Vor kurzem haben mich Kollegen im "Shop" unabhängig voneinander gefragt: Wie kann man alle Bluetooth-Kanäle gleichzeitig von einem SDR-Empfänger empfangen? Die Bandbreite erlaubt, es gibt SDR mit einer Ausgangsbandbreite von 80 MHz oder mehr. Sie können dies natürlich auch auf FPGA tun, aber die Entwicklungszeit wird ziemlich lang sein. Ich habe lange gewusst, dass es ziemlich einfach ist, dies auf einer GPU zu tun, aber das war's!
Der Bluetooth-Standard definiert die physische Schicht in zwei Versionen: Classic und Low Energy. Die Spezifikation ist hier . Das Dokument ist furchtbar groß, das vollständige Lesen ist für das Gehirn gefährlich. Glücklicherweise haben große Instrumentierungsunternehmen die Möglichkeit, visuelle Dokumente zu einem Thema zu erstellen. Zum Beispiel Tektronix und National Instruments . Ich habe absolut keine Chance, mit ihnen in Bezug auf die Qualität der Präsentation des Materials zu konkurrieren. Wenn Sie interessiert sind, folgen Sie bitte den Links.
Alles, was ich über die physikalische Schicht wissen muss, um ein Mehrkanalfilter zu erstellen, ist der Frequenzgitterschritt und die Modulationsrate. Sie sind in einem der folgenden Dokumente aufgeführt:
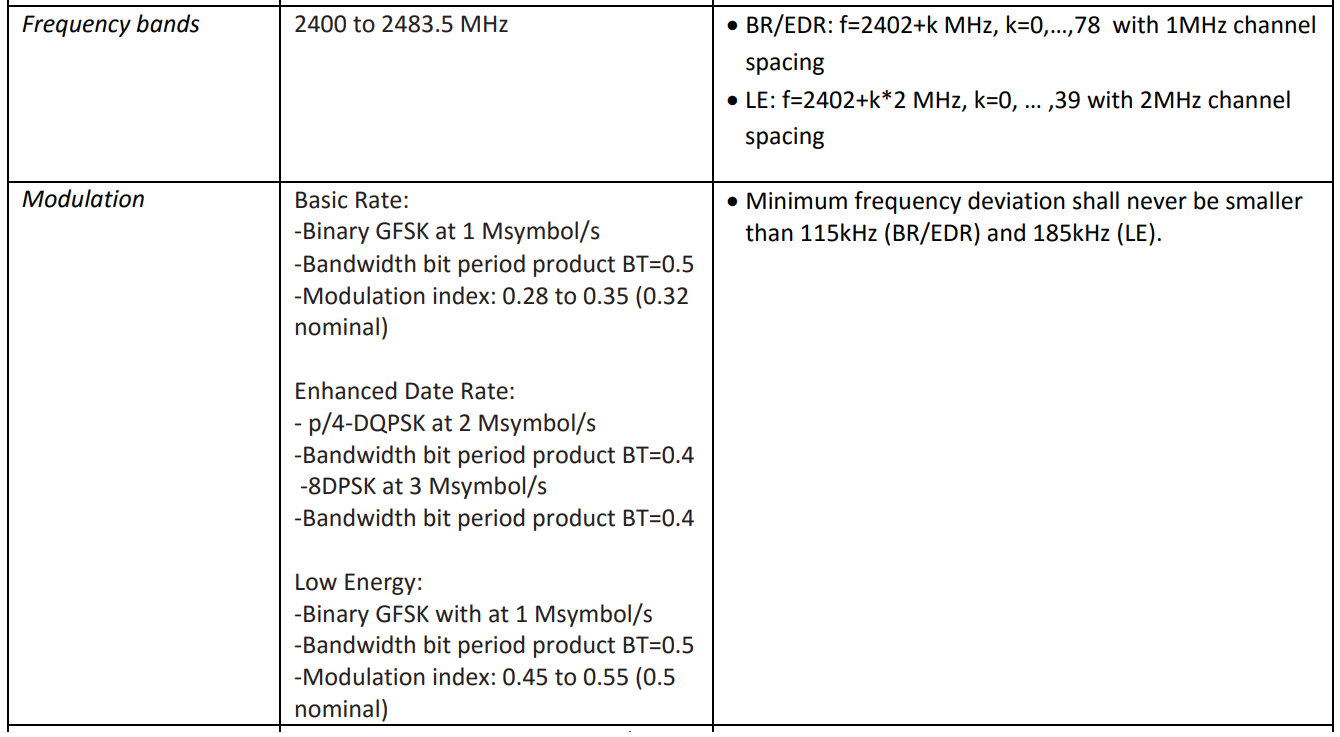
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
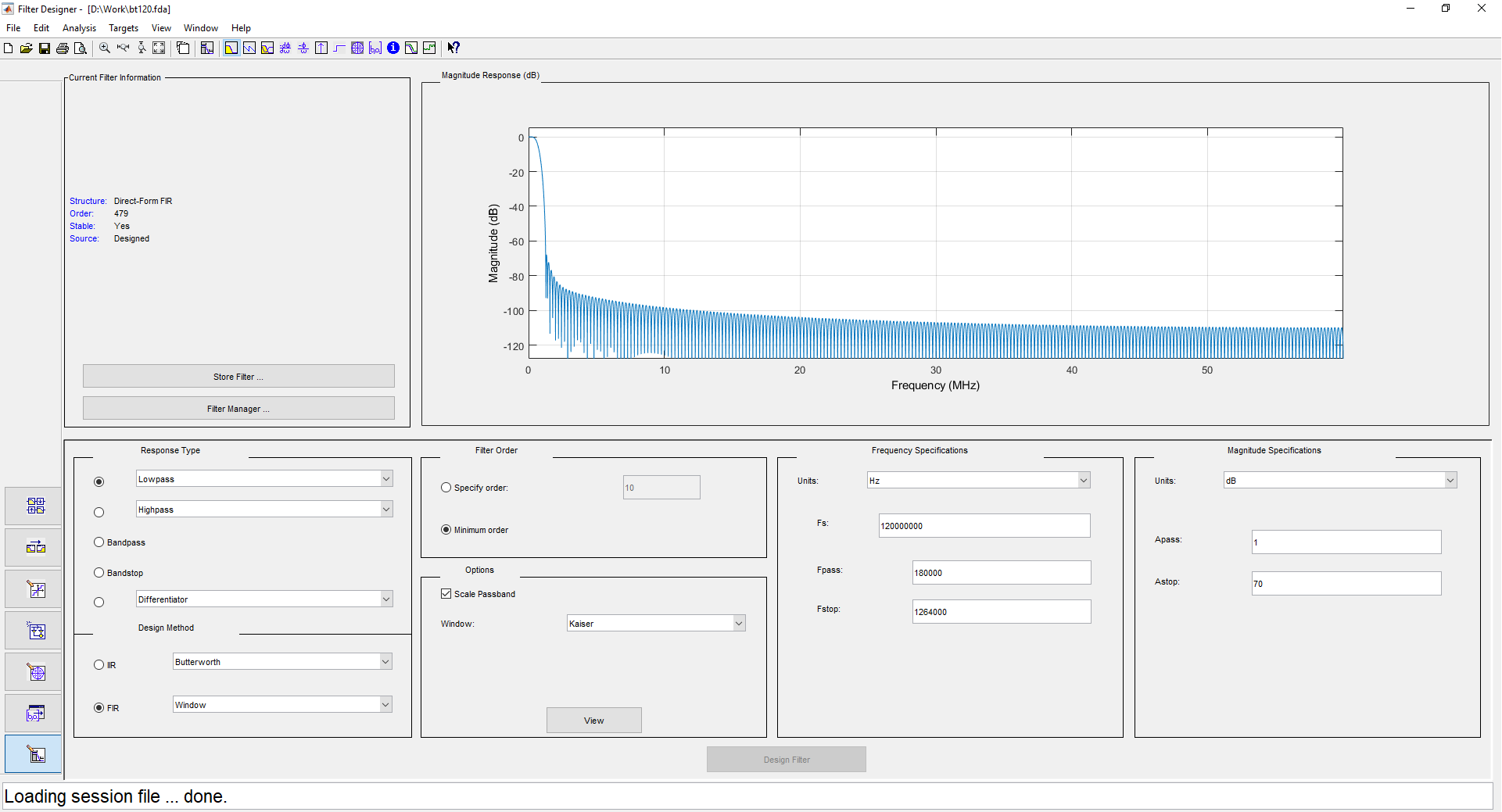
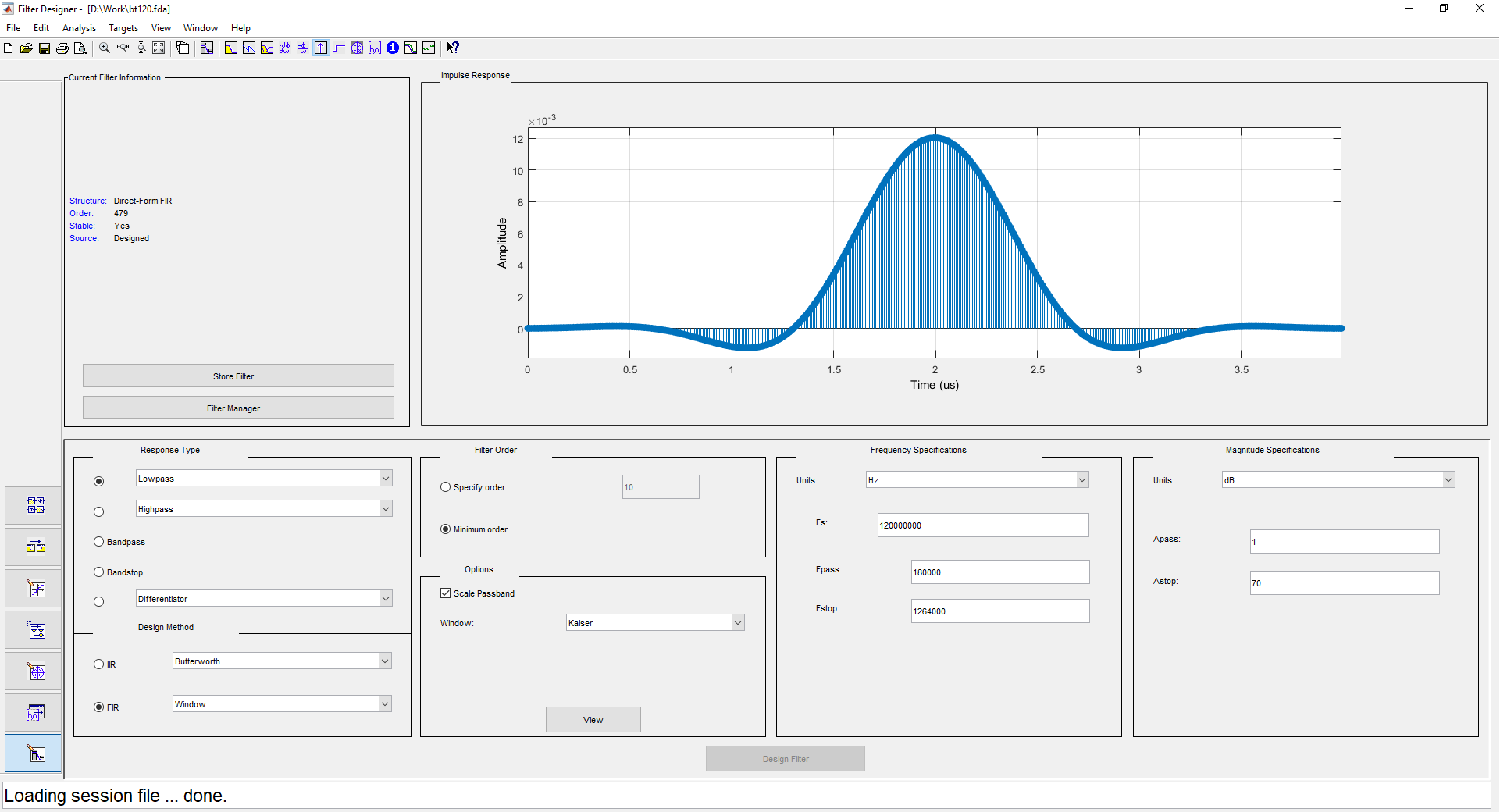
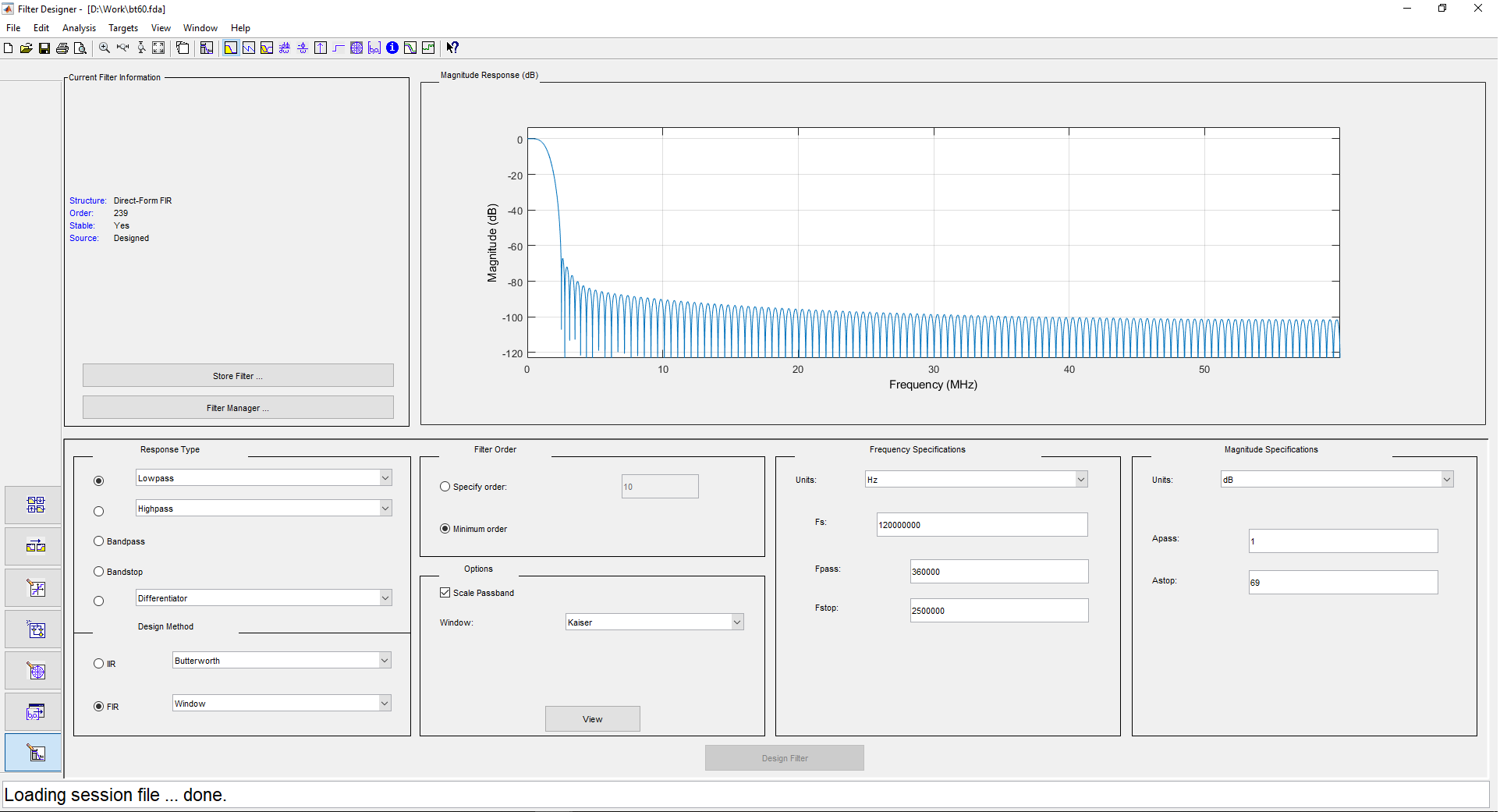
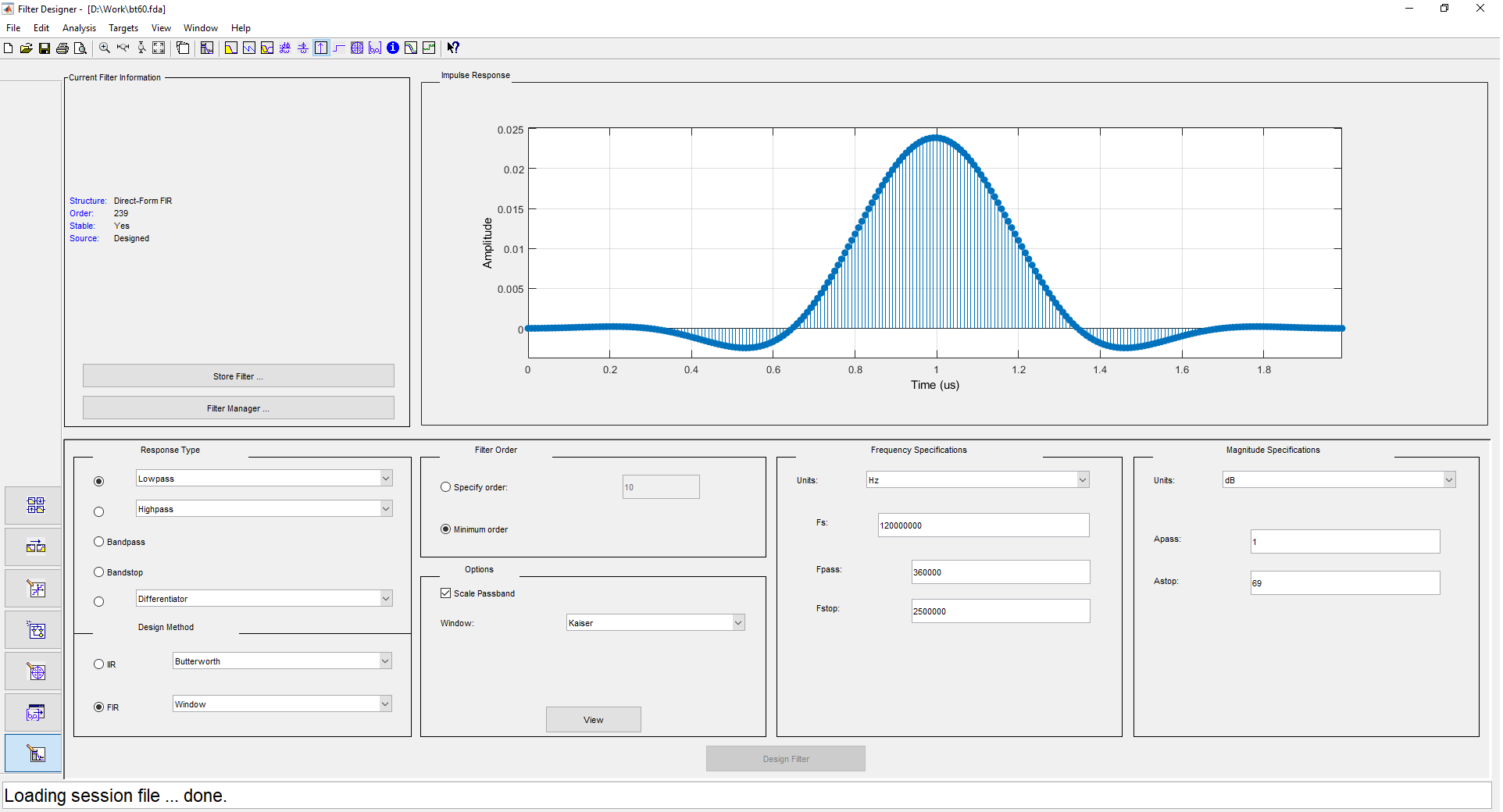
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
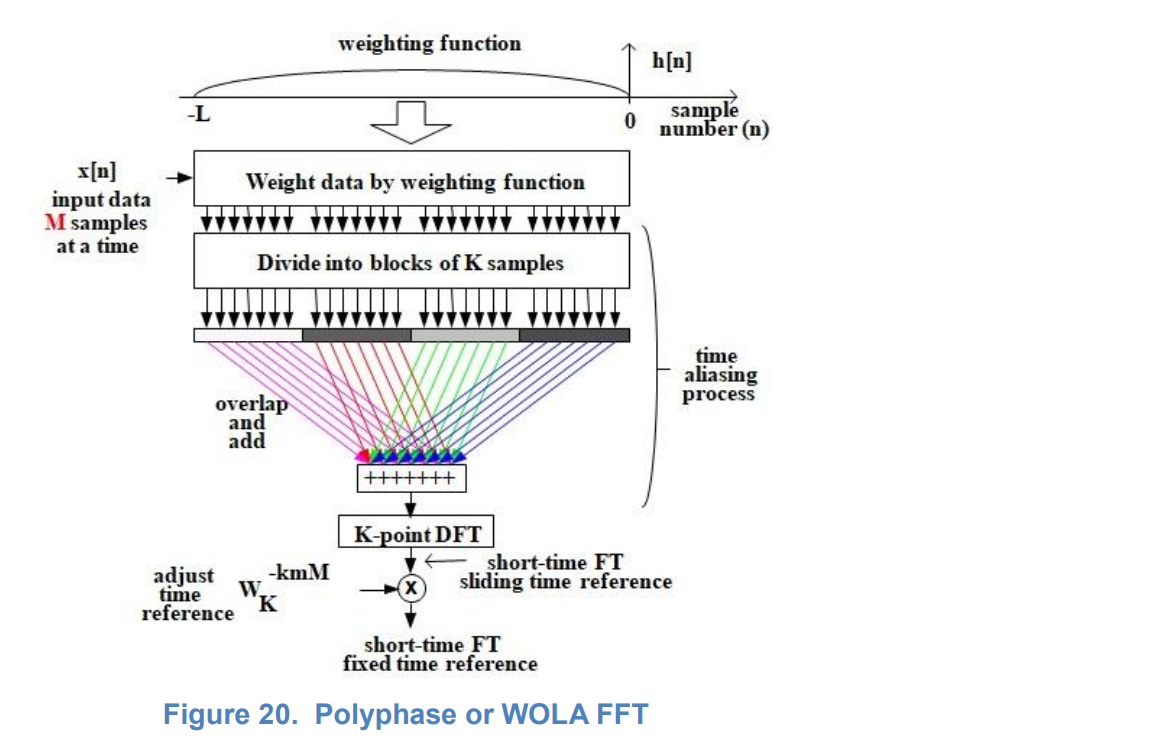
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
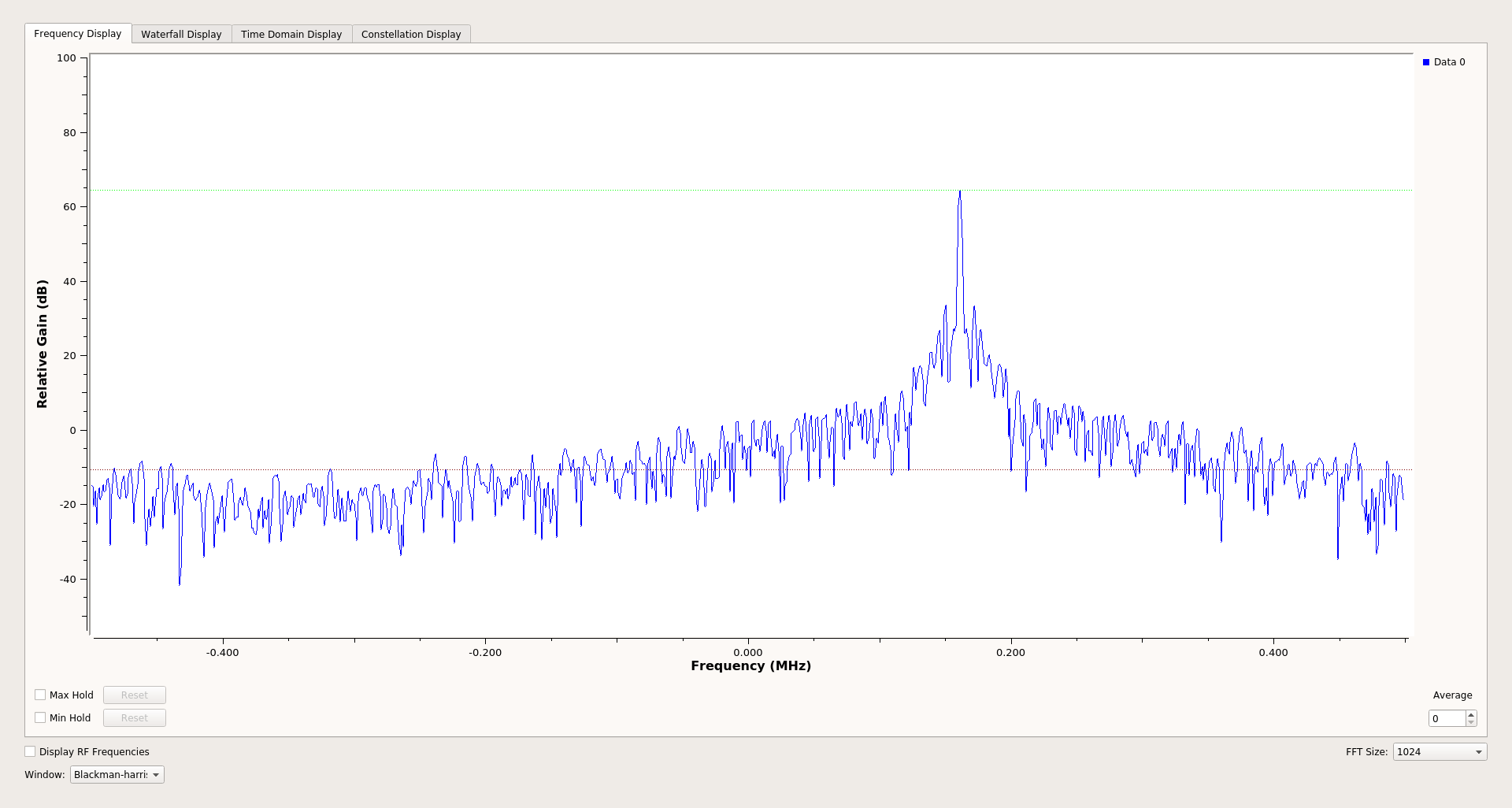
: XRTX , - .
gaudima, !