Daher gibt es in jedem einzelnen Prozess keine traditionellen "seltsamen" Probleme mit paralleler Codeausführung, Sperren, Rennbedingungen usw. Und die Entwicklung des DBMS selbst ist angenehm und einfach.
Die gleiche Einfachheit führt jedoch zu einer erheblichen Einschränkung. Da der Prozess nur einen Worker-Thread enthält, kann er nicht mehr als einen CPU-Kern zum Ausführen einer Anforderung verwenden . Dies bedeutet, dass die Geschwindigkeit des Servers direkt von der Häufigkeit und Architektur eines separaten Kerns abhängt.
In unserer Zeit des beendeten "Megahertz-Rennens" und der siegreichen Multicore- und Multiprozessorsysteme ist ein solches Verhalten ein inakzeptabler Luxus und eine Verschwendung. Ab PostgreSQL 9.6 können daher bei der Verarbeitung einer Abfrage einige Vorgänge von mehreren Prozessen gleichzeitig ausgeführt werden.
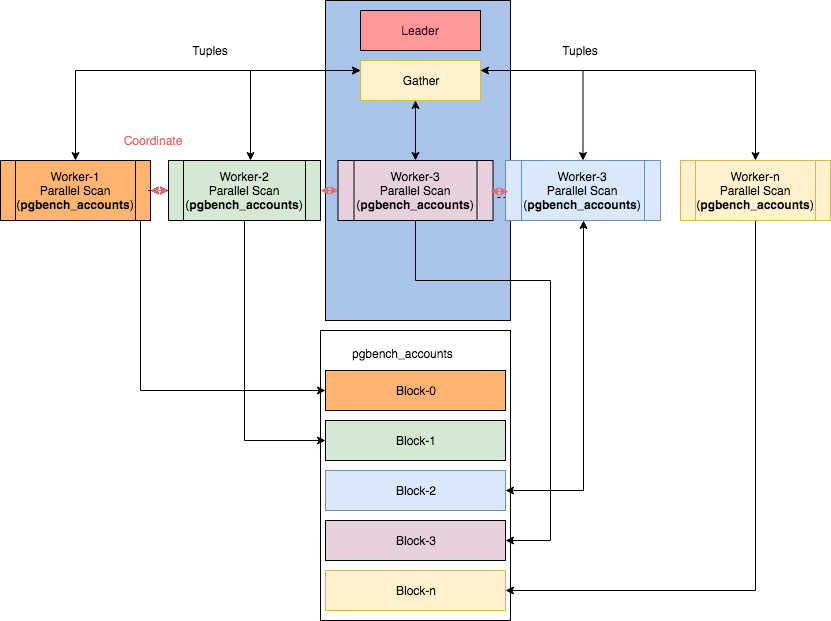
Die Funktionsweise einiger paralleler Knoten können Sie im Artikel "Parallelität in PostgreSQL" von Ibrar Ahmed kennenlernen, aus dem dieses Bild stammt.In diesem Fall wird es jedoch nicht trivial, die Pläne zu lesen.
Kurz gesagt sieht die Chronologie der Implementierung der parallelen Ausführung von Planoperationen folgendermaßen aus:
- 9.6 - Grundfunktionen: Seq Scan , Join, Aggregate
- 10 - Index-Scan (für btree), Bitmap-Heap-Scan, Hash-Join, Merge-Join, Unterabfrage-Scan
- 11 - Gruppenoperationen : Hash Join mit gemeinsam genutzter Hash-Tabelle, Anhängen (UNION)
- 12 - Grundlegende Statistiken pro Mitarbeiter zu Plan-Knoten
- 13 - detaillierte Statistiken pro Arbeitnehmer
Wenn Sie eine der neuesten PostgreSQL-Versionen verwenden, ist die Wahrscheinlichkeit
Parallel ...sehr hoch, dass sie im Plan angezeigt wird. Und mit ihm kommen sie und ...
Seltsamkeiten im Laufe der Zeit
Werfen wir einen Plan von PostgreSQL 9.6 :
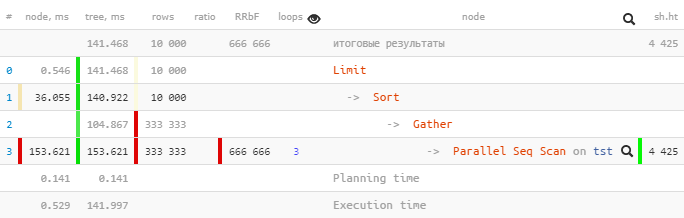
[Blick auf explain.tensor.ru]
Nur einer wurde
Parallel Seq Scanausgeführt 153,621 ms innerhalb eines Unterbaums, und Gatherzusammen mit allen untergeordneten Knoten - nur 104,867 ms.
Wieso das? Ist die Gesamtzeit "oben" kürzer geworden? ..
Schauen wir uns den
GatherKnoten genauer an:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2sagt uns, dass zusätzlich zu dem Hauptprozess unter dem Baum 2 weitere beteiligt waren - insgesamt 3. Daher ist alles, was innerhalb des GatherTeilbaums passiert ist, die Gesamtkreativität aller 3 Prozesse gleichzeitig.
Nun wollen wir sehen, was da drin ist
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425Aha!
loops=3Ist eine Zusammenfassung aller 3 Prozesse. Und im Durchschnitt dauerte jeder dieser Zyklen 51,207 ms. Das heißt, der Server hat 51.207 x 3 = 153.621Millisekunden Prozessorzeit benötigt , um diesen Knoten fertigzustellen . Das heißt, wenn wir verstehen wollen, "was der Server getan hat", hilft uns diese Nummer zu verstehen.
Beachten Sie, dass Sie zum Verständnis der "tatsächlichen" Ausführungszeit die Gesamtzeit durch die Anzahl der Mitarbeiter dividieren müssen [actual time] x [loops] / [Workers Launched].
In unserem Beispiel hat jeder Worker daher nur einen Zyklus durch den Knoten ausgeführt
153.621 / 3 = 51.207. Und ja, jetzt ist es nichts Seltsames, dass der einzige Gatherim Kopfprozess "sozusagen in kürzerer Zeit" abgeschlossen wurde.
Gesamt: Sehen Sie sich EXPLAIN.tensor.ru die Gesamtknotenzeit (für alle Prozesse) an, um zu verstehen, mit welcher Art von Last Ihr Server beschäftigt war, und um zu optimieren, welcher Teil der Abfrage Zeit wert ist.
In diesem Sinne erscheint das Verhalten derselben EXPLAIN.DEPESZ.com , das die "reale durchschnittliche" Zeit auf einmal anzeigt , für Debugging-Zwecke weniger nützlich: Stimmen
Sie nicht zu? Willkommen zu den Kommentaren!
Gather Merge verliert alles
Lassen Sie uns nun dieselbe Abfrage für PostgreSQL 10- Versionen ausführen :
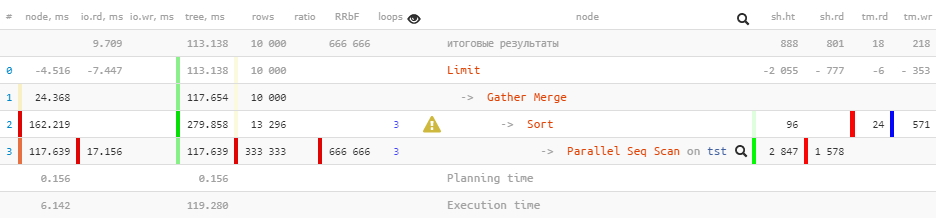
[siehe EXPLAIN.tensor.ru]
Beachten Sie, dass wir
Gatherjetzt einen Knoten anstelle eines Knotens im Plan haben Gather Merge. Das Handbuch dazu sagt Folgendes :
Wenn sich ein Knoten über dem parallelen Teil des Plans befindetGather Merge,Gatherbedeutet dies, dass alle Prozesse, die die Teile des parallelen Plans ausführen, Tupel in sortierter Reihenfolge ausgeben und dass der führende Prozess eine auftragserhaltende Zusammenführung durchführt. Der KnotenGatherhingegen empfängt Tupel von untergeordneten Prozessen in einer für ihn geeigneten willkürlichen Reihenfolge, wodurch die möglicherweise vorhandene Sortierreihenfolge verletzt wird.
Aber im dänischen Königreich ist nicht alles in Ordnung:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156Beim Übergeben von Attributen
Buffersund I/O Timingsim Baum gingen einige Daten vorzeitig verloren . Wir können die Größe dieses Verlusts auf nur etwa 2/3 schätzen , die durch Hilfsprozesse gebildet werden.
Leider gibt es im Plan selbst keinen Ort, an dem diese Informationen abgerufen werden können - daher die "Minuspunkte" auf dem darüber liegenden Knoten. Wenn Sie sich die weitere Entwicklung dieses Plans in PostgreSQL 12 ansehen , ändert sich dies nicht grundlegend, außer dass für jeden Worker auf dem
Sort-node einige Statistiken hinzugefügt werden :
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msInsgesamt: Vertraue den obigen Knotendaten nicht
Gather Merge.