Wenn Sie Backend-Anwendungen oder -Datenbanken für eine Weile entworfen haben, haben Sie wahrscheinlich Code geschrieben, um paginierte Abfragen auszuführen. Zum Beispiel - so:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Wie es ist?
Aber wenn Sie so paginiert haben, muss ich leider sagen, dass Sie es nicht auf die effizienteste Weise getan haben.
Willst du mit mir streiten? Sie müssen keine Zeit verschwenden . Slack , Shopify und Mixmax verwenden bereits die Tricks, über die ich heute sprechen möchte. Nennen Sie mindestens ein Entwickler-Backend, das nie verwendet wurde, und führen Sie Abfragen mit Paginierung durch. In MVP (Minimum Viable Product, Minimum Viable Product) und in Projekten, in denen kleine Datenmengen verwendet werden, ist dieser Ansatz durchaus anwendbar. Es funktioniert sozusagen einfach.
OFFSETLIMIT
Wenn Sie jedoch zuverlässige und effiziente Systeme von Grund auf neu erstellen müssen, sollten Sie sich im Voraus um die Effizienz von Abfragen an die in solchen Systemen verwendeten Datenbanken kümmern.
Heute werden wir über die Probleme sprechen, die mit weit verbreiteten (leider) Implementierungen von paginierten Abfrageausführungs-Engines verbunden sind, und darüber, wie bei der Ausführung solcher Abfragen eine hohe Leistung erzielt werden kann.
Was ist los mit OFFSET und LIMIT?
Wie gesagt,
OFFSETund LIMITzeigen sich perfekt in Projekten, die nicht mit großen Datenmengen arbeiten müssen.
Das Problem tritt auf, wenn die Datenbank so groß wird, dass sie nicht mehr in den Speicher des Servers passt. Während Sie mit dieser Datenbank arbeiten, müssen Sie jedoch paginierte Abfragen verwenden.
Damit sich dieses Problem manifestiert, muss eine Situation auftreten, in der das DBMS bei der Ausführung jeder Abfrage mit Paginierung auf einen ineffizienten Full Table Scan-Vorgang zurückgreift (gleichzeitig können Dateneinfüge- und Löschvorgänge auftreten und wir brauchen keine veralteten Daten!).
Was ist ein "vollständiger Tabellenscan" (oder "sequentieller Tabellenscan", sequentieller Scan)? Dies ist eine Operation, bei der das DBMS nacheinander jede Zeile der Tabelle, dh die darin enthaltenen Daten, liest und sie mit einer bestimmten Bedingung vergleicht. Diese Art der Tabellensuche ist bekanntermaßen die langsamste. Tatsache ist, dass bei der Ausführung viele E / A-Vorgänge ausgeführt werden, die das Festplattensubsystem des Servers verwenden. Die Situation wird durch die Verzögerungen bei der Arbeit mit auf Festplatten gespeicherten Daten und die Tatsache, dass das Übertragen von Daten von der Festplatte in den Speicher ein ressourcenintensiver Vorgang ist, noch verschärft.
Sie haben beispielsweise Datensätze von 100.000.000 Benutzern und führen eine Abfrage mit der Konstruktion aus
OFFSET 50000000... Dies bedeutet, dass das DBMS alle diese Datensätze laden muss (und wir brauchen sie nicht einmal!), Sie im Speicher ablegen muss und erst danach beispielsweise 20 gemeldete Ergebnisse benötigt LIMIT.
Nehmen wir an, es könnte so aussehen: "Wählen Sie die Zeilen 50.000 bis 50020 von 100.000 aus." Das heißt, das System muss zuerst 50.000 Zeilen laden, um die Abfrage auszuführen. Sehen Sie, wie viel unnötige Arbeit sie zu tun hat?
Wenn Sie mir nicht glauben, schauen Sie sich das Beispiel an, das ich mit db-fiddle.com erstellt habe .

Beispiel bei db-fiddle.com
Links im Feld
Schema SQLbefindet sich Code zum Einfügen von 100.000 Zeilen in die Datenbank, und rechts im FeldQuery SQLwerden zwei Abfragen angezeigt. Das erste, langsam, sieht so aus:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Und die zweite, die eine effektive Lösung für dasselbe Problem darstellt, wie diese:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Um diese Anforderungen zu erfüllen, klicken Sie einfach auf die Schaltfläche
Runoben auf der Seite. Vergleichen Sie anschließend die Informationen zur Ausführungszeit der Abfrage. Es stellt sich heraus, dass die Ausführung einer ineffizienten Abfrage mindestens 30-mal länger dauert als die Ausführung der zweiten (diese Zeit unterscheidet sich von Start zu Start, z. B. kann das System melden, dass die erste Anforderung 37 ms gedauert hat, und Ausführung der Sekunde - 1 ms).
Und wenn es mehr Daten gibt, wird alles noch schlimmer aussehen (um dies zu überprüfen, schauen Sie sich mein Beispiel mit 10 Millionen Zeilen an).
Was wir gerade besprochen haben, soll Ihnen einen Einblick geben, wie Datenbankabfragen tatsächlich behandelt werden.
Denken Sie daran, dass der Wert umso größer ist
OFFSET - Je länger die Anfrage dauert.
Was sollte anstelle einer Kombination aus OFFSET und LIMIT verwendet werden?
Statt einer Kombination
OFFSET, LIMITist es wert , eine Struktur aufgebaut nach folgendem Schema verwendet:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Dies ist die Ausführung einer Cursor-basierten Paginierungsabfrage.
Anstelle des lokal gespeicherten Stroms
OFFSETund des LIMITSendens an jede Anforderung muss der zuletzt empfangene Primärschlüssel (normalerweise - a ID) gespeichert werden, und LIMITals Ergebnis wird eine Aufforderung angezeigt, die der oben angegebenen ähnelt.
Warum? Tatsache ist, dass Sie Ihrem DBMS durch explizite Angabe der Kennung der zuletzt gelesenen Zeile mitteilen, wo es nach den benötigten Daten suchen muss. Darüber hinaus wird die Suche dank der Verwendung des Schlüssels effizient durchgeführt, und das System muss nicht durch Linien abgelenkt werden, die außerhalb des angegebenen Bereichs liegen.
Schauen wir uns den folgenden Leistungsvergleich verschiedener Abfragen an. Hier ist eine ineffektive Abfrage.
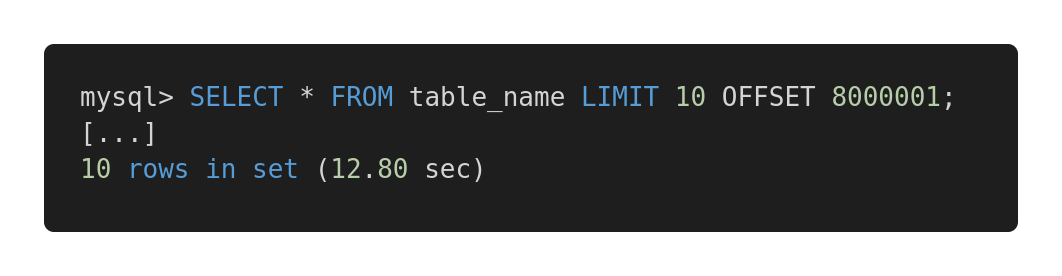
Langsame Abfrage
Und hier ist eine optimierte Version dieser Abfrage.

Schnelle Abfrage
Beide Abfragen geben genau die gleiche Datenmenge zurück. Der erste dauert 12,80 Sekunden und der zweite 0,01 Sekunden. Fühlst du den Unterschied?
Mögliche Probleme
Damit die vorgeschlagene Abfrageausführungsmethode effizient funktioniert, muss die Tabelle eine Spalte (oder Spalten) enthalten, die eindeutige sequentielle Indizes enthält, z. B. eine Ganzzahlkennung. In bestimmten Fällen kann dies den Erfolg der Verwendung solcher Abfragen bestimmen, um die Arbeitsgeschwindigkeit mit der Datenbank zu erhöhen.
Natürlich müssen Sie beim Entwerfen von Abfragen die Besonderheiten der Architektur der Tabellen berücksichtigen und die Mechanismen auswählen, die sich am besten in den vorhandenen Tabellen zeigen. Wenn Sie beispielsweise in Abfragen mit großen Mengen verwandter Daten arbeiten müssen, ist dieser Artikel möglicherweise interessant .
Wenn wir mit dem Problem des Fehlens eines Primärschlüssels konfrontiert sind, z. B. wenn wir eine Tabelle mit einer Viele-zu-Viele-Beziehung haben, funktioniert der traditionelle Ansatz der Verwendung
OFFSETund LIMITgarantiert für uns. Die Anwendung kann jedoch zur Ausführung potenziell langsamer Abfragen führen. In solchen Fällen würde ich die Verwendung eines automatisch inkrementierenden Primärschlüssels empfehlen, auch wenn Sie ihn nur zum Organisieren paginierter Abfragen benötigen.
Wenn Sie sich für dieses Thema interessieren - hier , hier und hier - einige nützliche Materialien.
Ergebnis
Die wichtigste Schlussfolgerung, die wir ziehen können, ist, dass es immer notwendig ist, die Geschwindigkeit der Abfrageausführung zu analysieren, unabhängig von der Größe der Datenbanken. In unserer Zeit ist die Skalierbarkeit von Lösungen äußerst wichtig. Wenn Sie von Beginn der Arbeit an einem bestimmten System an alles richtig entwerfen, kann dies den Entwickler in Zukunft vor vielen Problemen bewahren.
Wie analysieren und optimieren Sie Datenbankabfragen?
