
Hallo! Unser Unternehmen hat sich seit langem mit dem Problem des Schutzes vor DDoS-Angriffen befasst, und im Verlauf dieser Arbeit habe ich es geschafft, verwandte Bereiche ausreichend detailliert kennenzulernen - um die Prinzipien der Erstellung von Bots und deren Verwendung zu untersuchen. Insbesondere Web-Scraping, dh Massenerfassung öffentlicher Daten aus Webressourcen mithilfe von Bots.
Irgendwann faszinierte mich dieses Thema mit einer Vielzahl von angewandten Problemen, bei denen das Schaben erfolgreich eingesetzt wird. Hierbei ist zu beachten, dass die "dunkle Seite" des Web-Scraping für mich von größtem Interesse ist, dh schädliche und schlechte Szenarien seiner Verwendung und die negativen Auswirkungen, die es auf die Webressourcen und das damit verbundene Geschäft haben kann.
Gleichzeitig mussten wir uns aufgrund der Besonderheiten unserer Arbeit in solchen (schlechten) Fällen meistens eingehend mit interessanten Details befassen. Das Ergebnis dieser Tauchgänge war, dass meine Begeisterung an meine Kollegen weitergegeben wurde - wir haben unsere Lösung implementiert, um unerwünschte Bots zu fangen, aber ich habe genug Geschichten und Beobachtungen gesammelt, die hoffentlich interessantes Material für Sie sein werden.

Ich werde über Folgendes sprechen:
- Warum kratzen sich die Leute überhaupt?
- Was sind die Arten und Anzeichen eines solchen Schabens?
- Welche Auswirkungen hat dies auf gezielte Websites?
- Welche Tools und technischen Fähigkeiten verwenden die Entwickler von Bots zum Scraping?
- Wie verschiedene Kategorien von Bots erkannt und erkannt werden können;
- Was tun und was tun, wenn der Schaber Ihre Website besucht (und ob Sie überhaupt etwas tun müssen)?
Beginnen wir mit einem harmlosen hypothetischen Szenario - stellen wir uns vor, Sie sind Student, morgen früh haben Sie eine Verteidigung Ihrer Hausarbeit, Sie haben „kein Pferd herumliegen“, basierend auf den Materialien, es gibt keine Zahlen, keine Auszüge, keine Zitate - und Sie verstehen das für den Rest der Nacht Sie haben weder die Zeit noch die Energie noch den Wunsch, diese gesamte Wissensbasis manuell zu durchlaufen.
Auf Anraten älterer Kameraden decken Sie daher die Python-Befehlszeile auf und schreiben ein einfaches Skript, das URLs als Eingabe akzeptiert, dorthin geht, die Seite lädt, den Inhalt analysiert, Schlüsselwörter, Blöcke oder Nummern von Interesse darin findet, sie einer Datei hinzufügt oder in den Teller und geht weiter.
Laden Sie in dieses Skript die erforderliche Anzahl von Adressen für wissenschaftliche Veröffentlichungen, Online-Veröffentlichungen und Nachrichtenressourcen - es geht schnell alles durch und summiert die Ergebnisse. Sie müssen nur Grafiken und Diagramme zeichnen, Tabellen darauf - und am nächsten Morgen, mit dem Erscheinen eines Gewinners, erhalten Sie Ihren wohlverdienten Punkt.
Lassen Sie uns darüber nachdenken - haben Sie dabei jemanden schlecht gemacht? Wenn Sie HTML nicht mit einem regulären Ausdruck analysiert haben, haben Sie höchstwahrscheinlich niemandem Schaden zugefügt, und noch mehr den Websites, die Sie auf diese Weise besucht haben. Dies ist eine einmalige Aktivität, die als bescheiden und unauffällig bezeichnet werden kann, und kaum jemand wurde durch die Tatsache verletzt, dass Sie schnell und leise die benötigten Daten ergriffen haben.
Auf der anderen Seite, werden Sie es wieder tun, wenn beim ersten Mal alles geklappt hat? Seien wir ehrlich - höchstwahrscheinlich werden Sie es tun, weil Sie gerade viel Zeit und Ressourcen gespart haben und höchstwahrscheinlich sogar mehr Daten erhalten haben, als Sie ursprünglich gedacht hatten. Und dies ist nicht auf wissenschaftliche, akademische oder allgemeinbildende Forschung beschränkt.

Weil Informationen Geld kosten und rechtzeitig gesammelte Informationen noch mehr Geld kosten. Deshalb ist Schaben für eine große Anzahl von Menschen eine ernsthafte Einnahmequelle. Dies ist ein beliebtes freiberufliches Thema: Sehen Sie sich eine Reihe von Bestellungen an, in denen Sie aufgefordert werden, Daten zu sammeln oder Scraping-Software zu schreiben. Es gibt auch kommerzielle Organisationen, die Scraping durchführen, um Plattformen für diese Aktivität zu bestellen oder bereitzustellen, das sogenannte Scraping as a Service. Eine solche Vielfalt und Verbreitung ist möglich, auch weil das Abkratzen selbst etwas Illegales, Verwerfliches ist und nicht. Aus rechtlicher Sicht ist es sehr schwierig, ihn zu bemängeln - besonders im Moment werden wir bald herausfinden, warum.

Von besonderem Interesse ist für mich auch die Tatsache, dass Ihnen technisch gesehen niemand den Kampf gegen das Schaben verbieten kann - dies schafft eine interessante Situation, in der die Teilnehmer des Prozesses auf beiden Seiten der Barrikaden im öffentlichen Raum die Möglichkeit haben, die technischen und organisatorischen Aspekte dieser Angelegenheit zu diskutieren. Bis zu einem gewissen Grad das technische Denken voranzutreiben und immer mehr Menschen in diesen Prozess einzubeziehen.

Aus rechtlicher Sicht war die Situation, die wir jetzt betrachten - mit der Zulässigkeit des Schabens - vorher nicht immer dieselbe. Wenn wir uns ein wenig die Chronologie ziemlich bekannter Rechtsstreitigkeiten im Zusammenhang mit dem Scraping ansehen, werden wir feststellen, dass eBay bereits zu Beginn seiner Klage gegen einen Scraper vorging, der Daten aus Auktionen sammelte, und das Gericht ihm untersagte, sich an dieser Aktivität zu beteiligen. In den nächsten 15 Jahren blieb der Status quo mehr oder weniger erhalten - große Unternehmen gewannen Klagen gegen Schaber, als sie ihre Auswirkungen entdeckten. Facebook und Craigslist sowie einige andere Unternehmen haben Behauptungen gemeldet, die zu ihren Gunsten endeten.
Vor einem Jahr änderte sich jedoch plötzlich alles. Das Gericht stellte fest, dass die Behauptung von LinkedIn gegen das Unternehmen, das öffentliche Profile von Benutzern und Lebensläufen gesammelt hatte, unbegründet war, und ignorierte die Briefe und Drohungen, die die Einstellung der Aktivität forderten. Das Gericht entschied, dass die Erhebung öffentlicher Daten, unabhängig davon, ob es sich um einen Bot oder einen Menschen handelt, nicht die Grundlage für eine Forderung des Unternehmens sein kann, das diese öffentlichen Daten anzeigt. Dieser mächtige Präzedenzfall hat das Gleichgewicht zugunsten von Schabern verschoben und es mehr Menschen ermöglicht, ihr eigenes Interesse auf diesem Gebiet zu zeigen, zu demonstrieren und zu versuchen.
Vergessen Sie jedoch bei all diesen im Allgemeinen harmlosen Dingen nicht, dass das Scraping viele negative Verwendungszwecke hat - wenn Daten nicht nur zur weiteren Verwendung gesammelt werden, sondern auch die Idee verwirklicht wird, die Site oder das dahinter stehende Unternehmen zu beschädigen. oder versucht, sich auf Kosten der Benutzer der Zielressource auf irgendeine Weise zu bereichern.
Schauen wir uns einige ikonische Beispiele an.

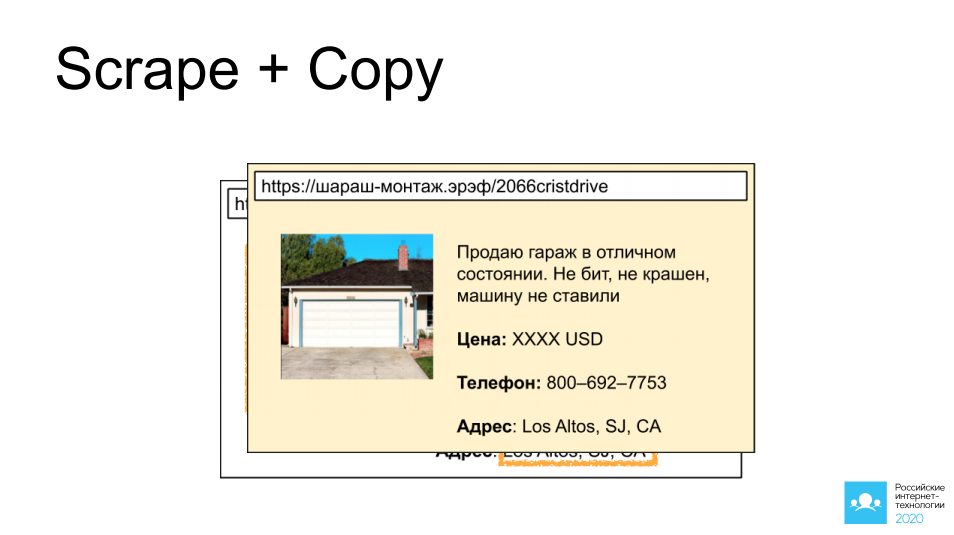
Die erste davon ist das Scraping und Kopieren der Anzeigen anderer Personen von Websites, die Zugriff auf solche Anzeigen bieten: Autos, Immobilien, persönliche Gegenstände. Ich habe als Beispiel eine wundervolle Garage in Kalifornien gewählt. Stellen Sie sich vor, wir setzen dort einen Bot, sammeln ein Bild, sammeln eine Beschreibung, nehmen alle Kontaktinformationen auf und nach 5 Minuten hängt dieselbe Anzeige auf einer anderen Website mit einem ähnlichen Fokus, und es ist durchaus möglich, dass dadurch ein profitables Geschäft zustande kommt.
Wenn wir hier unsere Fantasie ein wenig anregen und zur nächsten Seite denken - was ist, wenn nicht unser Konkurrent dies tut, sondern ein Angreifer? Eine solche Kopie der Website kann sehr nützlich sein, um beispielsweise eine Vorauszahlung vom Besucher anzufordern oder einfach die Eingabe der Zahlungskartendaten anzubieten. Sie können sich die Weiterentwicklung der Ereignisse selbst vorstellen.
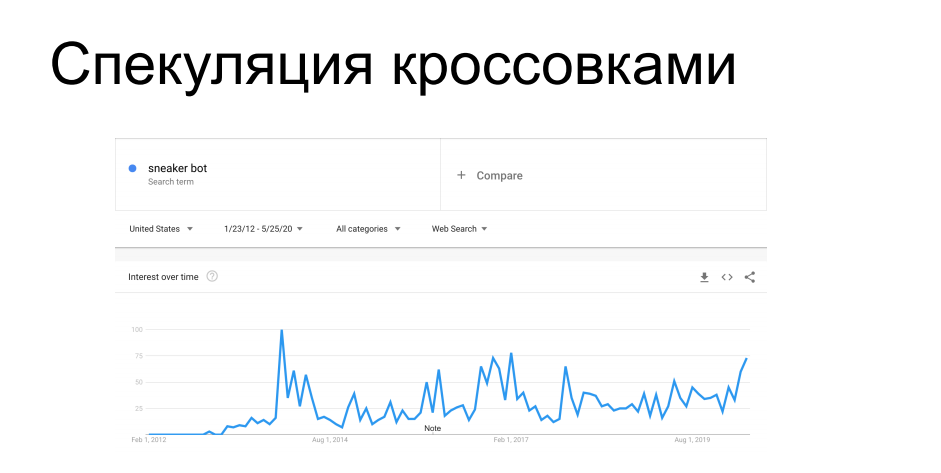
Ein weiterer interessanter Fall von Schaben ist der Kauf von Artikeln mit begrenzter Verfügbarkeit. Sportschuhhersteller wie Nike, Puma und Reebok bringen regelmäßig Sneakers in limitierter Auflage usw. auf den Markt. Signaturserien - sie werden von Sammlern gejagt und sind für eine begrenzte Zeit im Verkauf. Vor den Käufern rennen Bots zu den Websites der Schuhgeschäfte und machen die gesamte Auflage wieder gut. Danach schweben diese Sneaker mit einem völlig anderen Preis auf den grauen Markt. Zu einer Zeit machte es Verkäufer und Einzelhändler wütend, die sie vertreiben. Seit 7 Jahren kämpfen sie gegen Schaber usw. Sneaker Bots mit unterschiedlichem Erfolg, sowohl technische als auch administrative Methoden.

Sie haben wahrscheinlich Geschichten gehört, als Sie beim Online-Einkauf persönlich in einen Sneaker-Laden kommen mussten, oder über Honeypots mit Sneakers für 100.000 US-Dollar, die der Bot gekauft hat, ohne nachzusehen, woraufhin sein Besitzer seinen Kopf ergriff - all diese Geschichten sind in diesem Trend.
Ein weiterer ähnlicher Fall ist die Erschöpfung des Lagerbestands in Online-Shops. Es ist ähnlich wie das vorherige, aber es werden tatsächlich keine Einkäufe getätigt. Es gibt einen Online-Shop und bestimmte Waren, die die eingehenden Bots in der Menge in den Warenkorb schieben, die als im Lager verfügbar angezeigt wird. Infolgedessen erhält ein legitimer Benutzer, der versucht, ein Produkt zu kaufen, die Nachricht, dass dieser Artikel nicht vorrätig ist, kratzt sich frustriert am Hinterkopf und geht in ein anderes Geschäft. Die Bots selbst lassen dann die gesammelten Körbe fallen, die Waren werden in den Pool zurückgebracht - und derjenige, der sie benötigt, kommt und bestellt. Oder kommt nicht und bestellt nicht, wenn dies ein Szenario von kleinlichem Unfug und Rowdytum ist. Daraus ergibt sich, dass selbst wenn solche Aktivitäten einem Online-Geschäft keinen direkten finanziellen Schaden zufügen, dies zumindest die Geschäftsmetriken ernsthaft stören kann.auf welche Analysten sich konzentrieren wird. Parameter wie Conversion, Anwesenheit, Produktnachfrage, durchschnittliche Warenkorbprüfung - alle werden durch die Aktionen von Bots in Bezug auf diese Artikel stark beeinträchtigt. Und bevor diese Metriken in Betrieb genommen werden, müssen sie sorgfältig und sorgfältig von den Auswirkungen von Schabern gereinigt werden.
Neben dieser geschäftlichen Ausrichtung ergeben sich aus der Arbeit der Schaber durchaus spürbare technische Auswirkungen - meistens, wenn das Schaben aktiv und intensiv durchgeführt wird.
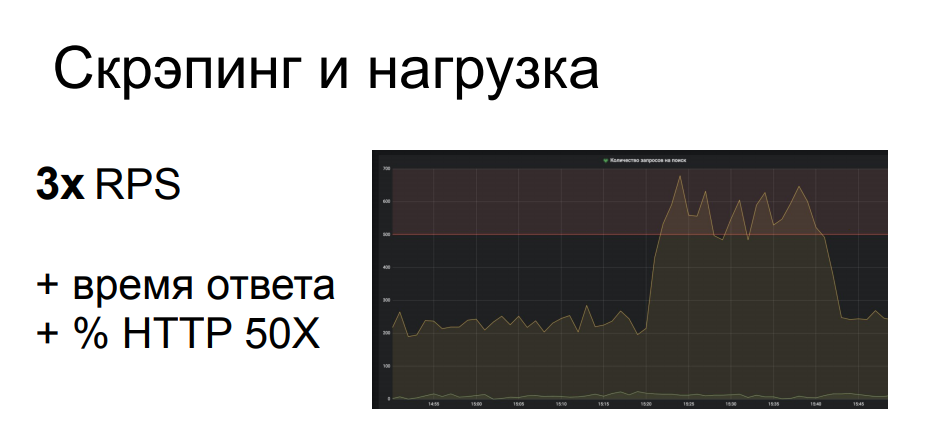
Eines unserer Beispiele von einem unserer Kunden. Der Schaber kam mit einer parametrisierten Suche an einen Ort, was eine der schwierigsten Operationen im Backend der betreffenden Struktur ist. Der Schaber musste viele Suchanfragen durchlaufen, und er machte fast 700 von 200 RPS an diesem Standort. Dies belastete einen Teil der Infrastruktur ernsthaft, was zu einer Verschlechterung der Servicequalität für den Rest der legitimen Benutzer führte, die Reaktionszeit nahm ab, die 502er und 503er und Fehler. Im Allgemeinen war es dem Schaber überhaupt egal und er saß und erledigte seine Arbeit, während alle anderen die Browserseite hektisch aktualisierten.
Daraus ergibt sich, dass eine solche Aktivität durchaus als angewandter DDoS-Angriff eingestuft werden kann - und dies ist häufig der Fall. Insbesondere wenn der Online-Shop nicht so groß ist, verfügt er nicht über eine Infrastruktur, die in Bezug auf Leistung und Standort wiederholt reserviert wird. Eine solche Aktivität kann durchaus dazu führen, dass alle anderen Benutzer ernsthaft verärgert sind, wenn Sie die Ressource nicht vollständig einsetzen - dies ist für den Schaber nicht sehr rentabel, da er in diesem Fall seine Daten nicht erhält.
Neben DDoS hat Scraping auch interessante Nachbarn für Cyberkriminalität. Beispielsweise verwenden Brute-Force-Anmeldungen und -Kennwörter eine ähnliche technische Basis, dh mit denselben Skripten kann ein Schwerpunkt auf Geschwindigkeit und Leistung gelegt werden. Für das Füllen von Anmeldeinformationen werden Benutzerdaten verwendet, die von irgendwoher verschrottet wurden und in Formularfelder verschoben werden. Nun, dieses Beispiel, Inhalte zu kopieren und auf ähnlichen Websites zu veröffentlichen, ist eine ernsthafte Vorarbeit, um Phishing-Links zu entfernen und ahnungslose Käufer anzulocken.

Um zu verstehen, wie sich verschiedene Varianten des Scrapings aus technischer Sicht auf die Ressource auswirken können, versuchen wir, den Beitrag einzelner Faktoren zu dieser Aufgabe zu berechnen. Lassen Sie uns etwas rechnen.

Nehmen wir an, wir haben rechts eine Reihe von Daten, die wir sammeln müssen. Wir haben die Aufgabe oder den Auftrag, 10.000.000 Zeilen mit Warenartikeln abzurufen, z. B. Preisschilder oder Angebote. Und auf der linken Seite haben wir ein Zeitbudget, weil der Kunde diese Daten morgen oder in einer Woche nicht mehr benötigt - sie werden veraltet sein und wir müssen sie erneut sammeln. Daher müssen Sie einen bestimmten Zeitrahmen einhalten und dies mit Ihren eigenen Ressourcen optimal tun. Wir haben eine Reihe von Servern - Maschinen und IP-Adressen, hinter denen sie sich befinden, von denen aus wir zu der für uns interessanten Ressource gehen. Wir haben eine Reihe von Benutzerinstanzen, die wir vorgeben zu sein - es gibt eine Aufgabe, einen Online-Shop oder eine öffentliche Basis davon zu überzeugen, dass es sich um unterschiedliche Personen oder Computer handelt, die Daten abrufen, damit diejenigen, die dies tunWer die Protokolle analysieren wird, gab es keinen Verdacht. Und wir haben eine gewisse Leistung, Anforderungsrate, von einer solchen Instanz.
Es ist klar, dass in einem einfachen Fall - ein Host-Computer, ein Student mit einem Laptop, der die Washington Post durchläuft - eine große Anzahl von Anfragen mit denselben Vorzeichen und Parametern gestellt wird. Dies wird in den Protokollen sehr deutlich, wenn es viele solcher Anfragen gibt - was bedeutet, dass es in diesem Fall leicht ist, die IP-Adresse zu finden und zu sperren.
Wenn die Scraping-Infrastruktur komplexer wird und eine größere Anzahl von IP-Adressen angezeigt wird, werden zunehmend Proxys verwendet, einschließlich Haus-Proxys - dazu später mehr. Und wir beginnen, auf jedem Computer mehrere Instanzen zu erstellen - um die Abfrageparameter, die Zeichen, die uns charakterisieren, zu ersetzen, damit das Ganze in den Protokollen verschmiert und nicht so auffällig ist.
Wenn wir in die gleiche Richtung gehen, haben wir die Möglichkeit, im Rahmen derselben Gleichung die Intensität der Anforderungen von jeder dieser Instanzen zu verringern - sie seltener zu machen und sie effizienter zu drehen, damit Anforderungen von denselben Benutzern nicht in den Protokollen in der Nähe landen. ohne Verdacht zu erregen und den Endbenutzern (legitimen Benutzern) ähnlich zu sein.
Nun, es gibt einen Randfall - wir hatten einmal einen solchen Fall in der Praxis, als ein Schaber von einer großen Anzahl von IP-Adressen mit völlig unterschiedlichen Benutzerattributen hinter diesen Adressen zu einem Kunden kam und jede dieser Instanzen genau eine Anforderung für den Inhalt stellte. Ich habe ein GET zur gewünschten Produktseite erstellt, es analysiert und bin gegangen - und nie wieder aufgetaucht. Solche Fälle sind ziemlich selten, da mehr Ressourcen (die Geld kosten) in der gleichen Zeit benötigt werden. Gleichzeitig wird es viel schwieriger, sie aufzuspüren und zu verstehen, dass sogar jemand hierher gekommen ist und sie abgekratzt hat. Verkehrsforschungsinstrumente wie die Verhaltensanalyse - das Erstellen eines Verhaltensmusters eines bestimmten Benutzers - werden sehr kompliziert. Wie können Sie eine Verhaltensanalyse durchführen, wenn kein Verhalten vorliegt? Es gibt keine Historie von Benutzeraktionen.er war noch nie zuvor aufgetaucht und interessanterweise ist er seitdem nie wieder gekommen. Wenn wir unter solchen Bedingungen bei der ersten Anfrage nicht versuchen, etwas zu tun, erhält es seine Daten und geht, und es bleibt uns nichts übrig - wir haben das Problem, dem Schaben hier entgegenzuwirken, nicht gelöst. Daher besteht die einzige Möglichkeit darin, bei der ersten Anfrage zu erraten, dass die falsche Person gekommen ist, die wir auf der Website sehen möchten, und ihm einen Fehler zu geben oder auf andere Weise sicherzustellen, dass er seine Daten nicht erhält.wen wir auf der Website sehen wollen, und ihm einen Fehler geben oder auf andere Weise sicherstellen, dass er seine Daten nicht erhält.wen wir auf der Website sehen wollen, und ihm einen Fehler geben oder auf andere Weise sicherstellen, dass er seine Daten nicht erhält.
Um zu verstehen, wie Sie sich beim Bau eines Schabers in dieser Komplexität bewegen können, schauen wir uns das Arsenal an, über das Bot-Entwickler am häufigsten verfügen - und in welche Kategorien es unterteilt werden kann.

Die primäre, einfachste Kategorie, mit der die meisten Leser vertraut sind, ist das Scraping von Skripten, die Verwendung von Skripten, die einfach genug sind, um relativ komplexe Probleme zu lösen.

Und diese Kategorie ist vielleicht die beliebteste und am besten dokumentierte. Es ist sogar schwierig zu empfehlen, was genau zu lesen ist, da es in Wirklichkeit viel Material gibt. Viele Bücher wurden mit dieser Methode geschrieben, es gibt viele Artikel und Veröffentlichungen - im Prinzip reicht es aus, 5/4/3/2 Minuten (abhängig von der Unverschämtheit des Autors des Materials) zu verwenden, um Ihre erste Site zu analysieren. Dies ist ein logischer erster Schritt für viele, die mit dem Web-Scraping beginnen. Das "Starterpaket" einer solchen Aktivität ist meistens Python sowie eine Bibliothek, die Anforderungen flexibel stellen und ihre Parameter wie Anforderungen oder urllib2 ändern kann. Und eine Art HTML-Parser, meistens Beautiful Soup. Es gibt auch eine Option zur Verwendung von Bibliotheken, die speziell für das Scraping erstellt wurden, z. B. Scrapy, das alle diese Funktionen mit einer benutzerfreundlichen Oberfläche enthält.
Mit Hilfe einfacher Tricks können Sie vorgeben, unterschiedliche Geräte und Benutzer zu sein, auch ohne Ihre Aktivitäten nach Maschinen, IP-Adressen und Hardwareplattformen skalieren zu können.

Um den Geruch desjenigen zu beseitigen, der die Protokolle auf der Serverseite überprüft, von der die Daten erfasst werden, reicht es aus, die interessierenden Parameter zu ersetzen - und dies ist nicht schwierig und nicht lange. Schauen wir uns ein Beispiel für ein benutzerdefiniertes Protokollformat für Nginx an: Wir zeichnen eine IP-Adresse, TLS-Informationen und für uns interessante Header auf. Hier natürlich nicht alles, was normalerweise gesammelt wird, aber wir brauchen diese Einschränkung als Beispiel - um eine Teilmenge zu betrachten, einfach weil alles andere noch einfacher zu "werfen" ist.
Um nicht durch Adressen gesperrt zu werden, verwenden wir private Proxys, wie sie im Ausland genannt werden, dh Proxys von gemieteten (oder gehackten) Maschinen in den Heimnetzwerken von Anbietern. Es ist klar, dass durch das Verbot einer solchen IP-Adresse die Möglichkeit besteht, eine bestimmte Anzahl von Benutzern, die in diesen Häusern leben, zu sperren - und es kann durchaus Besucher auf Ihrer Website geben, so dass es für Sie manchmal teurer ist, dies zu tun.
Es ist auch nicht schwierig, TLS-Informationen zu ändern. Nehmen Sie die Chiffresuiten gängiger Browser und wählen Sie diejenige aus, die Ihnen am besten gefällt, oder drehen Sie sie regelmäßig, um sich als verschiedene Geräte zu präsentieren.
In Bezug auf die Header können Sie mithilfe einer kleinen Studie den Verweis auf das einstellen, was der kratzenden Site gefällt, und wir übernehmen den Benutzeragenten von Chrome oder Firefox, damit er sich in keiner Weise von Zehntausenden anderer Benutzer unterscheidet.
Wenn Sie dann mit diesen Parametern jonglieren, können Sie sich als verschiedene Geräte ausgeben und weiter kratzen, ohne Angst zu haben, für das bloße Auge, das durch die Protokolle geht, bemerkt zu werden. Für das bewaffnete Auge ist dies noch etwas schwieriger, da solche einfachen Tricks durch dieselben, eher einfachen Gegenmaßnahmen neutralisiert werden.

Durch den Vergleich von Anforderungsparametern, Headern und IP-Adressen untereinander und mit öffentlich bekannten Adressen können Sie die arrogantesten Scraper abfangen. Ein einfaches Beispiel: Ein Suchbot kam zu uns, aber aus irgendeinem Grund stammt seine IP nicht aus dem Netzwerk der Suchmaschine, sondern von einem Cloud-Anbieter. Sogar Google selbst auf der Seite, auf der Googlebot beschrieben wird, empfiehlt, DNS-Einträge mit umgekehrter Suche durchzuführen, um sicherzustellen, dass dieser Bot tatsächlich von google.com oder anderen gültigen Google-Ressourcen stammt.
Es gibt viele solcher Kontrollen, meistens sind sie für diejenigen Schaber gedacht, die sich nicht mit Fuzzing beschäftigen, einer Art Ersatz. Für komplexere Fälle gibt es zuverlässigere und umständlichere Methoden, z. B. Javascript in diesen Bot einfügen. Es ist klar, dass unter solchen Bedingungen der Kampf bereits ungleich ist - Ihr Python-Skript kann den JS-Code nicht ausführen und interpretieren. Dies kann jedoch vom Skriptautor durchgeführt werden - wenn der Bot-Autor genügend Zeit, Wünsche, Ressourcen und Fähigkeiten hat, um zu sehen, was Ihr Javascript im Browser tut.
Das Wesentliche bei den Überprüfungen ist, dass Sie das Skript in Ihre Seite integrieren und es für Sie nicht nur wichtig ist, dass es ausgeführt wird, sondern auch, dass es eine Art Ergebnis zeigt, das normalerweise per POST an den Server zurückgesendet wird, bevor der Client genügend Schlaf erhält Inhalt, und die Seite selbst wird geladen. Wenn der Autor des Bots Ihr Rätsel gelöst und die richtigen Antworten in sein Python-Skript fest codiert oder beispielsweise versteht, wo er die Skriptzeilen selbst analysieren muss, um nach den erforderlichen Parametern und aufgerufenen Methoden zu suchen, und die Antwort selbst berechnet, kann er Sie umkreisen um deinen Finger. Hier ist ein Beispiel.

Ich denke, dass einige Hörer dieses Stück Javascript erkennen werden - dies ist eine Überprüfung, die einer der größten Cloud-Anbieter der Welt vor dem Zugriff auf die angeforderte Seite hatte, kompakt und sehr einfach, und gleichzeitig, ohne es zu lernen, ist es so einfach Die Seite bricht nicht durch. Gleichzeitig können wir mit ein wenig Aufwand die Seite nach den JS-Methoden fragen, an denen wir interessiert sind. Diese werden aufgerufen, zählen ab, finden die Werte, an denen wir interessiert sind, die berechnet werden sollen, und stecken die Berechnungen in unseren Code. Vergessen Sie danach nicht, wegen der Verzögerung ein paar Sekunden zu schlafen, und voila.

Wir sind auf der Seite und können dann analysieren, was wir brauchen, und nicht mehr Ressourcen ausgeben, als unseren eigenen Schaber zu erstellen. Das heißt, unter dem Gesichtspunkt des Ressourceneinsatzes benötigen wir nichts Zusätzliches, um solche Probleme zu lösen. Es ist klar, dass das Wettrüsten in diesem Sinne - JS-Herausforderungen schreiben, analysieren und mit Tools von Drittanbietern umgehen - nur durch die Zeit, den Wunsch und die Fähigkeiten des Autors von Bots und des Autors von Schecks begrenzt ist. Dieses Rennen kann ziemlich lange dauern, aber irgendwann werden die meisten Schaber uninteressant, weil es interessantere Möglichkeiten gibt, damit umzugehen. Warum herumsitzen und JS-Code in Python analysieren, wenn Sie nur einen Browser greifen und ausführen können?

Ja, ich spreche hauptsächlich von Headless-Browsern, da sich dieses Tool, das ursprünglich für Tests und Fragen und Antworten entwickelt wurde, derzeit als ideal für Web-Scraping-Aufgaben erwiesen hat.
Wir werden nicht auf Details über kopflose Browser eingehen, ich denke, dass die meisten Hörer bereits über sie Bescheid wissen. Orchestratoren, die kopflose Browser automatisieren, haben in den letzten 10 Jahren eine recht zügige Entwicklung durchlaufen. Zur Zeit von PhantomJS und den ersten Versionen von Selenium 2.0 und Selenium WebDriver war ein kopfloser Browser, der unter einem Automaten ausgeführt wurde, zunächst überhaupt nicht schwer von einem Live-Benutzer zu unterscheiden. Aber im Laufe der Zeit und mit dem Aufkommen von Tools wie Puppeteer für kopfloses Chrome und jetzt der Schaffung von Gentlemen von Microsoft - Playwright, die das Gleiche wie Puppeteer tun, aber nicht nur für Chrome, sondern für alle Versionen beliebter Browser, werden sie immer mehr und bringen Sie kopflose Browser näher an die realen in Bezug aufWie viel können sie mit Hilfe einer Orchestrierung verdient werden, die sich im Verhalten und in verschiedenen Zeichen und Eigenschaften dem Browser einer gesunden Person ähnelt?

Um die kopflose Erkennung vor dem Hintergrund gewöhnlicher Browser zu bewältigen, in denen Benutzer sitzen, werden in der Regel dieselben Javascript-Überprüfungen verwendet, jedoch tiefer und detaillierter, wobei eine Wolke von Parametern erfasst wird. Das Ergebnis dieser Sammlung wird entweder an das Schutzwerkzeug oder an die Site zurückgesendet, von der der Schaber die Daten sammeln wollte. Diese Technologie wird als Fingerabdruck bezeichnet, da sie einen echten digitalen Fingerabdruck des Browsers und des Geräts erfasst, auf dem er ausgeführt wird.
Es gibt einige Dinge, die JS-Checks beim Fingerabdruck berücksichtigen - sie können in einige bedingte Blöcke unterteilt werden, in denen jeweils weiter gegraben werden kann. Es gibt wirklich viele Eigenschaften, einige sind leicht zu verbergen, andere sind weniger einfach. Und hier, wie im vorherigen Beispiel, hängt vieles davon ab, wie akribisch sich der Schaber der Aufgabe näherte, die hervorstehenden "Schwänze" der Kopflosigkeit zu verbergen. Es gibt Eigenschaften von Objekten im Browser, die der Orchestrator standardmäßig ersetzt. Es gibt genau die Eigenschaft (navigator.webdriver), die in Headless festgelegt ist, aber gleichzeitig in normalen Browsern nicht vorhanden ist. Es kann ausgeblendet werden, ein Versuch, sich auszublenden, kann durch Überprüfen bestimmter Methoden erkannt werden. Was diese Überprüfungen überprüft, kann auch ausgeblendet und gefälschte Ausgabe an Funktionen übertragen werden, die beispielsweise Methoden druckenund es kann unbegrenzt dauern.
Ein weiterer Überprüfungsblock ist in der Regel für die Untersuchung von Fenster- und Bildschirmparametern zuständig, die per Definition in kopflosen Browsern nicht vorhanden sind: Überprüfen von Koordinaten, Überprüfen von Größen und Größe eines fehlerhaften Bilds, das nicht gezeichnet wurde. Es gibt viele Nuancen, die eine Person, die das Gerät von Browsern gut kennt, vorhersehen und eine plausible (aber nicht reale) Schlussfolgerung daraus ziehen kann, die bei Fingerabdruckprüfungen zum Server fliegt und diese analysiert. Wenn Sie beispielsweise einige Bilder, 2D und 3D, mithilfe von WebGL und Canvas rendern, können Sie die gesamte Ausgabe vollständig fertig stellen, fälschen, in einer Methode ausgeben und jemanden glauben lassen, dass etwas wirklich gezeichnet ist.
Es gibt schwierigere Überprüfungen, die nicht gleichzeitig durchgeführt werden. Nehmen wir jedoch an, der JS-Code dreht sich für eine bestimmte Anzahl von Sekunden auf der Seite oder er hängt ständig und überträgt einige Informationen vom Browser an den Server. Zum Beispiel die Position und Geschwindigkeit des Cursors verfolgen - wenn der Bot nur an den Stellen klickt, die er benötigt, und den Links mit Lichtgeschwindigkeit folgt, kann dies durch die Bewegung des Cursors verfolgt werden, wenn der Autor des Bots nicht daran denkt, eine Art menschliches, glattes zu schreiben Versatz.
Und es gibt einen ziemlichen Dschungel - dies sind versionenspezifische Parameter und Eigenschaften des Objektmodells, die von Browser zu Browser, von Version zu Version spezifisch sind. Damit diese Überprüfungen ordnungsgemäß funktionieren und beispielsweise bei Live-Benutzern mit einigen alten Browsern nicht verfälscht werden, müssen Sie eine Reihe von Faktoren berücksichtigen. Zunächst müssen Sie mit der Veröffentlichung neuer Versionen Schritt halten und Ihre Schecks so ändern, dass sie den Stand der Dinge an den Fronten berücksichtigen. Es ist notwendig, die Abwärtskompatibilität aufrechtzuerhalten, damit jemand eine durch solche Überprüfungen geschützte Site in einem atypischen Browser besuchen und nicht wie ein Bot und viele andere erwischt werden kann.
Dies ist eine mühsame, ziemlich komplizierte Arbeit - solche Dinge werden normalerweise von Unternehmen erledigt, die die Bot-Erkennung als Service anbieten, und dies allein aus eigener Kraft zu tun, ist keine sehr rentable Investition von Zeit und Geld.
Aber was können wir tun? Wir müssen wirklich die Baustelle abkratzen, mit einer Wolke solcher Kopflosigkeitsprüfungen aufgehängt sein und trotz allem, egal wie sehr wir uns bemühen, unser kopfloses Chrom mit Puppenspieler berechnen.
Ein kleiner lyrischer Exkurs - für diejenigen, die mehr über die Geschichte und Entwicklung von Schecks lesen möchten, zum Beispiel wegen der Kopflosigkeit von Chrome, gibt es ein lustiges Briefduell zwischen zwei Autoren. Ich weiß nicht viel über einen Autor, und der andere heißt Antoine Vastel, ein junger Mann aus Frankreich, der einen Blog über Bots und ihre Entdeckung, Verschleierung von Schecks und viele andere interessante Dinge unterhält. Und so streiten sie und ihr Gegenüber seit zwei Jahren darüber, ob es möglich ist, kopfloses Chrome zu erkennen.
Und wir werden weitermachen und verstehen, was zu tun ist, wenn wir die Schecks nicht mit einem Kopflosen durchstehen können.

Dies bedeutet, dass wir kein Headless verwenden, sondern große echte Browser, die uns Fenster und alle Arten von visuellen Elementen zeichnen. Tools wie Puppeteer und Playwright ermöglichen es, ohne Kopf Browser mit einem gerenderten Bildschirm zu starten, Benutzereingaben von dort zu lesen, Screenshots zu machen und vieles mehr, die Browsern ohne visuelle Komponente nicht zur Verfügung stehen.

In diesem Fall können Sie nicht nur die Überprüfung der Kopflosigkeit umgehen, sondern auch das folgende Problem lösen: Wenn wir einige listige Site-Builder haben, verstecken Sie sich vor dem Text in Bildern und machen Sie sie unsichtbar, ohne zusätzliche Klicks oder andere Aktionen und Bewegungen auszuführen. Sie verbergen einige Elemente, die ausgeblendet werden sollten und die kopflos auftauchen: Sie wissen nicht, dass dieses Element jetzt nicht auf dem Bildschirm angezeigt werden soll, und sie stoßen darauf. Wir können dieses Bild einfach im Browser zeichnen, den Screenshot der OCR zuführen, den Text an der Ausgabe abrufen und verwenden. Ja, es ist schwieriger, teurer in Bezug auf die Entwicklung, dauert länger und verbraucht mehr Ressourcen. Es gibt jedoch Schaber, die auf diese Weise funktionieren und auf Kosten von Geschwindigkeit und Leistung Daten auf diese Weise erfassen.

"Was ist mit der CAPTCHA?" - du fragst. Schließlich kann OCR (Advanced) Captcha nicht ohne komplexere Dinge gelöst werden. Darauf gibt es eine einfache Antwort: Wenn wir das Captcha nicht automatisch lösen können, warum nicht menschliche Arbeit einsetzen? Warum einen Bot und einen Menschen trennen, wenn Sie ihre Arbeit kombinieren können, um ein Ziel zu erreichen?
Es gibt Dienste, mit denen Sie ihnen ein Captcha senden können, das von den Händen der vor den Bildschirmen sitzenden Personen gelöst wird. Über die API können Sie eine Antwort auf Ihr Captcha erhalten, beispielsweise ein Cookie in die Anfrage einfügen, das ausgegeben wird, und dann automatisch Informationen von dieser Site verarbeiten ... Jedes Mal, wenn ein Captcha auftaucht, ziehen wir die Apishka, erhalten eine Antwort auf das Captcha - schieben Sie es in die nächste Frage und fahren Sie fort.
Es ist klar, dass dies auch einen hübschen Cent kostet - die CAPTCHA-Lösung wird in großen Mengen gekauft. Aber wenn unsere Daten teurer sind als die Kosten all dieser Tricks, warum dann nicht?
Nachdem wir uns nun die Entwicklung hin zur Komplexität all dieser Tools angesehen haben, überlegen wir, was zu tun ist, wenn in unserer Online-Ressource - einem Online-Shop, einer öffentlichen Wissensdatenbank oder was auch immer - Scraping auftritt.

Als erstes muss der Schaber lokalisiert werden. Ich sage Ihnen Folgendes: Nicht alle Fälle von öffentlichen Versammlungen haben im Allgemeinen negative Auswirkungen, wie wir bereits zu Beginn des Berichts berücksichtigt haben. In der Regel können primitivere Methoden, dieselben Skripte ohne Ratenbegrenzung, ohne Einschränkung der Anforderungsgeschwindigkeit, viel mehr Schaden anrichten (wenn sie nicht durch Schutz verhindert werden) als jedes komplexe, ausgefeilte Scraping von Headful-Browsern mit einer Anforderung in der Stunde, die zunächst noch irgendwie in den Protokollen zu finden ist.

Daher müssen Sie zuerst verstehen, dass wir abgekratzt werden - um die Bedeutungen zu betrachten, die normalerweise von dieser Aktivität betroffen sind. Wir sprechen jetzt über technische Parameter und Geschäftsmetriken. Diese Dinge, die Sie in Ihrem Grafana sehen können, beobachten im Laufe der Zeit die Last und den Verkehr, alle Arten von Ausbrüchen und Anomalien. Sie können dies auch manuell tun, wenn Sie kein Sicherheitstool verwenden. Dies wird jedoch zuverlässiger von Personen durchgeführt, die wissen, wie Datenverkehr gefiltert, alle Arten von Vorfällen erkannt und mit einigen Ereignissen abgeglichen werden. Denn neben der nachträglichen Analyse von Protokollen und der Analyse jeder einzelnen Anforderung kann hier auch die Verwendung einiger akkumulierter Schutzmittel für die Wissensbasis funktionieren, bei denen bereits die Aktionen von Schabern auf diese Ressource oder ähnliche Ressourcen angewendet wurden, und Sie können sie irgendwie mit der anderen vergleichen - Sprache über Korrelationsanalyse.
In Bezug auf Geschäftsmetriken haben wir uns bereits an das Beispiel von Skripten erinnert, die direkten oder indirekten finanziellen Schaden verursachen. Wenn es möglich ist, die Dynamik dieser Parameter schnell zu verfolgen, kann erneut ein Scraping festgestellt werden. Wenn Sie dieses Problem selbst lösen, sind Sie in den Protokollen Ihres Backends willkommen.
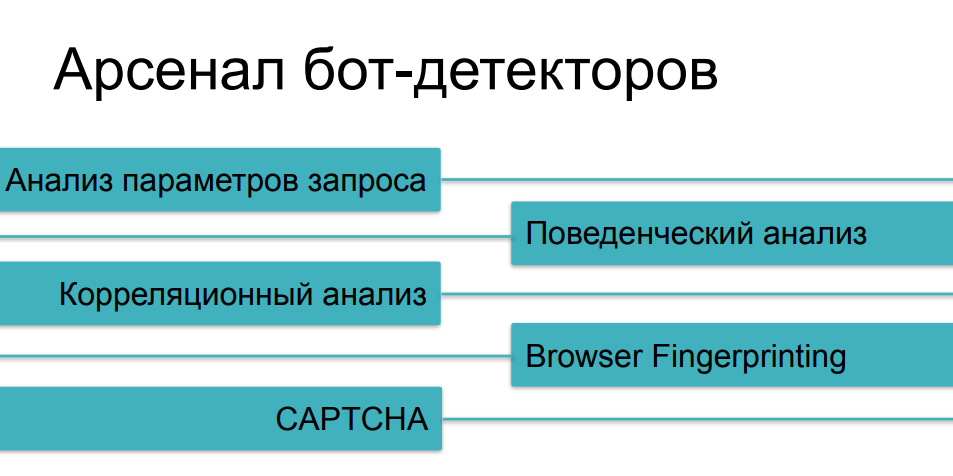
In Bezug auf die Schutzmittel, die gegen aggressives Schaben eingesetzt werden, haben wir bereits die meisten Methoden in Betracht gezogen und über verschiedene Kategorien von Bots gesprochen. Die Verkehrsanalyse hilft uns in den einfachsten Fällen. Die Verhaltensanalyse hilft uns dabei, Dinge wie Fuzzing (Identitätsersetzung) und Skripte mit mehreren Instanzen zu verfolgen. Gegen komplexere Dinge werden wir Digitaldrucke sammeln. Und natürlich haben wir ein CAPTCHA als letztes Argument der Könige - wenn wir bei den vorherigen Fragen keinen schlauen Bot fangen könnten, dann würde es wahrscheinlich über ein CAPTCHA stolpern, oder?
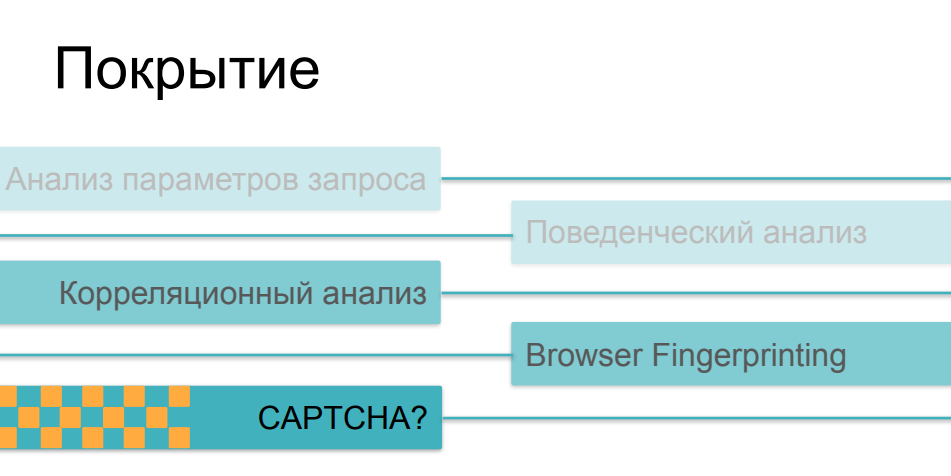
Nun, hier ist es etwas komplizierter. Tatsache ist, dass Schecks mit zunehmender Komplexität und List vor allem für den Kunden immer teurer werden. Wenn die Verkehrsanalyse und der anschließende Vergleich von Parametern mit einigen historischen Werten absolut nicht-invasiv durchgeführt werden können, ohne die Ladezeit der Seite und die Geschwindigkeit der Online-Ressource im Prinzip zu beeinflussen, kann der Fingerabdruck, wenn er massiv genug ist und Hunderte verschiedener Überprüfungen auf der Browserseite durchführt, dies tun die Download-Geschwindigkeit ernsthaft beeinträchtigen. Und nur wenige Leute sehen sich gerne Seiten mit Schecks an, während sie Links folgen.
Wenn es um CAPTCHAs geht, ist dies die gröbste und invasivste Methode. Dies ist eine Sache, die Benutzer oder Käufer wirklich von der Ressource abschrecken kann. Niemand mag Captcha, und sie wenden sich wegen eines guten Lebens nicht daran - sie greifen darauf zurück, wenn alle anderen Optionen nicht funktioniert haben. Es gibt hier noch ein lustiges Paradoxon, ein Problem bei einer solchen Anwendung dieser Methoden. Tatsache ist, dass die meisten Schutzmittel in der einen oder anderen Überlagerung alle diese Möglichkeiten nutzen, je nachdem, wie schwierig das Szenario der Bot-Aktivität ist, auf das sie gestoßen sind. Wenn es unserem Benutzer gelungen ist, Verkehrsanalysatoren zu bestehen, wenn sich sein Verhalten nicht vom Verhalten der Benutzer unterscheidet, wenn sein Fingerabdruck wie ein gültiger Browser aussieht, hat er alle diese Überprüfungen überwunden, und am Ende zeigen wir ihm das Captcha - und es stellt sich heraus, dass es sich um eine Person handelt ... es kann sehr traurig sein ...Infolgedessen wird das Captcha nicht bösen Bots gezeigt, die wir abschneiden möchten, sondern einem ziemlich ernsten Teil der Benutzer - Menschen, die sich darüber ärgern und möglicherweise das nächste Mal nicht kommen, nichts an der Ressource kaufen und nicht an ihrer weiteren Entwicklung teilnehmen.

In Anbetracht all dieser Faktoren - was sollten wir am Ende tun, wenn das Schaben zu uns kam, wir haben es uns angesehen und konnten seine Auswirkungen auf unsere geschäftlichen und technischen Indikatoren irgendwie einschätzen? Einerseits macht es keinen Sinn, per Definition gegen Scraping zu kämpfen, wie bei der Erfassung öffentlicher Daten, Maschinen oder Personen - Sie selbst haben zugestimmt, dass diese Daten jedem Benutzer zur Verfügung stehen, der aus dem Internet kommt. Und um das Problem der Begrenzung des Scrapings "aus Prinzip" zu lösen - das heißt, aufgrund der Tatsache, dass fortgeschrittene und talentierte Bot-Bots zu Ihnen kommen, versuchen Sie, sie alle zu verbieten - müssen Sie eine Menge Ressourcen für den Schutz aufwenden, entweder für sich selbst oder für die Verwendung einer teuren und sehr komplexen Lösung , selbst gehostet oder cloudbasiert im "Maximum Security Mode" und bei der Verfolgung jedes einzelnen Bots das Risiko, den Anteil gültiger Benutzer mit solchen Dingen zu verringern,wie schwere Javascript-Prüfungen, wie Captcha, das bei jedem dritten Übergang auftaucht. All dies kann Ihre Website bis zur Unkenntlichkeit zum Nachteil Ihrer Besucher verändern.
Wenn Sie ein Schutzwerkzeug verwenden möchten, müssen Sie nach solchen suchen, mit denen Sie Änderungen vornehmen und auf irgendeine Weise ein Gleichgewicht zwischen dem Anteil der Schaber (von einfach bis komplex), den Sie von der Nutzung Ihrer Ressource abschneiden möchten, und der Geschwindigkeit Ihres Webs finden können -Ressource. Denn wie wir bereits gesehen haben, werden einige Überprüfungen einfach und schnell durchgeführt, während einige Überprüfungen schwierig und zeitaufwändig sind - und gleichzeitig für die Besucher selbst sehr auffällig sind. Daher können Sie mit Lösungen, die diese Gegenmaßnahmen innerhalb einer gemeinsamen Plattform anwenden und variieren können, dieses Gleichgewicht schneller und besser erreichen.
Nun, es ist auch sehr wichtig, die so genannte "richtige Denkweise" zu verwenden, um all diese Probleme anhand ihrer eigenen oder der Beispiele anderer zu untersuchen. Es muss daran erinnert werden, dass nicht die öffentlichen Daten selbst geschützt werden müssen - früher oder später werden sie alle Personen sehen, die sie wollen. Die Benutzererfahrung muss geschützt werden: Die Benutzeroberfläche Ihrer Kunden, Kunden und Benutzer, die im Gegensatz zu Schabern Einnahmen für Sie generieren. Sie können es behalten und erhöhen, wenn Sie sich in diesem sehr interessanten Bereich besser auskennen.
Vielen Dank für Ihre Aufmerksamkeit!
