Jetzt müssen wir lernen, wie wir die Logik beschreiben, die mit den empfangenen Daten arbeitet, und ein Urteil darüber abgeben, ob unsere Regel in einer bestimmten Situation funktioniert. Diesem Abschnitt der Regel und ihren Funktionen ist dieser Artikel gewidmet. Die Beschreibung des Erkennungslogikabschnitts ist der wichtigste Teil der Syntax, deren Kenntnis erforderlich ist, um die vorhandenen Regeln zu verstehen und eigene Regeln zu schreiben.
In der nächsten Veröffentlichung werden wir uns ausführlich mit der Beschreibung von Metainformationen (informative oder infrastrukturelle Attribute wie eine Beschreibung oder Kennung) und Regelsammlungen befassen. Folgen Sie unseren Veröffentlichungen!
Beschreibung der Erkennungslogik (Erkennungsattribut)
Regeln, die Bedingungen auslösen, werden im Erkennungsattribut festgelegt . Seine Unterfelder beschreiben den technischen Hauptteil der Regel. Es ist wichtig zu beachten, dass eine Regel nur einen beschreibenden Teil und mehrere Protokollquellen und -erkennungen enthalten kann. Da der Erkennungsabschnitt das Auslösekriterium basierend auf Daten aus dem Quellenabschnitt beschreibt, haben diese beiden Abschnitte eine 1 zu 1.
Im Allgemeinen besteht der Inhalt des Erkennungsfelds aus zwei logischen Teilen:
- eine Beschreibung der Annahmen zu den Ereignisfeldern (Such-IDs),
- die logische Beziehung zwischen diesen Beschreibungen ( Zeitrahmen und Ausdruck im Bedingungsfeld ).

Die Beschreibung der Annahmen über den Inhalt der Ereignisfelder erfolgt durch Angabe von Suchkennungen. Eine solche Kennung kann eine sein (wie hier ) oder es kann mehrere von ihnen geben (wie hier ).
Der zweite Teil kann von drei Arten sein:
- der übliche Zustand,
- eine Bedingung mit einem aggregierten Ausdruck (wie im obigen Beispiel),
- Bedingung mit dem Schlüsselwort in der Nähe .
Die Syntax der Elemente jedes Teils wird im entsprechenden Abschnitt dieses Artikels beschrieben.
IDs suchen
Eine Suchkennung ist ein Schlüssel-Wert-Paar, wobei der Schlüssel der Name der Suchkennung ist und der Wert eine Liste oder ein Wörterbuch (auch als assoziatives Array bezeichnet). In Analogie zu Programmiersprachen - Liste oder Karte. Das Format für die Angabe von Listen und Wörterbüchern wird durch den YAML-Standard definiert, den Sie hier finden . Es ist erwähnenswert, dass das Sigma-Regelformat die Namen der Suchkennungen nicht festlegt, aber meistens können Sie Variationen bei der Wortauswahl finden.
Es gibt allgemeine Anforderungen, die sowohl für Listenelemente als auch für Vokabeln gelten:
- Alle Werte werden als Zeichenfolgen behandelt, bei denen die Groß- und Kleinschreibung nicht berücksichtigt wird. Das heißt, es gibt keinen Unterschied zwischen Groß- und Kleinbuchstaben.
- (wildcards) ‘*’ ‘?’. ‘*’ — ( ), ‘?’ — ( ).
- ‘\’, ‘\*’. , : ‘\\*’. .
- , .
- ‘ .
Werteliste
Suchkennung Wertelisten enthalten Zeichenfolgen, nach denen in der gesamten Ereignismeldung gesucht wird. Die Elemente der Liste werden mit einem logischen ODER kombiniert.
detection:
keywords:
- EVILSERVICE
- svchost.exe -n evil
condition: keywords

Beispiele für Regeln, die Suchkennungen als Werteliste enthalten:
- rules / web / web_apache_segfault.yml (die Liste kann ein Element enthalten)
- rules / windows / Powershell / Powershell_clear_powershell_history.yml
- rules / linux / lnx_shell_susp_log_entries.yml
Kennung der Wörterbuchsuche
Wörterbücher bestehen aus einer Reihe von Schlüssel-Wert-Paaren, wobei der Schlüssel der Name des Felds aus dem Ereignis ist und der Wert eine Zeichenfolge, eine Ganzzahl oder eine Liste eines dieser Typen sein kann (Listen von Zeichenfolgen oder Zahlen werden mit einem logischen ODER kombiniert). Sätze von Wörterbüchern werden durch logisches UND kombiniert.
Allgemeines Schema:
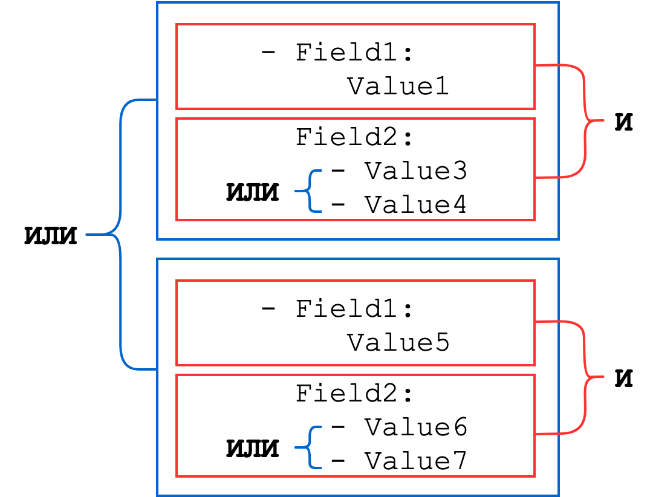
Betrachten wir einige Beispiele.
Beispiel 1. Regeln für die Erkennung von Ereignisprotokollbereinigungsregeln
/ windows / builtin / win_susp_security_eventlog_cleared.yml
Diese Regel wird ausgelöst, wenn das Ereignis die Bedingung erfüllt:
EventID = 517 OR EventID = 1102
In der Regel sieht es folgendermaßen aus:
detection:
selection:
EventID:
- 517
- 1102
condition: selection Hier ist die Auswahl der Name der einzigen Suchkennung, und der Rest der Unterfelder ist ihr Wert, und dieser Wert ist vom Typ "Wörterbuch". In diesem Wörterbuch ist EventID der Schlüssel, und die Nummern 517 und 1102 bilden eine Liste, die den Wert dieses Wörterbuchschlüssels darstellt.
Beispiel 2. Eine verdächtige Ticketanforderung, höchstwahrscheinlich Kerberoasting-
Regeln / windows / builtin / win_susp_rc4_kerberos.yml
Diese Regel wird ausgelöst, wenn das Ereignis die Bedingung erfüllt:
EventID = 4679 AND TicketOptions = 0x40810000 AND TicketEncryption = 0x17 AND ServiceName endet nicht mit einem '$'-Zeichen.
In der Regel sieht es folgendermaßen aus:
detection:
selection:
EventID: 4769
TicketOptions: '0x40810000'
TicketEncryption: '0x17'
reduction:
- ServiceName: '*$'
condition: selection and not reduction Spezielle Feldwerte
Es gibt zwei spezielle Feldwerte, die verwendet werden können:
- Ein leerer Wert, der durch zwei einfache Anführungszeichen '' angegeben wird
- Der durch das Schlüsselwort null angegebene Nullwert
Hinweis: Ein nicht leerer Wert kann nicht über das Konstrukt not null angegeben werden
Die Anwendung dieser Werte hängt vom Ziel-SIEM-System ab. Um die Nicht-Null-Bedingung zu beschreiben, müssen Sie eine separate Suchkennung mit einem leeren Wert erstellen und daraus die Negation in der Bedingung entnehmen (das Bedingungsfeld wird am Ende des Artikels beschrieben). Betrachten Sie weitere Beispiele für Regeln, die die Beschreibung eines leeren Felds verwenden.
Beispiel 3. Verdächtiger Start eines Remote-Streams
rules / windows / sysmon / sysmon_password_dumper_lsass.yml
Die angegebene Regel wird ausgelöst, wenn das Ereignis die Bedingung erfüllt:
EventID = 8 AND TargetImage = 'C: \ Windows \ System32 \ lsass.exe' UND StartModule ist ein leeres Feld.
In der Regel sieht es folgendermaßen aus:
detection:
selection:
EventID: 8
TargetImage: 'C:\Windows\System32\lsass.exe'
StartModule: null
condition: selection Beispiel 4. Schreiben einer ausführbaren Datei in einen alternativen Dateistream NTFS
rules / windows / sysmon / sysmon_ads_executable.yml
Die betrachtete Regel ist ein Beispiel für die korrekte Bezeichnung eines nicht leeren Werts. Diese Regel wird ausgelöst, wenn das Ereignis die Bedingung erfüllt:
EventID = 15 AND I
mphash != '00000000000000000000000000000000' Imphash
In der Regel sieht es folgendermaßen aus:
detection:
selection:
EventID: 15
filter:
Imphash:
- '00000000000000000000000000000000'
- null
condition: selection and not filter Wie oben erwähnt, muss die Negation jetzt in die Bedingung (das Bedingungsfeld) und nicht in die Suchkennungen eingefügt werden.
Wertmodifikatoren
Die Interpretation von Feldwerten in einer Regel kann mithilfe von Modifikatoren geändert werden. Modifikatoren werden nach dem Feldnamen hinzugefügt. Vor jedem Modifikator steht ein vertikaler Balken (Pipe) - "|". Sie können verkettet werden, um Ketten (Pipelines) von Modifikatoren zu bilden:

Der Feldwert wird gemäß der Reihenfolge der Modifikatoren in der Kette geändert. Es gibt zwei Arten von Modifikatoren: Transformations- und Typmodifikatoren.
Transformationsmodifikatoren sind solche, die den ursprünglichen Feldwert in einen anderen Wert konvertieren oder die Logik zum Verarbeiten von Wertelisten in Suchkennungen transformieren. Ein Beispiel für den ersten Typ sind Base64-Modifikatoren, und der zweite ist der All- Modifikator . Alle Modifikatoren werden später ausführlicher besprochen.
Werfen wir einen Blick auf die einzelnen Transformationsmodifikatoren. Zur Verdeutlichung zeigen wir schematisch, wie genau dieser oder jener Modifikator den Anfangswert ändert.
beginnt mit
Der Modifikator " Start mit" wird verwendet, um den Anfang einer Zeichenfolge mit dem gewünschten Wert abzugleichen .

Anwendungsbeispiele:
- rules / windows / builtin / win_ad_replication_non_machine_account.yml
- rules / windows / process_creation / win_apt_winnti_mal_hk_jan20.yml
- rules / windows / Powershell / Powershell_downgrade_attack.yml
endet mit
Der Modifikator " Endswith" wird verwendet, um das Ende einer Zeichenfolge mit einem Suchwert abzugleichen .

Anwendungsbeispiele:
- rules / windows / process_creation / win_local_system_owner_account_discovery.yml
- rules / windows / sysmon / sysmon_minidumwritedump_lsass.yml
- rules / windows / process_creation / win_susp_odbcconf.yml
enthält
Der Modifikator enthält prüft das Auftreten eines Teilstrings im Feldwert. Tatsächlich konvertiert dieser Modifikator den Feldwert wie folgt:

Wenn wir also die Ergebnisse der Anwendung der betrachteten Modifikatoren berücksichtigen, können Sie die folgende Formel schreiben:
Start mit + Ende mit = enthält
Beispiele:
- rules / windows / process_creation / win_hack_bloodhound.yml
- rules / windows / process_creation / win_mimikatz_command_line.yml
- rules / windows / sysmon / sysmon_webshell_creation_detect.yml
alle
Normalerweise werden Blattelemente mit einem logischen ODER kombiniert. Der Modifikator all ändert das logische ODER in das logische UND. Das heißt, alle Elemente der Liste müssen vorhanden sein. Mal sehen, wie sich die Bedingungen im allgemeinen Schema am Anfang des Abschnitts ändern würden:
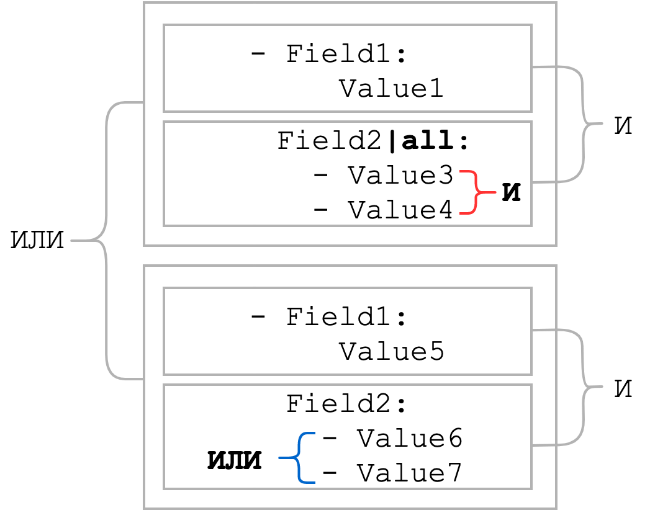
Wie Sie sehen, wurde beim Anwenden des Modifikators all die logische Verbindung zwischen den Listenelementen zu AND. Normalerweise wird der Modifikator all in Verbindung mit dem Modifikator enthält verwendet. Ein solches Bündel kann als Ersatz für das Muster durch Platzhalter-Metazeichen dienen, wenn die Reihenfolge der statischen Teile unbekannt ist.
Beispiele für die Verwendung des Modifikators all :
- rules / windows / builtin / win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- rules / windows / Powershell / Powershell_suspicious_profile_create.yml
- rules / windows / Powershell / Powershell_suspicious_download.yml
base64
Dieser Modifikator wird angewendet, wenn der Feldwert in Base64 codiert wird. Aus Gründen der Übersichtlichkeit schreiben wir den codierten Text in die Regel und nicht die resultierende Base64-Zeichenfolge.

Dieser Modifikator setzt eine genaue Übereinstimmung des Feldes mit der codierten Zeichenfolge voraus. In der Regel ist es sinnvoller, Anzeichen verdächtiger Aktivitäten in den Originaldaten zu identifizieren, als nach einer genauen Übereinstimmung mit dem codierten Ergebnis zu suchen. Daher gibt es noch keine Beispiele für die Verwendung des Modifikators base64 .
base64offset
Aufgrund der Art der Base64-Codierung können Sie keine Pipeline von base64 verwenden und enthält , um einen codierten Teilstring zu finden . Zu diesem Zweck wurde der Modifikator base64offset erstellt . Es wird verwendet, wenn eine Zeichenfolge Base64- codiert ist und wir einen Teilstring der codierten Zeichenfolge suchen möchten. Darüber hinaus sind die Zeichen, die den gewünschten Teilstring umgeben, im Voraus unbekannt, und der Versatz des Teilstrings relativ zum Anfang des Strings ist unbekannt. Sie können deutlich sehen, worum es hier geht.
Fast immer wird dieser Modifikator zusammen mit dem Modifikator " enthält" verwendet :

Anwendungsbeispiele:
- rules / windows / process_creation / win_encoded_frombase64string.yml
- rules / windows / process_creation / win_encoded_iex.yml
Wichtig! Die folgenden drei Codierungstransformationsmodifikatoren werden nur in Verbindung mit Base64-Modifikatoren verwendet.
utf16le oder breit
Die Modifikatoren utf16le und wide sind Synonyme. Sie wandeln den Zeichenfolgenwert des Felds in UTF-16LE-Codierung um
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00.

utf16be
Der Modifikator utf16be konvertiert den Zeichenfolgenwert des Felds in UTF-16BE
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33.

utf16
Der Modifikator utf16 fügt eine Byte Order Mark (BOM) hinzu und codiert eine Zeichenfolge in UTF-16
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00. Derzeit

gibt es nur einen Typmodifikator - re .
Re
Dieser Typmodifikator interpretiert den Feldwert als Muster für reguläre Ausdrücke. Bisher wird es nur vom Konverter für eine Elasticsearch-Abfrage unterstützt, sodass es praktisch nicht in öffentlichen Regeln angezeigt wird.
Anwendungsbeispiele:
- rules / windows / process_creation / win_invoke_obfuscation_obfuscated_iex_commandline.yml
- rules / windows / builtin / win_invoke_obfuscation_obfuscated_iex_services.yml
- rules / windows / builtin / win_mal_creddumper.yml
Zeitintervall (Zeitrahmenattribut)
Zusätzlich kann die Erkennungslogik verfeinert werden, indem das Zeitintervall angegeben wird, in dem die Suchkennungen erscheinen sollen. Standardabkürzungen werden verwendet, um Zeiteinheiten zu bezeichnen:
15s (15 )
30m (30 )
12h (12 )
7d (7 )
3M (3 ) Anwendungsbeispiele:
- rules / linux / modsecurity / modsec_mulitple_blocks.yml
- rules-unsupported / net_possible_dns_rebinding.yml
- rules / windows / builtin / win_rare_service_installs.yml
Beschreibung der Regelauslösebedingungen (Bedingungsattribut)
Gemäß der offiziellen Sigma-Dokumentation ist der Teil der Regel, der die Auslösebedingung enthält, der komplexeste und wird sich im Laufe der Zeit ändern. Die folgenden Ausdrücke sind derzeit verfügbar.
Logische Operationen AND, OR
Sie werden durch die Schlüsselwörter bzw. und bzw. angezeigt. Diese Ausdrücke sind die Hauptelemente zum Aufbau einer logischen Beziehung zwischen Suchkennungen.
detection:
keywords1:
- EVILSERVICE
- svchost.exe -n evil
keywords2:
- SERVICEEVIL
- svchost.exe -n live
condition: keywords1 or keywords2 Anwendungsbeispiele:
Einer der Such-ID-Werte / alle Such-ID-Werte (1 / alle Such-IDs)
Der gleiche wie im vorherigen Fall, wenn die Such-ID
- 1 - logisches ODER unter Alternativen,
- alllogisch UND unter Alternativen.
Standardmäßig
condition: keywordsbedeutet dies, dass die in der Schlüsselwortkennung aufgeführten Werte logisch sind ODER, dh dies entspricht dem Schreiben condition: 1 of keywords. Wenn wir wollen, dass die Werte mit logischem UND kombiniert werden, müssen wir schreiben condition: all of keywords.
Anwendungsbeispiele:
Eine der Such-IDs / alle Such-IDs (1 / alle)
Logisches ODER (1 von ihnen) oder logisches UND (alle) unter allen angegebenen Such-IDs. Standardmäßig werden Such-IDs durch ein logisches UND verknüpft, wenn sie Elemente eines Wörterbuchs sind, oder durch ein logisches ODER, wenn sie Elemente einer Liste sind. Um diese Beziehungen zu ändern, wurde diese Struktur erstellt. Die Bedingung, Bedingung: 1 von ihnen, bedeutet also, dass mindestens eine der Suchkennungen im Ereignis erscheinen muss.
Anwendungsbeispiele:
- rules / windows / process_creation / win_hack_bloodhound.yml
- rules / windows / Powershell / Powershell_psattack.yml
- rules / cloud / aws_ec2_download_userdata.yml
Eine der Such-IDs, die mit dem Namensmuster übereinstimmen / alle Such-IDs, die mit dem Namensmuster übereinstimmen (1 / alle Such-ID-Muster)
Das gleiche wie für das vorherige Element, jedoch ist die Auswahl auf Suchkennungen beschränkt, deren Namen mit dem Muster übereinstimmen. Solche Muster werden unter Verwendung des Platzhalters * (beliebig viele Zeichen) an einer bestimmten Position im Namensmuster erstellt.
Die Syntax lautet wie folgt:
condition: 1 of selection*
condition: all of selection* Anwendungsbeispiele:
- rules / windows / builtin / win_user_added_to_local_administrators.yml
- rules / windows / process_creation / win_susp_eventlog_clear.yml
- rules / cloud / aws_iam_backdoor_users_keys.yml
Logische Negation
Logische Negative werden mit dem Schlüsselwort not erstellt . Wie oben erwähnt, muss der Ausdruck "nicht leer" im Bedingungsfeld und nicht in der Beschreibung der Such-ID angegeben werden. Das folgende Beispiel zeigt deutlich die korrekte Version der Beschreibung des Ausdrucks "Feldwert ist nicht leer".

Anwendungsbeispiele:
- rules / windows / sysmon / sysmon_malware_backconnect_ports.yml
- rules / windows / process_creation / win_apt_gallium.yml
Rohr
Der vertikale Balken (oder die Pipe) zeigt an, dass das Ergebnis des Ausdrucks an eine Aggregatfunktion übergeben wird, deren Ergebnis wahrscheinlich mit einem bestimmten Wert verglichen wird.
Allgemeines Schema:
_ | _
condition: selection | count(category) by dst_ip > 30 Anwendungsbeispiele:
- rules / windows / builtin / win_susp_failed_logons_single_source.yml
- rules / windows / other / win_rare_schtask_creation.yml
- rules / network / net_high_dns_requests_rate.yml
Klammern
Klammern werden verwendet, um einen Unterausdruck anzugeben. Dies kann nützlich sein, um die Reihenfolge anzugeben, in der ein logischer Ausdruck ausgewertet wird, oder um ein Prädikat zu negieren, das mehrere Ausdrücke enthält. Sie haben die höchste Priorität für die Operation.
condition: selection and (keywords1 or keywords2)
condition: selection and not (filter1 or filter2) Anwendungsbeispiel:
Aggregierte Funktionsausdrücke
Aggregierte Ausdrücke (oder aggregierte Funktionsausdrücke) werden verwendet, um die aufgetretenen Ereignisse zu quantifizieren.
Aggregatausdrucksschema: Für

alle Aggregatfunktionen außer count ist ein Feldname als Parameter erforderlich. Die Zählfunktion zählt alle übereinstimmenden Ereignisse, wenn kein Feldname angegeben ist. Wenn ein Feldname angegeben wird, zählt die Funktion in diesem Feld unterschiedliche Werte. Der folgende Ausdruck zählt beispielsweise die Anzahl der verschiedenen Ports, zu denen Verbindungen von einer IP-Adresse hergestellt wurden. Wenn diese Anzahl 10 überschreitet, wird die Regel ausgelöst:
condition: selection | count(dst_port) by src_ip > 10 Anwendungsbeispiele:
- rules / linux / lnx_susp_failed_logons_single_source.yml
- rules / windows / other / win_rare_schtask_creation.yml
- rules / network / net_susp_network_scan.yml
Aggregierter Ausdruck in der Nähe
Das Schlüsselwort Near wird verwendet, um eine Abfrage zu generieren (sofern diese Funktionalität vom Zielsystem und vom Backend unterstützt wird), die das Auftreten aller angegebenen Such-IDs innerhalb eines bestimmten Zeitintervalls nach dem Auffinden der ersten ID erkennt.
Allgemeines Schema:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ]
Syntaxbeispiel:
timeframe: 30s
condition: selector | near dllload1 and dllload2 and not exclusion Für den Suchausdruck nach dem Wort in der Nähe gelten dieselben Regeln wie für den Suchausdruck vor dem vertikalen Balken, den wir oben ausführlich besprochen haben.
Anwendungsbeispiele:
- rules / windows / sysmon / sysmon_mimikatz_inmemory_detection.yml
- rules / windows / builtin / win_susp_samr_pwset.yml
Die Standardpriorität von Operationen ist:
- (Ausdruck)
- X des Suchmusters
- Nicht
- Und
- Oder
- |
Daher haben Klammern die höchste Priorität und die Pipe die niedrigste.
Hinweis: Wenn mehrere Bedingungsfelder angegeben sind, wird der endgültige Wert durch Anwenden eines logischen ODER auf alle Ausdruckswerte erhalten.
In diesem Artikel haben wir die Erkennungslogik beschrieben. Folgen Sie unseren Beiträgen, im nächsten Artikel werden wir uns die verbleibenden Felder der Regel ansehen. Die meisten von ihnen sind informativer oder infrastruktureller Natur. Lassen Sie uns neben Feldern mit Metainformationen auf ein solches Merkmal der Regelzusammensetzung eingehen, das als Regelsammlungen bezeichnet wird. Für Leute, die mit den Feinheiten der YAML-Sprache nicht vertraut sind, ist es hilfreich, diesen Aspekt der Syntax zu berücksichtigen, wenn sie Fremde lesen und ihre eigenen Regeln schreiben.
Autor : Anton Kutepov, Spezialist der Abteilung für Expertendienste und Entwicklung positiver Technologien (PT Expert Security Center)