Einführung
Dieser Artikel beschreibt einen stabilen nicht rekursiven adaptiven Zusammenführungssortieralgorithmus namens quadsort.
Vierfacher Austausch
Quadsort basiert auf einem Vierfachaustausch. Traditionell basieren die meisten Sortieralgorithmen auf einem binären Austausch, bei dem zwei Variablen unter Verwendung einer dritten temporären Variablen sortiert werden. Es sieht normalerweise so aus:
if (val[0] > val[1])
{
tmp[0] = val[0];
val[0] = val[1];
val[1] = tmp[0];
}Bei einem vierfachen Austausch erfolgt die Sortierung unter Verwendung von vier Substitutionsvariablen (Swap). Im ersten Schritt werden die vier Variablen teilweise in vier Swap-Variablen sortiert, im zweiten Schritt werden sie vollständig in die vier ursprünglichen Variablen zurücksortiert.
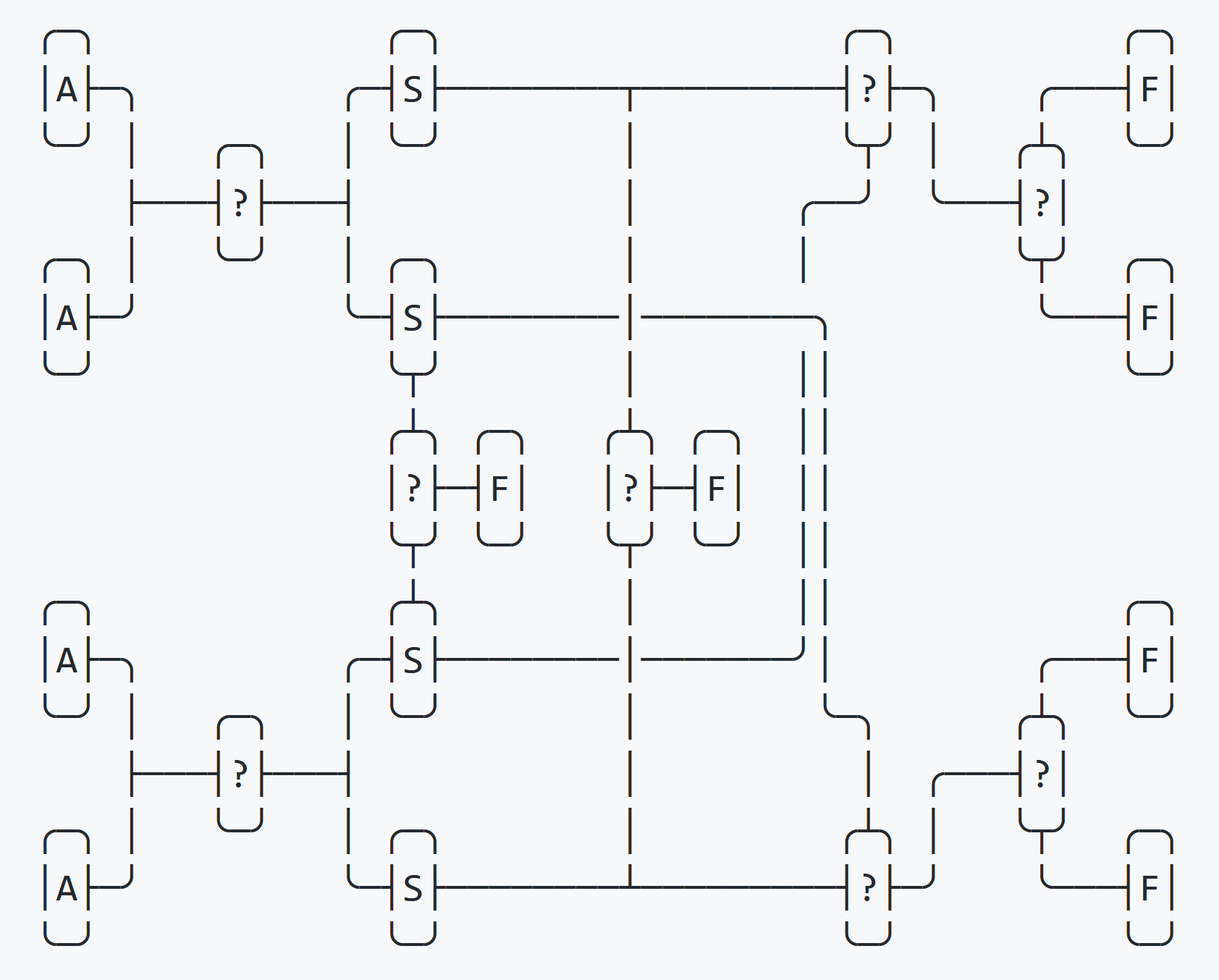
Dieser Vorgang ist im obigen Diagramm dargestellt.
Nach der ersten Sortierrunde bestimmt eine if-Prüfung, ob die vier Swap-Variablen der Reihe nach sortiert sind. In diesem Fall endet der Austausch sofort. Anschließend wird geprüft, ob die Swap-Variablen in umgekehrter Reihenfolge sortiert sind. Wenn ja, endet die Sortierung sofort. Wenn beide Tests fehlschlagen, ist der endgültige Ort bekannt und es verbleiben zwei Tests, um die endgültige Reihenfolge zu bestimmen.
Dies eliminiert einen redundanten Vergleich für Sequenzen, die in Ordnung sind. Gleichzeitig wird ein zusätzlicher Vergleich für zufällige Sequenzen erstellt. In der realen Welt vergleichen wir jedoch selten wirklich zufällige Daten. Wenn die Daten also eher geordnet als unordentlich sind, ist diese Verschiebung der Wahrscheinlichkeit von Vorteil.
Es gibt auch eine allgemeine Leistungsverbesserung durch Eliminieren des verschwenderischen Austauschs. In der Sprache C sieht ein einfacher Vierfach-Swap folgendermaßen aus:
if (val[0] > val[1])
{
tmp[0] = val[1];
tmp[1] = val[0];
}
else
{
tmp[0] = val[0];
tmp[1] = val[1];
}
if (val[2] > val[3])
{
tmp[2] = val[3];
tmp[3] = val[2];
}
else
{
tmp[2] = val[2];
tmp[3] = val[3];
}
if (tmp[1] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[1];
val[2] = tmp[2];
val[3] = tmp[3];
}
else if (tmp[0] > tmp[3])
{
val[0] = tmp[2];
val[1] = tmp[3];
val[2] = tmp[0];
val[3] = tmp[1];
}
else
{
if (tmp[0] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[2];
}
else
{
val[0] = tmp[2];
val[1] = tmp[0];
}
if (tmp[1] <= tmp[3])
{
val[2] = tmp[1];
val[3] = tmp[3];
}
else
{
val[2] = tmp[3];
val[3] = tmp[1];
}
}Falls das Array nicht perfekt in vier Teile unterteilt werden kann, wird das Ende von 1-3 Elementen unter Verwendung des herkömmlichen binären Austauschs sortiert.
Der oben beschriebene Vierfachaustausch ist in Quadsort implementiert.
Vierfache Zusammenführung
In der ersten Stufe sortiert der Vierfachaustausch das Array wie oben beschrieben in Blöcke mit vier Elementen vor.
Die zweite Stufe verwendet einen ähnlichen Ansatz zum Erkennen geordneter und umgekehrter Ordnungen, aber in Blöcken mit 4, 16, 64 oder mehr Elementen wird diese Stufe wie eine herkömmliche Zusammenführungssortierung behandelt.
Dies kann wie folgt dargestellt werden:
main memory: AAAA BBBB CCCC DDDD
swap memory: ABABABAB CDCDCDCD
main memory: ABCDABCDABCDABCDIn der ersten Zeile werden mit einem vierfachen Tausch vier Blöcke mit jeweils vier sortierten Elementen erstellt. In der zweiten Zeile wird eine Quad-Zusammenführung verwendet, um zwei Blöcke mit jeweils acht sortierten Elementen im Swap-Speicher zu kombinieren. In der letzten Zeile werden die Blöcke wieder in den Hauptspeicher zusammengeführt, und es bleibt ein Block mit 16 sortierten Elementen übrig. Unten ist die Visualisierung.

Diese Operationen erfordern tatsächlich eine Verdoppelung des Auslagerungsspeichers. Dazu später mehr.
Überspringen
Ein weiterer Unterschied besteht darin, dass es aufgrund der erhöhten Kosten für Zusammenführungsvorgänge vorteilhaft ist, zu überprüfen, ob vier Blöcke in Vorwärts- oder Rückwärtsreihenfolge sind.
Wenn die vier Blöcke in Ordnung sind, wird der Zusammenführungsvorgang übersprungen, da er bedeutungslos ist. Dies erfordert jedoch eine zusätzliche if-Prüfung, und für zufällig sortierte Daten wird diese if-Prüfung mit zunehmender Blockgröße zunehmend unwahrscheinlicher. Glücklicherweise vervierfacht sich die Häufigkeit dieser Prüfung in jedem Zyklus, während sich der potenzielle Nutzen in jedem Zyklus vervierfacht.
Falls die vier Blöcke in umgekehrter Reihenfolge sind, wird ein stabiler In-Place-Swap durchgeführt.
Für den Fall, dass nur zwei der vier Blöcke geordnet oder in umgekehrter Reihenfolge sind, sind Vergleiche in der Zusammenführung selbst nicht erforderlich und werden anschließend weggelassen. Die Daten müssen noch in den Auslagerungsspeicher kopiert werden, dies ist jedoch ein weniger rechnerischer Vorgang.
Dies ermöglicht es dem Quadsort-Algorithmus, Sequenzen in Vorwärts- und Rückwärtsreihenfolge unter Verwendung von
nVergleichen anstelle von n * log nVergleichen zu sortieren .
Grenzkontrollen
Ein weiteres Problem bei der herkömmlichen Zusammenführungssortierung besteht darin, dass Ressourcen für unnötige Grenzprüfungen verschwendet werden. Es sieht aus wie das:
while (a <= a_max && b <= b_max)
if (a <= b)
[insert a++]
else
[insert b++]Zur Optimierung vergleicht unser Algorithmus das letzte Element der Sequenz A mit dem letzten Element der Sequenz B. Wenn das letzte Element der Sequenz A kleiner als das letzte Element der Sequenz B ist, wissen wir, dass der Test
b < b_maximmer falsch ist, da die Sequenz A das erste ist, das vollständig zusammengeführt wird.
Wenn das letzte Element der Sequenz A größer als das letzte Element der Sequenz B ist, wissen wir ebenfalls, dass der Test
a < a_maximmer falsch ist. Es sieht aus wie das:
if (val[a_max] <= val[b_max])
while (a <= a_max)
{
while (a > b)
[insert b++]
[insert a++]
}
else
while (b <= b_max)
{
while (a <= b)
[insert a++]
[insert b++]
}Fusionsschwanz
Wenn Sie ein Array mit 65 Elementen sortieren, erhalten Sie am Ende ein Array mit 64 Elementen und am Ende ein Array mit einem Element. Dies führt nicht zu einem zusätzlichen Austauschvorgang, wenn die gesamte Sequenz in Ordnung ist. In jedem Fall muss das Programm dazu die optimale Arraygröße wählen (64, 256 oder 1024).
Ein weiteres Problem besteht darin, dass die suboptimale Größe des Arrays zu unnötigen Austauschoperationen führt. Um diese beiden Probleme zu umgehen, wird die vierfache Zusammenführungsprozedur abgebrochen, wenn die Blockgröße 1/8 der Arraygröße erreicht und der Rest des Arrays mithilfe der Endzusammenführung sortiert wird. Der Hauptvorteil der Schwanzfusion besteht darin, dass der Quadsort-Swap auf n / 2 reduziert werden kann, ohne die Leistung wesentlich zu beeinträchtigen.
Big O.
| Name | Beste | Mitte | Am schlimmsten | Stabil | Erinnerung |
|---|---|---|---|---|---|
| Quadsort | n | n log n | n log n | Ja | n |
Wenn die Daten bereits sortiert oder in umgekehrter Reihenfolge sortiert sind, führt quadsort n Vergleiche durch.
Zwischenspeicher
Da quadsort n / 2 Swaps verwendet, ist die Cache-Nutzung nicht so ideal wie die direkte Sortierung. Das Sortieren zufälliger Daten führt jedoch zu einem nicht optimalen Austausch. Basierend auf meinen Benchmarks ist quadsort immer schneller als die direkte Sortierung, solange das Array den L1-Cache nicht überläuft, der auf modernen Prozessoren bis zu 64 KB betragen kann.
Wolfsort
Wolfsort ist ein hybrider Radixsort / Quadsort-Sortieralgorithmus, der die Leistung beim Arbeiten mit zufälligen Daten verbessert. Dies ist im Grunde ein Proof of Concept, der nur mit vorzeichenlosen 32- und 64-Bit-Ganzzahlen funktioniert.
Visualisierung
Die folgende Visualisierung führt vier Tests aus. Der erste Test basiert auf einer zufälligen Verteilung, der zweite auf einer aufsteigenden Verteilung, der dritte auf einer absteigenden Verteilung und der vierte auf einer aufsteigenden Verteilung mit einem zufälligen Schwanz.
Die obere Hälfte zeigt Swap und die untere Hälfte zeigt den Hauptspeicher. Die Farben variieren beim Überspringen, Austauschen, Zusammenführen und Kopieren.
Benchmark: quadsort, std :: stabile_sort, timsort, pdqsort und wolfsort
Der folgende Benchmark wurde mit der WSL gcc-Konfigurationsversion 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1) ausgeführt. Der Quellcode wird vom Team zusammengestellt
g++ -O3 quadsort.cpp. Jeder Test wird hundertmal ausgeführt und nur der beste Lauf wird gemeldet.
Die Abszisse ist die Ausführungszeit.
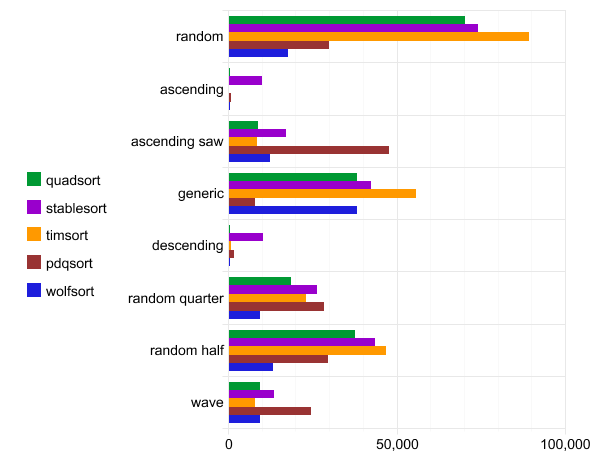
Quadsort-Datenblatt, std :: stabile_sort, timsort, pdqsort und wolfsort
| Name | Elemente | Eine Art | Beste | Mitte | Vergleiche | Bestellung |
|---|---|---|---|---|---|---|
| Quadsort | 1.000.000 | i32 | 0,070469 | 0,070635 | zufällige Reihenfolge | |
| stablesort | 1000000 | i32 | 0.073865 | 0.074078 | ||
| timsort | 1000000 | i32 | 0.089192 | 0.089301 | ||
| pdqsort | 1000000 | i32 | 0.029911 | 0.029948 | ||
| wolfsort | 1000000 | i32 | 0.017359 | 0.017744 | ||
| quadsort | 1000000 | i32 | 0.000485 | 0.000511 | ||
| stablesort | 1000000 | i32 | 0.010188 | 0.010261 | ||
| timsort | 1000000 | i32 | 0.000331 | 0.000342 | ||
| pdqsort | 1000000 | i32 | 0.000863 | 0.000875 | ||
| wolfsort | 1000000 | i32 | 0.000539 | 0.000579 | ||
| quadsort | 1000000 | i32 | 0.008901 | 0.008934 | () | |
| stablesort | 1000000 | i32 | 0.017093 | 0.017275 | () | |
| timsort | 1000000 | i32 | 0.008615 | 0.008674 | () | |
| pdqsort | 1000000 | i32 | 0.047785 | 0.047921 | () | |
| wolfsort | 1000000 | i32 | 0.012490 | 0.012554 | () | |
| quadsort | 1000000 | i32 | 0.038260 | 0.038343 | ||
| stablesort | 1000000 | i32 | 0.042292 | 0.042388 | ||
| timsort | 1000000 | i32 | 0.055855 | 0.055967 | ||
| pdqsort | 1000000 | i32 | 0.008093 | 0.008168 | ||
| wolfsort | 1000000 | i32 | 0.038320 | 0.038417 | ||
| quadsort | 1000000 | i32 | 0.000559 | 0.000576 | ||
| stablesort | 1000000 | i32 | 0.010343 | 0.010438 | ||
| timsort | 1000000 | i32 | 0.000891 | 0.000900 | ||
| pdqsort | 1000000 | i32 | 0.001882 | 0.001897 | ||
| wolfsort | 1000000 | i32 | 0.000604 | 0.000625 | ||
| quadsort | 1000000 | i32 | 0.006174 | 0.006245 | ||
| stablesort | 1000000 | i32 | 0.014679 | 0.014767 | ||
| timsort | 1000000 | i32 | 0.006419 | 0.006468 | ||
| pdqsort | 1000000 | i32 | 0.016603 | 0.016629 | ||
| wolfsort | 1000000 | i32 | 0.006264 | 0.006329 | ||
| quadsort | 1000000 | i32 | 0.018675 | 0.018729 | ||
| stablesort | 1000000 | i32 | 0.026384 | 0.026508 | ||
| timsort | 1000000 | i32 | 0.023226 | 0.023395 | ||
| pdqsort | 1000000 | i32 | 0.028599 | 0.028674 | ||
| wolfsort | 1000000 | i32 | 0.009517 | 0.009631 | ||
| quadsort | 1000000 | i32 | 0.037593 | 0.037679 | ||
| stablesort | 1000000 | i32 | 0.043755 | 0.043899 | ||
| timsort | 1000000 | i32 | 0.047008 | 0.047112 | ||
| pdqsort | 1000000 | i32 | 0.029800 | 0.029847 | ||
| wolfsort | 1000000 | i32 | 0.013238 | 0.013355 | ||
| quadsort | 1000000 | i32 | 0.009605 | 0.009673 | ||
| stablesort | 1000000 | i32 | 0.013667 | 0.013785 | ||
| timsort | 1000000 | i32 | 0.007994 | 0.008138 | ||
| pdqsort | 1000000 | i32 | 0.024683 | 0.024727 | ||
| wolfsort | 1000000 | i32 | 0.009642 | 0.009709 |
Es ist zu beachten, dass pdqsort keine stabile Sortierung ist und daher schneller mit Daten in normaler Reihenfolge (allgemeine Reihenfolge) arbeitet.
Der folgende Benchmark wurde auf WSL gcc Version 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1) ausgeführt. Der Quellcode wird vom Team zusammengestellt
g++ -O3 quadsort.cpp. Jeder Test wird hundertmal ausgeführt und nur der beste Lauf wird gemeldet. Es misst die Leistung auf Arrays mit 675 bis 100.000 Elementen.
Die x-Achse des folgenden Diagramms ist die Kardinalität, die y-Achse ist die Ausführungszeit.

Quadsort-Datenblatt, std :: stabile_sort, timsort, pdqsort und wolfsort
| quadsort | 100000 | i32 | 0.005800 | 0.005835 | ||
| stablesort | 100000 | i32 | 0.006092 | 0.006122 | ||
| timsort | 100000 | i32 | 0.007605 | 0.007656 | ||
| pdqsort | 100000 | i32 | 0.002648 | 0.002670 | ||
| wolfsort | 100000 | i32 | 0.001148 | 0.001168 | ||
| quadsort | 10000 | i32 | 0.004568 | 0.004593 | ||
| stablesort | 10000 | i32 | 0.004813 | 0.004923 | ||
| timsort | 10000 | i32 | 0.006326 | 0.006376 | ||
| pdqsort | 10000 | i32 | 0.002345 | 0.002373 | ||
| wolfsort | 10000 | i32 | 0.001256 | 0.001274 | ||
| quadsort | 5000 | i32 | 0.004076 | 0.004086 | ||
| stablesort | 5000 | i32 | 0.004394 | 0.004420 | ||
| timsort | 5000 | i32 | 0.005901 | 0.005938 | ||
| pdqsort | 5000 | i32 | 0.002093 | 0.002107 | ||
| wolfsort | 5000 | i32 | 0.000968 | 0.001086 | ||
| quadsort | 2500 | i32 | 0.003196 | 0.003303 | ||
| stablesort | 2500 | i32 | 0.003801 | 0.003942 | ||
| timsort | 2500 | i32 | 0.005296 | 0.005322 | ||
| pdqsort | 2500 | i32 | 0.001606 | 0.001661 | ||
| wolfsort | 2500 | i32 | 0.000509 | 0.000520 | ||
| quadsort | 1250 | i32 | 0.001767 | 0.001823 | ||
| stablesort | 1250 | i32 | 0.002812 | 0.002887 | ||
| timsort | 1250 | i32 | 0.003789 | 0.003865 | ||
| pdqsort | 1250 | i32 | 0.001036 | 0.001325 | ||
| wolfsort | 1250 | i32 | 0.000534 | 0.000655 | ||
| quadsort | 675 | i32 | 0.000368 | 0.000592 | ||
| stablesort | 675 | i32 | 0.000974 | 0.001160 | ||
| timsort | 675 | i32 | 0.000896 | 0.000948 | ||
| pdqsort | 675 | i32 | 0.000489 | 0.000531 | ||
| wolfsort | 675 | i32 | 0.000283 | 0.000308 |
Benchmark: Quadsort und Qsort (Mergesort)
Der nächste Benchmark wurde auf WSL gcc Version 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1) ausgeführt. Der Quellcode wird vom Team zusammengestellt
g++ -O3 quadsort.cpp. Jeder Test wird hundertmal ausgeführt und nur der beste Lauf wird gemeldet.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)MO gibt die Anzahl der Vergleiche an, die mit 1 Million Artikeln durchgeführt wurden.
Der obige Benchmark vergleicht quadsort mit glibc qsort () über dieselbe Allzweckschnittstelle und ohne bekannte unfaire Vorteile wie Inlining.
random order: 635, 202, 47, 229, etc
ascending order: 1, 2, 3, 4, etc
uniform order: 1, 1, 1, 1, etc
descending order: 999, 998, 997, 996, etc
wave order: 100, 1, 102, 2, 103, 3, etc
stable/unstable: 100, 1, 102, 1, 103, 1, etc
random range: time to sort 1000 arrays ranging from size 0 to 999 containing random dataBenchmark: Quadsort und Qsort (Quicksort)
Dieser spezielle Test wird mit der qsort () - Implementierung von Cygwin durchgeführt, die Quicksort unter der Haube verwendet. Der Quellcode wird vom Team zusammengestellt
gcc -O3 quadsort.c. Jeder Test wird hundertmal ausgeführt, es wird nur der beste Lauf gemeldet.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)In diesem Benchmark wird deutlich, warum Quicksort häufig der herkömmlichen Zusammenführung vorzuziehen ist. Es werden weniger Vergleiche für Daten in aufsteigender Reihenfolge, gleichmäßig verteilt und für Daten in absteigender Reihenfolge durchgeführt. In den meisten Tests schnitt es jedoch schlechter ab als Quadsort. Quicksort weist auch eine extrem langsame Sortiergeschwindigkeit für wellengeordnete Daten auf. Der Zufallsdatentest zeigt, dass Quadsort beim Sortieren kleiner Arrays mehr als doppelt so schnell ist.
Quicksort ist in allgemeinen und stabilen Tests schneller, aber nur, weil es sich um einen instabilen Algorithmus handelt.
Siehe auch: