
diesem Artikel werden einige gängige Muster zusammengefasst, mit denen Ingenieure mit umfangreichen Diensten arbeiten können, die von Millionen von Benutzern angefordert werden.
Nach Erfahrung des Autors ist dies keine vollständige Liste, sondern wirklich effektive Tipps. Also fangen wir an.
Übersetzt mit Unterstützung von Mail.ru Cloud Solutions .
Erste Ebene
Die unten aufgeführten Maßnahmen sind relativ einfach umzusetzen, bringen jedoch hohe Renditen. Wenn Sie sie noch nicht ausprobiert haben, werden Sie von den signifikanten Verbesserungen überrascht sein.
Infrastruktur als Code
Der erste Ratschlag besteht darin, die Infrastruktur als Code zu implementieren. Dies bedeutet, dass Sie eine programmatische Möglichkeit haben müssen, Ihre gesamte Infrastruktur bereitzustellen. Es klingt schwierig, aber wir sprechen tatsächlich über den folgenden Code:
Stellen Sie 100 virtuelle Maschinen bereit
- mit Ubuntu
- Jeweils 2 GB RAM
- Sie haben den folgenden Code
- mit solchen Parametern
Mithilfe der Quellcodeverwaltung können Sie Infrastrukturänderungen schnell verfolgen und wiederherstellen.
Der Modernist in mir sagt, dass Sie Kubernetes / Docker verwenden können, um all das zu tun, und er hat Recht.
Sie können die Automatisierung auch mit Chef, Puppet oder Terraform bereitstellen.
Kontinuierliche Integration und Lieferung
Um einen skalierbaren Service zu erstellen, ist es wichtig, für jede Pull-Anforderung eine Build- und Test-Pipeline zu haben. Selbst wenn der Test der einfachste ist, wird zumindest sichergestellt, dass der von Ihnen bereitgestellte Code kompiliert wird.
Zu diesem Zeitpunkt beantworten Sie jedes Mal die Frage: Wird meine Assembly Tests kompilieren und bestehen, ist sie gültig? Dies mag wie ein niedriger Balken klingen, löst jedoch viele Probleme.
Es gibt nichts Schöneres, als diese Kontrollkästchen zu sehen.
Für diese Technologie können Sie Github, CircleCI oder Jenkins ausprobieren.
Load Balancer
Daher möchten wir einen Load Balancer starten, um den Datenverkehr umzuleiten, und sicherstellen, dass die Last auf allen Knoten gleich ist oder dass der Dienst im Falle eines Fehlers funktioniert:
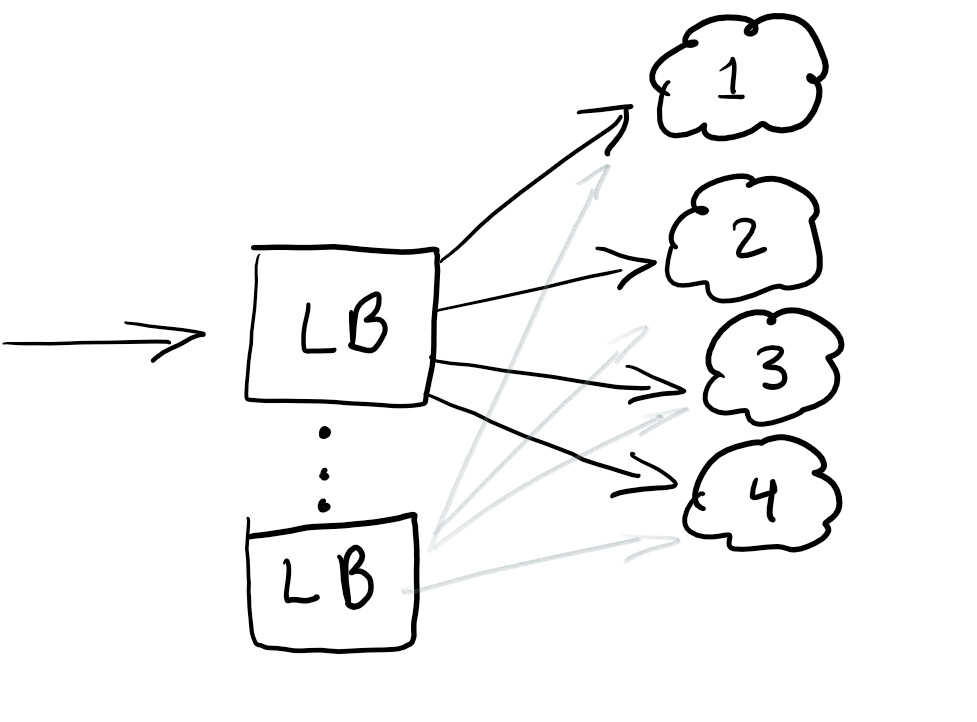
Ein Load Balancer kann im Allgemeinen gut zur Verteilung des Datenverkehrs beitragen. Es wird empfohlen, das Gleichgewicht zu halten, damit Sie keinen einzigen Fehlerpunkt haben.
In der Regel werden Load Balancer in der von Ihnen verwendeten Cloud konfiguriert.
RayID, Korrelations-ID oder UUID für Anfragen
Haben Sie jemals einen Fehler in einer Anwendung mit der folgenden Meldung festgestellt: „Es ist ein Fehler aufgetreten . Speichern Sie diese ID und senden Sie es an unser Support - Team“ ?
Eindeutiger Bezeichner, Korrelations-ID, RayID oder eine der Variationen ist ein eindeutiger Bezeichner, mit dem Sie eine Anforderung während ihres gesamten Lebenszyklus verfolgen können. Auf diese Weise können Sie den gesamten Pfad der Anforderung in den Protokollen verfolgen.
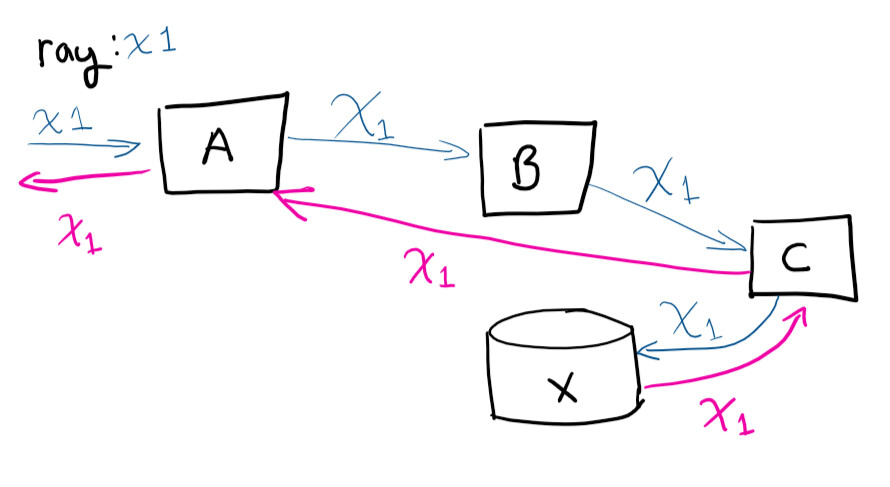
Der Benutzer stellt eine Anforderung an System A, dann an A, kontaktiert B, kontaktiert C, speichert in X, und die Anforderung kehrt zu A zurück.
Wenn Sie eine Remoteverbindung zu virtuellen Maschinen herstellen und versuchen, den Anforderungspfad zu verfolgen (und manuell zu korrelieren, welche Anrufe auftreten), du würdest verrückt werden. Eine eindeutige Kennung erleichtert das Leben erheblich. Dies ist eine der einfachsten Maßnahmen, um Zeit zu sparen, wenn Ihr Service wächst.
Mittelstufe
Die Beratung hier ist komplexer als die vorherigen, aber die richtigen Tools erleichtern die Aufgabe und bieten selbst kleinen und mittleren Unternehmen einen Return on Investment.
Zentralisierte Protokollierung
Herzliche Glückwünsche! Sie haben 100 virtuelle Maschinen bereitgestellt. Am nächsten Tag kommt der CEO herein und beschwert sich über einen Fehler, den er beim Testen des Dienstes erhalten hat. Es wird die entsprechende ID gemeldet, über die wir oben gesprochen haben. Sie müssen jedoch die Protokolle von 100 Computern durchsuchen, um die zu finden, die den Absturz verursacht hat. Und sie muss vor der morgigen Präsentation gefunden werden.
Während dies nach einem lustigen Abenteuer klingt, sollten Sie sicherstellen, dass Sie alle Magazine von einem Ort aus durchsuchen können. Ich habe das Problem der Zentralisierung von Protokollen mit der integrierten Funktionalität des ELK-Stacks gelöst: Es unterstützt die durchsuchbare Protokollsammlung. Dies wird wirklich helfen, das Problem beim Finden eines bestimmten Protokolls zu lösen. Als Bonus können Sie Diagramme und andere lustige Dinge wie diese erstellen.
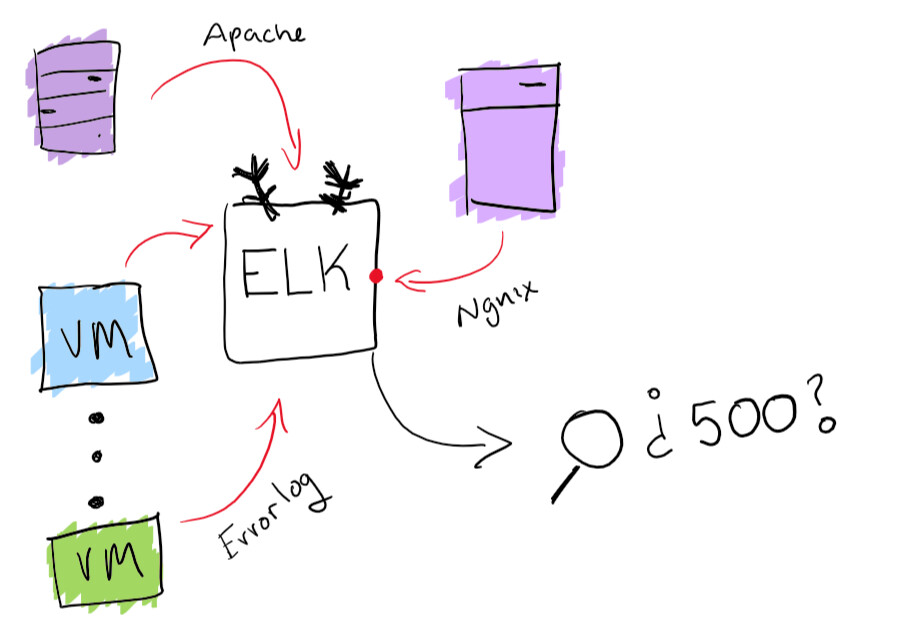
ELK-Stack-Funktionalität
Überwachungsagenten
Jetzt, da Ihr Dienst betriebsbereit ist, müssen Sie sicherstellen, dass er reibungslos funktioniert. Der beste Weg, dies zu tun, besteht darin, mehrere Agenten auszuführen, die parallel ausgeführt werden, und zu überprüfen, ob sie ausgeführt werden und grundlegende Vorgänge ausgeführt werden.
An diesem Punkt stellen Sie sicher, dass die laufende Baugruppe ordnungsgemäß funktioniert und ordnungsgemäß funktioniert .
Für kleine bis mittlere Projekte empfehle ich Postman zur Überwachung und Dokumentation von APIs. Im Allgemeinen müssen Sie jedoch nur sicherstellen, dass Sie wissen, wann ein Fehler aufgetreten ist, und rechtzeitig Benachrichtigungen erhalten.
Automatische Skalierung basierend auf der Last
Es ist sehr einfach. Wenn eine virtuelle Maschine Anforderungen bedient und sich einer Speicherauslastung von fast 80% nähert, können Sie entweder ihre Ressourcen erhöhen oder dem Cluster weitere virtuelle Maschinen hinzufügen. Die automatische Ausführung dieser Vorgänge eignet sich hervorragend für elastische Leistungsänderungen unter Last. Sie sollten jedoch immer darauf achten, wie viel Geld Sie ausgeben, und angemessene Grenzen setzen.
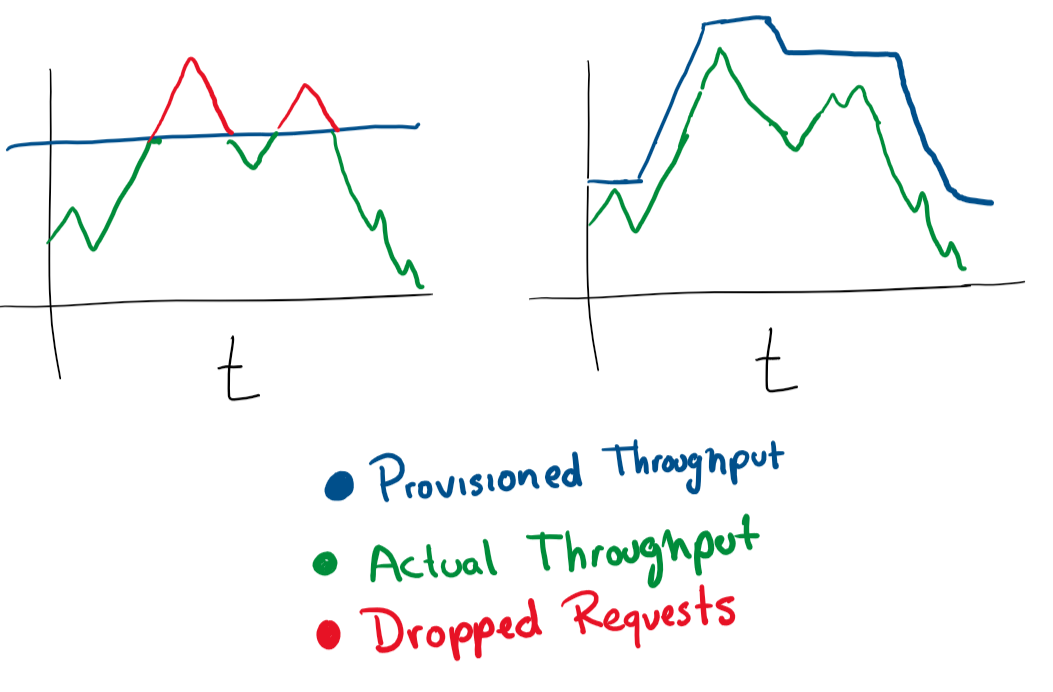
In den meisten Cloud-Diensten können Sie die automatische Skalierung mit mehr Servern oder leistungsstärkeren Servern konfigurieren.
Experimentiersystem
Eine gute Möglichkeit, Updates sicher bereitzustellen, besteht darin, innerhalb einer Stunde etwas für 1% der Benutzer testen zu können. Sie haben solche Mechanismen sicherlich in Aktion gesehen. Beispielsweise zeigt Facebook Teilen des Publikums eine andere Farbe oder ändert die Schriftgröße, um zu sehen, wie Benutzer die Änderung wahrnehmen. Dies wird als A / B-Test bezeichnet.
Sogar das Freigeben einer neuen Funktion kann als Experiment ausgeführt und dann herausgefunden werden, wie sie freigegeben werden kann. Sie haben auch die Möglichkeit, sich im laufenden Betrieb an die Konfiguration zu erinnern oder diese zu ändern, wobei die Funktion berücksichtigt wird, die die Verschlechterung Ihres Dienstes verursacht.
Fortgeschrittenes Level
Hier sind einige Tipps, die ziemlich schwierig zu implementieren sind. Sie werden wahrscheinlich etwas mehr Ressourcen benötigen, daher wird es für ein kleines bis mittleres Unternehmen schwierig sein, damit umzugehen.
Blaugrüne Bereitstellungen
Dies ist die Bereitstellungsmethode "Erlang". Erlang war weit verbreitet, als die Telefongesellschaften kamen. Soft-Schalter wurden verwendet, um Telefonanrufe weiterzuleiten. Das Hauptaugenmerk der Software auf diesen Switches lag nicht darauf, Anrufe während System-Upgrades abzubrechen. Erlang bietet eine hervorragende Möglichkeit, ein neues Modul zu laden, ohne das vorherige zum Absturz zu bringen.
Dieser Schritt hängt vom Vorhandensein eines Load Balancers ab. Angenommen, Sie haben Version N Ihrer Software und möchten dann Version N + 1 bereitstellen.
Sie können den Dienst einfach beenden und die nächste Version zu einem Zeitpunkt bereitstellen, der für Ihre Benutzer günstig ist, und Ausfallzeiten verursachen. Aber nehmen wir an, Sie habenwirklich strenge SLA-Bedingungen. SLA 99,99% bedeutet also, dass Sie nur 52 Minuten pro Jahr offline gehen können .
Wenn Sie dies wirklich erreichen möchten, benötigen Sie zwei Bereitstellungen gleichzeitig:
- derjenige, der gerade ist (N);
- nächste Version (N + 1).
Sie weisen den Load Balancer an, einen Prozentsatz Ihres Datenverkehrs auf die neue Version (N + 1) umzuleiten, während Sie selbst Regressionen aktiv verfolgen.
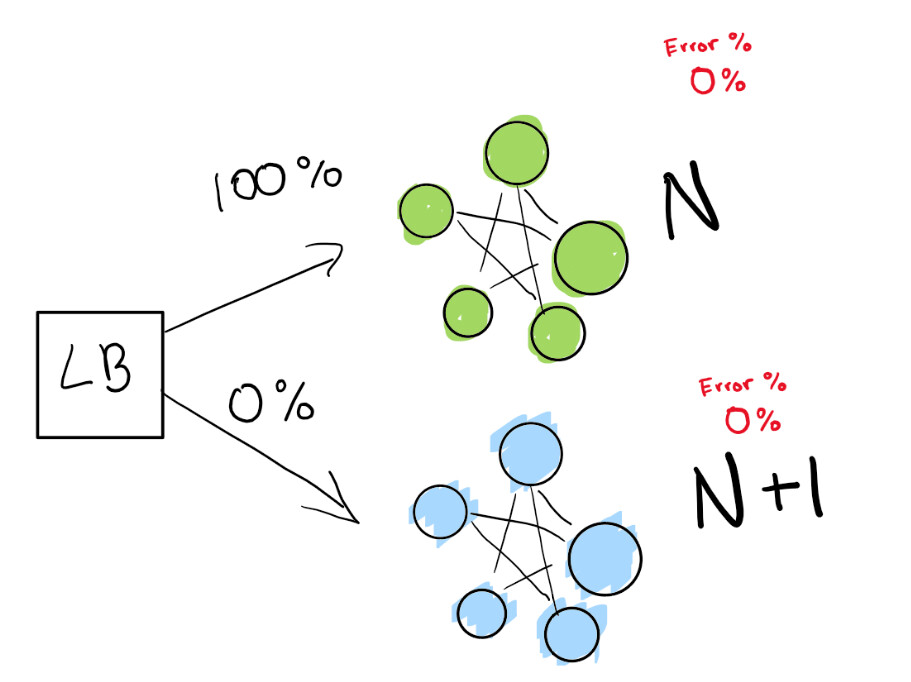
Hier haben wir eine grüne Bereitstellung N, die gut funktioniert. Wir versuchen, mit der nächsten Version dieser Bereitstellung fortzufahren.
Zuerst senden wir einen wirklich kleinen Test, um festzustellen, ob unsere N + 1-Bereitstellung mit wenig Datenverkehr funktioniert:
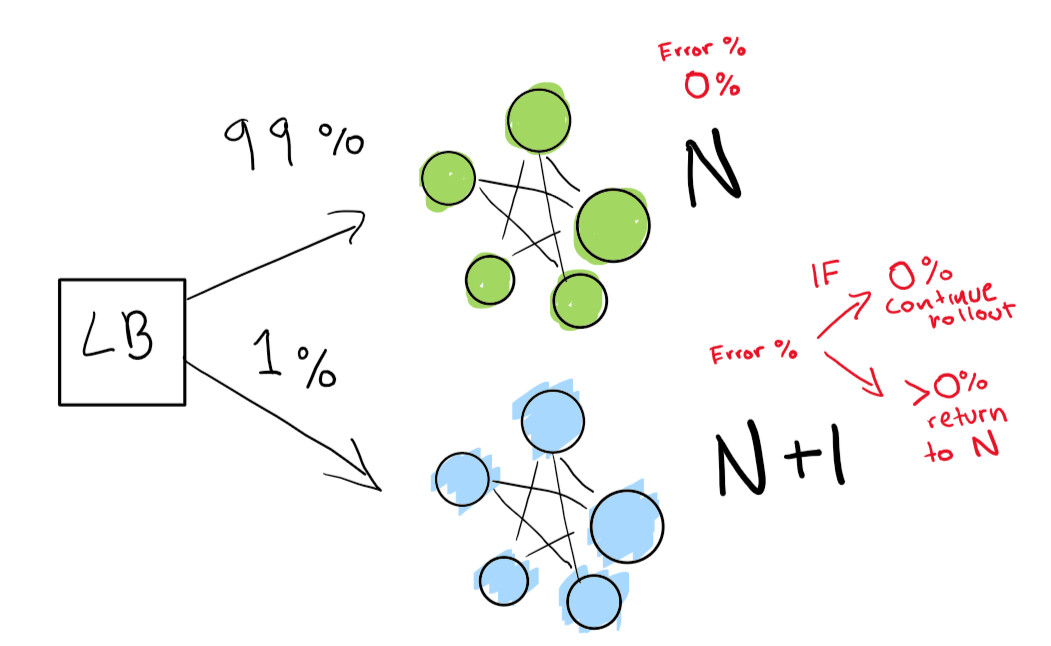
Schließlich haben wir eine Reihe automatisierter Überprüfungen, die wir bis zum Abschluss unserer Bereitstellung ausführen. Wenn Sie wirklich sehr, sehr vorsichtig sind, können Sie Ihre N-Bereitstellung auch für immer behalten, um im Falle einer schlechten Regression einen schnellen Rollback durchzuführen:
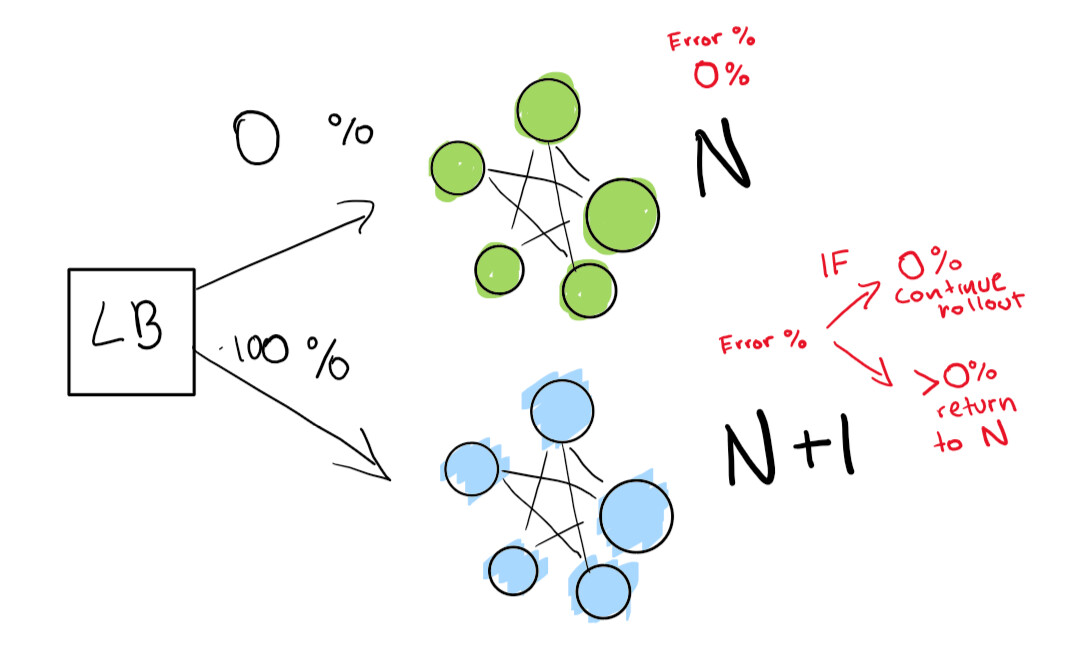
Wenn Sie eine noch weiter fortgeschrittene Stufe erreichen möchten, lassen Sie alles in der blau-grünen Bereitstellung automatisch erledigen.
Anomalieerkennung und automatische Schadensbegrenzung
Da Sie über eine zentralisierte Protokollierung und eine gute Protokollsammlung verfügen, können Sie bereits höhere Ziele festlegen. Zum Beispiel proaktive Vorhersage von Fehlern. Auf Monitoren und in Protokollen werden Funktionen verfolgt und verschiedene Diagramme erstellt - und Sie können im Voraus vorhersagen, was schief gehen wird:
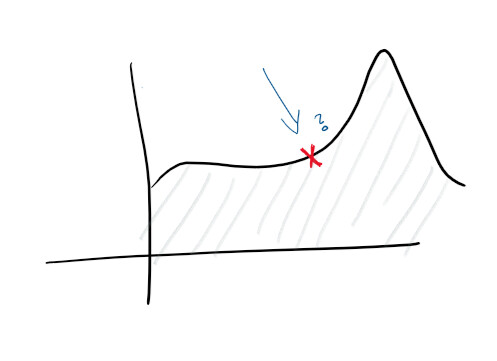
Mit der Entdeckung von Anomalien beginnen Sie, einige der Hinweise zu untersuchen, die der Dienst verursacht. Ein Anstieg der CPU-Auslastung kann beispielsweise darauf hinweisen, dass eine Festplatte ausfällt, während ein Anstieg der Anforderungen bedeutet, dass Sie skalieren müssen. Diese Art von Statistik ermöglicht es uns, den Service proaktiv zu gestalten.
Mit dieser Erkenntnis können Sie in jeder Dimension skalieren und die Eigenschaften von Maschinen, Datenbanken, Verbindungen und anderen Ressourcen proaktiv und reaktiv ändern.
Das ist alles!
Diese Prioritätenliste erspart Ihnen viel Ärger, wenn Sie einen Cloud-Dienst aufrufen.
Der Autor des Originalartikels lädt die Leser ein, ihre Kommentare zu hinterlassen und Änderungen vorzunehmen. Der Artikel wird als Open Source verbreitet, der Autor akzeptiert Pull-Anfragen auf Github .
Was gibt es sonst noch zu diesem Thema zu lesen: