
Im Jahr 2020 ist maschinelles Lernen auf mobilen Plattformen nicht mehr revolutionär. Die Integration intelligenter Funktionen in Anwendungen ist zur Standardpraxis geworden.
Glücklicherweise bedeutet dies nicht, dass Apple die Entwicklung innovativer Technologien eingestellt hat.
In diesem Beitrag werde ich kurz die Neuigkeiten bezüglich der Core ML-Plattform und anderer KI- und maschineller Lerntechnologien im Apple-Ökosystem mitteilen.
Kern ML
Im vergangenen Jahr erhielt die Core ML-Plattform ein umfangreiches Update. In diesem Jahr ist alles viel bescheidener: Es wurden mehrere neue Layertypen hinzugefügt, Unterstützung für Verschlüsselungsmodelle und die Möglichkeit, Modellaktualisierungen in CloudKit zu veröffentlichen.
Es sieht so aus, als ob die Entscheidung getroffen wurde, die Versionsnummern zu löschen. Nach dem letztjährigen Update wurde die Plattform als Core ML 3 bekannt, jetzt wird der Name Core ML ohne Versionsnummer verwendet. Das coremltools-Paket wurde jedoch auf Version 4 aktualisiert.
Hinweis . Die interne Spezifikation von mlmodel ist jetzt Version 5, was bedeutet, dass in Netron neue Modelle mit dem Namen "Core ML v5" erscheinen.
Neue Layertypen in Core ML
Die folgenden Ebenen wurden hinzugefügt:
Convolution3DLayer, Pooling3DLayer, GlobalPooling3DLayer: — Vision ( Core ML - , ).OneHotLayer: .ClampedReLULayer: ReLU ( ReLU6).- ArgSortLayer: . . , GatherLayer, argsort.
CumSumLayer: .SliceBySizeLayer: In Core ML sind bereits verschiedene Arten von Split-Layern verfügbar. In dieser Ebene können Sie einen Tensor übergeben, der den Index enthält, von dem aus die Partition gestartet wird. Gleichzeitig bleibt die Sektorgröße immer fest.
Diese Arten von Ebenen können ab Version 5 verwendet werden, dh in iOS 14 und macOS 11.0 oder höher.
Eine weitere nützliche Verbesserung: 8-Bit-quantisierte Operationen für die folgenden Schichten:
InnerProductLayerBatchedMatMulLayer
In früheren Versionen von Core ML wurden Gewichte quantisiert, aber nach dem Laden des Modells wurden sie wieder in das Gleitkommaformat konvertiert. Mit der neuen Funktion
int8DynamicQuantizekönnen Gewichte als 8-Bit-Ganzzahlwerte gespeichert und tatsächliche Berechnungen auch mit Ganzzahlen durchgeführt werden.
Berechnungen mit INT8 können viel schneller sein als Gleitkommaoperationen. Dies bietet der CPU einige Vorteile, es ist jedoch ungewiss, ob sich die Leistung der GPUs verbessern wird, da Gleitkommaoperationen für sie sehr effizient sind. Möglicherweise wird in einem zukünftigen Update der Neural Engine die integrierte Unterstützung für INT8-Vorgänge implementiert (schließlich hat Apple kürzlich Xnor.ai übernommen ...).
In Bezug auf CPUs kann Core ML jetzt auch 16-Bit-Gleitkomma anstelle von 32-Bit-Gleitkommazahlen verwenden (bei A11 Bionic und höher). Wie wir im Video Explore Numerical Computing in Swift besprochen haben, ist Float16 jetzt Swifts erstklassiger Datentyp. Mit nativer Unterstützung für 16-Bit-Gleitkommaoperationen kann Core ML die Geschwindigkeit verdoppeln!
Hinweis . In Core ML wurde der Float16-Datentyp bereits auf GPUs und der Neural Engine verwendet, sodass die Unterschiede nur bei Verwendung auf der CPU erkennbar sind.
Sonstige (geringfügige) Änderungen:
UpsampleLayer. BILINEAR ( align-corners). , , .-
ReorganizeDataLayerParamsPIXEL_SHUFFLE. , . , . -
SliceStaticLayerSliceDynamicLayersqueezeMasks, . -
TileLayer, .
In Bezug auf das lokale Lernen auf Geräten scheint sich nichts zu ändern: Es werden immer noch nur vollständig verbundene und Faltungsschichten unterstützt. Die Klasse
MLParameterKeyin CoreML.framework enthält jetzt einen Konfigurationsparameter für das RMSprop- Optimierungsprogramm . Diese Erweiterung ist jedoch noch nicht in NeuralNetwork.proto enthalten . Vielleicht wird es in der nächsten Beta hinzugefügt.
Die folgenden neuen Modelltypen wurden hinzugefügt :
VisionFeaturePrint.Object- Merkmalsextraktionseinheit, die für die Objekterkennung optimiert ist.
SerializedModel... Ich weiß nicht genau, wofür das ist. Dies ist eine "private" Definition und kann "ohne vorherige Ankündigung oder Haftung geändert werden". Vielleicht bettet Apple so proprietäre Modellformate in mlmodel ein?
Modellaktualisierungen in CloudKit veröffentlichen

Mit dieser neuen Core ML-Komponente können Sie Modelle getrennt von der Anwendung aktualisieren.
Anstatt die gesamte Anwendung zu aktualisieren, können Sie die bereitgestellten Instanzen einfach mit der neuen Version des ml-Modells laden. Um ehrlich zu sein, ist diese Idee nicht neu, und einige Drittanbieter haben bereits entsprechende SDKs entwickelt. Außerdem ist es nicht schwierig, ein solches Paket selbst zu erstellen. Der Vorteil der Apple-Lösung in diesem Fall ist die Möglichkeit , Modelle in der Apple Cloud zu hosten .
Da eine Anwendung mehrere Modelle haben kann, können Sie mit dem neuen Konzept einer Modellsammlung Modelle in einem Paket kombinieren, sodass die Anwendung sie alle gleichzeitig aktualisieren kann. Solche Sammlungen können mithilfe des CloudKit-Dashboards erstellt werden.
Die Anwendung verwendet die Klasse zum Herunterladen und Verwalten von Modellaktualisierungen
MLModelCollection. Das WWDC-Video zeigt die Codefragmente, um diese Aufgabe auszuführen.
Um ein Core ML-Modell für die Bereitstellung vorzubereiten, ist die Schaltfläche Modellarchiv erstellen jetzt in Xcode verfügbar . Wenn Sie darauf klicken, wird in die .mlarchive- Datei geschrieben . Diese Version des Modells kann an das CloudKit-Dashboard gesendet und dann der Modellsammlung hinzugefügt werden (mlarchive sieht aus wie ein reguläres ZIP-Archiv mit dem Inhalt des hinzugefügten mlmodelc-Ordners).
Es ist sehr praktisch, dass Sie verschiedene Modellkollektionen für verschiedene Benutzer bereitstellen können. Die iPhone-Kamera unterscheidet sich beispielsweise von der iPad-Kamera. Daher müssen Sie möglicherweise zwei Versionen des Modells erstellen und eine an iPhone-Benutzer und die andere an iPad-Benutzer senden.
Sie können Anpassungsregeln für verschiedene Geräteklassen (iPhone, iPad, TV, Watch), verschiedene Betriebssysteme und deren Versionen, Regionalcodes, Sprachcodes und Anwendungsversionen definieren.
Es scheint keinen Mechanismus zu geben, mit dem Benutzer anhand anderer Kriterien in Gruppen eingeteilt werden können, z. B. A / B-Tests auf Modellaktualisierungen oder Optimierung für bestimmte Gerätetypen - iPhone X oder früher. Dies kann jedoch weiterhin manuell erfolgen, indem Sammlungen mit unterschiedlichen Namen erstellt und anschließend explizit angefordert werden
MLModelCollectionBereitstellung der entsprechenden Sammlung unter dem angegebenen Namen zur Laufzeit.
Die Bereitstellung einer neuen Version eines Modells ist nicht immer schnell . Irgendwann erkennt die Anwendung ein neues verfügbares Modell und lädt es automatisch und platziert es in der Testumgebung der Anwendung. Sie können jedoch nicht bestimmen, wo und wie dies geschieht: Core ML kann beispielsweise im Hintergrund heruntergeladen werden, während Sie Ihr Telefon nicht verwenden.
Aus diesem Grund wird in jedem Fall empfohlen, Ihrer App ein integriertes Modell als Ersatz hinzuzufügen - beispielsweise ein generisches Modell, das sowohl iPhone als auch iPad unterstützt.
Mit dieser praktischen Lösung können sich Benutzer keine Gedanken über Self-Hosting-Modelle machen. Beachten Sie jedoch, dass Ihre Anwendung jetzt CloudKit verwendet. Nach meinem Verständnis werden Modellsammlungen für das gesamte Speicherkontingent und Modelllasten für die Netzwerkverkehrskontingente angerechnet.
Siehe auch:
- Bereitstellen von Modellen und Sichern von Core ML (WWDC-Video)
- Erstellen und Bereitstellen einer Sammlung von Modellen
- Erweiterte Modellsammlungen abrufen
Hinweis . Die neue Update-Funktion mit CloudKit lässt sich leider nur schwer mit der Personalisierung lokaler Modelle kombinieren. Es gibt keine einfachen Möglichkeiten, das von einem personalisierten Modell gewonnene Wissen auf ein neues Modell zu übertragen oder es irgendwie zu kombinieren.
Modell verschlüsseln
Bisher konnte jeder Angreifer Ihr Core ML-Modell problemlos stehlen und in seine eigene Anwendung integrieren. Ab iOS 14 / macOS 11.0 unterstützt Core ML die automatische Ver- und Entschlüsselung von Modellen, wodurch der Zugriff von Angreifern auf Ihre mlmodelc-Ordner eingeschränkt wird. Die Verschlüsselung kann in Verbindung mit der neuen Bereitstellungsfunktion über CloudKit oder separat verwendet werden.

Xcode verschlüsselt die kompilierten Modelle ( mlmodelc ), nicht das ursprüngliche mlmodel. Das Modell wird immer auf dem Gerät des Benutzers verschlüsselt. Und nur wenn die Anwendung eine Instanz des Modells erstellt, entschlüsselt Core ML diese automatisch. Die entschlüsselte Version des Modells ist nur im Speicher vorhanden und wird nicht als Datei gespeichert.
Zunächst benötigen Sie jetzt einen Verschlüsselungsschlüssel. Die gute Nachricht ist, dass Sie diesen Schlüssel nicht selbst verwalten müssen! Die Schaltfläche Verschlüsselungsschlüssel erstellen ist jetzt im Core ML Xcode Model Viewer verfügbar(Verschlüsselungsschlüssel erstellen). Wenn Sie auf diese Schaltfläche klicken, generiert Xcode einen neuen Verschlüsselungsschlüssel und ordnet ihn Ihrem Apple-Entwicklungsteamkonto zu. Sie müssen sich nicht mit Zertifikatsignierungsanforderungen und physischen Zugriffsschlüsseln befassen.
Diese Prozedur erstellt eine neue .mlmodelkey- Datei . Der Schlüssel wird auf Apple-Servern gespeichert. Sie erhalten jedoch auch eine lokale Kopie, um die Modelle in Xcode zu verschlüsseln. Sie müssen diesen Verschlüsselungsschlüssel nicht in die Anwendung einbetten, zumal Sie dies nicht sollten!
Um ein Core ML-Modell zu verschlüsseln, können Sie ein Compiler-Flag
--encrypt YourModel.mlmodelkeyfür dieses Modell hinzufügen . Wenn Sie das Modell mit CloudKit bereitstellen möchten, müssen Sie beim Erstellen des Modellarchivs den Verschlüsselungsschlüssel angeben.
Um das Modell zu entschlüsseln, nachdem die Anwendung es instanziiert hat, muss Core ML den Verschlüsselungsschlüssel von den Apple-Servern über das Netzwerk abrufen. Dies erfordert natürlich eine Netzwerkverbindung. Core ML führt diesen Vorgang nur aus, wenn Sie das Modell zum ersten Mal verwenden.
Wenn keine Netzwerkverbindung besteht und der Verschlüsselungsschlüssel noch nicht geladen wurde, kann die Anwendung das Core ML-Modell nicht instanziieren. Aus diesem Grund wird empfohlen, die neue Funktion zu verwenden
YourModel.load(). Es enthält einen endgültigen Handler, mit dem Sie auf Downloadfehler reagieren können. Der Fehlercode modelKeyFetchbesagt beispielsweise, dass Core ML den Verschlüsselungsschlüssel nicht von Apple-Servern herunterladen konnte.
Dies ist eine sehr nützliche Funktion, wenn Sie sich Sorgen machen, dass jemand Ihre patentierte Technologie stiehlt. Außerdem ist es einfach, sich in Ihre Anwendung zu integrieren.
Siehe auch:
- Bereitstellen von Modellen und Sichern von Core ML (WWDC-Video)
- Generieren eines Modellverschlüsselungsschlüssels
- Verschlüsselung des Modells in der Anwendung
Hinweis . Gemäß den Informationen in diesem Beitrag im Entwicklerforum unterstützen verschlüsselte Modelle keine lokale Personalisierung. Klingt vernünftig.
CoreML.framework
Die iOS-API für die Arbeit mit Core ML-Modellen hat sich nicht wesentlich geändert. Und dennoch möchte ich einige interessante Punkte erwähnen.
Die einzige neue Klasse hier ist
MLModelCollectioneine, die mit CloudKit bereitgestellt werden soll.
Wie Sie bereits wissen, generiert Xcode beim Hinzufügen einer mlmodel-Datei zu Ihrem Projekt automatisch eine Swift- oder Objective-C-Quelldatei, die Klassen enthält, um die Arbeit mit dem Modell zu vereinfachen. Sie können einige Änderungen in diesen generierten Klassen feststellen:
-
init(). ,let model = YourModel().YourModel(configuration:)YourModel.load(), (, ). - ,
CVPixelBufferYourModelInput,CGImageURL-, PNG- JPG-, . ,cropAndScalecropRect. , , .
In der MLModel-Dokumentation gibt es eine neue Warnung:
Verwenden Sie eine MLModel-Instanz nur in einem Thread oder einer Sendewarteschlange. Zu diesem Zweck können Sie Methodenaufrufe für das Modell serialisieren oder für jeden Thread und jede Versandwarteschlange eine separate Instanz des Modells erstellen.
Oh es tut mir leid. Es schien mir, dass im MLModel eine sequentielle Warteschlange verwendet wurde, um Anfragen zu verarbeiten, aber ich könnte mich irren - oder etwas geändert. In jedem Fall ist es am besten, sich in Zukunft an diese Empfehlung zu halten.
Der
MLMultiArrayimplementierte neue Initialisiererinit(concatenating:axis:dataType:)Hiermit wird ein neues Multi-Array erstellt, indem mehrere vorhandene Multi-Arrays kombiniert werden. Sie müssen alle dieselbe Form haben, mit Ausnahme der angegebenen Achse, entlang der die Vereinigung durchgeführt wird. Es sieht so aus, als ob diese Funktion speziell für Vorhersagen aus Videodaten hinzugefügt wurde, wie in den neuen Aktionsklassifizierungsmodellen in Create ML. Bequem!
Hinweis . Die Aufzählung
MLMultiArrayDataTypeenthält jetzt statische Eigenschaften .floatund .float64. Ich weiß nicht genau, wofür sie sind, weil diese Aufzählung bereits Eigenschaften .float32und hat .double. Beta-Fehler?
Xcode Model Viewer
Xcode zeigt jetzt viel mehr Informationen zu Modellen an, z. B. Klassenbeschriftungen und hinzugefügte benutzerdefinierte Metadaten. Außerdem werden Statistiken zu den Layertypen im Modell angezeigt.
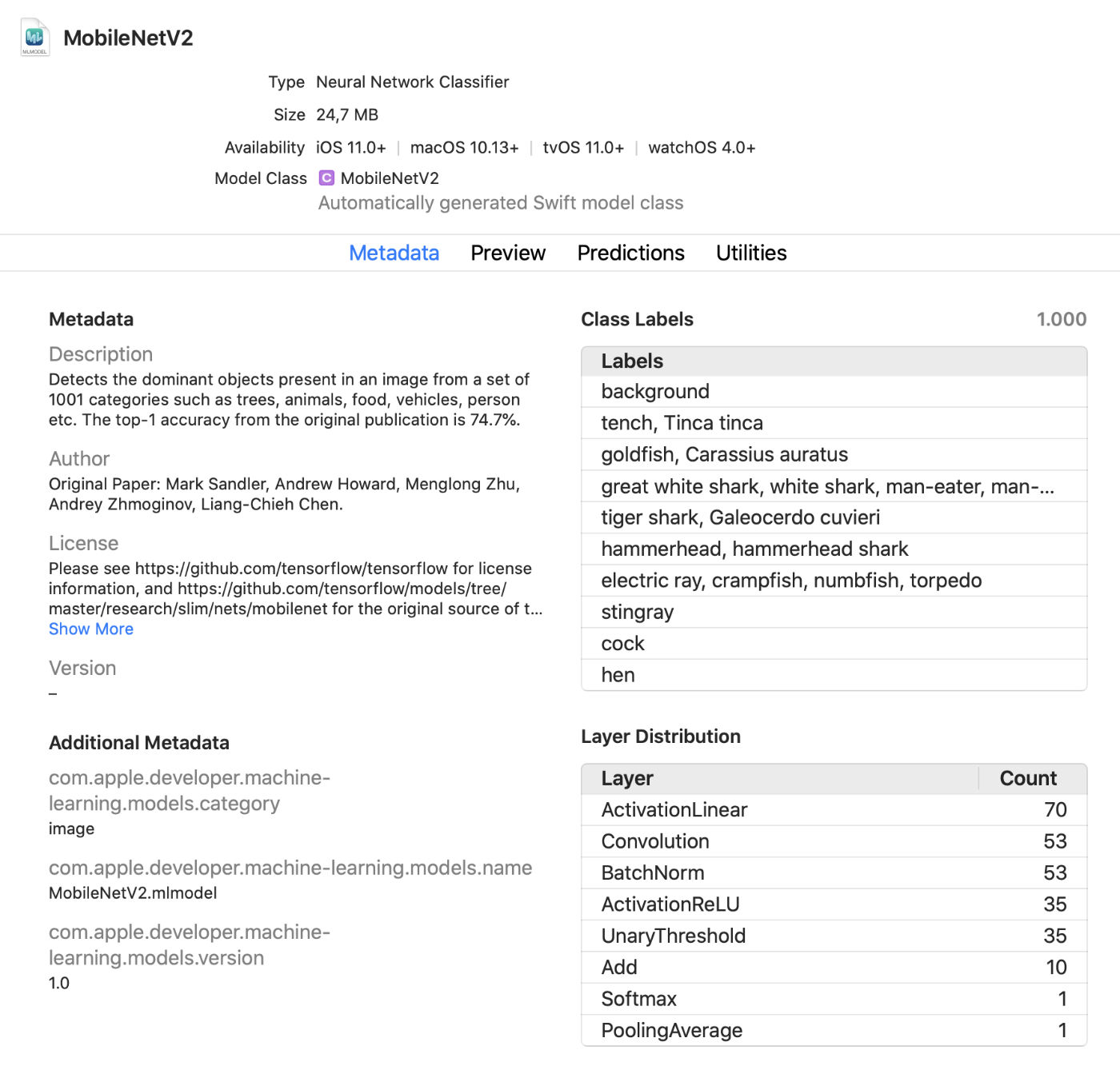
Dies ist ein praktischer Live-Viewer , mit dem Sie im Testmodus Änderungen am Modell vornehmen können, ohne die Anwendung auszuführen. Sie können Bilder, Videos oder Text in dieses Vorschaufenster ziehen und Modellvorhersagen sofort anzeigen. Tolles Update!
Darüber hinaus können Sie jetzt Core ML-Modelle in einer interaktiven Umgebung verwenden . Xcode generiert hierfür automatisch eine Klasse, die Sie normal verwenden können. Dies ist eine weitere Möglichkeit, Modelle interaktiv zu testen, bevor sie der Anwendung hinzugefügt werden.
coremltools 4
Während es praktisch ist, mit Create ML eigene Modelle für einfache Projekte zu erstellen, werden TensorFlow und PyTorch viel häufiger für Schulungen verwendet. Um ein solches Modell in Core ML zu verwenden, müssen Sie es zuerst in das mlmodel-Format konvertieren. Dafür wird die coremltools-Toolbox verwendet.
Tolle Neuigkeiten: Die Dokumentation ist viel besser . Ich empfehle Ihnen, sich damit vertraut zu machen. Hoffentlich wird das Benutzerhandbuch regelmäßig aktualisiert, da die Dokumentation in der Vergangenheit nicht immer auf dem neuesten Stand war.
Hinweis . Leider sind die Beispiel-Jupyter-Notebooks weg. Sie sind jetzt im Benutzerhandbuch enthalten, jedoch nicht als Notizbücher.
Die Art und Weise, Modelle zu transformieren, hat sich dramatisch verändert... Bisher verwendete neuronale Netzwerkkonverter sind veraltet und wurden durch neuere und flexiblere Versionen ersetzt.
Es gibt heute drei Arten von Konvertern:
- Moderne Konverter für TensorFlow (1.x und 2.x), tf.keras und PyTorch. Alle diese Konverter basieren auf denselben Technologien und verwenden die sogenannte Intermediate Model Language (MIL). Sie müssen für solche Modelle nicht mehr tfcoreml oder onnx-coreml verwenden.
- Alte Konverter für neuronale Netze von Keras 1.x, Caffe und ONNX. Für jeden von ihnen ist ein spezieller Konverter vorgesehen. Ihre weitere Entwicklung wurde eingestellt, und für die Zukunft sind nur Korrekturen geplant. Es wird nicht mehr empfohlen, ONNX zum Konvertieren von PyTorch-Modellen zu verwenden.
- Konverter für nicht-neuronale Netzwerkmodelle wie Scikit-Learn und XGBoost.
Eine neue einheitliche Konvertierungs-API wird verwendet, um TensorFlow 1.x-, 2.x-, PyTorch- oder tf.keras-Modelle zu transformieren . Es wird wie folgt angewendet:
import coremltools as ct
class_labels = [ "cat", "dog" ]
image_input = ct.ImageType(shape=(1, 224, 224, 3),
bias=[-1, -1, -1],
scale=2/255.)
model = ct.convert(
keras_model,
inputs=[ image_input ],
classifier_config=ct.ClassifierConfig(class_labels)
)
model.save("YourModel.mlmodel")
Die Funktion
ct.convert()überprüft die Modelldatei auf ihr Format und wählt dann automatisch den entsprechenden Konverter aus. Die Argumente unterscheiden sich geringfügig von den zuvor verwendeten: Vorverarbeitungsargumente werden mithilfe eines Objekts übergeben ImageType, Klassifikatorbezeichnungen werden mithilfe eines Objekts übergeben ClassifierConfigusw.
Die neue Transformations-API konvertiert das Modell in eine Zwischendarstellung - die sogenannte. MIL . Derzeit sind Konverter verfügbar, um TensorFlow 1.x in MIL, TensorFlow 2.x in MIL (einschließlich tf.keras) und PyTorch in MIL zu konvertieren. Wenn die neue Deep-Learning-Plattform an Popularität gewinnt, erhält sie einen eigenen Konverter für MIL.

Nach der Konvertierung des Modells in das MIL-Format kann es nach allgemeinen Regeln optimiert werden, z. B. unnötige Operationen entfernen oder mehrere verschiedene Ebenen kombinieren. Das Modell wird dann von MIL in das mlmodel-Format konvertiert.
Ich habe das alles noch nicht im Detail untersucht, aber der neue Ansatz gibt mir Hoffnung, dass coremtools 4 effizientere mlmodel-Dateien als zuvor erstellen kann - insbesondere für TF 2.x-Diagramme.
In MIL gefällt mir besonders die Fähigkeit des Konverters, Ebenen zu verarbeiten , die er noch nicht analysiert hat . Wenn Ihr Modell eine Ebene enthält, die in Core ML nicht direkt unterstützt wird, müssen Sie sie möglicherweise in einfachere MIL-Operationen wie Matrixmultiplikation oder andere arithmetische Operationen unterteilen.
Danach kann der Konverter die sogenannten "zusammengesetzten Operationen" für alle Schichten dieses Typs verwenden. Dies ist viel einfacher als das Hinzufügen nicht unterstützter Operationen mit benutzerdefinierten Ebenen, obwohl dies möglich ist. Die Dokumentation bietet ein gutes Beispiel für die Verwendung solcher zusammengesetzten Operationen.
Siehe auch:
Andere Apple-Plattformen mit maschinellem Lernen
Mehrere andere übergeordnete Frameworks in den iOS- und MacOS-SDKs werden ebenfalls für maschinelle Lernaufgaben verwendet. Mal sehen, was es Neues in diesem Bereich gibt.
Vision
Die Vision Computer Vision-Plattform hat eine Reihe neuer Funktionen erhalten.
Die Vision-Plattform hat bereits Modelle zur Erkennung von Gesichtern, Besonderheiten und menschlichen Körpern verwendet. Die neue Version fügt die folgenden Funktionen:
Handpositionserkennung (
VNDetectHumanHandPoseRequest) Mehrere Person Pose
Erkennung ( ) Es ist toll , dass Apple Pose Erkennungsfunktionen im Betriebssystem enthalten ist. Mehrere Open-Source-Modelle unterstützen diese Funktion, sind jedoch bei weitem nicht so effizient oder schnell. Kommerzielle Lösungen sind teuer. Hochwertige Tools zur Posenerkennung sind jetzt kostenlos verfügbar! Im Gegensatz zum Betrachten statischer Bilder wird jetzt mehr Aufmerksamkeit geschenkt
VNDetectHumanBodyPoseRequest
Erkennung von Objekten auf Videoaufzeichnungen sowohl offline als auch in Echtzeit. Zur Vereinfachung können Sie Objekte
CMSampleBuffermithilfe von Anforderungshandlern direkt von der Kamera aus verwenden.
Außerdem wurde
VNImageBasedRequestder Klasse eine Unterklasse hinzugefügt VNStatefulRequest, die für die sofortige Bestätigung der Entdeckung des gewünschten Objekts verantwortlich ist. Im Gegensatz zur Standardklasse wird VNImageBasedRequesteine statusbehaftete Abfrage verwendet, die mehrere Frames umfasst. Diese Anforderung führt eine Analyse alle N Frames des Videos durch.
Nachdem das Suchobjekt gefunden wurde, wird der letzte Handler aufgerufen, der das Objekt enthält
VNObservation, das nun eine Eigenschaft hat timeRange, die die Start- und Stoppzeit der Beobachtung im Video angibt.
Die Klasse wird
VNStatefulRequestnicht direkt verwendet . Es ist eine abstrakte Basisklasse und wird derzeit nur durch Abfragen VNDetectTrajectoriesRequestzur Pfaderkennung untergeordnet. Dies ermöglicht die Erkennung von Formen, die sich entlang eines parabolischen Pfades bewegen, z. B. beim Werfen oder Treten eines Balls (dies scheint derzeit die einzige integrierte Videoaufgabe zu sein).
Für die Offline-Videoanalyse können Sie verwenden.
VNVideoProcessor.Dieses Objekt fügt einem lokalen Video eine URL hinzu und stellt alle N Frames oder N Sekunden eine oder mehrere Vision-Anforderungen.
Eine der wichtigsten traditionellen Computer-Vision-Techniken zur Analyse von Videoaufzeichnungen ist der optische Fluss... In Vision ist jetzt eine Abfrage verfügbar
VNGenerateOpticalFlowRequest, die die Richtung berechnet, in die sich jedes Pixel von einem Bild zum anderen bewegt (dichter optischer Fluss). Als Ergebnis wird ein Objekt erstellt, VNPixelBufferObservationdas ein neues Bild enthält, in dem jedes Pixel zwei 32-Bit- oder 16-Bit-Gleitkommawerten entspricht.
Darüber hinaus wurde eine neue Abfrage hinzugefügt
VNDetectContoursRequest, um die Umrisse von Objekten in einem Bild zu erkennen. Solche Pfade werden als Vektorpfade zurückgegeben. VNGeometryUtilsbietet Hilfswerkzeuge zur Weiterverarbeitung erkannter Konturen, z. B. zur Vereinfachung auf geometrische Grundformen.
Die letzte Innovation in Vision ist eine neue Version des integrierten Feature-Extraktors VisionFeaturePrint. IOS hat den Block bereits implementiertVisionFeaturePrint.Scene , das besonders nützlich ist, um Bildklassifizierer zu erstellen. Darüber hinaus ist jetzt ein neues VisionFeaturePrint.Object-Modell verfügbar, das für die Hervorhebung von Funktionen optimiert ist, die bei der Objekterkennung verwendet werden.
Dieses Modell unterstützt 299 x 299 Eingabebilder und gibt zwei Multi-Arrays der Form (288, 35, 35) bzw. (768, 17, 17) zurück. Dies ist noch kein klares einschränkendes Framework, sondern nur "rohe" Funktionen. Für eine vollständige Objekterkennung müssen Sie eine Logik hinzufügen, die diese Features in Begrenzungsrahmen und Klassenbeschriftungen konvertiert. ML erstellen führt diese Aufgabe aus, wenn Sie ein Objekterkennungswerkzeug mithilfe der Trainingsübertragung trainieren.
Siehe auch:
- Entdecken Sie Computer Vision APIs (WWDC-Video)
- Körper- und Handhaltung mit Vision erkennen (WWDC-Video)
- Entdecken Sie die Action & Vision App (WWDC Video)
Verarbeitung natürlicher Sprache
Für Aufgaben zur Verarbeitung natürlicher Sprache können Sie die Plattform für natürliche Sprache verwenden. Sie nutzt aktiv die in Create ML trainierten Modelle.
In diesem Jahr wurden nur sehr wenige neue Funktionen hinzugefügt:
NLTaggerundNLModeljetzt finden Sie mehrere Tags und sagen deren Gültigkeit voraus. Bisher wurde die Gültigkeit eines Tags nur durch die Anzahl der erzielten Punkte bestimmt.- Sätze einfügen. Das Einfügen von Wörtern hätte früher verwendet werden können,
NLEmbeddingunterstützt jetzt aber ganze Sätze.
Beim Einfügen von Sätzen wird ein eingebautes neuronales Netzwerk verwendet, um den gesamten Satz in einen 512-dimensionalen Vektor zu codieren. Auf diese Weise können Sie den Kontext abrufen, in dem Wörter in einem Satz verwendet werden (das Einfügen von Wörtern unterstützt diese Funktion nicht).
Siehe auch:
- Machen Sie Apps mit Natural Language intelligenter (WWDC-Video)
Analyse von Sprache und Lauten
In diesem Bereich gab es keine Änderungen.
Modelltraining
Zugmodelle mit Apple APIs wurden erstmals in iOS 11.3 und auf der Metal Performance Shaders-Plattform verfügbar. In den letzten Jahren wurden viele neue Trainings-APIs hinzugefügt, und dieses Jahr war keine Ausnahme: Nach meinen Berechnungen haben wir jetzt bis zu 7 verschiedene APIs zum Trainieren neuronaler Netze auf iOS- und macOS-Plattformen!
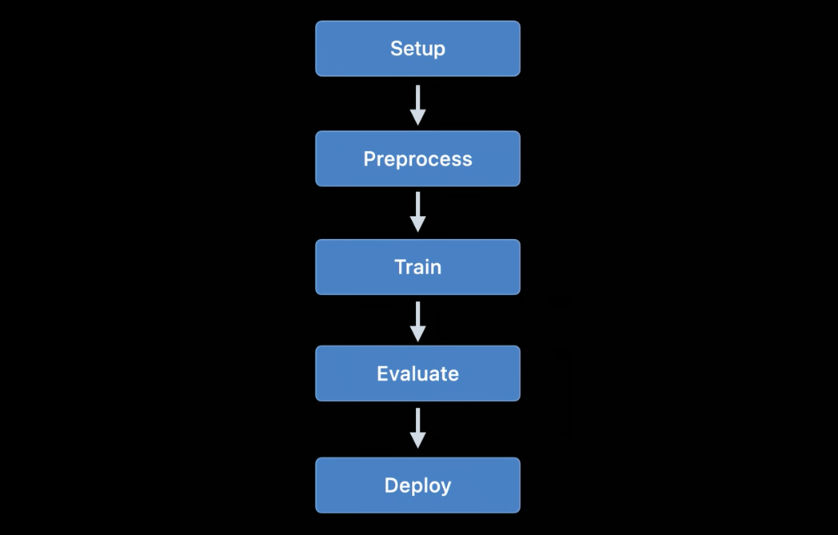
Derzeit können die folgenden Apple-APIs verwendet werden, um Modelle für maschinelles Lernen - insbesondere neuronale Netze - unter iOS und macOS zu trainieren:
- Lokales Lernen in Core ML.
- ML erstellen : Diese Schnittstelle ist Ihnen möglicherweise als Anwendung bekannt, sie ist jedoch auch eine Plattform, die unter macOS verfügbar ist.
- Metal Performance Shaders : API für Inferenz und Training auf einer GPU. Tatsächlich sind dies zwei verschiedene APIs, die ziemlich schwierig zu verwenden sind, wenn Sie Metal noch nicht kennen. Darüber hinaus ist ein neues Metal Performance Shaders Graph-Framework verfügbar, das diese älteren APIs zu ersetzen scheint.
- BNNS : Teil der Accelerate-Plattform. Bisher waren in BNNS nur Inferenzroutinen verfügbar, aber in diesem Jahr wurde auch Schulungsunterstützung hinzugefügt.
- ML Compute : Eine grundlegend neue Plattform, die sehr vielversprechend aussieht.
- Turi Create : Dies ist eigentlich die Python-Version von Create ML. Vor kurzem haben die Entwickler dies vergessen, obwohl die Plattformunterstützung noch nicht beendet wurde.
Schauen wir uns die Innovationen in diesen APIs genauer an.
Lokales Lernen in Core ML
Tatsächlich gibt es hier keine wesentlichen Änderungen. Update-Unterstützung hätte für mehrere weitere Layertypen hinzugefügt werden können, aber ich habe noch keine Dokumentation dazu gesehen.
Eine der wichtigsten Innovationen, die in einer zukünftigen Beta zu erwarten sind, ist der RMSprop-Optimierer. Es ist nicht in der aktuellen Beta-Version enthalten.
ML erstellen
Die Create ML-Plattform war ursprünglich nur für macOS verfügbar. Es kann auf dem Swift Playground ausgeführt werden, sodass Modelle mit nur wenigen Codezeilen trainiert werden können.

Letztes Jahr wurde Create ML in eine relativ begrenzte Anwendung umgewandelt, und ich freue mich über signifikante Verbesserungen in diesem Jahr. Trotzdem bleibt Create ML eine Plattform, die weiterhin vom Code-Behind aus verwendet werden kann. Tatsächlich ist die Anwendung nur eine praktische grafische Oberfläche für die Arbeit mit der Plattform.
In der vorherigen Version von Create ML konnten Sie ein Modell nur einmal trainieren. Um etwas zu ändern, musste man es von Grund auf neu trainieren, was viel Zeit in Anspruch nahm.
Die neue Version von Xcode 12 erlaubtUnterbrechen Sie das Training und setzen Sie es zu einem späteren Zeitpunkt fort , speichern Sie Modellprüfpunkte (Schnappschüsse) und zeigen Sie vorläufige Modelltrainingsergebnisse an. Wir verfügen jetzt über wesentlich mehr Tools zur Verwaltung des Lernprozesses. Mit diesem Update ist Create ML wirklich nützlich!
Auf der CreateML.framework-Plattform sind auch neue APIs zum Einrichten von Schulungen, zum Behandeln von Modell-Haltepunkten und mehr verfügbar. Ich nehme an, die meisten Benutzer verwenden nur die Create ML-Anwendung, aber es ist immer noch schön zu sehen, dass diese Funktion jetzt auf der Plattform verfügbar ist.
Neue Funktionen zum Erstellen von ML (sowohl auf der Plattform als auch in der App):
- Übertragen eines Stils für Bilder und Videos
- Klassifizierung menschlicher Handlungen in Videoaufnahmen
Schauen wir uns das neue Aktionsklassifizierungsmodell genauer an. Es verwendet das auf der Vision-Plattform verfügbare Haltungserkennungsmodell. Der Aktionsklassifizierer ist ein neuronales Netzwerk, das die Form (
window_size, 3, 18) als Eingabe annimmt, wobei der erste Wert die Dauer des Videofragments darstellt, angegeben in der Anzahl der Bilder (normalerweise werden Fragmente von etwa 2 Sekunden verwendet), und (3, 18) die Schlüsselpunkte der Pose darstellen.
Anstatt Schichten zu wiederholen, verwendet das neuronale Netzwerk eindimensionale Faltungen. Dies ist höchstwahrscheinlich eine Variation eines Space Time Graph Convolutional Network (STGCN) - einer Art Modell, das speziell für die Vorhersage von Zeitreihen entwickelt wurde. Diese Details sollten Sie bei der Verwendung solcher Modelle in einer Anwendung nicht beunruhigen. Ich möchte jedoch immer wissen, wie das alles funktioniert.
Bei den Objekterkennungsmodellen können Sie das gesamte Netzwerk basierend auf TinyYOLOv2 trainieren oder den neuen Trainingsübertragungsmodus verwenden, der die neue Funktionsextraktionseinheit VisionFeaturePrint.Object verwendet . Der Rest des Modells ähnelt immer noch YOLO und SSD. Dank der Übertragung ist das Training jedoch viel schneller als das Training des gesamten YOLO-basierten Modells.
Siehe auch:
- Erstellen Sie einen Aktionsklassifizierer mit Create ML (WWDC-Video)
- Erstellen Sie Bild- und Videostil-Übertragungsmodelle in Create ML (WWDC-Video).
- Control training in Create ML with Swift ( Create ML Swift) ( WWDC)
Metal Performance Shaders
Metal Performance Shaders (MPS) ist eine Plattform, die auf den Performance-Computing-Kernen von Metal basiert, die hauptsächlich für die Bildverarbeitung verwendet wird, aber seit 2016 auch Unterstützung für neuronale Netze bietet. Ich habe schon viel darüber gebloggt.
Heutzutage werden die meisten Benutzer Core ML anstelle von MPS wählen. Natürlich nutzt Core ML immer noch die Leistung von MPS, wenn Modelle auf der GPU ausgeführt werden. MPS kann jedoch auch direkt verwendet werden, insbesondere wenn der Benutzer eine eigene Schulung durchführen möchte (übrigens ist jetzt eine neue Plattform ML Compute verfügbar, deren Verwendung anstelle von MPS empfohlen wird. Die Beschreibung finden Sie unten).
In diesem Jahr wurden MPSCNN nur wenige neue Funktionen hinzugefügt, aber einige vorhandene wurden verbessert.
Neue Klassen hinzugefügt
MPSImageCannyfür die Kantenerkennung und MPSImageEDLines für die Liniensegmenterkennung. Sie sind sehr nützlich, wenn Sie an Problemen mit der Bildverarbeitung arbeiten.
Eine Reihe weiterer Änderungen sind ebenfalls erwähnenswert:
- Es wurde eine
MPSCNNConvolutionDataSourceneue Eigenschaft hinzugefügtkernelWeightsDataType, mit der Sie einen anderen Datentyp für die Gewichtungskoeffizienten als den für die Faltung verwendeten verwenden können. Interessanterweise können die Gewichte nicht vom Datentyp INT8 sein, obwohl Core ML die Verwendung dieses Datentyps für einzelne Ebenen zulässt. - Wenn
kernelWeightsDataTypezurückgegeben wird.float32, werden Faltungsschichten und vollständig verbundene Schichten unter Verwendung von 32-Bit-Gleitkomma anstelle von 16-Bit ausgeführt. Bisher wurde nur 16-Bit unterstützt. - Verlustfunktionen können jetzt einen Parameter verwenden
reduceAcrossBatch.
Sie können MPSCNN weiterhin verwenden, wenn Metal Sie nicht erschreckt. Jetzt ist jedoch eine neue Plattform verfügbar, die die Erstellung und Ausführung solcher Diagramme erheblich vereinfacht: MPS-Diagramm.
Hinweis . Das WWDC-Video besagt, dass MPSNDArray eine neue API ist, die jedoch letztes Jahr veröffentlicht wurde. Es ist eine viel flexiblere Datenstruktur als MPSImage, da nicht alle Tensoren in Ihrem Modell Bilder sein können.
Neu: Metal Performance Shaders Graph

Eine API ist in MPS seit langem verfügbar
MPSNNGraph, aber solche Diagramme beschreiben tatsächlich nur neuronale Netze. Es müssen jedoch nicht alle Graphen neuronale Netze sein, und in diesem Fall ist die Metal Performance Shaders Graph-Plattform nützlich.
Diese neue Plattform kann zum Erstellen von GPU-Berechnungsdiagrammen für allgemeine Zwecke verwendet werden. Die MPS Graph-Plattform ist nicht von Metal Performance Shaders abhängig, obwohl sie auf dieser Basis erstellt wurde.
In der vorherigen Version der veralteten API
MPSNNGraphkonnten dem Diagramm keine benutzerdefinierten Operationen hinzugefügt werden. Die neue Plattform ist in dieser Hinsicht viel flexibler. Sie können jedoch keine eigenen Metallkerne hinzufügen. Sie müssen alle Berechnungen mit den vorhandenen Grundelementen ausdrücken.
Zum Glück der Compiler
MPSGraphunterstützt die Integration solcher Grundelemente in einen einzigen Rechenkern, wodurch die effizienteste Arbeit am Grafikprozessor sichergestellt wird. Dieses Schema funktioniert jedoch nicht, wenn es unmöglich oder schwierig ist, die bereitgestellten Grundelemente für eine Operation zu verwenden. Ich verstehe nur nicht, warum Apple beim Erstellen einer neuen API wie dieser niemals vollständige benutzerdefinierte Funktionen zulässt! Aber nichts kann getan werden.
Die neue Plattform
MPSGraphist eine ziemlich einfache und logische Struktur, die die Beziehung zwischen Operationen in einer Menge unter MPSGraphOperationsVerwendung von Tensoren beschreibtMPSGraphTensorsmit den Ergebnissen der Operationen. Darüber hinaus können Sie Steuerelementabhängigkeiten definieren, um zu erzwingen, dass einzelne Knoten vor anderen gestartet werden. Nach der Konfiguration des Diagramms muss es ausgeführt oder in den Befehlspuffer übertragen werden und dann auf das Ergebnis warten.
MPSGraphbietet eine ganze Reihe von Instanzmethoden, mit denen Sie dem Diagramm beliebige mathematische oder neuronale Netzwerkoperationen hinzufügen können.
Darüber hinaus wird das Training unterstützt, bei dem dem Diagramm eine Verlustverarbeitungsoperation hinzugefügt und anschließend die Gradientenoperationen für alle Ebenen in umgekehrter Reihenfolge ausgeführt werden - wie in der alten
MPSNNGraph. Zur Vereinfachung steht auch ein automatischer Differenzierungsmodus zur Verfügung, in dem MPSGraphautomatisch Gradientenoperationen für das Diagramm ausgeführt werden. Das spart viel Aufwand.
Ich finde es toll, dass es jetzt eine neue, einfache und unkomplizierte API zum Erstellen solcher Berechnungsgraphen gibt. Es ist viel einfacher zu bedienen als frühere Versionen. Und Sie müssen kein Metal-Experte sein, um damit zu arbeiten. Übrigens ähnelt es TensorFlow 1.x-Diagrammen, hat jedoch einen großen Vorteil in Bezug auf die Optimierung, wodurch Sie die Kosten minimieren können. Dennoch gibt es nicht genügend Möglichkeiten, dem Diagramm beliebige Rechenkerne hinzuzufügen.
Siehe auch:
- Erstellen Sie angepasste ML-Modelle mit dem Metal Performance Shaders Graph (WWDC-Video).
- Hinzufügen von benutzerdefinierten Funktionen zum Shader-Diagramm
BNNS (Basic Neural Network Subroutines)
Wenn Core ML auf einer CPU ausgeführt wird, werden die BNSS-Routinen verwendet, die Teil der Accelerate-Plattform sind. Ich habe bereits in diesem Artikel über BNNS geschrieben . Die meisten dieser BNNS-Funktionen werden inzwischen weitgehend eingestellt und durch neue Funktionen ersetzt.
Bisher wurden nur vollständig verbundene Ebenen-, Falt-, Gruppierungs- und Aktivierungsfunktionen unterstützt. Dieses Update bietet BNNS Unterstützung für n-dimensionale Arrays, fast alle Arten von Core-ML-Schichten und Abwärtskompatibilitätsversionen solcher Trainingsebenen (einschließlich Schichten, die derzeit kein Core-ML-Training unterstützen, wie z. B. LSTM).
Es ist auch erwähnenswert, dass eine Schicht mehrfacher Aufmerksamkeit vorhanden ist.... Diese Schichten werden häufig in Transformer-Modellen wie BERT verwendet. Ein weiterer interessanter Punkt sind Tensorwindungen.
Möglicherweise verwenden Sie diese BNNS-Funktionen nicht selbst - genau wie Sie MPS nicht zum Trainieren auf einer GPU verwenden würden. Stattdessen steht jetzt eine übergeordnete ML Compute-Plattform zur Verfügung, die den verwendeten Prozessor abstrahiert. ML Compute basiert auf BNNS und MPS, aber Entwickler müssen sich nicht um solche kleinen Dinge kümmern.
Siehe auch: Dokumentation zur BNNS-Plattform
Neu: ML Compute
ML Compute ist eine grundlegend neue Plattform zum Trainieren neuronaler Netze auf einer CPU oder GPU (aber anscheinend nicht auf Neural Engine-Prozessoren). Auf einem Mac Pro mit mehreren GPUs kann diese Plattform automatisch alle zum Trainieren verwenden.
Ich war etwas überrascht von der Anwesenheit einer anderen Lernplattform, aber diese Plattform vereinfacht wirklich alles, da Sie damit Low-Level-Komponenten vor BNNS und MPS und in Zukunft möglicherweise vor der Neural Engine verbergen können.
Das Beste ist, dass ML Compute auch von iOS-Systemen unterstützt wird, nicht nur von Mac. Es ist lustig, dass Core ML nirgendwo erwähnt wird. ML Compute schien völlig separat erstellt zu werden. Dieses Framework kann nicht zum Erstellen von Core ML-Modellen verwendet werden.
Aus eigener Erfahrung kann ich sagen, dass die Aufgabe von ML Compute in erster Linie darin besteht, die Arbeit von Deep-Learning-Tools von Drittanbietern zu beschleunigen . Sie müssen keinen Code schreiben, um direkt mit ML Compute zu arbeiten. Es sieht so aus, als ob angenommen wird (oder die Entwickler hoffen es), dass Tools wie TensorFlow diese Plattform verwenden werden, um hardwarebeschleunigtes Lernen auf dem Mac zu ermöglichen.
Etwa derselbe Satz von Schichten verfügbar wie in BNNS. Die Ebenen müssen dem Diagramm hinzugefügt und dann ausgeführt werden (hier wird der Modus "Besetzt warten" nicht verwendet).
Um ein Diagramm zu erstellen, müssen Sie zuerst ein Objekt instanziieren
MLCGraphund Knoten hinzufügen. Ein Knoten ist eine Unterklasse MLCLayer. Knoten sind durch Objekte miteinander verbundenMLCTensordie die Ausgabe anderer Ebenen enthalten.
Interessanterweise handelt es sich bei den Operationen zum Teilen, Verketten, Neuformatieren und Übertragen nicht um separate Layertypen, sondern um Operationen direkt im Diagramm.
Hervorragende Debug-Funktion -
summarizedDOTDescription. Es gibt eine DOT-Beschreibung für ein Diagramm zurück, aus der Sie dann beispielsweise mit Graphviz oder OmniGraffle ein Diagramm erstellen können (Keras generiert übrigens auf diese Weise Modelldiagramme).
ML Compute unterscheidet zwischen Inferenzgraphen und Lerngraphen. Letzterer enthält zusätzliche Knoten, beispielsweise eine Verlustschicht und einen Optimierer.
Es sieht so aus, als gäbe es hier keine Möglichkeiten, benutzerdefinierte Ebenen zu erstellen. Sie müssen also nur mit den in ML Compute verfügbaren Typen auskommen.
Es ist seltsam, dass es auf dieser neuen Plattform keine WWDC-Sitzungen gab, und die Dokumentation ist auch ziemlich verstreut. Wie auch immer, ich werde seine Entwicklung weiter verfolgen, da es genau die API zu sein scheint, die am besten für das Training von Modellen auf Apple-Geräten geeignet ist.
Siehe auch: ML Compute Platform-Dokumentation
Fazit
Der Core ML hat eine Reihe nützlicher neuer Funktionen hinzugefügt, z. B. die automatische Aktualisierung von Modellen und die Verschlüsselung. Die neuen Ebenentypen werden wirklich nicht wirklich benötigt, da die im letzten Jahr hinzugefügten Ebenen fast jedes Problem lösen können. Insgesamt gefällt mir dieses Update.
In coremltools 4 wurden wichtige Verbesserungen hinzugefügt - die neue Konverterarchitektur und die integrierte Unterstützung von TensorFlow 2 und PyTorch. Ich bin froh, dass wir ONNX nicht mehr verwenden müssen, um PyTorch-Modelle zu transformieren.
In Visionviele neue praktische Funktionen hinzugefügt. Und ich finde es toll, dass Apple Videoanalysefunktionen hinzugefügt hat. Obwohl maschinelle Lernsysteme auf einzelne Videobilder angewendet werden können, wird in diesem Fall die Zeit nicht gezählt. Da mobile Geräte heute schnell genug sind, um maschinelles Lernen basierend auf Videodaten in Echtzeit durchzuführen, glaube ich, dass Video in naher Zukunft eine wichtigere Rolle bei der Entwicklung von Computer-Vision-Technologien spielen wird.
In Bezug auf die Ausbildung... nicht sicher, ob wir für diese Aufgabe sieben verschiedene APIs benötigen. Ich denke, Apple wollte die veralteten Schnittstellen erst dann außer Betrieb setzen, wenn die neuen vollständig verfeinert wurden. Über die ML Compute-Plattform ist wenig bekannt. Zum Zeitpunkt dieses Schreibens wurde jedoch nur die erste Beta-Version veröffentlicht. Wer weiß, was vor uns liegt ...
Das Vorlesungsbild verwendet das Freepik- Symbol von flaticon.com.