
Heute werde ich Ihnen ein wenig über meine Gedanken zum Tarantool / Cartridge-Failover erzählen. Zunächst ein paar Worte dazu, was Cartridge ist: Dies ist ein Stück Lua-Code, der in Tarantool funktioniert und Taranteln miteinander in einem bedingten "Cluster" kombiniert. Dies ist auf zwei Dinge zurückzuführen:
- Jede Vogelspinne kennt die Netzwerkadressen aller anderen Vogelspinnen.
- Vogelspinnen "pingen" sich regelmäßig über UDP, um zu verstehen, wer lebt und wer nicht. Hier vereinfache ich absichtlich ein wenig, der Ping-Algorithmus ist komplizierter als nur eine Anfrage-Antwort, aber dies ist für das Parsen nicht sehr wichtig. Bei Interesse - googeln Sie den SWIM-Algorithmus.
Innerhalb eines Clusters wird normalerweise alles in zustandsbehaftete (Master / Replikat) und zustandslose (Router) Taranteln unterteilt. Zustandslose Vogelspinnen sind für das Speichern von Daten verantwortlich, und zustandslose Vogelspinnen sind für das Weiterleiten von Anforderungen verantwortlich.
So sieht es im Bild aus:
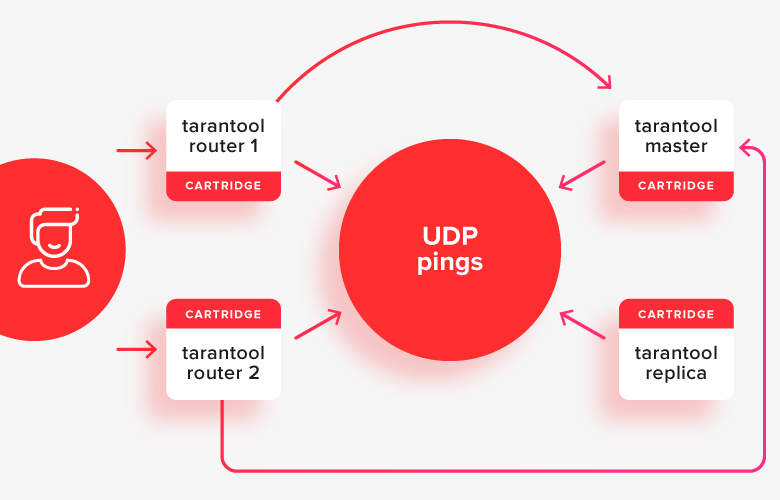
Der Client stellt Anforderungen an einen der aktiven Router und leitet Anforderungen an einen der Stores weiter, der jetzt der aktive Master ist. Im Bild sind diese Pfade mit Pfeilen dargestellt.
Jetzt möchte ich Sharding nicht komplizieren und in das Gespräch über die Auswahl eines Führers einführen, aber die Situation mit ihm wird wenig anders sein. Der einzige Unterschied besteht darin, dass der Router noch entscheiden muss, welcher Replikatsatz aus dem Store verwendet werden soll.
Lassen Sie uns zunächst darüber sprechen, wie Knoten die Adressen der anderen lernen. Zu diesem Zweck verfügt jeder von ihnen über eine Yaml-Datei auf der Festplatte mit der Clustertopologie, dh Informationen zu den Netzwerkadressen aller Mitglieder und wer von ihnen ist wer (mit oder ohne Status). Plus potenziell zusätzliche Anpassungen, aber lassen wir das vorerst beiseite. Die Konfigurationsdateien enthalten die Einstellungen für den gesamten Cluster als Ganzes und sind für jede Tarantel gleich. Wenn Änderungen an ihnen vorgenommen werden, werden sie für alle Vogelspinnen synchron vorgenommen.
Jetzt können Konfigurationsänderungen über die API aller Taranteln im Cluster vorgenommen werden: Es wird eine Verbindung zu allen anderen hergestellt, ihnen eine neue Version der Konfiguration gesendet, jeder wird sie anwenden und überall wird es eine neue Version geben, dieselbe wieder.
Szenario - Knotenausfall, Umschaltung
In einer Situation, in der ein Router ausfällt, ist alles mehr oder weniger einfach: Der Client muss nur zu einem anderen aktiven Router gehen und sendet die Anforderung an den gewünschten Speicher. Aber was ist, wenn zum Beispiel der Meister eines der Storaja gefallen ist?
Im Moment haben wir einen "naiven" Algorithmus für einen solchen Fall implementiert, der auf UDP-Ping beruht. Wenn das Replikat für kurze Zeit keine Antworten des Masters auf Ping „sieht“, wird davon ausgegangen, dass der Master gefallen ist und selbst zum Master wird, und vom schreibgeschützten Modus in den Lese- / Schreibmodus umgeschaltet. Router verhalten sich genauso: Wenn sie keine Ping-Antwortzeit vom Master sehen, schalten sie den Datenverkehr auf das Replikat um.
Dies funktioniert in einfachen Fällen relativ gut, mit Ausnahme einer Situation mit geteiltem Gehirn, in der die Hälfte der Knoten durch ein Netzwerkproblem von einem anderen getrennt ist:
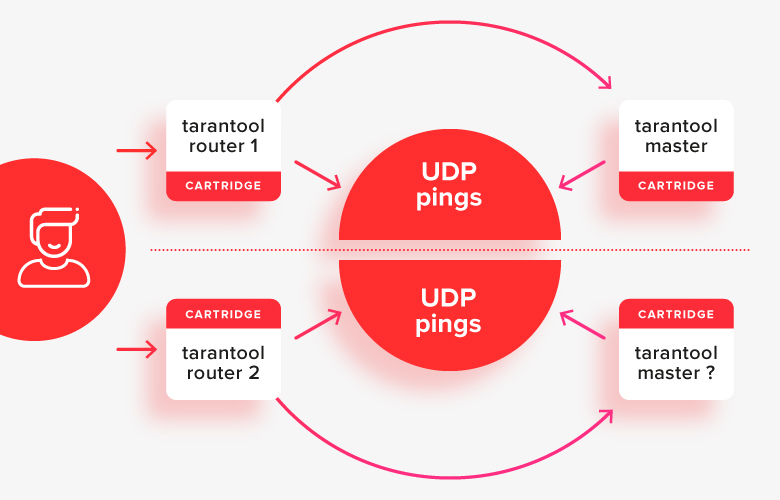
In dieser Situation sehen die Router, dass die „andere Hälfte“ des Clusters nicht verfügbar ist, und betrachten ihre Hälfte als die Haupthälfte, und es stellt sich heraus, dass zwei Master gleichzeitig im System vorhanden sind. Dies ist der erste wichtige Fall, der gelöst werden muss.
Szenario - Konfiguration bei Fehlern bearbeiten
Ein weiteres wichtiges Szenario ist das Ersetzen einer ausgefallenen Vogelspinne in einem Cluster durch eine neue oder das Hinzufügen von Knoten zum Cluster, wenn eines der Replikate oder Router nicht verfügbar ist.
Während des normalen Betriebs, wenn alles im Cluster verfügbar ist, können wir über eine API eine Verbindung zu einem beliebigen Knoten herstellen, ihn bitten, die Konfiguration zu bearbeiten, und wie oben erwähnt, wird der Knoten die neue Konfiguration für den gesamten Cluster "bereitstellen".
Wenn jedoch jemand nicht verfügbar ist, können Sie die neue Konfiguration nicht anwenden. Wenn diese Knoten wieder verfügbar sind, ist unklar, welcher von ihnen im Cluster die richtige Konfiguration hat und welcher nicht. Dennoch kann die Unzugänglichkeit der Knoten zueinander bedeuten, dass sich zwischen ihnen ein gespaltenes Gehirn befindet. Das Bearbeiten der Konfiguration ist einfach unsicher, da Sie sie fälschlicherweise auf unterschiedliche Weise in verschiedenen Hälften bearbeiten können.
Aus diesen Gründen verbieten wir jetzt das Bearbeiten der Konfiguration über die API, wenn jemand nicht verfügbar ist. Sie kann nur auf der Festplatte über Textdateien (manuell) korrigiert werden. Hier müssen Sie gut verstehen, was Sie tun, und sehr vorsichtig sein: Die Automatisierung hilft Ihnen in keiner Weise.
Dies macht den Betrieb unpraktisch und dies ist der zweite zu lösende Fall.
Szenario - stabiles Failover
Ein weiteres Problem mit dem naiven Failover-Modell besteht darin, dass der Wechsel vom Master zum Replikat bei einem Master-Fehler nirgendwo aufgezeichnet wird. Alle Knoten treffen die Entscheidung, selbst zu wechseln, und wenn der Master zum Leben erweckt wird, wechselt der Verkehr wieder zu ihm.
Dies kann ein Problem sein oder auch nicht. Vor dem Einschalten des Masters "holt" der Master die Transaktionsprotokolle des Replikats ein, sodass höchstwahrscheinlich keine große Datenverzögerung auftritt. Das Problem tritt nur dann auf, wenn ein Problem im Netzwerk vorliegt und Pakete verloren gehen. Dann wird der Master höchstwahrscheinlich regelmäßig "blinken" (Flattern).
Die Lösung ist ein "starker" Koordinator (etcd / consul / tarantool)
Um Probleme mit einem geteilten Gehirn zu vermeiden und die Konfiguration zu bearbeiten, wenn der Cluster teilweise nicht verfügbar ist, benötigen wir einen starken Koordinator, der gegen Netzwerksegmentierung resistent ist. Der Koordinator sollte auf drei Rechenzentren verteilt sein, damit er bei einem Ausfall weiterhin funktionsfähig bleibt.
Es gibt jetzt 2 beliebte RAFT-basierte Koordinatoren, die etcd und consul dafür verwenden. Wenn die synchrone Replikation im Tarantool angezeigt wird, kann sie auch dafür verwendet werden.
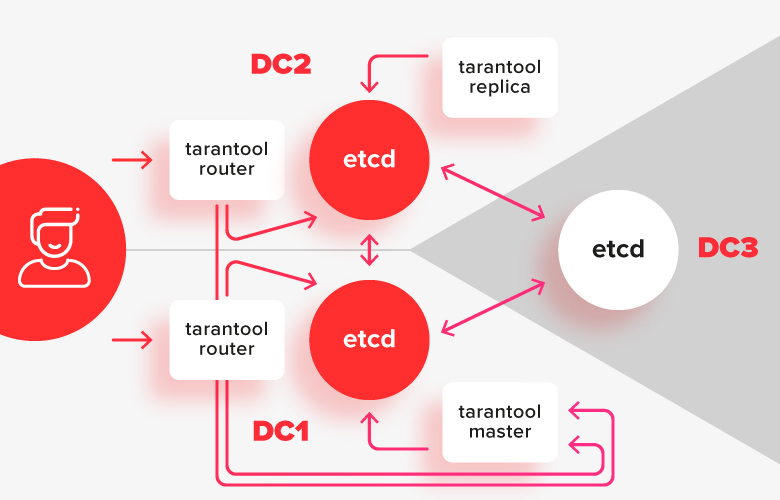
In diesem Schema sind die Tarantelinstallationen in zwei Rechenzentren unterteilt und mit ihrer lokalen etcd-Installation verbunden. Eine Instanz von etcd im dritten Datencenter dient als Arbiter, sodass im Falle eines Ausfalls eines der Rechenzentren genau angegeben werden kann, welcher von ihnen in der Mehrheit verbleibt.
Konfigurationsmanagement mit einem starken Koordinator
Wie oben erwähnt, konnten wir die Konfiguration ohne einen Koordinator und den Ausfall einer der Vogelspinnen nicht zentral bearbeiten, da dann nicht gesagt werden kann, welche Konfiguration auf welchem der Knoten korrekt ist.
Bei einem starken Koordinator ist alles einfacher: Wir können die Konfiguration auf dem Koordinator speichern, und jede Instanz der Tarantel enthält einen Cache dieser Konfiguration in ihrem Dateisystem. Nach erfolgreicher Verbindung mit dem Koordinator aktualisiert es seine Kopie der Konfiguration auf die im Koordinator.
Das Bearbeiten der Konfiguration wird ebenfalls einfacher: Dies kann über die API einer beliebigen Vogelspinne erfolgen Es wird die Sperre im Koordinator übernehmen, die gewünschten Werte in der Konfiguration ersetzen, warten, bis alle Knoten sie anwenden, und die Sperre aufheben. Nun, oder als letztes Mittel können Sie die Konfiguration in etcd manuell bearbeiten und sie gilt für den gesamten Cluster.
Die Konfiguration kann auch dann bearbeitet werden, wenn einige Vogelspinnen nicht verfügbar sind. Die Hauptsache ist, dass die meisten Koordinatorknoten verfügbar sind.
Failover mit einem starken Koordinator
Das zuverlässige Umschalten von Knoten mit einem Koordinator wird dadurch gelöst, dass zusätzlich zur Konfiguration im Koordinator Informationen darüber gespeichert werden, wer der aktuelle Master im Replikat ist und wo die Umschaltungen vorgenommen wurden.
Der Failover-Algorithmus ändert sich wie folgt:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
Mit einem Koordinator ist auch ein Schlagschutz möglich. Im Koordinator können Sie den gesamten Wechselverlauf aufzeichnen. Wenn der Master in den letzten X Minuten zu einem Replikat gewechselt ist, wird der Rückwärtswechsel nur explizit vom Administrator durchgeführt.
Ein weiterer wichtiger Punkt ist das sogenannte "Fechten". Vogelspinnen, die von anderen Rechenzentren abgeschnitten sind (oder mit einem Koordinator verbunden sind, der die Mehrheit verloren hat), sollten davon ausgehen, dass höchstwahrscheinlich der Rest des Clusters, auf den der Zugriff verloren geht, die Mehrheit hat. Und das bedeutet, dass innerhalb einer bestimmten Zeit alle von der Mehrheit abgeschnittenen Knoten schreibgeschützt sein müssen.
Problem der Nichtverfügbarkeit des Koordinators
Während wir über Ansätze für die Zusammenarbeit mit dem Koordinator diskutierten, erhielten wir eine Anfrage, um sicherzustellen, dass der gesamte Cluster nicht schreibgeschützt übersetzt wird, wenn der Koordinator fällt, aber alle Vogelspinnen intakt sind.
Zuerst schien es nicht sehr realistisch zu sein, aber dann erinnerten wir uns, dass der Cluster selbst die Verfügbarkeit anderer Knoten über UDP-Pings überwacht. Dies bedeutet, dass wir sie als Ziel festlegen und keine Wiederwahl des Masters innerhalb des Replikatsatzes auslösen können, wenn durch UDP-Pings klar ist, dass der gesamte Replikatsatz aktiv ist.
Mit diesem Ansatz können Sie sich weniger Gedanken über die Verfügbarkeit des Koordinators machen, insbesondere wenn Sie ihn beispielsweise zum Aktualisieren neu starten müssen.
Umsetzungspläne
Jetzt sammeln wir Feedback und beginnen mit der Implementierung. Wenn Sie etwas zu sagen haben - schreiben Sie in die Kommentare oder in eine persönliche.
Der Plan sieht ungefähr so aus:
- Machen Sie etcd Unterstützung in tarantool [fertig]
- Failover mit etcd als Koordinator, stateful [done]
- Failover mit Tarantel als Koordinator, Verriegeln [erledigt]
- Konfiguration in etcd speichern [in Bearbeitung]
- Schreiben von CLI-Tools für die Clusterreparatur [in Bearbeitung]
- Speichern der Konfiguration in der Vogelspinne
- Clusterverwaltung, wenn ein Teil des Clusters nicht verfügbar ist
- Fechten
- Schlagschutz
- Failover mit Konsul als Koordinator
- Konfiguration im Konsul speichern
In Zukunft werden wir den Cluster mit ziemlicher Sicherheit ganz ohne einen starken Koordinator fallen lassen. Dies wird höchstwahrscheinlich mit der RAFT-basierten Implementierung der synchronen Replikation in der Tarantel zusammenfallen.
Danksagung
Vielen Dank an die Entwickler von Mail.ru Mail und Administratoren für das Feedback, die Kritik und die Tests.