
Mein Name ist Alexander Deulin, ich arbeite in der Entwicklungsabteilung meiner eigenen Entwicklungsfabrik "Factory of Microservices" bei MegaFon. Und ich möchte Ihnen etwas über den schwierigen Weg der Entstehung von Tarantool-Caches in der Landschaft unseres Unternehmens sowie über die Implementierung der Replikation von Oracle erzählen. Und ich werde sofort erklären, dass in diesem Fall der Cache eine Anwendung mit einer Datenbank bedeutet.
Tarantool-Caches
Wir haben bereits viel darüber gesprochen, wie wir Unified Billing bei MegaFon implementiert haben. Wir werden nicht näher darauf eingehen, aber jetzt ist das Projekt in der Abschlussphase. Daher nur eine kleine Statistik:
Mit dem, was wir uns unserer Aufgabe genähert haben:
- 80 Millionen Abonnenten;
- 300 Millionen Abonnentenprofile;
- 2 Milliarden Transaktionsereignisse, um das Gleichgewicht pro Tag zu ändern;
- 250 TB aktive Daten;
- > 8 PB Archive;
- All dies befindet sich auf 5000 Servern in verschiedenen Rechenzentren.
Das heißt, wir sprechen von einem hoch ausgelasteten System, in dem jedes Subsystem 80 Millionen Abonnenten bedient. Wenn wir früher 7 Instanzen und eine bedingte horizontale Skalierung hatten, wechselten wir jetzt zur Domäne. Früher gab es einen Monolithen, jetzt haben wir DDD. Das System wird von der API gut abgedeckt, unterteilt in Subsysteme, aber nicht überall gibt es einen Cache. Jetzt sind wir mit der Tatsache konfrontiert, dass Subsysteme eine immer größere Last erzeugen. Darüber hinaus werden neue Kanäle angezeigt, bei denen 5000 Anforderungen pro Sekunde und Operation mit einer Latenz von 50 ms in 95% der Fälle bereitgestellt und die Verfügbarkeit auf einem Niveau von 99,99% sichergestellt werden muss.
Parallel dazu haben wir begonnen, eine Microservice-Architektur zu erstellen.

Wir haben eine separate Schicht von Caches, in die Daten von jedem Subsystem erhoben werden. Dies macht es einfach, Verbundwerkstoffe zusammenzubauen und von hohen Leseaufwänden zu isolieren.
Wie erstelle ich einen Cache für geschlossene Subsysteme?
Wir haben beschlossen, dass wir Caches selbst erstellen müssen, ohne uns auf den Anbieter zu verlassen. Unified Billing ist ein geschlossenes Ökosystem. Es enthält viele Microservice-Muster mit zahlreichen APIs und eigenen Datenbanken. Aufgrund der geschlossenen Natur ist es jedoch unmöglich, etwas zu ändern.
Wir begannen darüber nachzudenken, wie wir uns unseren Mastersystemen nähern sollten. Ein sehr beliebter Ansatz ist das ereignisgesteuerte Design, wenn wir Daten von einer Art Bus erhalten: Entweder handelt es sich um ein Kafka-Thema, oder Sie tauschen RabbitMQ aus. Sie können Daten auch von Oracle abrufen: durch Trigger mit CQN (einem kostenlosen Tool von Oracle) oder Golden Gate. Da wir uns nicht in die Anwendung integrieren können, standen uns die Optionen zum Durchschreiben und Zurückschreiben nicht zur Verfügung.
Empfangen von Daten vom Nachrichtenverteilerbus
Wir mögen die Option mit Warteschlangen und mit Nachrichtenmanagern sehr. RabbitMQ und Kafka werden bereits in "Unified Billing" verwendet. Wir haben eines der Systeme pilotiert und ein hervorragendes Ergebnis erzielt. Wir erhalten alle Ereignisse von RabbitMQ und laden kalt, die Datenmenge ist nicht sehr groß.
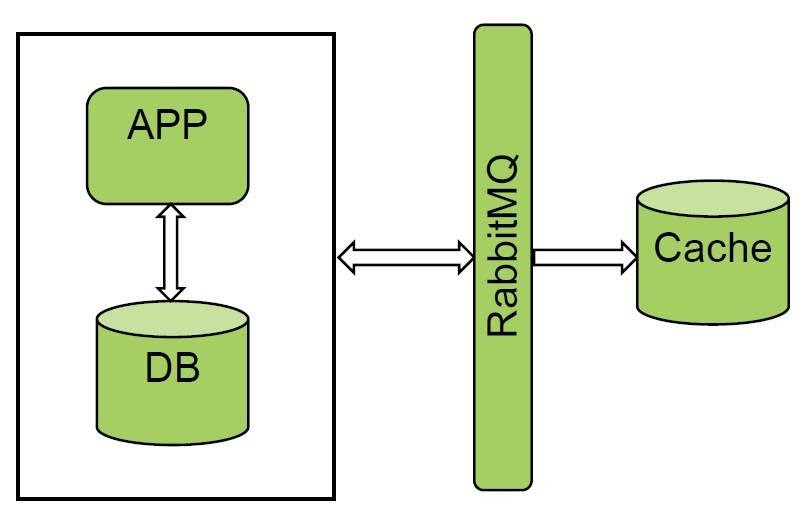
Die Lösung funktioniert einwandfrei, aber nicht alle Systeme können Busse benachrichtigen, sodass diese Option bei uns nicht funktioniert hat.
Daten aus der Datenbank abrufen: Auslöser
Es gab immer noch eine Möglichkeit, Daten aus der Datenbank abzurufen, um den Cache zu füllen.
Die einfachste Option sind Trigger. Sie sind jedoch nicht für Hochlastanwendungen geeignet, da wir zum einen das Mastersystem selbst modifizieren und zum anderen einen zusätzlichen Fehlerpunkt darstellen. Wenn der Trigger plötzlich nicht mehr in der Lage war, auf eine temporäre Platte zu schreiben, kommt es zu einer vollständigen Verschlechterung, einschließlich des Mastersystems.

Daten aus der Datenbank abrufen: CQN
Die zweite Option zum Abrufen von Daten aus der Datenbank. Wir verwenden Oracle und der Anbieter unterstützt derzeit nur ein kostenloses Tool zum Abrufen von Daten aus der Datenbank - CQN.
Mit diesem Mechanismus können Sie Benachrichtigungen über DDL- oder DML-Betriebsänderungen abonnieren. Dort ist alles ganz einfach. Es gibt Benachrichtigungen im JDBC- und PL / SQL-Stil.
JDBC bedeutet, dass wir die erweiterte Warteschlange benachrichtigen und dieses Ereignis an das externe System gesendet wird. Tatsächlich wird ein externer OSI-Anschluss benötigt. Diese Option hat uns nicht gefallen, da wir unsere Nachricht nicht lesen können, wenn wir die Verbindung zu Oracle verlieren.
Wir haben uns für PL / SQL entschieden, weil es uns ermöglicht, die Benachrichtigung abzufangen und in einer temporären Tabelle in derselben Oracle-Datenbank zu speichern. Das heißt, auf diese Weise können Sie eine gewisse Transaktionsintegrität bereitstellen.
Am Anfang hat alles gut funktioniert, bis wir eine ziemlich beladene Basis pilotiert haben. Folgende Mängel traten auf:
- Transaktionslast auf der Basis. Wenn wir eine Nachricht aus der Benachrichtigungswarteschlange abfangen, müssen wir sie in die Basis stellen. Das heißt, die Schreiblast verdoppelt sich.
- Es wird auch eine interne erweiterte Warteschlange verwendet. Und wenn Ihr Master-System es auch verwendet, kann ein Wettbewerb um die Warteschlange entstehen.
- Wir haben einen interessanten Fehler bei partitionierten Tabellen erhalten. Wenn ein Commit mehr als 100 Änderungen abschließt, erfasst CQN solche Änderungen nicht. Wir haben ein Ticket in Oracle geöffnet, die Systemparameter geändert - es hat nicht geholfen.
Für schwere Anwendungen ist CQN definitiv nicht geeignet. Es ist gut für kleine Installationen, für die Arbeit mit Wörterbüchern und Referenzdaten.
Daten aus der Datenbank abrufen: Golden Gate
Das gute alte Golden Gate bleibt erhalten. Anfangs wollten wir es nicht verwenden, da es sich um eine altmodische Lösung handelt. Wir waren von der Komplexität des Systems selbst eingeschüchtert.

In GG selbst mussten zwei zusätzliche Instanzen gewartet werden, und wir haben nicht viel Oracle-Wissen. Anfangs war es ziemlich schwierig, obwohl uns die Möglichkeiten der Lösung sehr gut gefallen haben.
Mit der SCN + XID-Kombination konnten wir die Transaktionsintegrität überwachen. Die Lösung erwies sich als universell und hat nur geringe Auswirkungen auf das Mastersystem, von dem wir alle Ereignisse empfangen können. Obwohl für die Lösung der Kauf einer Lizenz erforderlich ist, war dies für uns kein Problem, da die Lizenz bereits verfügbar war. Zu den Nachteilen der Lösung gehören auch eine komplexe Implementierung und die Tatsache, dass GG ein zusätzliches Subsystem ist.
Schlussfolgerungen
Welche Schlussfolgerungen können aus dem oben Gesagten gezogen werden?
Wenn Sie ein geschlossenes System haben, müssen Sie die Art Ihrer Last und die Verwendungsmöglichkeiten untersuchen und die geeignete Lösung auswählen. Das Optimum ist unserer Meinung nach das ereignisgesteuerte Design, wenn wir ein Thema in Kafka benachrichtigen und der Nachrichtenbroker zum Mastersystem wird. Ein Thema ist ein goldener Rekord, der Rest der Daten wird vom System übernommen. Für geschlossene Systeme in unserer Landschaft erwies sich GG als die erfolgreichste Lösung.
PIM - Food Showcase
Und jetzt werde ich Ihnen am Beispiel eines der Produkte erklären, wie wir diese Lösung angewendet haben. PIM ist eine SID-basierte Produktpräsentation. Das heißt, dies sind alle Produkte des Abonnenten, die derzeit mit ihm verbunden sind. Auf ihrer Grundlage werden Ausgaben berechnet und die Arbeitslogik aufgebaut.
Die Architektur
Ich möchte Sie daran erinnern, dass in diesem Artikel "Cache" eine Kombination aus einer Anwendung und einer Datenbank bedeutet. Dies ist das Hauptverwendungsmuster für Tarantool.
Die Besonderheit des PIM-Projekts besteht darin, dass das ursprüngliche Oracle-Mastersystem "klein" ist und nur 10 Milliarden Datensätze enthält. Es muss gelesen werden. Das größte Problem, das wir gelöst haben, war das Aufwärmen des Caches.
Wo haben wir angefangen?

Die 10 Haupttabellen geben 10 Milliarden Datensätze an. Wir wollten sie direkt lesen. Da wir nur heiße Daten in den Cache stellen und Oracle unter anderem historische Daten speichert, mussten wir eine where-Klausel festlegen und diese 10 Milliarden herausziehen. Eine nicht triviale Aufgabe. Oracle sagte uns, dass dies nicht getan werden sollte: Die Prozessorlast wurde auf 100% erhöht. Wir beschlossen, den anderen Weg zu gehen.
Aber zuerst ein paar Worte zur Clusterarchitektur.
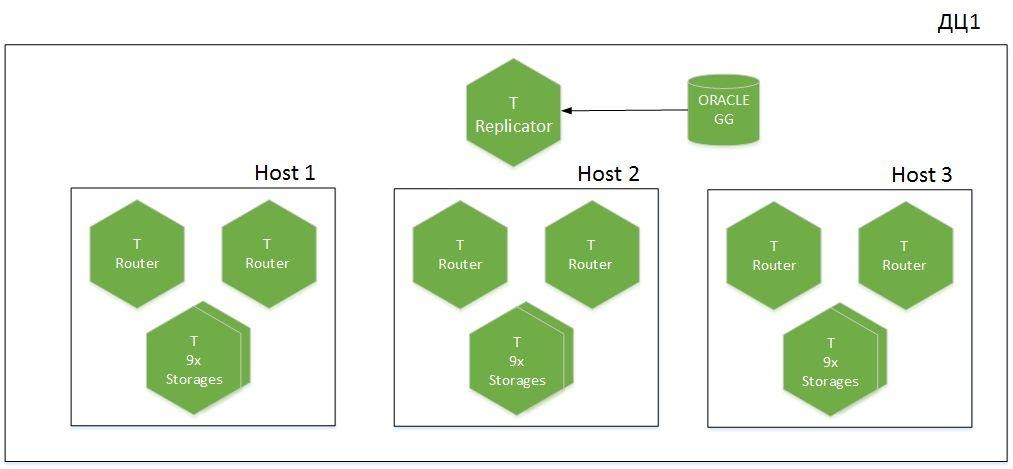
Dies ist eine Sharded-Anwendung, 9 Shards auf 6 Hosts, verteilt auf zwei Rechenzentren. Wir haben Tarantool mit der Rolle des Replikators, der Daten von Oracle empfängt, und eine andere Instanz namens Importer wird für den Kaltstart verwendet. Insgesamt werden 1,1 TB heiße Daten im Cache ausgelöst.
Kaltstart
Wie haben wir das Kaltstartproblem gelöst? Alles erwies sich als ziemlich trivial.

Wie funktioniert der gesamte Mechanismus? Wir haben die where-Klausel entfernt und alles gelesen. Zuerst starten wir den Redo-Log-Stream, um tatsächlich Online-Änderungen aus der Datenbank zu erhalten. Beim vollständigen Scannen gehen wir die Unterabschnitte durch und nehmen Daten in Chargen mit Normalisierung und Filtration auf. Wir speichern die Änderungen, führen parallel ein Cold-Cache-Warm-up durch und speichern alles in CSV-Dateien. Im Cache werden 10 Importer-Instanzen ausgeführt, die nach dem Lesen von Oracle Daten an Tarantool-Instanzen senden. Zu diesem Zweck berechnet jeder Importer den erforderlichen Shard und legt die Daten im erforderlichen Speicher selbst ab, ohne die Router zu laden.
Nachdem wir alle Daten von Oracle geladen haben, spielen wir den Stream der Trails von GG ab, die sich in dieser Zeit angesammelt haben. Wenn SCN + XID mit dem Mastersystem akzeptable Werte erreicht, wird davon ausgegangen, dass der Cache aufgewärmt ist, und die Last beim Lesen von externen Systemen berücksichtigt.
Einige Statistiken. Bei Oracle verfügen wir über ca. 2,5 TB Rohdaten. Wir lesen sie 5 Stunden lang und importieren sie in CSV. Das Laden in Tarantool mit Filterung und Normalisierung dauert 8 Stunden. Und sechs Stunden lang spielen wir die gesammelten Protokolle, die von der Spur zu uns kommen. Spitzengeschwindigkeit von 600.000 Datensätzen / s. bis zu 1 Million in Spitzen. Tarantool fügt 1,1 TB Daten mit 200.000 Datensätzen / s ein.
Das kalte Aufwärmen des Caches bei großen Volumina ist für uns mittlerweile alltäglich, da wir keinen großen Einfluss auf Oracle haben.

Anstelle der Basis laden wir die E / A und das Netzwerk. Daher müssen wir zunächst sicherstellen, dass die Netzwerkbandbreite ausreichend ist. In unseren Spitzenwerten erreicht sie 400 Mbit / s.
Funktionsweise der Replikationskette von Oracle zu Tarantool
Beim Entwerfen des Caches haben wir beschlossen, Speicherplatz zu sparen. Wir haben alle Redundanzen entfernt, fünf Tabellen zu einer zusammengefasst und ein sehr kompaktes Speicherschema erhalten, aber die Kontrolle über die Konsistenz verloren. Wir sind zu dem Schluss gekommen, dass die DDL von Oracle wiederholt werden muss. Dies ermöglichte es uns, SCN + XIDs zu steuern, indem sie für jede Platte in einem separaten technologischen Raum gespeichert wurden. Wenn Sie sie regelmäßig überprüfen, können Sie feststellen, wo die Replikation fehlgeschlagen ist, und bei Problemen die Archivierungsprotokolle erneut lesen.
Scherben
Ein wenig über logische Datenspeicherung. Um Map Reduce zu eliminieren, mussten wir zusätzliche Datenredundanz einführen und Wörterbücher in unsere eigenen Speicher zerlegen. Wir haben uns bewusst dafür entschieden, weil unser Cache hauptsächlich zum Lesen dient. Wir können es nicht in das Mastersystem integrieren, da diese Anwendung die Last externer Kanäle vom Mastersystem isoliert. Wir lesen alle Daten von Abonnenten aus einem Speicher. In diesem Fall verlieren wir an Schreibleistung, aber es ist nicht so wichtig für uns, Wörterbücher werden selten aktualisiert.
Was ist am Ende passiert?
Wir haben einen Cache für unser geschlossenes System erstellt. Es gab einige Filterfehler, die wir jedoch bereits behoben haben. Wir haben uns auf die Entstehung neuer Hochlastverbraucher vorbereitet. Letzten Sommer erschien ein neues System, das 5-10.000 Anfragen pro Sekunde hinzufügte, und wir haben diese Last nicht in die "Unified Billing" aufgenommen. Wir haben auch gelernt, wie die Replikation von Oracle nach Tarantool vorbereitet wird, und die Übertragung großer Datenmengen ohne Laden des Mastersystems ausgearbeitet.
Was müssen wir noch tun?
Dies sind hauptsächlich Betriebsszenarien:
- Automatische Kontrolle der Datenkonsistenz.
- Erarbeiten Sie das Oracle Active-Standby-Umschaltskript, sowohl Umschaltung als auch Failover.
- Abspielen von Archivprotokollen von GG.
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru