Prozessorlast während des Tests, der in allen Fällen 180 Sekunden betrug.
In Anbetracht des oben Gesagten habe ich mich entschlossen, zwei Autoren zu testen, da es mir so schien, als würde ein Prozess eine interne Grenze erreichen. Andererseits wurden auch keine weiteren Prozesse benötigt. Hat Tests mit 500 und 1000 Zeilen pro Sekunde durchgeführt. Die folgenden Diagramme zeigen die Ergebnisse sowohl für Tailing-Dateien als auch für den Forward-Port:

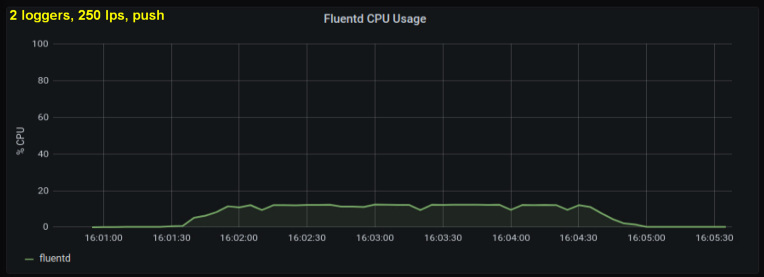
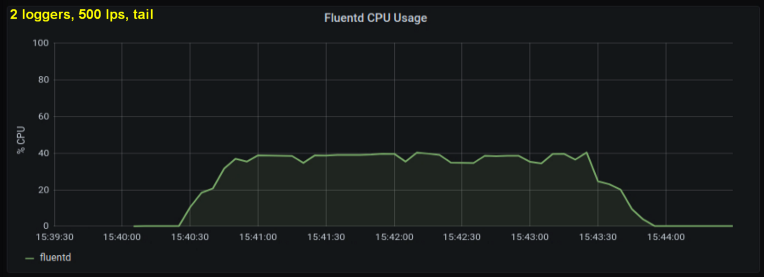

Schlussfolgerungen
Im Laufe einer Woche habe ich diese Tests auf viele verschiedene Arten durchgeführt und dabei zwei wichtige Schlussfolgerungen gezogen:
- Die Methode mit einem Forward-Socket verbraucht durchweg 30-50% weniger Rechenleistung als das Lesen von Zeilen aus Protokolldateien gleicher Größe. Eine mögliche Erklärung (zumindest für einen Teil des beobachtbaren Unterschieds) ist die Serialisierung der Daten im Nachrichtenpaket - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


Bedeuten diese Ergebnisse, dass wir alle anstelle von Dateien Protokolle in den Socket schreiben sollten? Offensichtlich ist es nicht so einfach ...
Wenn wir die Art und Weise, wie wir Protokolle sammeln, so einfach ändern könnten, wären die meisten der vorhandenen Probleme keine Probleme. Die Ausgabe von Protokollen
stdouterleichtert die Überwachung und Arbeit mit Containern während der Entwicklung erheblich. Das Ausgeben von Protokollen auf beide Arten erhöht je nach Kontext die Komplexität erheblich. In ähnlicher Weise wird das Einrichten von Fluentd zum Rendern von Protokollen während der Entwicklung (z. B. mithilfe des Ausgabe-Plugins stdout) erhöht .
Eine praktischere Interpretation dieser Ergebnisse wäre möglicherweise eine Empfehlung zur Vergrößerung der Knoten... Da fluentd für die Arbeit mit den am stärksten frequentierten (lautesten) Knoten konfiguriert werden muss, ist es logisch, deren Anzahl zu reduzieren. In Kombination mit einem Anti-Affinitäts-Mechanismus, der die Hauptprotokollgeneratoren gleichmäßig verteilt, wäre dies eine großartige Strategie. Leider erfordert die Größenänderung von Knoten viele Nuancen und Kompromisse, die weit über die Anforderungen des Protokollierungssystems hinausgehen.
Skalierung ist natürlich auch wichtig... Im kleinen Maßstab ist die Unannehmlichkeit und zusätzliche Komplexität vielleicht nicht praktikabel. Darüber hinaus gibt es in der Regel dringlichere Probleme. Wenn Sie gerade erst anfangen und der Geruch von "frischer Farbe" nicht aus dem Engineering-Prozess verschwunden ist, können Sie Ihr Protokollierungsformat im Voraus standardisieren und die Kosten mithilfe der Socket-Methode senken, ohne die Entwickler zu überfordern.
Für diejenigen, die mit Großprojekten arbeiten, sind die Schlussfolgerungen dieses Artikels unangemessen, da Unternehmen wie Google das Problem (im Vergleich zu meinem) viel gründlicher und wissensintensiver analysiert haben. In dieser Größenordnung stellen Sie offensichtlich Ihre eigenen Cluster bereit und können mit der Protokollierungspipeline alles tun, was Sie wollen (mit anderen Worten, nutzen Sie beide Ansätze).
Lassen Sie mich abschließend einige Fragen vorwegnehmen und im Voraus beantworten. Erstens: „Geht es in diesem Artikel nicht wirklich um fließend ? Und was hat das mit Kubernetes im Allgemeinen zu tun ? " ... Die Antwort auf beide Seiten dieser Frage lautet: "Nun, vielleicht ."
- Nach meinem allgemeinen Verständnis und meiner Erfahrung tritt dieses Tool häufig auf, wenn Dateien unter Linux in Situationen mit vielen Festplatten-E / A-Vorgängen verwaltet werden. Ich habe keine Tests mit einem anderen Log Forwarder wie Logstash durchgeführt , aber es wäre interessant, die Ergebnisse zu sehen.
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
Zum Schluss noch ein paar Worte zu einer anderen verbrauchbaren Ressource - dem Speicher . Ursprünglich wollte ich es in den Artikel aufnehmen: Ein speziell dafür vorbereitetes Dashboard zeigt die Speichernutzung von fluentd. Am Ende stellte sich jedoch heraus, dass dieser Faktor nicht wichtig ist. Den Testergebnissen zufolge betrug die maximal verwendete Speichermenge 85 MB nicht, wobei der Unterschied zwischen einzelnen Tests selten 10 MB überschritt. Dieser eher geringe Speicherverbrauch ist offensichtlich darauf zurückzuführen, dass ich keine gepufferten Ausgangs-Plugins verwendet habe . Noch wichtiger ist, dass es für beide Methoden fast gleich war. Und der Artikel wurde schon zu umfangreich ...
Es sollte beachtet werden, dass es viel mehr "Ecken" gibt, in die Sie schauen können, wenn Sie eingehendere Tests durchführen möchten. Sie können beispielsweise herausfinden, in welchen Prozessorzuständen und Systemaufrufen fluentd die meiste Zeit verbringt. Dazu müssen Sie jedoch den entsprechenden Wrapper dafür erstellen.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: