
Die Ausrüstung kam einige Monate vor dem Höhepunkt des Umsatzes am Standort an. Der Wartungsservice weiß natürlich, wie und was auf den Servern zu konfigurieren ist, um sie in die Produktionsumgebung einzuführen. Aber wir mussten dies automatisieren und den menschlichen Faktor beseitigen. Darüber hinaus wurden die Server vor der Migration einer Reihe von für das Unternehmen wichtigen SAP-Systemen ausgetauscht.
Die Inbetriebnahme neuer Server war eng an eine Frist gebunden. Und ein Umzug würde sowohl den Versand der Milliarden Geschenke als auch die Migration von Systemen gefährden. Auch ein Team aus Santa Claus und Santa Claus konnte das Datum nicht ändern - das SAP-System für die Lagerverwaltung kann nur einmal im Jahr übertragen werden. Vom 31. Dezember bis 1. Januar stellen die riesigen Lagerhäuser des Einzelhändlers, insgesamt 20 Fußballfelder, ihre Arbeit für 15 Stunden ein. Und dies ist die einzige Zeitspanne, in der sich das System bewegt. Wir hatten nicht das Recht, beim Betreten der Server einen Fehler zu machen.
Lassen Sie mich gleich erklären: Meine Geschichte spiegelt die Tools und den Konfigurationsmanagementprozess wider, die unser Team verwendet.
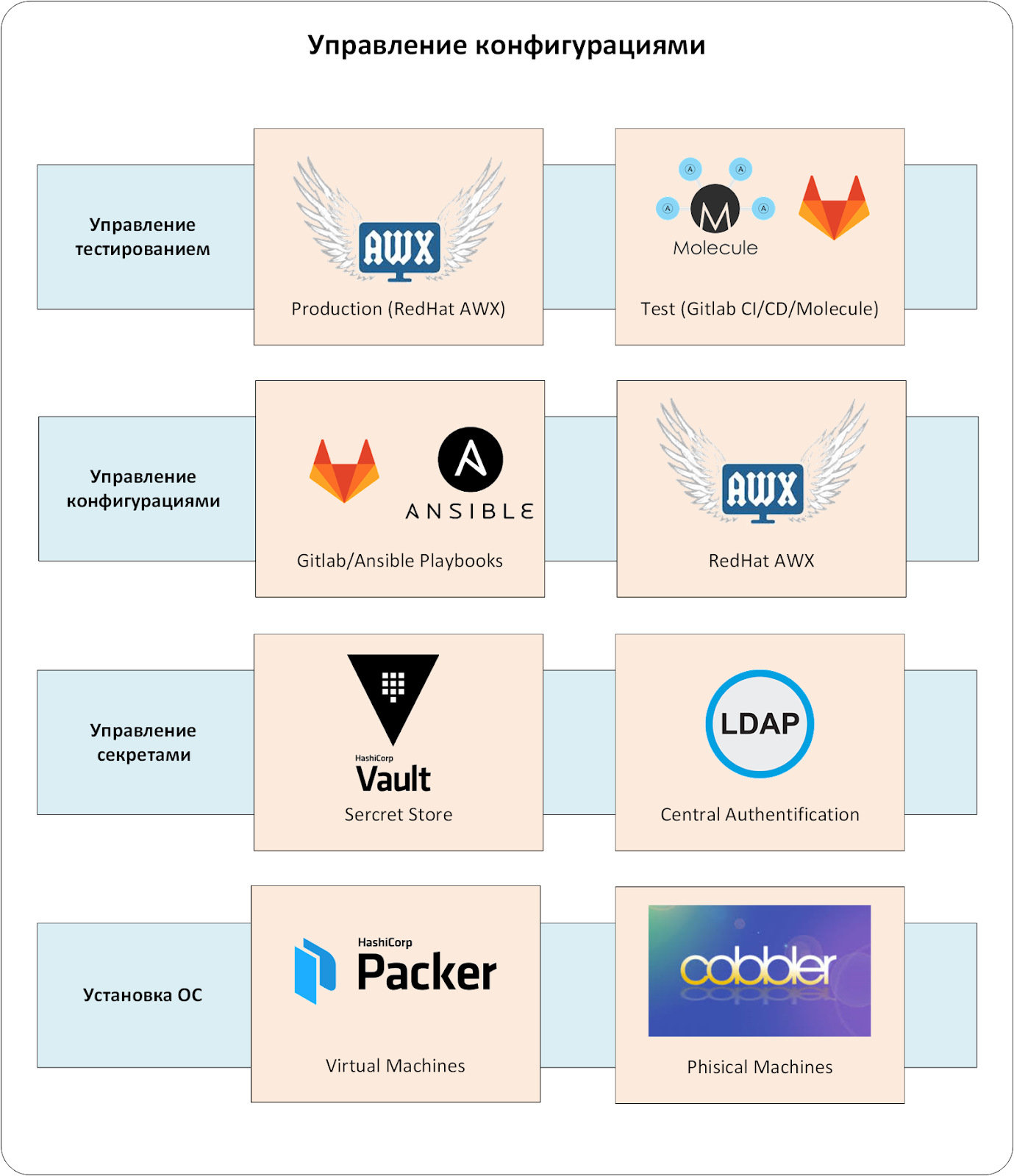
Der Konfigurationsverwaltungskomplex besteht aus mehreren Ebenen. Die Schlüsselkomponente ist das CMS-System. Bei der industriellen Ausbeutung würde das Fehlen einer der Ebenen unweigerlich zu unangenehmen Wundern führen.
Verwaltung der Betriebssysteminstallation
Die erste Ebene ist das System zum Verwalten der Installation von Betriebssystemen auf physischen und virtuellen Servern. Es werden grundlegende Betriebssystemkonfigurationen erstellt, wobei der menschliche Faktor eliminiert wird.
Mit Hilfe dieses Systems haben wir Standard erhalten und sind für weitere Automatisierungsinstanzen von Servern mit Betriebssystem geeignet. Bei der Besetzung erhielten sie einen minimalen Satz lokaler Benutzer und öffentlicher SSH-Schlüssel sowie eine konsistente Betriebssystemkonfiguration. Wir konnten garantieren, dass die Server über das CMS verwaltet werden, und waren uns sicher, dass es auf Betriebssystemebene keine Überraschungen „unten“ gab.
Das maximale Ziel für das Installationsmanagementsystem besteht darin, Server vom BIOS / Firmware-Level bis zum Betriebssystem automatisch zu konfigurieren. Viel hängt von den Hardware- und Konfigurationsaufgaben ab. Berücksichtigen Sie bei unterschiedlichen Geräten die REDFISH-API... Wenn die gesamte Hardware von einem Hersteller stammt, ist es häufig bequemer, vorgefertigte Verwaltungstools zu verwenden (z. B. HP ILO Amplifier, DELL OpenManage usw.).
Für die Installation des Betriebssystems auf physischen Servern haben wir den bekannten Cobbler verwendet, der eine Reihe von Installationsprofilen definiert, die mit dem Wartungsdienst koordiniert sind. Wenn der Infrastruktur ein neuer Server hinzugefügt wird, bindet der Techniker die MAC-Adresse des Servers an das erforderliche Profil in Cobbler. Beim ersten Start über das Netzwerk erhielt der Server eine temporäre Adresse und ein neues Betriebssystem. Dann wurde es an die Ziel-VLAN / IP-Adressierung übertragen und arbeitete dort weiter. Ja, das Ändern von VLANs erfordert Zeit und erfordert Koordination, bietet jedoch zusätzlichen Schutz vor versehentlicher Serverinstallation in einer Produktionsumgebung.
Wir haben virtuelle Server basierend auf Vorlagen erstellt, die mit HashiCorp Packer erstellt wurden. Der Grund war der gleiche: um mögliche menschliche Fehler bei der Installation des Betriebssystems zu vermeiden. Im Gegensatz zu physischen Servern können Sie mit Packer jedoch keine PXE-, Netzwerkstart- und VLAN-Änderungen verwenden. Dies machte es immer einfacher, virtuelle Server zu erstellen.
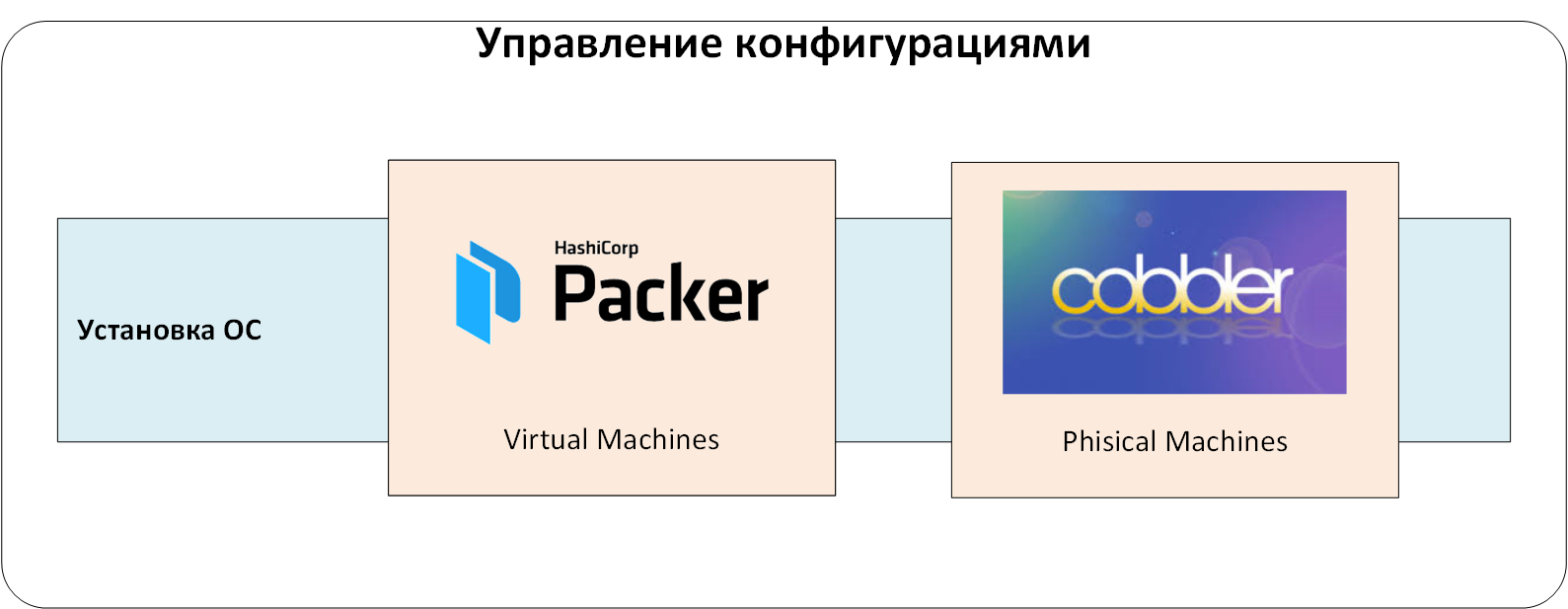
Zahl: 1. Verwaltung der Installation von Betriebssystemen.
Geheime Verwaltung
Jedes Konfigurationsverwaltungssystem enthält Daten, die für normale Benutzer verborgen sein sollten, aber zur Vorbereitung der Systeme benötigt werden. Dies sind Kennwörter lokaler Benutzer und Dienstkonten, Zertifikatschlüssel, verschiedene API-Token usw. Normalerweise werden sie als "Geheimnisse" bezeichnet.
Wenn von Anfang an nicht festgelegt ist, wo und wie diese Geheimnisse gespeichert werden sollen, sind abhängig von der Schwere der IS-Anforderungen die folgenden Speichermethoden wahrscheinlich:
- direkt im Konfigurationsverwaltungscode oder in Dateien im Repository;
- in speziellen Konfigurationsmanagement-Tools (z. B. Ansible Vault);
- in CI / CD-Systemen (Jenkins / TeamCity / GitLab / usw.) oder in Konfigurationsmanagementsystemen (Ansible Tower / Ansible AWX);
- Auch Geheimnisse können auf "manuelle Steuerung" übertragen werden. Beispielsweise werden sie an einem vereinbarten Ort angeordnet und dann von Konfigurationsmanagementsystemen verwendet.
- verschiedene Kombinationen der oben genannten.
Jede Methode hat ihre eigenen Nachteile. Das wichtigste ist das Fehlen von Richtlinien für den Zugriff auf Geheimnisse: Es ist unmöglich oder schwierig zu bestimmen, wer bestimmte Geheimnisse verwenden kann. Ein weiterer Nachteil ist das Fehlen einer Zugriffsprüfung und ein vollständiger Lebenszyklus. Wie kann man beispielsweise einen öffentlichen Schlüssel, der im Code und in einer Reihe verwandter Systeme geschrieben ist, schnell ersetzen?
Wir haben das zentralisierte HashiCorp-Gewölbe verwendet. Dies erlaubte uns:
- Geheimnisse bewahren. Sie sind verschlüsselt, und selbst wenn jemand Zugriff auf die Vault-Datenbank erhält (z. B. durch Wiederherstellen aus einer Sicherung), kann er die dort gespeicherten Geheimnisse nicht lesen.
- . «» ;
- . Vault;
- « » . , , . .
- , ;
- , , ..
Kommen wir nun zum zentralen Authentifizierungs- und Autorisierungssystem. Sie könnten darauf verzichten, aber die Verwaltung von Benutzern in vielen verwandten Systemen ist zu trivial. Wir haben die Authentifizierung und Autorisierung über den LDAP-Dienst konfiguriert. Andernfalls müsste derselbe Tresor fortlaufend Authentifizierungstoken für Benutzer ausstellen und Aufzeichnungen darüber führen. Das Löschen und Hinzufügen von Benutzern würde zu einer Quest "Habe ich diese UZ überall erstellt / gelöscht?"
Wir erweitern unser System um eine weitere Ebene: Verwaltung von Geheimnissen und zentrale Authentifizierung / Autorisierung:
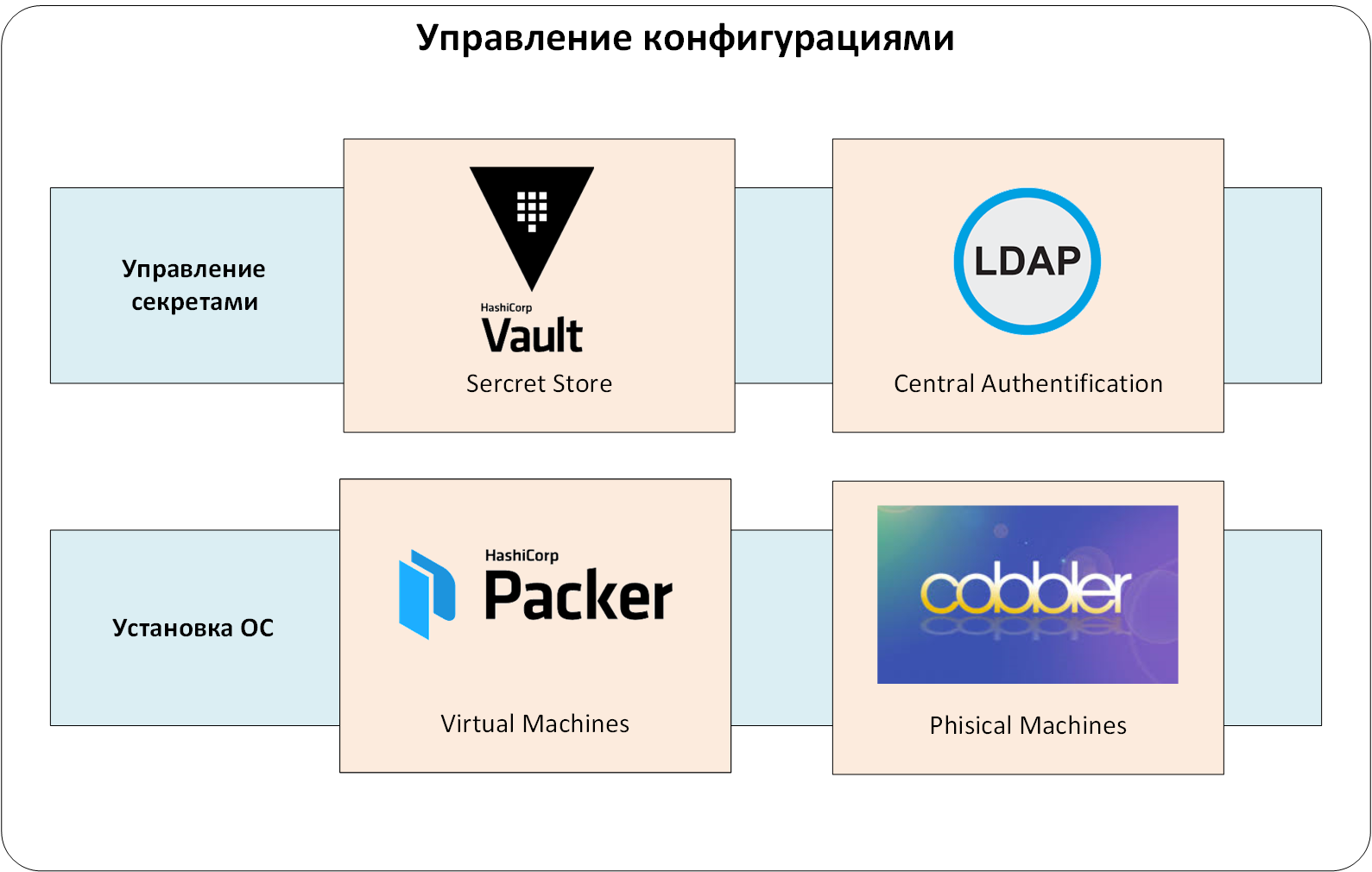
Zahl: 2. Verwaltung von Geheimnissen.
Konfigurationsmanagement
Wir sind zum Kern gekommen - zum CMS-System. In unserem Fall handelt es sich um eine Reihe von Ansible und Red Hat Ansible AWX.
Chef, Puppet, SaltStack kann anstelle von Ansible agieren. Wir haben uns aus mehreren Gründen für Ansible entschieden.
- Erstens ist es Vielseitigkeit. Der Satz vorgefertigter Steuerungsmodule ist beeindruckend . Und wenn Sie nicht genug haben, können Sie auf GitHub und Galaxy suchen.
- Zweitens müssen keine Agenten auf kontrollierten Geräten installiert und gewartet werden, um nachzuweisen, dass sie die Last nicht stören, und um das Fehlen von "Lesezeichen" zu bestätigen.
- Drittens hat Ansible eine niedrige Eintrittsbarriere. Ein kompetenter Ingenieur wird am ersten Tag der Arbeit mit dem Produkt buchstäblich ein funktionierendes Spielbuch schreiben.
Aber Ansible allein hat uns in einem industriellen Umfeld nicht gereicht. Andernfalls würde es viele Probleme geben, den Zugriff einzuschränken und die Aktionen von Administratoren zu überwachen. Wie kann man den Zugang unterscheiden? Schließlich musste jede Abteilung "ihre" Server verwalten (das Ansible-Playbook lesen - ausführen). Wie kann ich nur bestimmten Mitarbeitern erlauben, bestimmte Ansible-Playbooks auszuführen? Oder wie kann man nachverfolgen, wer ein Playbook gestartet hat, ohne viele lokale KMs auf Ansible-Servern und -Hardware auszuführen?
Der Red Hat Ansible Tower oder sein Open-Source-Upstream-Projekt Ansible AWX lösen den Löwenanteil dieser Probleme . Deshalb haben wir es für den Kunden bevorzugt.
Und noch eine Berührung zum Porträt unseres CMS-Systems. Ansible Playbook muss in Code-Repository-Verwaltungssystemen gespeichert werden. Wir haben dieses GitLab CE .
Die Konfigurationen selbst werden also vom Bundle von Ansible / Ansible AWX / GitLab verwaltet (siehe Abb. 3). Natürlich ist AWX / GitLab in das einheitliche Authentifizierungssystem integriert, und das Ansible-Playbook ist in den HashiCorp-Tresor integriert. Konfigurationen werden nur über Ansible AWX in die Produktionsumgebung eingegeben, in dem alle "Spielregeln" festgelegt sind: Wer und was kann konfiguriert werden, wo erhält man den Konfigurationsverwaltungscode für das CMS usw.
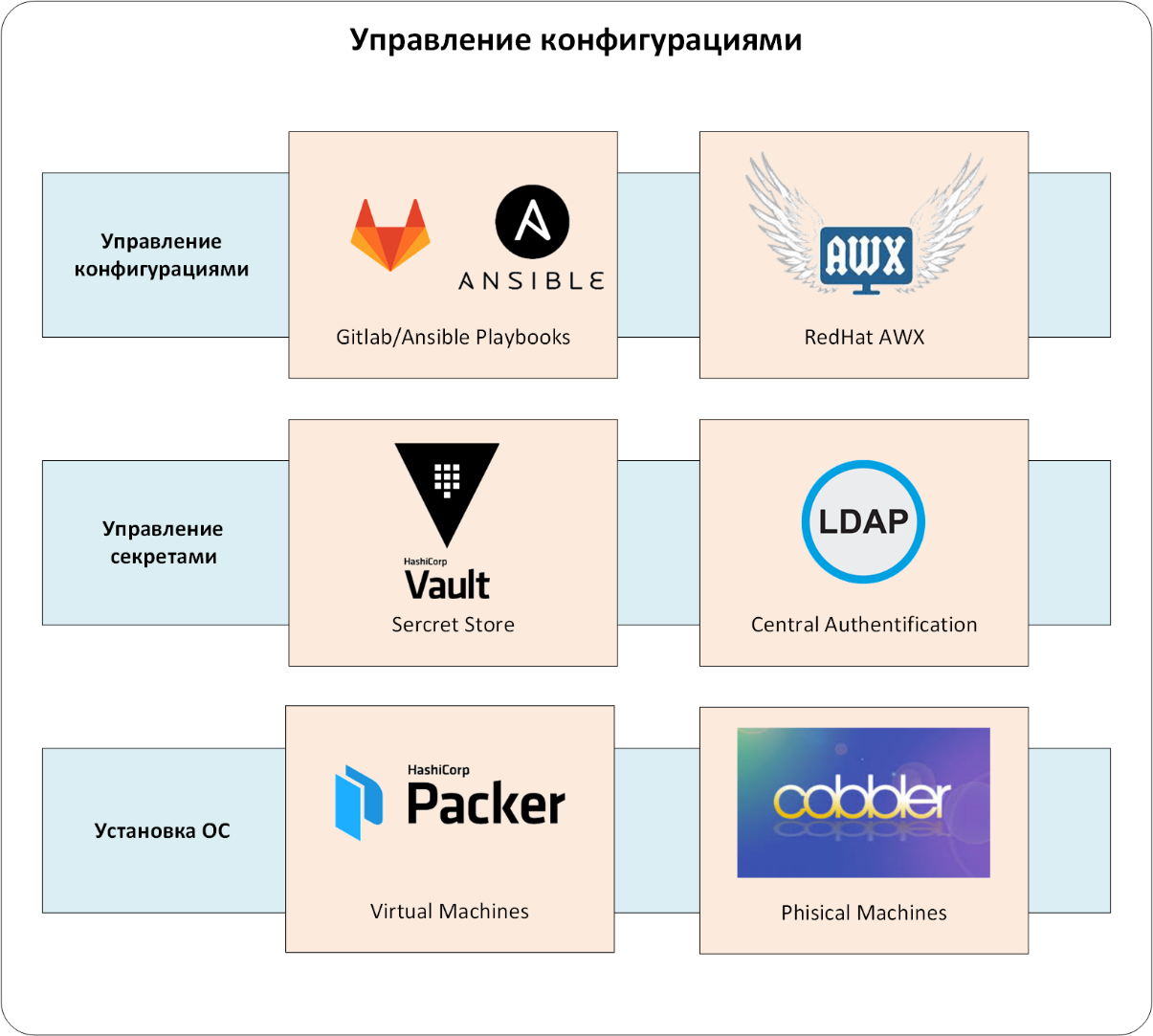
Zahl: 3. Konfigurationsverwaltung.
Testmanagement
Unsere Konfiguration wird als Code dargestellt. Daher sind wir gezwungen, nach den gleichen Regeln wie Softwareentwickler zu spielen. Wir mussten die Entwicklungsprozesse, das kontinuierliche Testen, die Bereitstellung und die Anwendung von Konfigurationscode auf Produktionsserver organisieren.
Wenn dies nicht sofort geschehen würde, würden die schriftlichen Rollen für die Konfiguration entweder nicht mehr beibehalten und geändert oder in der Produktion nicht mehr ausgeführt. Die Heilung für diesen Schmerz ist bekannt und hat sich in diesem Projekt ausgezahlt:
- Jede Rolle wird durch Unit-Tests abgedeckt.
- Tests werden automatisch ausgeführt, wenn sich der Konfigurationsverwaltungscode ändert.
- Änderungen im Konfigurationsverwaltungscode werden erst in die Produktionsumgebung übernommen, nachdem alle Tests und die Codeüberprüfung erfolgreich bestanden wurden.
Codeentwicklung und Konfigurationsmanagement sind ruhiger und vorhersehbarer. Um kontinuierliche Tests zu organisieren, haben wir das GitLab CI / CD-Toolkit verwendet und Ansible Molecule als Framework für die Organisation von Tests verwendet .
Bei Änderungen im Konfigurationsverwaltungscode ruft GitLab CI / CD Molecule auf:
- es überprüft die Syntax des Codes,
- hebt den Docker-Container an,
- wendet den geänderten Code auf den generierten Container an.
- Überprüft die Rolle auf Idempotenz und führt Tests für diesen Code durch (die Granularität liegt hier auf der Ebene der ansiblen Rollen, siehe Abb. 4).
Wir haben Konfigurationen mit Ansible AWX an die Produktionsumgebung geliefert. Die Betriebsingenieure haben Konfigurationsänderungen über vordefinierte Vorlagen vorgenommen. AWX "forderte" unabhängig die neueste Version des Codes bei jeder Verwendung vom GitLab-Hauptzweig an. Auf diese Weise haben wir die Verwendung von nicht getestetem oder veraltetem Code in der Produktionsumgebung ausgeschlossen. Natürlich gelangte der Code erst nach Prüfung, Überprüfung und Genehmigung in die Hauptniederlassung.
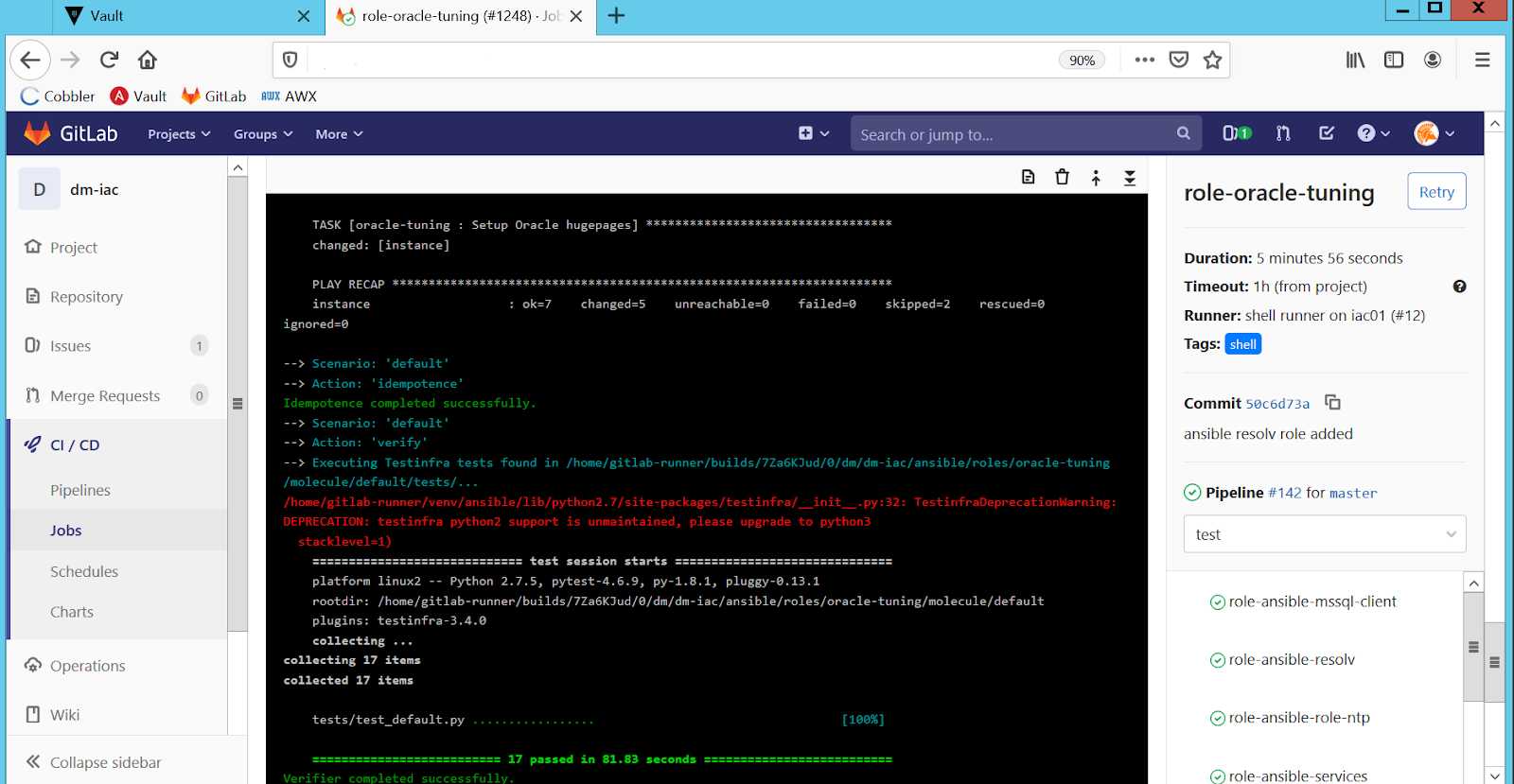
Zahl: 4. Automatisches Testen von Rollen in GitLab CI / CD.
Es gibt auch ein Problem im Zusammenhang mit dem Betrieb von Produktionssystemen. Im wirklichen Leben ist es sehr schwierig, Konfigurationsänderungen nur über den CMS-Code vorzunehmen. Anormale Situationen treten auf, wenn ein Techniker die Konfiguration „hier und jetzt“ ändern muss, ohne auf die Bearbeitung, das Testen, die Genehmigung usw. des Codes zu warten.
Aufgrund manueller Änderungen treten daher Abweichungen in der Konfiguration auf demselben Gerätetyp auf (z. B. auf den Knoten des HA-Clusters) unterschiedliche Konfiguration der Systemeinstellungen). Oder die tatsächliche Konfiguration auf der Hardware unterscheidet sich von der im CMS-Code festgelegten.
Daher überprüfen wir neben kontinuierlichen Tests auch Produktionsumgebungen auf Konfigurationsdifferenzen. Wir haben die einfachste Option gewählt: Ausführen des CMS-Konfigurationscodes im Trockenlaufmodus, dh ohne Änderungen vorzunehmen, jedoch mit Benachrichtigung über alle Abweichungen zwischen der geplanten und der tatsächlichen Konfiguration. Wir haben dies implementiert, indem wir regelmäßig alle Ansible-Playbooks mit der Option "--check" auf Produktionsservern ausführen. Ansible AWX ist wie immer für den Start und die Relevanz des Playbooks verantwortlich (siehe Abb. 5):
Zahl: 5. Überprüft Ansible AWX auf Konfigurationsdifferenzen.
Nach der Überprüfung sendet AWX einen Diskrepanzbericht an die Administratoren. Sie untersuchen die Problemkonfiguration und beheben sie dann über das angepasste Playbook. Auf diese Weise pflegen wir die Konfiguration in der Produktionsumgebung und das CMS ist immer aktuell und synchronisiert. Dies beseitigt die unangenehmen "Wunder", wenn der CMS-Code auf "Produktions" -Servern angewendet wird.
Wir haben jetzt eine wichtige Testschicht, die aus Ansible AWX / GitLab / Molecule besteht (Abbildung 6).
Zahl: 6. Testmanagement.
Hart? Ich streite nicht. Ein solcher Konfigurationsverwaltungskomplex ist jedoch zu einer umfassenden Antwort auf viele Fragen im Zusammenhang mit der Automatisierung der Serverkonfiguration geworden. Jetzt hat der Händler immer eine streng definierte Konfiguration für Standardserver. Im Gegensatz zu einem Ingenieur wird CMS nicht vergessen, die erforderlichen Einstellungen hinzuzufügen, Benutzer zu erstellen und zehn oder Hunderte der erforderlichen Einstellungen vorzunehmen.
In den Einstellungen von Servern und Umgebungen gibt es heute kein "geheimes Wissen". Alle notwendigen Funktionen sind im Playbook enthalten. Keine Kreativität und keine vagen Anweisungen mehr: „ Sagen Sie es wie ein normales Oracle, aber dort müssen Sie einige sysctl-Einstellungen registrieren und Benutzer mit der erforderlichen UID hinzufügen. Fragen Sie die Jungs von der Operation, sie wissen es . "
Die Möglichkeit, Konfigurationsabweichungen zu erkennen und im Voraus zu korrigieren, gibt Ihnen Sicherheit. Ohne CMS sieht dies normalerweise anders aus. Probleme häufen sich, bis sie eines Tages in der Produktion "erschossen" werden. Anschließend wird eine Nachbesprechung durchgeführt, die Konfigurationen überprüft und korrigiert. Und der Zyklus wiederholt sich erneut.
Und natürlich haben wir den Start von Servern in der Produktion von einigen Tagen auf Stunden beschleunigt.
Nun, an Silvester selbst, als Kinder glücklich Geschenke auspackten und Erwachsene Wünsche an das Glockenspiel stellten, migrierten unsere Ingenieure das SAP-System auf neue Server. Sogar der Weihnachtsmann wird sagen, dass die besten Wunder gut vorbereitet sind.
PS Unser Team ist häufig mit der Tatsache konfrontiert, dass Kunden das Problem des Konfigurationsmanagements so einfach wie möglich lösen möchten. Idealerweise wie von Zauberhand - mit einem Werkzeug. Aber im Leben ist alles komplizierter (ja, wieder wurden keine Silberkugeln geliefert): Sie müssen einen ganzen Prozess mit Hilfe von Werkzeugen erstellen, die für das Kundenteam bequem sind.
Autor: Sergey Artemov, Architekt der DevOps-Lösungsabteilung von Jet Infosystems