Vorteile der Verwendung von TensorFlow.js in einem Browser
- Interaktivität - Der Browser verfügt über zahlreiche Tools zur Visualisierung der laufenden Prozesse (Grafiken, Animationen usw.).
- Sensoren - Der Browser hat direkten Zugriff auf die Sensoren des Geräts (Kamera, GPS, Beschleunigungsmesser usw.).
- Sicherheit von Benutzerdaten - Es ist nicht erforderlich, verarbeitete Daten an den Server zu senden.
- Kompatibilität mit in Python erstellten Modellen .
Performance
Eines der Hauptprobleme ist die Leistung.
Aufgrund der Tatsache, dass maschinelles Lernen tatsächlich verschiedene Arten von mathematischen Operationen mit matrixartigen Daten (Tensoren) ausführt, verwendet die Bibliothek für diese Art von Berechnungen im Browser WebGL. Dies verbessert die Leistung erheblich, wenn dieselben Vorgänge in reinem JS ausgeführt wurden. Natürlich hat die Bibliothek einen Fallback, falls WebGL aus irgendeinem Grund im Browser nicht unterstützt wird (zum Zeitpunkt dieses Schreibens zeigt caniuse , dass 97,94% der Benutzer WebGL-Unterstützung haben).
Um die Leistung zu verbessern, verwendet Node.js native Bindung mit TensorFlow. Hier können CPU, GPU und TPU ( Tensor Processing Unit ) als Beschleuniger dienen
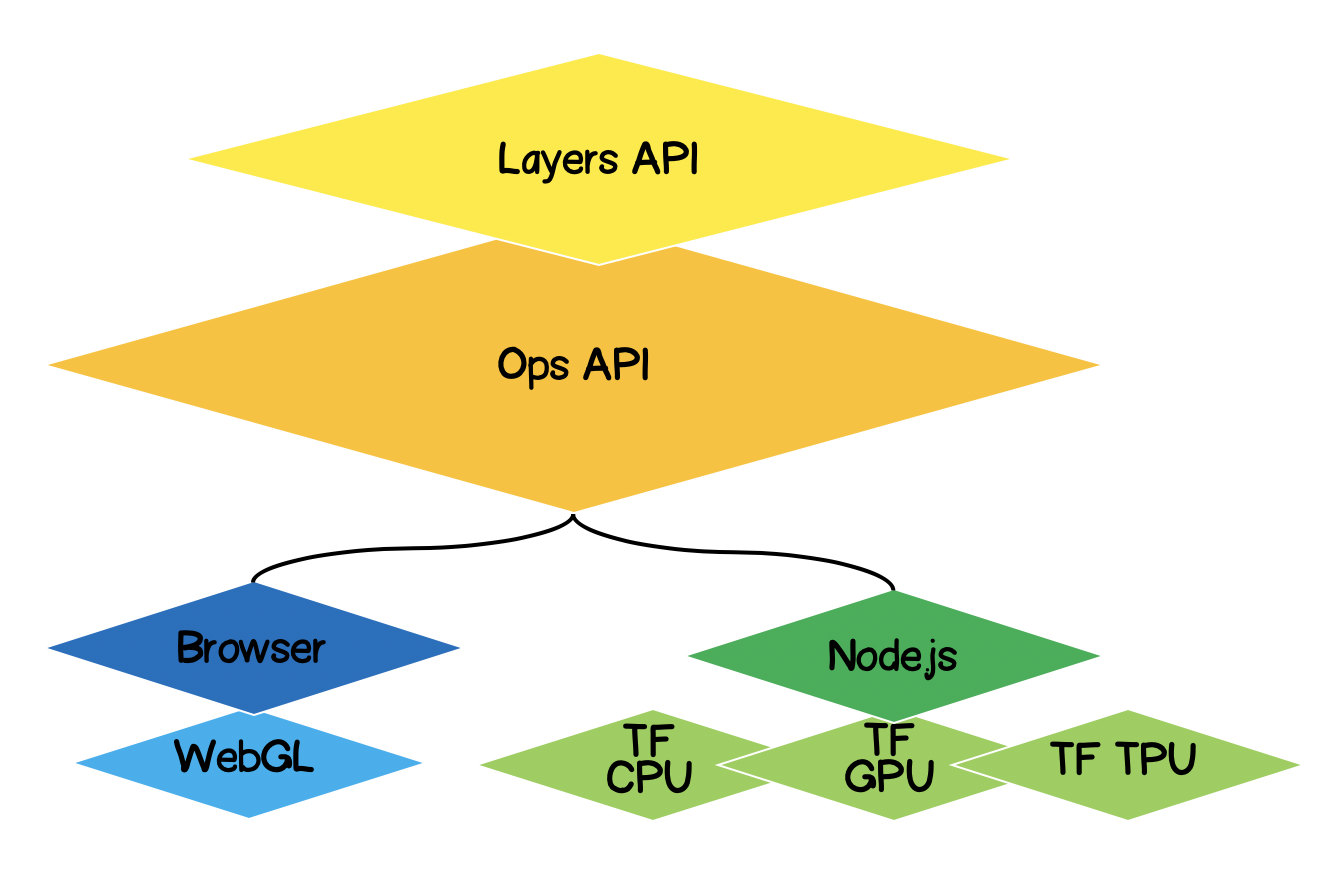
TensorFlow.js Architektur
- Niedrigste Schicht - Diese Schicht ist für die Parallelisierung von Berechnungen verantwortlich, wenn mathematische Operationen an Tensoren ausgeführt werden.
- Die Ops-API - Bietet eine API zum Ausführen mathematischer Operationen an Tensoren.
- Layer-API - Ermöglicht die Erstellung komplexer Modelle neuronaler Netze mit verschiedenen Layertypen (dicht, faltungsorientiert). Diese Ebene ähnelt der Keras Python-API und kann vorab trainierte Keras Python-basierte Netzwerke laden.
Formulierung des Problems
Es ist notwendig, die Gleichung der approximierenden linearen Funktion für einen gegebenen Satz von experimentellen Punkten zu finden. Mit anderen Worten, wir müssen eine solche lineare Kurve finden, die den experimentellen Punkten am nächsten liegt.

Lösungsformalisierung
Der Kern jedes maschinellen Lernens wird ein Modell sein. In unserem Fall ist dies die Gleichung einer linearen Funktion:
Basierend auf der Bedingung haben wir auch eine Reihe von experimentellen Punkten:
Angenommen, das ist aktiviert Im Trainingsschritt wurden die folgenden Koeffizienten der linearen Gleichung berechnet ... Jetzt müssen wir mathematisch ausdrücken, wie genau die ausgewählten Koeffizienten sind. Dazu müssen wir den Fehler (Verlust) berechnen, der beispielsweise durch die Standardabweichung bestimmt werden kann. Tensorflow.js bietet eine Reihe häufig verwendeter Verlustfunktionen: tf.metrics.meanAbsoluteError , tf.metrics.meanSquaredError usw.
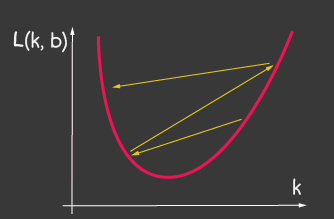
Der Zweck der Approximation besteht darin, die Fehlerfunktion zu minimieren ... Verwenden wir hierfür die Gradientenabstiegsmethode. Es ist notwendig:
- — -, ;
- — -. , :
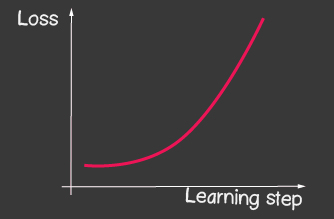
— (learning rate) . . learning rate ( 2), — , 1.
|


|
|---|---|
| 1: (learning-rate) | 2: (learning-rate) |
Tensorflow.js
Die Berechnung des Werts der Verlustfunktion (Standardabweichung) würde beispielsweise folgendermaßen aussehen:
function loss(ysPredicted, ysReal) {
const squaredSum = ysPredicted.reduce(
(sum, yPredicted, i) => sum + (yPredicted - ysReal[i]) ** 2,
0);
return squaredSum / ysPredicted.length;
}
Die Menge der Eingabedaten kann jedoch groß sein. Während des Modelltrainings müssen wir nicht nur den Wert der Verlustfunktion bei jeder Iteration berechnen, sondern auch ernstere Operationen ausführen - die Berechnung des Gradienten. Daher ist es sinnvoll, Tensorflow zu verwenden, der die Berechnungen mithilfe von WebGL optimiert. Darüber hinaus wird der Code viel ausdrucksvoller, vergleiche:
function loss(ysPredicted, ysReal) => {
const ysPredictedTensor = tf.tensor(ysPredicted);
const ysRealTensor = tf.tensor(ysReal);
const loss = ysPredictedTensor.sub(ysRealTensor).square().mean();
return loss.dataSync()[0];
};
Lösung mit TensorFlow.js
Die gute Nachricht ist, dass wir keine Optimierer für eine bestimmte Fehlerfunktion (Verlust) schreiben müssen, keine numerischen Methoden zur Berechnung partieller Ableitungen entwickeln und den Backpropogation-Algorithmus bereits für uns implementiert haben. Wir müssen nur die folgenden Schritte ausführen:
- setze ein Modell (in unserem Fall lineare Funktion);
- Beschreiben Sie die Fehlerfunktion (in unserem Fall ist dies die Standardabweichung).
- Wählen Sie einen der implementierten Optimierer (es ist möglich, die Bibliothek mit Ihrer eigenen Implementierung zu erweitern).
Was ist Tensor?
Absolut jeder ist in der Mathematik auf Tensoren gestoßen - das sind Skalar, Vektor, 2D - Matrix, 3D - Matrix. Ein Tensor ist ein verallgemeinertes Konzept aller oben genannten Punkte. Dies ist ein Datencontainer, der Daten eines homogenen Typs enthält (Tensorflow unterstützt int32, float32, bool, complex64, string) und eine bestimmte Form hat (die Anzahl der Achsen (Rang) und die Anzahl der Elemente in jeder der Achsen). Im Folgenden werden Tensoren bis zu 3D-Matrizen betrachtet. Da dies jedoch eine Verallgemeinerung ist, kann ein Tensor beliebig viele Achsen haben: 5D, 6D, ... ND.
TensorFlow verfügt über die folgende API zur Tensorgenerierung:
tf.tensor (values, shape?, dtype?)Dabei ist Form die Form des Tensors und wird durch ein Array angegeben, bei dem die Anzahl der Elemente die Anzahl der Achsen ist und jeder Wert des Arrays die Anzahl der Elemente entlang jeder der Achsen bestimmt. Um beispielsweise eine 4x2-Matrix (4 Zeilen, 2 Spalten) zu definieren, hat das Formular die Form [4, 2].
| Visualisierung | Beschreibung |
|---|---|

|
Skalar
Rang: 0 Form: [] JS Struktur: TensorFlow API: |

|
Vektor
Rang: 1 Form: [4] JS-Struktur: TensorFlow API: |
 |
Matrix
Rang: 2 Form: [4,2] JS-Struktur: TensorFlow API: |
 |
Matrix
Rang: 3 Form: [4,2,3] JS-Struktur: TensorFlow API: |
Lineare Approximation mit TensorFlow.js
Zunächst werden wir darüber sprechen, den Code erweiterbar zu machen. Wir können die lineare Approximation durch eine Funktion jeglicher Art in eine Approximation der experimentellen Punkte umwandeln. Die Klassenhierarchie sieht folgendermaßen aus:

Beginnen wir mit der Implementierung der Methoden der abstrakten Klasse, mit Ausnahme der abstrakten Methoden, die in den untergeordneten Klassen definiert werden. Hier werden Stubs nur dann mit Fehlern belassen, wenn die Methode aus irgendeinem Grund nicht in der untergeordneten Klasse definiert ist.
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
}Im Konstruktor des Modells haben wir also Breite und Höhe definiert - dies sind die tatsächliche Breite und Höhe der Ebene, auf der wir die experimentellen Punkte platzieren werden. Dies ist erforderlich, um die Eingabedaten zu normalisieren. Jene. wenn wir habenNach der Normalisierung haben wir dann:
optimizerFunction - Wir werden die Aufgabe des Optimierers flexibel gestalten, um andere in der Bibliothek verfügbare Optimierer ausprobieren zu können. Standardmäßig haben wir die stochastische Gradientenabstiegsmethode tf.train.sgd festgelegt . Ich würde auch empfehlen, mit anderen verfügbaren Optimierern zu spielen, die die Lernrate während des Trainings optimieren können, und der Lernprozess wird erheblich verbessert. Probieren Sie beispielsweise die folgenden Optimierer aus: tf.train.momentum , tf.train.adam .
Damit der Lernprozess nicht endlos verläuft, haben wir zwei Parameter definiert: maxEpochPerTrainSesion und expectedLoss- auf diese Weise werden wir den Trainingsprozess stoppen , wenn entweder die maximale Anzahl der Trainings Iterationen erreicht ist , oder wenn der Wert der Fehlerfunktion niedriger als der erwartete Fehler wird (wir werden in der alles berücksichtigen Zug Methode unten).
Im Konstruktor rufen wir die Methode initModelVariables auf - aber wie vereinbart stubben und definieren wir sie später in der untergeordneten Klasse.
initModelVariables() {
throw Error('Model variables should be defined')
}
Implementieren wir nun die Hauptmethode des Zugmodells:
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert array into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
trainSession ist im Wesentlichen eine eindeutige Kennung für die Schulungssitzung, falls die externe API die Zugmethode aufruft, während die vorherige Schulungssitzung noch nicht beendet wurde.
Aus dem Code können Sie ersehen, dass wir tensor1d aus eindimensionalen Arrays erstellen. Während die Daten zuerst normalisiert werden müssen, sind die Funktionen für die Normalisierung hier:
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
In einer Schleife rufen wir für jeden Trainingsschritt den Modelloptimierer auf, an den wir die Verlustfunktion übergeben müssen. Wie vereinbart wird die Verlustfunktion durch die Standardabweichung festgelegt. Dann haben wir mit der API tensorflow.js:
/**
* Calculate loss function as mean-square deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
// L = sum ((x_pred_i - x_real_i)^2) / N
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
Der Lernprozess geht dabei weiter
- Das Limit für die Anzahl der Iterationen wird nicht erreicht
- Die gewünschte Fehlergenauigkeit wird nicht erreicht
- Ein neuer Trainingsprozess wurde nicht gestartet
Beachten Sie auch, wie die Verlustfunktion aufgerufen wird. Um den vorhergesagten Wert zu erhalten - wir nennen die Funktion f -, die tatsächlich die Form festlegt, nach der die Regression durchgeführt wird, setzen wir in der abstrakten Klasse, wie vereinbart, einen Stub:
f(x) {
throw Error('Model should be defined')
}
Bei jedem Trainingsschritt speichern wir in der Eigenschaft des Objekts des Verlaufsmodells die Dynamik der Fehleränderung in jeder Trainingsepoche.
Nach dem Training des Modells benötigen wir eine Methode, die mit dem trainierten Modell berechnete Ausgaben akzeptiert. Zu diesem Zweck haben wir in der API die Vorhersagemethode definiert und sie sieht folgendermaßen aus:
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
Achten Sie analog zu node.js auf arraySync. Wenn es eine arraySync- Methode gibt, gibt es definitiv eine asynchrone Array- Methode , die ein Promise zurückgibt. Hier ist ein Versprechen erforderlich, da, wie bereits erwähnt, alle Tensoren nach WebGL migriert werden, um die Berechnungen zu beschleunigen, und der Prozess asynchron wird, da das Verschieben von Daten aus WebGL in eine JS-Variable einige Zeit in Anspruch nimmt.
Wir sind mit der abstrakten Klasse fertig. Die Vollversion des Codes finden Sie hier:
AbstractRegressionModel.js
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
initModelVariables() {
throw Error('Model variables should be defined')
}
f() {
throw Error('Model should be defined')
}
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
/**
* Calculate loss function as mean-squared deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert data into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
stop() {
this.trainSession++;
}
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
}
Für die lineare Regression definieren wir eine neue Klasse, die von der abstrakten Klasse erbt, wobei wir nur zwei Methoden definieren müssen: initModelVariables und f .
Da wir an einer linearen Näherung arbeiten, müssen wir zwei Variablen k, b - angeben, und sie werden Skalartensoren sein. Für den Optimierer müssen wir angeben, dass sie anpassbar sind (Variablen), und beliebige Zahlen als Anfangswerte zuweisen.
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}Betrachten Sie hier die API für Variable :
tf.variable (initialValue, trainable?, name?, dtype?)Achten Sie auf das zweite Argument für trainable - eine boolesche Variable, die standardmäßig wahr ist . Es wird von Optimierern verwendet, die ihnen mitteilen, ob diese Variable konfiguriert werden muss, um die Verlustfunktion zu minimieren. Dies kann nützlich sein, wenn wir ein neues Modell erstellen, das auf einem mit Keras Python geladenen vorab trainierten Modell basiert, und wir sind zuversichtlich, dass einige Ebenen in diesem Modell nicht neu trainiert werden müssen.
Als nächstes müssen wir die Gleichung der Approximationsfunktion mithilfe der Tensorflow-API definieren, einen Blick auf den Code werfen und Sie werden intuitiv verstehen, wie er verwendet wird:
f(x) {
// y = kx + b
return x.mul(this.k).add(this.b);
}Auf diese Weise können Sie beispielsweise eine quadratische Näherung angeben:
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f(x) {
// y = ax^2 + bx + c
return this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}Hier können Sie die Modelle für die lineare und quadratische Regression überprüfen:
LinearRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class LinearRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}
f = x => x.mul(this.k).add(this.b);
}
QuadraticRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class QuadraticRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f = x => this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}
Im Folgenden finden Sie einen in React geschriebenen Code, der das geschriebene lineare Regressionsmodell verwendet und die UX für den Benutzer erstellt:
Regression.js
import React, { useState, useEffect } from 'react';
import Canvas from './components/Canvas';
import LossPlot from './components/LossPlot_v3';
import LinearRegressionModel from './model/LinearRegressionModel';
import './RegressionModel.scss';
const WIDTH = 400;
const HEIGHT = 400;
const LINE_POINT_STEP = 5;
const predictedInput = Array.from({ length: WIDTH / LINE_POINT_STEP + 1 })
.map((v, i) => i * LINE_POINT_STEP);
const model = new LinearRegressionModel(WIDTH, HEIGHT);
export default () => {
const [points, changePoints] = useState([]);
const [curvePoints, changeCurvePoints] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
if (points.length > 0) {
const input = points.map(({ x }) => x);
const output = points.map(({ y }) => y);
model.train(input, output, () => {
changeCurvePoints(() => model.predict(predictedInput));
changeLossHistory(() => model.history);
});
}
}, [points]);
return (
<div className="regression-low-level">
<div className="regression-low-level__top">
<div className="regression-low-level__workarea">
<div className="regression-low-level__canvas">
<Canvas
width={WIDTH}
height={HEIGHT}
points={points}
curvePoints={curvePoints}
changePoints={changePoints}
/>
</div>
<div className="regression-low-level__toolbar">
<button
className="btn btn-red"
onClick={() => model.stop()}>Stop
</button>
<button
className="btn btn-yellow"
onClick={() => {
model.stop();
changePoints(() => []);
changeCurvePoints(() => []);
}}>Clear
</button>
</div>
</div>
<div className="regression-low-level__loss">
<LossPlot
loss={lossHistory}/>
</div>
</div>
</div>
)
}Ergebnis:
Ich würde die folgenden Aufgaben wärmstens empfehlen:
- die Funktionsnäherung durch die logarithmische Funktion zu implementieren
- Versuchen Sie für den Optimierer tf.train.sgd, mit learningRate zu spielen, und beobachten Sie, wie sich der Lernprozess ändert. Versuchen Sie, die Lernrate sehr hoch einzustellen, um das in Abbildung 2 gezeigte Bild zu erhalten.
- Setzen Sie den Optimierer auf tf.train.adam. Hat sich der Lernprozess verbessert? Ob der Lernprozess von der Änderung des LearningRate-Werts im Modellkonstruktor abhängt.