Zuerst werden wir uns kurz mit den Methoden zum Durchlaufen von Diagrammen vertraut machen, die eigentliche Pfadfindung schreiben und dann zu der köstlichsten übergehen: Optimierung der Leistung und der Speicherkosten. Idealerweise sollten Sie eine Implementierung entwickeln, die bei Verwendung überhaupt keinen Müll erzeugt.
Ich war erstaunt, als eine flüchtige Suche mir keine einzige gute Implementierung des A * -Algorithmus in C # ohne die Verwendung von Bibliotheken von Drittanbietern ergab (dies bedeutet nicht, dass es keine gibt). Es ist also Zeit, die Finger zu strecken!
Ich warte auf einen Leser, der die Arbeit von Pfadfindungsalgorithmen verstehen möchte, sowie auf Experten für Algorithmen, um sich mit der Implementierung und den Methoden ihrer Optimierung vertraut zu machen.
Lass uns anfangen!
Ein Ausflug in die Geschichte
Ein zweidimensionales Netz kann als Diagramm dargestellt werden, wobei jeder der Scheitelpunkte 8 Kanten hat:
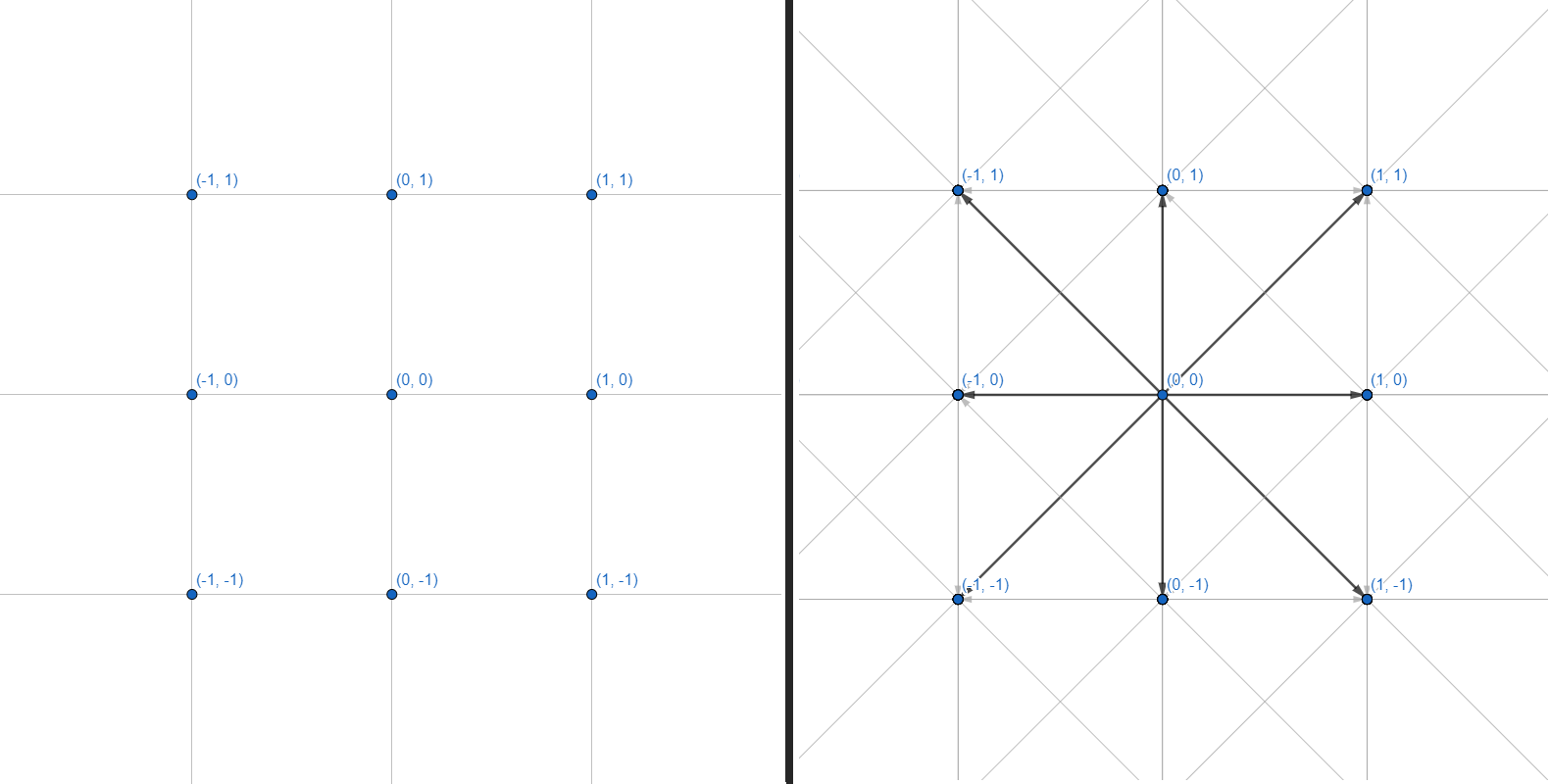
Wir werden mit Diagrammen arbeiten. Jeder Scheitelpunkt ist eine ganzzahlige Koordinate. Jede Kante ist ein gerader oder diagonaler Übergang zwischen benachbarten Koordinaten. Wir werden das Koordinatengitter und die Berechnung der Geometrie von Hindernissen nicht durchführen - wir werden uns auf eine Schnittstelle beschränken, die mehrere Koordinaten als Eingabe akzeptiert und eine Reihe von Punkten zum Erstellen eines Pfades zurückgibt:
public interface IPath
{
IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles);
}Berücksichtigen Sie zunächst die vorhandenen Methoden zum Durchlaufen des Diagramms.
Tiefensuche
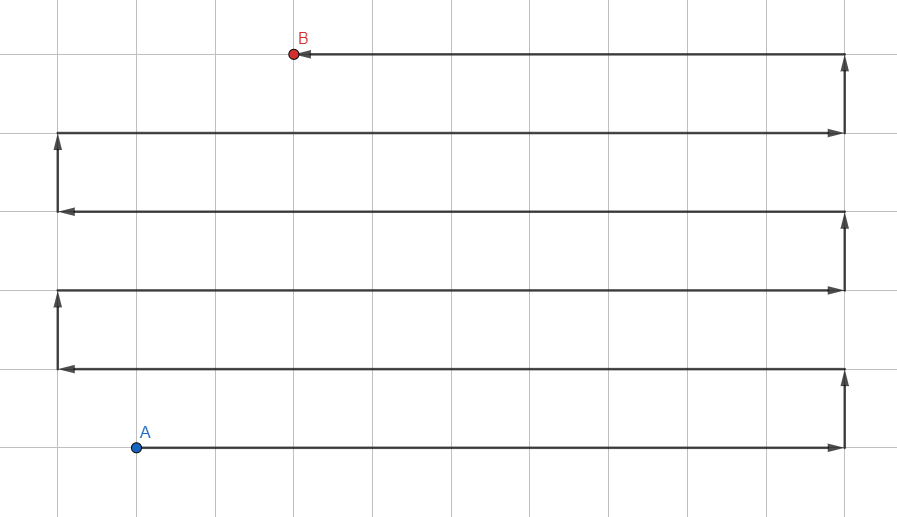
Der einfachste der Algorithmen:
- Fügen Sie alle nicht besuchten Scheitelpunkte in der Nähe des aktuellen zum Stapel hinzu.
- Gehen Sie vom Stapel zum ersten Scheitelpunkt.
- Wenn der Scheitelpunkt der gewünschte ist, verlassen Sie den Zyklus. Wenn Sie in eine Sackgasse geraten, gehen Sie zurück.
- GOTO 1.
Es sieht aus wie das:
, Node , .
private Node DFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Stack<Node> frontier = new Stack<Node>();
frontier.Push(first);
while (frontier.Count > 0)
{
var current = frontier.Pop();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Push(neighbour);
}
return default;
}, Node , .
Es ist im LIFO-Format ( Last in - First out ) organisiert, in dem neu hinzugefügte Scheitelpunkte zuerst analysiert werden. Jeder Übergang zwischen den Eckpunkten muss überwacht werden, um dann den tatsächlichen Pfad entlang der Übergänge zu erstellen.
Dieser Ansatz wird niemals (fast) den kürzesten Weg zurückgeben, da er den Graphen in einer zufälligen Richtung verarbeitet. Es ist besser für kleine Diagramme geeignet, um ohne Kopfschmerzen zu bestimmen, ob mindestens ein Pfad zum gewünschten Scheitelpunkt vorhanden ist (z. B. ob die gewünschte Verknüpfung im Technologiebaum vorhanden ist).
Im Fall eines Navigationsrasters und unendlicher Grafiken geht diese Suche endlos in eine Richtung und verschwendet Rechenressourcen, ohne den gewünschten Punkt zu erreichen. Dies wird gelöst, indem der Bereich begrenzt wird, in dem der Algorithmus arbeitet. Wir lassen es nur Punkte analysieren, die nicht weiter als N Schritte vom ursprünglichen entfernt sind. Wenn der Algorithmus die Grenze der Region erreicht, entfaltet er sich und analysiert weiterhin die Eckpunkte innerhalb des angegebenen Radius.
Manchmal ist es unmöglich, den Bereich genau zu bestimmen, aber Sie möchten den Rand nicht zufällig festlegen. Eine iterative Tiefensuche hilft :
- Legen Sie den Mindestbereich für DFS fest.
- Suche starten.
- Wenn der Pfad nicht gefunden wird, vergrößern Sie den Suchbereich um 1.
- GOTO 2.
Der Algorithmus wird immer wieder ausgeführt und deckt jedes Mal einen größeren Bereich ab, bis er schließlich den gewünschten Punkt findet.
Es mag wie Energieverschwendung erscheinen, den Algorithmus in einem etwas größeren Radius erneut auszuführen (der größte Teil des Bereichs wurde ohnehin bereits bei der letzten Iteration analysiert!). Aber nein: Die Anzahl der Übergänge zwischen Scheitelpunkten wächst geometrisch mit jeder Vergrößerung des Radius. Es ist viel teurer, einen größeren Radius als nötig zu nehmen, als mehrmals entlang kleiner Radien zu gehen.
Für eine solche Suche ist es einfach, ein Timer-Limit zu verschärfen: Es wird genau bis zum Ende der angegebenen Zeit nach einem Pfad mit einem sich erweiternden Radius gesucht.
Breite erste Suche
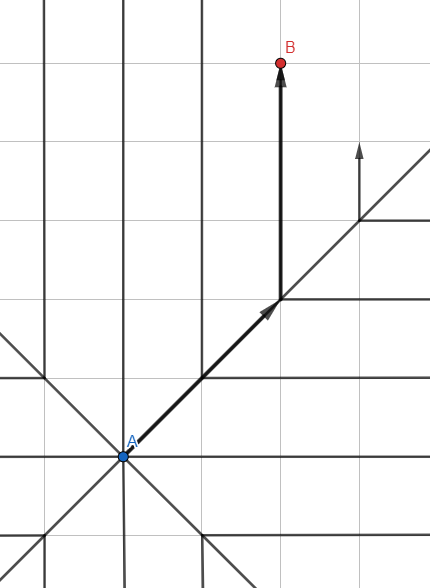
Die Abbildung ähnelt möglicherweise der Sprungsuche - dies ist jedoch der übliche Wellenalgorithmus , und die Linien repräsentieren die Suchausbreitungspfade, wobei die Zwischenpunkte entfernt wurden.
Im Gegensatz zur Tiefensuche mit einem Stapel (LIFO) nehmen wir eine Warteschlange (FIFO), um die Scheitelpunkte zu verarbeiten:
- Fügen Sie alle nicht besuchten Nachbarn zur Warteschlange hinzu.
- Gehen Sie zum ersten Scheitelpunkt aus der Warteschlange.
- Wenn der Scheitelpunkt der gewünschte ist, verlassen Sie den Zyklus, andernfalls GOTO 1.
Es sieht aus wie das:
, Node , .
private Node BFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Queue<Node> frontier = new Queue<Node>();
frontier.Enqueue(first);
while (frontier.Count > 0)
{
var current = frontier.Dequeue();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Enqueue(neighbour);
}
return default;
}, Node , .
Dieser Ansatz liefert den optimalen Pfad, aber es gibt einen Haken: Da der Algorithmus Scheitelpunkte in alle Richtungen verarbeitet, arbeitet er über große Entfernungen und Diagramme mit starker Verzweigung sehr langsam. Dies ist nur unser Fall.
Hier kann der Einsatzbereich des Algorithmus nicht eingeschränkt werden, da er in jedem Fall nicht über den Radius bis zum gewünschten Punkt hinausgeht. Andere Optimierungsmethoden sind erforderlich.
EIN *
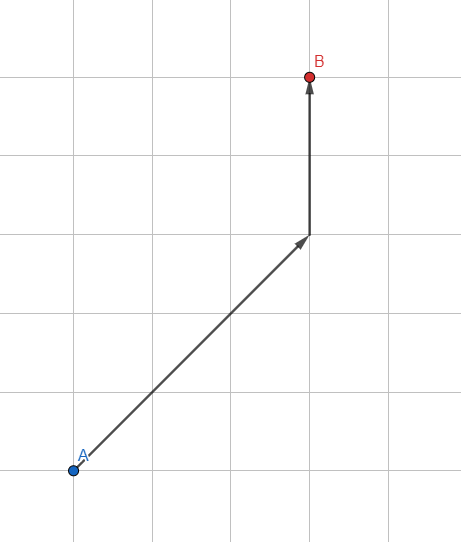
Lassen Sie uns die Standard-Breitensuche ändern: Wir verwenden keine reguläre Warteschlange zum Speichern von Scheitelpunkten, sondern eine sortierte Warteschlange basierend auf Heuristiken - eine ungefähre Schätzung des erwarteten Pfads.
Wie schätze ich den erwarteten Pfad? Am einfachsten ist die Länge des Vektors vom verarbeiteten Scheitelpunkt bis zum gewünschten Punkt. Je kleiner der Vektor ist, desto vielversprechender ist der Punkt und desto näher am Anfang der Warteschlange wird er. Der Algorithmus gibt den Eckpunkten Vorrang, die in Richtung des Ziels liegen.
Daher dauert jede Iteration innerhalb des Algorithmus aufgrund zusätzlicher Berechnungen etwas länger. Durch Verringern der Anzahl der zu analysierenden Scheitelpunkte (nur die vielversprechendsten werden verarbeitet) wird jedoch eine enorme Steigerung der Geschwindigkeit des Algorithmus erzielt.
Es gibt jedoch noch viele verarbeitete Scheitelpunkte. Das Ermitteln der Länge eines Vektors ist eine teure Operation, bei der die Quadratwurzel berechnet wird. Daher werden wir eine vereinfachte Berechnung für die Heuristik verwenden.
Erstellen wir einen ganzzahligen Vektor:
public readonly struct Vector2Int : IEquatable<Vector2Int>
{
private static readonly double Sqr = Math.Sqrt(2);
public Vector2Int(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
/// <summary>
/// Estimated path distance without obstacles.
/// </summary>
public double DistanceEstimate()
{
int linearSteps = Math.Abs(Math.Abs(Y) - Math.Abs(X));
int diagonalSteps = Math.Max(Math.Abs(Y), Math.Abs(X)) - linearSteps;
return linearSteps + Sqr * diagonalSteps;
}
public static Vector2Int operator +(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X + b.X, a.Y + b.Y);
public static Vector2Int operator -(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X - b.X, a.Y - b.Y);
public static bool operator ==(Vector2Int a, Vector2Int b)
=> a.X == b.X && a.Y == b.Y;
public static bool operator !=(Vector2Int a, Vector2Int b)
=> !(a == b);
public bool Equals(Vector2Int other)
=> X == other.X && Y == other.Y;
public override bool Equals(object obj)
{
if (!(obj is Vector2Int))
return false;
var other = (Vector2Int) obj;
return X == other.X && Y == other.Y;
}
public override int GetHashCode()
=> HashCode.Combine(X, Y);
public override string ToString()
=> $"({X}, {Y})";
}Eine Standardstruktur zum Speichern eines Koordinatenpaars. Hier sehen wir das Quadratwurzel-Caching, so dass es nur einmal berechnet werden kann. Die IEquatable-Schnittstelle ermöglicht es uns, Vektoren miteinander zu vergleichen, ohne Vector2Int in Objekt und zurück übersetzen zu müssen. Dies wird unseren Algorithmus erheblich beschleunigen und unnötige Zuordnungen beseitigen.
DistanceEstimate () wird verwendet, um die ungefähre Entfernung zum Ziel zu schätzen, indem die Anzahl der geraden und diagonalen Übergänge berechnet wird. Ein alternativer Weg ist üblich:
return Math.Max(Math.Abs(X), Math.Abs(Y))Diese Option funktioniert noch schneller, wird jedoch durch die geringe Genauigkeit der Diagonalabstandsschätzung kompensiert.
Nachdem wir nun ein Werkzeug zum Arbeiten mit Koordinaten haben, erstellen wir ein Objekt, das den oberen Rand des Diagramms darstellt:
internal class PathNode
{
public PathNode(Vector2Int position, double traverseDist, double heuristicDist, PathNode parent)
{
Position = position;
TraverseDistance = traverseDist;
Parent = parent;
EstimatedTotalCost = TraverseDistance + heuristicDist;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
public PathNode Parent { get; }
}In Parent zeichnen wir den vorherigen Scheitelpunkt für jeden neuen auf: Dies hilft beim Erstellen des endgültigen Pfads nach Punkten. Zusätzlich zu den Koordinaten speichern wir auch die zurückgelegte Strecke und die geschätzten Kosten des Pfades, damit wir dann die vielversprechendsten Eckpunkte für die Verarbeitung auswählen können.
Diese Klasse bittet um Verbesserung, aber wir werden später darauf zurückkommen. Lassen Sie uns zunächst eine Methode entwickeln, die die Nachbarn des Scheitelpunkts generiert:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static IEnumerable<PathNode> GenerateNeighbours(this PathNode parent, Vector2Int target)
{
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
double heuristicDistance = (position - target).DistanceEstimate();
yield return new PathNode(nodePosition, traverseDistance, heuristicDistance, parent);
}
}
}NeighborsTemplate - eine vordefinierte Vorlage zum Erstellen linearer und diagonaler Nachbarn des gewünschten Punkts. Es berücksichtigt auch die erhöhten Kosten für diagonale Übergänge.
GenerateNeighbors - Ein Generator, der die NeighborsTemplate durchläuft und einen neuen Scheitelpunkt für alle acht benachbarten Seiten zurückgibt.
Es wäre möglich, die Funktionalität in den PathNode zu verschieben, aber es fühlt sich wie eine leichte Verletzung von SRP an. Und ich möchte dem Algorithmus selbst auch keine Funktionen von Drittanbietern hinzufügen: Wir werden die Klassen so kompakt wie möglich halten.
Zeit, die Hauptklasse der Wegfindung anzugehen!
public class Path
{
private readonly List<PathNode> frontier = new List<PathNode>();
private readonly List<Vector2Int> ignoredPositions = new List<Vector2Int>();
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles) {...}
private bool GenerateNodes(Vector2Int start, Vector2Int target,
IEnumerable<Vector2Int> obstacles, out PathNode node)
{
frontier.Clear();
ignoredPositions.Clear();
ignoredPositions.AddRange(obstacles);
// Add starting point.
frontier.Add(new PathNode(start, 0, 0, null));
while (frontier.Any())
{
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target))
{
node = current;
return true;
}
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
node = null;
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
var node = frontier.FirstOrDefault(a => a.Position == newNode.Position);
if (node == null)
frontier.Add(newNode);
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < node.TraverseDistance)
{
frontier.Remove(node);
frontier.Add(newNode);
}
}
}
}GenerateNodes arbeitet mit zwei Sammlungen: Frontier, das eine Warteschlange mit zu analysierenden Scheitelpunkten enthält, und ignorierte Positionen, zu denen bereits verarbeitete Scheitelpunkte hinzugefügt werden.
Jede Iteration der Schleife findet den vielversprechendsten Scheitelpunkt, prüft, ob wir am Endpunkt angekommen sind, und generiert neue Nachbarn für diesen Scheitelpunkt.
Und all diese Schönheit passt in 50 Zeilen.
Es bleibt die Schnittstelle zu implementieren:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles, out PathNode node))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int>();
while (node.Parent != null)
{
output.Add(node.Position);
node = node.Parent;
}
output.Add(start);
return output.AsReadOnly();
}GenerateNodes gibt uns den endgültigen Scheitelpunkt zurück, und da wir jedem von ihnen einen übergeordneten Nachbarn geschrieben haben, reicht es aus, alle Eltern bis zum anfänglichen Scheitelpunkt zu durchlaufen - und wir erhalten den kürzesten Weg. Alles ist gut!
Oder nicht?
Algorithmusoptimierung
1. PathNode
Fangen wir einfach an. Vereinfachen wir PathNode:
internal readonly struct PathNode
{
public PathNode(Vector2Int position, Vector2Int target, double traverseDistance)
{
Position = position;
TraverseDistance = traverseDistance;
double heuristicDistance = (position - target).DistanceEstimate();
EstimatedTotalCost = traverseDistance + heuristicDistance;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
}Dies ist ein gängiger Daten-Wrapper, der ebenfalls sehr häufig erstellt wird. Es gibt keinen Grund , warum es eine Klasse und Ladespeicher jedes Mal , wenn wir schreiben , um neue . Daher werden wir struct verwenden.
Es gibt jedoch ein Problem: Strukturen dürfen keine Zirkelverweise auf ihren eigenen Typ enthalten. Anstatt das übergeordnete Element im PathNode zu speichern, benötigen wir eine andere Möglichkeit, um die Konstruktion von Pfaden zwischen Scheitelpunkten zu verfolgen. Es ist ganz einfach - fügen wir der Path-Klasse eine neue Sammlung hinzu:
private readonly Dictionary<Vector2Int, Vector2Int> links;Und wir modifizieren die Generation der Nachbarn leicht:
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
}
}Anstatt das übergeordnete Element in den Scheitelpunkt selbst zu schreiben, schreiben wir den Übergang zum Wörterbuch. Als Bonus kann das Wörterbuch direkt mit Vector2Int und nicht mit PathNode arbeiten, da wir nur Koordinaten und sonst nichts benötigen.
Das Generieren des Ergebnisses in Calculate wird ebenfalls vereinfacht:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int> {target};
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}2. NodeExtensions
Als nächstes beschäftigen wir uns mit der Generation der Nachbarn. IEnumerable erzeugt trotz all seiner Vorteile in vielen Situationen eine traurige Menge an Müll. Lassen Sie es uns loswerden:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static void Fill(this PathNode[] buffer, PathNode parent, Vector2Int target)
{
int i = 0;
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
buffer[i++] = new PathNode(nodePosition, target, traverseDistance);
}
}
}Jetzt ist unsere Erweiterungsmethode kein Generator: Sie füllt nur den Puffer, der als Argument an sie übergeben wird. Der Puffer wird als weitere Sammlung im Pfad gespeichert:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];Und es wird so verwendet:
neighbours.Fill(parent, target);
foreach(var neighbour in neighbours)
{
// ...3. HashSet
Verwenden Sie anstelle von List HashSet:
private readonly HashSet<Vector2Int> ignoredPositions;Bei der Arbeit mit großen Sammlungen ist die Methode ignorePositions.Contains () aufgrund der Häufigkeit von Aufrufen sehr ressourcenintensiv. Eine einfache Änderung des Sammlungstyps führt zu einer spürbaren Leistungssteigerung.
4. BinaryHeap
Es gibt eine Stelle in unserer Implementierung, die den Algorithmus verzehnfacht:
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);List selbst ist eine schlechte Wahl, und die Verwendung von Linq macht die Sache noch schlimmer.
Idealerweise möchten wir eine Sammlung mit:
- Automatische Sortierung.
- Geringes Wachstum der asymptotischen Komplexität.
- Schneller Einfügevorgang.
- Schneller Entfernungsvorgang.
- Einfache Navigation durch die Elemente.
SortedSet scheint eine gute Option zu sein, weiß aber nicht, wie man Duplikate enthält. Wenn wir die Sortierung nach EstimatedTotalCost schreiben, werden alle Scheitelpunkte mit demselben Preis (aber unterschiedlichen Koordinaten!) Eliminiert. In offenen Gebieten mit einer kleinen Anzahl von Hindernissen ist dies nicht schrecklich und beschleunigt den Algorithmus. In engen Labyrinthen führt dies jedoch zu ungenauen Routen und falsch negativen Ergebnissen.
Also implementieren wir unsere Sammlung - den binären Haufen ! Die klassische Implementierung erfüllt 4 von 5 Anforderungen, und eine kleine Modifikation macht diese Sammlung ideal für unseren Fall.
Die Sammlung ist ein teilweise sortierter Baum mit der Komplexität von Einfüge- und Löschvorgängen gleich log (n) .
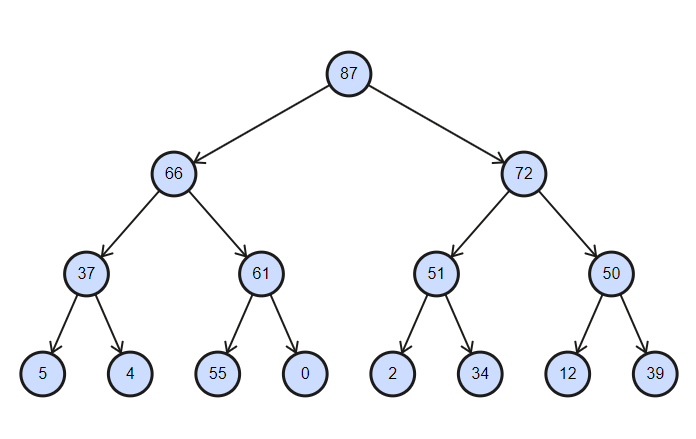
Binärer Heap in absteigender Reihenfolge sortiert
internal interface IBinaryHeap<in TKey, T>
{
void Enqueue(T item);
T Dequeue();
void Clear();
bool TryGet(TKey key, out T value);
void Modify(T value);
int Count { get; }
}Schreiben wir den einfachen Teil:
internal class BinaryHeap : IBinaryHeap<Vector2Int, PathNode>
{
private readonly IDictionary<Vector2Int, int> map;
private readonly IList<PathNode> collection;
private readonly IComparer<PathNode> comparer;
public BinaryHeap(IComparer<PathNode> comparer)
{
this.comparer = comparer;
collection = new List<PathNode>();
map = new Dictionary<Vector2Int, int>();
}
public int Count => collection.Count;
public void Clear()
{
collection.Clear();
map.Clear();
}
// ...
}Wir werden IComparer zum benutzerdefinierten Sortieren von Scheitelpunkten verwenden. IList ist eigentlich der Vertex-Speicher, mit dem wir arbeiten werden. Wir benötigen IDictionary, um die Indizes der Scheitelpunkte für ihre schnelle Entfernung zu verfolgen (die Standardimplementierung des binären Heaps ermöglicht es uns, bequem nur mit dem obersten Element zu arbeiten).
Fügen wir ein Element hinzu:
public void Enqueue(PathNode item)
{
collection.Add(item);
int i = collection.Count - 1;
map[item.Position] = i;
// Sort nodes from bottom to top.
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
private void Swap(int i, int j)
{
PathNode temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[collection[i].Position] = i;
map[collection[j].Position] = j;
}Jedes neue Element wird zur letzten Zelle des Baums hinzugefügt und anschließend teilweise von unten nach oben sortiert: nach Knoten vom neuen Element zur Wurzel, bis das kleinste Element so hoch wie möglich ist. Da nicht die gesamte Sammlung sortiert ist, sondern nur Zwischenknoten zwischen dem oberen und dem letzten, hat die Operation das Komplexitätsprotokoll (n) .
Einen Artikel bekommen:
public PathNode Dequeue()
{
if (collection.Count == 0) return default;
PathNode result = collection.First();
RemoveRoot();
map.Remove(result.Position);
return result;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[collection[0].Position] = 0;
collection.RemoveAt(collection.Count - 1);
// Sort nodes from top to bottom.
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count
&& comparer.Compare(collection[leftInd], collection[largest]) > 0)
largest = leftInd;
if (rightInd < collection.Count
&& comparer.Compare(collection[rightInd], collection[largest]) > 0)
largest = rightInd;
return largest;
}In Analogie zum Hinzufügen: Das Wurzelelement wird entfernt und das letzte an seine Stelle gesetzt. Dann tauscht eine teilweise Top-Down-Sortierung die Elemente so aus, dass das kleinste oben liegt.
Danach implementieren wir die Suche nach einem Element und ändern es:
public bool TryGet(Vector2Int key, out PathNode value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(PathNode value)
{
if (!map.TryGetValue(value.Position, out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}Hier gibt es nichts Kompliziertes: Wir suchen über das Wörterbuch nach dem Index des Elements und greifen danach direkt darauf zu.
Generische Version des Heaps:
internal class BinaryHeap<TKey, T> : IBinaryHeap<TKey, T> where TKey : IEquatable<TKey>
{
private readonly IDictionary<TKey, int> map;
private readonly IList<T> collection;
private readonly IComparer<T> comparer;
private readonly Func<T, TKey> lookupFunc;
public BinaryHeap(IComparer<T> comparer, Func<T, TKey> lookupFunc, int capacity)
{
this.comparer = comparer;
this.lookupFunc = lookupFunc;
collection = new List<T>(capacity);
map = new Dictionary<TKey, int>(capacity);
}
public int Count => collection.Count;
public void Enqueue(T item)
{
collection.Add(item);
int i = collection.Count - 1;
map[lookupFunc(item)] = i;
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
public T Dequeue()
{
if (collection.Count == 0) return default;
T result = collection.First();
RemoveRoot();
map.Remove(lookupFunc(result));
return result;
}
public void Clear()
{
collection.Clear();
map.Clear();
}
public bool TryGet(TKey key, out T value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(T value)
{
if (!map.TryGetValue(lookupFunc(value), out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[lookupFunc(collection[0])] = 0;
collection.RemoveAt(collection.Count - 1);
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private void Swap(int i, int j)
{
T temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[lookupFunc(collection[i])] = i;
map[lookupFunc(collection[j])] = j;
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count && comparer.Compare(collection[leftInd], collection[largest]) > 0) largest = leftInd;
if (rightInd < collection.Count && comparer.Compare(collection[rightInd], collection[largest]) > 0) largest = rightInd;
return largest;
}
}Jetzt hat unsere Wegfindung eine anständige Geschwindigkeit und es gibt fast keine Müllgenerierung mehr. Das Ziel ist nahe!
5. Wiederverwendbare Sammlungen
Der Algorithmus wird mit Blick auf die Fähigkeit entwickelt, ihn Dutzende Male pro Sekunde aufzurufen. Die Erzeugung von Müll ist kategorisch inakzeptabel: Ein überladener Müllsammler kann (und wird!) Regelmäßige Leistungseinbußen verursachen.
Alle Sammlungen mit Ausnahme der Ausgabe werden beim Erstellen der Klasse bereits einmal deklariert, und die letzte wird dort ebenfalls hinzugefügt:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly IList<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
public Path()
{
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer);
ignoredPositions = new HashSet<Vector2Int>();
output = new List<Vector2Int>();
links = new Dictionary<Vector2Int, Vector2Int>();
}Die öffentliche Methode hat die folgende Form:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}Und es geht nicht nur darum, Sammlungen zu erstellen! Sammlungen ändern ihre Kapazität dynamisch, wenn sie gefüllt sind. Wenn der Pfad lang ist, erfolgt die Größenänderung Dutzende Male. Dies ist sehr speicherintensiv. Wenn wir die Sammlungen löschen und wiederverwenden, ohne neue zu deklarieren, behalten sie ihre Kapazität. Die erste Pfadkonstruktion verursacht beim Initialisieren von Sammlungen und Ändern ihrer Kapazitäten viel Müll, aber nachfolgende Aufrufe funktionieren ohne Zuweisungen einwandfrei (vorausgesetzt, die Länge jedes berechneten Pfads ist ohne scharfe Verzerrungen plus oder minus gleich). Daher der nächste Punkt:
6. (Bonus) Bekanntgabe der Sammlungsgröße
Es stellen sich sofort eine Reihe von Fragen:
- Ist es besser, die Last an den Konstruktor der Path-Klasse zu verlagern oder beim ersten Aufruf des Pathfinders zu belassen?
- Welche Kapazität, um die Sammlungen zu füttern?
- Ist es billiger, sofort eine größere Kapazität anzukündigen oder die Sammlung selbst erweitern zu lassen?
Die dritte Frage kann sofort beantwortet werden: Wenn wir Hunderte und Tausende von Zellen haben, um einen Pfad zu finden, ist es definitiv billiger, unseren Sammlungen sofort eine bestimmte Größe zuzuweisen.
Die beiden anderen Fragen sind schwieriger zu beantworten. Die Antwort auf diese Fragen muss für jeden Anwendungsfall empirisch ermittelt werden. Wenn wir uns dennoch dazu entschließen, die Last in den Konstruktor einzufügen, ist es an der Zeit, die Anzahl der Schritte für unseren Algorithmus zu begrenzen:
public Path(int maxSteps)
{
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer, maxSteps);
ignoredPositions = new HashSet<Vector2Int>(maxSteps);
output = new List<Vector2Int>(maxSteps);
links = new Dictionary<Vector2Int, Vector2Int>(maxSteps);
}Korrigieren Sie in GenerateNodes die Schleife:
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
// ...
}Sammlungen wird daher sofort eine Kapazität zugewiesen, die dem maximalen Pfad entspricht. Einige Sammlungen enthalten nicht nur die durchquerten Knoten, sondern auch deren Nachbarn: Für solche Sammlungen können Sie eine Kapazität verwenden, die 4-5 mal größer ist als die angegebene.
Es mag etwas zu viel erscheinen, aber für Pfade, die nahe am deklarierten Maximum liegen, verbraucht die Zuweisung der Größe von Sammlungen ein halbes bis dreimal weniger Speicher als die dynamische Erweiterung. Wenn Sie dem maxSteps-Wert jedoch sehr große Werte zuweisen und kurze Pfade generieren, kann eine solche Innovation nur schaden. Oh, und Sie sollten nicht versuchen, int.MaxValue zu verwenden!
Die optimale Lösung wäre, zwei Konstruktoren zu erstellen, von denen einer die Anfangskapazität der Sammlungen festlegt. Dann kann unsere Klasse in beiden Fällen verwendet werden, ohne sie zu ändern.
Was kannst du noch tun?
- .
- XML-.
- GetHashCode Vector2Int. , , , .
- , . .
- IComparable PathNode EqualityComparer. .
- : , . , , .
- Ändern Sie die Methodensignatur in unserer Benutzeroberfläche, um ihre Essenz besser widerzuspiegeln:
bool Calculate(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles, out IReadOnlyCollection<Vector2Int> path);
Somit zeigt die Methode deutlich die Logik ihrer Operation, während die ursprüngliche Methode wie folgt aufgerufen werden sollte: CalculateOrReturnEmpty .
Die endgültige Version der Path-Klasse:
/// <summary>
/// Reusable A* path finder.
/// </summary>
public class Path : IPath
{
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly int maxSteps;
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly List<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
/// <summary>
/// Creation of new path finder.
/// </summary>
/// <exception cref="ArgumentOutOfRangeException"></exception>
public Path(int maxSteps = int.MaxValue, int initialCapacity = 0)
{
if (maxSteps <= 0)
throw new ArgumentOutOfRangeException(nameof(maxSteps));
if (initialCapacity < 0)
throw new ArgumentOutOfRangeException(nameof(initialCapacity));
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap<Vector2Int, PathNode>(comparer, a => a.Position, initialCapacity);
ignoredPositions = new HashSet<Vector2Int>(initialCapacity);
output = new List<Vector2Int>(initialCapacity);
links = new Dictionary<Vector2Int, Vector2Int>(initialCapacity);
}
/// <summary>
/// Calculate a new path between two points.
/// </summary>
/// <exception cref="ArgumentNullException"></exception>
public bool Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles,
out IReadOnlyCollection<Vector2Int> path)
{
if (obstacles == null)
throw new ArgumentNullException(nameof(obstacles));
if (!GenerateNodes(start, target, obstacles))
{
path = Array.Empty<Vector2Int>();
return false;
}
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target)) output.Add(target);
path = output;
return true;
}
private bool GenerateNodes(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles)
{
frontier.Clear();
ignoredPositions.Clear();
links.Clear();
frontier.Enqueue(new PathNode(start, target, 0));
ignoredPositions.UnionWith(obstacles);
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
PathNode current = frontier.Dequeue();
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target)) return true;
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
neighbours.Fill(parent, target);
foreach (PathNode newNode in neighbours)
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position;
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position;
}
}
}
}Link zum Quellcode