
Wir setzen den Zyklus der Notizen über echte Probleme in Data Science fort und werden uns heute mit einem lebenden Problem befassen und sehen, welche Probleme uns auf dem Weg erwarten.
Zusätzlich zu Data Science habe ich mich schon lange für Leichtathletik interessiert und eines der Ziele beim Laufen ist für mich natürlich ein Marathon. Und wo ist der Marathon dort und die Frage ist - wie viel muss man laufen? Oft wird die Antwort auf diese Frage mit dem Auge gegeben: "Nun, im Durchschnitt rennen sie" oder "Dies ist eine gute Zeit!"
Und heute werden wir uns mit einer wichtigen Angelegenheit befassen - wir werden Data Science im wirklichen Leben anwenden und die Frage beantworten:
Was sagen uns die Daten über den Moskauer Marathon?
Genauer gesagt, wie bereits zu Beginn aus der Tabelle hervorgeht, werden wir Daten sammeln, herausfinden, wer wie gelaufen ist. Gleichzeitig hilft es uns zu verstehen, ob wir uns einmischen sollten, und ermöglicht es uns, unsere Stärken vernünftig einzuschätzen!
TL; DR: Ich habe Daten zu den Moskauer Marathonrennen für 2018/2019 gesammelt, die Zeit und Leistung der Teilnehmer analysiert und den Code und die Daten öffentlich zugänglich gemacht.
Datensammlung
Durch schnelles Googeln haben wir die Ergebnisse der letzten Jahre, 2019 und 2018, gefunden .
Ich habe mir die Webseite genau angesehen und festgestellt, dass die Daten recht einfach zu erhalten sind. Sie müssen nur herausfinden, welche Klassen für was verantwortlich sind, z. B. die Klasse "results-table__col-result", natürlich für das Ergebnis usw.
Es bleibt zu verstehen, wie alle Daten von dort abgerufen werden können.
Und dies ist, wie sich herausstellt, nicht schwierig, da es eine direkte Paginierung gibt und wir tatsächlich über das gesamte Zahlensegment iterieren. Bingo, ich poste die gesammelten Daten für 2019 und 2018 hier. Wenn jemand an weiteren Analysen interessiert ist, können die Daten selbst hier heruntergeladen werden: hier und hier .
Womit musste ich basteln?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- Datentypen: Die Zeit hier ist Zeitdelta, aber aufgrund von Neustarts und ungültigen Werten müssen wir mit Filtern und Löschzeitwerten arbeiten, damit wir mit reinen Zeitergebnissen arbeiten, um Durchschnittswerte zu berechnen Wer hat eine gültige Zeit.
Und hier ist der Spoiler-Code für den Fall, dass jemand weiterhin interessante Laufdaten sammelt.
Parser-Code
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
Analyse von Zeit und Ergebnissen
Fahren wir mit der Analyse der Daten und der tatsächlichen Rennergebnisse fort.
Gebrauchte Pandas, Numpy, Matplotlib und Seaborn - alles in den Klassikern.
Zusätzlich zu den Durchschnittswerten für alle Arrays werden die folgenden Gruppen separat betrachtet:
- Männer - da ich zu dieser Gruppe gehöre, sind diese Ergebnisse für mich interessant.
- Frauen sind für Symmetrie.
- 35 — «» , — .
- 2018 2019 — ?.
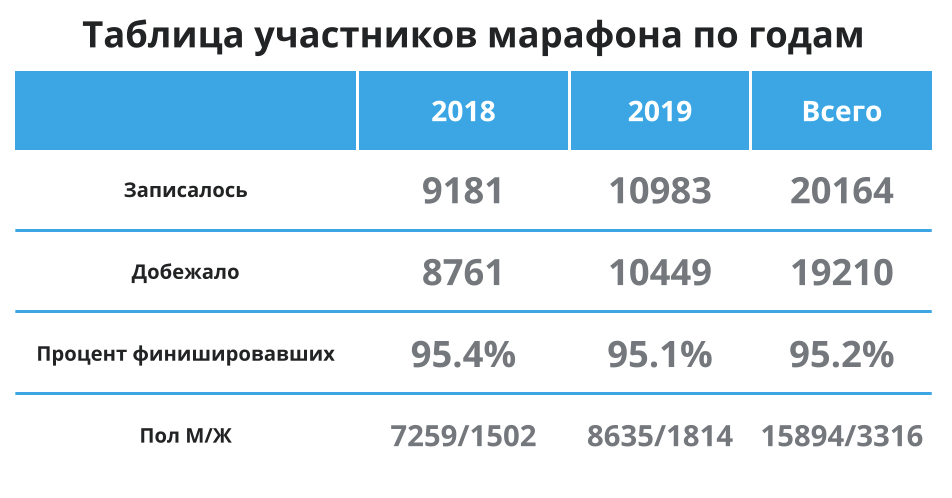
Lassen Sie uns zunächst einen kurzen Blick auf die folgende Tabelle werfen - hier noch einmal, um nicht zu scrollen: Es gibt mehr Teilnehmer, durchschnittlich 95% erreichen die Ziellinie, und die meisten Teilnehmer sind Männer. Okay, das bedeutet, dass ich im Durchschnitt in der Hauptgruppe bin und die Daten im Durchschnitt die durchschnittliche Zeit für mich gut darstellen sollten. Lass uns weitermachen.

Wie wir sehen können, haben sich die Durchschnittswerte für 2018 und 2019 praktisch nicht geändert - etwa 1,5 Minuten waren für Läufer im Jahr 2019 schneller. Der Unterschied zwischen den Gruppen, an denen ich interessiert bin, ist vernachlässigbar.
Kommen wir zu den Distributionen als Ganzes. Und zuerst zur Gesamtzeit des Rennens.
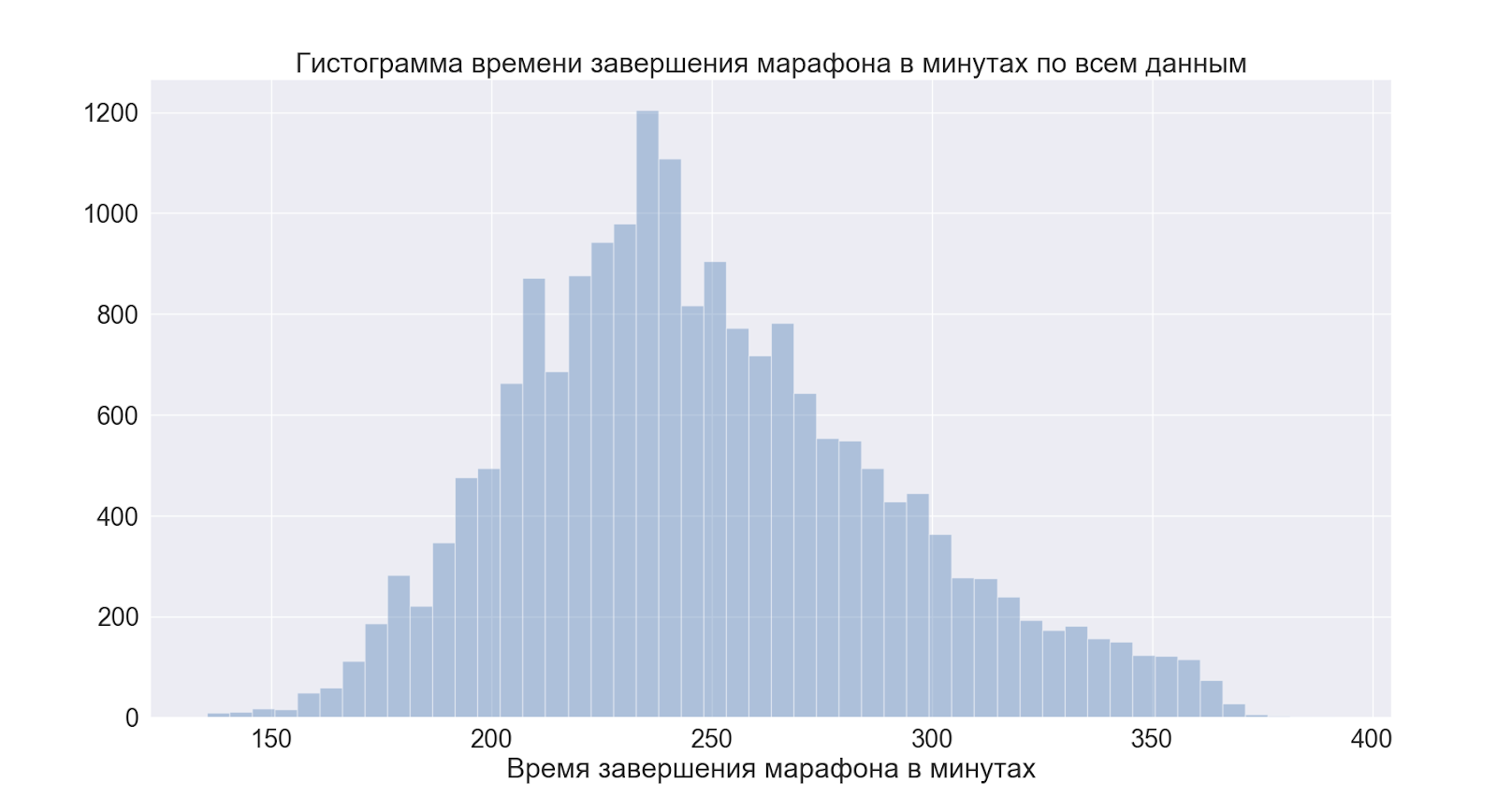
Da wir den Höhepunkt kurz vor 4 Uhr sehen - dies ist eine bedingte Marke für diejenigen, die gut laufen möchten = keine 4 Uhr mehr haben -, bestätigen die Daten das populäre Gerücht.
Als nächstes wollen wir sehen, wie sich die Situation im Durchschnitt im Laufe des Jahres verändert hat.
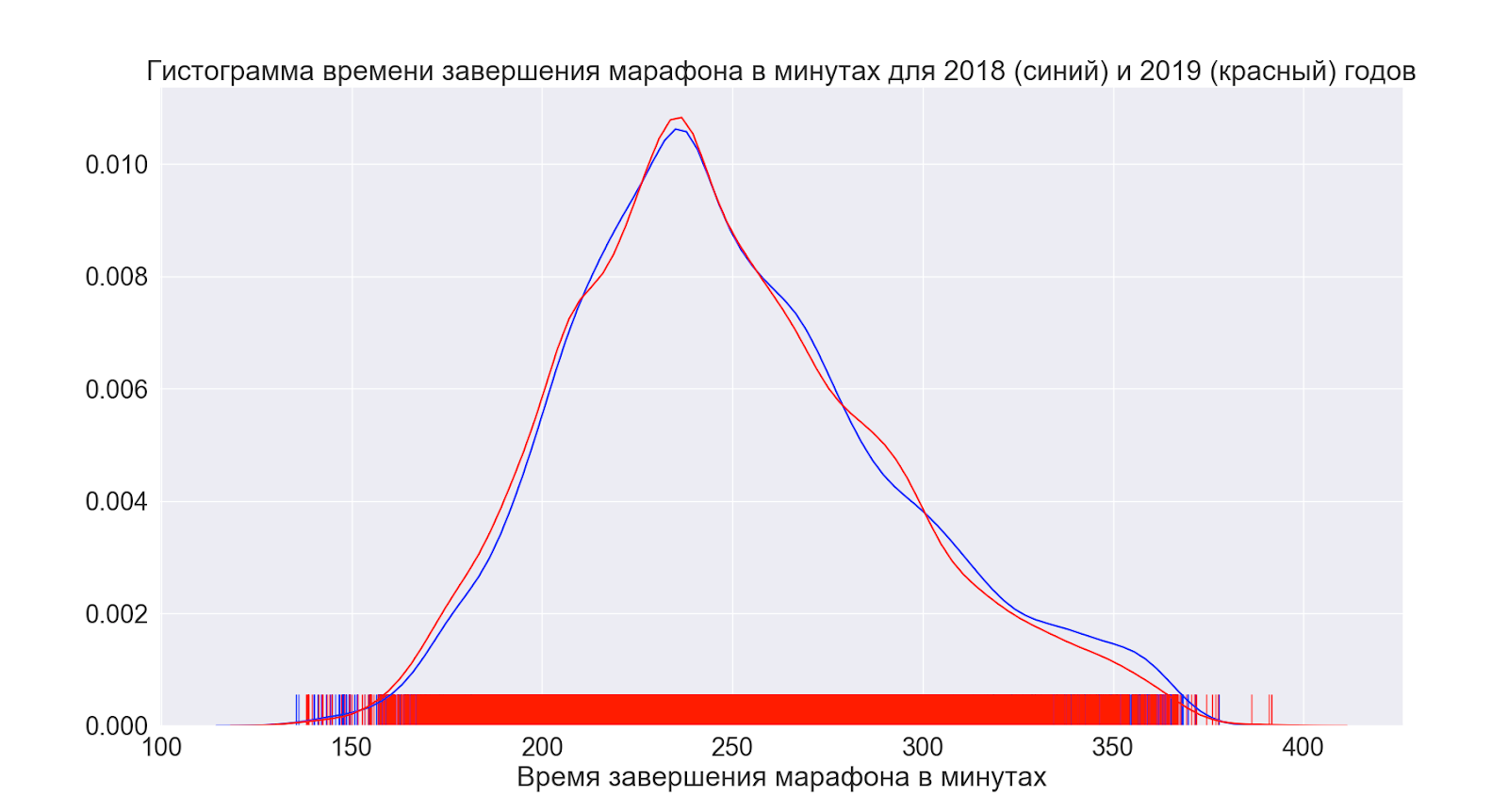
Wie wir sehen können, hat sich überhaupt nichts geändert - die Verteilungen sehen praktisch identisch aus.
Betrachten Sie als nächstes die Verteilungen nach Geschlecht:

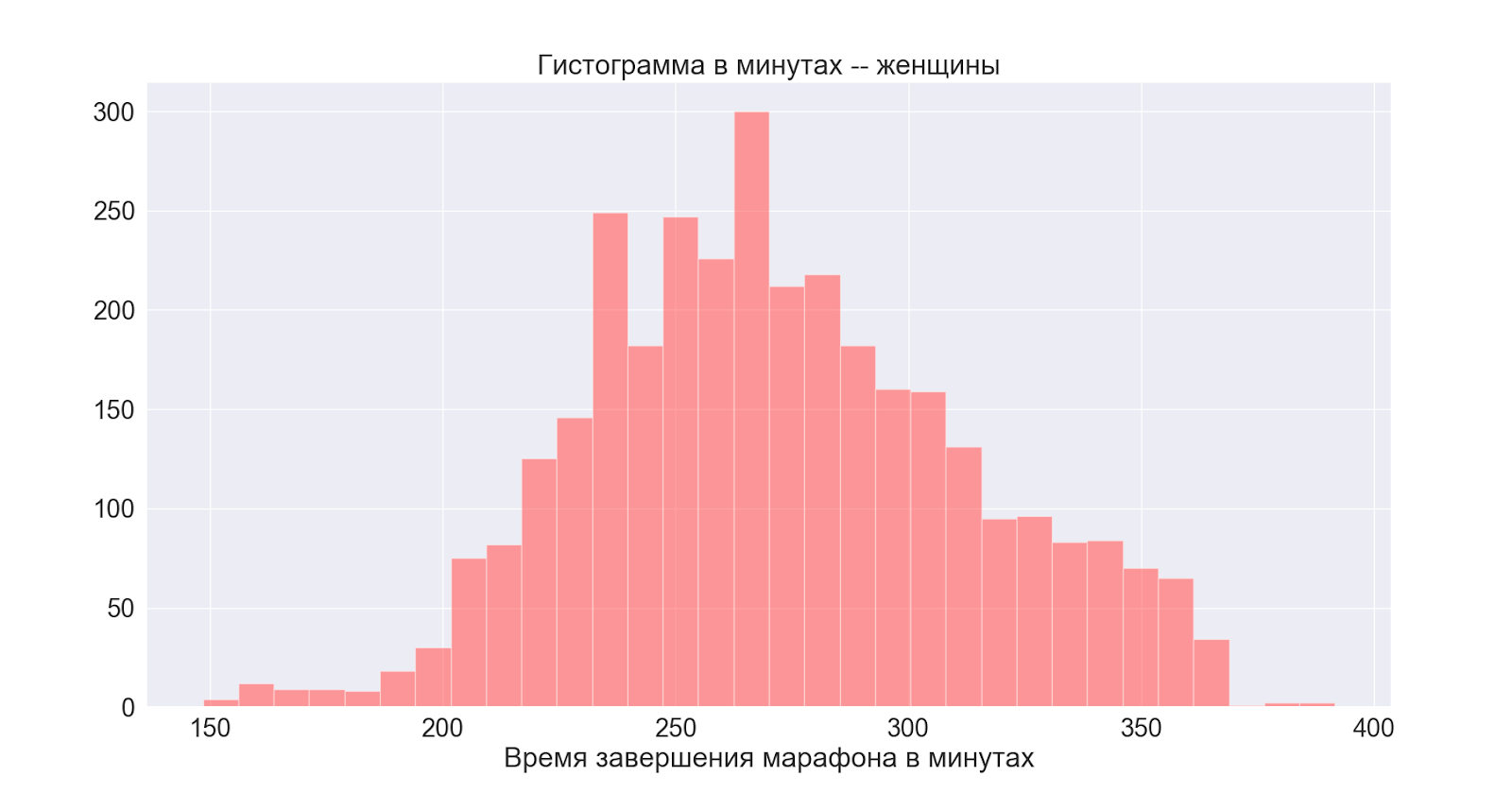
Im Allgemeinen sind beide Verteilungen normal mit leicht unterschiedlichen Zentren - wir sehen, dass sich der Peak beim Mann auch in der Hauptverteilung (allgemein) manifestiert.
Kommen wir getrennt zu der für mich interessantesten Gruppe:
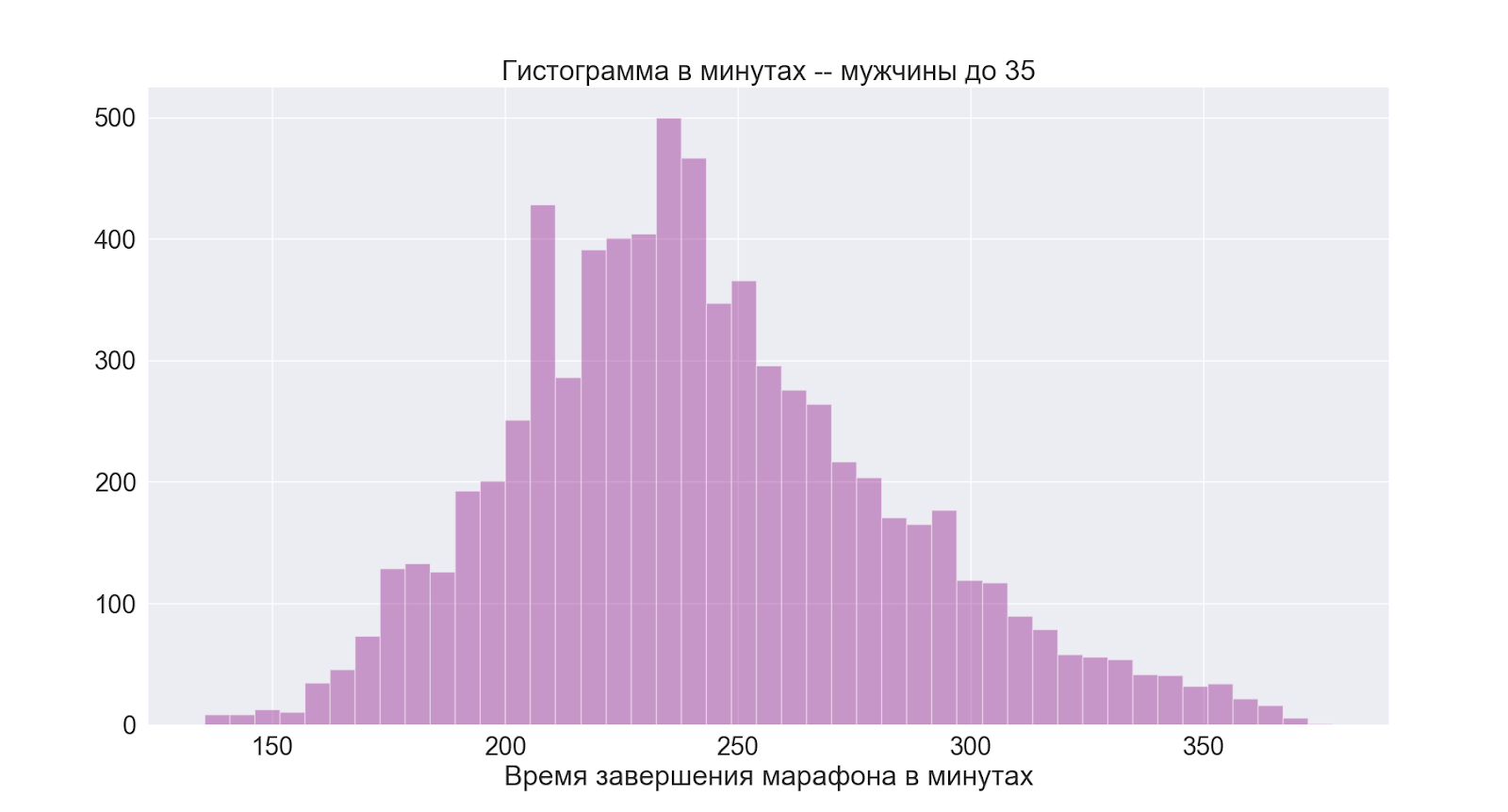
Wie wir sehen können, ist das Bild im Grunde das gleiche wie in der gesamten männlichen Gruppe.
Daraus schließen wir, dass 4 Stunden auch eine gute Durchschnittszeit für mich sind.
Untersuchung der Verbesserungen der Teilnehmer 2018 → 2019
Interessant: Aus irgendeinem Grund dachte ich, dass ich jetzt schnell die Daten sammeln und tiefer in die Analyse einsteigen, dort stundenlang nach Mustern suchen und so weiter könnte. Es stellte sich heraus, dass das Gegenteil der Fall war. Die Datenerfassung erwies sich als schwieriger als die Analyse selbst. Laut den Klassikern dauerte die Arbeit mit dem Netzwerk, den Rohdaten, die Reinigung, Formatierung, das Casting usw. viel länger als die Analyse und Visualisierung. Vergessen Sie nicht, dass kleine Dinge etwas Zeit in Anspruch nehmen - aber es gibt einige davon [kleine Dinge], und am Ende werden sie Ihren ganzen Abend essen.
Unabhängig davon wollte ich sehen, wie die Personen, die beide Male teilnahmen, ihre Ergebnisse verbesserten, indem ich die Daten zwischen den Jahren verglich und Folgendes feststellen konnte:
- 14 Personen haben beide Jahre teilgenommen und sind nie fertig geworden
- 89 Menschen liefen auf 18 m, scheiterten aber mit 19
- 124 umgekehrt
- Diejenigen, die beide Male laufen konnten, verbesserten ihr Ergebnis um durchschnittlich 4 Minuten
Aber hier hat sich alles als sehr interessant herausgestellt:
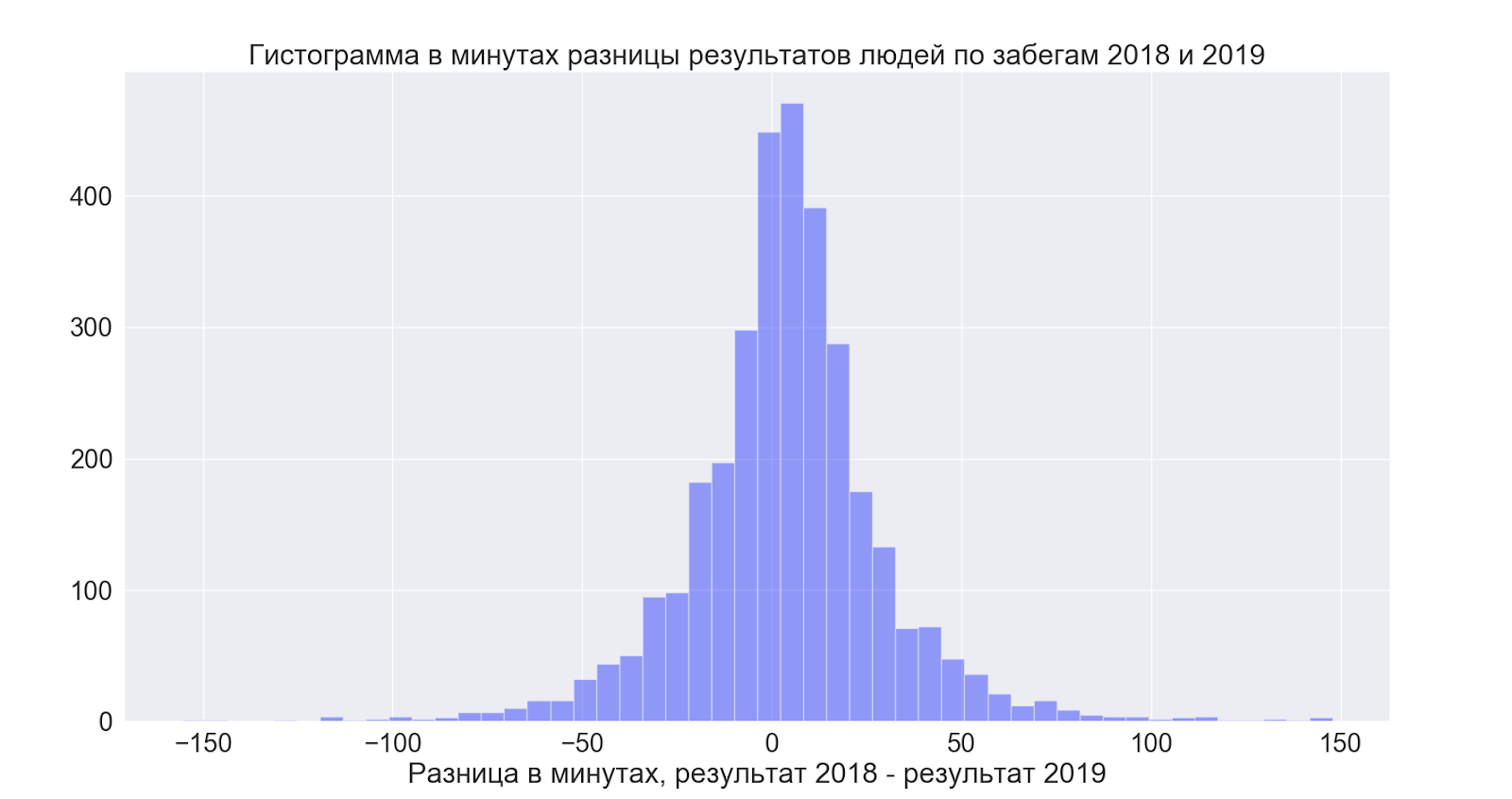
Das heißt, die Leute verbessern die Ergebnisse im Durchschnitt leicht - aber im Allgemeinen ist die Verbreitung unglaublich und in beide Richtungen - das heißt, es ist gut zu hoffen, dass es besser wird - aber nach den Daten zu urteilen, stellt sich im Allgemeinen heraus, wie Sie möchten!
Schlussfolgerungen
Aus den analysierten Daten habe ich folgende Schlussfolgerungen gezogen
- Insgesamt sind 4 Stunden ein gutes durchschnittliches Ziel.
- Die Hauptgruppe der Läufer befindet sich bereits im sehr wettbewerbsintensiven Alter (und in derselben Gruppe wie ich).
- Im Durchschnitt verbessern die Menschen ihre Ergebnisse leicht, aber im Allgemeinen, gemessen an den Daten, wie sie überhaupt dorthin gelangen.
- Die durchschnittlichen Ergebnisse für das gesamte Rennen sind für beide Jahre ungefähr gleich.
- Es ist sehr angenehm, von der Couch aus über den Marathon zu sprechen.
