Ich habe mich entschlossen, eine Multisession aus Audioaufnahmen zu erstellen, die in einem Kalendermonat gesammelt wurden, um unnötige Unordnung für Adobe Audition zu vermeiden. Natürlich kann eine solche Sitzung manuell erstellt werden, aber es ist eine lange und mühsame Arbeit. Das Hauptinteresse dieser Aufgabe besteht darin, den Aufbau einer Multisession durch Software zu automatisieren. Genauer gesagt, schreiben Sie ein Programm, das basierend auf einer Liste von Audioaufzeichnungsdateien eine SES-Datei für eine Adobe Audition-Multisession generiert. Für diejenigen, die es nicht wissen: Kurz gesagt, eine Multisession ist ein Projekt, das aus vielen verschiedenen Audioaufnahmen besteht, die zeitlich und über Tracks (Tracks) verteilt sind und eine Mischung daraus erstellen sollen.
Zunächst lohnt es sich zu diskutieren, wie ich die Audioaufnahmen von Telefongesprächen bekomme. Es ist kein Geheimnis, dass moderne Smartphones Telefonanrufe mit verschiedenen Tools aufzeichnen können, die sowohl im System als auch von Drittanbietern integriert sind. Persönlich verwende ich ein Lenovo TAB3-Tablet (mit MT8735P-Prozessor). Mit dem Gerät können Sie Audioaufnahmen im manuellen Modus in einem komprimierten Format erstellen und Dateien mit der Erweiterung 3gpp empfangen. Die Aufnahmen werden in Stereo mit getrennten Kanälen aufgenommen: In einem Kanal wird die Stimme des Teilnehmers aufgezeichnet und in dem anderen seine eigene Stimme. Das komprimierte Format von Audioaufnahmen beeinflusst deren Verzerrung während der Wiedergabe. Aus diesem Grund verwende ich Audioaufzeichnungsanwendungen von Drittanbietern, von denen es unzählige gibt. Eine der Apps, die mir am besten gefallen hat, ist "Record My Call".Diese Anwendung zeichnet Anrufe im automatischen Modus auf und verfügt über viele Einstellungen, die sich insbesondere auf die Wahl des Formats und der Qualität der Audioaufzeichnung beziehen. Als Bonus verfügt die Anwendung über ein schönes, sehr praktisches integriertes Anrufprotokoll, das in der Datenbankdatei der Datenbank gespeichert wird (Abb. 1).
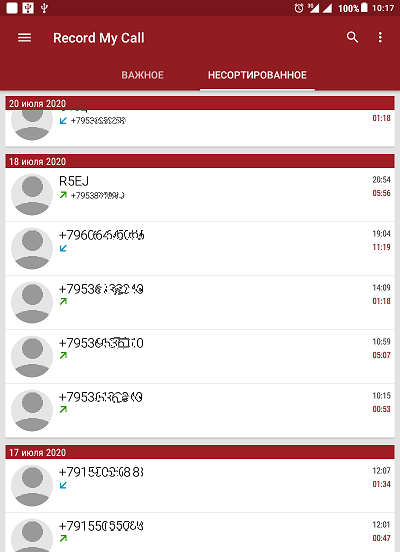
Zahl: 1. Anrufprotokoll in der Anwendung "Meinen Anruf aufzeichnen".
Die besten Audioaufzeichnungsparameter für die Klangqualität sind WAV 8000Hz 16bit Stereo. Mit solchen Einstellungen hat die Aufnahme keine Verzerrungen, klingt klar, obwohl sie mehr Speicherplatz beansprucht. Die Anwendung ist so konfiguriert, dass die Audioaufzeichnung bereits vor Beginn des Telefongesprächs automatisch startet: wenn ein eingehender Anruf eingeht, bevor der Hörer abgenommen wird, oder wenn während des Klingelns eine Nummer gewählt wird. Das heißt, verpasste und unbeantwortete Anrufe werden ebenfalls aufgezeichnet. Kann so konfiguriert werden, dass nur die Konversation aufgezeichnet wird. Das Format des Namens der Audioaufzeichnungsdatei kann ebenfalls konfiguriert werden. In meinem Fall habe ich es wie in Abbildung 2 gezeigt konfiguriert
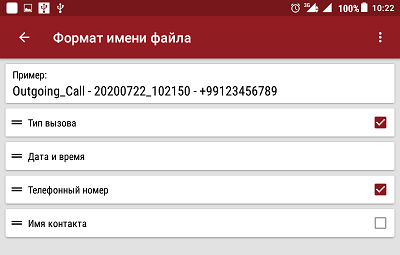
. 2. Einstellen des Dateinamenformats unter „Meinen Anruf aufzeichnen“.
Während der Entwicklung des Multisession-Generierungsprogramms müssen Informationen zu Datum und Uhrzeit der Audioaufzeichnung des Telefonanrufs erfasst werden. Diese Informationen werden dem Dateinamen an festen Positionen entnommen.
Bevor Sie mit dem Erstellen einer SES-Datei mit mehreren Sitzungen beginnen, müssen Sie wissen, wie eine solche Datei funktioniert. Natürlich gibt es nirgendwo eine Dokumentation zu diesem Format, daher musste ich es selbst lösen und mich dabei auf persönliche Erfahrungen und Kenntnisse stützen. Diese Datei ist keine Textdatei, daher macht es wenig Sinn, sie im Editor zu öffnen. "WinHex" - ein hexadezimaler Editor hilft. Ich habe bereits eine Reihe von Artikeln über das Arbeiten mit Binärdaten und das Entschlüsseln von Informationen geschrieben, insbesondere einen Artikel über das Schreiben eines 264-avi-Video-Umpackprogramms. Dort habe ich mehr oder weniger ausführlich über das Gerät der AVI-Datei geschrieben.
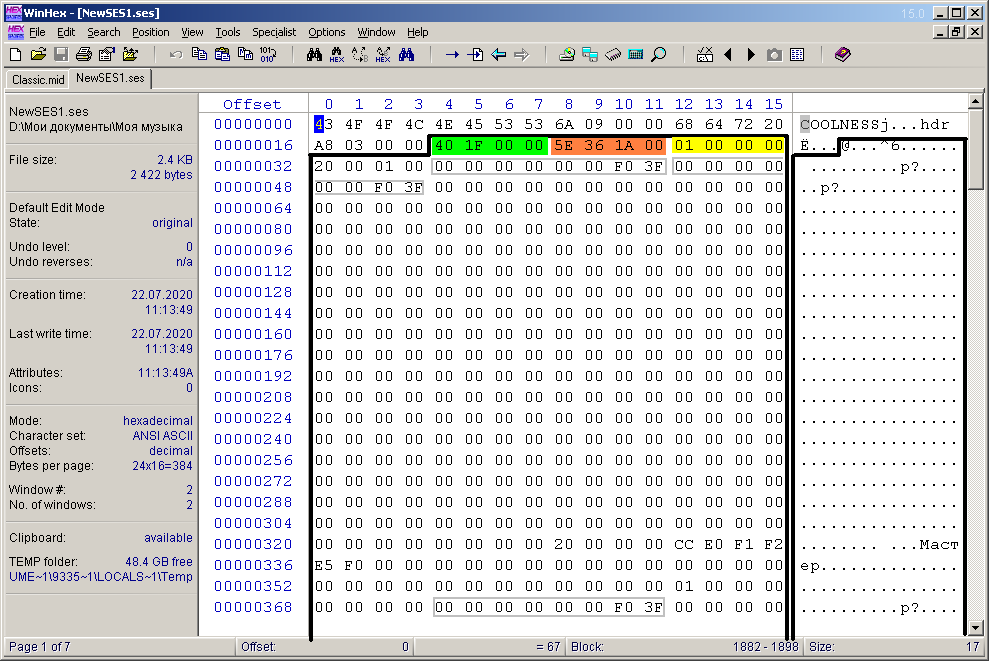
Zuerst habe ich in Adobe Audition 1.5 eine einfache willkürliche Multisession erstellt, die aus einer Spur und einer Audiodatei besteht (Abb. 3), und diese in einer Datei mit der Erweiterung ses gespeichert. Die Datei ist 2422 Byte groß. Dann habe ich diese Datei in WinHex geöffnet (Abb. 4).
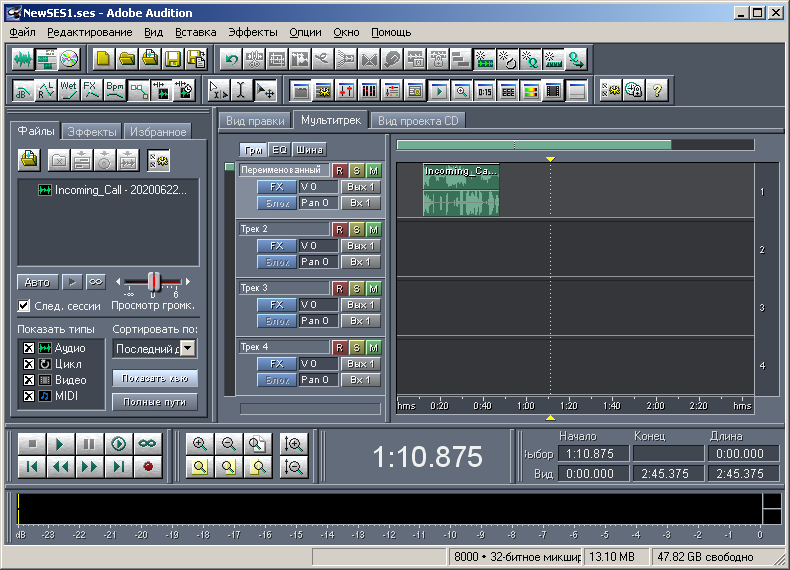
Zahl: 3. Ansicht der Multisession in Adobe Audition 1.5 - Beispiel 1.
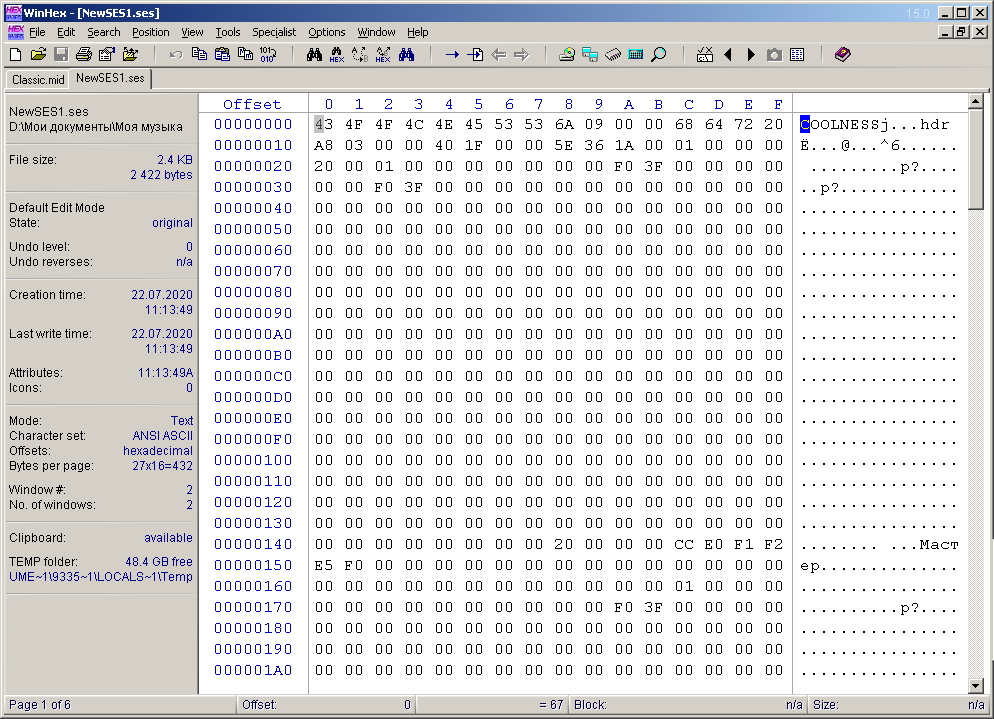
Abb. 4. In WinHex geöffnete Multisession-Datei.
Auf den ersten Blick ist überhaupt nichts klar. Im symbolischen Teil des Fensters sehen Sie die semantischen Wörter "COOLNESS", "hdr", "Master". Wenn Sie durch das folgende Dokument scrollen, sehen Sie den Text mit dem vollständigen Pfad zur Datei (und in zwei Versionen), die in der Multisession verwendet wird. Dies ist in Abbildung 5 dargestellt und grün umrandet. Sofort auffällig sind kurze semantische Wörter, die in derselben Figur in einem roten Rahmen eingekreist sind.
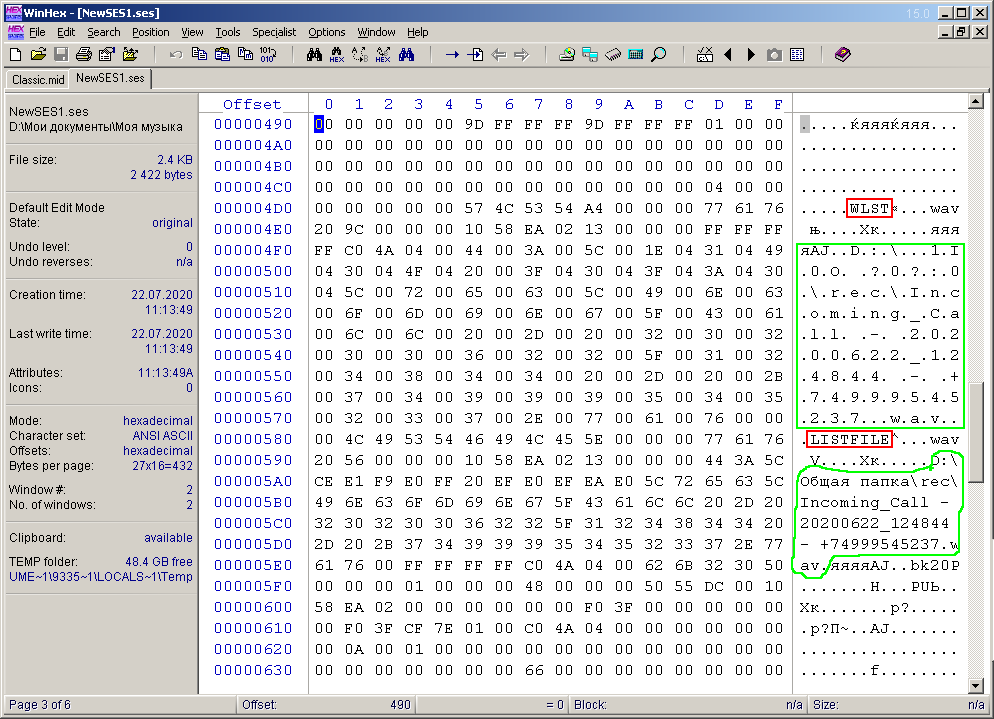
Zahl: 5. Bytes von Pfaden zu Multisession-Audiodateien.
Als ich dieses Dokument von Anfang bis Ende genauer betrachtete, bemerkte ich einige andere kurze semantische Wörter. Mir ist auch aufgefallen, dass die Länge eines bedeutungsvollen Wortes ein Vielfaches von vier ist. Anscheinend sind diese Wörter die Überschriften der Blöcke, aus denen die gesamte Multisession-Datei besteht. Es erinnerte mich an die RIFF-Struktur einer AVI- oder WAV-Datei, die aus Blöcken besteht, die auch Header derselben Größe haben. Diesen Headern folgte eine 32-Bit-Zahl (4 Bytes), die die Größe des aktuellen Blocks angibt. Vor diesem Hintergrund habe ich mich entschlossen zu prüfen, ob dieses Prinzip für die ses-Datei funktioniert. Es stellte sich heraus, dass dies auch beim ses-Format funktioniert (Abb. 6).
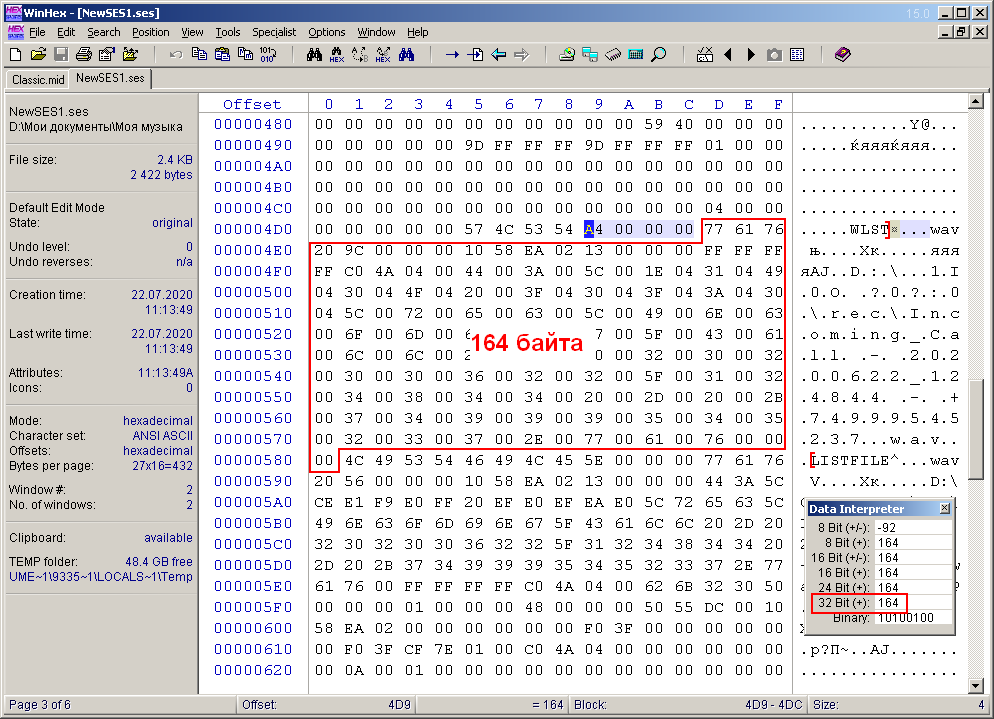
Zahl: 6. Ähnlichkeit mit der RIFF-Struktur (zum Beispiel dem Block "WLST").
Das erste Wort "COOLNESS" in der ses-Datei scheint der Hauptheader und der Typ dieser Datei zu sein. Die nächsten 4 Bytes entsprechen der Größe des Inhalts, der bis zum Ende der Datei als Nächstes platziert wird. Das heißt, wenn Sie sorgfältig berechnen, ist dieser Wert 12 Byte kleiner als die Größe der gesamten Datei. Weitere Inhalte bestehen aus einer Sammlung verschiedener Blöcke. Der Block hat einen Header von vier oder acht Bytes, gefolgt von 4 Bytes, die die Größe dieses Blocks angeben, und danach folgt der Inhalt dieses Blocks. In einigen Blöcken habe ich das Vorhandensein von Unterblöcken festgestellt, dies wird jedoch im Verlauf einer detaillierteren Beschreibung jedes Blocks erläutert. In dieser Datei, in der ich im Beispiel 17 Blöcke gezählt habe, sind sie in der Tabelle in Abbildung 7 aufgeführt
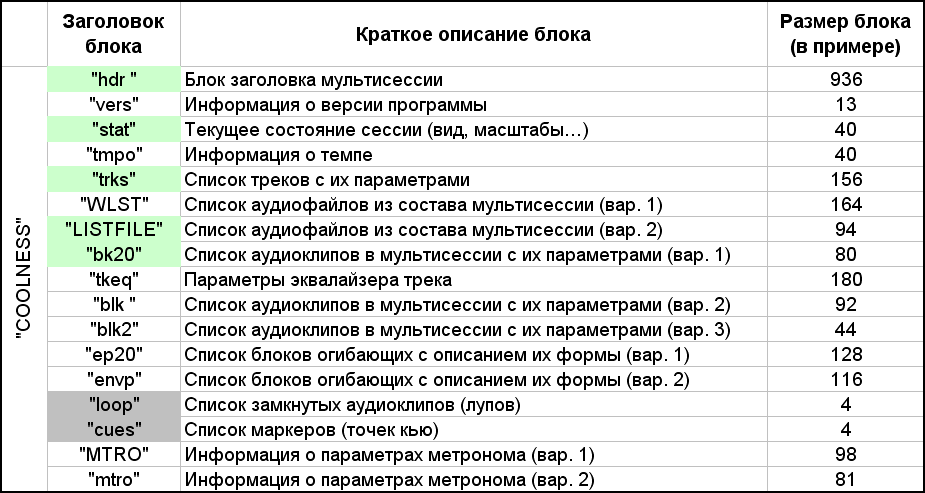
. 7. Liste der Blöcke, aus denen die Multisession besteht.
Wie Sie der Tabelle entnehmen können, werden einige der gleichen Informationen in verschiedenen Versionen von verschiedenen Blöcken dargestellt. Dies geschieht wahrscheinlich aus Gründen der Kompatibilität verschiedener Programmversionen. Mit Blick auf die Zukunft werden diese Blöcke grün hervorgehoben, ohne die die im Beispiel dargestellte Multisession nicht existieren kann. Zwei 4-Byte-Blöcke werden grau hervorgehoben, die in dieser Sitzung fiktiv sind. In der Tat hatte ich eine Frage: Was passiert, wenn Sie einige der Blöcke aus der Datei löschen? Schließlich brauche ich zum Beispiel keine Informationen über das Metronom und das Tempo, und die Hüllkurven auf Clips (genauer gesagt auf einem Clip) fehlen in meinem einfachen Beispiel. Hüllkurven sind Kurven über einem Audioclip, die die Dynamik der Klangparameter (Lautstärke, Balance) über die Zeit einstellen. Ich fing nacheinander an, Blöcke aus der angegebenen Datei zu schneiden.Nicht zu vergessen, den Wert nach dem Wort "COOLNESS" neu zu berechnen und zu korrigieren. Infolgedessen wurde die Multisession erfolgreich mit mindestens fünf grün hervorgehobenen Blöcken eröffnet. Die Sitzung enthält zwei Blöcke der Liste der Audiodateien. Jeder von ihnen könnte verlassen werden. Ich bevorzuge die zweite Option (den Block "LISTFILE"), da in der ersten Option (dem Block "WLST") zwei Bytes pro Zeichen in der Dateipfadbeschreibung enthalten sind. Dies wurde möglicherweise für das erweiterte Zeichenalphabet durchgeführt, aber das Standard-ASCII-Alphabet reicht mir aus. Darüber hinaus werden russische Schriftzeichen, wie Sie sehen können, gut unterstützt. Die Beschreibung der Audioclips erfolgt in drei Versionen. Ich habe die erste Option gewählt (Block "bk20"), weil ich die Beschreibung am schnellsten herausgefunden habe.Die Sitzung enthält zwei Blöcke der Liste der Audiodateien. Jeder von ihnen könnte verlassen werden. Ich bevorzuge die zweite Option (den Block "LISTFILE"), da in der ersten Option (dem Block "WLST") zwei Bytes pro Zeichen in der Dateipfadbeschreibung enthalten sind. Dies wurde möglicherweise für das erweiterte Zeichenalphabet durchgeführt, aber das Standard-ASCII-Alphabet reicht mir aus. Darüber hinaus werden russische Schriftzeichen, wie Sie sehen können, gut unterstützt. Die Beschreibung der Audioclips erfolgt in drei Versionen. Ich habe die erste Option gewählt (Block "bk20"), weil ich die Beschreibung am schnellsten herausgefunden habe.Die Sitzung enthält zwei Blöcke der Liste der Audiodateien. Jeder von ihnen könnte verlassen werden. Ich bevorzuge die zweite Option (den Block "LISTFILE"), da in der ersten Option (dem Block "WLST") zwei Bytes pro Zeichen in der Dateipfadbeschreibung enthalten sind. Dies wurde möglicherweise für ein erweitertes Zeichenalphabet durchgeführt, aber das Standard-ASCII-Alphabet reicht mir. Darüber hinaus werden russische Schriftzeichen, wie Sie sehen können, gut unterstützt. Die Beschreibung der Audioclips erfolgt in drei Versionen. Ich habe die erste Option gewählt (Block "bk20"), weil ich die Beschreibung am schnellsten herausgefunden habe.Aber das Standard-ASCII-Alphabet reicht mir. Darüber hinaus werden russische Schriftzeichen, wie Sie sehen können, gut unterstützt. Beschreibungen von Audioclips werden in drei Versionen präsentiert. Ich habe die erste Option gewählt (Block "bk20"), weil ich die Beschreibung am schnellsten herausgefunden habe.Aber das Standard-ASCII-Alphabet reicht mir. Darüber hinaus werden russische Schriftzeichen, wie Sie sehen können, gut unterstützt. Die Beschreibung der Audioclips erfolgt in drei Versionen. Ich habe die erste Option gewählt (Block "bk20"), weil ich die Beschreibung am schnellsten herausgefunden habe.
Eine Multisession aus Audioaufzeichnungen von Telefongesprächen ist ähnlich komplex wie die in diesem Beispiel vorgestellte Multisession. Der einzige Unterschied besteht darin, dass es umfangreicher wird: Die Anzahl der Audiodateien ist ziemlich groß und die Anzahl der Spuren entspricht der Anzahl der Tage in einem Monat. Für eine solche Multisession werden keine weiteren "Schnickschnack" benötigt. Die Blockgrößen "hdr" und "stat" sind statisch und betragen unabhängig von der Größe der Multisession immer 936 bzw. 40 Byte. Die Größe der Blöcke "trks" und "bk20" hängt von der Anzahl der Spuren bzw. Audioclips in der Multisession ab. Die Größe des "LISTFILE" -Blocks ist jedoch am unvorhersehbarsten: Sie hängt nicht nur von der Anzahl der Audiodateien in einer Multisession ab, sondern auch von der Länge ihrer Namen und ihren Standortpfaden.
Das Entschlüsseln und Verfassen einer vollständigen Beschreibung der Blöcke einer Multisession-Datei ist eine ziemlich zeitaufwändige Aufgabe. Daher habe ich die Informationen teilweise dekodiert und nur die Byte-Abschnitte berücksichtigt, die bei der Bildung einer Multisession vereinfachter Inhalte berücksichtigt werden müssen. In diesem Artikel werde ich den Inhalt jedes Blocks beschreiben, den ich entschlüsseln konnte.
Im Inhalt des Multisession-Headerblocks "hdr" (am Ende steht nur ein Leerzeichen) sind die Schlüsselbytes die ersten 12 Bytes, dh 3 Wörter zu je 4 Bytes (Abb. 8). Das erste Wort ist die Abtastrate der Abtastwerte in der Multisession. Für meine Multisession beträgt dieser Wert 8000 Hz (0x1F40). In Abbildung 8 ist es mit grüner Füllung hervorgehoben. Ich möchte Sie daran erinnern, dass Bytes in Wörtern für numerische Werte rückwärts gelesen werden. Das zweite Wort ist die Dauer (Länge) der Multisession, ausgedrückt in der Anzahl der Proben (orangefarbene Füllung in der Abbildung). In diesem Beispiel ist dieser Wert 0x1A365E (1717854). In Minuten übersetzt erhalten Sie 1717854/8000/60, was ungefähr dreieinhalb Minuten entspricht. Und so ist es auch: In einem minimalen Maßstab hat eine Multisession genau diese Dauer.Und für eine Multisession aus Telefonanrufaufzeichnungen sollte die Dauer ein Tag oder 24 * 3600 * 8000 = 691200000 = 0x2932E000 Proben sein. In dieser Situation stimmt die aktuelle Wiedergabezeit der Multisession auf dem Panel unten, die eine relative Zeit ist, übrigens genau mit dem Wert der absoluten Zeit des aktuellen Telefonanrufs (oder einer Gruppe von Anrufen pro Tag) überein. Das nächste gelb hervorgehobene Wort gibt die Anzahl der Audioclips in der Multisession an. In diesem Beispiel ist dieser Wert gleich eins, aber bei Telefonanrufen entspricht die Anzahl solcher Clips der Anzahl der Audiodateien. Mit Blick auf die Zukunft ist die letzte Aussage nicht ganz richtig. Tatsächlich kann die Anzahl der Audioclips geringfügig höher sein als die Anzahl der Audiodateien. Eine Datei kann in diesem Fall zwei Clips enthaltenwenn während eines Telefongesprächs ein neuer Tag gekommen ist. In diesem Fall müssen Sie die Aufnahme auf eine neue Spur "übertragen", und ein Clip funktioniert nicht. In der Praxis sind solche Fälle jedoch selten, da der Übergang zu einem neuen Tag nachts erfolgt, wenn die Aktivität von Telefonanrufen minimal ist. Übrigens habe ich diesen Punkt bei der Erstellung des SVG-Diagramms im vorherigen Artikel nicht berücksichtigt. Nachdem das Wort des Wertes der Anzahl der Blöcke folgt, höchstwahrscheinlich ein "halbes Wort" von zwei Bytes 0x0020 oder 32 in Dezimalform. Es könnte auch mit einer Farbfüllung hervorgehoben werden, da dies höchstwahrscheinlich die Bittiefe des Mischens bedeutet. In Adobe Audition wird in der Statusleiste unten Folgendes angezeigt: 8000 Hz, 32-Bit-Mischung. Zusätzlich zu den drei wichtigsten Wörtern des "hdr" -Inhalts gibt es weitere obskure Bytes. Zum Beispiel kenne ich nicht einmal das Wort "Meister"worauf es sich bezieht. Anscheinend ist dies der Name des Hauptmischbusses. Aber die interessantesten Gruppen von Bytes, die ich umkreiste, kreisten in einem grauen Rahmen. Tatsache ist, dass diese Sequenz häufig in anderen Blöcken der Multisession-Datei gefunden wird. Es ist kein Zufall, dass ich genau 8 Bytes zu einer Gruppe zusammengefasst habe, da dies höchstwahrscheinlich ein realer Datentyp ist. Insbesondere wird diese Konstante "00 00 00 00 00 00 F0 3F" HEX vom Editor im Double-Typ als 1.0e + 0 interpretiert, dh als Einheit. Höchstwahrscheinlich sind dies die Werte für Lautstärkepegel und andere "Drehungen", die jedoch nicht in Dezibel, sondern in Form eines Koeffizienten angegeben werden. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.Aber die interessantesten Gruppen von Bytes, die ich in einem grauen Rahmen eingekreist habe. Tatsache ist, dass diese Sequenz häufig in anderen Blöcken der Multisession-Datei gefunden wird. Es ist kein Zufall, dass ich genau 8 Bytes zu einer Gruppe zusammengefasst habe, da dies höchstwahrscheinlich ein realer Datentyp ist. Insbesondere wird diese Konstante "00 00 00 00 00 00 F0 3F" HEX vom Editor im Double-Typ als 1.0e + 0 interpretiert, dh als Einheit. Höchstwahrscheinlich sind dies die Werte für Lautstärkepegel und andere "Drehungen", die jedoch nicht in Dezibel, sondern in Form eines Koeffizienten angegeben werden. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.Aber die interessantesten Gruppen von Bytes, die ich in einem grauen Rahmen eingekreist habe. Tatsache ist, dass diese Sequenz häufig in anderen Blöcken der Multisession-Datei gefunden wird. Es ist kein Zufall, dass ich genau 8 Bytes zu einer Gruppe zusammengefasst habe, da dies höchstwahrscheinlich ein realer Datentyp ist. Insbesondere wird diese Konstante "00 00 00 00 00 00 F0 3F" HEX vom Editor im Double-Typ als 1.0e + 0 interpretiert, dh als Einheit. Höchstwahrscheinlich sind dies die Werte für Lautstärkepegel und andere "Drehungen", die jedoch nicht in Dezibel, sondern in Form eines Koeffizienten angegeben werden. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.Es ist kein Zufall, dass ich genau 8 Bytes zu einer Gruppe zusammengefasst habe, da dies höchstwahrscheinlich ein realer Datentyp ist. Insbesondere wird diese Konstante "00 00 00 00 00 00 F0 3F" HEX vom Editor im Double-Typ als 1.0e + 0 interpretiert, dh als Einheit. Höchstwahrscheinlich sind dies die Werte für Lautstärkepegel und andere "Drehungen", die jedoch nicht in Dezibel, sondern in Form eines Koeffizienten angegeben werden. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.Es ist kein Zufall, dass ich genau 8 Bytes zu einer Gruppe zusammengefasst habe, da dies höchstwahrscheinlich ein realer Datentyp ist. Insbesondere wird diese Konstante "00 00 00 00 00 00 F0 3F" HEX vom Editor im Double-Typ als 1.0e + 0 interpretiert, dh als Einheit. Höchstwahrscheinlich sind dies die Werte für Lautstärkepegel und andere "Drehungen", die jedoch nicht in Dezibel, sondern in Form eines Koeffizienten angegeben werden. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.und als Koeffizient. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.und als Koeffizient. Ich muss sofort sagen, dass alle Bytes eines Blocks, die ich nicht erkennen konnte (oder nicht benötigte), wie im Beispiel unverändert in die generierte Multisession-Datei geschrieben werden.
. 8. «hdr ».
Ich habe beschlossen, den "stat" -Block des aktuellen Multisession-Status (den kürzesten) nicht zu studieren. Ich habe eine weitere Beispiel-Multisession aus einer Audiodatei erstellt, sie für 24 Stunden gedehnt und ihre vollständige Ansicht (Skalierung) horizontal erstellt. Vertikal wurde die Ansicht der Spuren so skaliert, dass beim Erweitern des Adobe Audition-Fensters 31 Spuren auf den FullHD-Bildschirm passen. Dies ist die maximale Anzahl von Tagen in einem Monat. Der Multisession-Cursor wurde ganz am Anfang positioniert. Dann habe ich diese Multisession in einer anderen Datei gespeichert und dann den "stat" -Block mit all seinen Headern herausgezogen. Ich habe diese Bytes in der Datei "stat_31_full.BLK" zur weiteren Verwendung bei der Entwicklung des Programms gespeichert. Die Ansicht des Inhalts einer solchen Datei ist in Abbildung 9 dargestellt. Die Größe dieser Datei betrug 48 Byte (40 Byte des Blockinhalts + 4 Byte des Headers + 4 Byte der Beschreibung der Größe des Inhalts).
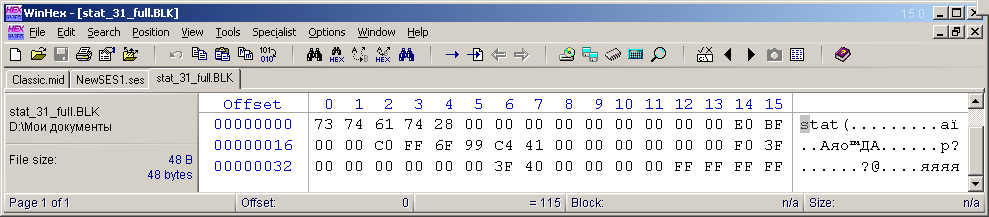
. 9. «stat» .
Für eine visuellere Beschreibung der nächsten drei Blöcke im Verlauf dieses Artikels habe ich beschlossen, eine komplexere Multisession zu erstellen, die aus zwei Spuren, zwei Dateien und drei Clips besteht (Abb. 10). Die erste Datei "Incoming_Call - 20200622_124844 - + 74999545237.wav" hat eine Dauer von 281280 Samples. Die zweite Datei "Outgoing_Call - 20200621_231753 - + 79536170218.wav" hat eine Dauer von 63360 Samples. Der erste Titel mit dem Namen "First" (umbenannt) enthält zwei Clips. Der erste Clip wird vom Beginn der Sitzung um 10 Sekunden verschoben (um 80.000 Samples). Der Clip wird durch den vollständigen Inhalt der ersten Audiodatei dargestellt, dh die Dauer des Clips entspricht der Dauer der Datei. Der zweite Clip wird ab Beginn der Sitzung um 50 Sekunden verschoben (um 50 * 8000 = 400000 Samples). Der Clip wird durch den unvollständigen Inhalt der zweiten Audiodatei dargestellt. Innerhalb eines bestimmten Clips beginnt Audio am Anfang der Datei.dauert aber nur 5 Sekunden (40.000 Proben). Das heißt, die Cliplänge beträgt 5 Sekunden. Der zweite Titel mit dem Namen "Second" enthält einen Clip. Sie wird vom Beginn der Sitzung um eine Sekunde verschoben (um 8000 Abtastwerte). Dieser Clip wird durch unvollständigen Inhalt der ersten Audiodatei dargestellt. In diesem Clip beginnt Audio nicht am Anfang, sondern nach 3 Sekunden, sondern enthält es bis zum Ende. Somit beträgt der Versatz der Audiodaten in diesem Clip 3 Sekunden (24.000 Samples). Die Länge eines bestimmten Clips wird als Differenz zwischen der Dauer des entsprechenden Audios und dem Versatz der Audiodaten innerhalb des Clips berechnet. In diesem Fall beträgt die Cliplänge 281280-24000 = 257280 Samples.Dieser Clip wird durch unvollständigen Inhalt der ersten Audiodatei dargestellt. In diesem Clip beginnt Audio nicht am Anfang, sondern nach 3 Sekunden, sondern enthält es bis zum Ende. Somit beträgt der Versatz der Audiodaten in diesem Clip 3 Sekunden (24.000 Samples). Die Länge eines bestimmten Clips wird als Differenz zwischen der Dauer des entsprechenden Audios und dem Versatz der Audiodaten innerhalb des Clips berechnet. In diesem Fall beträgt die Cliplänge 281280-24000 = 257280 Samples.Dieser Clip wird durch unvollständigen Inhalt der ersten Audiodatei dargestellt. In diesem Clip beginnt Audio nicht am Anfang, sondern nach 3 Sekunden, sondern enthält es bis zum Ende. Somit beträgt der Versatz der Audiodaten in diesem Clip 3 Sekunden (24.000 Samples). Die Länge eines bestimmten Clips wird als Differenz zwischen der Dauer des entsprechenden Audios und dem Versatz der Audiodaten innerhalb des Clips berechnet. In diesem Fall beträgt die Cliplänge 281280-24000 = 257280 Samples.In diesem Fall beträgt die Cliplänge 281280-24000 = 257280 Samples.In diesem Fall beträgt die Cliplänge 281280-24000 = 257280 Samples.
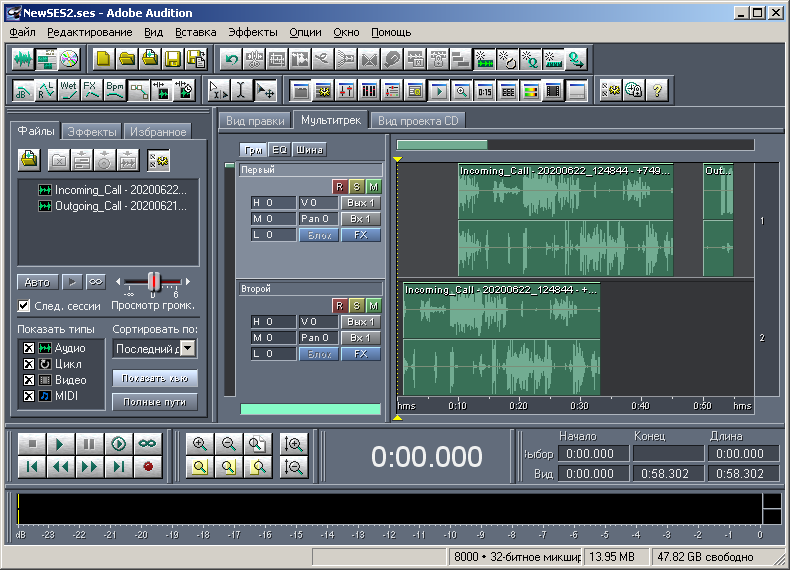
. 10. Adobe Audition 1.5 — 2.
Fig. 11 zeigt die Ansicht des Inhalts des Spurbeschreibungsblocks "trks". 4 Bytes des Blockheaders werden im roten Rahmen hervorgehoben, die Größe des Blockinhalts im grünen. Dies wurde bereits oben diskutiert. Als nächstes folgt der Inhalt des Blocks, dessen Bytes im WinHex-Editor mit einer charakteristischen bläulichen Füllung hervorgehoben werden. Die Größe der Auswahl, deren Wert in der unteren rechten Ecke des Editors angezeigt wird (ebenfalls grün eingekreist), stimmt mit dem Wert aus den Bytes nach dem Header überein und beträgt in diesem Beispiel bereits 308 Bytes. Wenn im ersten (vorherigen) Beispiel einer Spur die Blockgröße 156 Bytes und im aktuellen 308 Bytes betrug, kann die folgende Schlussfolgerung gezogen werden. Aufgrund der Annahme der Homogenität und Äquivalenz der Spuren sollten die Beschreibungsbereiche jeder Spur dieselbe Größe haben. Diese Bereiche sind sozusagen Unterblöcke des "trks" -Blocks.Sie sind in der Abbildung blau umrandet. Es stellte sich heraus, dass die Größe eines solchen Unterblocks 152 Bytes beträgt. Ganz am Anfang der aufeinanderfolgenden Unterblöcke befindet sich eine Unterüberschrift von vier Bytes, die in der Abbildung mit gelber Füllung markiert ist. Diese vier Bytes sind nichts anderes als der Wert der Anzahl der Spuren in einer Multisession oder die Anzahl der Unterblöcke. Und so kann die Größe S des Inhalts des "trks" -Blocks durch die Formel S = 4 + 152 * n berechnet werden, wobei n die Anzahl der Spuren in der Sitzung ist. So ist es: 4 + 152 * 1 = 156 und 4 + 152 * 2 = 308.Die Größe S des Inhalts des "trks" -Blocks kann durch die Formel S = 4 + 152 * n berechnet werden, wobei n die Anzahl der Spuren in der Sitzung ist. So ist es: 4 + 152 * 1 = 156 und 4 + 152 * 2 = 308.Die Größe S des Inhalts des "trks" -Blocks kann durch die Formel S = 4 + 152 * n berechnet werden, wobei n die Anzahl der Spuren in der Sitzung ist. So ist es: 4 + 152 * 1 = 156 und 4 + 152 * 2 = 308.
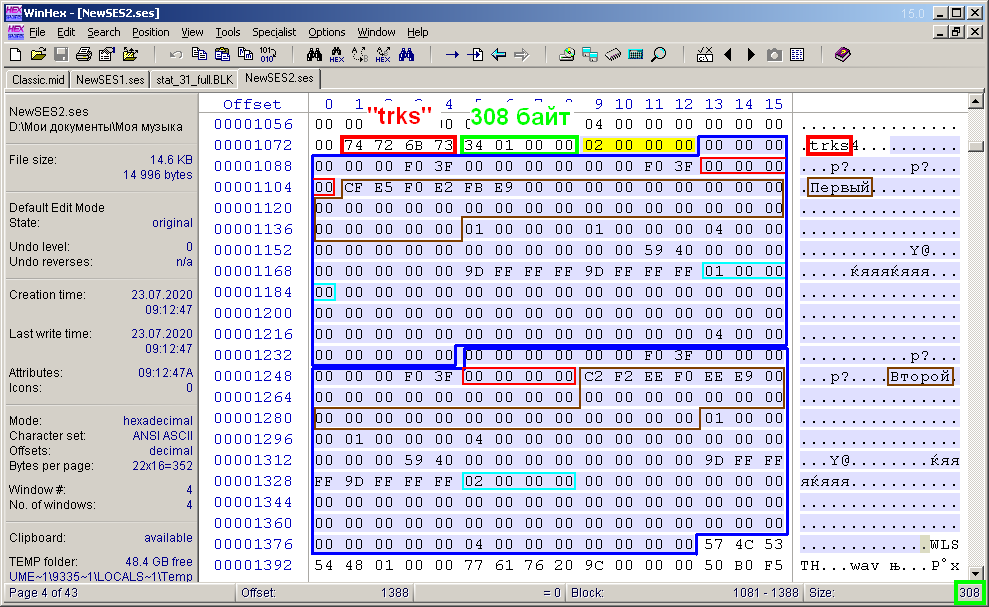
. 11. «trks».
Fahren wir nun mit der Beschreibung des Inhalts des Unterblocks fort. Es gibt viel, aber ich habe nur das Notwendigste entschlüsselt. Es gibt nur drei Parameter: 4 Bytes Binärflags (rot eingekreist), Spurname (braun eingekreist) und Spur-ID (blau eingekreist). Die Spurkennung ist ihre Sequenznummer. Es wird benötigt, um den Link zur Spur in der Beschreibung der Audioclips anzugeben (dazu später mehr). Der Titelname nimmt eine Fläche von 36 Bytes ein. Dies ist die maximale Anzahl von Zeichen im Titelnamen, kann jedoch geringer sein als im aktuellen Beispiel. Nicht verwendete Bytes sind Null. In einer Multisession mit Audioaufzeichnungen von Telefonanrufen stimmen die Titelnamen mit der Aufzeichnung der entsprechenden Daten überein. Sie können den entsprechenden Wochentag neben dem Datum in zwei Großbuchstaben in Kurzform hinzufügen.Vier Bytes Binärflags (insgesamt 32 Flags) werden verwendet, um die für die Spur spezifischen Binärparameter zu beschreiben. Tatsächlich gibt es möglicherweise weniger als 32 davon. Ich habe nur einen Teil der Flaggen entschlüsselt. Von diesen geben mindestens drei Flags an, ob die Spur "R" (Aufnahme), "S" (Solo) oder "M" (Stumm) ist. Im angegebenen Beispiel wird keine dieser drei Tasten auf den Spuren gedrückt, und der Wert der Binärflags ist Null (0x00000000). Wenn Sie jedoch die Taste "R" auf der Spur drücken (dh die Spur aufzeichnen) und die Sitzung erneut speichern, wird der Wert der Binärflags 0x00000004, dh das dritte Bit von rechts (Bit2) wird einzeln. Es ist dieses Bit, das für die "record" -Eigenschaft des Tracks verantwortlich ist. Diese Eigenschaft hat in meinem Projekt keine Bedeutung, da meine Multisession für die visuelle Anzeige und Wiedergabe ausgelegt ist.Ich kam jedoch auf die Idee, dass der "R" -Knopf auf den Tracks gedrückt wurde, die dem Wochenende entsprechen. Diese Technik erleichtert die Visualisierung der Multisession.
Der Block der Liste der Audiodateien der Multisession "LISTFILE" (Abb. 12) besteht aus folgenden Teilen. Wie im Fall des Spurbeschreibungsblocks kann er auch entsprechend der Anzahl der Dateien in der Sitzung in Unterblöcke unterteilt werden. Ähnlich wie in Abbildung 11 habe ich auch den 8-Byte-Blockheader in einem roten Feld und die Größe seines Inhalts in einem grünen Feld hervorgehoben. In diesem Beispiel beträgt dieser Wert 188 Byte. Der Inhalt wird analog zu Abb. 11. Es ist in zwei Zonen unterteilt, die mit einer blauen Linie hervorgehoben sind. Dies sind die Unterblöcke des Dateilistenblocks.
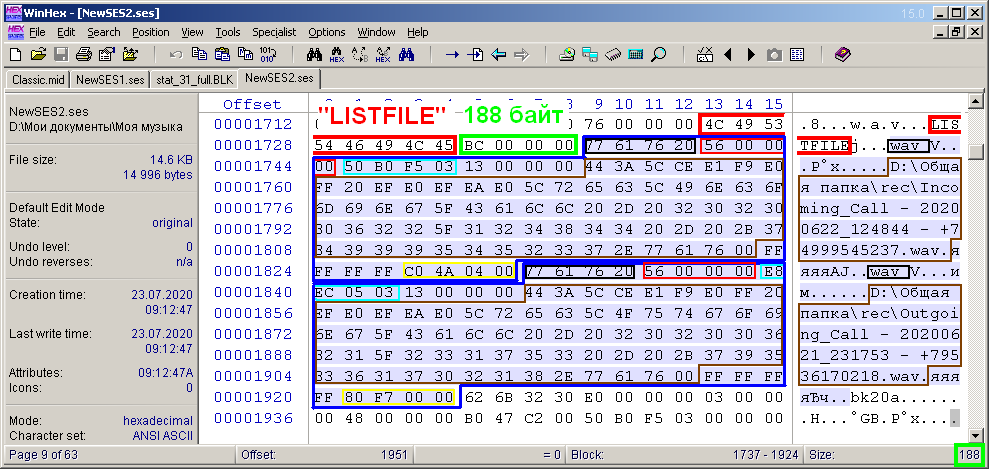
Zahl: 12. Bytes des Beschreibungsblocks der Audiodateien "LISTFILE".
Jeder Unterblock entspricht einer Audiodatei. In diesem Beispiel werden zwei Audiodateien verwendet, sodass die Anzahl der Unterblöcke angemessen ist. Im Gegensatz zum vorherigen Fall mit Spurbeschreibungen gibt es keine Unterüberschrift über die Anzahl der Unterblöcke. Der Unterblock enthält 4 Bytes seines "wav" -Headers (schwarz hervorgehoben) und 4 Bytes, die die Größe des weiteren Inhalts angeben (in Magenta hervorgehoben). Für beide Unterblöcke ist dieser Wert in diesem Beispiel gleich und beträgt 0x56 (86) Byte. Dies liegt daran, dass sich die Dateien im selben Pfad befinden und denselben Namen haben. Genauer gesagt haben vollständig qualifizierte Dateinamen die gleiche Anzahl von Zeichen. Andernfalls hätten die Untereinheiten unterschiedliche Größen. Der Unterblock-Inhaltsbereich (weitere Bytes) enthält die folgenden Informationen. Eine Nummer, die eine Audiodatei identifiziert, wird in einem blauen Rahmen hervorgehoben.Im Gegensatz zur Titel-ID ist diese Nummer keine Dateisequenznummer. Soweit ich weiß, wird beim Speichern einer Multisession jede Datei zufällig oder pseudozufällig zugewiesen. Die Hauptsache ist, dass es keinen Zufall zwischen diesen Werten gibt. Davon war ich überzeugt, als ich die Multisession zweimal gespeichert und die ses-Dateien nach Inhalten verglichen habe. Als Ergebnis stellte sich heraus, dass sich die Dateien nur um dieselben Bytes unterscheiden. Und nicht nur diese. Eine ID wird auch der ID der Hüllkurvenschichten im Block „ep20“ zugewiesen. In diesem Block besteht jedoch, wie oben erwähnt, überhaupt keine Notwendigkeit, und seine Beschreibung wird in diesem Artikel nicht berücksichtigt. Audio-IDs werden benötigt, um sie mit Clips zu verknüpfen. Dieser Link erfolgt im Block mit der Beschreibung der Clips.In meinem Fall sind für eine Multisession mit Telefonaufzeichnungen die Bezeichner für die Audiodateien eine Folge natürlicher Zahlen, jedoch nicht bei Null, sondern beispielsweise bei 1000. Die nächsten 4 Bytes, die ich nicht hervorgehoben habe, haben in beiden Unterblöcken den Wert 0x13. Dieser Wert gibt höchstwahrscheinlich den Typ des Audiodateiformats an. Sie können diesen Wert bedingt als Konstante betrachten, da alle meine Audiodateien vom gleichen Typ sind. Die folgende Bytezeichenfolge beschreibt den vollständigen Namen der Audiodatei mit einem Nullterminator (z. B. einem Zeilenabschluss). Die Größe dieser Kette ist eins mehr als die Anzahl der Zeichen im vollständigen Namen der Audiodatei. Als nächstes kommt die Konstante 0xFFFFFFFF. Es folgt ein Wert, der die Anzahl der Samples in dieser Audiodatei angibt (in Abb. 12 in einem gelben Rahmen hervorgehoben). Für die erste Datei ist dieser Wert 0x44AC0 und für die zweite 0xF780.Sie entsprechen lediglich den Dezimalwerten 281280 bzw. 63360, die bereits oben in der Beschreibung des zweiten Multisession-Beispiels aufgeführt sind.
Abschließend bleibt noch die Beschreibung des schwierigsten Blocks zu betrachten - des Blocks zur Beschreibung der Audioclips "bk20" (Abb. 13). In Analogie zu den beiden vorhergehenden Abbildungen werden Titel und Größe des Blockinhalts hervorgehoben.
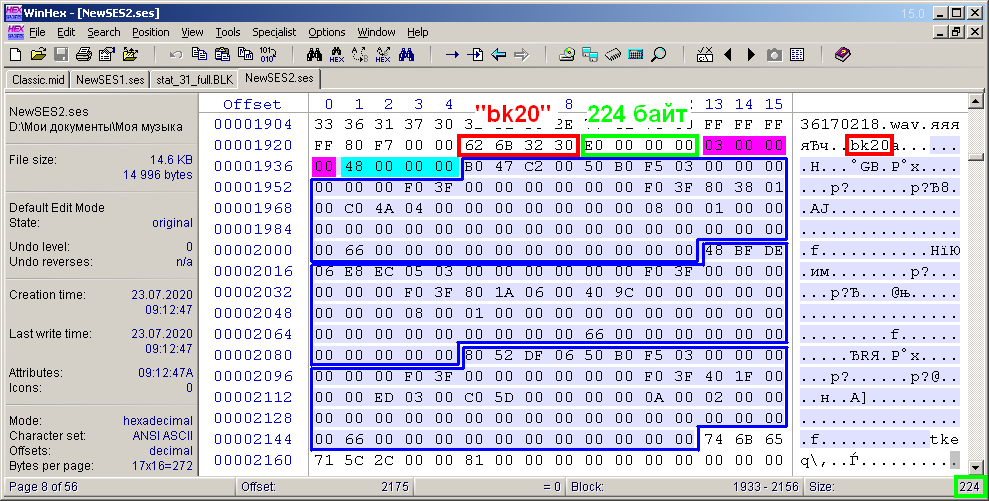
Zahl: 13. Bytes des Beschreibungsblocks der Audioclips "bk20".
Im Inhalt des Blocks gibt es zunächst zwei Unterüberschriften mit jeweils 4 Bytes. Sie werden mit Magenta- und Cyanfüllungen hervorgehoben. Der erste Untertitel ist die Anzahl der Clips in der Sitzung. Im Beispiel gibt es drei davon. Der zweite Untertitel ist die Konstante 0x48 (72). Anscheinend gibt es die Größe jedes Unterblocks an und sie gehen einfach weiter. Ihre Anzahl stimmt mit der Anzahl der Clips in der Sitzung überein. Jeder dieser Unterblöcke beschreibt die Parameter eines Clips. Übrigens kann die Größe D des Inhalts des "bk20" -Blocks nach der Formel D = 8 + 72 * b berechnet werden, wobei b die Anzahl der Audioclips in einer Multisession ist. In der Abbildung gibt es keine erklärenden Byte-Zuordnungen innerhalb der Unterblöcke, da viele notwendige Parameter vorhanden sind. Sie sind in einer separaten Tabelle aufgeführt (Abb. 14). Die blaue Füllung markiert die Parameter, die in meinem Projekt erforderlich sind, und die graue Füllung - nicht erkannte Konstanten.Diese Tabelle zeigt auch die Parameterwerte für jeden der drei Multisession-Clips aus dem letzten Beispiel.
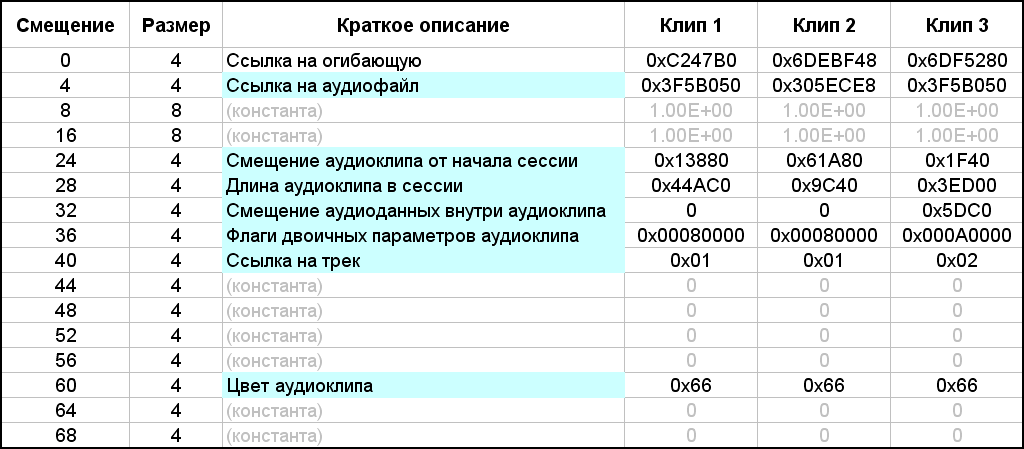
. 14. .
Das erste Wort (Gruppe von 4 Bytes) bezieht sich auf die Hüllkurve, die wir nicht benötigen. Der zweite Parameter ist ein Link zur Audiodatei. Der Wert dieses Parameters entspricht dem Wert des Bezeichners der Audiodatei, der dieser Audioclip entspricht. Dann gibt es zwei reelle Konstanten, die bereits früher aufgetreten sind. Darauf folgen drei Koordinierungsparameter, ausgedrückt in der Anzahl der Samples: der Versatz des Clips vom Beginn der Sitzung, die Länge (Dauer) des Clips in der Sitzung und der Versatz des Audios innerhalb des Clips. Aus den Namen dieser Parameter sollte alles klar sein. Etwas früher, als ich das zweite Beispiel einer Multisession ausführlich beschrieb, gab ich die numerischen Werte aller Offsets und Dauern an. In Abbildung 14 sind in der Tabelle die Parameter für jeden Clip in hexadezimaler Form aufgeführt. Ich habe diese Werte in die Tabelle eingegeben, indem ich sie direkt aus Abbildung 13 neu geschrieben habe.Wenn Sie sie jedoch in eine Dezimalform konvertieren, stimmen sie mit den entsprechenden Werten aus der Beschreibung des zweiten Beispiels überein (separat geprüft). Es ist zu beachten, dass die Links zur Audiodatei für den ersten und dritten Clip den gleichen Wert 0x3F5B050 haben, da beide Clips auf dieselbe Audiodatei mit der entsprechenden Kennung verweisen. Darauf folgt ein Block von Bytes von Binärparametern (4 Bytes). Wie bei der Beschreibung der Spuren habe ich nur einen Teil der Bits dekodiert. Der Standardwert ist 0x00080000, dh wenn er in eine Binärdatei übersetzt wird, wird nur ein Bit 19 auf eins "angehoben", und die verbleibenden 31 Bits sind gleich Null. Ohne dieses einzelne Bit weigert sich die Multisession, wie die Praxis gezeigt hat, zu laden. Im aktuellen Beispiel ist dieser Wert für den ersten und den zweiten Clip charakteristisch, für den dritten ist der Wert der Flags aus irgendeinem Grund gleich 0x000A0000.Wenn Sie zählen, werden in diesem Wert zwei Bits "angehoben": immer noch Bit19 und ein weiteres Bit17. Ich weiß nicht, warum es passiert ist. Ich habe versucht, Bit17 auf Null zurückzusetzen und den Wert des gesamten Parameters wie bei den nebenstehenden Clips auf 0x00080000 zu ändern. Infolgedessen wurde die Sitzung in Adobe Audition ohne sichtbare Änderungen geöffnet. Während der Arbeit in Adobe Audition sind mir Clip-Eigenschaften wie "In der Zeit korrigieren" und "Nur für die Wiedergabe korrigieren" aufgefallen. Es ist logisch anzunehmen, dass bestimmte Bits im Block der Binärparameter für das Speichern dieser Eigenschaften verantwortlich sind. Es gibt auch andere binäre Eigenschaften für Clips, die wir jedoch nicht benötigen. Und die beiden aufgeführten Eigenschaften werden sehr nützlich sein. Die Eigenschaft "Zeit fixieren" ist nützlich, da der Clip vor der Möglichkeit einer versehentlichen Bewegung des Mauszeigers in horizontaler Richtung geschützt ist.Bei einem solchen Clip wird jedoch ein Symbol in Form eines Schlosses in einem Kreis in der unteren linken Ecke visuell gezeichnet, und dies sind unnötige grafische Informationen zum Anzeigen. Die zweite Eigenschaft des Clips "Nur für die Wiedergabe korrigieren" ist nützlich, da der Clip keine erzwungene rote Farbe erhält, wenn der Parameter "R" (Aufnahme) auf der entsprechenden Spur aktiviert ist. Für das, was ich beschlossen habe, den Parameter "R" auf einigen Spuren zu verwenden - es ist oben geschrieben. Empirisch habe ich herausgefunden, dass Bit1 für die erste Eigenschaft des Clips und Bit3 für die zweite verantwortlich ist. Aus all dem, was gesagt wurde, folgt das Folgende. Um die Eigenschaft Clip in Time festzulegen, müssen Sie den Wert 0x00080002 in die Binärparameter schreiben. Die Eigenschaft Nur für Wiedergabe festschreiben lautet 0x00080008. Für beide Eigenschaften beträgt ihre logische Summe 0x0008000A. Behandelt mit binären Parametern.Nach diesen Bytes befindet sich ein Link zu der Spur, auf der sich der Clip befindet. Tatsächlich wird die Titelkennung registriert, die mit ihrer Seriennummer übereinstimmt. Adobe Audition 1.5 unterstützt übrigens nicht mehr als 128 Spuren, sodass diese Kennung in ein Byte passt, obwohl sie als 32-Bit-Wert aufgeführt ist. Dann gibt es nicht entschlüsselte Nullkonstanten (4 Konstanten, jeweils 4 Bytes). Schließlich ist der letzte wichtige Parameter die Farbe des Clips. Mit dem Adobe Audition 1.5-Editor können Sie einen Farbwert von 0 bis 239 für einen Clip im entsprechenden Dialogfeld festlegen oder aus einer Palette auswählen (Abb. 15). Die Farbpalette ist nicht besonders ansprechend, aber andere Optionen sind nicht angegeben. Die Standardfarbe für Clips ist 102 (0x66) (grün).Übrigens werden nicht mehr als 128 Spuren unterstützt, sodass eine solche Kennung in ein Byte passt, obwohl sie als 32-Bit-Wert aufgeführt ist. Dann gibt es nicht entschlüsselte Nullkonstanten (4 Konstanten, jeweils 4 Bytes). Schließlich ist der letzte wichtige Parameter die Farbe des Clips. Mit dem Adobe Audition 1.5-Editor können Sie einen Farbwert von 0 bis 239 für einen Clip im entsprechenden Dialogfeld festlegen oder aus einer Palette auswählen (Abb. 15). Die Farbpalette ist nicht besonders ansprechend, aber andere Optionen sind nicht angegeben. Die Standardfarbe für Clips ist 102 (0x66) (grün).Übrigens werden nicht mehr als 128 Spuren unterstützt, sodass eine solche Kennung in ein Byte passt, obwohl sie als 32-Bit-Wert aufgeführt ist. Dann gibt es nicht entschlüsselte Nullkonstanten (4 Konstanten, jeweils 4 Bytes). Schließlich ist der letzte wichtige Parameter die Farbe des Clips. Mit dem Adobe Audition 1.5-Editor können Sie einen Farbwert von 0 bis 239 für einen Clip im entsprechenden Dialogfeld festlegen oder aus einer Palette auswählen (Abb. 15). Die Farbpalette ist nicht besonders ansprechend, aber andere Optionen sind nicht angegeben. Die Standardfarbe für Clips ist 102 (0x66) (grün).Mit 5 können Sie im entsprechenden Dialogfeld einen Farbwert für den Clip von 0 bis 239 festlegen oder aus der Palette auswählen (Abb. 15). Die Farbpalette ist nicht besonders ansprechend, aber andere Optionen sind nicht angegeben. Die Standardfarbe für Clips ist 102 (0x66) (grün).Mit 5 können Sie im entsprechenden Dialogfeld einen Farbwert von 0 bis 239 für den Clip festlegen oder ihn aus der Palette auswählen (Abb. 15). Die Farbpalette ist nicht besonders ansprechend, aber andere Optionen sind nicht angegeben. Die Standardfarbe für Clips ist 102 (0x66) (grün).
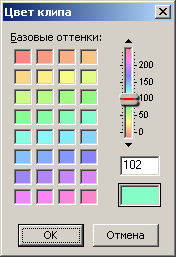
. 15. Adobe Audition 1.5.
Der Farbparameter in der ses-Datei ist 32-Bit, und tatsächlich gibt es nur 240 Farben, die in ein Byte passen. Die anderen drei höchstwertigen Bytes sind Null. Ich hatte die Idee, dass beim Öffnen einer Multisession neue Farben im Clip angezeigt werden, wenn ich versuche, diese Bytes für verschiedene Werte zu bearbeiten. Aber dieser Trick hat nicht funktioniert. Wie im vorherigen Artikel erläutert, sind Farben in einem Diagramm nützlich, um eine bestimmte Funktion eines Telefonanrufs visuell hervorzuheben. Eine Multisession von Audioaufnahmen von Telefonanrufen ähnelt einem ähnlichen Diagramm, daher ist die Farbe der Clips sehr hilfreich. Dem Parameter für die Clipfarbe folgen zwei Wörter mit Nullen. Dies vervollständigt die Beschreibung der Untereinheit. Diese acht Bytes von Nullen sind die letzten im Unterblock des letzten Blocks. Daher sind sie auch die letzten in der gesamten ses-Datei.
Während ich über das Projekt nachdachte, kam mir eine andere Idee: Markierungen (Cue-Points) zur Multisession hinzuzufügen, sie stündlich zu platzieren und die entsprechenden Markierungen zu signieren. Wenn wir diese Idee mit dem vorherigen Artikel vergleichen, ist dies eine vollständige Analogie der vertikalen Linien im Diagramm, die jede Stunde gezeichnet werden. Damit die Cue-Punkte in der Multisession vorhanden sind, muss der sechste Block namens "Cues" berücksichtigt werden. Ich habe mir nicht die Mühe gemacht, die Bytes dieses Blocks zu verstehen. In Analogie zum Block "stat" habe ich in der erstellten Multisession für 24 Stunden stündlich 23 Cue-Points manuell platziert und ihnen die entsprechenden Namen gegeben. Dann habe ich die Multisession als separate ses-Datei gespeichert, den Inhalt des Blocks "cues" ausgeschnitten und in der Datei "cues_24h.BLK" gespeichert. Diese Datei wird bei der Entwicklung des Programms berücksichtigt. Die Bytes dieser Datei sind in Abbildung 16 dargestellt. Ich weiß nicht warum,Ich habe jedoch genau den Inhalt ohne den Titel und das Feld für die Inhaltsgröße gespeichert (im Gegensatz zu "stat_31_full.BLK"). Diese beiden Wörter werden dem Programmcode hinzugefügt. Die Inhaltsgröße beträgt 556 Byte. Davon sind 4 Bytes mit dem Untertitel (der Anzahl der Cue-Points) und 23 Subblocks mit jeweils 24 Bytes belegt. In 16 sind die Inhaltsbytes des ersten Unterblocks ausgefüllt. Ich habe beschlossen, die Namen der Cue-Points (Labels) wie folgt zu machen: 01h, 02h,…, 23h.
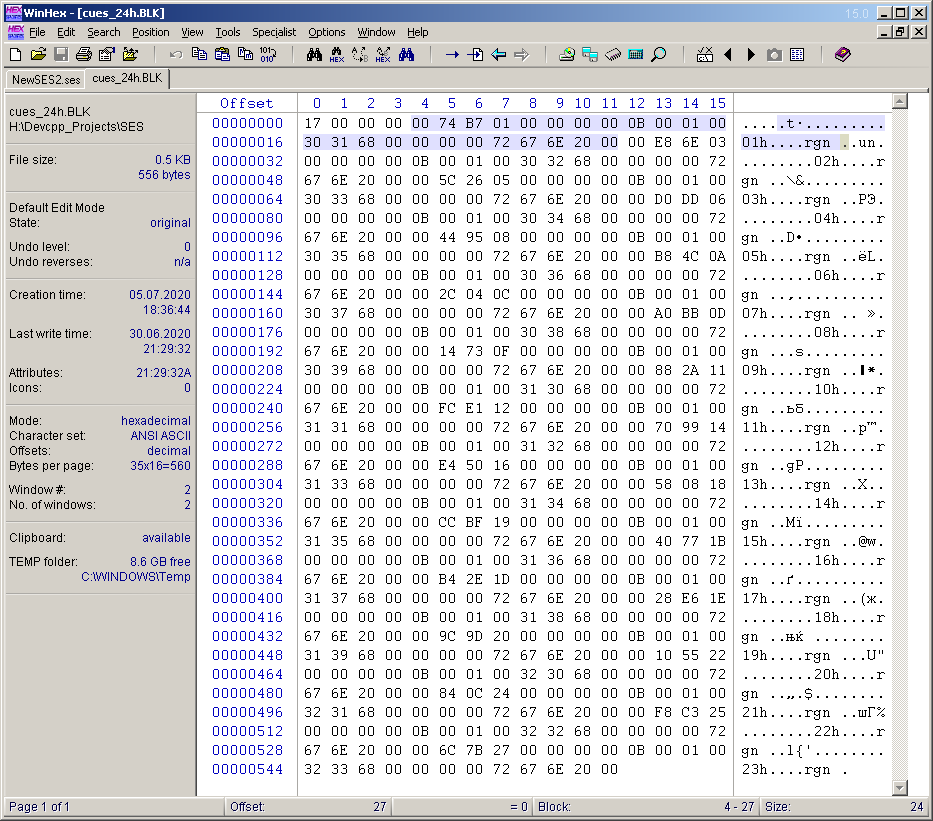
. 16. «cues» .
Damit ist die Beschreibung des Multisession-Formats abgeschlossen. Jetzt haben wir die notwendige Wissensbasis, um ein Programm zum Erstellen einer Multisession zu schreiben. Das Schreiben eines Programms ist einfacher als das Erlernen und Entschlüsseln des ses-Formats. Ich habe das Programm an zwei Abenden abgeschlossen und mindestens eine Woche damit verbracht, das Format zu studieren. Außerdem habe ich das Programm mit zuvor verwendeten Funktionen geschrieben, insbesondere mit Dateien und Verzeichnissen. Daher war die Hauptunterstützung für das Schreiben des Programms nicht Nachschlagewerke oder das Internet, sondern meine früheren Projekte, über die ich auch auf Habré schrieb. Aus dem Internet habe ich nur eine Funktion übernommen, die den Wochentag nach Datum zurückgibt. Bevor ich jedoch den Text des Programms zitierte, beschloss ich, einige weitere Informationen zu teilen, über die ich in diesem Artikel zunächst nicht schreiben wollte.
Die Idee, aus Telefonaufzeichnungen eine Multisession zu bilden, kam mir, als ich an einer neueren Version von Adobe Audition 3.0 arbeitete, die die Audioeingabe / -ausgabe über ASIO unterstützt. Beim Speichern der Multisession stellte ich fest, dass sie in zwei Formaten gespeichert werden kann: dem üblichen klassischen SES und dem neuen XML-Format, das in früheren Versionen des Programms nicht vorhanden war. Nachdem ich die Sitzung im XML-Format gespeichert hatte, öffnete ich diese Datei sofort im Editor, wo ich eine Beschreibung einer Reihe von Parametern fand, die in einer komplexen hierarchischen Struktur miteinander verbunden waren. Um diese Hierarchie besser anzeigen zu können, habe ich das Programm WMHelp XmlPad verwendet. Abbildung 17 zeigt einen Screenshot dieses Programms mit einer darin geöffneten einfachen Multisession-Testdatei. Links ist die Dokumenthierarchie. Das aktive (ausgewählte) Element der Hierarchie ist der Längenparameter der ersten Audiodatei.in der ersten Untereinheit des Audiodateibeschreibungsblocks stehen.
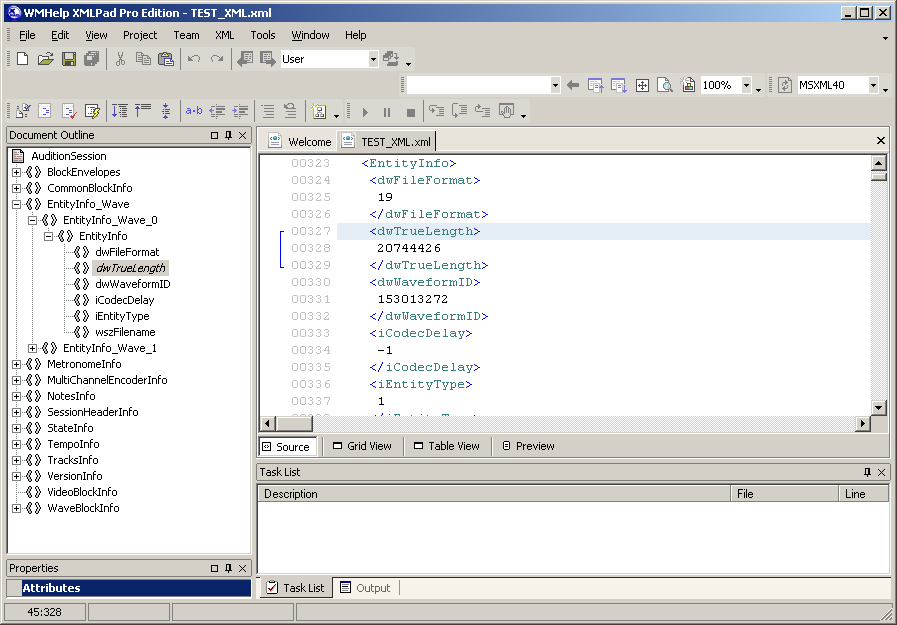
. 17. XML Adobe Audition 3.0.
Ich habe mich entschlossen, dieses spezielle Format zu studieren und in Zukunft programmgesteuert den erforderlichen XML-Text zu generieren, um die gewünschte Multisession am Ausgang zu erhalten. Es gab sogar eine Idee, Excel für diesen Zweck zu verwenden. Die Schwierigkeit bestand darin, dass etwa 95% der gesamten XML-Datei vom Trackbeschreibungsblock belegt sind. Es gibt eine riesige Anzahl von Parametern, die ich nicht ausschließen konnte, ohne die Multisession zu beeinträchtigen. Tatsache ist, dass es in dieser Version von Adobe Audition viel mehr Funktionen für Tracks gibt. Logischerweise sind diese Funktionen für meine einfache Multisession nicht erforderlich. Durch Ausschließen der entsprechenden Felder aus dem XML-Dokument wird die Sitzung jedoch nicht mehr aktiv. Und ich müsste diesen riesigen Textblock in der Beschreibung jedes Tracks für die einfachste Sitzung "ziehen". Dies ist die einzige Unannehmlichkeit beim Generieren einer Multisession-XML-Datei. Wissen,Die Multisession-Varianten, die während des Studiums von textuellem XML erhalten wurden, waren sicherlich nützlich während des Studiums der binären ses. Und selbst in XML konnte ich einige Parameter nicht entschlüsseln. Die Felder jedes Parameters haben einen abgekürzten Namen in Englisch, aber trotzdem habe ich nicht immer verstanden, was dieser Parameter ist. Die Hauptsache ist, dass ich die grundlegenden notwendigen Parameter, ihre hierarchischen Blöcke und Felder studieren und entschlüsseln konnte. Dann wurde ich lange Zeit von der Frage gequält, wie man eine solche Sitzung in einer älteren Version von Adobe Audition öffnet. Neue Versionen der Programme verfügen über eine sehr ausgefeilte Oberfläche (fast 3D), was für die Visualisierung von Multisession-ähnlichen Diagrammen sehr unpraktisch ist. Und aufgrund dieses "Drei-Te" in Adobe Audition 3.0 mit einem vollständig erweiterten Fenster auf dem FullHD-Bildschirm passen maximal (bei minimalem Maßstab) 28 Spuren. Und in Adobe Audition 1.5 würden 37 passen (Abb.18, Maßstab 1: 2). Insgesamt müssen 31 Titel auf dem Bildschirm angezeigt werden.
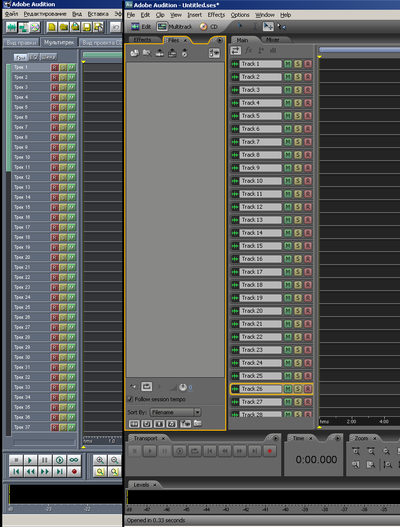
. 18. Adobe Audition .
Vor allem aber habe ich die Klangqualität beim Spielen einer Multisession mit einer Frequenz von 8000 Hz in der neuen Version des Programms beendet. Der Klang ist nicht sehr gut, es liegt eine harmonische Verzerrung vor. Dies liegt an der Tatsache, dass der Ton mit einer anderen Abtastrate (48 kHz) ausgegeben wird und ASIO nichts anderes tun kann. Die Situation ändert sich nicht, wenn Sie in den Einstellungen ein anderes Ausgabegerät "Audition 3.0 Windows Sound" auswählen. Die neue Version des Programms unterstützt keine klassischen "DirectSound" -Ausgabegeräte (ich nenne Version 3.0 neu). Abbildung 19 zeigt das Audiospektrum bei der Wiedergabe von 8-kHz-Audio (oder -Sitzungen) in Adobe Audition 3.0 mit einer harmonischen Verzerrung des invertierten Spektrums. Diese Frequenzen sind grün eingekreist, was ideal klingen sollte (und sonst nichts). Und die Frequenzen sind rot eingekreist,das sind zusätzliche Verzerrungen. Dieser Effekt ist höchstwahrscheinlich auf das Fehlen einer Filterung nach dem Upsampling-Verfahren zurückzuführen. Danach beschloss ich, das SES-Binärformat des einfacheren und angenehmeren Adobe Audition 1.5-Programms zu studieren. Ich hoffte, dass es nach dem Erlernen des "menschlichen" XML-Formats aus einer neueren Version des Programms angesichts meiner Erfahrung mit Binärdateien nicht schwierig sein würde, es herauszufinden. Und so geschah es: Ich habe das SES-Format ziemlich schnell "beworben". Und die Hauptsache ist, dass die Abwärtskompatibilität mit Blick auf die Zukunft gut funktioniert: Eine für Version 1.5 gebildete Sitzung wird in Version 3.0 erfolgreich geöffnet. Oben habe ich auf die Nachteile von Adobe Audition 3.0 in Bezug auf Klangqualität und grafische Oberfläche hingewiesen. Diese Version des Programms bietet jedoch Vorteile bei der Multisession-Navigation. Zum Beispiel,Es besteht die Möglichkeit, einen Audioclip in einer Multisession zu hören, indem Sie mit der Maus darauf klicken und dann nach rechts verschieben.
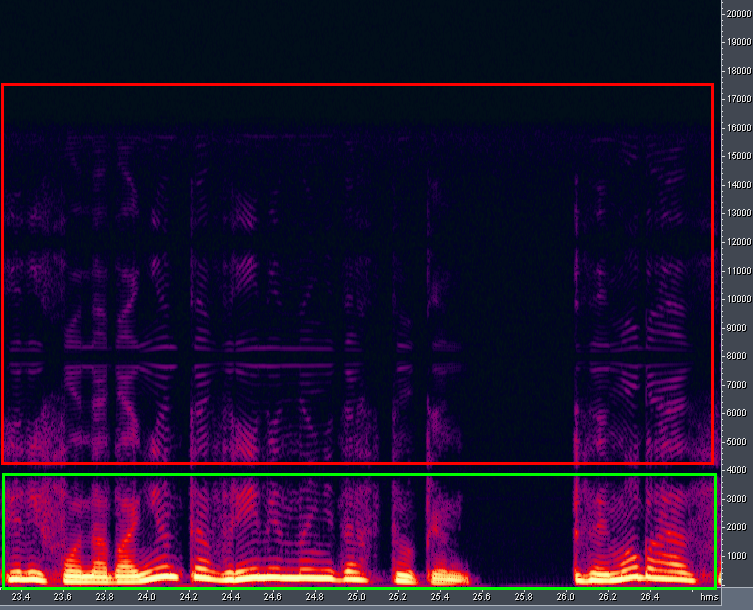
Zahl: 19. Harmonische Verzerrung während der Wiedergabe.
Jetzt werde ich den Text des Programms unter dem Spoiler geben. Das Programm verfügt natürlich nicht über eine grafische Oberfläche, da es für diese Aufgabe nicht benötigt wird. Der Programmtext enthält detaillierte Kommentare, sodass keine zusätzlichen Erläuterungen erforderlich sind. Das Programm wird über die Befehlszeile gestartet und verarbeitet innerhalb einer Sekunde eine Liste von vierhundert Dateien, die eine Multisession-Datei bilden. Innerhalb des Programms gibt es vier parametrische Variablen, mit denen Sie auf Wunsch keine Cue-Marker generieren, an Wochenenden kein "R" auf Tracks setzen, die Eigenschaft "Fix in Time" für Clips nicht festlegen und das Kriterium für das Färben von Clips (nach Anruftyp oder nach Telefonnummern) auswählen können. ... Diese drei Variablen müssten aus dem Programmtext ausgeschlossen und "herausgebracht" werden, dh in einer separaten Datei mit Programmparametern.
C Programm Quellcode
/********************************************************************
"RMC" ,
wav .
, .
yyyy-mn,
. .
(.. -),
.
, ,
"RMC" "I:".
*********************************************************************/
#include <windows.h>
#include <stdio.h>
#include <string.h>
DWORD wr; // , ;
DWORD ww; // , ;
DWORD wi; // , ;
// ( );
int Date( int D, int M, int Y ){
int a, y, m, R;
a = ( 14 - M ) / 12;
y = Y - a;
m = M + 12 * a - 2;
R = 6999 + ( D + y + y / 4 - y / 100 + y / 400 + (31 * m) / 12 );
return R % 7;
}
// ;
HANDLE openInputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_READ, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
HANDLE openOutputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_WRITE, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
void filepos(HANDLE f, __int64 p){
LONG HPos;
LONG LPos;
HPos = p>>32;
LPos = p;
SetFilePointer (f, LPos, &HPos, FILE_BEGIN);
}
// 32- ;
void write32(HANDLE f, signed long int a){
WriteFile(f, &a, 4, &ww, NULL);
}
// ;
void fill(HANDLE f, signed long int a, unsigned char c){
unsigned char i;
for(i=0;i<c;i++){
write32(f,a);
}
}
int main(){
HANDLE out; // Adobe Audition;
HANDLE stat; // "stat" (+ );
HANDLE cues; // "cues";
HANDLE lf; // "LISTFILE";
HANDLE blk; // "bk20";
char* week[7]={"", "", "", "", "", "", ""}; // -;
unsigned char dm[]={31,29,31,30,31,30,31,31,30,31,30,31}; // ;
unsigned char p_cues=1; //: (cues);
unsigned char p_R=1; //: "R" ( ) ;
unsigned char p_lock=1; //: ;
unsigned char p_color=2; // ;
unsigned char flg; // , . ;
unsigned long int lfsize=0; // "LISTFILE";
unsigned long int blksize=0; // "bk20";
unsigned long int smp; // ;
unsigned long int offset; // ;
unsigned int cfile=0; // ;
unsigned int cblk=0; // ;
char name[100]; // ( ...);
char fullname[100]; // ;
char infld[8]; // ;
char number[11]; // . ;
unsigned char len; // ;
printf("Input yyyy-dd name of folder:\n"); // ;
scanf("%s",infld); // ;
WIN32_FIND_DATA fld; // ;
HANDLE hf; // ( , );
char buf1[48],buf2[556]; // "stat" "cues";
char str[16]; // ;
unsigned long int outpos=0; // ;
unsigned char byte; // "LISTFILE" "bk20";
unsigned char i; // ;
unsigned char mn,d,dw,h,m,s; // -;
unsigned char cdm; // ;
int yy; // ;
yy=2000+(infld[2]-48)*10+(infld[3]-48); // ;
mn=(infld[5]-48)*10+(infld[6]-48); // ;
sprintf(name,"I:\\RMC\\%s.ses",infld); // ( );
out=openOutputFile(name); // ;
WriteFile(out, "COOLNESS", 8, &wi, NULL); // : ;
write32(out,0); // ( , );
WriteFile(out, "hdr ", 4, &wi, NULL); //, : ;
write32(out,936); // , 936;
write32(out,8000); // ;
write32(out,24*3600*8000); // (. 24 );
write32(out,0); // ( );
write32(out,0x00010020);
write32(out,0);
write32(out,0x3ff00000);
write32(out,0);
write32(out,0x3ff00000);
filepos(out,328); // ;
write32(out,0x20);
WriteFile(out, "", 6, &wi, NULL); // ;
filepos(out,376); // ;
write32(out,0x3ff00000);
filepos(out,892); // ;
write32(out,0x0430041c);
write32(out,0x04420441);
write32(out,0x04400435);
filepos(out,956); // ;
stat=openInputFile("stat_31_full.BLK"); // ,
ReadFile(stat, &buf1, 48, &wr, NULL); // ;
WriteFile(out, buf1, 48, &wi, NULL);
CloseHandle(stat);
if(mn==2){ // ,
if(!(yy%4)){ // ,
cdm=29; // 29 ,
}else{
cdm=28; // - 28;
}
}else{ // ,
cdm=dm[mn-1]; // ;
}
WriteFile(out, "trks", 4, &wi, NULL); // ;
write32(out,4+cdm*152); // ;
write32(out,cdm); // ;
outpos=1016; // ;
for(i=0;i<cdm;i++){ //
dw=Date(i+1,mn,yy); // ;
write32(out,0); // ses, ;
write32(out,0x3ff00000);
write32(out,0); // 8- double;
write32(out,0x3ff00000);
if((dw%7==5||dw%7==6)&&p_R){ // - , "R",
write32(out,4); // "R",
}else{
write32(out,0); // - ;
}
sprintf(str,"%02d.%02d.%i %s",i+1,mn,yy,week[dw]); // , ;
WriteFile(out, str, strlen(str), &wi, NULL);
filepos(out,1072+152*i); // (i+1)- ;
write32(out,1); // , ;
write32(out,1);
write32(out,4);
write32(out,0);
write32(out,0);
write32(out,0x40590000);
write32(out,0);
write32(out,0);
write32(out,0xffffff9d);
write32(out,0xffffff9d);
write32(out,i+1); // , ;
fill(out,0,11);
write32(out,4);
write32(out,0);
outpos+=152; // ;
}
if(p_cues){ // , "cues";
WriteFile(out, "cues", 4, &wi, NULL); // ,
write32(out,556); // - ;
cues=openInputFile("cues_24h.BLK"); // , ;
ReadFile(cues, &buf2, 556, &wr, NULL); //( , "stat");
WriteFile(out, buf2, 556, &wi, NULL);
CloseHandle(cues);
outpos+=564;
}
DeleteFile("LISTFILE"); // ( )
DeleteFile("bk20"); // "LISTFILE" "bk20",
lf=openOutputFile("LISTFILE"); // ()
blk=openOutputFile("bk20"); // ;
WriteFile(lf, "LISTFILE", 8, &wi, NULL); // ;
WriteFile(blk, "bk20", 4, &wi, NULL);
write32(lf,0);
write32(blk,0);
write32(blk,0);
write32(blk,0x48); // , ;
sprintf(name,"I:\\RMC\\%s\\*.wav",infld); // wav ;
hf=FindFirstFile(name,&fld); // ;
do{ // ;
len=strlen(fld.cFileName); // ;
for(i=10;i>=1;i--){ // 10 ;
number[10-i]=fld.cFileName[len-i-4]; // ;
}
number[10]=0; // , ;
cfile+=1; // ;
sprintf(fullname,"I:\\RMC\\%s\\%s",infld,fld.cFileName); // ;
d=(fld.cFileName[22]-48)*10+(fld.cFileName[23]-48); // () ;
h=(fld.cFileName[25]-48)*10+(fld.cFileName[26]-48); // ;
m=(fld.cFileName[27]-48)*10+(fld.cFileName[28]-48); // ;
s=(fld.cFileName[29]-48)*10+(fld.cFileName[30]-48); // ;
offset=(h*3600+m*60+s)*8000; // ;
smp=(fld.nFileSizeLow-44)/4; // ( );
WriteFile(lf, "wav ", 4, &wi, NULL); // ;
write32(lf,17+strlen(fullname)); // ( );
write32(lf,1000+cfile); // ( , 1000 );
write32(lf,0x14); // ( );
WriteFile(lf, fullname, strlen(fullname), &wi, NULL); // ( );
WriteFile(lf, "\0", 1, &wi, NULL); // ;
write32(lf,0xffffffff); //;
write32(lf,smp); // ;
lfsize+=(25+strlen(fullname)); // "LISTFILE";
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile); // ();
write32(blk,0); // ;
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,offset); // ;
if(((24*3600*8000)-offset)>smp){ // ( ) ,
write32(blk,smp); // ,
}else{
write32(blk,(24*3600*8000)-offset); // ;
}
write32(blk,0); // ;
if(p_lock){ // ,
write32(blk,0x0008000a); // (3 32 ),
}else{
write32(blk,0x00080008); // (2 32 );
} // - " ";
write32(blk,d); // ( );
fill(blk,0,4); // ;
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ;
case 'I': // "I" ( ),
write32(blk,0); // ;
break;
case 'O': // "O" ( ),
write32(blk,102); // ( );
break;
default: // - ,
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0; // ;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // - ();
if(!flg){ // ( ),
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
if(((24*3600*8000)-offset)<=smp){ // ( ) ( ),
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0); // ,
write32(blk,smp-((24*3600*8000)-offset)); // ,
write32(blk,(24*3600*8000)-offset); // , ;
if(p_lock){
write32(blk,0x0008000a);
}else{
write32(blk,0x00080008);
}
write32(blk,d+1); // () ();
fill(blk,0,4);
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ( );
case 'I': // ,
write32(blk,0); // ;
break;
case 'O': // ,
write32(blk,102); // , ;
break;
default: // - ( ),
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // ( );
if(!flg){ // ,
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
}
}while(FindNextFile(hf,&fld)); // wav ;
filepos(lf,8);
write32(lf,lfsize); // "LISTFILE", ;
filepos(blk,4);
blksize=8+72*cblk; // "bk20", ;
write32(blk,blksize); // "bk20";
write32(blk,cblk); // ;
blksize+=8; // "bk20", . ;
lfsize+=12; // "LISTFILE", . ;
CloseHandle(lf); // . ;
CloseHandle(blk); // . ;
lf=openInputFile("LISTFILE"); // . ;
do{ // , ( );
ReadFile(lf, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(lf); // . ;
blk=openInputFile("bk20"); // . ;
do{ // , ( );
ReadFile(blk, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(blk); // . ;
outpos=outpos+blksize+lfsize; // ;
filepos(out,8);
write32(out,outpos-12); // ;
filepos(out,28);
write32(out,cblk); // ;
CloseHandle(out); // ! ;
printf("c_files: %i\nc_block: %i\n",cfile,cblk); // ( );
system("PAUSE");
return 0;
}
Jetzt können Sie Screenshots der Ergebnisse anzeigen. Es wird mehrere davon geben: in verschiedenen Betrachtungsskalen, in verschiedenen Versionen des Programms und mit verschiedenen Farbkriterien. Der Katalog "2020-05" wurde bearbeitet, dh Aufzeichnungen für Mai des laufenden Jahres. Insgesamt wurden 446 Datensätze verarbeitet. Die Anzahl der Blöcke ist gleich, da beim Übergang zu einem neuen Tag keine Datensätze vorhanden sind.
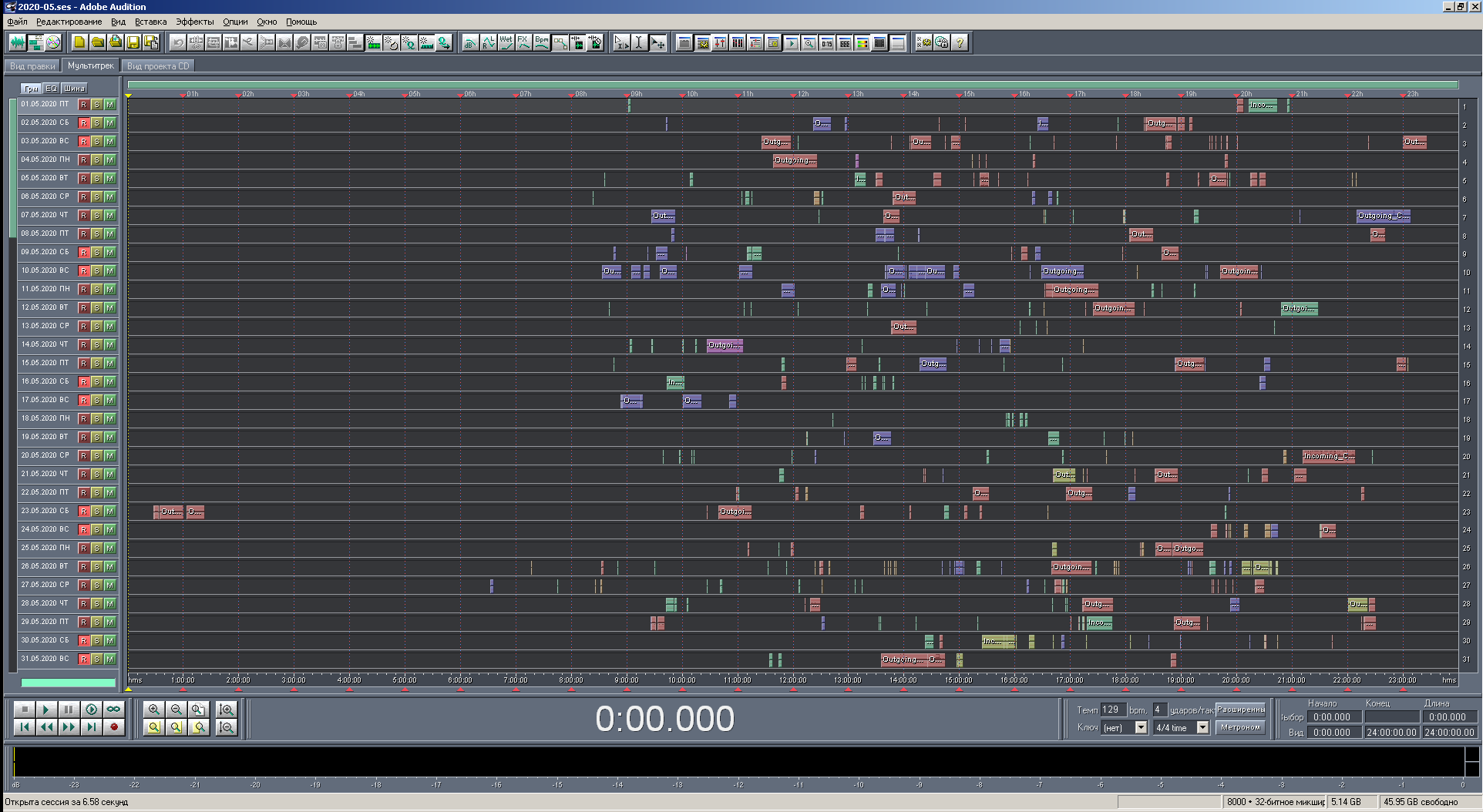
Zahl: 20. Ansicht der Multisession in Originalgröße mit telefonischer Färbung. Zahlen.
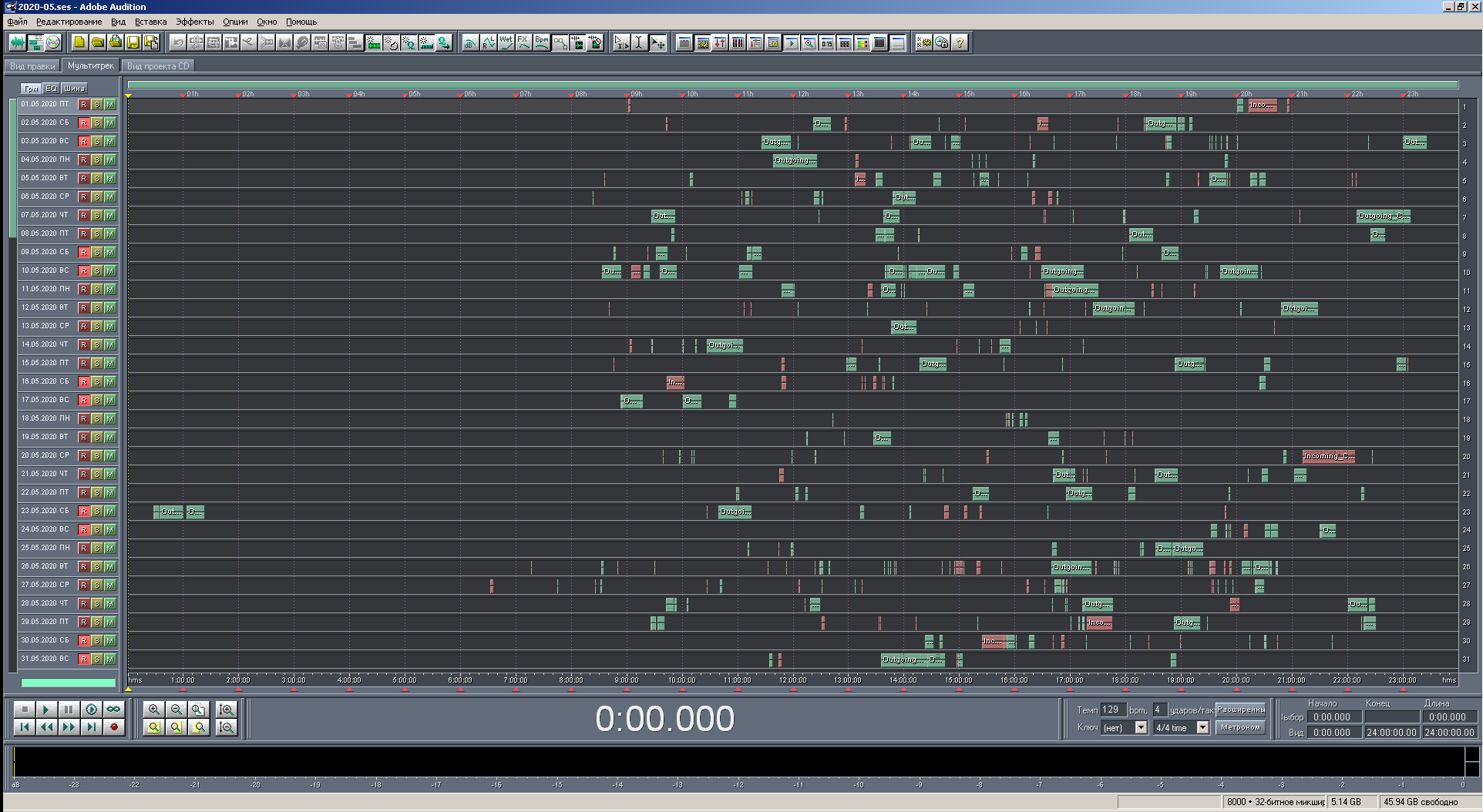
Zahl: 21. Ansicht der Multisession in Originalgröße mit Farbgebung nach Anruftyp.
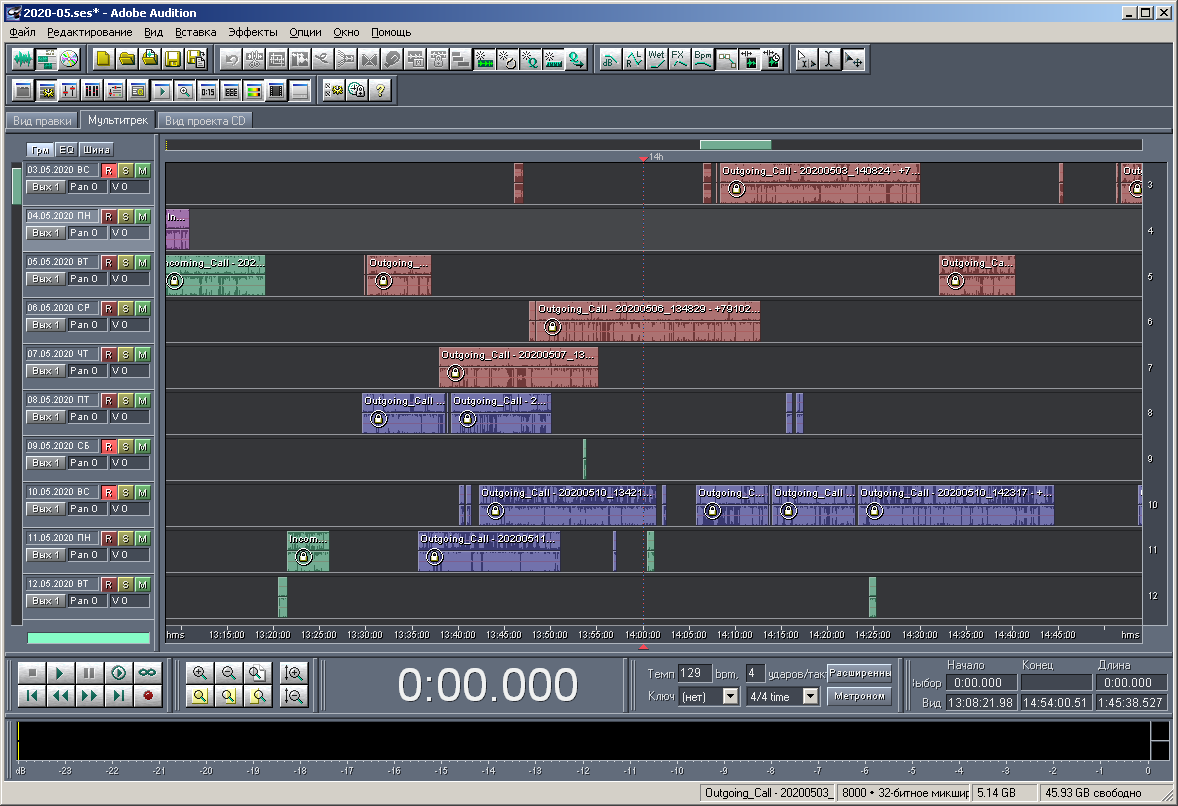
Zahl: 22. Art der Multisession im mittleren Maßstab.
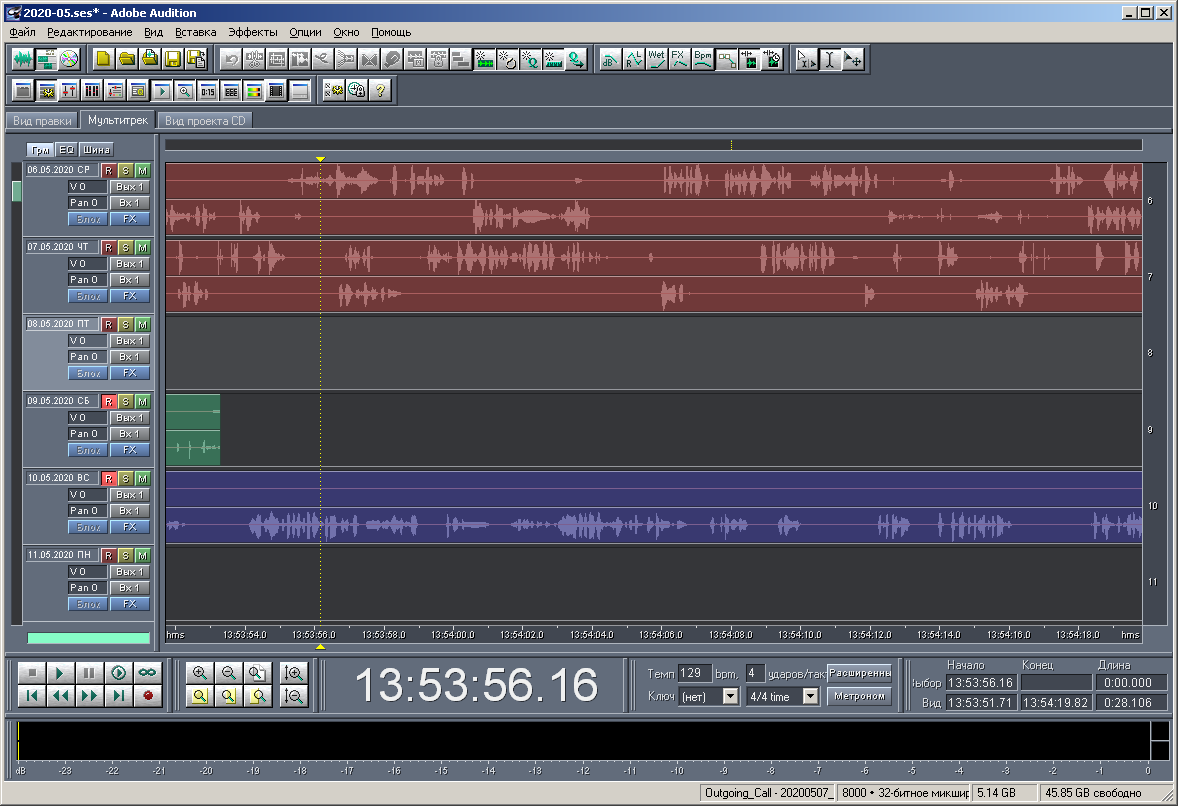
Zahl: 23. Blick auf eine Multisession in großem Maßstab.
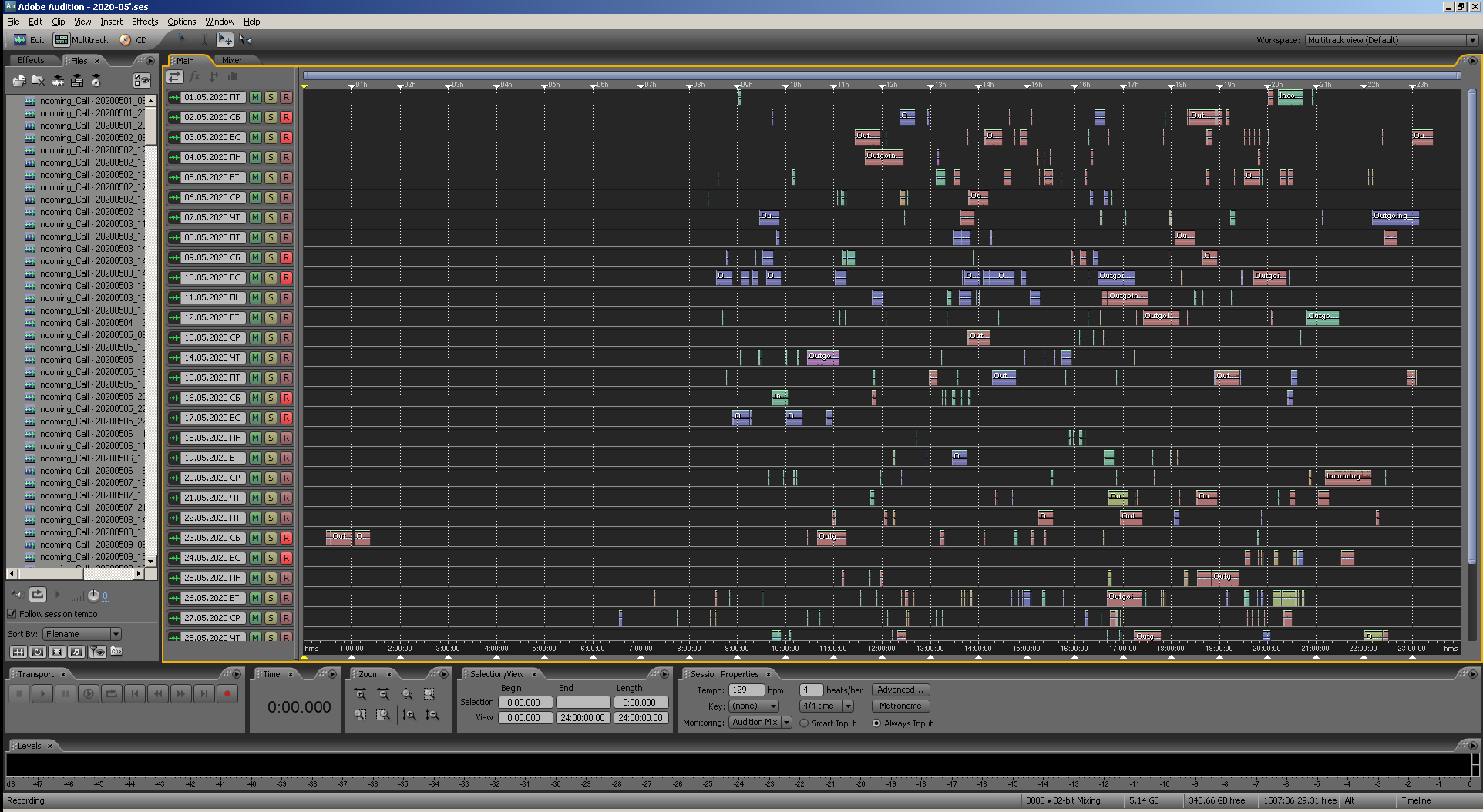
Zahl: 24. Ansicht derselben Multisession in Adobe Audition 3.0.