Hallo Habr! In diesem Artikel werde ich Ihnen zeigen, wie Sie eine Frequenzanalyse der modernen russischen Internetsprache durchführen und diese zum Entschlüsseln des Textes verwenden. Wen kümmert es, willkommen unter dem Schnitt!

Frequenzanalyse der russischen Internetsprache
Das soziale Netzwerk Vkontakte wurde als Quelle verwendet, aus der Sie mit einer modernen Internet-Sprache viel Text abrufen können. Genauer gesagt handelt es sich hierbei um Kommentare zu Veröffentlichungen in verschiedenen Communities dieses Netzwerks. Ich habe mich für echten Fußball als Community entschieden . Zum Parsen von Kommentaren habe ich die Vkontakte-API verwendet :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passDas Ergebnis war etwa 200 MB Text. Jetzt zählen wir, welches Zeichen wie oft erscheint:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyDie erhaltenen Ergebnisse können mit den Ergebnissen von Wikipedia verglichen und wie folgt angezeigt werden:
1) Vergleichstabelle
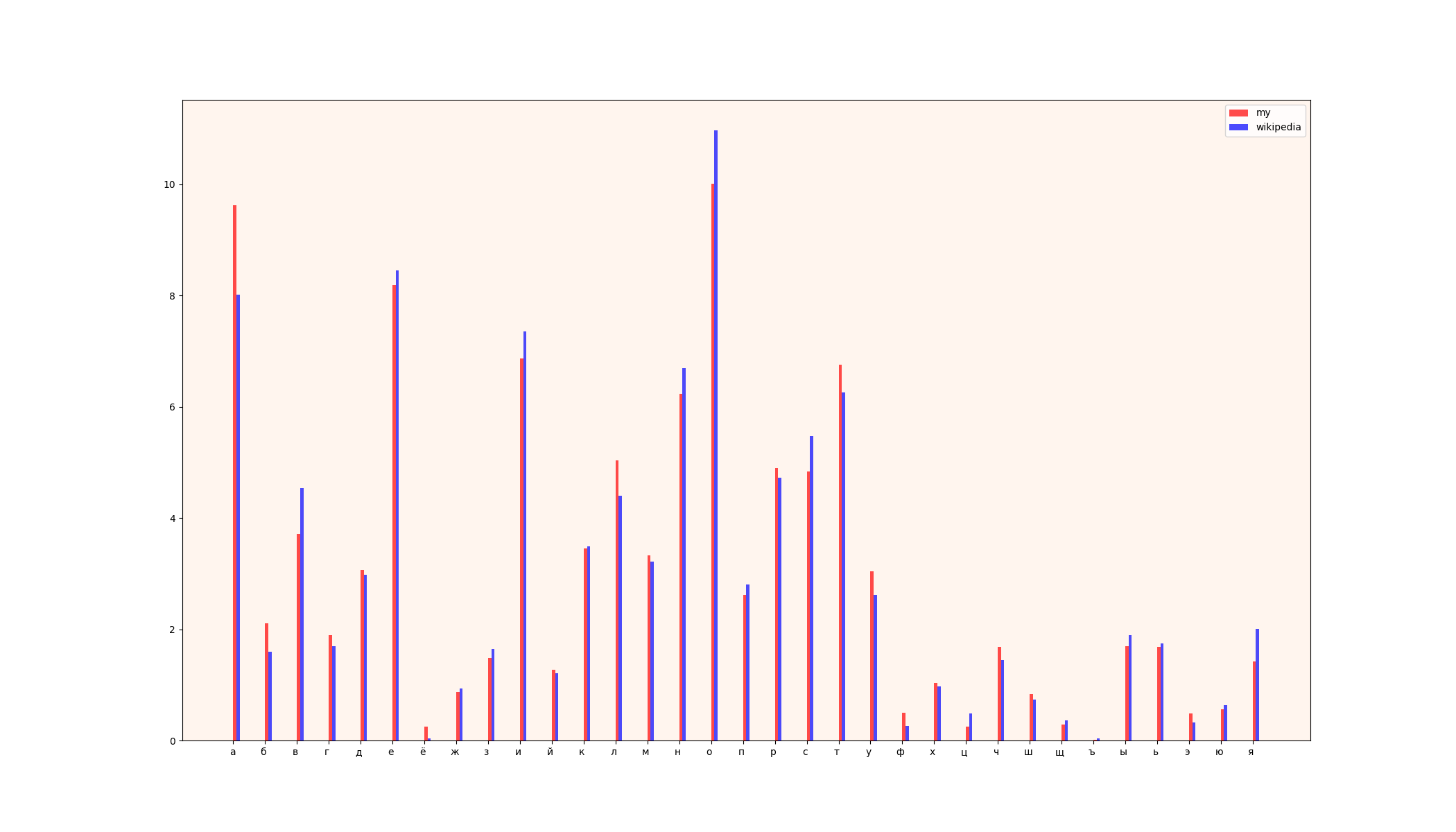
2) Tabellen (links - Wikipedia-Daten, rechts - meine Daten)
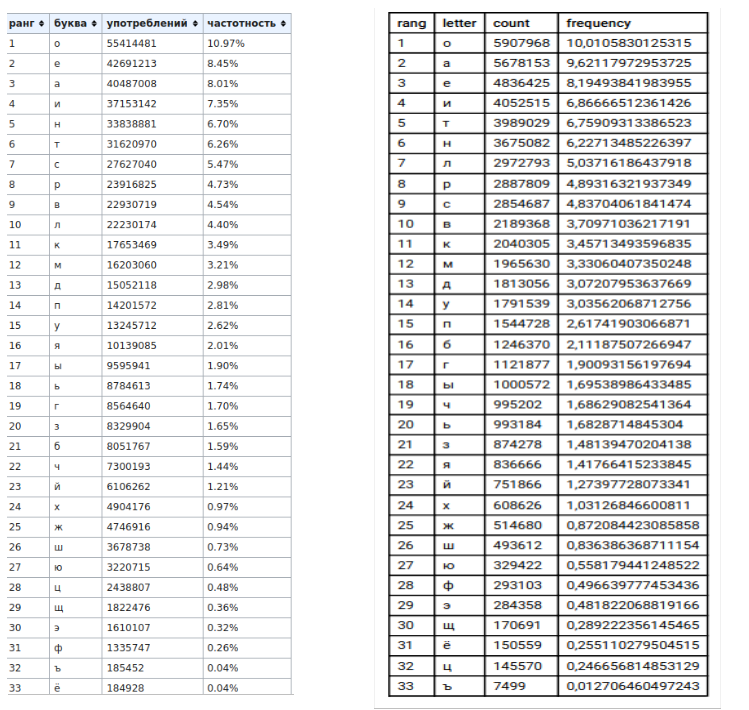
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
Wenn Sie sich den entschlüsselten Text ansehen, können Sie erraten, wo unser Algorithmus schief gelaufen ist: Kämpfe → Taten, Vadio → Radio, Toho → Addition, Leads → Personen. Somit ist es möglich, den gesamten Text zu entschlüsseln, zumindest um die Bedeutung des Textes zu erfassen. Ich möchte auch darauf hinweisen, dass diese Methode nur lange Texte entschlüsselt, die mit symmetrischen Verschlüsselungsmethoden verschlüsselt wurden. Der vollständige Code ist auf Github verfügbar .