
Es scheint, dass keine unserer Zusammenfassungen vollständig ist, ohne die Entwicklungen von Open AI zu erwähnen: Im Juli wurde der neue GPT-3-Algorithmus zum am meisten diskutierten Thema im Bereich des maschinellen Lernens. Technisch gesehen ist dies nicht ein Modell, sondern eine ganze Familie, die der Einfachheit halber unter einem einzigen Namen verallgemeinert wird. Das größte Modell verwendet 175 Milliarden Parameter, und für das Training wurde ein Datensatz von 570 GB verwendet, der gefilterte Daten aus Common Crawl-Archiven und hochwertige Daten aus WebText2, Books1, Books2 und Wikipedia enthielt.
Hierbei ist zu beachten, dass das Modell vorab trainiert wurde und keine Feinabstimmung für bestimmte Aufgaben erfordert: Um bessere Ergebnisse zu erzielen, wird empfohlen, mindestens ein (einmaliges) oder mehrere (wenige Schuss) Beispiele für die Lösung von Problemen am Eingang bereitzustellen. Sie können jedoch darauf verzichten sie (Zero-Shot). Damit das Modell eine Lösung für das Problem generiert, reicht es aus, das Problem auf Englisch zu beschreiben. Es wird allgemein angenommen, dass dies ein Algorithmus zum Generieren von Texten ist, aber es ist bereits klar, dass das Potenzial viel größer ist.
Das Modell wurde bereits im Mai vorgestellt. Schon damals zeigte Open AI, dass GPT-3, das auf den GitHub-Repositorys trainiert wurde, erfolgreich Python-Code generieren kann. Nach anderthalb Monaten erhielten die ersten Glücklichen Zugriff auf die API und zeigten ihre Best Practices. Die Ergebnisse sind erstaunlich. Wir als Entwickler sind natürlich daran interessiert, wie sehr dieser Algorithmus unser Leben vereinfachen und vielleicht Wettbewerb schaffen wird.
Der Dienst debuild.co ist bereits erschienen, der gemäß der Textbeschreibung der Funktion einen Arbeitscode erstellt und ein gutes Layout erstellt .
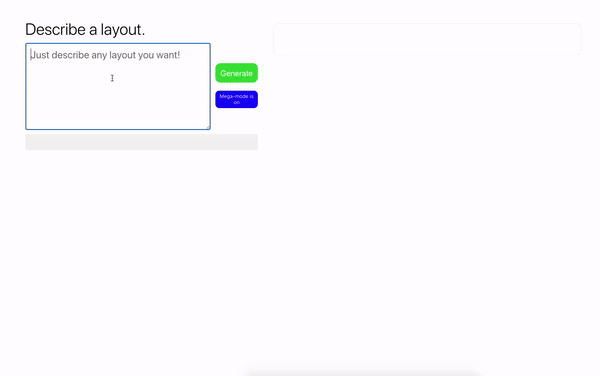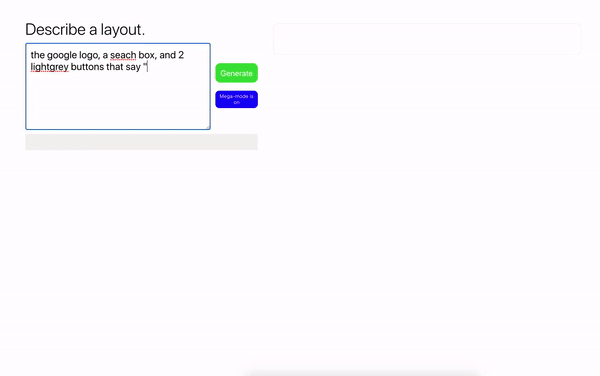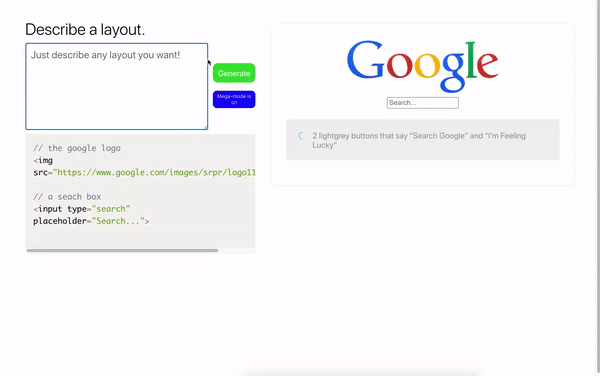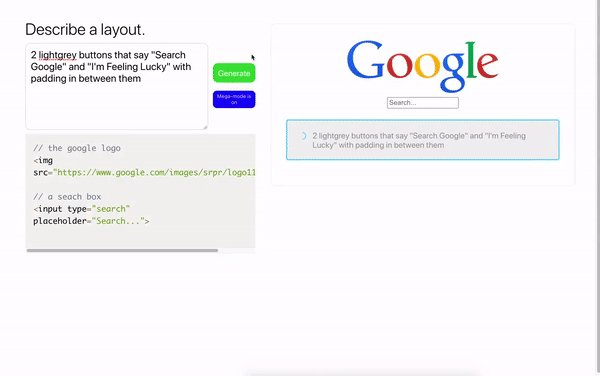
Sie können die Best Practices nicht nur in der Webprogrammierung, sondern auch im Design verwenden. Das Modell ist in der Lage, JSON-Daten durch Textbeschreibung zu generieren und in das Figma-Layout zu übersetzen.
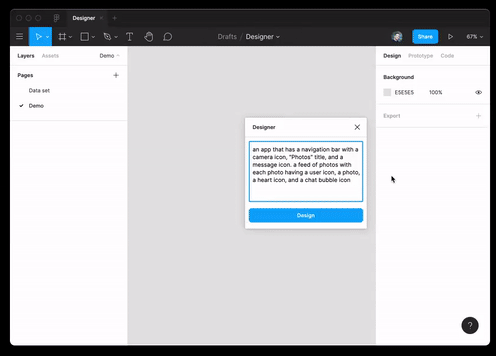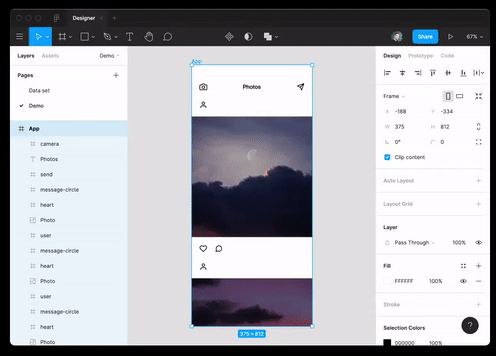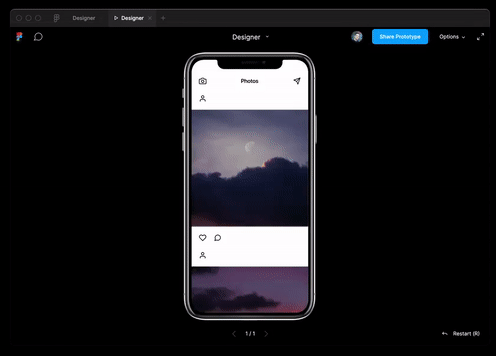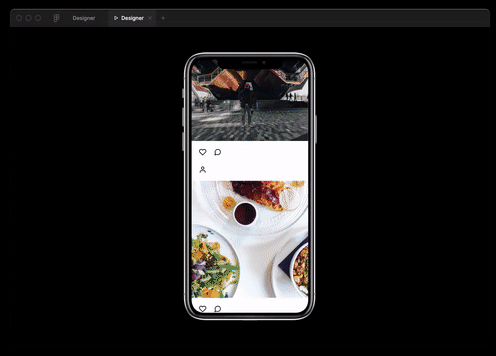
Und auch sie hat es praktisch geschafftInterview für eine Ruby-Entwicklerposition.
Die Nachrichten über den Einsatz von maschinellem Lernen in der Programmierung enden hier nicht.
TransCoder Die
Migration Ihrer Codebasis von einer archaischen Programmiersprache wie COBOL auf eine moderne Alternative wie Java oder C ++ ist eine komplexe, ressourcenintensive Aufgabe, bei der Fachleute beide Technologien beherrschen müssen. Gleichzeitig werden archaische Sprachen immer noch in Großrechnern auf der ganzen Welt verwendet, was den Eigentümern häufig eine schwierige Wahl lässt - entweder die Codebasis manuell in eine moderne Sprache übersetzen oder weiterhin alten Code beibehalten.
Facebook enthüllt Open Source Selbstlernmodell, was diese Aufgabe erleichtern wird. Es ist das erste System, das Code von einer Programmiersprache in eine andere übersetzen kann, ohne dass parallele Trainingsdaten erforderlich sind.
Die Entwickler schätzen, dass das Modell über 90% der Java-Funktionen korrekt in C ++, 74,8% der C ++ - Funktionen in Java und 68,7% der Java-Funktionen in Python übersetzt. Welches ist höher als die Indikatoren der kommerziellen Gegenstücke.
ContraCode-Entwicklungstools
verwenden zunehmend maschinelles Lernen, um von Menschen geschriebenen Code zu verstehen und zu ändern. Die Hauptschwierigkeit bei der Arbeit mit Algorithmen mit Code ist das Fehlen beschrifteter Datensätze.
Forscher in Berkeley schlagen vor, dieses Problem mit der ContraCode-Methode zu lösen. Die Autoren glauben, dass Programme mit derselben Funktionalität dieselben Darstellungen haben sollten und umgekehrt. Daher generieren sie Codevarianten für kontrastives Lernen. Um Daten zu erstellen, werden die Variablen umbenannt, der Code neu formatiert und verschleiert.
In Zukunft kann ein selbstlernendes Modell mit dieser Methode Typen vorhersagen, Fehler erkennen, Code zusammenfassen usw. Angesichts dieser und anderer Fortschritte auf diesem Gebiet ist es möglich, dass Maschinen bald lernen werden, Code genau wie Menschen zu schreiben.
DeepSIM

Die Autoren dieser Studie zeigen, dass ein generatives kontradiktorisches Netzwerk auf einem einzelnen Zielbild komplexe Manipulationen verarbeiten kann.
Das Modell lernt, die primitive Darstellung des Bildes (z. B. nur die Kanten von Objekten auf dem Foto) mit dem Bild selbst abzugleichen. Während der Manipulation können Sie mit dem Generator Bilder ändern, indem Sie ihre primitive Darstellung am Eingang ändern und über das Netzwerk zuordnen. Dieser Ansatz löst das DNN-Problem, das einen großen Trainingsdatensatz erfordert. Die Ergebnisse sind beeindruckend.
3D Photo Inpainting

Eine andere Möglichkeit, 2D-RGB-D-Bilder in 3D zu konvertieren. Der Algorithmus erstellt Bereiche neu, die von Objekten im Originalbild ausgeblendet werden. Als Basisdarstellung wurde ein geschichtetes Tiefenbild verwendet, aus dem das Modell unter Berücksichtigung des Kontexts iterativ neue Farb- und Tiefendaten für den unsichtbaren Bereich synthetisiert. Die Ausgabe sind Fotos, zu denen Sie mit Standard-Grafik-Engines einen Parallaxeeffekt hinzufügen können. Es steht ein Colab zur Verfügung, in dem Sie das Modell selbst testen können.
HiDT

Ein Team russischer Forscher präsentierte einen Open-Source-Algorithmus, der die Tageszeit in Fotografien ändert. Das Modellieren von Beleuchtungsänderungen in hochauflösenden Fotos ist eine Herausforderung. Der vorgestellte Algorithmus kombiniert das generative Bild-zu-Bild-Modell und das Upsampling-Schema, das Transformationen auf hochauflösenden Bildern ermöglicht. Es ist wichtig zu beachten, dass das Modell auf statischen Bildern verschiedener Landschaften ohne Zeitstempel trainiert wurde.
Autoencoder tauschen

Wenn HiDT in der Lage ist, die Beleuchtung in Bildern qualitativ zu ändern, kann dieses neuronale Netzwerk, das auf verschiedenen Datensätzen trainiert wird, nicht nur die Tageszeit, sondern auch die Landschaft ändern. Leider gibt es keine Möglichkeit, den Quellcode zu sehen, sodass wir nur das Video bewundern können, das die Funktionen dieses Modells demonstriert.
SCAN Ein
neuronales Open-Source-Netzwerk, das Bilder unabhängig voneinander in semantisch bedeutsame Cluster gruppiert. Das Neue am Ansatz des Autors ist, dass die Phasen Training und Clustering getrennt sind. Zuerst wird die Aufgabe des Lehrens von Funktionen gestartet, dann basiert das Modell auf den Daten, die in der ersten Phase während des Clustering erhalten wurden. Dies ermöglicht bessere Ergebnisse als andere ähnliche Modelle.
RetrieveGAN

Die Erzeugung neuronaler Netze entwickelt sich rasant, und RetrieveGAN ist eine weitere Bestätigung dafür. Ein Algorithmus, der auf einer Textbeschreibung einer Szene basiert, verwendet Fragmente vorhandener Bilder, um eindeutige neue zu erstellen. Die resultierenden Bilder weisen zwar viele Artefakte auf und sehen nicht sehr glaubwürdig aus, aber dies könnte in Zukunft neue Möglichkeiten im Bereich der Fotomontage eröffnen.
Fahrgastverfolgung
Dank der Fortschritte in der Bildverarbeitung und beim maschinellen Lernen wird die Verfolgung von Menschen noch effektiver. Eine Gruppe von Forschern aus Shanghai beauftragte einen großen Entwickler mit der Entwicklung eines Systems zur sozialen Kontrolle des Verhaltens in Aufzügen in Echtzeit. Das System kann verdächtige Aktivitäten in Aufzügen erkennen. So hoffen die Macher, Vandalismus, sexuelle Belästigung und Drogenhandel zu verhindern. Das System wird auch feststellen, wenn Personen häufiger auf einer bestimmten Etage anhalten: Beispielsweise war es bereits möglich, Catering zu identifizieren, das illegal in der Wohnung funktioniert. Das System wurde bereits installiert und überwacht Hunderttausende von Aufzügen.
So intensiv war der Juli. Mal sehen, welche Neuigkeiten uns der nächste Monat bringt. Vielen Dank für Ihre Aufmerksamkeit!