
In diesem Artikel werden die Implementierungsdetails und der Betrieb verschiedener JIT-Compiler sowie Optimierungsstrategien erläutert. Wir werden ausreichend detailliert diskutieren, aber wir werden viele wichtige Konzepte weglassen. Das heißt, dieser Artikel enthält nicht genügend Informationen , um bei einem Vergleich von Implementierungen und Sprachen zu vernünftigen Schlussfolgerungen zu gelangen.
Lesen Sie diesen Artikel, um ein grundlegendes Verständnis der JIT-Compiler zu erhalten .
Ein kleiner Hinweis:
, , , - . , JIT ( ), , . , , , , . - , , .
- Pypy
- GraalVM C
- OSR
- JIT
()
LuaJIT verwendet das sogenannte Tracing. Pypy führt Metatracing durch, dh es verwendet das System, um Trace- und JIT-Interpreter zu generieren. Pypy und LuaJIT sind keine beispielhaften Python- und Lua-Implementierungen, sondern eigenständige Projekte. Ich würde LuaJIT als schockierend schnell charakterisieren und es beschreibt sich selbst als eine der schnellsten dynamischen Sprachimplementierungen - und das glaube ich absolut.
Um zu verstehen, wann mit der Ablaufverfolgung begonnen werden soll, sucht die Interpreter-Schleife nach Hot-Loops (das Konzept des Hot-Codes ist für alle JIT-Compiler universell!). Der Compiler "verfolgt" dann die Schleife und zeichnet ausführbare Operationen auf, um gut optimierten Maschinencode zu kompilieren. In LuaJIT basiert die Kompilierung auf Spuren mit einer anweisungsähnlichen Zwischendarstellung, die nur in LuaJIT verfügbar ist.
Wie die Ablaufverfolgung in Pypy implementiert wird
Pypy beginnt nach 1619 Ausführungen mit der Verfolgung der Funktion und kompiliert nach 1039 Ausführungen. Das heißt, es dauert ungefähr 3000 Ausführungen der Funktion, bis sie schneller funktioniert. Diese Werte wurden vom Pypy-Team sorgfältig ausgewählt, und im Allgemeinen werden in der Welt der Compiler viele Konstanten sorgfältig ausgewählt.
Dynamische Sprachen erschweren die Optimierung. Der folgende Code kann statisch in einer strengeren Sprache entfernt werden, da er
Falseimmer falsch ist. In Python 2 kann dies jedoch erst zur Laufzeit garantiert werden.
if False:
print("FALSE")
Für jedes intelligente Programm ist diese Bedingung immer falsch. Leider kann der Wert
Falseneu definiert werden und der Ausdruck befindet sich in einer Schleife. Er kann an einer anderen Stelle neu definiert werden. Daher kann Pypy eine "Wache" erstellen. Wenn der Verteidiger ausfällt, greift JIT auf die Interpretationsschleife zurück. Pypy verwendet dann eine andere Konstante (200), die als Trace-Eifer bezeichnet wird , um zu entscheiden, ob der Rest des neuen Pfads vor dem Ende der Schleife kompiliert werden soll. Dieser Unterpfad wird als Brücke bezeichnet .
Darüber hinaus stellt Pypy diese Konstanten als Argumente zur Verfügung, die Sie zur Laufzeit zusammen mit der Abrollkonfiguration, d. H. Schleifenerweiterung und Inlining, anpassen können! Darüber hinaus bietet es Hooks, die wir nach Abschluss der Kompilierung sehen können.
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
Oben habe ich ein reines Python-Programm mit einem Kompilierungs-Hook geschrieben, um die Art der angewendeten Kompilierung anzuzeigen. Der Code gibt am Ende auch Daten aus, die die Anzahl der Verteidiger anzeigen. Für dieses Programm habe ich eine Loop-Zusammenstellung und 66 Verteidiger bekommen. Als ich den Ausdruck durch einen
ifeinfachen Out-of-Loop-Pass ersetzte for, waren nur noch 59 Verteidiger übrig.
for i in range(10000):
pass # removing the `if False` saved 7 guards!
Durch Hinzufügen dieser beiden Zeilen zur Schleife
forerhielt ich zwei Zusammenstellungen, von denen eine vom Typ "Brücke" war!
if random.randint(1, 100) < 20:
False = True
Warten Sie, Sie haben über Metatracing gesprochen!
Die Idee des Metatracing kann beschrieben werden als "Schreiben Sie einen Interpreter und erhalten Sie einen Compiler kostenlos!" Oder "Verwandeln Sie Ihren Interpreter in einen JIT-Compiler!" Das Schreiben eines Compilers ist schwierig, und wenn Sie ihn kostenlos erhalten können, ist die Idee cool. Pypy "enthält" einen Interpreter und einen Compiler, implementiert jedoch keinen herkömmlichen Compiler explizit.
Pypy verfügt über ein RPython-Tool (für Pypy entwickelt). Es ist ein Rahmen für das Schreiben von Dolmetschern. Seine Sprache ist eine Art Python und statisch typisiert. In dieser Sprache müssen Sie einen Dolmetscher schreiben. Die Sprache ist nicht für die typisierte Python-Programmierung konzipiert, da sie keine Standardbibliotheken oder -pakete enthält. Jedes RPython-Programm ist ein gültiges Python-Programm. RPython-Code wird nach C transpiliert und dann kompiliert. Somit existiert ein Meta-Compiler in dieser Sprache als kompiliertes C-Programm.
Das Präfix "meta" in metatrace bedeutet, dass die Ablaufverfolgung erfolgt, wenn der Interpreter ausgeführt wird, nicht das Programm. Es verhält sich mehr oder weniger wie jeder andere Interpreter, kann jedoch seine Operationen verfolgen und optimiert die Ablaufverfolgung durch Aktualisierung seines Pfads. Mit der weiteren Verfolgung wird der Interpreterpfad optimiert. Ein gut optimierter Interpreter folgt einem bestimmten Pfad. Der in diesem Pfad verwendete Maschinencode, der durch Kompilieren von RPython erhalten wird, kann für die endgültige Kompilierung verwendet werden.
Kurz gesagt, der "Compiler" in Pypy kompiliert Ihren Interpreter, weshalb Pypy manchmal als Meta-Compiler bezeichnet wird. Das von Ihnen ausgeführte Programm wird weniger kompiliert als der Pfad eines optimierten Interpreters.
Das Konzept des Metatracing mag verwirrend erscheinen, daher habe ich zu Illustrationszwecken ein sehr schlechtes Programm geschrieben, das nur
a = 0und versteht a++to.
# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
Wenn ich diesen heißen Zyklus durchführe:
a = 0
a++
a++
Die Tracks könnten folgendermaßen aussehen:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
Der Compiler ist jedoch kein spezielles separates Modul, sondern in den Interpreter integriert. Daher sieht der Interpretationszyklus folgendermaßen aus:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
Einführung in die JVM
Ich habe vier Monate lang in der auf Graal basierenden TruffleRuby- Sprache geschrieben und mich in sie verliebt.
Hotspot (so genannt, weil es nach Hotspots sucht ) ist eine virtuelle Maschine, die mit Standard-Java-Installationen geliefert wird. Es enthält mehrere Compiler zum Implementieren der gestuften Kompilierung. Die 250.000-Zeilen-Codebasis von Hotspot ist offen und verfügt über drei Garbage Collectors. Dev kommt mit der JIT-Kompilierung zurecht, in einigen Benchmarks funktioniert sie besser als C ++ - (diesmal als
Die in Hotspot verwendeten Strategien haben viele Autoren nachfolgender JIT-Compiler, Frameworks für virtuelle Sprachmaschinen und insbesondere Javascript-Engines inspiriert. Hotspot brachte auch eine Welle von JVM-Sprachen wie Scala, Kotlin, JRuby und Jython hervor. JRuby und Jython sind unterhaltsame Ruby- und Python-Implementierungen, die Quellcode zu JVM-Bytecode kompilieren, den Hotspot dann ausführt. Alle diese Projekte sind relativ erfolgreich darin, die Sprachen Python und Ruby (Ruby mehr als Python) zu beschleunigen, ohne alle Tools zu implementieren, wie dies bei Pypy der Fall ist. Hotspot ist auch insofern einzigartig, als es sich um eine JIT für weniger dynamische Sprachen handelt (obwohl es sich technisch gesehen um eine JIT für JVM-Bytecode handelt, nicht um Java).

GraalVM ist eine JavaVM mit einem Java-Code. Es kann jede JVM-Sprache ausführen (Java, Scala, Kotlin usw.). Es unterstützt auch Native Image, um mit AOT-kompiliertem Code über die Substrate VM zu arbeiten. Ein erheblicher Teil der Scala-Dienste von Twitter läuft auf Graal, was von der Qualität der virtuellen Maschine spricht. In mancher Hinsicht ist sie besser als die JVM, obwohl sie in Java geschrieben ist.
Und das ist noch nicht alles! GraalVM bietet auch Truffle: ein Framework zum Implementieren von Sprachen durch Erstellen von AST-Interpreten (Abstract Syntax Tree). Es gibt keinen expliziten Schritt in Truffle, wenn der JVM-Bytecode wie in einer regulären JVM-Sprache generiert wird. Vielmehr verwendet Truffle einfach den Interpreter und spricht mit Graal, um Maschinencode direkt mit Profiling und sogenannter Teilbewertung zu generieren. Eine teilweise Bewertung würde den Rahmen dieses Artikels sprengen: Kurz gesagt: Diese Methode entspricht der Philosophie des Metatrackings: "Schreiben Sie einen Interpreter, erhalten Sie einen Compiler kostenlos!".
TruffleJS — Truffle- Javascript, V8 , , V8 , Google , . TruffleJS «» V8 ( JS-) , Graal.
JIT-
C
JIT-Implementierungen haben häufig Probleme bei der Unterstützung von C-Erweiterungen. Standardinterpreter wie Lua, Python, Ruby und PHP verfügen über eine API für C, mit der Benutzer Pakete in dieser Sprache erstellen können, was die Ausführung erheblich beschleunigt. Viele Pakete sind in C geschrieben, zum Beispiel numpy, Standardbibliotheksfunktionen wie
rand. Alle diese C-Erweiterungen sind wichtig, damit eine interpretierte Sprache schnell ausgeführt werden kann.
C-Erweiterungen sind aus mehreren Gründen schwierig zu warten. Der offensichtlichste Grund ist, dass die API unter Berücksichtigung der internen Implementierung entwickelt wurde. Darüber hinaus ist es einfacher, C-Erweiterungen zu unterstützen, wenn der Interpreter in C geschrieben ist. Daher kann JRuby keine C-Erweiterungen unterstützen, verfügt jedoch über eine API für Java-Erweiterungen. Pypy hat kürzlich eine Beta-Version der Unterstützung für C-Erweiterungen veröffentlicht, obwohl ich nicht sicher bin, ob dies aufgrund des Hyrum-Gesetzes funktioniert . LuaJIT unterstützt C-Erweiterungen, einschließlich zusätzlicher Funktionen in seinen C-Erweiterungen (LuaJIT ist einfach fantastisch!)
Graal löst dieses Problem mit Sulong, einer Engine, die LLVM-Bytecode auf GraalVM ausführt und in Trüffel konvertiert. LLVM ist eine Toolbox, und wir müssen nur wissen, dass C zu LLVM-Bytecode kompiliert werden kann (Julia hat auch ein LLVM-Backend!). Es ist seltsam, aber die Lösung besteht darin, eine gut kompilierte Sprache mit über vierzigjähriger Geschichte zu interpretieren! Natürlich läuft es nicht annähernd so schnell wie ordnungsgemäß kompiliertes C, bietet jedoch mehrere Vorteile.
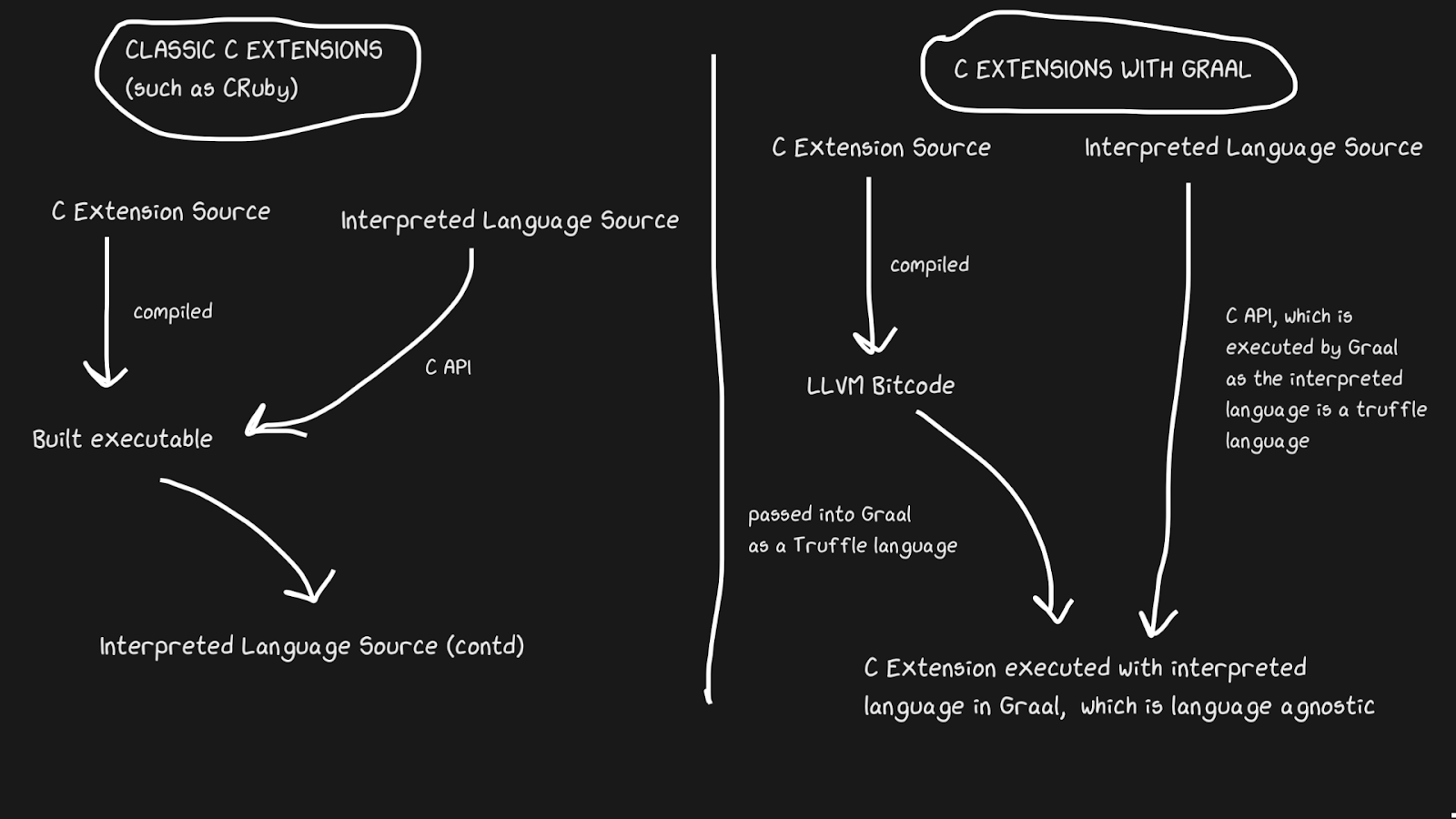
Der LLVM-Bytecode ist bereits recht niedrig, das heißt, es ist nicht so ineffizient, JIT auf diese Zwischendarstellung anzuwenden wie auf C. Ein Teil der Kosten wird durch die Tatsache kompensiert, dass der Bytecode zusammen mit dem Rest des Ruby-Programms optimiert werden kann, das kompilierte C-Programm jedoch nicht optimiert werden kann ... Alle diese Speicherstreifen, Inlining, Dead Chunks und mehr können auf C- und Ruby-Code angewendet werden, anstatt die C-Binärdatei aus Ruby-Code aufzurufen. TruffleRuby C-Erweiterungen sind in mancher Hinsicht schneller als CRuby C-Erweiterungen.
Damit dieses System funktioniert, müssen Sie wissen, dass Truffle vollständig sprachunabhängig ist und der Aufwand für den Wechsel zwischen C, Java oder einer anderen Sprache in Graal minimal ist.
Die Fähigkeit von Graal, mit Sulong zu arbeiten, ist Teil ihrer polyglotten Fähigkeiten, die eine hohe Austauschbarkeit der Sprache ermöglichen. Dies ist nicht nur gut für den Compiler, sondern beweist auch, dass Sie problemlos mehrere Sprachen in einer "Anwendung" verwenden können.
Zurück zum interpretierten Code ist es schneller
Wir wissen, dass JITs einen Interpreter und einen Compiler enthalten und dass sie von Interpreter zu Compiler wechseln, um die Dinge zu beschleunigen. Pypy erstellt Brücken für den Rückweg, obwohl dies aus Sicht von Graal und Hotspot eine De-Optimierung ist . Wir sprechen nicht von völlig anderen Konzepten, aber mit Deoptimierung meinen wir eine Rückkehr zum Interpreten als bewusste Optimierung und keine Lösung für die Unvermeidlichkeit einer dynamischen Sprache. Hotspot und Graal nutzen die De-Optimierung stark, insbesondere Graal, da Entwickler die Kompilierung streng kontrollieren und für Optimierungen noch mehr Kontrolle über die Kompilierung benötigen (im Vergleich zu beispielsweise Pypy). Deoptimierung wird auch in JS-Engines verwendet, über die ich viel sprechen werde, da JavaScript in Chrome und Node.js davon abhängt.
Um die De-Optimierung schnell anzuwenden, ist es wichtig, dass Sie so schnell wie möglich zwischen Compiler und Interpreter wechseln. Bei der naivsten Implementierung muss der Interpreter den Compiler „einholen“, um die Deoptimierung durchzuführen. Zusätzliche Komplikationen sind mit der Deoptimierung von asynchronen Streams verbunden. Graal erstellt eine Reihe von Frames und vergleicht sie mit dem generierten Code, um zum Interpreter zurückzukehren. Mit Sicherheitspunkten können Sie einen Java-Thread pausieren lassen und sagen: "Hallo, Garbage Collector, muss ich aufhören?" Damit die Thread-Verarbeitung nicht viel Overhead erfordert. Es stellte sich als ziemlich grob heraus, aber es funktioniert schnell genug, damit die Deoptimierung eine gute Strategie ist.
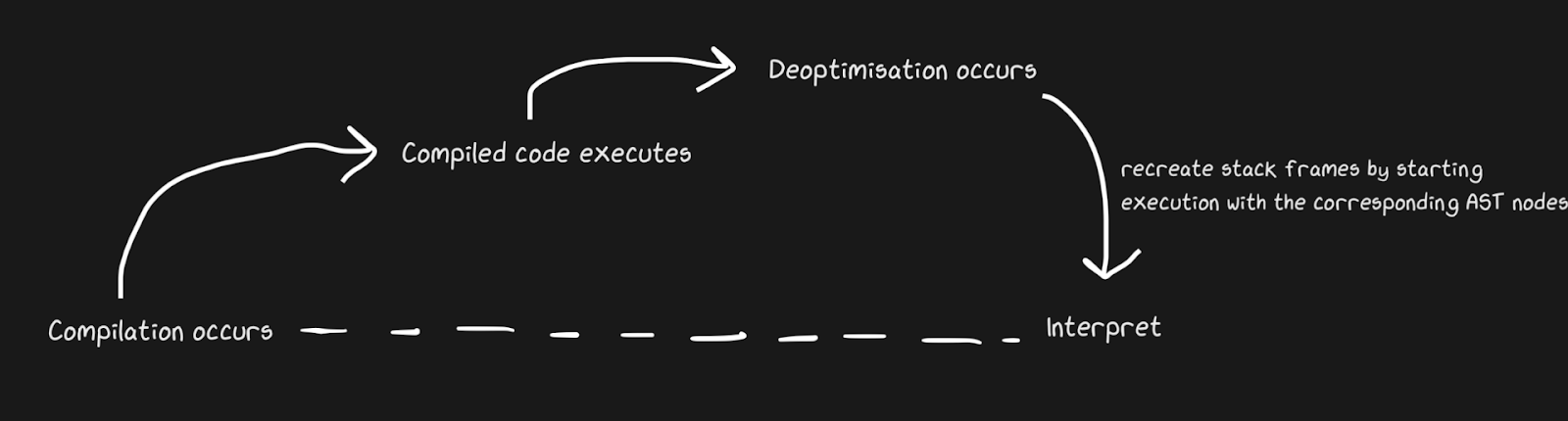
Ähnlich wie beim Pypy-Bridging-Beispiel kann auch das Affen-Patching von Funktionen deoptimiert werden. Es ist eleganter, weil wir De-Optimierungs-Code nicht hinzufügen, wenn der Verteidiger ausfällt, sondern wenn Guerilla-Patches angewendet werden.
Ein gutes Beispiel für die JIT-Deoptimierung: Der Conversion-Überlauf ist ein inoffizieller Begriff. Es handelt sich um eine Situation, in der ein bestimmter Typ (z. B.
int32) intern dargestellt / zugewiesen wird , in den jedoch konvertiert werden muss int64. TruffleRuby macht dies mit De-Optimierungen, genau wie der V8.
Sagen Sie, wenn Sie in Ruby fragen
var = 0, erhalten Sie int32(Ruby nennt es Fixnumund Bignum, aber ich werde die Notation int32und verwenden int64). Durchführen einer Operation mitvarmüssen Sie überprüfen, ob ein Wertüberlauf auftritt. Es ist jedoch eine Sache zu überprüfen, und das Kompilieren von Code, der Überläufe behandelt, ist teuer, insbesondere angesichts der Häufigkeit numerischer Operationen.
Ohne die kompilierten Anweisungen zu lesen, können Sie sehen, wie diese De-Optimierung die Codemenge reduziert.
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
In TruffleRuby wird nur der erste Lauf einer bestimmten Operation deoptimiert, sodass wir nicht jedes Mal Ressourcen verschwenden, wenn eine Operation überläuft.
WET-Code ist schneller Code. Inlining und OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
Selbst Trivialitäten wie diese Trigger werden in V8 deoptimiert! Mit Optionen wie
--trace-deoptund können --trace-optSie viele Informationen über die JIT sammeln und auch das Verhalten ändern. Graal hat einige sehr nützliche Tools, aber ich werde V8 verwenden, da viele es installiert haben.
Die Deoptimierung wird durch die letzte Zeile (
foo(1, 2)) gestartet , was rätselhaft ist, da dieser Aufruf in der Schleife erfolgte! Wir erhalten die Meldung "Unzureichendes Feedback vom Typ für einen Anruf" (die vollständige Liste der Gründe für die De-Optimierung finden Sie hier , und es gibt einen lustigen Grund für "keinen Grund"). Dadurch wird ein Eingaberahmen erstellt, in dem die Literale 1und angezeigt werden 2.
Warum also de-optimieren? V8 ist klug genug, um Typografie zu machen: wenn es
iTyp istintegerAuch Literale werden weitergegeben integer.
Um dies zu verstehen, ersetzen wir die letzte Zeile durch
foo(i, i +1). Die De-Optimierung wird jedoch weiterhin angewendet, nur dass diesmal die Meldung anders lautet: "Unzureichende Typrückmeldung für den binären Betrieb". WARUM?! Immerhin ist dies genau die gleiche Operation, die in einer Schleife mit den gleichen Variablen ausgeführt wird!
Die Antwort, mein Freund, liegt im On-Stack-Ersatz (OSR). Inlining ist eine leistungsstarke Compiler-Optimierung (nicht nur JIT), bei der Funktionen keine Funktionen mehr sind und Inhalte an den Ort der Aufrufe übergeben werden. JIT-Compiler können inline arbeiten, um die Geschwindigkeit zu erhöhen, indem sie den Code zur Laufzeit ändern (kompilierte Sprachen können nur statisch inline).
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
V8 kompiliert also
foo, stellt fest, dass es inline und inline mit OSR sein kann. Die Engine führt dies jedoch nur für den Code in der Schleife aus, da dies ein heißer Pfad ist und die letzte Zeile zum Zeitpunkt des Inlining noch nicht im Interpreter enthalten ist. Daher hat V8 noch nicht genügend Feedback zum Typ der Funktion foo, da es nicht in der Schleife verwendet wird, sondern in der Inline-Version. Wenn angewendet --no-use-osr, gibt es keine Deoptimierung, unabhängig davon, ob wir wörtlich oder wörtlich übergeben i. Ohne Inlining werden jedoch selbst eine winzige Million Iterationen merklich langsamer ausgeführt. JIT-Compiler verkörpern wirklich das No-Solution-Only-Trade-Off-Prinzip. Deoptimierungen sind teuer, aber nicht vergleichbar mit den Kosten für das Auffinden von Methoden und Inlining, die in diesem Fall bevorzugt werden.
Inlining ist unglaublich effektiv! Ich habe den obigen Code mit ein paar zusätzlichen Nullen ausgeführt und er lief viermal langsamer, wenn Inlining deaktiviert war.

Obwohl es in diesem Artikel um JIT geht, ist Inlining auch in kompilierten Sprachen wirksam. Alle LLVM-Sprachen verwenden aktiv Inlining, da LLVM dies auch tun wird. Obwohl Julia ohne LLVM inline ist, liegt dies in ihrer Natur. JITs können mithilfe von Laufzeitheuristiken inliniert werden und mithilfe von OSR zwischen Nicht-Inlining- und Inlining-Modus wechseln.
Ein Hinweis zu JIT und LLVM
LLVM bietet eine Reihe kompilierungsbezogener Tools. Julia arbeitet mit LLVM (beachten Sie, dass dies eine große Toolbox ist und jede Sprache sie anders verwendet), genau wie Rust, Swift und Crystal. Es genügt zu sagen, dass dies ein großes und wunderbares Projekt ist, das auch JITs unterstützt, obwohl LLVM keine signifikanten integrierten dynamischen JITs hat. Die vierte Stufe der JavaScriptCore-Kompilierung verwendete das LLVM-Backend für eine Weile, wurde jedoch vor weniger als zwei Jahren ersetzt. Seitdem ist dieses Toolkit für dynamische JITs nicht sehr gut geeignet, hauptsächlich weil es nicht für die Arbeit in einer dynamischen Umgebung ausgelegt ist. Pypy versuchte es 5-6 Mal, entschied sich aber für JSC. Mit LLVM waren Zuordnungssenkung und Codebewegung begrenzt.Es war auch unmöglich, leistungsstarke JIT-Funktionen wie Range-Inferencing zu verwenden (es ist wie Casting, aber mit einem bekannten Wertebereich). Noch wichtiger ist jedoch, dass mit LLVM viele Ressourcen für das Kompilieren aufgewendet werden.
Was ist, wenn wir anstelle einer befehlsbasierten Zwischendarstellung ein großes Diagramm haben, das sich selbst ändert?
Wir haben über LLVM-Bytecode und Python / Ruby / Java-Bytecode als Zwischendarstellung gesprochen. Sie sehen alle aus wie eine Sprache in Form von Anweisungen. Hotspot, Graal und V8 verwenden die Zwischendarstellung "Sea of Nodes" (eingeführt in Hotspot), bei der es sich um einen untergeordneten AST handelt. Dies ist eine effektive Ansicht, da ein wesentlicher Teil der Profilerstellung auf der Vorstellung eines bestimmten Pfads basiert, der selten verwendet wird (oder sich bei einigen Mustern überschneidet). Beachten Sie, dass sich diese AST-Compiler von den AST-Parsern unterscheiden.
Normalerweise halte ich mich an die Position „versuche es zu Hause zu machen!“, Aber es ist ziemlich schwierig, Diagramme zu betrachten, obwohl sie sehr interessant und oft äußerst nützlich sind, um die Arbeit des Compilers zu verstehen. Zum Beispiel kann ich nicht alle Grafiken lesen, nicht nur wegen mangelnden Wissens, sondern auch wegen der Rechenfähigkeiten meines Gehirns (Compileroptionen können helfen, Verhalten loszuwerden, an dem ich nicht interessiert bin).
Im Fall des V8 verwenden wir das D8-Tool mit einem Flag
--print-ast. Für Graal wird es sein --vm.Dgraal.Dump=Truffle:2. Der Text wird auf dem Bildschirm angezeigt (formatiert, um ein Diagramm zu erhalten). Ich weiß nicht, wie die V8-Entwickler visuelle Grafiken erstellen, aber Oracle verfügt über einen "Ideal Graph Visualizer", der in der vorherigen Abbildung verwendet wird. Ich hatte nicht die Kraft, IGV neu zu installieren, also habe ich die Grafiken von Chris Seaton übernommen, die mit Seafoam erstellt wurden, dessen Quelle jetzt geschlossen ist.
Okay, schauen wir uns das JavaScript AST an!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
Ich habe diesen Code durchlaufen
d8 --print-ast test.js, obwohl wir nur an der Funktion interessiert sind accumulate. Sehen Sie, dass ich es nur einmal aufgerufen habe, das heißt, ich muss nicht auf die Kompilierung warten, um den AST zu erhalten.
So sieht der AST aus (ich habe einige unwichtige Zeilen entfernt):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
Es ist schwierig, dies zu analysieren, aber es ähnelt dem AST des Parsers (gilt nicht für alle Programme). Und der nächste AST wird mit Acorn.js generiert.
Ein bemerkenswerter Unterschied ist die Definition von Variablen. Im AST des Parsers gibt es keine explizite Definition von Parametern, und die Schleifendeklaration ist im Knoten ausgeblendet
ForStatement. In einem AST auf Compilerebene werden alle Deklarationen mit Adressen und Metadaten gruppiert.
Der Compiler AST verwendet auch diesen dummen Ausdruck
VAR PROXY. Der AST des Parsers kann die Beziehung zwischen Namen und Variablen (nach Adressen) nicht bestimmen, da Variablen (Heben), Auswerten (Auswerten) und andere angehoben werden. Der AST des Compilers verwendet also Variablen PROXY, die später der tatsächlichen Variablen zugeordnet werden.
// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
Und so sieht der AST desselben Programms aus, der mit Graal erhalten wurde!
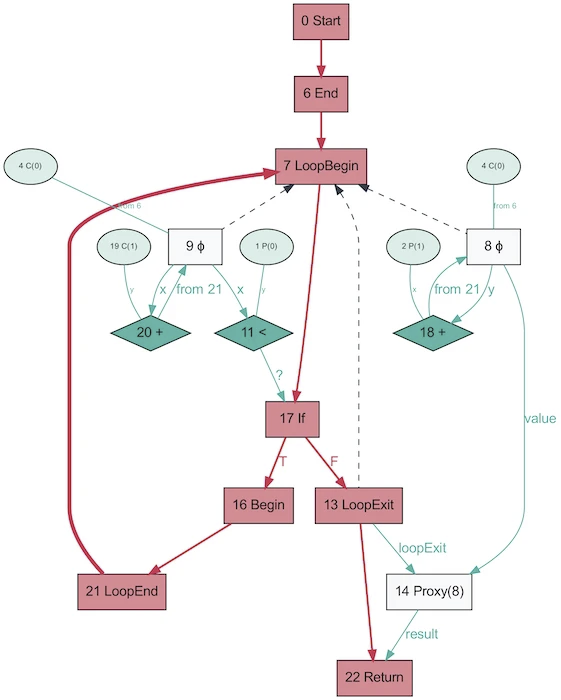
Es sieht viel einfacher aus. Rot zeigt den Kontrollfluss an, Blau zeigt den Datenfluss an, Pfeile zeigen Richtungen an. Beachten Sie, dass dieses Diagramm zwar einfacher als das AST von V8 ist, dies jedoch nicht bedeutet, dass Graal das Programm besser vereinfacht hat. Es wird nur auf Basis von Java generiert, das viel weniger dynamisch ist. Das gleiche von Ruby generierte Graal-Diagramm ist näher an der ersten Version.
Es ist lustig, dass sich AST in Graal abhängig von der Ausführung des Codes ändert. Dieses Diagramm wird mit deaktiviertem OSR und Inlining generiert, wenn die Funktion wiederholt mit zufälligen Parametern aufgerufen wird, damit sie nicht optimiert wird. Und der Dump liefert Ihnen eine ganze Reihe von Grafiken! Graal verwendet einen speziellen AST, um Programme zu optimieren (V8 führt ähnliche Optimierungen durch, jedoch nicht auf AST-Ebene). Wenn Sie Diagramme in Graal speichern, erhalten Sie mehr als zehn Schemata mit unterschiedlichen Optimierungsstufen. Beim Umschreiben von Knoten ersetzen sie sich durch andere Knoten.
Das obige Diagramm ist ein hervorragendes Beispiel für die Spezialisierung auf eine dynamisch typisierte Sprache (Bild von einer VM zu Rule Them All, 2013). Der Grund, warum dieser Prozess existiert, hängt eng mit der Funktionsweise der Teilbewertung zusammen - es geht nur um Spezialisierung.
Hurra JIT hat den Code kompiliert! Lassen Sie uns noch einmal kompilieren! Und wieder!
Oben habe ich über "Mehrebenen" gesprochen, lassen Sie uns darüber sprechen. Die Idee ist einfach: Wenn wir noch nicht bereit sind, vollständig optimierten Code zu erstellen, die Interpretation jedoch immer noch teuer ist, können wir sie vorkompilieren und dann endgültig kompilieren, wenn wir bereit sind, optimierten Code zu generieren.
Hotspot ist eine geschichtete JIT mit zwei Compilern, C1 und C2. C1 führt eine schnelle Kompilierung durch, führt den Code aus und führt dann eine vollständige Profilerstellung durch, um den mit C2 kompilierten Code zu erhalten. Dies kann helfen, viele Aufwärmprobleme zu lösen. Nicht optimierter kompilierter Code ist ohnehin schneller als die Interpretation. Außerdem kompilieren C1 und C2 nicht den gesamten Code. Wenn die Funktion einfach genug aussieht, hilft uns C2 mit hoher Wahrscheinlichkeit nicht und läuft nicht einmal (wir sparen auch Zeit bei der Profilerstellung!). Wenn C1 mit dem Kompilieren beschäftigt ist, kann die Profilerstellung fortgesetzt werden, die Arbeit von C1 wird unterbrochen und die Kompilierung mit C2 beginnt.
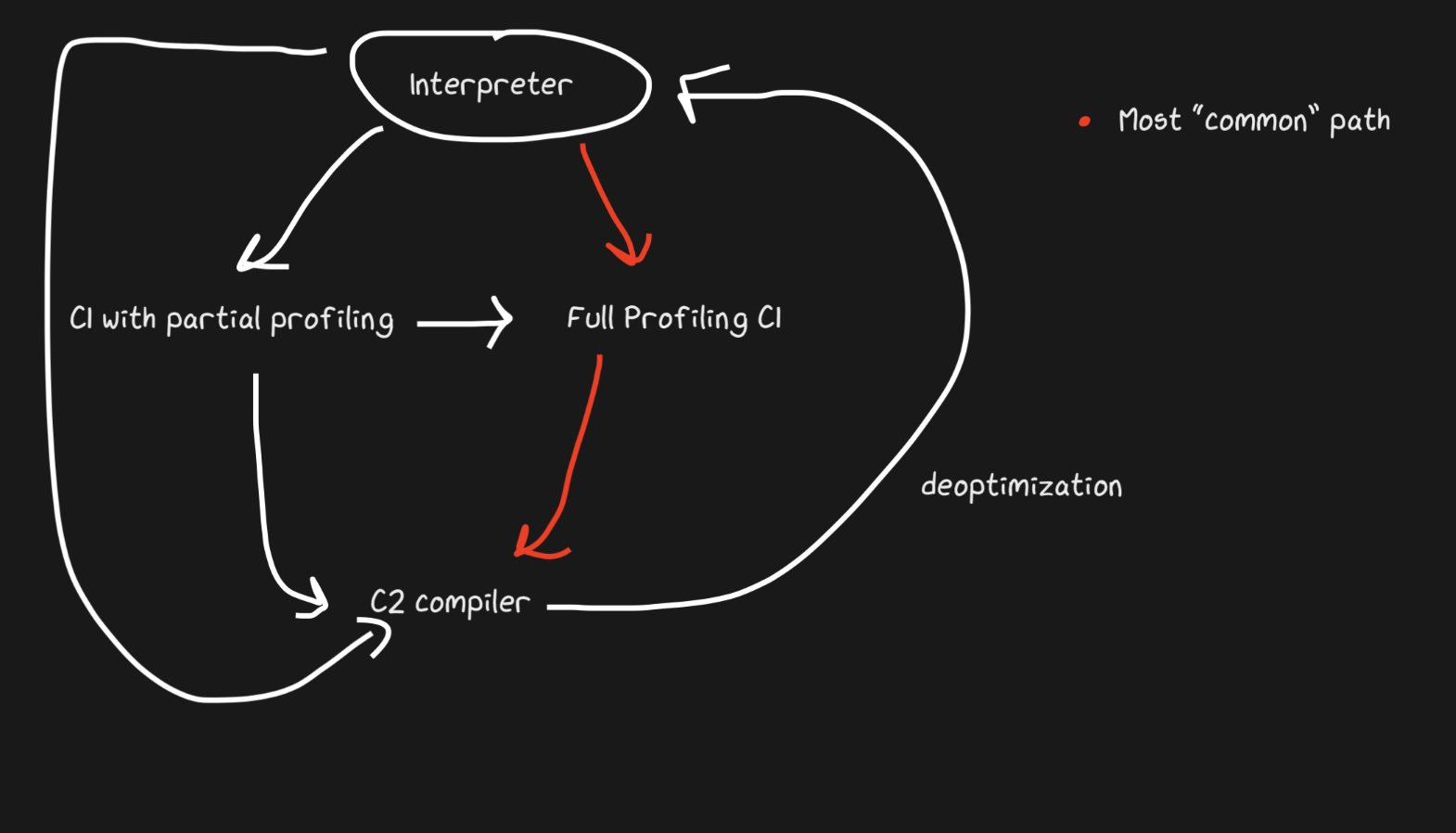
JavaScript Core hat noch mehr Ebenen! Tatsächlich gibt es drei JITs . Der JSC-Interpreter führt einige Lichtprofile durch, wechselt dann zur Baseline-JIT, dann zur DFG-JIT (Data Flow Graph) und schließlich zur FTL-JIT (Faster than Light). Bei so vielen Ebenen beschränkt sich die Bedeutung der De-Optimierung nicht mehr auf den Übergang vom Compiler zum Interpreter. Die De-Optimierung kann beginnend mit der DFG und endend mit der Baseline-JIT durchgeführt werden (dies ist im Fall von Hotspot C2-> C1 nicht der Fall). Alle De-Optimierungen und Übergänge zur nächsten Ebene werden mit OSR (Stack Override) durchgeführt.
Die Baseline-JIT stellt nach ca. 100 Ausführungen eine Verbindung her und die DFG-JIT nach ca. 1000 (mit einigen Ausnahmen). Dies bedeutet, dass die JIT den kompilierten Code viel schneller erhält als derselbe Pypy (der ungefähr 3000 Ausführungen benötigt). Durch Layering kann die JIT versuchen, die Dauer der Codeausführung mit der Dauer ihrer Optimierung zu korrelieren. Es gibt eine Reihe von Tricks, welche Art von Optimierung (Inlining, Casting usw.) auf den einzelnen Ebenen durchgeführt werden soll. Daher ist diese Strategie optimal.
Hilfreiche Quellen
- Wie der Trace Compiler von LuaJIT funktioniert von Mike Pall
- Einfluss von Meta-Tracing auf VMs von Laurie Tratt
- Pypy Escape Analyse
- Warum Benutzer mit VMs von Laurie Tratt nicht zufriedener sind
- Über JS-Engines:
- Über Deoptimierung:
- Graal:
- :
- :