Erinnern wir uns an den Plan, nach dem wir uns bewegen:
1 Teil . Wir haben uns für die technische Aufgabe und die Architektur der Lösung entschieden und eine Anwendung in Golang geschrieben.
Teil 2 (Sie sind jetzt hier). Wir geben unsere Anwendung für die Produktion frei, machen sie skalierbar und testen die Last.
Teil 3. Versuchen wir herauszufinden, warum wir Nachrichten in einem Puffer und nicht in Dateien speichern müssen, und vergleichen wir auch den Warteschlangendienst kafka, rabbitmq und yandex untereinander.
Teil 4. Wir werden den Clickhouse-Cluster bereitstellen, Streaming schreiben, um Daten aus dem dortigen Puffer zu übertragen, und die Visualisierung in Daten einrichten.
Teil 5.Lassen Sie uns die gesamte Infrastruktur in den richtigen Zustand bringen - konfigurieren Sie ci / cd mit gitlab ci, verbinden Sie Überwachung und Serviceerkennung mit consul und prometheus.

Kommen wir zu unseren Aufgaben.
Wir strömen in die Produktion
In Teil 1 haben wir die Anwendung zusammengestellt, getestet und das Image zur Bereitstellung in die Registrierung für private Container hochgeladen.
Im Allgemeinen sollten die nächsten Schritte fast offensichtlich sein: Wir erstellen virtuelle Maschinen, richten einen Load Balancer ein und schreiben einen DNS-Namen mit Proxy für Cloudflare. Ich befürchte jedoch, dass diese Option nicht genau unseren Bestimmungen entspricht. Wir möchten in der Lage sein, unseren Service im Falle einer Erhöhung der Last zu skalieren und defekte Knoten daraus zu entfernen, die keine Anforderungen bedienen können.
Für die Skalierung verwenden wir die in der Compute Cloud verfügbaren Instanzgruppen. Mit ihnen können Sie virtuelle Maschinen aus einer Vorlage erstellen, ihre Verfügbarkeit mithilfe von Integritätsprüfungen überwachen und bei einer Erhöhung der Last automatisch die Anzahl der Knoten erhöhen.Weitere Details hier .
Es gibt nur eine Frage: Welche Vorlage soll für die virtuelle Maschine verwendet werden? Natürlich können Sie Linux installieren, konfigurieren, ein Image erstellen und es in den Image-Speicher in Yandex.Cloud hochladen. Aber für uns ist es eine lange und schwierige Reise. Bei der Überprüfung der verschiedenen beim Erstellen einer virtuellen Maschine verfügbaren Images stießen wir auf eine interessante Instanz - ein für Container optimiertes Image ( https://cloud.yandex.ru/docs/cos/concepts/ ). Sie können einen einzelnen Docker-Container im Netzwerkmodus-Host ausführen. Das heißt, beim Erstellen einer virtuellen Maschine wird ungefähr die folgende Spezifikation für das containeroptimierte Image angegeben:
spec:
containers:
- name: api
image: vozerov/events-api:v1
command:
- /app/app
args:
- -kafka=kafka.ru-central1.internal:9092
securityContext:
privileged: false
tty: false
stdin: false
restartPolicy: AlwaysNach dem Start der virtuellen Maschine wird dieser Container heruntergeladen und lokal gestartet.
Das Schema ist sehr interessant:
- Wir erstellen eine Instanzgruppe mit automatischer Skalierung, wenn die CPU-Auslastung 60% überschreitet.
- Als Vorlage geben wir eine virtuelle Maschine mit einem containeroptimierten Image und Parametern für die Ausführung unseres Docker-Containers an.
- Wir erstellen einen Load Balancer, der unsere Instanzgruppe betrachtet und beim Hinzufügen oder Entfernen von virtuellen Maschinen automatisch aktualisiert.
- Die Anwendung wird sowohl als Instanzgruppe als auch vom Balancer selbst überwacht, wodurch unzugängliche virtuelle Maschinen aus dem Balancing ausgeschlossen werden.
Klingt wie ein Plan!
Versuchen wir, eine Instanzgruppe mit terraform zu erstellen. Die gesamte Beschreibung liegt in instance-group.tf, ich werde die wichtigsten Punkte kommentieren:
- Die Dienstkonto-ID wird zum Erstellen und Löschen von virtuellen Maschinen verwendet. Übrigens müssen wir es schaffen.
service_account_id = yandex_iam_service_account.instances.id - spec.yml, , . registry , - — docker hub. , —
metadata = { docker-container-declaration = file("spec.yml") ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}" } - service account id, container optimized image, container registry . registry , :
service_account_id = yandex_iam_service_account.docker.id - Scale policy. :
autoscale { initialsize = 3 measurementduration = 60 cpuutilizationtarget = 60 minzonesize = 1 maxsize = 6 warmupduration = 60 stabilizationduration = 180 }
. — fixed_scale , auth_scale.
:
initial size — ;
measurement_duration — ;
cpu_utilization_target — , ;
min_zone_size — — , ;
max_size — ;
warmup_duration — , , ;
stabilization_duration — — , .
. 3 (initial_size), (min_zone_size). cpu (measurement_duration). 60% (cpu_utilization_target), , (max_size). 60 (warmup_duration), cpu. 120 (stabilization_duration), 60% (cpu_utilization_target).
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#auto-scale-policy - Allocation policy. , , — .
allocationpolicy { zones = ["ru-central1-a", "ru-central1-b", "ru-central1-c"] } - :
deploy_policy { maxunavailable = 1 maxcreating = 1 maxexpansion = 1 maxdeleting = 1 }
max_creating — ;
max_deleting — ;
max_expansion — ;
max_unavailable — RUNNING, ;
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#deploy-policy - :
load_balancer { target_group_name = "events-api-tg" }
Beim Erstellen einer Instanzgruppe können Sie auch eine Zielgruppe für den Load Balancer erstellen. Es zielt auf die zugeordneten virtuellen Maschinen ab. Wenn sie gelöscht werden, werden die Knoten aus dem Ausgleich entfernt und beim Erstellen nach dem Bestehen der Statusprüfungen zum Ausgleich hinzugefügt.
Es scheint, dass alles grundlegend ist - erstellen wir ein Dienstkonto für die Instanzgruppe und tatsächlich für die Gruppe selbst.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_iam_service_account.instances -target yandex_resourcemanager_folder_iam_binding.editor
... skipped ...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_compute_instance_group.events_api_ig
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Die Gruppe wurde erstellt - Sie können Folgendes anzeigen und überprüfen:
vozerov@mba:~/events/terraform (master *) $ yc compute instance-group list
+----------------------+---------------+------+
| ID | NAME | SIZE |
+----------------------+---------------+------+
| cl1s2tu8siei464pv1pn | events-api-ig | 3 |
+----------------------+---------------+------+
vozerov@mba:~/events/terraform (master *) $ yc compute instance list
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ef3huodj8g4gc6afl0jg | cl1s2tu8siei464pv1pn-ocih | ru-central1-c | RUNNING | 130.193.44.106 | 172.16.3.3 |
| epdli4s24on2ceel46sr | cl1s2tu8siei464pv1pn-ipym | ru-central1-b | RUNNING | 84.201.164.196 | 172.16.2.31 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmh4la5dj0m82ihoskd | cl1s2tu8siei464pv1pn-ahuj | ru-central1-a | RUNNING | 130.193.37.94 | 172.16.1.37 |
| fhmr401mknb8omfnlrc0 | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.14 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
vozerov@mba:~/events/terraform (master *) $Drei Knoten mit krummen Namen sind unsere Gruppe. Wir prüfen, ob Anwendungen für sie verfügbar sind:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.44.106:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:04 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://84.201.164.196:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:09 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.37.94:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:15 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $Übrigens können Sie mit der Ubuntu-Anmeldung zu virtuellen Maschinen gehen und die Containerprotokolle und deren Start anzeigen.
Für den Balancer wurde auch eine Zielgruppe erstellt, an die Anforderungen gesendet werden können:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer target-group list
+----------------------+---------------+---------------------+-------------+--------------+
| ID | NAME | CREATED | REGION ID | TARGET COUNT |
+----------------------+---------------+---------------------+-------------+--------------+
| b7rhh6d4assoqrvqfr9g | events-api-tg | 2020-04-13 16:23:53 | ru-central1 | 3 |
+----------------------+---------------+---------------------+-------------+--------------+
vozerov@mba:~/events/terraform (master *) $Lassen Sie uns bereits einen Balancer erstellen und versuchen, Datenverkehr an ihn zu senden! Dieser Prozess wird in load-balancer.tf beschrieben, wichtige Punkte:
- Wir geben an, welchen externen Port der Balancer abhört und an welchen Port eine Anforderung an virtuelle Maschinen gesendet werden soll. Wir geben den Typ der externen Adresse an - ip v4. Im Moment arbeitet der Load Balancer auf Transportebene, sodass nur TCP / UDP-Verbindungen ausgeglichen werden können. Sie müssen also ssl entweder auf Ihre virtuellen Maschinen oder auf einen externen Dienst schrauben, der https verarbeiten kann, z. B. Cloudflare.
listener { name = "events-api-listener" port = 80 target_port = 8080 external_address_spec { ipversion = "ipv4" } } healthcheck { name = "http" http_options { port = 8080 path = "/status" } }
Gesundheitschecks. Hier geben wir die Parameter für die Überprüfung unserer Knoten an - wir überprüfen anhand von http url / status an Port 8080. Wenn die Überprüfung fehlschlägt, wird der Computer aus dem Gleichgewicht gebracht.
Weitere Informationen zum Load Balancer - cloud.yandex.ru/docs/load-balancer/concepts . Interessanterweise können Sie den DDOS-Schutzdienst auf dem Balancer verbinden. Dann kommt bereits bereinigter Datenverkehr zu Ihren Servern.
Wir erstellen:
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_lb_network_load_balancer.events_api_lb
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Wir nehmen die IP des erstellten Balancers heraus und testen die Arbeit:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer network-load-balancer get events-api-lb
id:
folder_id:
created_at: "2020-04-13T16:34:28Z"
name: events-api-lb
region_id: ru-central1
status: ACTIVE
type: EXTERNAL
listeners:
- name: events-api-listener
address: 130.193.37.103
port: "80"
protocol: TCP
target_port: "8080"
attached_target_groups:
- target_group_id:
health_checks:
- name: http
interval: 2s
timeout: 1s
unhealthy_threshold: "2"
healthy_threshold: "2"
http_options:
port: "8080"
path: /statusJetzt können wir Nachrichten darin hinterlassen:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:57 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":1}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:58 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":2}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:43:00 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":3}
vozerov@mba:~/events/terraform (master *) $Großartig, alles funktioniert. Der letzte Schliff bleibt, damit wir über https verfügbar sind - wir werden Cloudflare mit Proxy verbinden. Wenn Sie auf Cloudflare verzichten möchten, können Sie diesen Schritt überspringen.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target cloudflare_record.events
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Testen über HTTPS:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' https://events.kis.im/post
HTTP/2 200
date: Mon, 13 Apr 2020 16:45:01 GMT
content-type: application/json
content-length: 41
set-cookie: __cfduid=d7583eb5f791cd3c1bdd7ce2940c8a7981586796301; expires=Wed, 13-May-20 16:45:01 GMT; path=/; domain=.kis.im; HttpOnly; SameSite=Lax
cf-cache-status: DYNAMIC
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5836a7b1bb037b2b-DME
{"status":"ok","partition":0,"Offset":5}
vozerov@mba:~/events/terraform (master *) $Alles funktioniert endlich.
Last testen
Wir haben den vielleicht interessantesten Schritt - einen Lasttest unseres Dienstes durchzuführen und einige Zahlen zu erhalten - zum Beispiel das 95. Perzentil der Verarbeitungszeit einer Anfrage. Es wäre auch schön, die automatische Skalierung unserer Knotengruppe zu testen.
Bevor Sie mit dem Testen beginnen, sollten Sie eine einfache Sache tun: Fügen Sie prometheus unsere Anwendungsknoten hinzu, um die Anzahl der Anforderungen und die Verarbeitungszeit einer Anforderung zu verfolgen. Da wir noch keine Serviceerkennung hinzugefügt haben (wir werden dies in Artikel 5 dieser Serie tun), schreiben wir einfach static_configs auf unseren Überwachungsserver. Sie können die IP-Adresse auf standardmäßige Weise in der Liste der yc-Recheninstanzen ermitteln und anschließend die folgenden Einstellungen zu /etc/prometheus/prometheus.yml hinzufügen:
- job_name: api
metrics_path: /metrics
static_configs:
- targets:
- 172.16.3.3:8080
- 172.16.2.31:8080
- 172.16.1.37:8080Die IP-Adressen unserer Maschinen können auch der Liste der yc-Recheninstanzen entnommen werden. Starten Sie prometheus über systemctl neu. Starten Sie prometheus neu und überprüfen Sie, ob die Knoten erfolgreich abgefragt werden, indem Sie auf die an Port 9090 (84.201.159.71:9090) verfügbare Weboberfläche gehen.
Fügen wir grafana ein Dashboard aus dem grafana-Ordner hinzu. Wir fahren nach Grafana auf Port 3000 (84.201.159.71:3000) und mit einem Benutzernamen / Passwort - admin / Passwort. Fügen Sie als Nächstes einen lokalen Prometheus hinzu und importieren Sie das Dashboard. Zu diesem Zeitpunkt ist die Vorbereitung tatsächlich abgeschlossen - Sie können Anfragen an unsere Installation senden.
Zum Testen verwenden wir den yandex-Tank ( https://yandex.ru/dev/tank/ ) mit einem Plugin für overload.yandex.netDadurch können wir die vom Tank empfangenen Daten visualisieren. Alles, was Sie zum Arbeiten benötigen, befindet sich im Ladeordner des ursprünglichen Git-Repositorys.
Ein wenig darüber, was da ist:
- token.txt - eine Datei mit einem API-Schlüssel von overload.yandex.net - Sie können sie erhalten, indem Sie sich beim Dienst registrieren.
- load.yml - eine Konfigurationsdatei für den Tank, es gibt eine Domäne zum Testen - events.kis.im, rps load type und die Anzahl der Anforderungen 15.000 pro Sekunde für 3 Minuten.
- data - eine spezielle Datei zum Generieren einer Konfiguration im Format ammo.txt. Darin schreiben wir die Art der Anfrage, die URL, die Gruppe für die Anzeige von Statistiken und die tatsächlichen Daten, die gesendet werden müssen.
- makeammo.py - Skript zum Generieren der Datei ammo.txt aus einer Datendatei. Weitere Informationen zum Skript - yandextank.readthedocs.io/en/latest/ammo_generators.html
- ammo.txt - Die resultierende Munitionsdatei, die zum Senden von Anforderungen verwendet wird.
Zum Testen nahm ich eine virtuelle Maschine außerhalb von Yandex.Cloud (damit alles fair war) und erstellte einen DNS-Eintrag für load.kis.im. Ich habe dort Docker gerollt, da wir den Panzer mit dem Bild https://hub.docker.com/r/direvius/yandex-tank/ starten werden .
Nun, fangen wir an. Kopieren Sie unseren Ordner auf den Server, fügen Sie ein Token hinzu und starten Sie den Tank:
vozerov@mba:~/events (master *) $ rsync -av load/ cloud-user@load.kis.im:load/
... skipped ...
sent 2195 bytes received 136 bytes 1554.00 bytes/sec
total size is 1810 speedup is 0.78
vozerov@mba:~/events (master *) $ ssh load.kis.im -l cloud-user
cloud-user@load:~$ cd load/
cloud-user@load:~/load$ echo "TOKEN" > token.txt
cloud-user@load:~/load$ sudo docker run -v $(pwd):/var/loadtest --net host --rm -it direvius/yandex-tank -c load.yaml ammo.txt
No handlers could be found for logger "netort.resource"
17:25:25 [INFO] New test id 2020-04-13_17-25-25.355490
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a266850> added
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a20aa50> added
17:25:25 [INFO] Created a folder for the test. /var/loadtest/logs/2020-04-13_17-25-25.355490
17:25:25 [INFO] Configuring plugins...
17:25:25 [INFO] Loading plugins...
17:25:25 [INFO] Testing connection to resolved address 104.27.164.45 and port 80
17:25:25 [INFO] Resolved events.kis.im into 104.27.164.45:80
17:25:25 [INFO] Configuring StepperWrapper...
17:25:25 [INFO] Making stpd-file: /var/loadtest/ammo.stpd
17:25:25 [INFO] Default ammo type ('phantom') used, use 'phantom.ammo_type' option to override it
... skipped ...Das war's, der Prozess läuft. In der Konsole sieht es ungefähr so aus:

Und wir warten auf den Abschluss des Prozesses und beobachten die Antwortzeit, die Anzahl der Anforderungen und natürlich die automatische Skalierung unserer Gruppe virtueller Maschinen. Sie können eine Gruppe virtueller Maschinen über die Weboberfläche überwachen. In den Einstellungen einer Gruppe virtueller Maschinen befindet sich die Registerkarte "Überwachung".
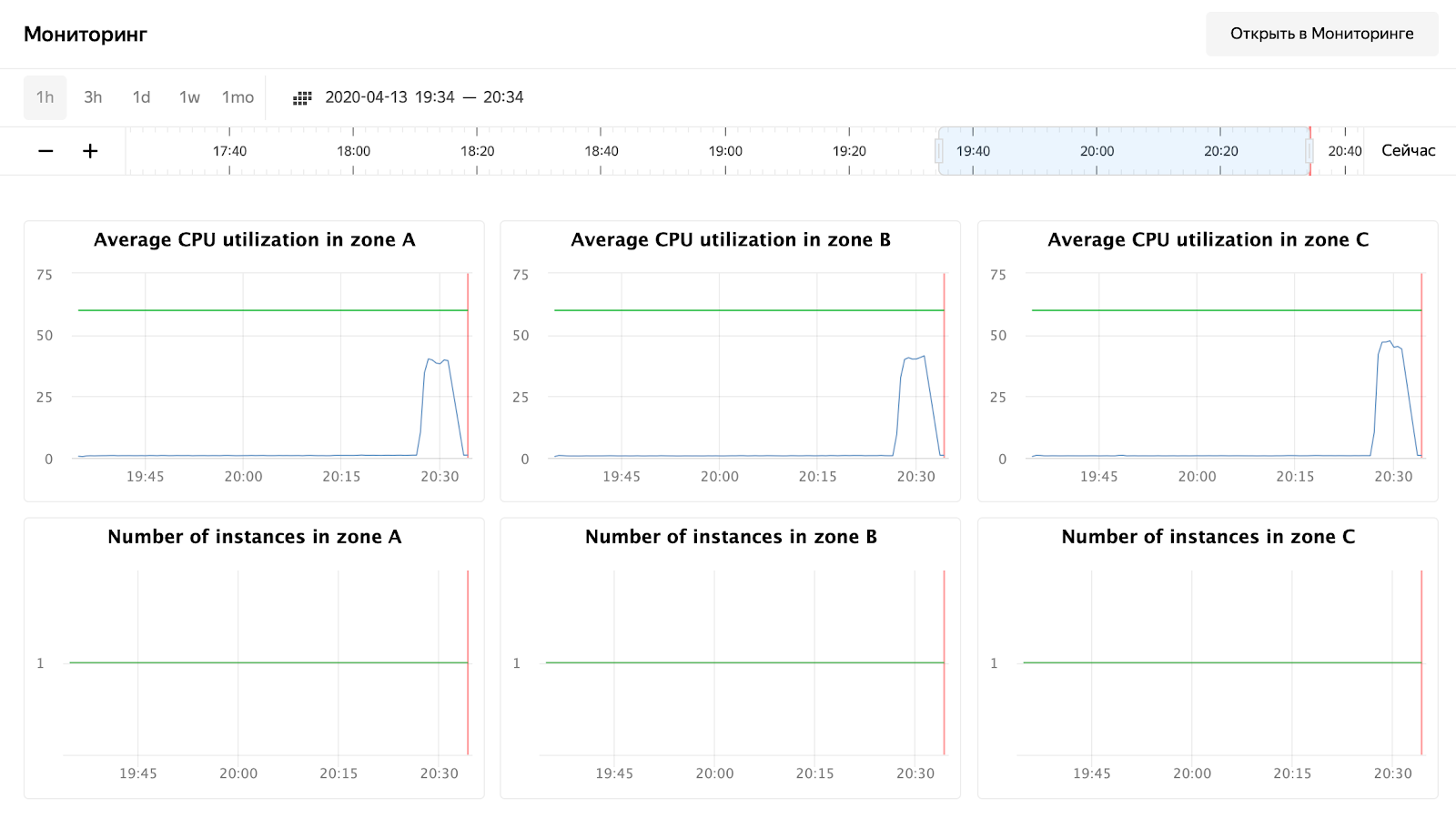
Wie Sie sehen können, haben unsere Knoten nicht einmal bis zu 50% der CPU geladen, sodass der Autoscaling-Test wiederholt werden muss. Schauen wir uns zunächst die Bearbeitungszeit der Anfrage in Grafana an:
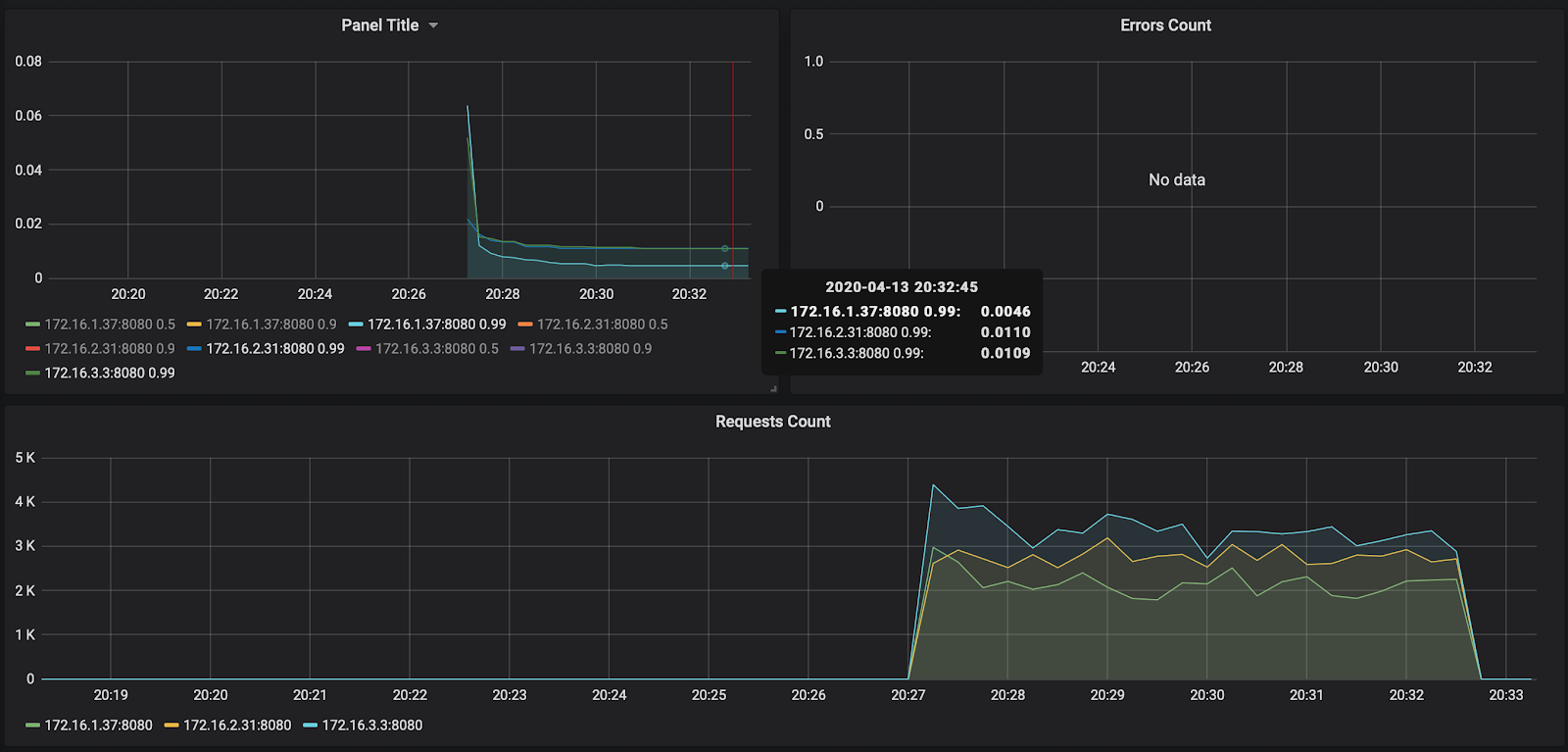
Die Anzahl der Anfragen - etwa 3000 pro Knoten - wurde nicht ein wenig auf 10.000 geladen. Die Antwortzeit gefällt - ca. 11 ms pro Anfrage. Der einzige, der auffällt - 172.16.1.37 - hat die Hälfte der Zeit, um eine Anfrage zu bearbeiten. Dies ist aber auch logisch - es befindet sich in derselben Verfügbarkeitszone wie kafka, in der Nachrichten gespeichert werden.
Der Bericht zum ersten Start ist übrigens unter folgendem Link verfügbar: https://overload.yandex.net/265967 .
Führen wir also einen unterhaltsameren Test durch - fügen Sie Instanzen hinzu: 2000, um 15.000 Anforderungen pro Sekunde zu erhalten und die Testzeit auf 10 Minuten zu erhöhen. Die resultierende Datei sieht folgendermaßen aus:
overload:
enabled: true
package: yandextank.plugins.DataUploader
token_file: "token.txt"
phantom:
address: 130.193.37.103
load_profile:
load_type: rps
schedule: const(15000, 10m)
instances: 2000
console:
enabled: true
telegraf:
enabled: falseDer aufmerksame Leser wird feststellen, dass ich die Adresse in die IP des Balancers geändert habe - dies liegt an der Tatsache, dass Cloudflare mich für eine große Anzahl von Anfragen von einer IP blockiert hat. Ich musste den Tank direkt auf den Yandex.Cloud Balancer stellen. Nach dem Start sehen Sie das folgende Bild: Die
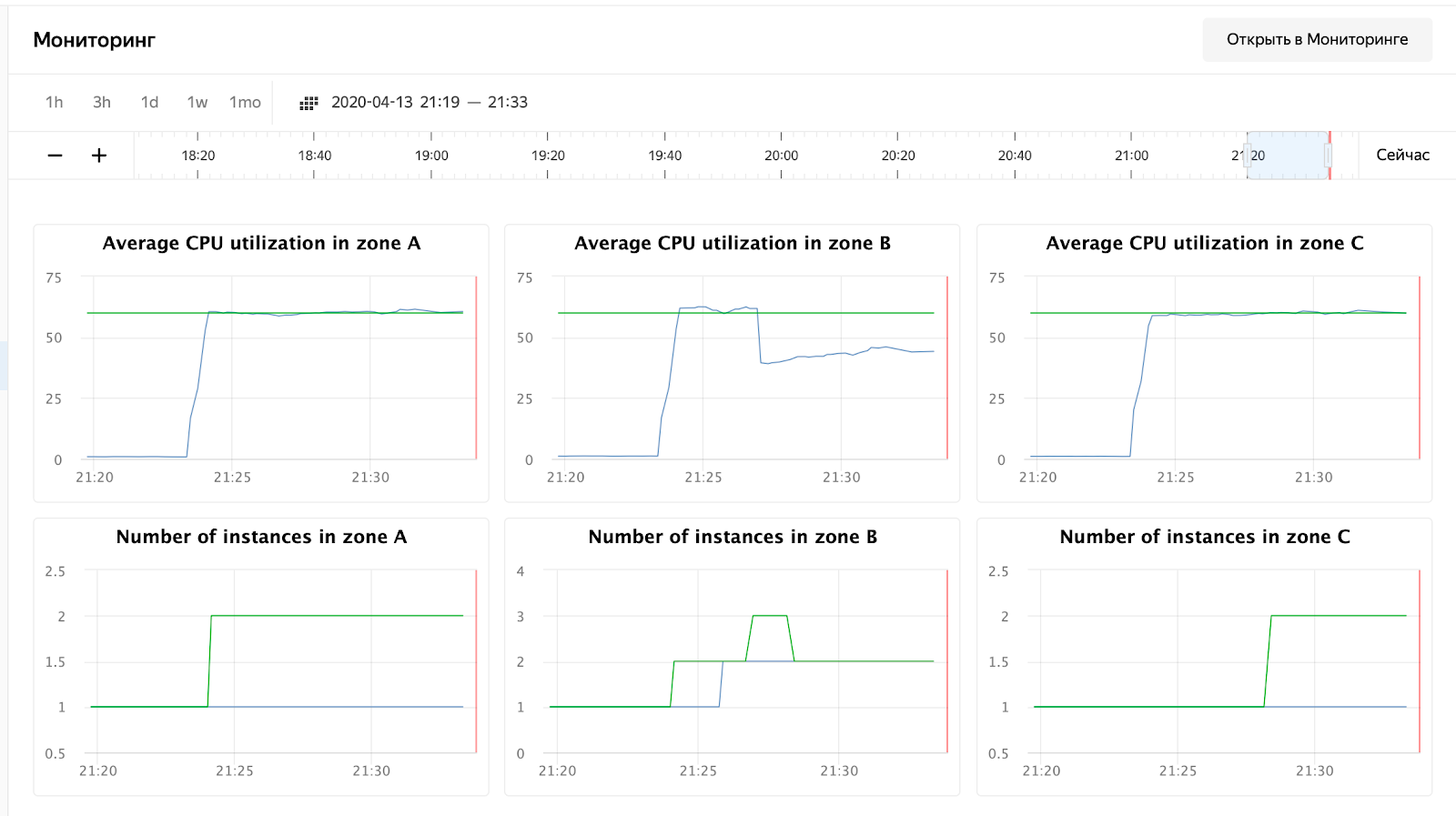
CPU-Auslastung ist gestiegen, und der Scheduler hat beschlossen, die Anzahl der Knoten in Zone B zu erhöhen, was er auch getan hat. Dies ist in den Instanzgruppenprotokollen zu sehen:
vozerov@mba:~/events/load (master *) $ yc compute instance-group list-logs events-api-ig
2020-04-13 18:26:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 1m AWAITING_WARMUP_DURATION -> RUNNING_ACTUAL
2020-04-13 18:25:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 37s OPENING_TRAFFIC -> AWAITING_WARMUP_DURATION
2020-04-13 18:25:09 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 43s CREATING_INSTANCE -> OPENING_TRAFFIC
2020-04-13 18:24:26 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 6s DELETED -> CREATING_INSTANCE
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ozix.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-a: 1 -> 2
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-b: 1 -> 2
... skipped ...
2020-04-13 16:23:57 Balancer target group b7rhh6d4assoqrvqfr9g created
2020-04-13 16:23:43 Going to create balancer target group
Der Scheduler hat auch beschlossen, die Anzahl der Server in anderen Zonen zu erhöhen, aber ich habe das Limit für externe IP-Adressen überschritten :) Übrigens können sie durch eine Anfrage an den technischen Support erhöht werden, indem Kontingente und gewünschte Werte angegeben werden.
Fazit
Der Artikel war nicht einfach - sowohl in Bezug auf das Volumen als auch in Bezug auf die Informationsmenge. Aber wir haben die schwierigste Phase durchlaufen und Folgendes getan:
- Erhöhte Überwachung und Kafka.
- , .
- load balancer’ cloudflare ssl .
Vergleichen und testen wir das nächste Mal den Warteschlangenservice von rabbitmq / kafka / yandex.
Bleib dran!
* Dieses Material befindet sich in der Videoaufzeichnung des offenen Workshops REBRAIN & Yandex.Cloud: Wir akzeptieren 10.000 Anfragen pro Sekunde in der Yandex Cloud - https://youtu.be/cZLezUm0ekE
Wenn Sie daran interessiert sind, solche Veranstaltungen online zu besuchen und Fragen in Echtzeit zu stellen, verbinden Sie sich mit Kanal DevOps von REBRAIN .
Wir möchten uns ganz besonders bei Yandex.Cloud für die Gelegenheit bedanken, eine solche Veranstaltung abzuhalten. Link zu ihnen
Wenn Sie einen Wechsel in die Cloud benötigen oder Fragen zu Ihrer Infrastruktur haben, können Sie gerne eine Anfrage hinterlassen .
PS Wir haben 2 kostenlose Audits pro Monat, vielleicht gehört Ihr Projekt dazu.