
In den letzten drei Jahren hat Nvidia Grafikchips entwickelt, in denen neben den für Shader üblichen Kernen weitere installiert sind. Diese als Tensorkerne bezeichneten Kerne befinden sich bereits in Tausenden von Desktops, Laptops, Workstations und Rechenzentren auf der ganzen Welt. Aber was machen sie und wofür werden sie verwendet? Werden sie überhaupt in Grafikkarten benötigt?
Heute werden wir erklären, was ein Tensor ist und wie Tensorkerne in der Grafik- und Deep-Learning-Welt verwendet werden.
Eine kurze Mathe-Lektion
Um zu verstehen, was Tensorkerne tun und wofür sie verwendet werden können, müssen wir zunächst herausfinden, was Tensoren sind. Alle Mikroprozessoren führen unabhängig von ihrer Aufgabe mathematische Operationen an Zahlen aus (Addition, Multiplikation usw.).
Manchmal müssen diese Zahlen gruppiert werden, weil sie eine bestimmte Bedeutung für einander haben. Wenn der Chip beispielsweise Daten verarbeitet, um Grafiken zu rendern, kann er einzelne ganzzahlige Werte (z. B. +2 oder +115) als Skalierungsfaktor oder eine Gruppe von Floats (+0,1, -0,5, +0,6) als Koordinaten eines Punktes im 3D-Raum. Im zweiten Fall werden alle drei Datenelemente für die Punktposition benötigt.
TensorIst ein mathematisches Objekt, das die Beziehungen zwischen anderen miteinander verbundenen mathematischen Objekten beschreibt. Sie werden normalerweise als Array von Zahlen angezeigt , deren Abmessungen unten angegeben sind.

Der einfachste Tensortyp hat die Dimension Null und besteht aus einem einzelnen Wert. Andernfalls wird es als Skalar bezeichnet . Mit zunehmender Anzahl von Dimensionen stoßen wir auf andere gängige mathematische Strukturen:
- 1 Dimension = Vektor
- 2 Dimensionen = Matrix
Streng genommen ist ein Skalar ein Tensor 0 x 0, ein Vektor 1 x 0 und eine Matrix 1 x 1, aber der Einfachheit halber und in Bezug auf die Tensorkerne der GPU werden wir Tensoren nur in Form von Matrizen betrachten.
Eine der wichtigsten mathematischen Operationen, die an Matrizen ausgeführt werden, ist die Multiplikation (oder das Produkt). Schauen wir uns an, wie zwei Matrizen mit vier Zeilen und Spalten von Daten miteinander multipliziert werden:
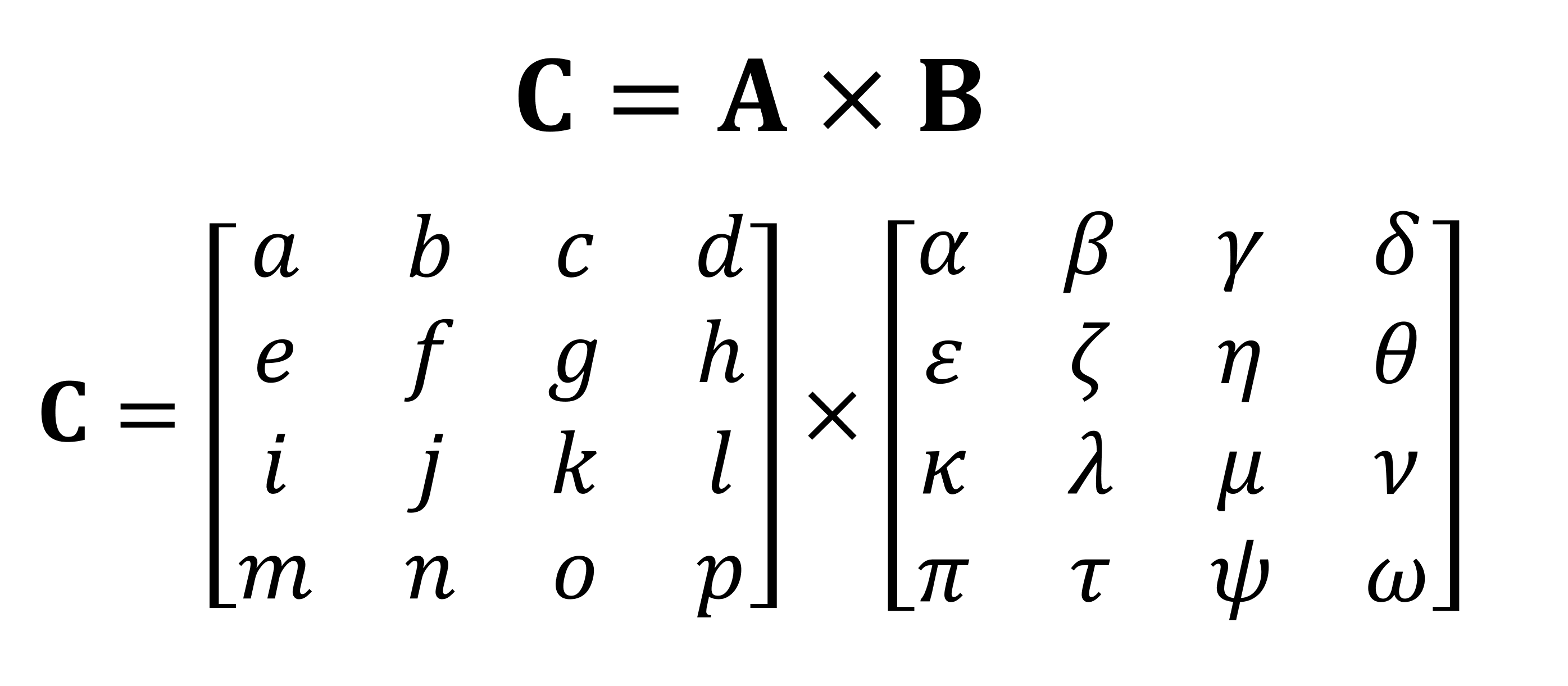
Das Endergebnis der Multiplikation ist immer die gleiche Anzahl von Zeilen wie in der ersten Matrix und die gleiche Anzahl von Spalten wie in der zweiten. Wie multiplizieren Sie diese beiden Arrays? So:
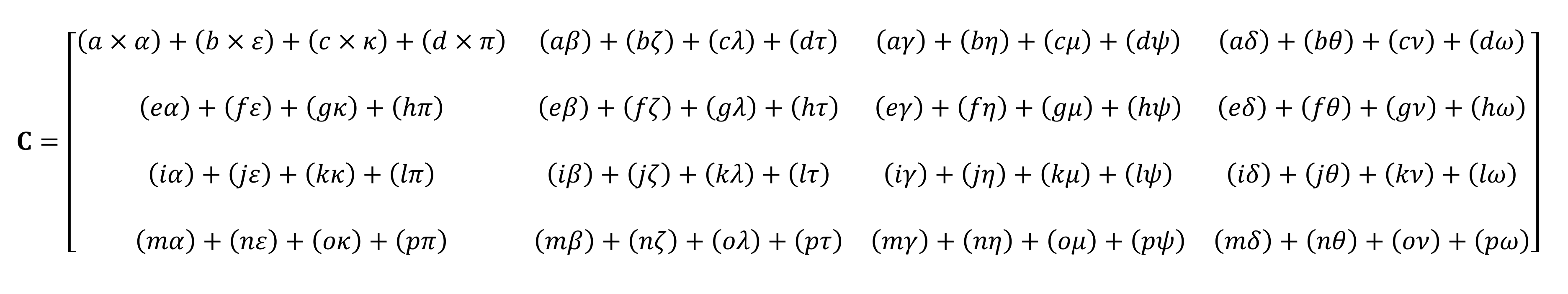
Es wird nicht möglich sein, es an den Fingern zu zählen.
Wie Sie sehen können, besteht die Berechnung des "einfachen" Produkts von Matrizen aus einer ganzen Reihe kleiner Multiplikationen und Additionen. Da jede moderne Zentraleinheit beide Vorgänge ausführen kann, können die einfachsten Tensoren von jedem Desktop, Laptop oder Tablet ausgeführt werden.
Das oben gezeigte Beispiel enthält jedoch 64 Multiplikationen und 48 Additionen; Jedes kleine Produkt gibt einen Wert an, der irgendwo gespeichert werden muss, bevor er zu den anderen drei kleinen Produkten hinzugefügt werden kann, damit der endgültige Tensorwert später gespeichert werden kann. Daher sind sie trotz der mathematischen Einfachheit von Matrixmultiplikationen rechenintensiv . - Es müssen viele Register verwendet werden, und der Cache muss in der Lage sein, eine Reihe von Lese- und Schreibvorgängen zu bewältigen.

Intel Sandy Bridge-Architektur, die erstmals AVX-Erweiterungen einführte
Im Laufe der Jahre hatten AMD- und Intel-Prozessoren verschiedene Erweiterungen (MMX, SSE und jetzt AVX - allesamt SIMD, Single-Instruction-Multiple-Daten ), sodass der Prozessor viele Zahlen gleichzeitig verarbeiten kann Gleitkomma; Dies ist genau das, was für die Matrixmultiplikation erforderlich ist.
Es gibt jedoch einen speziellen Prozessortyp, der speziell für SIMD-Vorgänge entwickelt wurde: die Grafikverarbeitungseinheit (GPU).
Klüger als ein normaler Taschenrechner?
In der Welt der Grafik ist es notwendig, gleichzeitig große Informationsmengen in Form von Vektoren zu übertragen und zu verarbeiten. GPUs sind aufgrund ihrer Parallelverarbeitungsfähigkeit ideal für die Tensorverarbeitung. Alle modernen GPUs unterstützen eine Funktionalität namens GEMM ( General Matrix Multiplication ).
Dies ist eine "geklebte" Operation, bei der zwei Matrizen multipliziert werden und das Ergebnis dann mit einer anderen Matrix akkumuliert wird. Das Format der Matrizen unterliegt wichtigen Einschränkungen, die sich alle auf die Anzahl der Zeilen und Spalten jeder Matrix beziehen.

GEMM-Zeilen- und Spaltenanforderungen: Matrix A (mxk), Matrix B (kxn), Matrix C (mxn)
Die Algorithmen, die zum Ausführen von Operationen an Matrizen verwendet werden, funktionieren normalerweise am besten, wenn Matrizen quadratisch sind (z. B. funktioniert ein 10 × 10-Array besser als 50 x 2) und eher klein. Sie arbeiten jedoch immer noch besser, wenn sie auf Geräten verarbeitet werden, die ausschließlich für solche Vorgänge ausgelegt sind.
Im Dezember 2017 veröffentlichte Nvidia eine Grafikkarte mit einer GPU mit der neuen Volta- Architektur . Es war auf professionelle Märkte ausgerichtet, daher wurde dieser Chip in GeForce-Modellen nicht verwendet. Es war einzigartig, weil es die erste GPU mit Kernen nur für Tensorberechnungen war.

Eine Nvidia Titan V-Grafikkarte mit einem GV100 Volta-Chip. Ja, können Sie Crysis laufen auf es Nvidias
Tensor Kerne wurden entwickelt , um ausführen 64 GEMMS pro Taktzyklus mit 4 x 4 Matrizen enthalten , FP16 - Werte (Gleitkommazahlen von 16 Bit) oder FP16 Multiplikation mit FP32 hinaus. Solche Tensoren sind sehr klein, so dass die Kernel bei der Verarbeitung realer Datensätze kleine Teile großer Matrizen verarbeiten und so die endgültige Antwort bilden.
Weniger als ein Jahr später veröffentlichte Nvidia die Turing- Architektur . Dieses Mal wurden auch Tensorkerne im GeForce-Modell installiertVerbraucherebene. Das System wurde verbessert, um andere Datenformate wie INT8 (8-Bit-Integer-Wert) zu unterstützen, ansonsten funktionierten sie genauso wie in Volta.

Anfang dieses Jahres debütierte die Ampere- Architektur in der GPU des A100-Rechenzentrums , und diesmal verbesserte Nvidia die Leistung (256 GEMM pro Zyklus anstelle von 64), fügte neue Datenformate hinzu und die Fähigkeit, sehr schnelle Tensoren mit geringer Dichte (Matrizen mit vielen) zu verarbeiten Nullen).
Programmierer können sehr einfach auf die Tensorkerne von Volta-, Turing- und Ampere-Chips zugreifen : Der Code muss nur ein Flag verwenden, das der API und den Treibern die Verwendung von Tensorkernen mitteilt, der Datentyp muss von den Kernen unterstützt werden und die Matrixdimensionen müssen ein Vielfaches von 8 sein Alle diese Bedingungen werden von der Ausrüstung berücksichtigt.
Das ist alles großartig, aber wie viel besser können Tensorkerne GEMM verarbeiten als normale GPU-Kerne?
Als die Volta herauskam, führte Anandtech Mathe-Tests mit drei Nvidia-Karten durch: der neuen Volta, der mächtigsten der Pascal-Reihe, und der alten Maxwell-Karte.
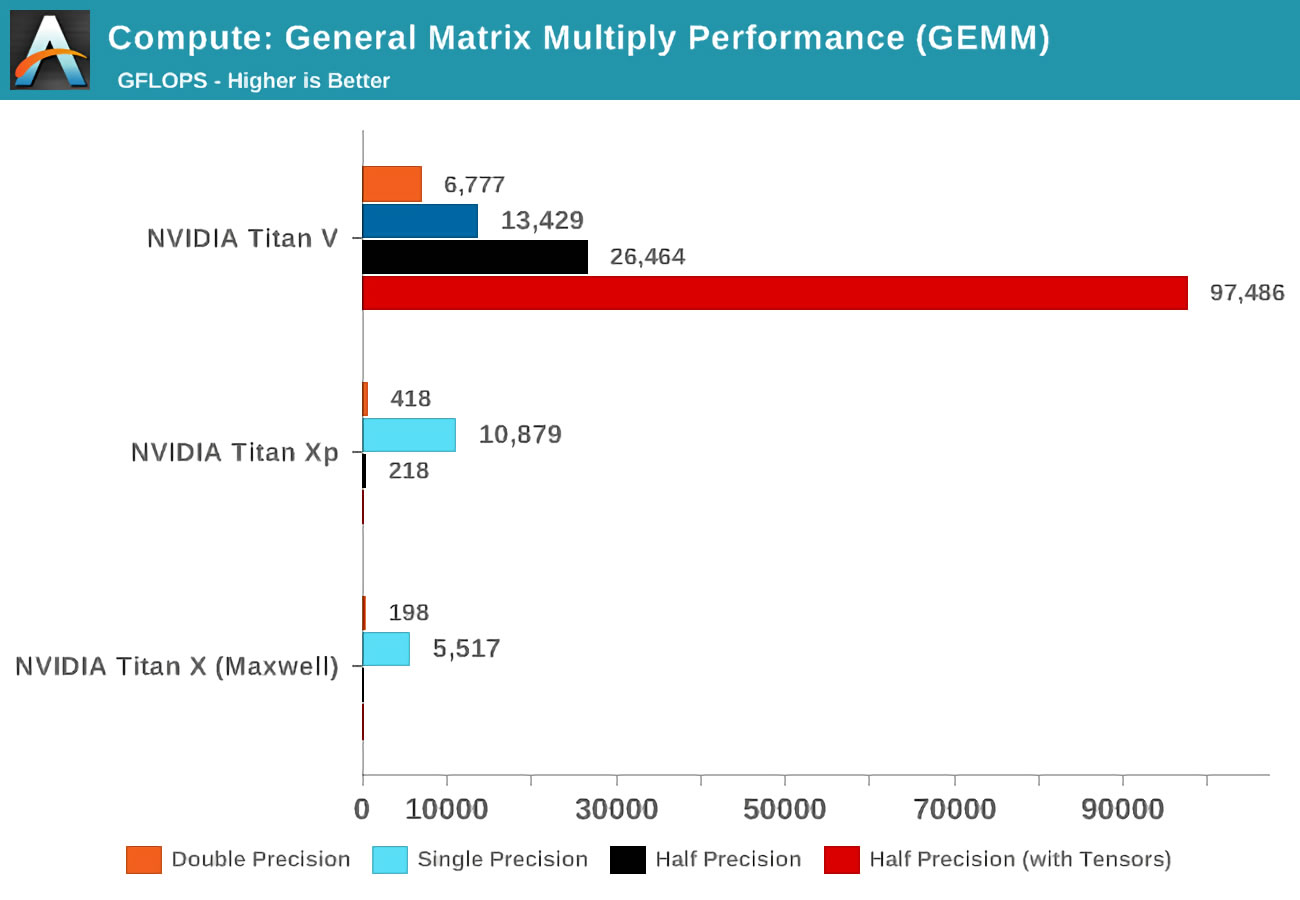
Das Konzept der Genauigkeit (Präzision) bezieht sich auf die Anzahl der Bits, die für Gleitkommazahlen in den Matrizen verwendet werden: double (double) bezeichnet 64, single (single) - 32 usw. Die horizontale Achse ist die maximale Anzahl von Gleitkommaoperationen pro Sekunde, kurz FLOPs (denken Sie daran, dass ein GEMM 3 FLOPs ist).
Schauen Sie sich einfach die Ergebnisse an, wenn Sie Tensorkerne anstelle der sogenannten CUDA-Kernel verwenden! Natürlich sind sie bei diesem Job großartig, aber was können wir mit Tensorkernen machen?
Die Mathematik, die alles besser macht
Tensor-Computing ist in der Physik und Technik äußerst nützlich. Es wird verwendet, um alle möglichen komplexen Probleme in der Strömungsmechanik , im Elektromagnetismus und in der Astrophysik zu lösen. Die Computer, die zur Verarbeitung solcher Zahlen verwendet wurden, führten jedoch normalerweise Matrixoperationen in großen Clustern von Zentraleinheiten aus aus.
Ein weiterer Bereich, in dem Tensoren beliebt sind, ist das maschinelle Lernen , insbesondere der Unterabschnitt "Deep Learning". Seine Bedeutung läuft darauf hinaus, riesige Datensätze in riesigen Arrays zu verarbeiten, die als neuronale Netze bezeichnet werden . Verbindungen zwischen verschiedenen Datenwerten wird ein bestimmtes Gewicht zugewiesen - eine Zahl, die die Wichtigkeit einer bestimmten Verbindung ausdrückt.
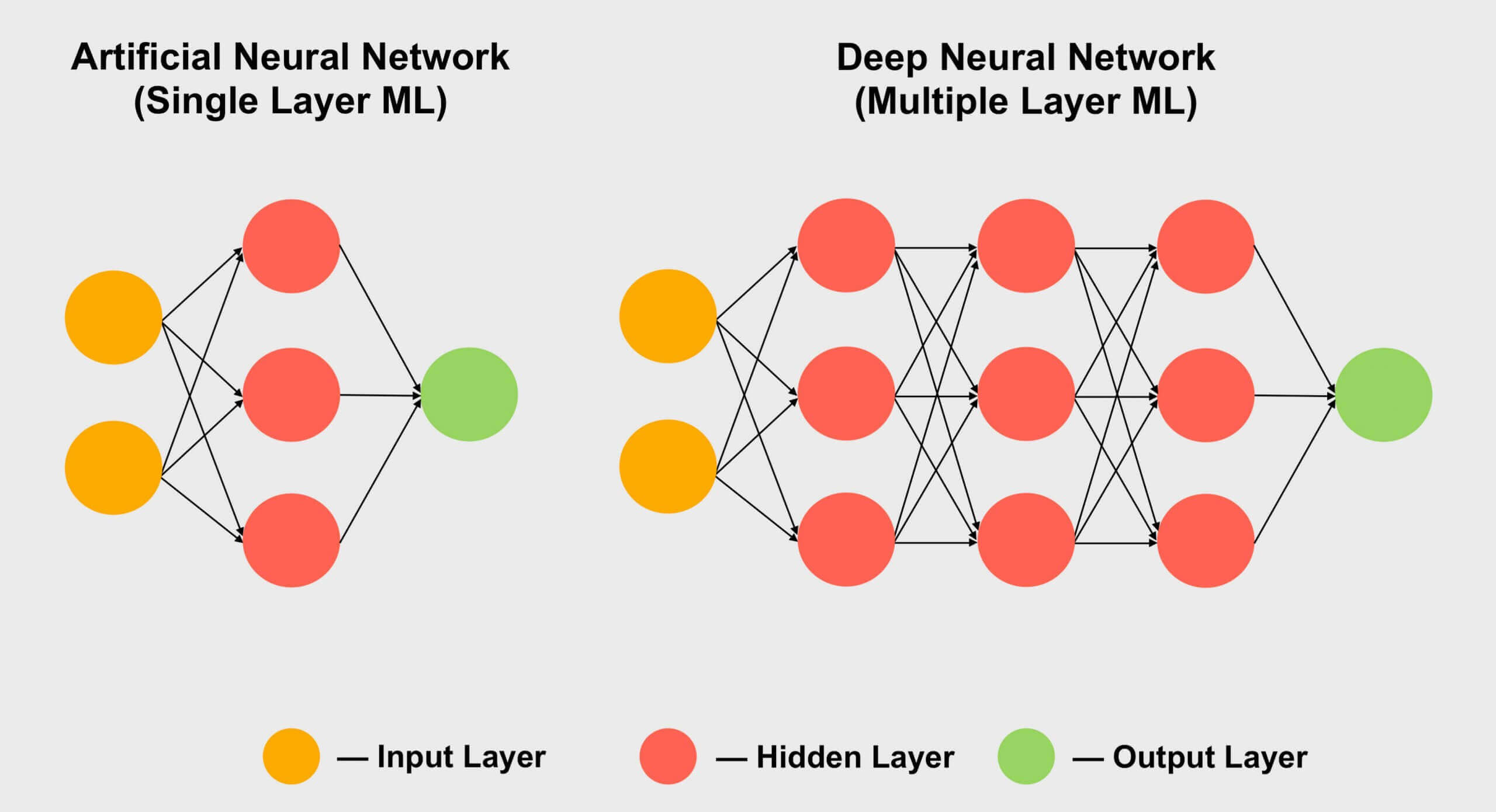
Wenn wir also herausfinden müssen, wie all diese Hunderte, wenn nicht Tausende von Verbindungen interagieren, müssen wir jedes Datenelement im Netzwerk mit allen möglichen Verbindungsgewichten multiplizieren. Mit anderen Worten, multiplizieren Sie zwei Matrizen, was klassische Tensormathematik ist!

Google TPU 3.0-Chips, die von einem Wasserkühlungssystem abgedeckt werden Aus
diesem Grund verwenden alle Deep-Learning-Supercomputer GPUs, und es handelt sich fast immer um Nvidia. Einige Unternehmen haben jedoch sogar eigene Prozessoren aus Tensorkernen entwickelt. Google hat beispielsweise die Entwicklung seiner ersten TPU ( Tensor Processing Unit ) im Jahr 2016 angekündigt. Diese Chips sind jedoch so spezialisiert, dass sie nur mit Matrizen arbeiten können.
Tensorkerne in Consumer-GPUs (GeForce RTX)
Aber was ist, wenn ich eine Nvidia GeForce RTX-Grafikkarte kaufe, kein Astrophysiker bin, der Riemannsche vielfältige Probleme löst, oder ein Experte, der mit Faltungstiefen neuronaler Netze experimentiert ...? Wie kann ich Tensorkerne verwenden?
Meistens gelten sie nicht für das normale Rendern, Codieren oder Decodieren von Videos. Es scheint also, als hätten Sie Geld für eine nutzlose Funktion verschwendet. Nvidia hat jedoch 2018 Tensorkerne in seine Verbraucherprodukte eingebaut (Turing GeForce RTX), während DLSS - Deep Learning Super Sampling implementiert wurde .

Das Prinzip ist einfach: Rendern Sie den Frame mit einer relativ niedrigen Auflösung und erhöhen Sie nach Abschluss die Auflösung des Endergebnisses so, dass sie den "nativen" Bildschirmabmessungen des Monitors entspricht (z. B. mit 1080p rendern und dann die Größe auf 1400p ändern). Dies verbessert die Leistung, da weniger Pixel verarbeitet werden und der Bildschirm immer noch ein schönes Bild erzeugt.
Konsolen haben diese Funktion seit Jahren, und viele moderne PC-Spiele bieten diese Funktion ebenfalls an. In Assassin's Creed: Odyssey von Ubisoft können Sie die Renderauflösung auf nur 50% der Monitorauflösung reduzieren. Leider sehen die Ergebnisse nicht so hübsch aus. So sieht das Spiel in 4K mit maximalen Grafikeinstellungen aus:

Texturen sehen bei hohen Auflösungen besser aus, weil sie detaillierter bleiben. Das Anzeigen dieser Pixel auf dem Bildschirm erfordert jedoch viel Verarbeitung. Schauen Sie sich nun an, was passiert, wenn das Rendering auf 1080p (25% der vorherigen Pixelanzahl) eingestellt ist, und strecken Sie das Bild mit den Shadern am Ende auf 4K.

Aufgrund der JPEG-Komprimierung ist der Unterschied möglicherweise nicht sofort erkennbar, aber Sie können sehen, dass die Rüstung des Charakters und der Stein in der Ferne verschwommen aussehen. Vergrößern wir einen Teil des Bildes für einen genaueren Blick:

Das Bild links wird in 4K gerendert. Das Bild rechts ist 1080p und auf 4K gestreckt. Der Unterschied macht sich in der Bewegung viel deutlicher bemerkbar, da das Erweichen aller Details schnell zu einem verschwommenen Durcheinander wird. Ein Teil der Schärfe kann dank des Schärfeeffekts der Grafikkartentreiber wiederhergestellt werden, aber wir wünschten, wir müssten dies überhaupt nicht tun.
Hier kommt DLSS ins Spiel - in der ersten VersionDiese Technologie Nvidia analysierte mehrere ausgewählte Spiele. Sie liefen mit hohen Auflösungen, niedrigen Auflösungen, mit und ohne Anti-Aliasing. In all diesen Modi wurde eine Reihe von Bildern generiert und dann in die Supercomputer des Unternehmens geladen, die mithilfe eines neuronalen Netzwerks bestimmten, wie ein 1080p-Bild am besten in ein ideales Bild mit höherer Auflösung umgewandelt werden kann.

Ich muss sagen, dass DLSS 1.0 nicht perfekt war : Details gingen oft verloren und an einigen Stellen trat seltsames Flackern auf. Außerdem wurden die Tensorkerne der Grafikkarte selbst nicht verwendet (sie lief im Nvidia-Netzwerk), und für jedes DLSS-fähige Spiel war eine separate Nvidia-Untersuchung erforderlich, um den Upscaling-Algorithmus zu generieren.

Als die Version 2.0 Anfang 2020 veröffentlicht wurde, wurden wesentliche Verbesserungen vorgenommen. Am wichtigsten ist, dass die Supercomputer von Nvidia nur noch zur Erstellung eines allgemeinen Upscaling-Algorithmus verwendet wurden. Die neue Version von DLSS verwendet Daten aus einem gerenderten Frame, um Pixel mithilfe eines neuronalen Modells (GPU-Tensorkerne) zu verarbeiten.

Wir sind beeindruckt von den Funktionen von DLSS 2.0 , aber bisher unterstützen es nur sehr wenige Spiele - zum Zeitpunkt dieses Schreibens waren es nur 12. Immer mehr Entwickler möchten es in ihren zukünftigen Spielen implementieren, und das aus gutem Grund.
Jede Vergrößerung kann zu erheblichen Produktivitätssteigerungen führen, sodass Sie sicher sein können, dass sich DLSS weiterentwickelt.
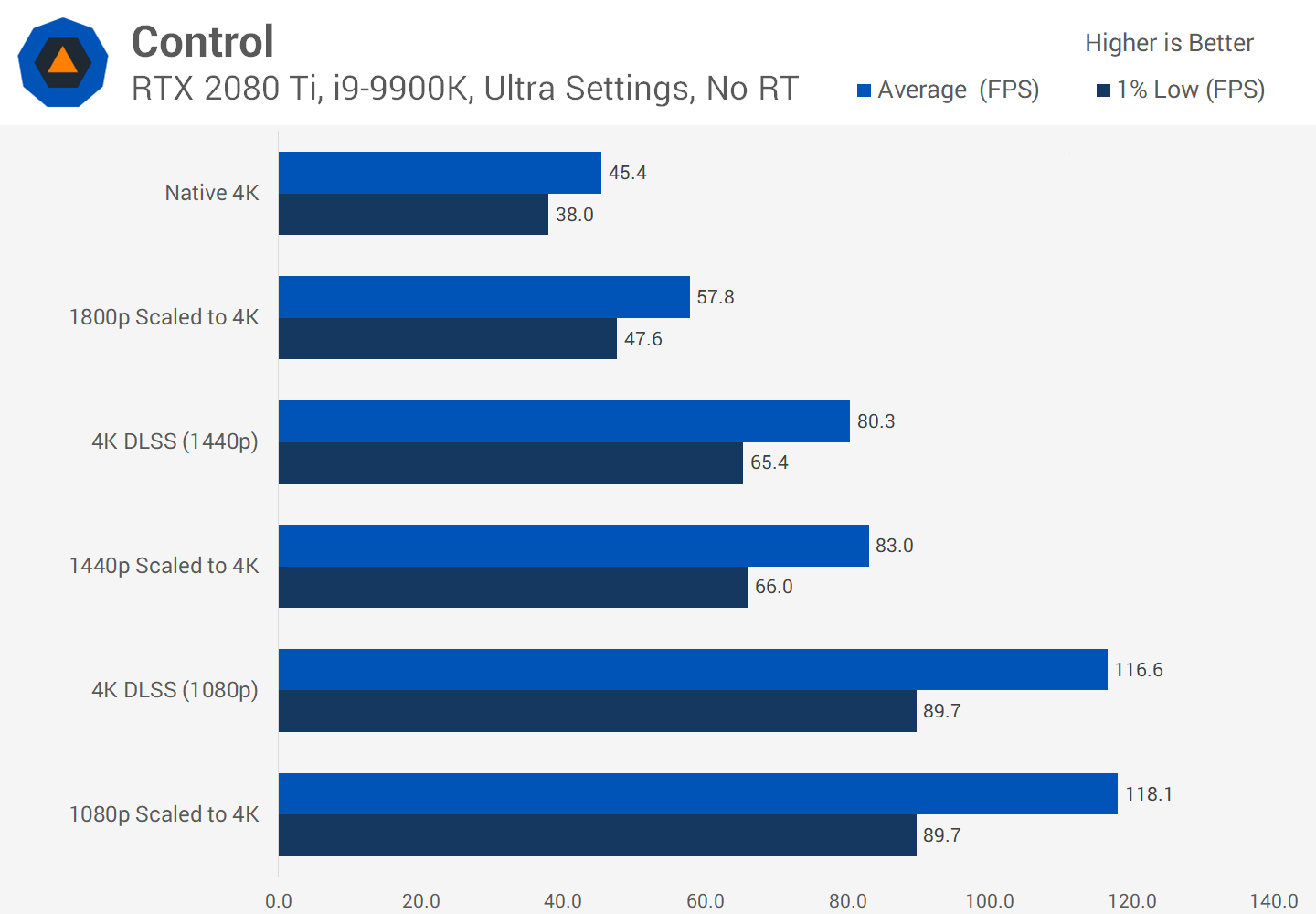
Obwohl die visuellen Ergebnisse von DLSS nicht immer perfekt sind, können Entwickler durch die Freigabe von Rendering-Ressourcen mehr visuelle Effekte hinzufügen oder eine Grafikebene für eine größere Anzahl von Plattformen bereitstellen.
Beispielsweise wird DLSS häufig zusammen mit Raytracing in "RTX-fähigen" Spielen beworben. GeForce RTX-Karten enthalten zusätzliche Rechenblöcke, die als RT-Kerne bezeichnet werden. Hierbei handelt es sich um spezielle Logikblöcke zur Beschleunigung von Schnittpunkten von Strahlendreiecken und zum Durchlaufen der Bounding Volume Hierarchy (BVH). Diese beiden Prozesse sind sehr zeitaufwändige Verfahren, die bestimmen, wie Licht mit anderen Objekten in der Szene interagiert.
Wie wir herausgefunden haben, RaytracingDies ist ein sehr zeitaufwändiger Prozess. Um eine akzeptable Bildrate in Spielen zu gewährleisten, müssen Entwickler die Anzahl der in der Szene durchgeführten Strahlen und Reflexionen begrenzen. Dieser Prozess kann körnige Bilder erzeugen, daher muss ein Rauschunterdrückungsalgorithmus angewendet werden, der die Verarbeitungskomplexität erhöht. Es wird erwartet, dass Tensorkerne die Leistung dieses Prozesses verbessern, indem sie Rauschen mithilfe von KI eliminieren. Dies muss jedoch noch realisiert werden: Die meisten modernen Anwendungen verwenden für diese Aufgabe immer noch CUDA-Kernel. Da DLSS 2.0 zu einer sehr praktischen Upsizing-Technik wird, können Tensor-Kernel effektiv verwendet werden, um die Bildraten nach dem Raytracing in einer Szene zu erhöhen.
Es gibt andere Pläne, die Tensorkerne von GeForce RTX-Karten zu nutzen, z. B. die Verbesserung von Charakteranimationen oder die Gewebesimulation . Aber wie bei DLSS 1.0 wird es lange dauern, bis es Hunderte von Spielen gibt, die auf der GPU spezialisiertes Matrix-Computing verwenden.
Ein vielversprechender Start
Die Situation ist also so: Tensorkerne, hervorragende Hardwareeinheiten, die jedoch nur in einigen Consumer-Karten zu finden sind. Wird sich in Zukunft etwas ändern? Da Nvidia die Leistung jedes Tensorkerns in seiner Ampere-Architektur bereits dramatisch verbessert hat, besteht eine hohe Wahrscheinlichkeit, dass sie in Modellen der unteren und mittleren Preisklasse installiert werden.
Obwohl solche Kerne noch nicht in den GPUs von AMD und Intel enthalten sind, werden wir sie möglicherweise in Zukunft sehen. AMD verfügt über ein System zum Schärfen oder Verbessern von Details in fertigen Rahmen auf Kosten einer geringfügigen Leistungsminderung. Daher kann das Unternehmen an diesem System festhalten, insbesondere da es nicht von Entwicklern integriert werden muss und ausreicht, um es in den Treibern zu aktivieren.
Es besteht auch die Auffassung, dass der Platz auf den Kristallen in Grafikchips besser für zusätzliche Shader-Kerne verwendet werden sollte - genau das hat Nvidia bei der Erstellung von Budgetversionen seiner Turing-Chips getan. Bei Produkten wie der GeForce GTX 1650 hat das Unternehmen Tensorkerne vollständig über Bord geworfen und durch zusätzliche FP16-Shader ersetzt.
Wenn Sie jedoch eine ultraschnelle GEMM-Verarbeitung bereitstellen und diese voll ausnutzen möchten, haben Sie zwei Möglichkeiten: Kaufen Sie eine Reihe großer Multicore-CPUs oder nur eine GPU mit Tensorkernen.
Siehe auch: