Von der Fähigkeit, große Informationsmengen zu verarbeiten und Algorithmen für maschinelles Lernen viel effizienter einzusetzen, bis hin zu Quantenmodellierungsalgorithmen, die die Berechnungen (sowohl qualitativ als auch quantitativ) für das Design neuer Medikamente verbessern können, die Vorhersage der Proteinstruktur, die Analyse verschiedener Prozesse in einem biologischen Organismus und etc. Diese umwerfenden Perspektiven unterliegen heute einem überwältigenden Info-Hype, weshalb es wichtig ist, die Vorbehalte und Herausforderungen dieser neuen Technologie herauszustellen.
Warnung: Die Überprüfung basiert auf einem Artikel einer Gruppe europäischer Forscher aus Großbritannien und der Schweiz (Carlos Outeiral, Martin Strahm, Jiye Shi, Garrett M. Morris, Simon C. Benjamin und Charlotte M. Deane). WIREs Computational Molecular Science, veröffentlicht von Wiley Periodicals LLC, 2020). Die schwierigsten Teile des Artikels, die sich auf ausgefeilte mathematische Modelle beziehen, werden nicht in die Überprüfung einbezogen. Das Material ist jedoch zunächst komplex, und der Leser muss über Kenntnisse in Mathematik und Quantenphysik verfügen.
Wenn Sie jedoch beabsichtigen, die Anwendung von Quantentechnologien in der Bioinformatik zu untersuchen, sollten Sie sich zunächst einen kurzen Vortrag von Viktor Sokolov, Senior Researcher bei M & S Decisions, anhören, in dem einige moderne Probleme der Arzneimittelmodellierung beschrieben werden:
Einführung
Seit dem Aufkommen des Hochleistungsrechnens wurden Algorithmen und mathematische Modelle verwendet, um Probleme in den Biowissenschaften zu lösen - von der Untersuchung der Komplexität des menschlichen Genoms bis zur Modellierung des Verhaltens von Biomolekülen. Berechnungsmethoden werden heute regelmäßig verwendet, um wichtige Informationen aus biologischen Experimenten zu analysieren und zu extrahieren sowie das Verhalten biologischer Objekte und Systeme vorherzusagen. Tatsächlich befassen sich 10 der 25 am häufigsten zitierten wissenschaftlichen Arbeiten mit in der Biologie verwendeten Berechnungsalgorithmen [siehe S. hier ], einschließlich Quantenmodellierung [ hier , hier , hier und hier ], Sequenzausrichtung [ hier , hier und hierhier ], Computergenetik [siehe. hier ] und Röntgenbeugung in der Datenverarbeitung [vgl. hier und hier ].
Trotz dieses Fortschritts bleiben viele Probleme in der Biologie unter dem Gesichtspunkt ihrer Lösung unter Verwendung vorhandener Computertechnologien unlösbar. Die besten Algorithmen für Aufgaben wie die Vorhersage der Proteinfaltung, die Berechnung der Bindungsaffinität eines Liganden an ein Makromolekül oder das Finden der optimalen genomischen Ausrichtung im großen Maßstab erfordern Rechenressourcen, die über die derzeit leistungsstärksten Supercomputer hinausgehen.
Die Lösung für diese Probleme könnte in einem Paradigmenwechsel in der Computertechnologie liegen. In den 1980er Jahren unabhängig Richard Feynman [siehe. hier ] und Yuri Manin [siehe. hier ] schlug vor, quantenmechanische Effekte zu verwenden, um eine neue, leistungsfähigere Generation von Computern zu schaffen.
Die Quantentheorie hat sich als äußerst erfolgreiche Beschreibung der physikalischen Realität erwiesen und seit ihrer Einführung im frühen 20. Jahrhundert zu Fortschritten wie Lasern, Transistoren und Halbleitermikroprozessoren geführt. Der Quantencomputer verwendet die effizientesten Algorithmen und verwendet Operationen, die in klassischen Maschinen nicht möglich sind. Quantenprozessoren laufen nicht schneller als klassische Computer, arbeiten jedoch auf völlig andere Weise, erzielen beispiellose Beschleunigungen und vermeiden unnötige Berechnungen. Beispielsweise wird erwartet, dass die Berechnung der gesamten Elektronenwellenfunktion eines durchschnittlichen Wirkstoffmoleküls auf einem modernen Supercomputer unter Verwendung herkömmlicher Algorithmen länger dauert als das gesamte Alter unseres Universums [siehe Lit. Hier], während selbst ein kleiner Quantencomputer dieses Problem innerhalb weniger Tage lösen kann. Von einem solchen Versprechen des Quantenvorteils ermutigt, setzen Ingenieure und Wissenschaftler ihre Suche nach einem Quantenprozessor fort. Die technischen Schwierigkeiten bei der Herstellung, Verwaltung und dem Schutz von Quantensystemen sind jedoch unglaublich komplex, und die ersten Prototypen sind erst im letzten Jahrzehnt aufgetaucht.
Es ist wichtig anzumerken, dass die technischen Probleme beim Bau von Quantencomputern die Entwicklung von Quantencomputeralgorithmen nicht gestoppt haben. Selbst ohne Hardware können Algorithmen mathematisch analysiert werden, und das Aufkommen von Hochleistungs-Quantencomputersimulatoren sowie frühen Prototypen in den letzten Jahren hat weitere Forschungen ermöglicht.
Einige dieser Algorithmen haben bereits vielversprechende Anwendungsmöglichkeiten in der Biologie gezeigt. Ein Algorithmus zur Schätzung der Quantenphase ermöglicht es beispielsweise, Eigenwerte exponentiell schneller zu berechnen [siehe. hier ], mit dem die Korrelation zwischen Teilen eines Proteins in großem Maßstab verstanden oder die Zentralität eines Graphen in einem biologischen Netzwerk bestimmt werden kann. Der Quanten-Harrow-Hasidim-Lloyd (HHL) -Algorithmus [vgl. hier ] kann einige lineare Systeme exponentiell schneller lösen als jeder bekannte klassische Algorithmus und statistische Lernmethoden mit einem viel schnelleren Anpassungsprozess und der Fähigkeit, große Datenmengen zu verwalten, anwenden.
Quantenoptimierungsalgorithmen haben ein weites Anwendungsgebiet auf dem Gebiet der Proteinfaltung und Auswahl von Konformern sowie bei Problemen im Zusammenhang mit der Suche nach Minima oder Maxima [siehe. hier ]. Schließlich wurde kürzlich eine Technologie entwickelt, um Quantensysteme zu simulieren, die beispielsweise genaue Vorhersagen von Arzneimittel-Rezeptor-Wechselwirkungen liefern [siehe Lit. hier ] oder an der Untersuchung und dem Verständnis komplexer Prozesse und chemischer Mechanismen wie der Photosynthese teilzunehmen [siehe. hier ]. Quantum Computing kann die Methoden der Biologie selbst erheblich verändern, wie es das klassische Computing zu seiner Zeit getan hat.
Jüngste Behauptungen der Quantenüberlegenheit von Google [vgl. Hier], obwohl von IBM bestritten [vgl. hier ] weisen darauf hin, dass die Ära des Quantencomputers nicht mehr weit ist. Die ersten Prozessoren, die Quanteneffekte verwenden, um Berechnungen durchzuführen, die für die klassische Computertechnologie unmöglich sind, werden innerhalb des nächsten Jahrzehnts erwartet [vgl. hier ].
In diesem Aufsatz werden wir die wichtigsten Punkte aufschlüsseln, an denen Quantencomputer für die Computerbiologie vielversprechend sind. Diese Übersichten analysieren die möglichen Auswirkungen von Quantencomputern in einer Vielzahl von Bereichen, einschließlich maschinellem Lernen [vgl. hier , hier und hier ], Quantenchemie [vgl. hier , hier und hier ] und Wirkstoffsynthese [siehe.hier ]. Kürzlich wurde auch der Bericht des NIMH-Workshops zu Quantum Computing in den Biowissenschaften veröffentlicht [siehe S. hier ].
In diesem Aufsatz geben wir zunächst eine kurze Beschreibung der Bedeutung von Quantencomputing und eine kurze Einführung in die Prinzipien der Quanteninformationsverarbeitung. Anschließend diskutieren wir drei Hauptbereiche der Computerbiologie, in denen das Quantencomputing bereits vielversprechende algorithmische Entwicklungen gezeigt hat: statistische Methoden, elektronische Strukturberechnungen und Optimierung. Einige wichtige Themen werden außer Acht gelassen, beispielsweise Zeichenfolgenalgorithmen, die die Sequenzanalyse beeinflussen können [siehe. hier ], medizinische Bildgebungsalgorithmen [siehe. hier ], numerische Algorithmen für Differentialgleichungen [hier ] und andere mathematische Probleme oder Methoden zur Analyse biologischer Netzwerke [ hier ]. Abschließend diskutieren wir die möglichen mittel- und langfristigen Auswirkungen des Quantencomputers auf die Computerbiologie.
1. Quanteninformationsverarbeitung
Quantencomputer versprechen, Probleme in den Biowissenschaften zu lösen, beispielsweise die Vorhersage von Protein-Ligand-Wechselwirkungen oder das Verständnis der Koevolution von Aminosäuren in Proteinen. Und es ist nicht einfach zu lösen, aber exponentiell schneller, als Sie es sich mit einem modernen Computer vorstellen können. Dieser Paradigmenwechsel erfordert jedoch eine grundlegende Änderung unseres Denkens: Quantencomputer unterscheiden sich stark von ihren klassischen Vorgängern. Die physikalischen Phänomene, die dem Quantenvorteil zugrunde liegen, sind oft unlogisch und nicht intuitiv, und die Verwendung eines Quantenprozessors erfordert eine grundlegende Änderung unseres Verständnisses der Programmierung. In diesem Abschnitt stellen wir die Prinzipien der Quanteninformation vor und wie sie zur Durchführung von Berechnungen verarbeitet wird.
Wir erklären, wie Informationen in einem Quantensystem, in dem sie in Qubits gespeichert sind, anders funktionieren und wie diese Informationen mithilfe von Quantentoren manipuliert werden können. Wie Variablen und Funktionen in einer Programmiersprache definieren Qubits und Quantentore die Grundelemente eines jeden Algorithmus. Wir werden auch untersuchen, warum die Erstellung eines Quantencomputers technisch äußerst schwierig ist und was mit Hilfe früher Prototypen erreicht werden kann, die in den kommenden Jahren erwartet werden. Diese Einführung wird nur die Hauptpunkte behandeln; Für eine umfassende Studie lesen Sie das Buch von Nielsen und Chuang [ hier ].
1.1. Elemente von Quantenalgorithmen
1.1.1. Quanteninformation: eine Einführung in das Qubit
Das erste Problem bei der Darstellung von Quantencomputern besteht darin, zu verstehen, wie Informationen verarbeitet werden. In einem Quantenprozessor werden Informationen normalerweise in Qubits gespeichert, die das Quantenanalogon klassischer Bits sind. Ein Qubit ist ein physikalisches System wie ein Ion, das durch ein Magnetfeld begrenzt ist [siehe. hier ] oder ein polarisiertes Photon [siehe. hier ], aber es wird oft abstrakt gesprochen. Wie Schrödingers Katze kann ein Qubit nicht nur die Zustände 0 oder 1 annehmen, sondern auch jede mögliche Kombination beider Zustände. Wenn ein Qubit direkt beobachtet wird, befindet es sich nicht mehr in einer Überlagerung, die in einen der möglichen Zustände zusammenbricht, so wie Schrödingers Katze nach dem Öffnen der Schachtel tot oder lebendig ist [siehe. Hier]. Noch wichtiger ist, wenn mehrere Qubits kombiniert werden, können sie korreliert werden, und Interaktionen mit einem von ihnen haben Konsequenzen für den gesamten kollektiven Zustand. Das als Quantenverschränkung bekannte Phänomen der Korrelation zwischen mehreren Qubits ist eine grundlegende Ressource für das Quantencomputing.
In der klassischen Information ist die grundlegende Informationseinheit ein Bit, ein System mit zwei identifizierbaren Zuständen, die oft mit 0 und 1 bezeichnet werden. Ein Quantenanalogon, ein Qubit, ist ein System mit zwei Zuständen, dessen Zustände mit | 0⟩ und | 1⟩ bezeichnet sind. Wir verwenden die Dirac-Notation, wobei | *⟩ einen Quantenzustand identifiziert. Der Hauptunterschied zwischen klassischer und Quanteninformation besteht darin, dass sich ein Qubit in einer beliebigen Überlagerung der Zustände | 0⟩ und | 1⟩ befinden kann:
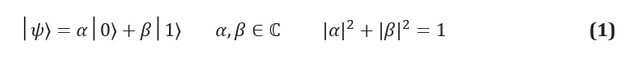
Die komplexen Koeffizienten α und β sind als Amplituden von Zuständen bekannt und stehen in Beziehung zu einem anderen Schlüsselkonzept der Quantenmechanik: dem Effekt der physikalischen Dimension. Da Qubits physische Systeme sind, können Sie jederzeit ein Protokoll zur Messung ihres Zustands erstellen. Wenn zum Beispiel die Zustände | 0⟩ und | 1⟩ den Zuständen des Spins eines Elektrons in einem Magnetfeld entsprechen, misst das Messen des Zustands eines Qubits einfach die Energie des Systems. Die Postulate der Quantenmechanik schreiben vor, dass der Messvorgang den Zustand selbst ändern muss, wenn sich das System in einer Überlagerung möglicher Messergebnisse befindet. Das Überlagerungssystem fällt in der Messphase auseinander; Die Messung zerstört somit die Informationen, die von den Amplituden im Qubit getragen werden.
Wichtige rechnerische Implikationen ergeben sich, wenn wir Systeme mit mehreren Qubits betrachten, die eine Quantenverschränkung erfahren können. Verschränkung ist ein Phänomen, bei dem eine Gruppe von Qubits korreliert ist und jede Operation an einem dieser Qubits den Gesamtzustand aller von ihnen beeinflusst. Ein kanonisches Beispiel für Quantenverschränkung ist das 1935 vorgestellte Einstein-Podolsky-Rosen-Paradoxon [vgl. hier ]. Stellen Sie sich ein System aus zwei Qubits vor, bei dem das zusammengesetzte System eine beliebige Überlagerung von Zuständen {| 00⟩, | 01⟩, | 10⟩, | 11 annehmen kann, da jedes der einzelnen Qubits eine beliebige Überlagerung von Zuständen {| 0⟩ und | 1⟩} annehmen kann ⟩} (Und dementsprechend kann das System der N-Qubits jedes von nehmen binäre Zeichenfolgen von {| 0 ... 0⟩ bis | 1 ... 1⟩}. Eine der möglichen Überlagerungen des Systems sind die sogenannten Bell-Zustände, von denen einer die folgende Form hat: Wenn wir eine Messung am ersten Qubit durchführen, können wir nur | 0⟩ oder | 1⟩ beobachten, von denen jeder eine Wahrscheinlichkeit von 1/2 hat. Dies nimmt keine Änderungen für den Einzel-Qubit-Fall vor. Wenn das Ergebnis für das erste Qubit | 0⟩ war, kollabiert das System zum System | 01⟩, und daher ergibt jede Messung am zweiten Qubit | 1⟩ mit der Wahrscheinlichkeit 1; In ähnlicher Weise würde die Messung am zweiten Qubit | 0⟩ ergeben, wenn die erste Messung | 1⟩ wäre. Eine Operation (in diesem Fall eine Messung mit dem Ergebnis "0"), die auf das erste Qubit angewendet wird, beeinflusst die Ergebnisse, die sichtbar werden, wenn das zweite Qubit anschließend gemessen wird.

Das Vorhandensein einer Verschränkung ist für ein nützliches Quantencomputing von grundlegender Bedeutung. Es wurde nachgewiesen, dass jeder Quantenalgorithmus, der keine Verschränkung verwendet, auf einen klassischen Computer ohne signifikanten Geschwindigkeitsunterschied angewendet werden kann [vgl. hier und hier ]. Grund ist intuitiv die Menge an Informationen, die ein Quantencomputer manipulieren kann. Wenn das N-Qubit-System nicht verwickelt ist, dann Amplituden seines Zustands können durch die Amplituden jedes Ein-Bit-Zustands beschrieben werden, dh 2N Amplituden. Wenn das System jedoch verwickelt ist, sind alle Amplituden unabhängig und das Qubit-Register bildet sich dimensionaler Vektor. Die Fähigkeit von Quantencomputern, große Informationsmengen mit mehreren Operationen zu manipulieren, ist einer der Hauptvorteile von Quantenalgorithmen und untermauert ihre Fähigkeit, Probleme exponentiell schneller als die klassische Computertechnologie zu lösen.
1.1.2. Quantentore
Die in Qubits gespeicherten Informationen werden unter Verwendung spezieller Operationen verarbeitet, die als Quantentore bekannt sind. Quantentore sind physikalische Operationen wie ein auf ein Ionen-Qubit gerichteter Laserpuls oder ein Satz von Spiegeln und Strahlteilern, durch die sich ein Photonen-Qubit bewegen muss. Tore werden jedoch oft als abstrakte Operationen angesehen. Die Postulate der Quantenmechanik stellen einige strenge Bedingungen an die Natur von Quantengattern in geschlossenen Systemen, die es ermöglichen, sie in Form von einheitlichen Matrizen darzustellen, bei denen es sich um lineare Operationen handelt, die die Normalisierung des Quantensystems bewahren.
Insbesondere ist ein Quantengatter, das an ein verschränktes Register von N Qubits angelegt wird, äquivalent zum Multiplizieren der Matrix × pro Eingabevektor . Die Fähigkeit eines Quantencomputers, große Informationsmengen zu speichern und zu berechnen, liegt in der Größenordnung von - durch Manipulieren mehrerer Elemente - der Ordnung N - bildet die Grundlage für seine Fähigkeit, einen potenziell exponentiellen Vorteil gegenüber klassischen Computern bereitzustellen. Quantengatter sind im Wesentlichen jede zulässige Operation in einem Qubitsystem. Die Postulate der Quantenmechanik legen der Form von Quantentoren zwei strenge Beschränkungen auf. Quantenoperatoren sind linear. Die Linearität ist eine mathematische Bedingung, die dennoch tiefgreifende Auswirkungen auf die Physik von Quantensystemen hat und daher darauf, wie sie für die Berechnung verwendet werden können. Wenn der lineare Operator auf die Überlagerung von Zuständen angewendet wird
, ist das Ergebnis eine Überlagerung der einzelnen Staaten, die vom Bediener beeinflusst werden. In einem Qubit bedeutet dies: Lineare Operatoren können in Form von Matrizen dargestellt werden, bei denen es sich lediglich um Tabellen handelt, die die Auswirkung eines linearen Operators auf jeden Basiszustand angeben. Fig. 1 (c, d) zeigt eine Matrixdarstellung eines von zwei Qubit- und zwei Ein-Bit-Gattern. Nicht jede Matrix repräsentiert jedoch echte Quantengatter. Wir erwarten, dass Quantentore, die auf eine Sammlung von Qubits angewendet werden, eine andere reale Menge von Qubits ergeben, insbesondere eine normalisierte (zum Beispiel in Gleichung (3) erwarten wir dies
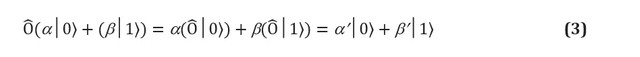
× ist ein vollständig gültiges N-Qubit-Quantengatter.
Bei der klassischen Berechnung gibt es nur ein nicht triviales Gatter für ein Bit: das NICHT-Gatter, das 0 in 1 konvertiert und umgekehrt. Beim Quantencomputing gibt es unendlich viele 2 × 2-Einheitsmatrizen, und jede von ihnen ist ein mögliches Ein-Qubit-Quantengatter. Einer der ersten Erfolge des Quantencomputers war die Entdeckung, dass diese Vielzahl von Möglichkeiten mit einer Reihe von universellen Gates realisiert werden kann, die ein und zwei Qubits beeinflussen [siehe Lit. Hier]. Mit anderen Worten, bei beliebigen Quantengattern gibt es eine Ein- und Zwei-Qubit-Gatterschaltung, die sie mit beliebiger Genauigkeit ansteuern kann. Dies bedeutet leider nicht, dass die Approximation effektiv ist. Die meisten Quantentore können nur durch eine exponentielle Anzahl von Gattern aus unserer universellen Menge angenähert werden. Selbst wenn diese Gatter zur Lösung nützlicher Probleme verwendet werden können, nimmt ihre Implementierung exponentiell viel Zeit in Anspruch und kann jeden Quantenvorteil zunichte machen. Fig. 1 (a) Vergleich eines klassischen Bits mit einem Quantenbit oder "Qubit". Während ein klassisches Bit nur einen von zwei Zuständen annehmen kann, 0 oder 1, kann ein Quantenbit einen beliebigen Zustand der Form annehmen

... Einzelne Qubits werden häufig unter Verwendung der Bloch-Kugeldarstellung dargestellt, wobei θ und ϕ als Azimut- und Polarwinkel in einer Kugel mit Einheitsradius verstanden werden. (b) Eine schematische Darstellung eines Ionenfallen-Qubits, einer der häufigsten Ansätze für experimentelles Quantencomputing. Ion (oft) wird durch elektromagnetische Felder im Hochvakuum gehalten und einem starken Magnetfeld ausgesetzt. Die Hyperfeinstufen werden gemäß dem Zeeman-Effekt getrennt, und die beiden ausgewählten Stufen werden als Zustände | 0⟩ und | 1⟩ ausgewählt. Quantentore werden durch geeignete Laserpulse implementiert, an denen häufig andere elektronische Ebenen beteiligt sind. Dieses Diagramm wurde aus [siehe. hier ]. (c) Diagramm einer Quantenschaltung, die X oder das Quantum of Controlled Negation (CNOT) implementiert.
Die Darstellung und Veränderung in der Bloch-Kugel wird gezeigt. (d) Quantenschaltung zur Erzeugung des Bell-Zustandsunter Verwendung eines Hadamard-Gates und eines CNOT-Gates (Controlled Negation). Die gepunktete Linie in der Mitte des Umrisses zeigt den Zustand nach dem Anlegen des Hadamard-Ventils an.
1.2. Quantenhardware
Quantenalgorithmen können interessante Probleme nur lösen, wenn sie auf der richtigen Quantenhardware ausgeführt werden. Es gibt viele konkurrierende Vorschläge für die Schaffung eines Quantenprozessors auf der Basis eingefangener Ionen [siehe. hier ] supraleitende Schaltungen [siehe. hier ] und photonische Geräte [siehe. Hier]. Sie alle haben jedoch ein gemeinsames Problem: Rechenfehler, die den Rechenprozess buchstäblich ruinieren können. Einer der Eckpfeiler des Quantencomputers ist die Entdeckung, dass diese Fehler mit Quantenfehlerkorrekturcodes beseitigt werden können. Leider erfordern diese Codes auch eine sehr starke Erhöhung der Anzahl der Qubits, so dass erhebliche technische Verbesserungen erforderlich sind, um eine Fehlertoleranz zu erreichen.
Es gibt viele Fehlerquellen, die einen Quantenprozessor betreffen können. Zum Beispiel kann die Verbindung eines Qubits mit seiner Umgebung zum Zusammenbruch des Systems in einen seiner klassischen Zustände führen - ein Prozess, der als Dekohärenz bekannt ist.... Kleine Schwankungen können Quantentore transformieren, was letztendlich zu anderen Ergebnissen als erwartet führt. Die bislang am wenigsten fehleranfälligen Gates wurden in einem Prozessor für eingeschlossene Ionen mit einer Häufigkeit von einem Fehler pro aufgezeichnetEin-Qubit-Gatter und mit einer Fehlerrate von 0,1% für Zwei-Qubit-Gatter [ hier und hier ]. Zum Vergleich: Eine kürzlich von Google durchgeführte Arbeit ergab eine Wiedergabetreue von 0,1% für Single-Qubit-Gates und 0,3% für Two-Qubit-Gates in einem supraleitenden Prozessor [siehe Lit. hier ]. Angesichts der Tatsache, dass der Ausfall eines Gateways die Berechnung ruinieren kann, ist leicht zu erkennen, dass die Ausbreitung von Fehlern die Berechnung nach einer kleinen Folge von Elementen bedeutungslos machen kann.
Eine der Hauptrichtungen des Quantencomputers ist die Entwicklung von Quantenfehlerkorrekturcodes. In den 1990er Jahren haben mehrere Forschungsgruppen bewiesen, dass diese Codes fehlertolerante Berechnungen erzielen können, vorausgesetzt, die Gate-Fehlerraten liegen unter einem bestimmten Schwellenwert, der vom Code abhängt [siehe. hier , hier , hier und hier ]. Einer der beliebtesten Ansätze, der Oberflächencode, kann mit Fehlerraten nahe 1% arbeiten [siehe Lit. hier ].
Leider erfordern Quantenfehlerkorrekturcodes eine große Anzahl realer physikalischer Qubits, um das abstrakte logische Qubit zu codieren, das für die Berechnung verwendet wird, und dieser Overhead steigt mit der Fehlerrate. Zum Beispiel ein Quantenalgorithmus zur Faktorisierung von Primzahlen [siehe. hier ] könnte eine 2000-Bit-Zahl mit etwa 4000 Qubits leise zerlegen, und bei 16 GHz würde dieser Vorgang etwa einen Arbeitstag dauern. Unter der Annahme einer Fehlerrate von 0,1% würde derselbe Algorithmus, der den Oberflächencode verwendet, um die Fehler der Umgebung zu korrigieren, mehrere Millionen Qubits und dieselbe Zeit in Anspruch nehmen [siehe. Hier]. In Anbetracht dessen, dass der aktuelle Datensatz für einen gesteuerten, programmierbaren Quantenprozessor 53 Qubits beträgt [siehe. hier ] ist es noch ein langer Weg in diese Forschungsrichtung.
Viele Gruppen haben sich bemüht, Algorithmen zu entwickeln, die auf sogenannten mittelgroßen Rauschquantenprozessoren ausgeführt werden können [vgl. hier ]. Beispielsweise kombinieren Variationsalgorithmen einen klassischen Computer mit einem kleinen Quantenprozessor und führen eine große Menge kurzer Quantenberechnungen durch, die durchgeführt werden können, bevor das Rauschen signifikant wird.
Diese Algorithmen verwenden häufig eine parametrisierte Quantenschaltung, die eine besonders schwierige Aufgabe erfüllt, und verwenden einen klassischen Computer, um die Parameter zu optimieren. Das Auflösungsverfahren ist ein Fehlerreduzierungsbereich, in dem anstelle des Erreichens einer Fehlertoleranz versucht wurde, Fehler mit minimalem Aufwand zu minimieren, um größere Gate-Schaltungen anzusteuern. Es gibt eine Reihe von Ansätzen, die die Verwendung zusätzlicher Operationen zum Verwerfen von Läufen mit Fehlern umfassen [siehe. hier ] oder Manipulation der Fehlerrate zur Extrapolation auf das richtige Ergebnis [vgl. hier und hier]. Obwohl die Hauptanwendungen sehr große fehlertolerante Quantencomputer erfordern werden; Geräte, die im nächsten Jahrzehnt verfügbar sein werden, werden diese Probleme voraussichtlich lösen [siehe hier ].
2. Statistische Methoden und maschinelles Lernen
In der Computerbiologie, in der häufig große Datenmengen gesammelt werden sollen, sind statistische Methoden und maschinelles Lernen Schlüsseltechniken. In der Genomik werden beispielsweise häufig Hidden-Markov-Modelle (HMM) verwendet, um Informationen über Gene zu kommentieren [siehe. hier ]; Während der Wirkstoffentdeckung wurde eine breite Palette statistischer Modelle entwickelt, um die molekularen Eigenschaften zu bewerten oder die Ligand-Protein-Bindung vorherzusagen [siehe. hier ]; und in der Strukturbiologie wurden tiefe neuronale Netze verwendet, um Proteinverbindungen vorherzusagen [siehe. hier ] und Sekundärstruktur [siehe. hier ] und in jüngerer Zeit auch dreidimensionale Proteinstrukturen [siehe. hier ].
Das Training und die Entwicklung solcher Modelle ist häufig rechenintensiv. Ein Hauptkatalysator für die jüngsten Fortschritte beim maschinellen Lernen war die Erkenntnis, dass Allzweck-Grafikprozessoren (GPUs) das Lernen erheblich beschleunigen können. Durch die Bereitstellung exponentiell schnellerer Algorithmen für maschinelles Lernen können Quantencomputermodelle ein ähnliches Interesse am Anwendungsfokus für wissenschaftliche Probleme wecken.
In diesem Abschnitt werden wir erklären, wie Quantencomputer zahlreiche statistische Lernmethoden beschleunigen können.
2.1. Vor- und Nachteile des Quantenmaschinellen Lernens
Wir betrachten zunächst die Vorteile, die ein Quantencomputer für maschinelles Lernen bietet. Mit Ausnahme idealisierter Beispiele können Quantencomputer nicht mehr Informationen lernen als ein klassischer Computer [vgl. hier ]. Im Prinzip können sie jedoch viel schneller sein und viel mehr Daten verarbeiten als ihre klassischen Gegenstücke. Zum Beispiel enthält das menschliche Genom 3 Milliarden Basenpaare, die in 1,2 × gespeichert werden könnenklassische Bits - ungefähr 1,5 Gigabyte. Ein Register von N Qubits enthältAmplituden, von denen jede ein klassisches Bit darstellen kann, indem die k-te Amplitude mit einem geeigneten Normalisierungsfaktor auf 0 oder 1 gesetzt wird. Daher kann das menschliche Genom in ~ 34 Qubits gespeichert werden. Während diese Informationen nicht aus einem Quantencomputer extrahiert werden können, können bestimmte Algorithmen für maschinelles Lernen darauf ausgeführt werden, bis ein bestimmter Zustand vorbereitet ist. Noch wichtiger ist, dass durch die Verdoppelung der Registergröße auf 68 Qubits genügend Platz bleibt, um das gesamte Genom jeder lebenden Person auf der Welt zu speichern. Die Darstellung und Analyse derart großer Datenmengen würde durchaus mit den Fähigkeiten eines kleinen fehlertoleranten Quantencomputers übereinstimmen.
Operationen zur Verarbeitung dieser Informationen können auch exponentiell schneller sein. Beispielsweise sind mehrere Algorithmen für maschinelles Lernen auf die langfristige Inversion der Kovarianzmatrix mit einer Strafe beschränktauf die Dimensionen der Matrix. Der von Harrow, Hassidim und Lloyd vorgeschlagene Algorithmus [vgl. hier ] können Sie die Matrix invertierenunter bestimmten Bedingungen. Die wichtigste Erkenntnis ist, dass Quantenalgorithmen im Gegensatz zu GPUs, die Berechnungen durch massive Parallelität beschleunigen, den Vorteil der Komplexität der direkt verwendeten Berechnungsalgorithmen haben. In einigen Fällen, insbesondere bei der aktuellen exponentiellen Beschleunigung, können mittelgroße Quantencomputer Lernprobleme lösen, die nur für die größten heute verfügbaren klassischen Supercomputer verfügbar sind.
Eine verbesserte Speicherung und Verarbeitung von Daten hat sekundäre Vorteile. Eine der Stärken neuronaler Netze ist ihre Fähigkeit, präzise Darstellungen von Daten zu finden [siehe. Hier]. Da Quanteninformationen allgemeiner sind als klassische Informationen (schließlich sind die Zustände eines klassischen Bits in Eigenzustände | 0⟩ und | 1⟩ oder ein Qubit unterteilt), ist es möglich, dass quantenmaschinelle Lernmodelle Informationen besser assimilieren können als klassische Modelle ... Andererseits verbessern Quantenalgorithmen mit logarithmischer Zeitkomplexität auch die Vertraulichkeit von Daten [siehe. hier ]. Seit dem Training benötigt das Modell, und erfordert eine Matrixrekonstruktion, für einen ausreichend großen Datensatz ist es unmöglich, einen signifikanten Teil der Informationen wiederherzustellen, obwohl ein effektives Training des Modells immer noch möglich ist. Im Rahmen der biomedizinischen Forschung kann dies den Datenaustausch erleichtern und gleichzeitig die Vertraulichkeit gewährleisten.
Obwohl quantenmaschinelle Lernalgorithmen auf Papier die klassischen Gegenstücke bei weitem übertreffen können, bleiben leider immer noch praktische Schwierigkeiten bestehen. Quantenalgorithmen sind oft Unterprogramme, die Eingaben in Ausgaben umwandeln. Genau in diesen beiden Phasen treten Probleme auf: wie man angemessene Eingaben vorbereitet und wie man Informationen aus Ausgaben extrahiert [siehe. hier ]. Nehmen wir zum Beispiel an, wir verwenden den HHL-Algorithmus [siehe. hier ], um ein lineares System der Form zu lösen... Am Ende des Unterprogramms gibt der Algorithmus das Qubit-Register im folgenden Zustand aus: Hier
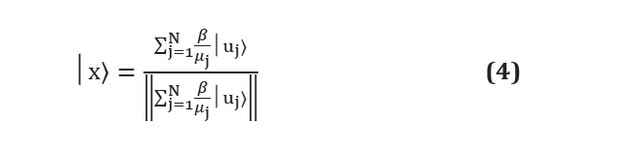
und Sind die Eigenvektoren und Eigenwerte von A und - j-ter Koeffizient wird in Form der Eigenvektoren von A ausgedrückt, und der Nenner ist einfach eine Normalisierungskonstante. Es ist ersichtlich, dass dies den Koeffizienten entspricht, die in den Amplituden verschiedener Zustände als gespeichert sind und sind nicht direkt zugänglich. Die Messung des Qubit-Registers führt dazu, dass es in einen der Zustände des Eigenvektors kollabiert und die Amplituden jedes einzelnen neu geschätzt werden Messungen erforderlich , was in erster Linie jeden Vorteil des Quantenalgorithmus überwiegt.
HHL und viele andere Algorithmen sind nur nützlich, um die globale Eigenschaft einer Lösung zu berechnen, z. B. den erwarteten Wert. Mit anderen Worten, HHL kann keine Lösung für ein Gleichungssystem bereitstellen oder eine Matrix in logarithmischer Zeit invertieren, es sei denn, wir interessieren uns nur für die globalen Eigenschaften der Lösung, die mit mehreren physikalisch beobachtbaren Messungen erhalten werden können. Dies schränkt die Verwendung einiger Unterprogramme ein, aber es gab viele Vorschläge, um dieses Problem zu umgehen.
Die Eingabe von Informationen in einen Quantencomputer ist ein viel größeres Problem. Die meisten Algorithmen für maschinelles Quantenlernen gehen davon aus, dass der Quantencomputer in Form eines Überlagerungszustands Zugriff auf den Datensatz hat. Zum Beispiel gibt es ein Register von Qubits, das sich in einem Zustand der Form befindet: Hier ist - | bin (j) ein Zustand, der als Index fungiert, und

Ist die entsprechende Amplitude. Dies kann zum Beispiel verwendet werden, um die Elemente eines Vektors oder einer Matrix zu speichern. Im Prinzip gibt es eine Quantenschaltung, die diesen Zustand vorbereiten kann, indem sie beispielsweise im Zustand | 0 ... 0⟩ wirkt. Ihre Implementierung kann jedoch sehr schwierig sein, da wir erwarten, dass die Approximation eines zufälligen Quantenzustands exponentiell schwierig ist und jeden möglichen Quantenvorteil zerstört.
Die meisten Quantenalgorithmen setzen den Zugriff auf den Quanten-Direktzugriffsspeicher (QRAM) voraus [siehe. hier ], ein Black-Box-Gerät, das diese Überlagerung konstruieren kann. Obwohl einige Zeichnungen vorgeschlagen wurden [siehe. hier und hier], soweit wir wissen, gibt es noch kein funktionierendes Gerät. Selbst wenn ein solches Gerät verfügbar wäre, gibt es keine Garantie dafür, dass keine Engpässe entstehen, die die Vorteile des Quantenalgorithmus überwiegen. Zum Beispiel ein kürzlich veröffentlichter schemabasierter Vorschlag für QRAM [vgl. hier ] zeigt die unvermeidbaren linearen Kosten der Anzahl von Zuständen, die jeden Log-Time-Algorithmus überwiegen. Selbst wenn QRAM keine zusätzlichen Kosten verursacht, muss die klassische Vorverarbeitung noch durchgeführt werden - für das Genombeispiel wäre der Zugriff auf 12 Exabyte klassischen Speicher erforderlich.
Abschließend müssen wir betonen, dass Algorithmen für quantenmaschinelles Lernen nicht frei von einem der häufigsten Probleme in der Praxis sind: dem Fehlen relevanter Daten. Die Verfügbarkeit großer Datenmengen ist entscheidend für den Erfolg vieler praktischer Anwendungen von KI in der Molekularwissenschaft, wie beispielsweise der De-novo-Molekularentwicklung [siehe Lit. hier ]. Die Leistungsfähigkeit von Quantenalgorithmen kann jedoch als wissenschaftliche und technologische Entwicklung wie die Entstehung selbstverwalteter Labors nützlich sein [siehe Lit. hier ] liefern immer mehr Daten.
Quantenmaschinelles Lernen hat das Potenzial, die Art und Weise, wie wir biologische Daten verarbeiten und analysieren, zu verändern. Die aktuellen praktischen Herausforderungen bei der Implementierung von Quantentechnologien sind jedoch nach wie vor erheblich.
2.2. Quantenmechanische Algorithmen für maschinelles Lernen
2.2.1. Lernen ohne Lehrer
Unüberwachtes Lernen umfasst verschiedene Techniken zum Extrahieren von Informationen aus nicht getaggten Datensätzen. In der Biologie, wo die Sequenzierung der nächsten Generation und eine gute internationale Zusammenarbeit die Datenerfassung stimuliert haben, haben diese Methoden weit verbreitete Verwendung gefunden, um beispielsweise Verbindungen zwischen Familien von Biomolekülen zu identifizieren [siehe. hier ] oder annotierte Genome [siehe. hier ].
Einer der beliebtesten unbeaufsichtigten Lernalgorithmen ist die Hauptkomponentenanalyse (PCA), mit der versucht wird, die Dimensionalität von Daten zu verringern, indem lineare Kombinationen von Merkmalen gefunden werden, die die Varianz maximieren [vgl. Hier]. Diese Methode wird häufig in allen Arten von hochdimensionalen Datensätzen verwendet, einschließlich RNA-Microarray- und Massenspektrometriedaten [siehe. hier ]. Ein Quantenalgorithmus für PCA wurde von einer Gruppe von Forschern vorgeschlagen [siehe. hier ]. Grundsätzlich baut dieser Algorithmus eine Datenkovarianzmatrix in einem Quantencomputer auf und verwendet eine als Quantenphasenschätzung bekannte Unterroutine, um die Eigenvektoren in logarithmischer Zeit zu berechnen. Die Ausgabedaten des Algorithmus sind ein Überlagerungszustand der Form: Hier

Ist die j-te Hauptkomponente und - der entsprechende Eigenwert. Da die PCA an großen Eigenwerten interessiert ist, die die Hauptkomponenten der Varianz sind, ergibt die Endzustandsmessung mit hoher Wahrscheinlichkeit eine geeignete Hauptkomponente. Wenn Sie den Algorithmus mehrmals wiederholen, erhalten Sie eine Reihe von Kernkomponenten. Dieses Verfahren ist in der Lage, die Dimension der riesigen Informationsmenge zu reduzieren, die in einem Quantencomputer gespeichert werden kann.
Ein Quantenalgorithmus wurde auch für ein spezifisches Verfahren zur Analyse topologischer Daten vorgeschlagen, nämlich für eine stabile Homologie [siehe. hier ]. Die topologische Datenanalyse versucht, Informationen mithilfe topologischer Eigenschaften in der Geometrie von Datensätzen zu extrahieren. es wurde zum Beispiel bei der Untersuchung der Datenaggregation verwendet [siehe.hier ] und Netzwerkanalyse [siehe. hier ]. Leider haben die besten klassischen Algorithmen eine exponentielle Abhängigkeit von der Dimension des Problems, was seine Anwendung einschränkt. Algorithmus Lloyd et al. verwendet auch eine Quantenphasenschätzungsroutine, um die Matrixdiagonalisierung exponentiell zu beschleunigen und Komplexität zu erreichen... Das Vorhandensein eines effizienten Algorithmus zur Durchführung topologischer Analysen kann seine Anwendung für die Analyse von Problemen in den Biowissenschaften stimulieren.
2.2.2. Überwachtes Lernen
Überwachtes Lernen bezieht sich auf eine Reihe von Methoden, mit denen Vorhersagen auf der Grundlage gekennzeichneter Daten getroffen werden können. Ziel ist es, ein Modell zu erstellen, mit dem die Eigenschaften unsichtbarer Beispiele klassifiziert oder vorhergesagt werden können. Überwachtes Lernen wird in der Biologie häufig eingesetzt, um so unterschiedliche Probleme wie die Vorhersage der Bindungsaffinität eines Liganden für ein Protein zu lösen [siehe. hier ] und Diagnose von Krankheiten mit einem Computer [siehe. hier ]. Schauen wir uns drei überwachte Lernansätze an.
Support Vector Machine(English Support Vector Machine - SVM) ist ein Algorithmus für maschinelles Lernen, der die optimale Hyperebene findet, die Datenklassen trennt. SVM ist in der pharmazeutischen Industrie weit verbreitet, um niedermolekulare Daten zu klassifizieren [vgl. hier ]. Je nach Kernel dauert das SVM-Training normalerweise von Vor ... Rebentrost [siehe. hier ] präsentierte einen Quantenalgorithmus, der eine SVM mit einem Polynomkern in trainieren kannund später wurde es auf den Kern der radialen Basisfunktion (RBF) erweitert [siehe. hier ]. Leider ist nicht klar, wie die in SVM weit verbreiteten nichtlinearen Operationen implementiert werden sollen, da Quantenoperationen auf linear beschränkt sind. Andererseits erlaubt ein Quantencomputer andere Arten von Kernen, die in einem klassischen Computer nicht realisiert werden können [siehe. hier ].
Die Gaußsche Prozessregression (GP) ist eine Technik, die häufig zum Erstellen von Ersatzmodellen verwendet wird, beispielsweise bei der Bayes'schen Optimierung [siehe. hier ]. Allgemeinmediziner werden auch häufig verwendet, um quantitative Struktur-Aktivitäts-Beziehungsmodelle (QSAR) für Arzneimitteleigenschaften zu erstellen.hier ] und kürzlich auch zur Modellierung der Molekulardynamik [siehe. hier ]. Einer der Nachteile der GP-Regression ist der hohe WertInversion der Kovarianzmatrix. Zhao und Kollegen [siehe. hier ] schlug vor, den HHL-Algorithmus für lineare Systeme zu verwenden, um diese Matrix zu invertieren und eine exponentielle Beschleunigung zu erreichen (solange die Matrix dünn und gut konditioniert ist) - eine Eigenschaft, die häufig durch Kovarianzmatrizen erreicht wird. Noch wichtiger ist, dass dieser Algorithmus erweitert wurde, um den Logarithmus der Grenzwahrscheinlichkeit zu berechnen [vgl. hier ], was ein wichtiger Schritt für die Optimierung von Hyperparametern ist.
Eine der häufigsten Methoden in der Computerbiologie ist das Hidden-Markov-Modell (HMM), das häufig bei der Annotation von Computergenen und der Sequenzausrichtung verwendet wird [vgl. Hier]. Diese Methode enthält eine Reihe von versteckten Zuständen, von denen jeder einer Markov-Kette zugeordnet ist. Übergänge zwischen verborgenen Zuständen führen zu Änderungen in der zugrunde liegenden Verteilung. Grundsätzlich kann HMM nicht direkt in einem Quantencomputer implementiert werden: Die Abtastung erfordert eine Messung, die das System stört. Es gibt jedoch eine Formulierung in Bezug auf offene Quantensysteme, dh ein Quantensystem, das mit der Umgebung in Kontakt steht und ein Markov-System ermöglicht [siehe. hier ]. Während für den klassischen Baum-Welch-Algorithmus zum Trainieren von HMMs keine Verbesserungen vorgeschlagen wurden, haben sich Quanten-HMMs als aussagekräftiger erwiesen: Sie können eine Verteilung mit weniger versteckten Zuständen reproduzieren [vgl. Hier]. Dies könnte zu einer breiteren Anwendung der Methode in der Computerbiologie führen.
2.2.3. Neuronale Netze und tiefes Lernen
Jüngste Entwicklungen beim maschinellen Lernen wurden durch die Entdeckung angeregt, dass mehrere Schichten künstlicher neuronaler Netze komplexe Strukturen in Rohdaten erkennen können [siehe S. hier ]. Deep Learning hat begonnen, jede wissenschaftliche Disziplin zu durchdringen, und in der Computerbiologie gehören zu seinen Fortschritten die genaue Vorhersage von Proteinbindungen. hier ], verbesserte Diagnose einiger Krankheiten [siehe. hier ], molekulares Design [vgl. hier ] und Modellierung [siehe. hier und hier ].
Angesichts der bedeutenden Fortschritte bei der Untersuchung neuronaler Netze wurden erhebliche Anstrengungen unternommen, um Quantenanaloga zu entwickeln, die zu weiteren technologischen Verbesserungen führen können.
Der Name künstliches neuronales Netzwerk bezieht sich häufig auf das mehrschichtige Perzeptron eines neuronalen Netzwerks, bei dem jedes Neuron eine gewichtete lineare Kombination seiner Eingaben verwendet und das Ergebnis über eine nichtlineare Aktivierungsfunktion zurückgibt. Die größte Herausforderung bei der Entwicklung eines Quantenanalogons besteht darin, eine nichtlineare Aktivierungsfunktion unter Verwendung linearer Quantentore zu implementieren. In letzter Zeit gab es viele Vorschläge, und einige Ideen beinhalten Messungen [vgl. hier , hier und hier ], dissipative Quantentore [ hier], Quantencomputer mit einer kontinuierlichen Variablen [ hier ] und die Einführung zusätzlicher Qubits zur Konstruktion linearer Gatter, die Nichtlinearität simulieren [siehe. hier ]. Diese Ansätze zielen darauf ab, ein quantenneurales Netzwerk zu implementieren, von dem aufgrund der größeren Leistung der Quanteninformation erwartet wird, dass es aussagekräftiger ist als ein klassisches neuronales Netzwerk. Die Vor- oder Nachteile der Skalierung des Trainings eines mehrschichtigen Perzeptrons in einem Quantencomputer sind unklar, obwohl der Schwerpunkt auf der möglichen verbesserten Ausdruckskraft dieser Modelle liegt.
Ein großer Teil der jüngsten Bemühungen konzentrierte sich auf Boltzmann-Maschinen, wiederkehrende neuronale Netze, die als generative Modelle fungieren können. Nach dem Training können sie neue Muster erzeugen, die dem Trainingssatz ähneln.
Generative Modelle haben wichtige Anwendungen, beispielsweise im molekularen Design de novo [vgl. hier und hier ]. Obwohl Boltzmann-Maschinen sehr leistungsfähig sind, ist es notwendig, das komplexe Problem der Probenahme aus der Boltzmann-Verteilung zu lösen, um Gradienten zu berechnen und Schulungen durchzuführen, was ihre praktische Anwendung einschränkt. Mit der D-Wave-Maschine wurden Quantenalgorithmen vorgeschlagen [siehe. hier , hier und hier ] oder ein Schaltungsalgorithmus [siehe.hier ]; Dieses Beispiel aus der Boltzmann-Verteilung ist quadratisch schneller als in der klassischen Version möglich [siehe. hier ].
Kürzlich wurde eine Heuristik für ein effizientes Training von Quanten-Boltzmann-Maschinen vorgeschlagen, die auf der Thermalisierung des Systems basiert [siehe. hier ]. Darüber hinaus wurden in einigen Veröffentlichungen Quantenimplementierungen generativer kontradiktorischer Netzwerke (GANs) vorgeschlagen [siehe. hier , hier und hier ]. Diese Entwicklungen beinhalten die Verbesserung generativer Modelle im Zuge der Entwicklung von Quantencomputerhardware.
3. Effektive Simulation von Quantensystemen
Nach den Modellen wird die Chemie durch Elektronentransfer reguliert. Chemische Reaktionen sowie Wechselwirkungen zwischen chemischen Einheiten werden auch durch die Verteilung der Elektronen und die von ihnen gebildete freie Energielandschaft gesteuert. Probleme wie die Vorhersage der Ligandenbindung an ein Protein oder das Verständnis des katalytischen Weges eines Enzyms beschränken sich auf das Verständnis der elektronischen Umgebung. Leider ist die Modellierung dieser Prozesse äußerst schwierig. Der effizienteste Algorithmus zur Berechnung der Energie eines Elektronensystems ist die vollständige Konfigurationswechselwirkung (FCI), die mit zunehmender Anzahl von Elektronen exponentiell skaliert, und selbst Moleküle mit mehreren Kohlenstoffatomen stehen für die Computerforschung kaum zur Verfügung [siehe. Hier]. Obwohl es viele ungefähre Methoden gibt, die in Veröffentlichungen zur Dichtefunktionaltheorie ausführlich und ausführlich beschrieben sind [siehe. hier und hier ] können sie ungenau sein und in vielen interessierenden Situationen sogar abrupt versagen, beispielsweise bei der Simulation eines Einschwingzustands [vgl. hier ]. Ein genauer und effizienter Algorithmus zur Untersuchung der elektronischen Struktur würde ein besseres Verständnis der biologischen Prozesse ermöglichen und auch Möglichkeiten für die Entwicklung biologischer Interaktionen der nächsten Generation eröffnen.
Quantencomputer wurden ursprünglich als Methode zur effizienteren Modellierung von Quantensystemen vorgeschlagen. 1996 zeigte Seth Lloyd, dass dies für bestimmte Arten von Quantensystemen möglich ist [ hier] und ein Jahrzehnt später zeigten Alan Aspuru-Guzik und Kollegen, dass chemische Systeme ein solcher Fall sind [ hier ]. In den letzten zwei Jahrzehnten wurden umfangreiche Forschungsarbeiten zur Feinabstimmung von Modellierungsmethoden für chemische Systeme durchgeführt, mit denen Eigenschaften von Forschungsinteresse berechnet werden können.
3.1. Vor- und Nachteile der Quantensimulation
Im Prinzip kann ein Quantencomputer ein vollständig korreliertes elektronisches Strukturproblem (FCI-Gleichungen) effizient lösen. Dies ist der erste Schritt, um Bindungsenergien genau abzuschätzen und die Dynamik chemischer Systeme zu simulieren. Die klassische Computerchemie konzentrierte sich fast ausschließlich auf Näherungsmethoden, die beispielsweise zur Abschätzung der thermochemischen Mengen kleiner Moleküle nützlich waren [ hier], aber dies reicht möglicherweise nicht für Prozesse aus, die mit dem Aufbrechen oder Bilden von Bindungen verbunden sind. Im Gegensatz dazu können Quantenprozessoren möglicherweise ein elektronisches Problem lösen, indem sie die FCI-Matrix direkt diagonalisieren, ein genaues Ergebnis innerhalb eines bestimmten Basissatzes liefern und so viele der Probleme lösen, die sich aus falschen Beschreibungen der Physik molekularer Prozesse ergeben (z. B. Polarisation von Liganden). ... Darüber hinaus erfordern sie im Gegensatz zu klassischen Ansätzen nicht unbedingt einen iterativen Prozess, obwohl die anfängliche Annahme immer noch wichtig ist.
Obwohl Quantencomputer nicht gut verstanden werden, überwinden sie auch die begrenzenden Näherungen, die bei der klassischen Berechnung benötigt wurden. Beispielsweise berücksichtigt die Formulierung der Quantensimulation im realen Raum automatisch die Kernwellenfunktion ohne die Born-Oppenheimer-Näherung [ hier ]. Dies ermöglicht es, die nicht-adiabatischen Wirkungen einiger Systeme zu untersuchen, von denen bekannt ist, dass sie für die DNA-Mutation wichtig sind [siehe. hier ] und der Wirkungsmechanismus vieler Enzyme [ hier ]. Anwendungen des Quantencomputers für die relativistische Systemmodellierung wurden ebenfalls vorgeschlagen [siehe. hier ], die nützlich sind, um Übergangsmetalle zu untersuchen, die in den aktiven Zentren vieler Enzyme auftreten.
In einem Artikel von Reicher und Kollegen [siehe hier ] wird das Konzept der Zeitskala zur Berechnung elektronischer Strukturen in einem Quantencomputer vorgestellt. Die Autoren betrachteten den Cofaktor FeMo des Stickstoffaseenzyms, dessen Mechanismus der Stickstofffixierung noch nicht untersucht wurde und zu komplex ist, um mit modernen Berechnungsansätzen untersucht zu werden. Die minimale Basis-FCI-Berechnung für FeMoCo wird mehrere Monate dauern und etwa 200 Millionen Qubits der höchsten heute verfügbaren Klasse. Diese Schätzungen müssen sich jedoch mit der raschen Entwicklung der Technologie ändern. In den drei Jahren seit der Veröffentlichung haben algorithmische Fortschritte den Zeitbedarf bereits um mehrere Größenordnungen reduziert [siehe. Hier]. Neben den leistungsfähigeren Methoden der elektronischen Struktur wurden kürzlich schnelle Versionen moderner Näherungsmethoden untersucht [vgl. hier und hier ] kann das Prototyping erheblich beschleunigen, was beispielsweise bei der Untersuchung der Reaktionskoordinaten enzymatischer Reaktionen nützlich sein könnte, deren Bereich ein Problem für die rechnerische Enzymologie darstellt [ hier ]. Darüber hinaus kann die Quantenmodellierung mit einem besseren Verständnis intermolekularer Wechselwirkungen, die durch den Zugriff auf vollständig korrelierte Berechnungen oder den Zugriff auf eine schnellere Bandbreite, die die Parametrisierung verbessert, katalysiert werden, Nicht-Quantenmodellierungstechniken wie Kraftfelder erheblich verbessern.
Ein letzter Punkt, auf den Sie achten sollten, ist, dass es im Gegensatz zu anderen Bereichen der Algorithmusforschung, wie dem Lernen mit Quantenmaschinen, eine Reihe von kurzfristigen Quantensimulationsalgorithmen gibt, die auf anspruchsloser, bereits vorhandener Hardware ausgeführt werden können. Zahlreiche Versuchsgruppen auf der ganzen Welt haben über erfolgreiche Demonstrationen dieser Algorithmen berichtet [ hier , hier , hier und hier ].
Leider gibt es auch einige Nachteile bei der Modellierung von Quantensystemen. Wie oben diskutiert, ist es sehr schwierig, Informationen von einem Quantencomputer zu extrahieren. Die Rekonstruktion der gesamten Wellenfunktion ist schwieriger als die klassische Berechnung. Dies ist ein wichtiger Nachteil bei chemischen Problemen, bei denen Argumente, die auf der elektronischen Struktur beruhen, die Hauptquelle für das Verständnis sind. Im Vergleich zum maschinellen Lernen überwiegen jedoch die Vorteile bei weitem die Nachteile, und es wird erwartet, dass die Quantensimulation eine der ersten nützlichen Anwendungen des praktischen Quantencomputers ist [siehe Lit. hier ].
3.2. Fehlertolerantes Quantencomputing
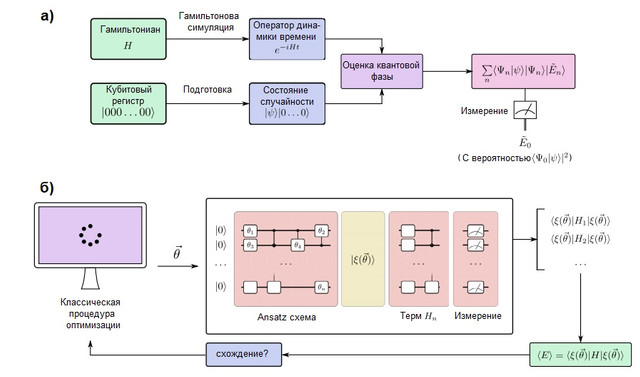
ABBILDUNG 2. (a) Ein Quantensimulationsalgorithmus in einem fehlertoleranten Quantencomputer. Die Qubits sind in zwei Register unterteilt: eines wird im Zustand vorbereitet, die der Zielwellenfunktion ähnelt, während die andere im Zustand bleibt ... Der Quantenphasenschätzungsalgorithmus (QPE) wird verwendet, um die Eigenwerte des Zeitentwicklungsoperators zu finden, das mit den Methoden der Hamiltonschen Modellierung hergestellt wird. Nach QPE liefert die Messung eines Quantencomputers mit Wahrscheinlichkeit die GrundzustandsenergieDaher ist es wichtig, den Stand der Vermutung vorzubereiten mit einer Überlappung ungleich Null mit der wahren Wellenfunktion. (b) Ein Variationsquanten-Simulationsalgorithmus in einem Kurzzeit-Quantencomputer. Dieser Algorithmus kombiniert einen Quantenprozessor mit einer klassischen Optimierungsroutine, um mehrere kurze Läufe durchzuführen, die schnell genug sind, um Fehler zu vermeiden. Ein Quantencomputer bereitet einen Vermutungszustand vormit einer Quanten ansatz Kette von mehreren Parametern abhängig... Die einzelnen Terme des Hamilton-Operators werden einzeln (oder in Pendlergruppen mit fortgeschritteneren Strategien) gemessen, um eine Schätzung der erwarteten Energie für einen bestimmten Parametervektor zu erhalten. Anschließend werden die Parameter nach dem klassischen Optimierungsverfahren bis zur Konvergenz optimiert. Der Variationsansatz wurde neben der Quantensimulation auf viele algorithmische Probleme erweitert.
Quantencomputer, die große chemische Systeme simulieren können, müssen fehlertolerant sein, um beliebig tiefe Algorithmen fehlerfrei ausführen zu können. Ein solcher Quantencomputer kann ein chemisches System simulieren, indem er das Verhalten seiner Elektronen auf das Verhalten seiner Qubits und Quantentore abbildet. Der Quantenmodellierungsprozess ist konzeptionell sehr einfach und in Abbildung 2 (a) dargestellt. Wir werden ein Register von Qubits erstellen, die die Wellenfunktion speichern und die einheitliche Entwicklung des Hamilton-Operators implementieren könnenunter Verwendung der Methoden der Hamiltonschen Modellierung, die unten diskutiert werden. Mit diesen Elementen kann eine als Quantenphasenschätzung bekannte Quantensubroutine die Eigenvektoren und Eigenwerte des Systems finden. Befindet sich das Qubit-Register anfänglich im Zustand | 0⟩, ist der Endzustand: Mit anderen Worten, der Endzustand ist eine Überlagerung von Eigenwerten

und Eigenvektoren Systeme. Der Grundzustand wird dann mit Wahrscheinlichkeit gemessen... Um diese Wahrscheinlichkeit zu maximieren, wird ein Basiszustand mit einem leicht vorbereitbaren, aber auch physikalisch motivierten Zustand erstellt, von dem erwartet wird, dass er dem genauen Grundzustand ähnlich ist. Ein typisches Beispiel ist der Hartree-Fock-Zustand, obwohl andere Ideen für stark korrelierte Systeme untersucht wurden [siehe Lit. hier ].
Es gibt zwei gängige Arten, Elektronen in einem Molekül darzustellen: gitterbasierte und orbitale oder grundlegende Methoden (eine vollständige Aufschlüsselung finden Sie bei McArdle und Kollegen [ hier ]). Bei Basissatzmethoden wird die Elektronenwellenfunktion als Summe der Slater-Determinanten von Elektronenorbitalen dargestellt, die direkt mit dem Qubit-Register verglichen werden können [ hier undhier ]. Dies erfordert die Wahl einer Basis und die vorläufige Berechnung elektronischer Integrale. Andererseits wird bei Gittermethoden das Problem als Lösung für eine gewöhnliche Differentialgleichung in einem Gitter formuliert. Der Vorteil der gitterbasierten Modellierung besteht darin, dass keine Bourne-Oppenheimer-Näherung oder Basissatz erforderlich ist. Sie sind jedoch von Natur aus nicht antisymmetrisch, was nach dem Pauli-Prinzip aus der Quantenmechanik erforderlich ist. Daher muss die Antisymmetrie mithilfe des Sortierverfahrens [ hier ] sichergestellt werden . Gitterbasierte Methoden wurden im Rahmen chemisch-dynamischer Simulationen diskutiert [vgl. hier ] und Berechnung der thermischen Geschwindigkeitskonstante [siehe. Hier]. Trotz der Unterschiede ist der Workflow für die Quantenmodellierung identisch, wie in Abbildung 2 dargestellt.
Es gibt auch verschiedene Möglichkeiten, den Operator zu konstruieren... Wir werden die einfachste Technik vorstellen, die Trotterisierung, auch als Produktformulierung bekannt [siehe S. hier ]; Für eine vollständige Übersicht siehe [ hier und hier ]. Die Trotterisierung basiert auf der Prämisse, dass der molekulare Hamilton-Operator als Summe von Begriffen aufgeteilt werden kann, die Ein- und Zwei-Elektronen-Wechselwirkungen beschreiben. Wenn ja, dann der Bedienerkann in Bezug auf die entsprechenden Operatoren für jeden Term im Hamilton-Operator unter Verwendung der Trotter-Suzuki-Formel [ hier ] implementiert werden : In der zweiten Quantisierung hat beispielsweise jeder Term in diesem Ausdruck die Form oder , wo sind die Vernichtungs- bzw. Erstellungsoperatoren. Explizite, detaillierte Schemakonstruktionen, die diese Begriffe darstellen, wurden von Whitfield und Kollegen angegeben [vgl. hier ]. Nach der Berechnung der Mitglieder
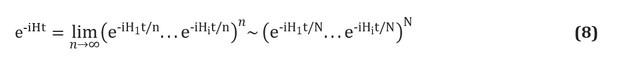

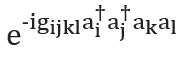
 und bekannt als elektronische Integrale, die Mengevöllig bestimmt. Sie können auch Trotter-Suzuki-Formeln höherer Ordnung verwenden, um den Fehler zu reduzieren. Es gibt viele andere Hamilton-Modellierungstechniken. Beispiele für leistungsfähige und ausgefeilte Techniken sind die Kubitisierung [ hier ] und die Quantensignalverarbeitung [siehe Lit. hier ], die nachweislich eine optimale asymptotische Skalierung aufweisen, obwohl unklar ist, ob dies zu besseren praktischen Anwendungen führen wird.
und bekannt als elektronische Integrale, die Mengevöllig bestimmt. Sie können auch Trotter-Suzuki-Formeln höherer Ordnung verwenden, um den Fehler zu reduzieren. Es gibt viele andere Hamilton-Modellierungstechniken. Beispiele für leistungsfähige und ausgefeilte Techniken sind die Kubitisierung [ hier ] und die Quantensignalverarbeitung [siehe Lit. hier ], die nachweislich eine optimale asymptotische Skalierung aufweisen, obwohl unklar ist, ob dies zu besseren praktischen Anwendungen führen wird.
4. Optimierungsprobleme
Viele Probleme in der Computerbiologie und anderen Disziplinen können so formuliert werden, dass sie das globale Minimum oder Maximum einer komplexen, mehrdimensionalen Funktion finden. Beispielsweise wird angenommen, dass die native Struktur eines Proteins das globale Minimum seiner Hyperfläche für freie Energie ist [siehe. hier ]. In einem anderen Bereich entspricht die Identifizierung von Gruppen in einem Netzwerk interagierender Proteine oder biologischer Objekte der Suche nach einer optimalen Teilmenge von Knoten [siehe. Hier]. Leider sind Optimierungsprobleme mit Ausnahme einiger einfacher Systeme oft sehr komplex. Obwohl es Heuristiken gibt, um ungefähre Lösungen zu finden, geben sie normalerweise nur lokale Minima an, und in vielen Fällen ist sogar die Heuristik unentscheidbar. Die Fähigkeit von Quantencomputern, Lösungen für solche Optimierungsprobleme zu beschleunigen oder bessere Lösungen zu finden, wurde eingehend untersucht.
Das Thema der Optimierung in einem Quantencomputer ist komplex, da oft nicht klar ist, ob ein Quantencomputer irgendeine Art von Beschleunigung bereitstellen kann. In diesem Abschnitt geben wir einen Überblick über einige Ideen der Quantenoptimierung. Die Garantien für eine Verbesserung sind jedoch nicht so klar, wenn man sie beispielsweise mit der Quantensimulation vergleicht, von der auf lange Sicht erwartet wird, dass sie von Vorteil ist.
4.1. Optimierung in einem Quantenprozessor
Die quantenadiabatische Optimierung ist aufgrund des Vorhandenseins von D-Wave-Maschinen einer der beliebtesten Optimierungsansätze [siehe. hier ], die diesen Ansatz zunächst umsetzen. Das adiabatische Quantencomputing [ hier ] basiert auf dem adiabatischen Theorem der Quantenmechanik [vgl. Hier]. Nach diesem Theorem bleibt das System immer in seinem augenblicklichen Grundzustand, wenn ein System im Grundzustand des Hamiltonian vorbereitet wird und sich dieser Hamiltonian ziemlich langsam ändert. Dies kann verwendet werden, um Berechnungen durchzuführen, indem ein Problem (wie eine Bewertungsfunktion, die wir zu minimieren hoffen) als Hamilton-Operator codiert wird und sich allmählich von einem ursprünglichen System, das in seinem Grundzustand trivial vorbereitet werden kann, zu diesem Hamilton-Operator entwickelt. Im Allgemeinen wird die adiabatische Evolution wie folgt ausgedrückt: Hier

und - funktioniert so, dass und für eine bestimmte Zeit T. Zum Beispiel könnten wir ein lineares Glühprogramm mit betrachten und ... Viele Arbeiten haben sich der Diskussion der Ausführungszeit des adiabatischen Algorithmus gewidmet, aber die allgemeine Heuristik ist, dass die Ausführungszeit während der adiabatischen Evolution maximal proportional zum inversen Quadrat der minimalen spektralen Lücke (der kleinsten Energiedifferenz zwischen dem Grundzustand und dem ersten angeregten Zustand) ist... Es wird angenommen, dass adiabatisches Quantencomputing (und Quantencomputing im Allgemeinen) die Klasse der NP-vollständigen Probleme nicht effektiv lösen kann, oder zumindest keine dieser Methoden hat strenge Tests bestanden [siehe Lit. hier ].
Grundsätzlich entspricht adiabatisches Quantencomputing dem universellen Quantencomputing [vgl. hier ]. Diese Universalität findet nur statt, wenn die Evolution eine Nichtstochastizität zulässt, was bedeutet, dass der Hamilton-Operator zu einem bestimmten Zeitpunkt in der Evolution nicht negative nicht diagonale Elemente aufweist. Die beliebteste experimentelle Implementierung des adiabatischen Quantencomputers, die von D-Wave Systems Inc. kommerzialisiert wird .verwendet stochastische Hamiltonianer und ist daher nicht universell. In der Fachliteratur gibt es einige Bedenken, dass diese Art des Quantencomputers [ hier ] klassisch simuliert werden könnte , was bedeutet, dass eine exponentielle Beschleunigung möglicherweise nicht möglich ist. Trotz dieser Bedenken wurde diese Technik häufig als metaheuristische Optimierungstechnik eingesetzt und es wurde kürzlich gezeigt, dass sie das simulierte Tempern übertrifft [siehe Lit. hier ].
Die Quantenoptimierung wurde außerhalb des adiabatischen Modells untersucht. Der e-Quanten-Approximations-Optimierungsalgorithmus (QAOA) [vgl. hier , hier und hier] Ist ein Variationsoptimierungsalgorithmus in einem Quantencomputer, der in der Literatur großes Interesse geweckt hat. Es gab mehrere experimentelle Implementierungen von QAOA in Quantenprozessoren, z. hier ] Abbildung 3. ABBILDUNG 3. (a) Simulation eines adiabatischen Quantencomputers, der das [ hier ] beschriebene vereinfachte Proteinfaltungsproblem implementiert . Die Farbe codiert die dezimale logarithmische Wahrscheinlichkeit einer bestimmten Binärzeichenfolge. Am Ende der Berechnung haben die beiden Lösungen mit der niedrigsten Energie eine Messwahrscheinlichkeit nahe 0,5. Die Evolution ist in einer endlichen Zeit niemals vollständig adiabatisch, und andere binäre Strings haben verbleibende Messwahrscheinlichkeiten. (b)

Beschreibung des adiabatischen Prozesses des Quantencomputers. Das Potential, das die Qubits antreibt, ändert sich langsam, wodurch sie sich drehen. Beachten Sie, dass die Bloch-Kugeldarstellung unvollständig ist, da sie nicht die Korrelationen zwischen verschiedenen Qubits anzeigt, die für den Quantenvorteil erforderlich sind. Am Ende der Evolution befindet sich das Qubitsystem in einem klassischen Zustand (oder einer Überlagerung klassischer Zustände), was eine Lösung mit der niedrigsten Energie darstellt. (c) Energieniveaus während der adiabatischen Quantenentwicklung. Die Zeit, die erforderlich ist, um eine quasi-adiabatische Entwicklung sicherzustellen, wird durch die minimale Energiedifferenz zwischen den Niveaus bestimmt, die durch die gestrichelte Linie angezeigt wird
4.2. Vorhersage der Proteinstruktur
Die Vorhersage der Proteinstruktur ohne Matrix bleibt ein großes offenes ungelöstes Problem in der Computerbiologie. Die Lösung für dieses Problem wird in der molekularen Technik und im Wirkstoffdesign breite Anwendung finden. Nach der Proteinfaltungshypothese wird die native Struktur eines Proteins als globales Minimum seiner freien Energie angesehen [siehe. hier ], obwohl es viele Gegenbeispiele gibt. Angesichts des riesigen Konformationsraums, der selbst für kleine Peptide zur Verfügung steht, sind erschöpfende klassische Simulationen nicht lösbar. Viele fragen sich jedoch, ob Quantencomputer zur Lösung dieses Problems beitragen können.
Die Literatur zum Quantencomputer konzentriert sich auf das Proteingittermodell, bei dem ein Peptid als selbstfahrende Gitterstruktur modelliert wird, obwohl in jüngster Zeit auch mehrere andere Modelle in der Computerpraxis angewendet wurden [vgl. hier ]. Jede Gitterstelle entspricht einem Rest, und Wechselwirkungen zwischen räumlich benachbarten Stellen tragen zur Energiefunktion bei. Es gibt verschiedene Schemata für den Energiekontakt, aber nur zwei wurden für Quantenanwendungen verwendet: das hydrophob-polare Modell [siehe. hier ], das nur zwei Klassen von Aminosäuren berücksichtigt, und das Miyazawa-Jernigan-Modell [vgl. Hier], die Wechselwirkungen für jedes Restpaar enthalten. Obwohl diese Modelle eine deutliche Vereinfachung darstellen, haben sie wesentliche Einblicke in die Proteinfaltung geliefert [siehe Lit. hier ] und wurden als grobes Werkzeug zur Untersuchung des Konformationsraums vor einer weiteren detaillierten Verfeinerung vorgeschlagen [siehe. hier und hier ].
Fast alle Arbeiten konzentrierten sich auf adiabatisches Quantencomputing, da selbst Modellpeptide eine große Anzahl von Qubits erfordern und D-Wave-Quantenmaschinen die größten heute verfügbaren Quantengeräte sind.
In einem kürzlich veröffentlichten Artikel von Fingerhat und Kollegen [siehe Hier] wurde versucht, die Verwendung des QAOA-Algorithmus zu beschreiben. Beide Methoden haben ähnliche Eigenschaften, wenn das Proteingitterproblem als Hamilton-Operator codiert ist. Diese Methode wurde zuerst von Perdomo in Betracht gezogen [siehe. hier ], was die Verwendung eines Qubit-Registers vorschlugUm die kartesischen Koordinaten von N Aminosäuren auf einem D-dimensionalen kubischen Gitter mit N Seiten zu codieren, wird die Energiefunktion in einem Hamilton-Operator ausgedrückt, der Begriffe zur Belohnung von Kontakten mit Proteinen enthält: Bewahren Sie die Primärstruktur und vermeiden Sie Aminosäureanpassungen. Kurz nach diesem wegweisenden Artikel erschien ein weiterer Artikel, in dem die Konstruktion biteffizienterer Modelle für ein zweidimensionales Gitter erörtert wurde [siehe. hier ].
Diese Codierungen wurden 2012 auf realer Hardware getestet, als Perdomo und Kollegen [siehe. Hier] berechnete die niedrigste Energiekonformation des PSVKMA-Peptids auf einer D-Wave-Quantenmaschine. Kürzlich hat Babays Forschungsteam die Rotations- und Diamantcodierung für 3D-Modelle erweitert und algorithmische Verbesserungen eingeführt, die die Komplexität und Bewegungsgeschwindigkeit der Hamilton-Codierung verringern [siehe Lit. hier ]. Sie verwendeten einen D-Wave 2000Q-Prozessor , um den Grundzustand von Higolin (10 Reste) auf einem quadratischen Gitter und Tryptophan (8 Reste) auf einem kubischen Gitter zu bestimmen. Dies sind die größten bisher untersuchten Peptide. Diese experimentellen Implementierungen verwenden ein Verfahren, bei dem ein Teil des Peptids fixiert ist. Dies ermöglicht es, aufgrund der Möglichkeit der Forschung große Probleme in einen Quantencomputer einzuführendie Anzahl der untersuchten problematischen Parameter.
Das Finden der Konformation mit der niedrigsten Energie im Gittermodell ist ein schwieriges NP-Problem [vgl. hier und hier ], was bedeutet, dass es unter Standardhypothesen keinen klassischen Algorithmus zum Lösen gibt. Darüber hinaus wird derzeit angenommen, dass Quantencomputer keine exponentielle Beschleunigung für NP-vollständige und komplexere Probleme bieten können [vgl. hier ], obwohl sie die Vorteile der Skalierung bieten können, die in der Literatur als "begrenzte Quantenbeschleunigung" bekannt sind [vgl. Hier]. Kürzlich verwendete die Forschungsgruppe von Outerel numerische Simulationen, um diese Tatsache zu untersuchen, und kam zu dem Schluss, dass es Hinweise auf eine begrenzte Quantenbeschleunigung gibt, obwohl dieses Ergebnis möglicherweise adiabatische Maschinen erfordert, die Fehlerkorrekturen oder Quantensimulationen in fehlertoleranten Allzweckmaschinen verwenden [vgl. hier ].
Obwohl sich der größte Teil der Literatur auf das Proteingittermodell konzentriert hat, wurde in einem kürzlich erschienenen Artikel [ hier ] versucht, mithilfe von Quantenglühen Rotamere in der Rosetta-Energiefunktion abzutasten [siehe Lit. hier ]. Die Autoren verwendeten den D-Wave 2000Q-Prozessoreine Skalierung zu finden, die im Vergleich zum klassischen simulierten Tempern nahezu konstant schien. Ein sehr ähnlicher Ansatz wurde von der Marchand-Gruppe vorgestellt [siehe. hier ] für eine Auswahl von Konformern.
Schlussfolgerungen
Ein Quantencomputer kann große Informationsmengen speichern und bearbeiten und Algorithmen exponentiell schneller ausführen als jede klassische Computertechnologie. Das Potenzial selbst kleiner Quantencomputer kann die besten Supercomputer, die es heute gibt, sicher übertreffen, was letztendlich im Rahmen bestimmter Aufgaben einen transformativen Effekt für die Computerbiologie haben kann und verspricht, Probleme von der Kategorie unlösbar über schwierig und komplex auf Routine zu übertragen. Die ersten Quantenprozessoren, die nützliche Probleme lösen können, werden voraussichtlich im nächsten Jahrzehnt erscheinen. Daher ist es für jeden Computerwissenschaftler eine Priorität zu verstehen, was Quantencomputer können und was nicht.
Obwohl wir gerade in die Ära des praktischen Quantencomputers eintreten, können wir bereits die Konturen einer neuen Quantencomputerbiologie für die kommenden Jahrzehnte erkennen. Wir hoffen, dass diese Übersicht bei Computerbiologen Interesse an Technologien weckt, die bald ihr Experimentier- und Forschungsgebiet verändern könnten. Und Spezialisten für Quantencomputer werden wiederum in der Lage sein, Biologen dabei zu helfen, das Niveau der Computerbiologie und Bioinformatik signifikant zu entwickeln, von dem viele signifikante Ergebnisse für die gesamte Menschheit erwartet werden.