Teil 2
Teil 3
In diesem Artikel lernen Sie:
- Was Transferlernen ist und wie es funktioniert
- Was ist Semantik- / Instanzsegmentierung und wie funktioniert sie ?
- Über die Objekterkennung und deren Funktionsweise
Einführung
Bei Objekterkennungsaufgaben werden zwei Methoden unterschieden (siehe Quelle und weitere Details hier ):
- Zwei -Stufe Methoden, sie sind auch „Methoden , die auf Regionen“ (eng Region-basierte Methoden.) - ein Ansatz in zwei Phasen unterteilt. In der ersten Phase werden interessierende Regionen (RoI) durch selektive Suche oder unter Verwendung einer speziellen Schicht des neuronalen Netzwerks ausgewählt - Regionen, die Objekte mit hoher Wahrscheinlichkeit enthalten. In der zweiten Stufe werden die ausgewählten Regionen vom Klassifizierer berücksichtigt, um die Zugehörigkeit zu den ursprünglichen Klassen zu bestimmen, und vom Regressor, der die Position der Begrenzungsrahmen angibt.
- Einstufige Methode (englische einstufige Methoden) - Ansatz, bei dem kein separater Algorithmus zum Generieren von Regionen verwendet wird, sondern stattdessen eine bestimmte Anzahl von Begrenzungsrahmen mit unterschiedlichen Merkmalen wie die Klassifizierungsergebnisse und der Grad des Vertrauens vorhergesagt und der Standortrahmen weiter angepasst wird.
Dieser Artikel beschreibt einstufige Methoden.
Lernen übertragen
Transferlernen ist eine Methode zum Trainieren neuronaler Netze, bei der wir ein Modell, das bereits auf einigen Daten trainiert wurde, für weiteres zusätzliches Training verwenden, um ein anderes Problem zu lösen. Zum Beispiel haben wir ein EfficientNet-B5-Modell, das auf einem ImageNet-Dataset (1000 Klassen) trainiert wurde. Im einfachsten Fall ändern wir nun die letzte Klassifiziererebene (z. B. um Objekte von 10 Klassen zu klassifizieren).
Schauen Sie sich das Bild unten an:
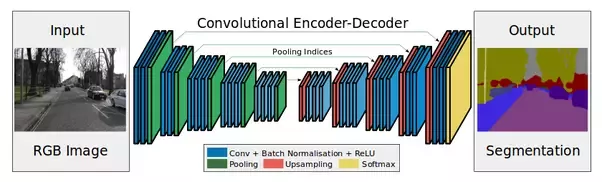
Encoder sind Unterabtastungsschichten (Windungen und Pools).
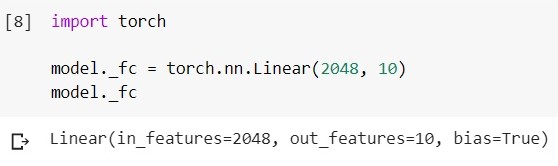
Das Ersetzen der letzten Ebene im Code sieht folgendermaßen aus (Framework - Pytorch, Umgebung - Google Colab):
Laden Sie das trainierte EfficientNet-b5-Modell und sehen Sie sich die Klassifiziererebene an:

Ändern Sie diese Ebene in eine andere:
Decoder wird insbesondere für die Segmentierungsaufgabe benötigt (dazu Des Weiteren).
Lernstrategien übertragen
Es sollte hinzugefügt werden, dass standardmäßig alle Ebenen des Modells, die wir weiter trainieren möchten, trainierbar sind. Wir können die Gewichte einiger Schichten "einfrieren".
So frieren Sie alle Ebenen ein:

Je weniger Ebenen wir trainieren, desto weniger Rechenressourcen benötigen wir, um das Modell zu trainieren. Ist diese Technik immer gerechtfertigt?
Abhängig von der Datenmenge, auf der das Netzwerk trainiert werden soll, und von den Daten, auf denen das Netzwerk trainiert wurde, gibt es 4 Optionen für die Entwicklung von Ereignissen für das Transferlernen (unter "wenig" und "viel" können Sie den bedingten Wert 10k annehmen):
- Sie haben nur wenige Daten und diese ähneln den Daten, auf denen das Netzwerk zuvor trainiert wurde. Sie können versuchen, nur die letzten Ebenen zu trainieren.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
Semantische Segmentierung ist, wenn wir ein Bild als Eingabe einspeisen und an der Ausgabe Folgendes erhalten möchten:

Formaler möchten wir jedes Pixel unseres Eingabebilds klassifizieren - um zu verstehen, zu welcher Klasse es gehört.
Hier gibt es viele Ansätze und Nuancen. Was ist nur die Architektur des ResNeSt-269-Netzwerks :)
Intuition - am Eingang das Bild (h, w, c), am Ausgang wollen wir eine Maske (h, w) oder (h, w, c) bekommen, wobei c die Anzahl der Klassen ist (abhängig von Daten und Modell). Fügen wir nun einen Decoder nach unserem Encoder hinzu und trainieren sie.
Der Decoder besteht insbesondere aus Upsampling-Schichten. Sie können die Bemaßung einfach erhöhen, indem Sie unsere Feature-Map in der einen oder anderen Stufe in Höhe und Breite "strecken". Beim Ziehen können Sie verwendenbilineare Interpolation (im Code ist dies nur einer der Methodenparameter).
Deeplabv3 + -Netzwerkarchitektur:
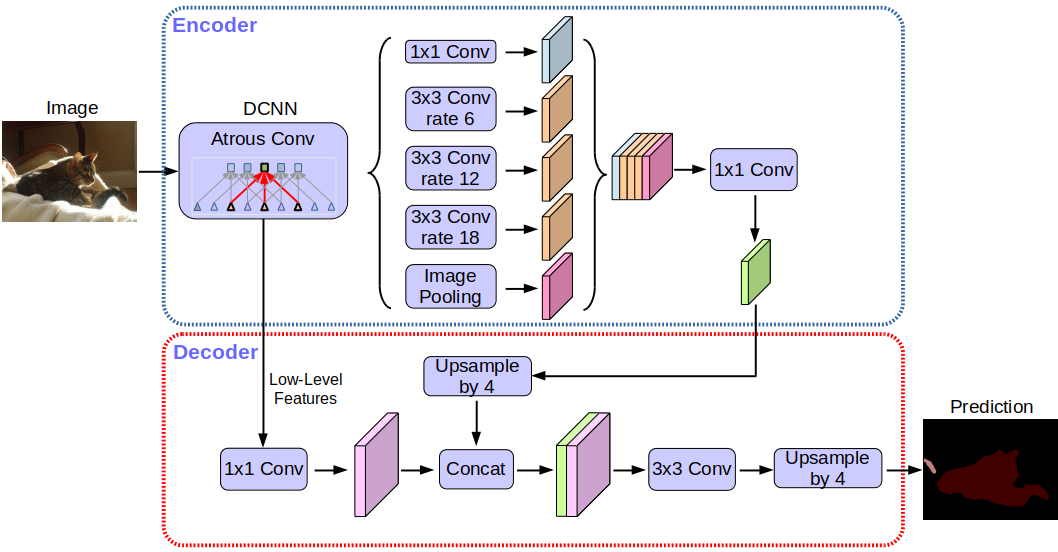
Ohne auf Details einzugehen , werden Sie feststellen, dass das Netzwerk die Encoder-Decoder-Architektur verwendet.
Eine klassischere Version, die Architektur des U-Net-Netzwerks:
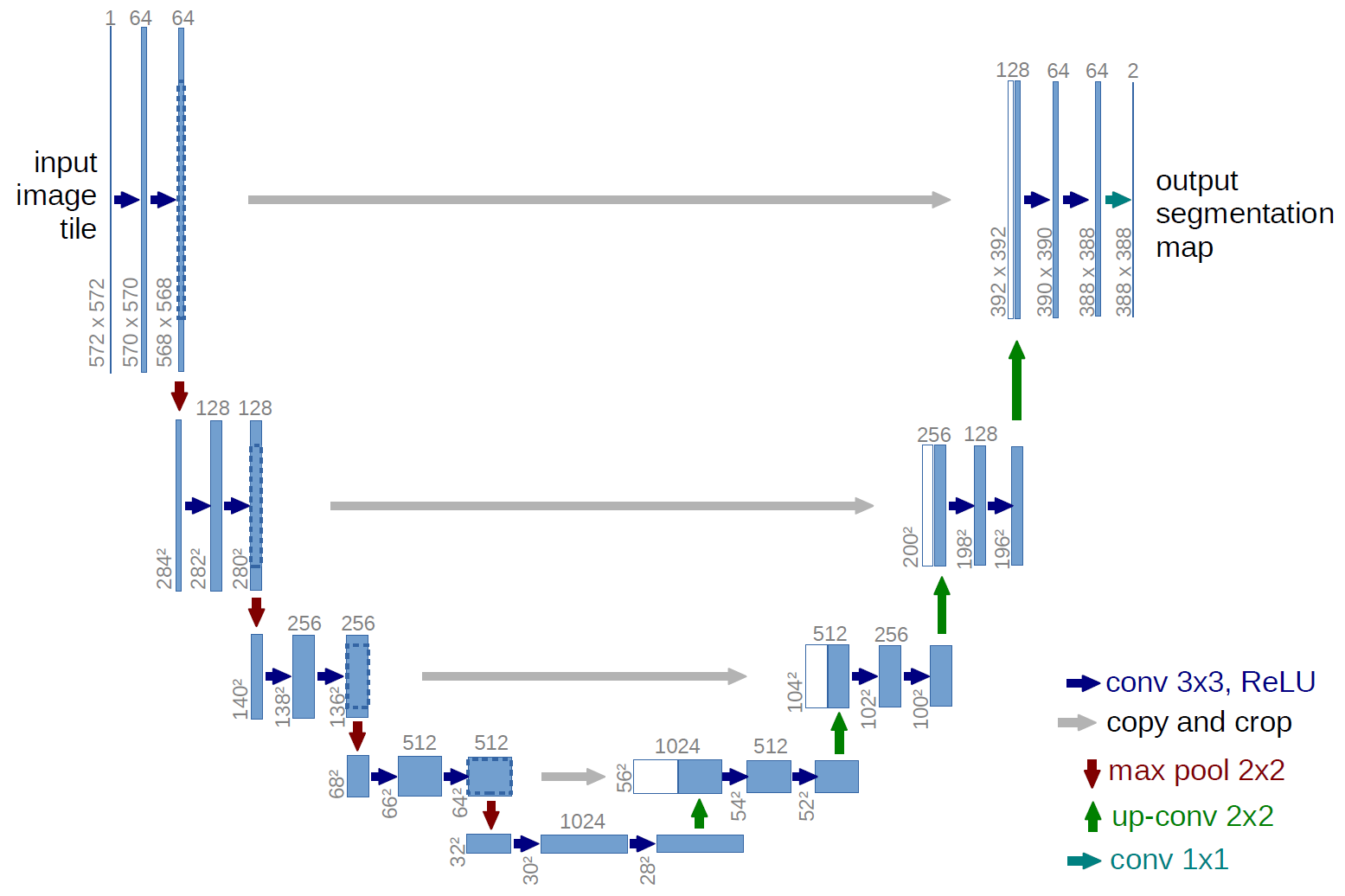
Was sind diese grauen Pfeile? Dies sind die sogenannten Sprungverbindungen. Der Punkt ist, dass der Encoder unser verlustbehaftetes Eingabebild „codiert“. Um solche Verluste zu minimieren, verwenden sie Sprungverbindungen.
In dieser Aufgabe können wir Transferlernen verwenden - zum Beispiel können wir ein Netzwerk mit einem bereits trainierten Encoder nehmen, einen Decoder hinzufügen und es trainieren.
Welche Daten und welche Modelle derzeit bei dieser Aufgabe am besten funktionieren - sehen Sie hier...
Instanzsegmentierung
Eine komplexere Version des Segmentierungsproblems. Das Wesentliche ist, dass wir nicht nur jedes Pixel des Eingabebildes klassifizieren, sondern auch irgendwie verschiedene Objekte derselben Klasse auswählen möchten:
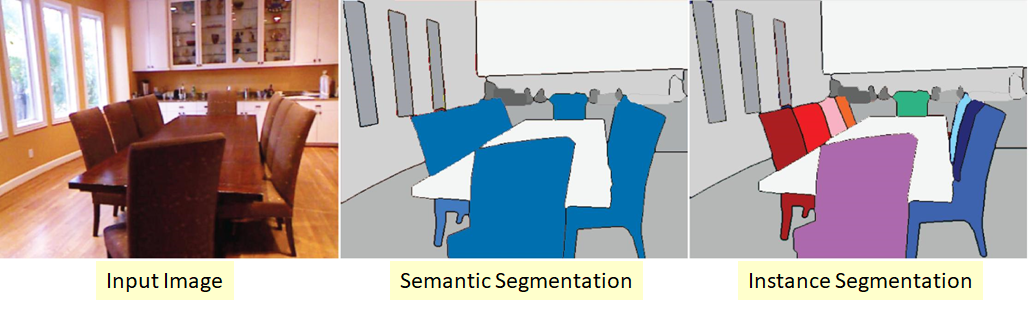
Es kommt also vor, dass Klassen "klebrig" sind oder es keine sichtbare Grenze zwischen ihnen gibt, sondern wir möchten Objekte derselben Klasse abgrenzen voneinander.
Hier gibt es auch mehrere Ansätze. Das einfachste und intuitivste ist, dass wir zwei verschiedene Netzwerke trainieren. Wir lehren die erste, Pixel für einige Klassen zu klassifizieren (semantische Segmentierung), und die zweite, um Pixel zwischen Klassenobjekten zu klassifizieren. Wir bekommen zwei Masken. Jetzt können wir die zweite von der ersten subtrahieren und bekommen, was wir wollten :)
Auf welchen Daten und welchen Modellen ist diese Aufgabe im Moment am besten - sehen Sie hier...
Object detection
Wir senden ein Bild an die Eingabe, und an der Ausgabe möchten wir Folgendes sehen:

Das intuitivste, was Sie tun können, ist, das Bild mit verschiedenen Rechtecken zu „überfahren“ und mithilfe eines bereits trainierten Klassifikators festzustellen, ob in diesem Bereich ein für uns interessantes Objekt vorhanden ist. Es gibt ein solches Schema, aber es ist offensichtlich nicht das beste. Wir haben Faltungsschichten, die die Feature-Map "vor" (A) in der Feature-Map "nach" (B) irgendwie unterschiedlich interpretieren. In diesem Fall kennen wir die Abmessungen der Faltungsfilter => wir wissen, welche Pixel von A in welche Pixel B konvertiert wurden.
Werfen wir einen Blick auf YOLO v3:
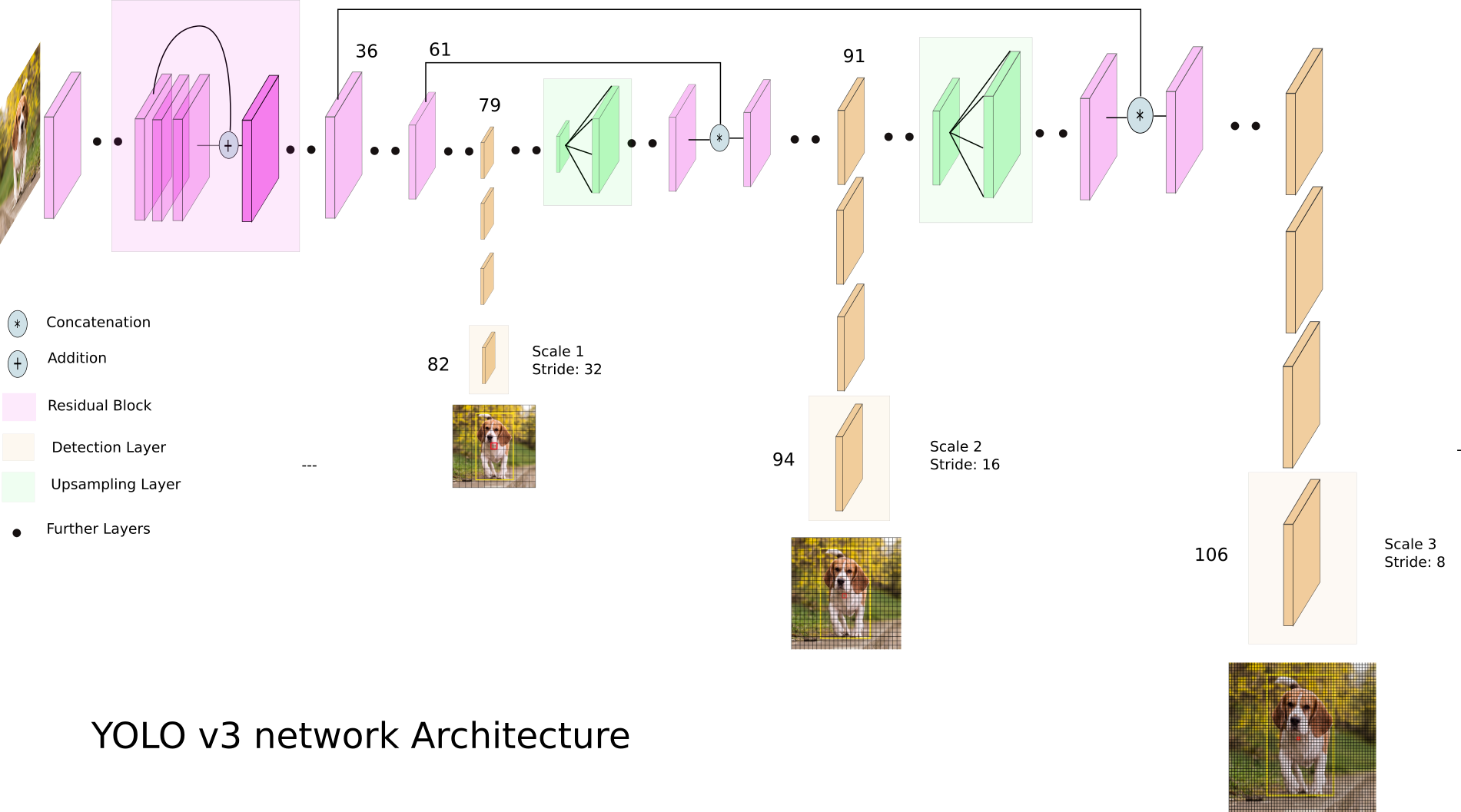
YOLO v3 verwendet unterschiedlich dimensionierte Feature-Maps. Dies geschieht insbesondere, um Objekte unterschiedlicher Größe korrekt zu erkennen.
Als nächstes werden alle drei Skalen verkettet:
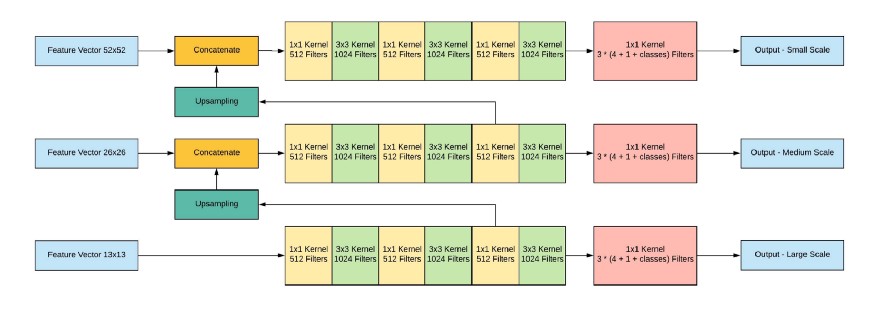
Netzwerkausgabe mit einem Eingabebild von 416 x 416, 13 x 13 x (B * (5 + C)), wobei C die Anzahl der Klassen und B die Anzahl der Boxen für jede Region ist (YOLO v3 hat 3 davon). 5 - Dies sind Parameter wie: Px, Py - Koordinaten des Objektzentrums, Ph, Pw - Höhe und Breite des Objekts, Pobj - die Wahrscheinlichkeit, dass sich das Objekt in diesem Bereich befindet.
Schauen wir uns das Bild an, damit es etwas klarer wird:

YOLO filtert Vorhersagedaten zunächst nach der Objektbewertung nach einem bestimmten Wert (normalerweise 0,5 bis 0,6) und dann nach nicht maximaler Unterdrückung heraus .
Welche Daten und welche Modelle derzeit bei dieser Aufgabe am besten funktionieren - sehen Sie hier .
Fazit
Es gibt heutzutage viele verschiedene Modelle und Ansätze für die Aufgaben der Segmentierung und Lokalisierung von Objekten. Es gibt bestimmte Ideen, die verstehen, dass es einfacher wird, diesen Zoo von Modellen und Ansätzen zu zerlegen. Ich habe versucht, diese Ideen in diesem Artikel auszudrücken.
In den nächsten Artikeln werden wir über Stilübertragungen und GANs sprechen.