
Als ich meine Karriere als Entwickler begann, war mein erster Job ein DBA (Datenbankadministrator, DBA). In diesen Jahren gab es bereits vor AWS RDS, Azure, Google Cloud und anderen Cloud-Diensten zwei Arten von Datenbankadministratoren:
- , . « », , .
- : , , SQL. ETL- . , .
Anwendungs-DBAs waren normalerweise Teil von Entwicklungsteams. Sie hatten tiefes Wissen über ein bestimmtes Thema und arbeiteten normalerweise nur an einem oder zwei Projekten. Infrastruktur-Datenbankadministratoren waren normalerweise Teil des IT-Teams und konnten gleichzeitig an mehreren Projekten arbeiten.
Ich bin der Administrator der Anwendungsdatenbank
Ich hatte nie das Bedürfnis, mit Backups herumzuspielen oder Speicher zu optimieren (ich bin sicher, es macht Spaß!). Bis heute möchte ich sagen, dass ich ein DB-Administrator bin, der weiß, wie man Anwendungen entwickelt, und kein Entwickler, der Datenbanken versteht.
In diesem Artikel werde ich einige der Tricks zur Datenbankentwicklung vorstellen, die ich im Laufe meiner Karriere gelernt habe.
Inhalt:
- Aktualisieren Sie nur das, was aktualisiert werden muss
- Deaktivieren Sie Einschränkungen und Indizes für schwere Lasten
- Verwenden Sie UNLOGGED-Tabellen für Zwischendaten
- Implementieren Sie ganze Prozesse mit WITH und RETURNING
- Vermeiden Sie Indizes in Spalten mit geringer Selektivität
- Verwenden Sie Teilindizes
- Laden Sie immer sortierte Daten
- Stark korrelierter Spaltenindex mit BRIN
- Indizes "unsichtbar" machen
- Planen Sie keine langen Prozesse so ein, dass sie zu Beginn einer Stunde beginnen
- Fazit
Aktualisieren Sie nur das, was aktualisiert werden muss
Die Operation
UPDATEverbraucht ziemlich viele Ressourcen. Der beste Weg, dies zu beschleunigen, besteht darin, nur das zu aktualisieren, was aktualisiert werden muss.
Hier ist ein Beispiel für eine Anforderung zum Normalisieren einer E-Mail-Spalte:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
Sieht unschuldig aus, oder? Die Anforderung aktualisiert die E-Mail-Adressen für 1.010.000 Benutzer. Aber müssen alle Zeilen aktualisiert werden?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Es mussten nur 10.000 Zeilen aktualisiert werden. Durch die Reduzierung der verarbeiteten Datenmenge haben wir die Ausführungszeit von 1,5 Sekunden auf weniger als 300 ms reduziert. Dies erspart uns auch weitere Anstrengungen bei der Pflege der Datenbank.
Aktualisieren Sie nur, was aktualisiert werden muss.
Diese Art von umfangreichen Updates ist in Datenmigrationsskripten sehr verbreitet. Wenn Sie das nächste Mal ein solches Skript schreiben, müssen Sie nur das aktualisieren, was benötigt wird.
Deaktivieren Sie Einschränkungen und Indizes für schwere Lasten
Einschränkungen sind ein wichtiger Bestandteil relationaler Datenbanken: Sie bewahren die Konsistenz und Zuverlässigkeit der Daten. Aber alles hat seinen eigenen Preis, und meistens müssen Sie beim Laden oder Aktualisieren einer großen Anzahl von Zeilen bezahlen.
Definieren wir ein kleines Speicherschema:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
Es werden verschiedene Arten von Einschränkungen definiert, z. B. "nicht null" sowie eindeutige Einschränkungen.
Um den Startpunkt festzulegen, fügen wir der Tabelle
saleFremdschlüssel hinzu
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
Nach dem Definieren der Einschränkungen und Indizes dauerte das Laden einer Million Zeilen in die Tabelle etwa 15,4 Sekunden.
Laden wir zunächst die Daten in die Tabelle und fügen erst dann Einschränkungen und Indizes hinzu:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
Das Laden war mit 2,27 Sekunden viel schneller. statt 15.4. Indizes und Limits wurden nach dem Laden der Daten viel länger erstellt, aber der gesamte Prozess war viel schneller: 3,1 s. statt 15.4.
Leider können Sie in PostgreSQL nicht dasselbe mit Indizes tun, sondern sie nur wegwerfen und neu erstellen. In anderen Datenbanken wie Oracle können Sie Indizes deaktivieren und aktivieren, ohne sie neu erstellen zu müssen.
UNLOGGED-
Wenn Sie Daten in PostgreSQL ändern, werden die Änderungen in das Write Ahead-Protokoll (WAL ) geschrieben. Es wird verwendet, um die Konsistenz aufrechtzuerhalten, während der Wiederherstellung schnell neu zu indizieren und die Replikation aufrechtzuerhalten.
Das Schreiben an WAL ist häufig erforderlich, aber es gibt einige Umstände, unter denen Sie WAL deaktivieren können, um die Arbeit zu beschleunigen. Zum Beispiel im Fall von Staging-Tabellen.
Zwischentabellen werden als Einmal-Tabellen bezeichnet, in denen temporäre Daten gespeichert werden, die zur Implementierung einiger Prozesse verwendet werden. In ETL-Prozessen ist es beispielsweise sehr üblich, Daten aus CSV-Dateien in Staging-Tabellen zu laden, die Informationen zu löschen und sie dann in die Zieltabelle zu laden. In diesem Szenario wird die Staging-Tabelle einmalig verwendet und nicht in Sicherungen oder Replikaten verwendet.
UNLOGGED Tabelle.
Staging-Tabellen, die im Fehlerfall nicht wiederhergestellt werden müssen und in Replikaten nicht benötigt werden, können als UNLOGGED festgelegt werden :
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
Achtung :
UNLOGGEDVergewissern Sie sich vor der Verwendung , dass Sie alle Auswirkungen vollständig verstanden haben.
Implementieren Sie ganze Prozesse mit WITH und RETURNING
Angenommen, Sie haben eine Benutzertabelle und stellen fest, dass sie doppelte Daten enthält:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
Benutzer haki benita zweimal registriert, mit mail
ME@hakibenita.comund me@hakibenita.com. Da wir E-Mail-Adressen bei der Eingabe in die Tabelle nicht normalisieren, müssen wir uns jetzt mit Duplikaten befassen.
Wir müssen:
- Identifizieren Sie doppelte Adressen in Kleinbuchstaben und verknüpfen Sie doppelte Benutzer miteinander.
- Aktualisieren Sie Bestellungen so, dass sie nur auf eines der Duplikate verweisen.
- Entfernen Sie Duplikate aus der Tabelle.
Sie können doppelte Benutzer mithilfe einer Staging-Tabelle verknüpfen:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
Die Zwischentabelle enthält Verknüpfungen zwischen Takes. Wenn ein Benutzer mit einer normalisierten E-Mail-Adresse mehrmals vorkommt, weisen wir ihm eine Mindestbenutzer-ID zu, in die wir alle Duplikate reduzieren. Der Rest der Benutzer wird in der Array-Spalte gespeichert und alle Verweise auf sie werden aktualisiert.
Mithilfe der Zwischentabelle aktualisieren wir die Links zu Duplikaten in der Tabelle
orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Jetzt können Sie Duplikate sicher entfernen aus
users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
Beachten Sie, dass wir die unnest- Funktion verwendet haben, um das Array zu "transformieren" , wodurch jedes Element in eine Zeichenfolge umgewandelt wird.
Ergebnis:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Großartig, alle user
3( ME@hakibenita.com) - Instanzen werden in user 2( me@hakibenita.com) konvertiert .
Wir können auch überprüfen, ob Duplikate aus der Tabelle entfernt wurden
users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
Jetzt können wir die Staging-Tabelle loswerden:
db=# DROP TABLE duplicate_users;
DROP TABLE
Alles ist gut, aber zu lang und muss gereinigt werden! Gibt es einen besseren Weg?
Generalisierte Tabellenausdrücke (CTE)
Mit generischen Tabellenausdrücken , auch als Ausdrücke bezeichnet
WITH, können wir die gesamte Prozedur mit einem einzigen SQL-Ausdruck ausführen:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
Anstelle einer Staging-Tabelle haben wir einen generischen Tabellenausdruck erstellt und wiederverwendet.
Ergebnisse vom CTE zurückgeben
Einer der Vorteile der Ausführung von DML innerhalb eines Ausdrucks
WITHbesteht darin, dass Sie mit dem Schlüsselwort RETURNING Daten daraus zurückgeben können . Angenommen, wir benötigen einen Bericht über die Anzahl der aktualisierten und gelöschten Zeilen:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Ergebnis:
orders_updated | users_deleted
----------------+---------------
2 | 1
Das Schöne an diesem Ansatz ist, dass der gesamte Prozess mit einem einzigen Befehl ausgeführt wird, sodass Sie bei einem Prozessfehler keine Transaktionen verwalten oder sich Gedanken über das Leeren der Staging-Tabelle machen müssen.
Warnung : Ein Reddit-Leser hat mich auf das mögliche unvorhersehbare Verhalten der DML-Ausführung in generischen Tabellenausdrücken hingewiesen :
Die Unterausdrücke inWITHwerden gleichzeitig und mit der Hauptabfrage ausgeführt. Daher istWITHdie tatsächliche Reihenfolge der Aktualisierungen bei Verwendung in datenmodifizierenden Ausdrücken nicht vorhersehbar.
Dies bedeutet, dass Sie sich nicht auf die Reihenfolge verlassen können, in der unabhängige Unterausdrücke ausgeführt werden. Es stellt sich heraus, dass Sie sich bei einer Abhängigkeit zwischen ihnen, wie im obigen Beispiel, auf die Ausführung des abhängigen Unterausdrucks verlassen können, bevor Sie sie verwenden.
Vermeiden Sie Indizes in Spalten mit geringer Selektivität
Angenommen, Sie haben einen Anmeldevorgang, bei dem sich ein Benutzer unter einer E-Mail-Adresse anmeldet. Um Ihr Konto zu aktivieren, müssen Sie Ihre E-Mails überprüfen. Die Tabelle könnte folgendermaßen aussehen:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
Die meisten Ihrer Benutzer sind bürgerbewusst, registrieren sich mit der richtigen Postanschrift und aktivieren sofort das Konto. Füllen wir die Tabelle mit Benutzerdaten und nehmen an, dass 90% der Benutzer aktiviert sind:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
Um die Anzahl der aktivierten und nicht aktivierten Benutzer abzufragen, können Sie einen Index nach Spalten erstellen
activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
Wenn Sie nach der Anzahl der nicht aktivierten Benutzer fragen , verwendet die Basis den Index:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
Die Basis entschied, dass der Filter 102.567 Elemente zurückgeben würde, was ungefähr 10% der Tabelle entspricht. Dies stimmt mit den von uns geladenen Daten überein, sodass die Tabelle gute Arbeit geleistet hat.
Wenn wir jedoch die Anzahl der aktivierten Benutzer abfragen , stellen wir fest, dass die Datenbank entschieden hat, den Index nicht zu verwenden :
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
Viele Entwickler sind verwirrt, wenn die Datenbank den Index nicht verwendet. Um zu erklären, warum dies so ist , würden Sie Folgendes tun: Wenn Sie die gesamte Tabelle lesen müssten, würden Sie einen Index verwenden ?
Wahrscheinlich nicht, warum ist das notwendig? Das Lesen von der Festplatte ist teuer, daher sollten Sie so wenig wie möglich lesen. Wenn die Tabelle beispielsweise 10 MB und der Index 1 MB groß ist, müssen Sie zum Lesen der gesamten Tabelle 10 MB von der Festplatte lesen. Und wenn Sie einen Index hinzufügen, erhalten Sie 11 MB. Es ist verschwenderisch.
Schauen wir uns nun die Statistiken an, die PostgreSQL auf unserer Tabelle gesammelt hat:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
Als PostgreSQL die Tabelle analysierte, stellte es fest, dass die Spalte
activatedzwei verschiedene Werte enthielt . Der Wert tin der Spalte most_common_valsentspricht der Häufigkeit 0.89743334in der Spalte most_common_freqsund der Wert fentspricht der Häufigkeit 0.10256667. Nach der Analyse der Tabelle stellte die Datenbank fest, dass 89,74% der Datensätze aktivierte Benutzer und die restlichen 10,26% nicht aktiviert waren.
Basierend auf diesen Statistiken entschied PostgreSQL, dass es besser ist, die gesamte Tabelle zu scannen, als anzunehmen, dass 90% der Zeilen die Bedingung erfüllen. Der Schwellenwert, ab dem eine Basis entscheiden kann, ob ein Index verwendet werden soll, hängt von vielen Faktoren ab, und es gibt keine Faustregel.
Index für Spalten mit niedriger und hoher Selektivität.
Verwenden Sie Teilindizes
Im vorherigen Kapitel haben wir einen Index für eine boolesche Spalte erstellt, die ungefähr 90% der Datensätze enthält
true(aktivierte Benutzer).
Als wir nach der Anzahl der aktiven Benutzer fragten, verwendete die Datenbank den Index nicht. Bei der Frage nach der Anzahl der nicht aktivierten Daten verwendete die Datenbank den Index.
Es stellt sich die Frage: Wenn die Datenbank den Index nicht zum Herausfiltern aktiver Benutzer verwendet, warum sollten wir sie dann überhaupt indizieren?
Bevor wir diese Frage beantworten, schauen wir uns das Gewicht des vollständigen Index nach Spalten an
activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
Der Index wiegt 21 MB. Nur als Referenz: Die Tabelle mit Benutzern ist 65 MB groß. Das heißt, das Indexgewicht beträgt ~ 32% des Grundgewichts. Wir wissen jedoch, dass ~ 90% des Indexinhalts wahrscheinlich nicht verwendet werden.
In PostgreSQL können Sie einen Index nur für einen Teil einer Tabelle erstellen - den sogenannten Teilindex :
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
Wir verwenden einen Ausdruck
WHERE, um die vom Index abgedeckten Zeichenfolgen einzuschränken. Lassen Sie uns überprüfen, ob es funktioniert:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
Die Datenbank erwies sich als intelligent genug, um zu erkennen, dass der in unserer Abfrage verwendete Boolesche Ausdruck möglicherweise für einen Teilindex funktioniert.
Dieser Ansatz hat einen weiteren Vorteil:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
Der vollständige Spaltenindex wiegt 21 MB und der Teilindex beträgt nur 2,2 MB. Das sind 10%, was dem Anteil der nicht aktivierten Benutzer in der Tabelle entspricht.
Laden Sie immer sortierte Daten
Dies ist einer meiner häufigsten Kommentare beim Parsen von Code. Der Rat ist nicht so intuitiv wie die anderen und kann einen großen Einfluss auf die Produktivität haben.
Angenommen, Sie haben einen riesigen Tisch mit bestimmten Verkäufen:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Während des ETL-Prozesses laden Sie jede Nacht Daten in eine Tabelle:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Um den Download zu simulieren, verwenden wir zufällige Daten. Wir haben 100.000 Zeilen mit zufälligen Namen und die Verkaufstermine für den Zeitraum vom 1. Januar 2020 und zwei Jahre im Voraus eingefügt.
Zum größten Teil wird die Tabelle für zusammenfassende Verkaufsberichte verwendet. Meistens filtern sie nach Datum, um Verkäufe für einen bestimmten Zeitraum anzuzeigen. Um den Bereichsscan zu beschleunigen, erstellen wir einen Index mit
sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
Werfen wir einen Blick auf den Ausführungsplan für die Anforderung, alle Verkäufe im Juni 2020 abzurufen:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
Nachdem die Anforderung zum Aufwärmen des Caches mehrmals ausgeführt wurde, stabilisierte sich die Ausführungszeit auf dem Niveau von 6 ms.
Bitmap-Scan
In Bezug auf die Ausführung sehen wir, dass die Basis das Bitmap-Scannen verwendet hat. Es erfolgt in zwei Schritten:
(Bitmap Index Scan): Die Basis durchläuft den gesamten Indexsale_fact_sold_at_ixund findet alle Seiten in der Tabelle, die die relevanten Zeilen enthalten.(Bitmap Heap Scan): Die Basis liest die Seiten mit den relevanten Zeichenfolgen und findet diejenigen, die die Bedingung erfüllen.
Seiten können viele Zeilen enthalten. Im ersten Schritt wird der Index verwendet, um Seiten zu finden . Die zweite Stufe sucht nach Zeilen in Seiten, daher folgt die Operation
Recheck Condim Ausführungsplan.
Zu diesem Zeitpunkt werden viele Datenbankadministratoren und Entwickler abrunden und mit der nächsten Abfrage fortfahren. Es gibt jedoch eine Möglichkeit, diese Abfrage zu verbessern.
Index-Scan
Nehmen wir eine kleine Änderung am Laden der Daten vor.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Diesmal haben wir Daten sortiert nach geladen
sold_at.
Der Ausführungsplan für dieselbe Abfrage sieht nun folgendermaßen aus:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
Nach mehreren Läufen stabilisierte sich die Ausführungszeit bei 2,3 ms. Wir haben nachhaltige Einsparungen von rund 60% erzielt.
Wir sehen auch, dass die Datenbank diesmal kein Bitmap-Scannen verwendete, sondern einen "normalen" Index-Scan anwendete. Warum?
Korrelation
Wenn die Datenbank die Tabelle analysiert, sammelt sie alle Statistiken, die sie erhalten kann. Einer der Parameter ist die Korrelation :
Statistische Korrelation zwischen der physischen Reihenfolge der Zeilen und der logischen Reihenfolge der Werte in Spalten. Wenn der Wert bei -1 oder +1 liegt, wird ein Index-Scan für die Spalte als vorteilhafter angesehen als bei einem Korrelationswert von etwa 0, da die Anzahl der zufälligen Festplattenzugriffe verringert wird.
Wie in der offiziellen Dokumentation erläutert, ist die Korrelation ein Maß dafür, wie Werte in einer bestimmten Spalte auf der Festplatte sortiert werden.
Korrelation = 1.
Wenn die Korrelation 1 oder so ist, bedeutet dies, dass die Seiten in ungefähr derselben Reihenfolge wie die Zeilen in der Tabelle auf der Festplatte gespeichert werden. Das ist sehr häufig. Beispielsweise haben automatisch inkrementierende IDs in der Regel eine Korrelation nahe 1. Datums- und Zeitstempelspalten, die anzeigen, wann Zeilen erstellt wurden, haben auch eine Korrelation nahe 1.
Wenn die Korrelation -1 ist, werden die Seiten in umgekehrter Reihenfolge der Spalten sortiert.
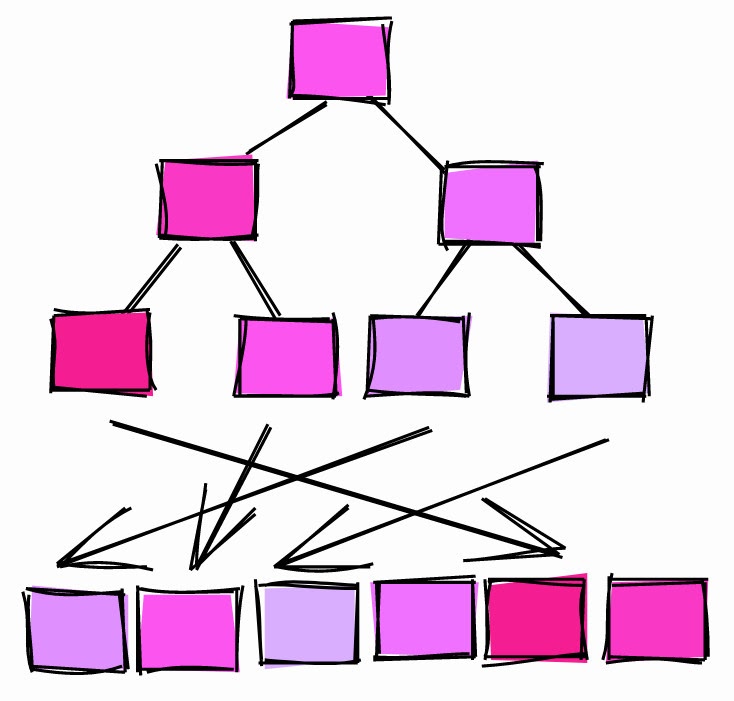
Korrelation ~ 0.
Wenn die Korrelation nahe bei 0 liegt, bedeutet dies, dass die Werte in der Spalte nicht oder kaum mit der Seitenreihenfolge in der Tabelle korrelieren.
Gehen wir zurück zu
sale_fact. Als wir die Daten ohne Vorsortierung in die Tabelle geladen haben, waren die Korrelationen wie folgt:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
Die automatisch generierte Spalten-ID hat eine Korrelation von 1. Die Spalte hat eine
sold_atsehr geringe Korrelation: Aufeinanderfolgende Werte sind über die Tabelle verteilt.
Als wir die sortierten Daten in die Tabelle geladen haben, hat sie die Korrelationen berechnet:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
Die Korrelation
sold_atist jetzt gleich 1.
Warum verwendete die Datenbank Bitmap-Scans, wenn die Korrelation niedrig war, aber Index-Scans, wenn die Korrelation hoch war?
- Wenn die Korrelation 1 war, stellte die Basis fest, dass sich die Zeilen des angeforderten Bereichs wahrscheinlich auf aufeinanderfolgenden Seiten befinden. Dann ist es besser, einen Index-Scan zu verwenden, um mehrere Seiten zu lesen.
- Wenn die Korrelation nahe bei 0 lag, stellte die Basis fest, dass die Zeilen des angeforderten Bereichs wahrscheinlich über die gesamte Tabelle verteilt sind. Dann ist es ratsam, einen Bitmap-Scan der Seiten zu verwenden, die die erforderlichen Zeilen enthalten, und diese erst dann unter Verwendung der Bedingung zu extrahieren.
Überlegen Sie beim nächsten Laden von Daten in eine Tabelle, wie viele Informationen angefordert werden, und sortieren Sie sie, damit die Indizes Bereiche schnell scannen können.
CLUSTER-Befehl
Eine andere Möglichkeit, eine Tabelle auf der Festplatte nach einem bestimmten Index zu sortieren, ist die Verwendung des Befehls CLUSTER .
Zum Beispiel:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
Wir haben die Daten in zufälliger Reihenfolge in die Tabelle geladen, sodass die Korrelation
sold_atnahe Null liegt.
Um die Tabelle nach "neu zusammenzusetzen"
sold_at, verwenden wir den Befehl CLUSTER, um die Tabelle auf der Festplatte nach dem Index zu sortieren sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
Nach dem Clustering der Tabelle wurde die Korrelation
sold_at1.
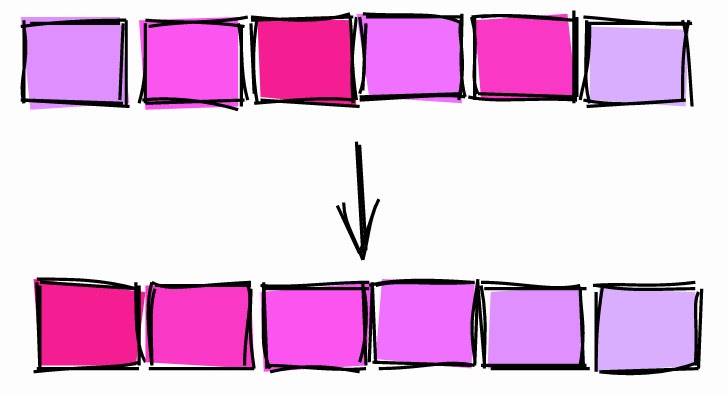
CLUSTER-Befehl.
Zu beachtende Punkte:
- Das Clustering einer Tabelle in einer bestimmten Spalte kann sich auf die Korrelation einer anderen Spalte auswirken. Sehen Sie sich beispielsweise die ID-Korrelation nach dem Clustering nach an
sold_at. CLUSTERIst eine schwere und blockierende Operation, wenden Sie sie daher nicht auf einen Live-Tisch an.
Aus diesen Gründen ist es am besten, Daten einzufügen, die bereits sortiert sind und auf die Sie sich nicht verlassen
CLUSTER.
Stark korrelierter Spaltenindex mit BRIN
Wenn es um Indizes geht, denken viele Entwickler an B-Bäume. PostgreSQL bietet jedoch auch andere Arten von Indizes an, z. B. BRIN :
BRIN ist für die Arbeit mit sehr großen Tabellen ausgelegt, bei denen einige Spalten natürlich mit ihrer physischen Position innerhalb der Tabelle korrelieren
BRIN steht für Block Range Index. Laut Dokumentation funktioniert BRIN am besten mit stark korrelierten Spalten. Wie wir in den vorherigen Kapiteln gesehen haben, korrelieren automatisch inkrementierende IDs und Zeitstempel natürlich mit der physischen Struktur der Tabelle, sodass BRIN für sie vorteilhafter ist.
Unter bestimmten Bedingungen kann BRIN in Bezug auf Größe und Leistung ein besseres "Preis-Leistungs-Verhältnis" bieten als ein vergleichbarer B-Tree-Index.
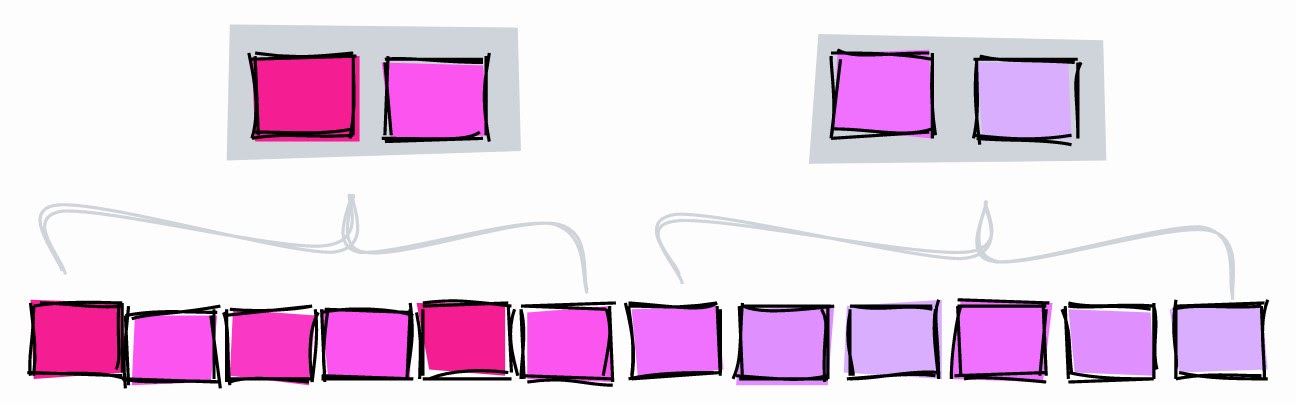
BRIN.
BRIN ist ein Wertebereich auf mehreren benachbarten Seiten in einer Tabelle. Angenommen, wir haben die folgenden Werte in einer Spalte, jeweils auf einer separaten Seite:
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN arbeitet mit Bereichen benachbarter Seiten. Wenn Sie drei benachbarte Seiten angeben, teilt der Index die Tabelle in Bereiche auf:
[1,2,3], [4,5,6], [7,8,9]
Für jeden Bereich speichert BRIN den minimalen und maximalen Wert :
[1–3], [4–6], [7–9]
Verwenden wir diesen Index, um nach dem Wert 5 zu suchen:
- [1–3] - er ist bestimmt nicht hier.
- [4–6] - vielleicht hier.
- [7–9] - er ist bestimmt nicht hier.
Mit BRIN haben wir den Suchbereich auf Block 4-6 beschränkt.
Nehmen wir ein anderes Beispiel. Lassen Sie die Werte in der Spalte eine Korrelation nahe Null haben, dh sie sind nicht sortiert:
[2,9,5], [1,4,7], [3,8,6]
Durch Indizieren von drei benachbarten Blöcken erhalten wir die folgenden Bereiche:
[2–9], [1–7], [3–8]
Suchen wir nach dem Wert 5:
- [2-9] - kann hier sein.
- [1-7] - kann hier sein.
- [3–8] - kann hier sein.
In diesem Fall schränkt der Index die Suche überhaupt nicht ein, sodass er unbrauchbar ist.
Grundlegendes zu pages_per_range
Die Anzahl der benachbarten Seiten wird durch den Parameter bestimmt
pages_per_range. Die Anzahl der Seiten in einem Bereich beeinflusst die Größe und Genauigkeit des BRIN:
- Ein
pages_per_rangekleinerer und weniger genauer Index ergibt einen großen Wert . - Ein kleiner Wert
pages_per_rangeergibt einen größeren und genaueren Index.
Der Standardwert
pages_per_rangeist 128.
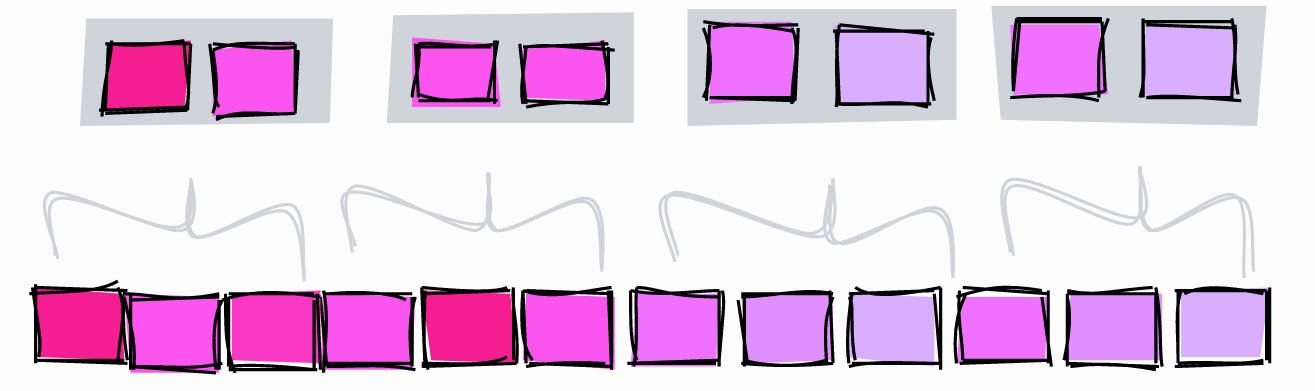
BRIN mit niedrigerem pages_per_range.
Zur Veranschaulichung erstellen wir einen BRIN mit zwei Seitenbereichen und suchen nach einem Wert von 5:
- [1–2] - er ist bestimmt nicht hier.
- [3–4] - er ist bestimmt nicht hier.
- [5-6] - kann hier sein.
- [7–8] - er ist bestimmt nicht hier.
- [9] - hier ist es definitiv nicht.
Mit einem zweiseitigen Bereich können wir die Suche auf die Blöcke 5 und 6 beschränken. Wenn der Bereich dreiseitig ist, beschränkt der Index die Suche auf die Blöcke 4, 5 und 6.
Ein weiterer Unterschied zwischen den beiden Indizes besteht darin, dass bei einem Bereich von drei Seiten drei Bereiche gespeichert werden mussten und mit zwei Seiten in einem Bereich erhalten wir bereits fünf Bereiche und der Index steigt.
Erstellen Sie BRIN
Nehmen wir eine Tabelle
sales_factund erstellen eine BRIN nach Spalte sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
Der Standardwert ist
pages_per_range = 128.
Fragen wir nun den Verkaufszeitraum ab:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
Die Basis hat den Datumszeitraum mit BRIN erhalten, aber das ist nichts Interessantes ...
Seiten_per_range optimieren
Gemäß dem Ausführungsplan hat die Datenbank 23.130 Zeilen von den Seiten entfernt, die sie mithilfe des Index gefunden hat. Dies kann darauf hinweisen, dass der für den Index angegebene Bereich für diese Abfrage zu groß ist. Erstellen wir einen Index mit der halben Anzahl von Seiten im Bereich:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
Mit 64 Seiten im Bereich löschte die Basis weniger Zeilen, die mit dem Index gefunden wurden - 9 434. Dies bedeutet, dass weniger E / A-Operationen ausgeführt werden mussten und die Abfrage etwas schneller ausgeführt wurde, in ~ 5,5 ms anstelle von ~ 8,9.
Testen wir den Index mit verschiedenen Werten
pages_per_range:
| pages_per_range | Zeilen werden entfernt, wenn der Index erneut überprüft wird |
| 128 | 23130 |
| 64 | 9 434 |
| 8 | 874 |
| 4 | 446 |
| 2 | 446 |
Das Verringern des
pages_per_rangeIndex wird präziser und entfernt weniger Zeilen von den gefundenen Seiten.
Bitte beachten Sie, dass wir eine sehr spezifische Abfrage optimiert haben. Dies ist zur Veranschaulichung in Ordnung, aber im wirklichen Leben ist es besser, Werte zu verwenden, die den Anforderungen der meisten Abfragen entsprechen.
Schätzung der Größe des Index
Ein weiterer großer Vorteil von BRIN ist seine Größe. In den vorherigen Kapiteln haben wir
sold_ateinen B-Baum-Index für ein Feld erstellt . Seine Größe betrug 2.224 KB. Und die BRIN-Größe mit dem Parameter ist pages_per_range=128nur 48 KB: 46-mal kleiner.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Die BRIN-Größe ist ebenfalls betroffen
pages_per_range. Zum Beispiel wiegen BRINs pages_per_range=256 Kb, etwas mehr als 48 Kb.
Indizes "unsichtbar" machen
PostgreSQL hat eine coole Transaktions-DDL- Funktion . Im Laufe der Jahre mit Oracle, ich habe wie zur Verwendung von DDL - Befehlen daran gewöhnt
CREATE, DROPund ALTER. In PostgreSQL können Sie jedoch DDL-Befehle innerhalb einer Transaktion ausführen. Änderungen werden erst angewendet, nachdem die Transaktion festgeschrieben wurde.
Ich habe kürzlich entdeckt, dass die Verwendung von Transaktions-DDL Indizes unsichtbar machen kann! Dies ist nützlich, wenn Sie einen Ausführungsplan ohne Indizes anzeigen möchten.
In einer Tabelle haben
sale_factwir beispielsweise einen Index für eine Spalte erstellt sold_at. Der Ausführungsplan für die Verkaufsabrufanforderung im Juli sieht folgendermaßen aus:
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
Um zu sehen, wie der Plan aussehen würde, wenn es keinen Index gäbe
sale_fact_sold_at_ix, können Sie den Index in eine Transaktion einfügen und sofort zurücksetzen:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
Beginnen wir zunächst eine Transaktion mit
BEGIN. Dann löschen wir den Index und generieren den Ausführungsplan. Beachten Sie, dass der Plan jetzt einen vollständigen Tabellenscan verwendet, als ob der Index nicht vorhanden wäre. Zu diesem Zeitpunkt ist die Transaktion noch nicht abgeschlossen, sodass der Index noch nicht gelöscht wurde. Um die Transaktion abzuschließen, ohne den Index zu löschen, rollen Sie ihn mit dem Befehl zurück ROLLBACK.
Überprüfen wir, ob der Index noch vorhanden ist:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Andere Datenbanken, die keine Transaktions-DDL unterstützen, erreichen das Ziel möglicherweise anders. Mit Oracle können Sie beispielsweise einen Index als unsichtbar markieren, und der Optimierer ignoriert ihn dann.
Achtung : Wenn Sie den Index innerhalb einer Transaktion fallen zu lassen, um es in die Blockierung der Wettbewerbs Operationen führen wird
SELECT, INSERT, UPDATEund DELETEin der Tabelle , bis die Transaktion aktiv ist . In Testumgebungen mit Vorsicht verwenden und in Produktionsanlagen vermeiden.
Planen Sie keine langen Prozesse so ein, dass sie zu Beginn einer Stunde beginnen
Anleger wissen, dass seltsame Dinge passieren können, wenn der Aktienkurs schöne runde Werte erreicht, zum Beispiel 10, 100, 1000 Dollar. Folgendes schreiben sie darüber :
[...] Der Preis von Vermögenswerten kann sich unvorhersehbar ändern und runde Werte wie 50 USD oder 100 USD pro Aktie überschreiten. Viele unerfahrene Händler kaufen oder verkaufen gerne Vermögenswerte, wenn der Preis runde Zahlen erreicht, weil sie glauben, dass sie faire Preise sind.
Unter diesem Gesichtspunkt unterscheiden sich Entwickler nicht sehr von Investoren. Wenn sie einen langen Prozess planen müssen, wählen sie normalerweise eine Stunde.
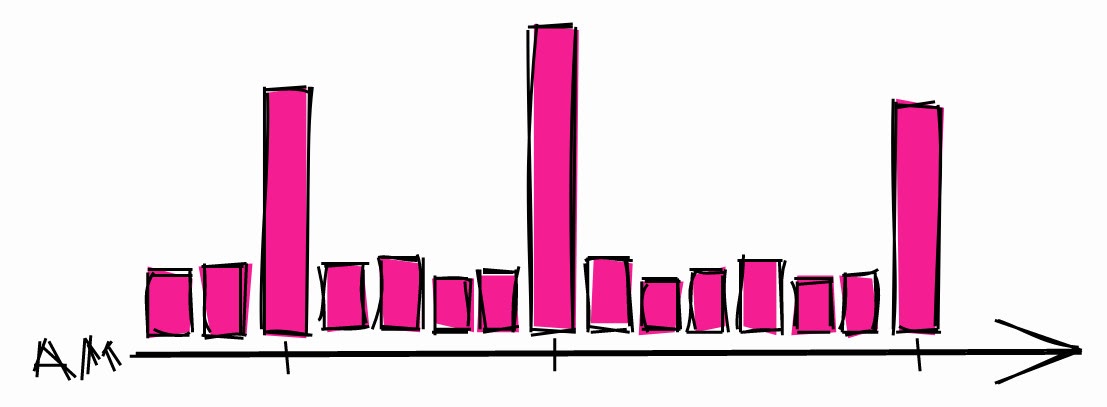
Typische Systemlast über Nacht.
Dies kann während dieser Stunden zu Lastspitzen führen. Wenn Sie also einen langen Prozess planen müssen, besteht eine größere Wahrscheinlichkeit, dass das System zu anderen Zeiten im Leerlauf ist.
Es wird auch empfohlen, zufällige Verzögerungen in Ihren Zeitplänen zu verwenden, damit Sie nicht jedes Mal zur gleichen Zeit starten. Selbst wenn für diese Stunde eine andere Aufgabe geplant ist, ist dies kein großes Problem. Wenn Sie einen systemd-Timer verwenden, können Sie die Option RandomizedDelaySec verwenden .
Fazit
Dieser Artikel enthält Tipps zu unterschiedlichen Evidenzgraden, die auf meinen Erfahrungen basieren. Einige sind einfach zu implementieren, andere erfordern ein tiefes Verständnis der Funktionsweise von Datenbanken. Datenbanken sind das Rückgrat der meisten modernen Systeme, daher ist die Zeit, die für das Erlernen der Arbeitsweise aufgewendet wird, eine gute Investition für jeden Entwickler!