
Quelle: Vecteezy
Ja, die lineare Regression ist nicht die einzige. Nennen Sie
schnell fünf Algorithmen für maschinelles Lernen.
Es ist unwahrscheinlich, dass Sie viele Regressionsalgorithmen nennen. Schließlich ist der einzige weit verbreitete Regressionsalgorithmus die lineare Regression, hauptsächlich wegen ihrer Einfachheit. Die lineare Regression ist jedoch aufgrund zu begrenzter Optionen und eingeschränkter Handlungsfreiheit häufig nicht auf reale Daten anwendbar. Es wird häufig nur als Basismodell für die Bewertung und den Vergleich mit neuen Forschungsansätzen verwendet. Mail.ru Cloud Solutions-
Teamübersetzte einen Artikel, dessen Autor 5 Regressionsalgorithmen beschreibt. Sie sind es wert, zusammen mit gängigen Klassifizierungsalgorithmen wie SVM, Entscheidungsbaum und neuronalen Netzen in Ihrer Toolbox enthalten zu sein.
1. Regression des neuronalen Netzwerks
Theorie
Neuronale Netze sind unglaublich leistungsfähig, werden jedoch häufig zur Klassifizierung verwendet. Signale wandern durch Schichten von Neuronen und werden in einer von mehreren Klassen zusammengefasst. Sie können jedoch sehr schnell in Regressionsmodelle umgewandelt werden, indem die letzte Aktivierungsfunktion geändert wird.
Jedes Neuron überträgt Werte aus der vorherigen Verbindung über eine Aktivierungsfunktion, die dem Zweck der Verallgemeinerung und Nichtlinearität dient. Normalerweise ist die Aktivierungsfunktion so etwas wie eine Sigmoid- oder eine ReLU-Funktion (Rectified Linear Unit).
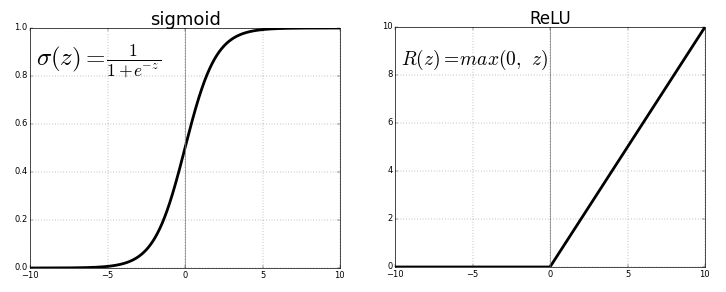
Quelle . Freies Bild
Ersetzen Sie jedoch die letzte Aktivierungsfunktion (Ausgangsneuron) durch eine lineareMit der Aktivierungsfunktion kann das Ausgangssignal auf viele Werte außerhalb der festen Klassen abgebildet werden. Somit ist der Ausgang nicht die Wahrscheinlichkeit, das Eingangssignal einer Klasse zuzuweisen, sondern ein kontinuierlicher Wert, bei dem das neuronale Netzwerk seine Beobachtungen festlegt. In diesem Sinne können wir sagen, dass das neuronale Netzwerk die lineare Regression ergänzt.
Die Regression des neuronalen Netzwerks hat den Vorteil der Nichtlinearität (zusätzlich zur Komplexität), die mit Sigmoid- und anderen nichtlinearen Aktivierungsfunktionen früher im neuronalen Netzwerk eingeführt werden kann. Eine übermäßige Verwendung von ReLU als Aktivierungsfunktion kann jedoch dazu führen, dass das Modell die Ausgabe negativer Werte vermeidet, da ReLU die relativen Unterschiede zwischen negativen Werten ignoriert.
Dies kann entweder gelöst werden, indem die Verwendung von ReLU eingeschränkt und mehr negative Werte der entsprechenden Aktivierungsfunktionen hinzugefügt werden, oder indem die Daten vor dem Training auf einen streng positiven Bereich normalisiert werden.
Implementierung
Lassen Sie uns mit Keras die Struktur eines künstlichen neuronalen Netzwerks aufbauen, obwohl dies auch mit einem Faltungs-Neuronalen Netzwerk oder einem anderen Netzwerk möglich ist, wenn die letzte Schicht entweder eine dichte Schicht mit linearer Aktivierung oder nur eine Schicht mit linearer Aktivierung ist. ( Beachten Sie, dass Keras-Importe aus Platzgründen nicht aufgelistet sind. )
model = Sequential()
model.add(Dense(100, input_dim=3, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation='softmax'))
#IMPORTANT PART
model.add(Dense(1, activation='linear'))
Das Problem bei neuronalen Netzen war immer ihre hohe Varianz und Tendenz zur Überanpassung. Im obigen Codebeispiel gibt es viele Ursachen für Nichtlinearität wie SoftMax oder Sigmoid.
Wenn Ihr neuronales Netzwerk gute Arbeit mit Trainingsdaten mit einer rein linearen Struktur leistet, ist es möglicherweise besser, eine abgeschnittene Entscheidungsbaumregression zu verwenden, die ein lineares und stark verteiltes neuronales Netzwerk emuliert, dem Datenwissenschaftler jedoch eine bessere Kontrolle über Tiefe, Breite und andere Attribute zur Kontrolle der Überanpassung ermöglicht.
2. Entscheidungsbaumregression
Theorie
Entscheidungsbäume in Klassifikation und Regression sind insofern sehr ähnlich, als sie Bäume mit Ja / Nein-Knoten konstruieren. Während Klassifizierungsblattknoten zu einem einzelnen Klassenwert führen (z. B. 1 oder 0 für ein binäres Klassifizierungsproblem), erhalten Regressionsbäume einen Wert im kontinuierlichen Modus (z. B. 4593,49 oder 10,98).
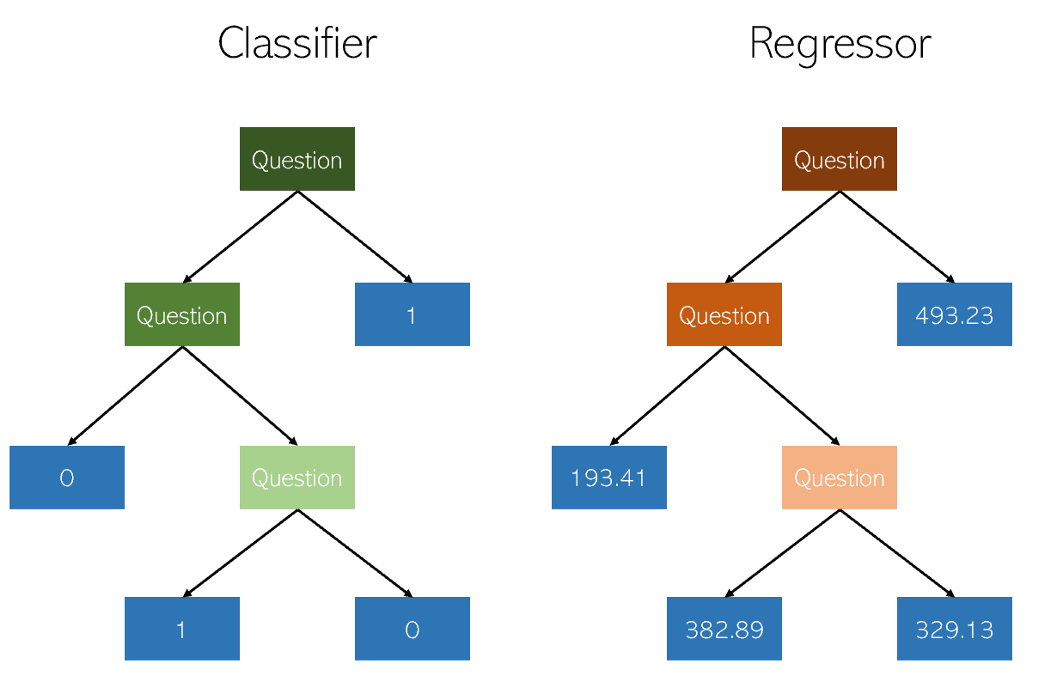
Illustration
des Autors Aufgrund der spezifischen und stark verstreuten Natur der Regression als bloßes Problem des maschinellen Lernens sollten Regressoren von Entscheidungsbäumen sorgfältig beschnitten werden. Der Regressionsansatz ist jedoch unregelmäßig - anstatt einen Wert auf einer kontinuierlichen Skala zu berechnen, gelangt er zu bestimmten Endknoten. Wenn der Regressor zu stark abgeschnitten ist, hat er zu wenige Blattknoten, um seinen Zweck ordnungsgemäß zu erfüllen.
Daher sollte der Entscheidungsbaum so beschnitten werden, dass er die größte Freiheit bietet (mögliche Regressionsausgabewerte sind die Anzahl der Blattknoten), aber nicht genug, um zu tief zu sein. Wenn Sie es nicht abschneiden, wird der bereits stark verteilte Algorithmus aufgrund der Art der Regression zu komplex.
Implementierung
Die Regression des Entscheidungsbaums kann einfach erstellt werden in
sklearn:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
Da die Parameter des Entscheidungsbaum-Regressors sehr wichtig sind, wird empfohlen, die Parameter eines Suchmaschinenoptimierungswerkzeugs
GridCVvon zu verwenden sklearn, um die richtige Empfehlung für dieses Modell zu finden.
Verwenden Sie bei der formalen Bewertung der Leistung Tests
K-foldanstelle von Standardtests train-test-split, um deren Zufälligkeit zu vermeiden, die die sensitiven Ergebnisse eines Modells mit hoher Varianz verletzen könnte.
Bonus: Ein enger Verwandter des Entscheidungsbaums, der Random Forest-Algorithmus, kann auch als Regressor implementiert werden. Ein zufälliger Waldregressor kann aufgrund des empfindlichen Gleichgewichts zwischen Redundanz und Mangel in der Art der Baumbildungsalgorithmen eine bessere Leistung als ein Entscheidungsbaum in der Regression erzielen oder nicht (während er normalerweise eine bessere Klassifizierung aufweist).
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
3. LASSO-Regression
Die Lasso-Regression (LASSO, Least Absolute Shrinkage and Selection Operator) ist eine Variation der linearen Regression, die speziell für Daten angepasst wurde, die eine starke Multikollinearität aufweisen (dh eine starke Korrelation der Merkmale untereinander).
Es automatisiert Teile der Modellauswahl wie die Variablenauswahl oder den Parameterausschluss. LASSO verwendet die Schrumpfung. Hierbei handelt es sich um einen Prozess, bei dem sich Datenwerte einem Mittelpunkt nähern (z. B. einem Durchschnitt).

Illustration des Autors. Vereinfachte Visualisierung des Komprimierungsprozesses
Der Komprimierungsprozess bietet Regressionsmodellen mehrere Vorteile:
- Genauere und stabilere Schätzungen der wahren Parameter.
- Reduzierung von Stichprobenfehlern und Nicht-Stichproben.
- Glättung räumlicher Schwankungen.
Anstatt die Komplexität des Modells anzupassen, um die Komplexität der Daten zu kompensieren, wie z. B. hochvariante neuronale Netzwerk- und Entscheidungsbaum-Regressionsmethoden, versucht das Lasso, die Komplexität der Daten so zu reduzieren, dass sie durch einfache Regressionsmethoden verarbeitet werden können, indem der Raum gekrümmt wird, auf dem sie liegen. In diesem Prozess hilft das Lasso automatisch dabei, stark korrelierte und redundante Merkmale bei einer Methode mit geringer Varianz zu eliminieren oder zu verzerren.
Die Lasso-Regression verwendet die L1-Regularisierung, dh sie gewichtet die Fehler mit ihrem absoluten Wert. Anstelle von beispielsweise L2-Regularisierung, bei der die Fehler durch ihr Quadrat gewichtet werden, um signifikantere Fehler stärker zu bestrafen.
Diese Regularisierung führt häufig zu sparsameren Modellen mit weniger Koeffizienten, da einige Koeffizienten Null werden und daher aus dem Modell ausgeschlossen werden können. Dies ermöglicht die Interpretation.
Implementierung
Das
sklearnRegressions-Lasso wird mit einem Kreuzvalidierungsmodell geliefert, das das effektivste der vielen trainierten Modelle mit unterschiedlichen grundlegenden Parametern und Lernpfaden auswählt, die eine Aufgabe automatisieren, die sonst manuell ausgeführt werden müsste.
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(X_train, y_train)
4. Gratregression (Gratregression)
Theorie
Die Ridge-Regression oder Ridge-Regression ist der LASSO-Regression insofern sehr ähnlich, als sie eine Komprimierung anwendet. Beide Algorithmen eignen sich gut für Datensätze mit einer Vielzahl von Merkmalen, die nicht unabhängig voneinander sind (Kollinearität).
Allerdings ist der größte Unterschied zwischen ihnen , dass die Firstregressions Anwendungen L2 Regularisierung, das heißt, keiner der Koeffizienten nicht geworden Null, da die LASSO Regression ist. Stattdessen nähern sich die Koeffizienten zunehmend Null an, haben jedoch aufgrund der Art der L2-Regularisierung wenig Anreiz, dies zu erreichen.
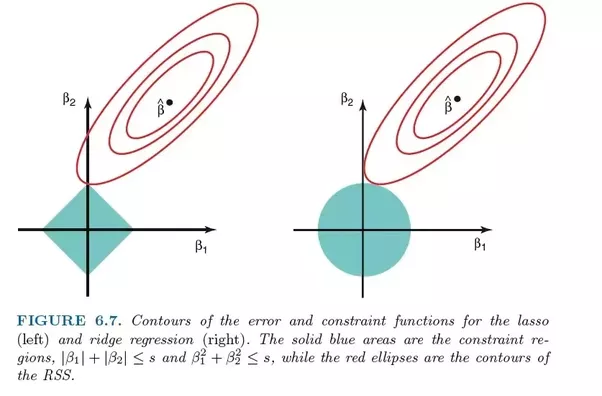
Vergleich der Fehler in der Lasso-Regression (links) und der Ridge-Regression (rechts). Da die Ridge-Regression die L2-Regularisierung verwendet, ähnelt ihre Fläche einem Kreis, während die L1-Lasso-Regularisierung gerade Linien zeichnet. Freies Bild. Quelle
Im Lasso wird die Verbesserung von Fehler 5 auf Fehler 4 auf die gleiche Weise gewichtet wie die Verbesserung von 4 auf 3 und auch von 3 auf 2, von 2 auf 1 und von 1 auf 0. Daher erreichen mehr Koeffizienten Null und mehr Merkmale werden eliminiert.
Bei der Gratregression wird die Verbesserung von Fehler 5 zu Fehler 4 jedoch mit 5² - 4² = 9 berechnet, während die Verbesserung von 4 auf 3 nur mit 7 gewichtet wird. Allmählich nimmt die Belohnung für die Verbesserung ab; Daher werden weniger Funktionen eliminiert.
Die Ridge-Regression eignet sich am besten für Situationen, in denen eine große Anzahl von Variablen priorisiert werden soll, von denen jede einen geringen Effekt hat. Wenn Ihr Modell mehrere Variablen berücksichtigen muss, von denen jede einen mittleren bis großen Effekt hat, ist das Lasso die beste Wahl.
Implementierung
Die Ridge-Regression
sklearnkann wie folgt implementiert werden (siehe unten). Wie bei der Lasso-Regression sklearngibt es eine Implementierung, um die Auswahl der besten von vielen trainierten Modellen gegenseitig zu validieren.
from sklearn.linear_model import RidgeCV
model = Ridge()
model.fit(X_train, y_train)
5. ElasticNet-Regression
Theorie
ElasticNet zielt darauf ab, das Beste aus Ridge Regression und Lasso Regression zu kombinieren, indem L1- und L2-Regularisierung kombiniert werden.
Lasso und Ridge Regression sind zwei verschiedene Regularisierungsmethoden. In beiden Fällen ist λ der Schlüsselfaktor, der die Höhe der Geldbuße steuert:
- λ = 0, , .
- λ = ∞, - . , , .
- 0 < λ < ∞, λ , .
Zum λ-Parameter fügt die ElasticNet-Regression einen zusätzlichen Parameter α hinzu , der misst, wie "gemischt" die Regularisierungen L1 und L2 sein sollten. Wenn α 0 ist, ist das Modell eine reine Ridge-Regression, und wenn α 1 ist, ist es eine reine Lasso-Regression.
Der "Mischungsfaktor" α definiert einfach, wie viel L1- und L2-Regularisierung in der Verlustfunktion berücksichtigt werden sollte. Alle drei gängigen Regressionsmodelle - Ridge, Lasso und ElasticNet - zielen darauf ab, die Größe ihrer Koeffizienten zu reduzieren, wirken jedoch jeweils unterschiedlich.
Implementierung
ElasticNet kann mithilfe des Kreuzvalidierungsmodells von sklearn implementiert werden:
from sklearn.linear_model import ElasticNetCV
model = ElasticNetCV()
model.fit(X_train, y_train)
Was gibt es sonst noch zu diesem Thema zu lesen: