"Programme zu verlangsamen ist viel schneller als Computer zu beschleunigen"
Seitdem gilt diese Aussage als Wirths Gesetz . Es negiert effektiv das Moore'sche Gesetz, das besagt, dass sich die Anzahl der Transistoren in Prozessoren seit etwa 1965 verdoppelt hat. Folgendes schreibt Wirth in seinem Artikel "Call for Slim Software" :
„Vor ungefähr 25 Jahren hatte ein interaktiver Texteditor nur 8000 Byte und ein Compiler 32 Kilobyte, während ihre modernen Nachkommen Megabyte benötigen. Ist all diese aufgeblähte Software schneller geworden? Nein, ganz im Gegenteil. Ohne tausendmal schnellere Hardware wäre moderne Software völlig unbrauchbar. "
Es ist schwierig, dem zu widersprechen.
Adipositas-Software
Das Problem der Entwicklung moderner Software ist sehr akut. Wirth weist auf einen wichtigen Aspekt hin: die Zeit. Er schlägt vor, dass der Hauptgrund für aufgeblähte Software der Mangel an Entwicklungszeit ist.
Heute gibt es einen weiteren Grund für Fettleibigkeit in der Software - die Abstraktion. Und das ist ein viel ernsthafteres Problem. Entwickler haben noch nie Programme von Grund auf neu geschrieben, aber dies war noch nie ein Problem.
Dijkstra und Wirth versuchten, die Qualität des Codes zu verbessern und entwickelten das Konzept der strukturierten Programmierung. Sie wollten das Programmieren aus der Krise herausholen, und für einige Zeit wurde das Programmieren als echtes Handwerk für echte Profis angesehen. Die Programmierer kümmerten sich um die Qualität der Programme, schätzten die Klarheit und Effizienz des Codes.
Diese Tage sind vorbei.
Mit dem Aufkommen höherer Sprachen wie Java, Ruby, PHP und Javascript wurde die Programmierung 1995 abstrakter, als Wirth seinen Artikel schrieb. Neue Sprachen haben das Programmieren viel einfacher gemacht und viel übernommen. Sie waren objektorientiert und wurden mit Dingen wie IDEs und Garbage Collection gebündelt.
Es ist für Programmierer einfacher geworden zu leben, aber sie müssen für alles bezahlen. Je einfacher es ist zu leben, desto weniger zu denken. Mitte der 90er Jahre hörten Programmierer auf, über die Qualität ihrer Programme nachzudenken, schreibt Entwickler Robin Martin in seinem Artikel "Niklaus Wirth hatte Recht, und das ist das Problem . " Gleichzeitig begann die weit verbreitete Nutzung von Bibliotheken, deren Funktionalität für ein bestimmtes Programm immer viel mehr als notwendig ist.
Da die Bibliothek nicht für ein bestimmtes Projekt erstellt wurde, verfügt sie wahrscheinlich über etwas mehr Funktionen, als sie wirklich benötigt. Kein Problem, sagst du? Die Dinge summieren sich jedoch ziemlich schnell. Selbst Leute, die Bibliotheken lieben, wollen das Rad nicht neu erfinden. Dies führt zu der sogenannten Abhängigkeitshölle. Nicola Duza hat einen Beitrag zu diesem Thema in Javascript geschrieben .
Das Problem scheint keine große Sache zu sein, aber in Wirklichkeit ist es ernster als Sie vielleicht denken. Zum Beispiel hat Nikola Dusa eine einfache To-Do-Listen-App geschrieben. Es funktioniert in Ihrem Browser mit HTML und Javascript. Wie viele Abhängigkeiten hat es Ihrer Meinung nach verwendet? 13.000. Dreizehn. Tausend. Beweis .
Die Zahlen sind verrückt, aber das Problem wird nur wachsen. Wenn neue Bibliotheken erstellt werden, erhöht sich auch die Anzahl der Abhängigkeiten in jedem Projekt.
Dies bedeutet, dass sich das Problem, vor dem Niklaus Wirth 1995 gewarnt hat, mit der Zeit nur noch verschlimmern wird.
Was zu tun ist?
Robin Martin schlägt vor, dass ein guter Weg, um loszulegen, darin besteht, die Bibliotheken aufzuteilen. Anstatt eine große Bibliothek zu erstellen, die das Beste tut, erstellen Sie einfach viele Bibliotheken.
Daher muss der Programmierer nur die Bibliotheken auswählen, die er wirklich benötigt, und dabei die Funktionen ignorieren, die er nicht verwenden wird. Es werden nicht nur weniger Abhängigkeiten selbst installiert, sondern die verwendeten Bibliotheken weisen auch weniger Abhängigkeiten auf.
Ende von Moores Gesetz
Leider kann die Miniaturisierung von Transistoren nicht ewig dauern und hat ihre physikalischen Grenzen. Vielleicht wird Moores Gesetz früher oder später nicht mehr funktionieren. Einige sagen, dass dies bereits geschehen ist. In den letzten zehn Jahren haben die Taktrate und die Leistung einzelner Prozessorkerne bereits aufgehört, wie früher zu wachsen.
Obwohl es zu früh ist, ihn zu begraben. Es gibt eine Reihe neuer Technologien, die versprechen, die Silizium-Mikroelektronik zu ersetzen. Zum Beispiel experimentieren Intel, Samsung und andere Unternehmen mit Transistoren, die auf Kohlenstoffnanostrukturen (Nanofilamenten) sowie photonischen Chips basieren .

Entwicklung von Transistoren. Abbildung: Samsung
Einige Forscher verfolgen jedoch einen anderen Ansatz. Sie schlagen neue Systemprogrammierungsansätze vor, um die Effizienz zukünftiger Software drastisch zu verbessern. Somit ist es möglich, Moores Gesetz durch Programmmethoden "neu zu starten", egal wie fantastisch es angesichts der Beobachtungen von Nicklaus Wirth über Programmadipositas klingt. Was aber, wenn wir diesen Trend umkehren können?
Software-Beschleunigungstechniken
Kürzlich veröffentlichte Science einen interessanten Artikel von Wissenschaftlern des Labors für Informatik und künstliche Intelligenz des Massachusetts Institute of Technology (CSAIL MIT). Sie heben drei vorrangige Bereiche hervor, um die Berechnung weiter zu beschleunigen:
- die beste Software;
- neue Algorithmen;
- optimierte Hardware.
Der Hauptautor der wissenschaftlichen Arbeit Charles Leiserson bestätigt die Fettleibigkeit der Software-These . Er sagt, die Vorteile der Miniaturisierung von Transistoren seien so groß, dass Programmierer seit Jahrzehnten Prioritäten setzen können, um das Schreiben von Code zu vereinfachen, anstatt die Ausführung zu beschleunigen. Ineffizienz könnte toleriert werden, da schnellere Computerchips immer die Fettleibigkeit von Software ausgleichen.
„Heutzutage erfordern weitere Fortschritte in Bereichen wie maschinelles Lernen, Robotik und virtuelle Realität eine enorme Rechenleistung, die die Miniaturisierung nicht mehr bieten kann“, sagt Leiserson. "Wenn wir das volle Potenzial dieser Technologien nutzen wollen, müssen wir unseren Computeransatz ändern."
Im Softwareteil wird vorgeschlagen, die Strategie der Verwendung von Bibliotheken mit übermäßiger Funktionalität zu überdenken, da dies zu Ineffizienz führt. Die Autoren empfehlen, sich auf die Hauptaufgabe zu konzentrieren - die Geschwindigkeit der Programmausführung zu erhöhen und nicht auf die Geschwindigkeit, mit der Code geschrieben wird.
In vielen Fällen kann die Leistung tatsächlich tausendfach gesteigert werden, und dies ist keine Übertreibung. Als Beispiel führen die Forscher die Multiplikation von zwei 4096 × 4096-Matrizen an. Sie begannen mit der Implementierung in Python als eine der beliebtesten Hochsprachen. Hier ist beispielsweise eine vierzeilige Implementierung in Python 2:
for i in xrange(4096):
for j in xrange(4096):
for k in xrange(4096):
C[i][j] += A[i][k] * B[k][j]Der Code hat drei verschachtelte Schleifen, und der Lösungsalgorithmus basiert auf dem Lehrplan für Schulalgebra.
Es stellt sich jedoch heraus, dass dieser naive Ansatz für die Rechenleistung zu ineffizient ist. Auf einem modernen Computer läuft es ungefähr sieben Stunden, wie in der folgenden Tabelle gezeigt.
| Ausführung | Implementierung | Ausführungszeit (en) | GFLOPS | Absolute Beschleunigung | Relative Beschleunigung | Prozentsatz der Spitzenleistung |
|---|---|---|---|---|---|---|
| 1 | Python | 25552.48 | 0,005 | 1 | - - | 0,00 |
| 2 | Java | 2372,68 | 0,058 | elf | 10.8 | 0,01 |
| 3 | C. | 542,67 | 0,253 | 47 | 4.4 | 0,03 |
| 4 | Parallele Schleifen | 69,80 | 1,97 | 366 | 7.8 | 0,24 |
| fünf | Paradigma teilen und erobern | 3,80 | 36.18 | 6727 | 18.4 | 4.33 |
| 6 | + Vektorisierung | 1.10 | 124,91 | 23224 | 3.5 | 14.96 |
| 7 | + Intristics AVX | 0,41 | 337,81 | 52806 | 2.7 | 40,45 |
Der Wechsel zu einer effizienteren Programmiersprache erhöht die Geschwindigkeit der Codeausführung bereits erheblich. Beispielsweise wird ein Java-Programm 10,8-mal schneller und ein C-Programm 4,4-mal schneller als Java ausgeführt. Der Wechsel von Python zu C bedeutet somit eine 47-mal schnellere Programmausführung.
Und dies ist erst der Anfang der Optimierung. Wenn Sie den Code unter Berücksichtigung der Besonderheiten der Hardware schreiben, auf der er ausgeführt wird, können Sie die Geschwindigkeit um weitere 1300-mal erhöhen. In diesem Experiment wurde der Code zuerst parallel auf allen 18 CPU-Kernen (Version 4) ausgeführt, dann haben wir die Prozessor-Cache-Hierarchie (Version 5) verwendet, die Vektorisierung hinzugefügt (Version 6) und in Version 7 spezifische Anweisungen für Advanced Vector Extensions (AVX) angewendet. Die neueste optimierte Version Der Code dauert nur 0,41 Sekunden, nicht 7 Stunden, dh mehr als 60.000 Mal schneller als der ursprüngliche Python-Code.
Auf einer AMD FirePro S9150-Grafikkarte läuft derselbe Code in nur 70 ms, 5,4-mal schneller als die am besten optimierte Version 7 auf einem Universalprozessor und 360.000-mal schneller als Version 1.
In Bezug auf Algorithmen schlagen die Forscher einen dreigliedrigen Ansatz vor, bei dem neue Problembereiche untersucht, die Algorithmen skaliert und angepasst werden, um die moderne Hardware besser nutzen zu können.
Zum Beispiel beschleunigt Strassens Algorithmus zur Matrixmultiplikation um weitere 10% die schnellste Version von Code Nummer 7. Bei anderen Problemen bieten die neuen Algorithmen noch mehr Leistungsgewinn. Das folgende Diagramm zeigt beispielsweise die Fortschritte bei der Effizienz von Algorithmen zur Lösung des Problems des maximalen Durchflusses zwischen 1975 und 2015. Jeder neue Algorithmus erhöhte die Rechengeschwindigkeit um buchstäblich mehrere Größenordnungen und wurde in den folgenden Jahren weiter optimiert.
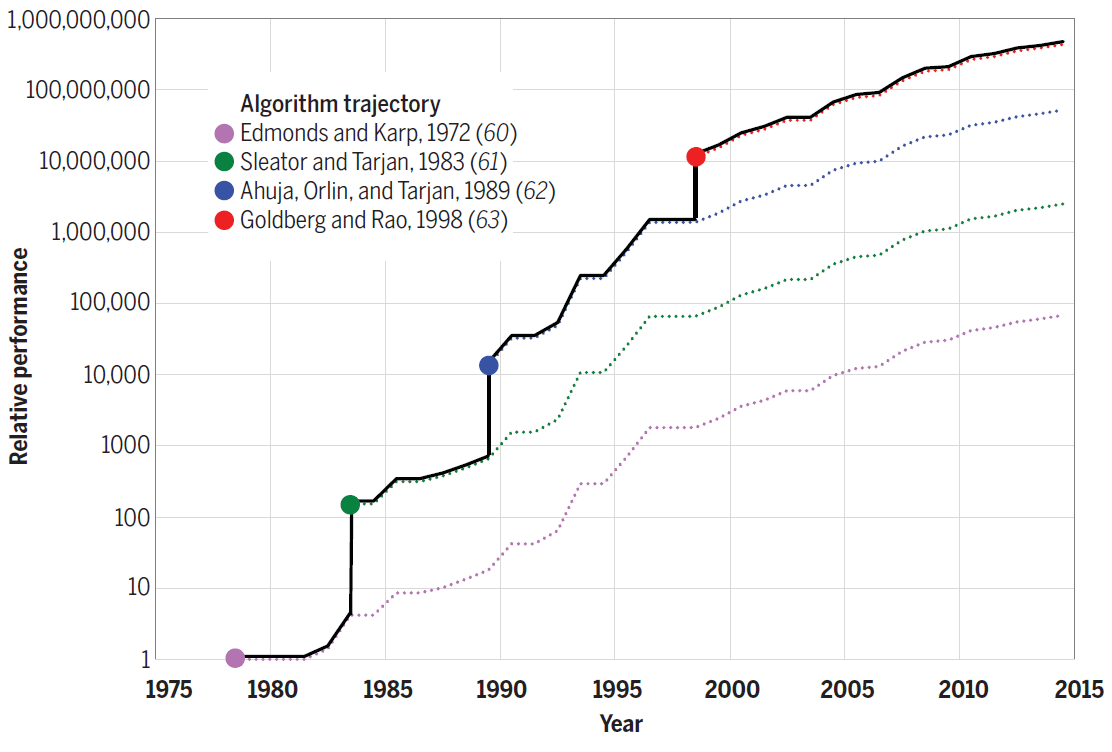
Effizienz von Algorithmen zur Lösung des Problems des maximalen Flusses in einem Graphen mit n = 10 12 Eckpunkten und m = n 11 Kanten
Somit trägt die Verbesserung der Algorithmen auch dazu bei, das Moore'sche Gesetz programmgesteuert zu "emulieren".
In Bezug auf die Hardwarearchitektur befürworten die Forscher schließlich die Optimierung der Hardware, damit Probleme mit weniger Transistoren gelöst werden können. Die Optimierung umfasst die Verwendung einfacherer Prozessoren und die Erstellung von Hardware, die an bestimmte Anwendungen angepasst ist, wie eine GPU für Computergrafiken.
„Geräte, die auf bestimmte Bereiche zugeschnitten sind, können viel effizienter sein und weitaus weniger Transistoren verwenden, sodass Anwendungen zehn- oder hundertmal schneller ausgeführt werden können“, sagt Tao Schardl, Mitautor des Forschungspapiers. "Im Allgemeinen wird die Hardwareoptimierung die parallele Programmierung weiter stimulieren, indem zusätzliche Bereiche auf dem Chip für die parallele Verwendung erstellt werden."
Der Trend zur Parallelisierung ist bereits sichtbar. Wie das Diagramm zeigt, hat sich die CPU-Leistung in den letzten Jahren allein aufgrund der Zunahme der Anzahl der Kerne erhöht.
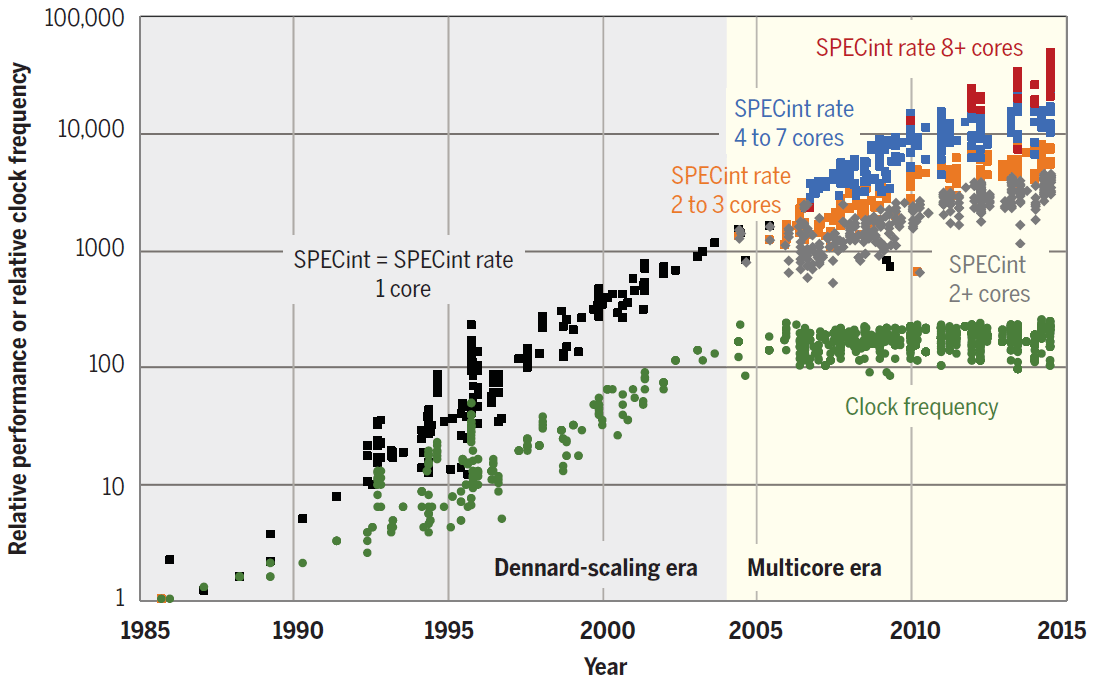
SPECint-Leistung einzelner Kerne sowie Einzel- und Mehrkernprozessoren von 1985 bis 2015. Die Basiseinheit ist ein 1985 80386 DX-Mikroprozessor
Für Rechenzentrumsbetreiber kann selbst die kleinste Verbesserung der Softwareleistung zu großen finanziellen Gewinnen führen. Es überrascht nicht, dass Unternehmen wie Google und Amazon jetzt Initiativen zur Entwicklung eigener spezialisierter CPUs leiten. Die ersten veröffentlichten (neuronalen) TPU- Tensorprozessoren von Google und AWS Graviton- Chips werden in Amazon-Rechenzentren ausgeführt .
Im Laufe der Zeit werden Branchenführer möglicherweise von anderen Eigentümern von Rechenzentren verfolgt, um die Effizienz der Wettbewerber nicht zu beeinträchtigen.
Die Forscher schreiben, dass in der Vergangenheit explosive Leistungssteigerungen bei Allzweckprozessoren den Entwicklungsspielraum für Spezialprozessoren eingeschränkt haben. Jetzt gibt es keine solche Einschränkung.
"Produktivitätssteigerungen erfordern neue Tools, Programmiersprachen und Hardware, um ein effizienteres Design mit Blick auf die Geschwindigkeit zu ermöglichen", sagte Professor Charles Leiserson, Co-Autor der Forschung. "Es bedeutet auch, dass Programmierer besser verstehen müssen, wie Software, Algorithmen und Hardware zusammenpassen, anstatt sie isoliert zu betrachten."
Auf der anderen Seite experimentieren Ingenieure mit Technologien, die die CPU-Leistung weiter steigern können. Dies sind Quantencomputer, 3D-Layout, supraleitende Mikroschaltungen, neuromorphes Computing, die Verwendung von Graphen anstelle von Silizium usw. Bisher befinden sich diese Technologien jedoch im Stadium der Experimente.
Wenn die CPU-Leistung wirklich nicht mehr wächst, befinden wir uns in einer völlig anderen Realität. Vielleicht müssen wir unsere Programmierprioritäten wirklich überdenken, und Assembler-Spezialisten sind Gold wert.
Werbung
Benötigen Sie einen leistungsstarken Server ? Unser Unternehmen bietet epische Server an - virtuelle Server mit AMD EPYC-CPU und einer CPU-Kernfrequenz von bis zu 3,4 GHz. Die maximale Konfiguration wird jeden beeindrucken - 128 CPU-Kerne, 512 GB RAM, 4000 GB NVMe.
