
Was hat sich im Consumer Banking geändert?
In China war es noch vor fünf Jahren keine schnelle Sache, einen Kredit zu bekommen - für einen Sterblichen sicher. Es war erforderlich, viele Papiere auszufüllen, zu senden oder zu einer Bankfiliale zu bringen, vielleicht sogar in der Schlange zu stehen, und nach Hause zurückzukehren, um auf eine Entscheidung zu warten. Wie lange Warten? Und wie es herauskommt, von einer Woche bis zu mehreren Monaten.
Bis 2020 wurde dieses Verfahren drastisch vereinfacht. Ich habe kürzlich ein kleines Experiment durchgeführt - ich habe versucht, mit der mobilen Anwendung meiner Bank einen Kredit aufzunehmen. Mehrere Fingertipps auf dem Smartphone-Bildschirm - und das System verspricht, mir spätestens in einer Viertelstunde eine Antwort zu geben. Aber in weniger als fünf Minuten erhalte ich eine Push-Benachrichtigung, die angibt, auf welche Kreditgröße ich zählen kann. Stimmen Sie zu, ein beeindruckender Fortschritt im Vergleich zur Situation vor fünf Jahren. Seltsamerweise hat es in der jüngeren Vergangenheit ganze Tage und Wochen gedauert.
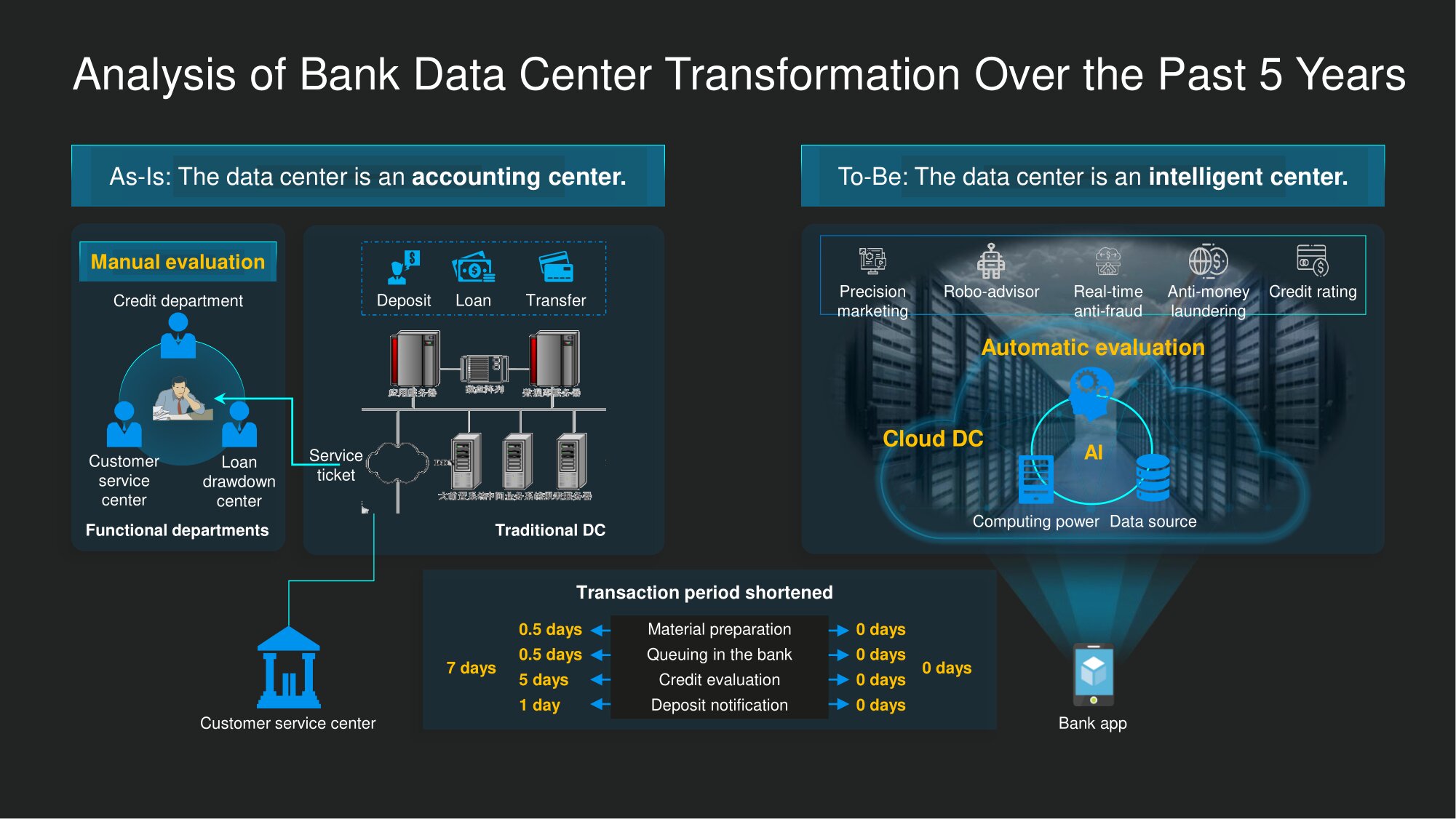
Zuvor wurde die meiste Zeit für die Datenüberprüfung und die manuelle Bewertung aufgewendet. Alle Informationen aus Fragebögen und anderen Unterlagen mussten in das IT-System der Bank eingegeben werden. Dies war jedoch erst der Beginn der Tortur: Die Bankangestellten überprüften persönlich Ihre Kreditwürdigkeit und trafen anschließend die endgültige Entscheidung. Sie verließen das Büro um 17:00 oder 18:00 Uhr, machten an den Wochenenden eine Pause, und der Prozess konnte sich infolgedessen lange hinziehen.
Die Dinge sind heutzutage anders. Der menschliche Faktor bei vielen Digital-Banking-Aufgaben wird im Allgemeinen aus den Klammern genommen. Die Bewertung, einschließlich Betrugsbekämpfung und Bekämpfung der Geldwäsche, wird automatisch mithilfe intelligenter Algorithmen durchgeführt. Die Autos brauchen keine Ruhe, deshalb fahren sie sieben Tage die Woche und rund um die Uhr. Darüber hinaus ist bereits eine angemessene Menge an Informationen, die für die Entscheidungsfindung erforderlich sind, in Bankdatenbanken gespeichert. Dies bedeutet, dass das Urteil in einer viel kürzeren Zeit als in der "itish Antike" gefällt wird.
Im Allgemeinen wurde das Bankdatenzentrum früher eher zur Lösung von Problemen vom Typ "Registrierung" verwendet. Es blieb lange Zeit nur ein Buchhaltungszentrum und produzierte nichts für sich. Heutzutage gibt es immer mehr "intelligente" Rechenzentren, in denen das Produkt erstellt wird... Sie werden für komplexe Berechnungen verwendet und helfen, Informationen aus Rohdaten abzuleiten - tatsächlich Wissen mit hohem Mehrwert. Darüber hinaus erhöht kontinuierliches Data Mining - wenn es natürlich richtig vorbereitet ist - letztendlich die Effizienz der Prozesse weiter.
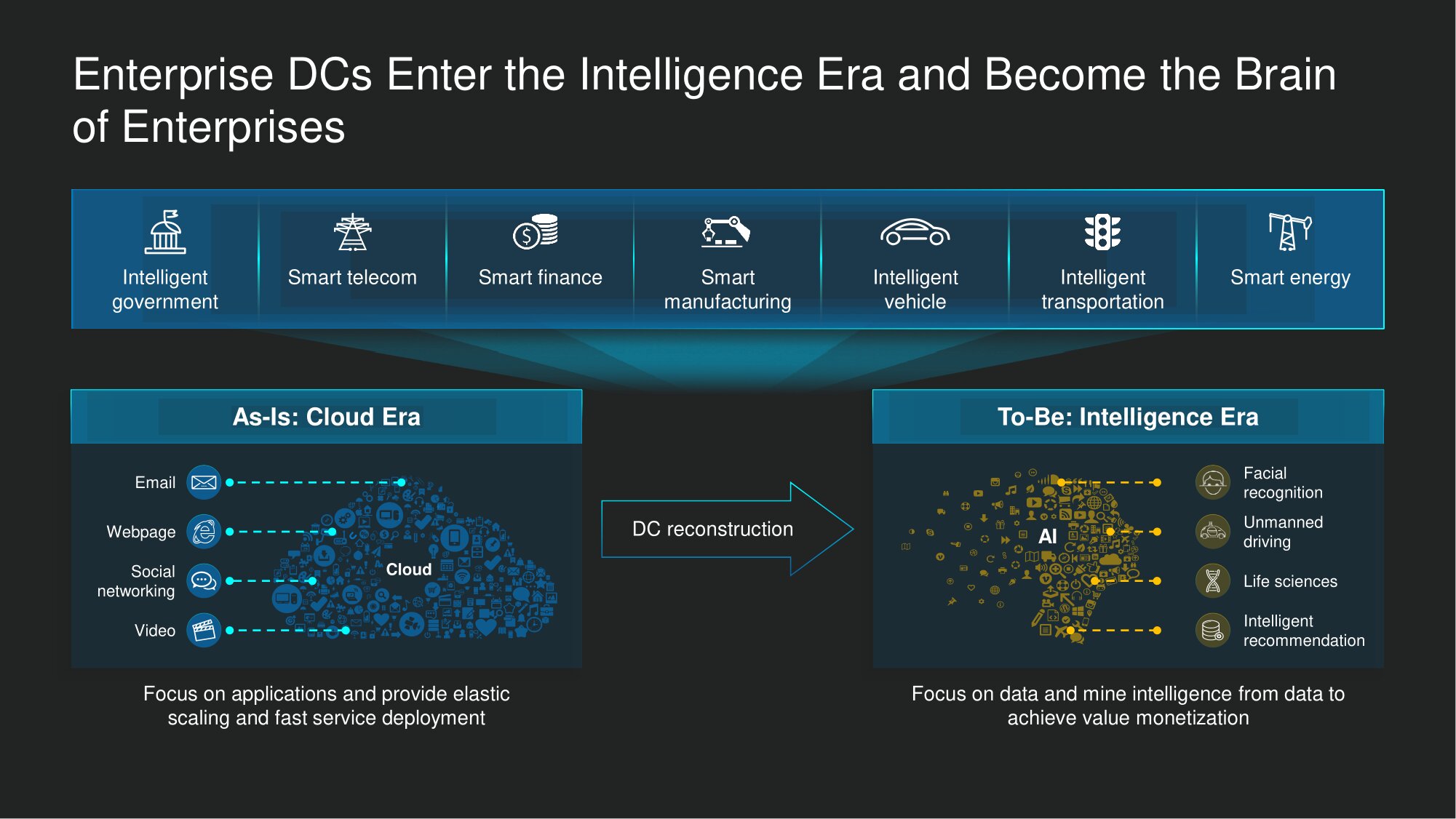
Diese Transformationen finden nicht nur im Finanzbereich statt, sondern in nahezu allen Geschäftsbereichen. Für Unternehmen mit einer Vielzahl von Profilen (und für uns als Lösungshersteller) sind Rechenzentren heute die Hauptunterstützung auf der Welt, wo der Wettbewerb zwischen intelligenten Entwicklungen intensiver ist als je zuvor. Noch vor fünf Jahren war es Mainstream, im Einklang mit der Tatsache zu argumentieren, dass das Rechenzentrum in die Welt der Cloud-Technologien eingeschrieben ist, und dies implizierte die Fähigkeit, den gesamten verteilten Ressourcenpool für Computer und Datenspeicherung flexibel zu skalieren. Dies ist jedoch die Ära intelligenter Lösungen. Im Rechenzentrum können wir kontinuierlich Data Mining durchführen und die erzielten Ergebnisse in außergewöhnliche Leistungssteigerungen umwandeln. Im Finanzsektor führen diese Veränderungen neben vielen anderen Ergebnissen dazu, dassdass sich die Bewertung von Kreditanträgen dramatisch beschleunigt. Oder sie ermöglichen es beispielsweise, einem bestimmten Bankkunden sofort die am besten geeigneten Finanzprodukte zu empfehlen.
Im öffentlichen Sektor, in der Telekommunikation und in der Energiewirtschaft trägt die intelligente Arbeit mit Daten heute zur digitalen Transformation bei und steigert die Produktivität des Unternehmens dramatisch. Natürlich werden neue Umstände eine neue Nachfrage bilden, und zwar nicht nur in Bezug auf Computerressourcen und Datenspeichersysteme, sondern auch in Bezug auf Netzwerklösungen für Rechenzentren.
Was sollte ein "intelligentes Rechenzentrum" sein?
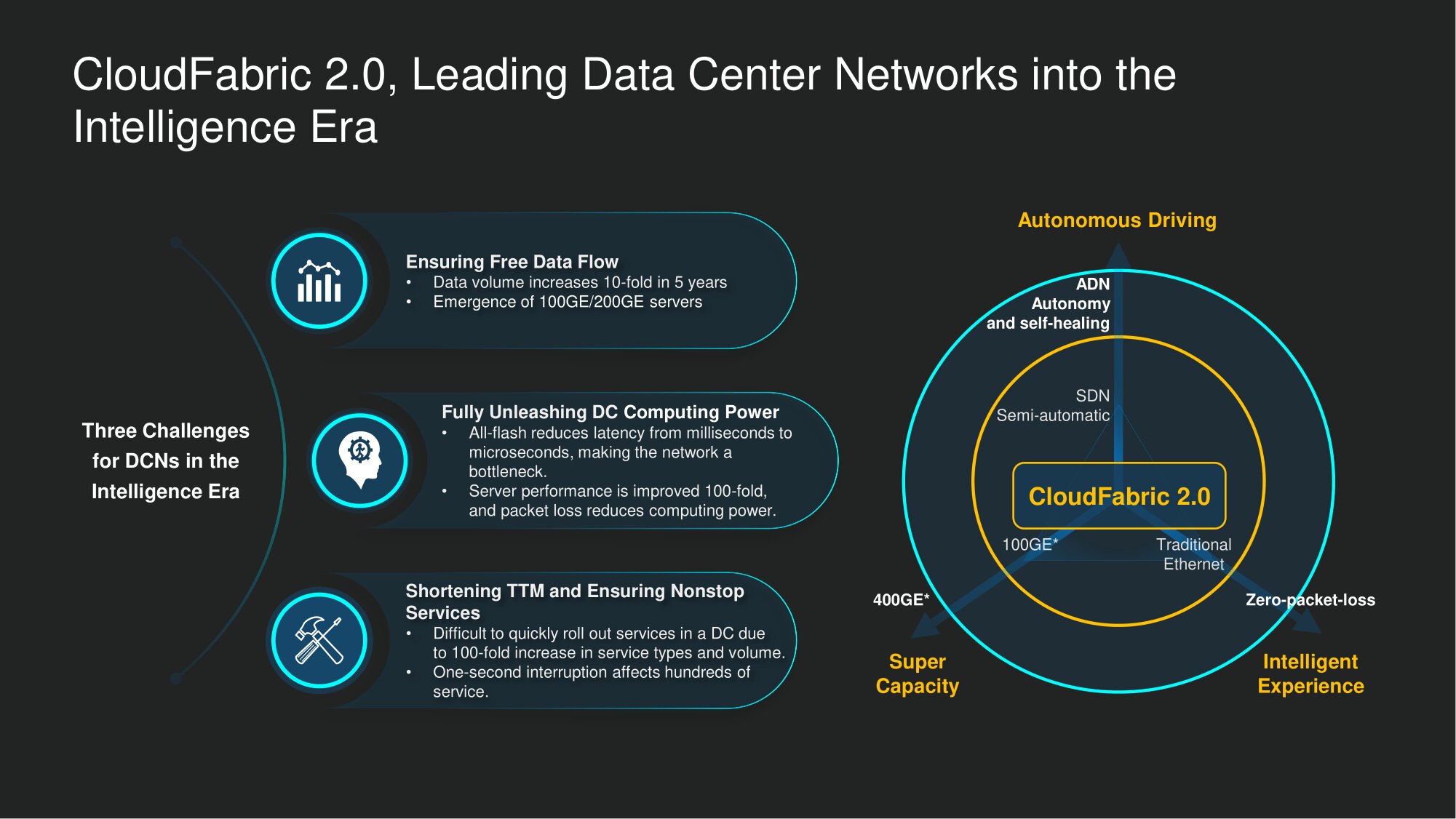
Bei Huawei haben wir drei große Herausforderungen für Rechenzentren im Zeitalter intelligenter Rechenzentren identifiziert.
Erstens ist eine außergewöhnliche Bandbreite erforderlich, um die nie endenden Ströme neuer Daten zu verarbeiten.... Nach unseren Beobachtungen hat sich das in Rechenzentren gespeicherte Datenvolumen in den letzten fünf Jahren verzehnfacht. Noch beeindruckender ist jedoch, wie viel Verkehr beim Zugriff auf solche Daten generiert wird. In Rechenzentren vom Typ "Registrierungstyp" wurden all diese Informationen verwendet, um Buchhaltungsprobleme zu lösen und häufig Eigengewicht zu verursachen. In Rechenzentren eines neuen Typs "funktioniert" dies - wir müssen ein konstantes Data Mining bereitstellen. Infolgedessen werden beim Zugriff auf eine gespeicherte Dateneinheit 10 bis 1000 Mal mehr Iterationen ausgeführt als zuvor. Wenn beispielsweise KI-Modelle trainiert werden, werden Rechenaufgaben im Hintergrund nahezu ununterbrochen ausgeführt, wobei die Algorithmen des neuronalen Netzwerks ständig funktionieren, um die "Intelligenz" des Systems zu erhöhen. Somit wächst nicht nur das Volumen der gespeicherten Daten, sondern auch der Verkehr, der beim Zugriff darauf generiert wird.Es ist also keineswegs eine Laune der Telekommunikationsanbieter, dass es immer mehr einhundertzweihundert Gigabit-Ports auf neuen Modellen von Datenspeicherservern gibt.
Zweitens kein Verlust von Datenpaketenim Jahr 2020 das absolute Muss. Auf jeden Fall aus unserer Sicht. Bisher bereiteten solche Verluste Ingenieuren in Bankenzentren keine Kopfschmerzen. Die Engpässe waren Verarbeitungsleistung und Speichereffizienz. Die Branchendurchschnittswerte beider Indikatoren sind in den letzten fünf Jahren weltweit jedoch erheblich gestiegen. Die Effizienz der Netzwerkinfrastruktur stellte sich natürlich als Engpass bei der Arbeit von Rechenzentren heraus. In Zusammenarbeit mit einem unserer Top-Kunden stellten wir fest, dass jeder Prozentsatz, der zur Paketverlustrate beiträgt, die Trainingseffizienz von KI-Modellen zu halbieren droht. Daher die enormen Auswirkungen auf die Produktivität und Effizienz des Einsatzes von Computerressourcen und Datenspeichersystemen. Das muss überwunden werdenUnterstützung der Umwandlung eines einfachen Rechenzentrums in ein Rechenzentrum für das intelligente Zeitalter.
Drittens ist es wichtig , den Service nahtlos und nahtlos bereitzustellen . Das moderne digitale Bankwesen hat den Menschen zu Recht beigebracht, dass die Dienstleistungen von Finanzinstituten rund um die Uhr verfügbar sein können oder sollten. Eine häufige Situation: Ein abgenutzter Unternehmer mit einem gestörten Tagesablauf, der dringend zusätzliche Mittel benötigt, wacht kurz vor Mitternacht auf und möchte herausfinden, auf welche Kreditlinie er zählen kann. Die Rückwege sind abgeschnitten: Die Bank kann die Arbeit des DC nicht mehr unterbrechen, um etwas zu reparieren oder zu aktualisieren.
Unsere CloudFabric 2.0-Lösung ist genau auf diese Herausforderungen ausgelegt. Es unterstützt den höchsten Durchsatz, ein intelligentes Netzwerkmanagement für Rechenzentren und die einwandfreie Funktion autonomer Fahrnetzwerke (ADN).
Was ist in CloudFabric 2.0 für Smart Data Center?

Im Hinblick auf einen hohen Durchsatz setzen wir nicht nur auf die Skalierbarkeit unserer Netzwerklösungen, sondern auch auf die Flexibilität bei der Arbeit mit ihnen. Zum Beispiel wurden Huawei-Rechenzentrums-Switches der CloudEngine-Linie zu den ersten Geräten dieser Klasse in der Branche mit einem eingebetteten Prozessor für neuronales Netzwerk-Computing in Echtzeit. Sie helfen dabei, Probleme innerhalb der Netzwerkinfrastruktur zu lösen und Datenpaketverluste zu verhindern (dies wird mithilfe des iLossless-Algorithmus erreicht) einschließlich für das iNOF RoCE-Szenario). Aber natürlich spielt auch die tatsächliche Bandbreite eine Rolle. Die Unterstützung von 400-Gbit / s-Schnittstellen ist wichtig, ebenso wie die Abwärtskompatibilität mit derzeit weit verbreiteten Zehn-, Vierzig- und Hundert-Gigabit-Verbindungen.
Die unterstützenden Knoten der Infrastruktur sollten auch in der Lage sein, mit einer hohen Verbindungsdichte (den sogenannten Szenarien mit hoher Dichte) zu arbeiten, mit der Möglichkeit einer signifikanten Skalierbarkeit der Lösung. Unser Flaggschiff-Rechenzentrumsmodell CloudEngine 16800 unterstützt bis zu 48 Ports mit 400 Gbit / s pro Steckplatz - dreimal mehr als sein Gegenstück zum nächsten Konkurrenten.
Was das Gesamtsystem betrifft, so sind auch die Möglichkeiten zur Erweiterung des Durchsatzes pro Chassis-Skalierbarkeit beeindruckend: 768 Ports mit 400 Gbit / s pro Chassis oder sechsmal mehr als Lösungen anderer Marktteilnehmer zulassen. Dies gibt uns Grund, die CloudEngine 16800 als den leistungsstärksten Rechenzentrums-Switch im Zeitalter der erfolgreichen KI zu bezeichnen.

Auch die intellektuelle Komponente der Netzwerklösung tritt in den Vordergrund. Insbesondere ist es auch notwendig, um sicherzustellen, dass keine Datenpakete verloren gehen. Um dieses Ergebnis zu erzielen, nutzen wir unsere fortschrittlichsten technologischen Fortschritte, einschließlich eines integrierten AI-Prozessors für das "neuronale Netzwerk" -Computing sowie des zuvor erwähnten iLossless-Algorithmus. Bei Projekten für unsere führenden Kunden waren wir davon überzeugt, dass diese Lösungen die Systemleistung in mindestens zwei gängigen Szenarien erheblich steigern können.
Das erste ist das Training von KI-Modellen. Es erfordert ständigen Zugriff auf Daten und Berechnungen für große Matrizen oder "schwere" Operationen mit TensorFlow. Unser iLossless ist in der Lage, die Produktivität des Trainings von KI-Modellen um 27% zu steigern - nachgewiesen in realen Fällen und verifiziert durch den Labortest der Tolly Group. Das zweite Szenario besteht darin, die Effizienz von Speichersystemen zu verbessern. Die Nutzung unserer Entwicklungen kann sie wiederum um etwa 30% steigern.
Unter anderem bemühen wir uns gemeinsam mit unseren Kunden, neue Möglichkeiten auszuprobieren, die sich aus unseren Entwicklungen ergeben. Wir sind zuversichtlich, dass wir durch die Verbesserung der Ethernet-basierten Switching-Struktur für das Rechenzentrum die Hochleistungs-Rechenzentrumsstruktur mit dem Speichernetzwerk in eine einzige, kohärente Ethernet-basierte Infrastruktur umwandeln können. Um nicht nur die Produktivität von Lernprozessen für KI-Modelle zu steigern und den Zugriff auf softwaredefinierte Datenspeicher zu verbessern, sondern auch die Gesamtbetriebskosten eines Rechenzentrums durch gegenseitige Integration und Zusammenführung vertikaler Netzwerke, die auf physischer Ebene unabhängig sind, erheblich zu optimieren.

Viele unserer Kunden genießen die Einführung dieser neuen Funktionen. Und einer dieser Kunden ist Huawei selbst. Insbesondere das gehört zu unserer Unternehmensgruppe Huawei Cloud. In enger Zusammenarbeit mit unseren Kollegen in diesem Bereich haben wir sichergestellt, dass wir durch die Gewährleistung eines Verlusts von Datenpaketen den Anstoß zur spürbaren Verbesserung ihrer Geschäftsprozesse gaben. Zu unseren "internen" Errungenschaften gehört schließlich die Tatsache, dass wir in Atlas 900, dem größten KI-Cluster der Welt, Rechenleistung für das Training künstlicher Intelligenz bei rund 1.000 Petaflops bereitstellen können - die höchste Zahl in einem Computer Industrie heute.
Ein weiteres äußerst relevantes Szenario ist die Speicherung von Cloud-Daten mit All-Flash-Systemen. Dies ist im Branchenvergleich ein sehr „trendiger“ Service. Die Erhöhung der Rechenressourcen und die Erweiterung der Speichereinrichtungen erfordern natürlich fortschrittliche Technologien aus dem Bereich der Netzwerklösungen für Rechenzentren. Daher arbeiten wir weiterhin mit Huawei Cloud zusammen und implementieren mit unseren Netzwerklösungen immer mehr Anwendungsszenarien.
Was ADN-Netzwerke heute tun können

Wenden wir uns den autonomen Netzwerken (ADN) zu. Es besteht kein Zweifel, dass softwaredefinierte Netzwerke (softwaredefinierte Netzwerke) aus technologischer Sicht ein sicherer Schritt vorwärts bei der Verwaltung der Netzwerkkomponente des Rechenzentrums sind. Die angewandte Implementierung des SDN-Konzepts beschleunigt die Initialisierung und Konfiguration der Rechenzentrumsnetzwerkschicht erheblich. Aber die Funktionen, die es bietet, reichen natürlich nicht aus, um den Betrieb des Rechenzentrums vollständig zu automatisieren. Um weiter zu gehen, müssen drei Hauptherausforderungen angegangen werden.
Erstens gibt es in der Netzwerkinfrastruktur von Rechenzentren immer mehr Möglichkeiten, Dienste und Einstellungen für deren Funktion bereitzustellen, insbesondere im Finanzsektor. Es ist wichtig, die Service-Level-Absicht automatisch in die Netzwerkschicht übersetzen zu können...
Zweitens kommt es auch darauf an, solche inkrementellen Bereitstellungsbefehle zu überprüfen . Verständlicherweise wurden Rechenzentrumsnetzwerke vor langer Zeit vielfach konfiguriert, basierend auf etablierten oder sogar veralteten Ansätzen. Wie stellen Sie sicher, dass zusätzliche Anpassungen Ihre debuggten Prozeduren nicht beschädigen? Die automatische Überprüfung neuer Zusatzeinstellungen ist unabdingbar. Genau automatisch, da die vorhandenen Einstellungen im Rechenzentrum normalerweise unerschwinglich groß sind. Es ist praktisch unmöglich, manuell damit umzugehen.
Drittens stellt sich die Frage nach einer wirksamen und sofortigen Beseitigung von Problemen in der Netzwerkinfrastruktur... Wenn die Automatisierung ein hohes Niveau erreicht, können Administratoren und Servicetechniker des Rechenzentrums nicht mehr in Echtzeit überwachen, was im Netzwerk geschieht. Sie benötigen ein Toolkit, mit dem ein Netzwerk mit Tausenden von Änderungen pro Tag für sie durchgehend transparent gemacht werden kann, sowie Datenbanken, die auf Wissensgraphen basieren, um Probleme schnell zu lösen.
ADNs können uns dabei helfen, diese Herausforderungen beim Umzug in wirklich intelligente Rechenzentren zu bewältigen. Und die Ideologie von Netzwerken mit autonomer Steuerung (die aus der benachbarten Industrie in die Welt der Rechenzentren migriert ist - insbesondere an der Schnittstelle von IoT und V2X) ermöglicht es uns, Ansätze zur Automatisierung auf verschiedenen Ebenen des Rechenzentrumsnetzwerks zu überdenken.
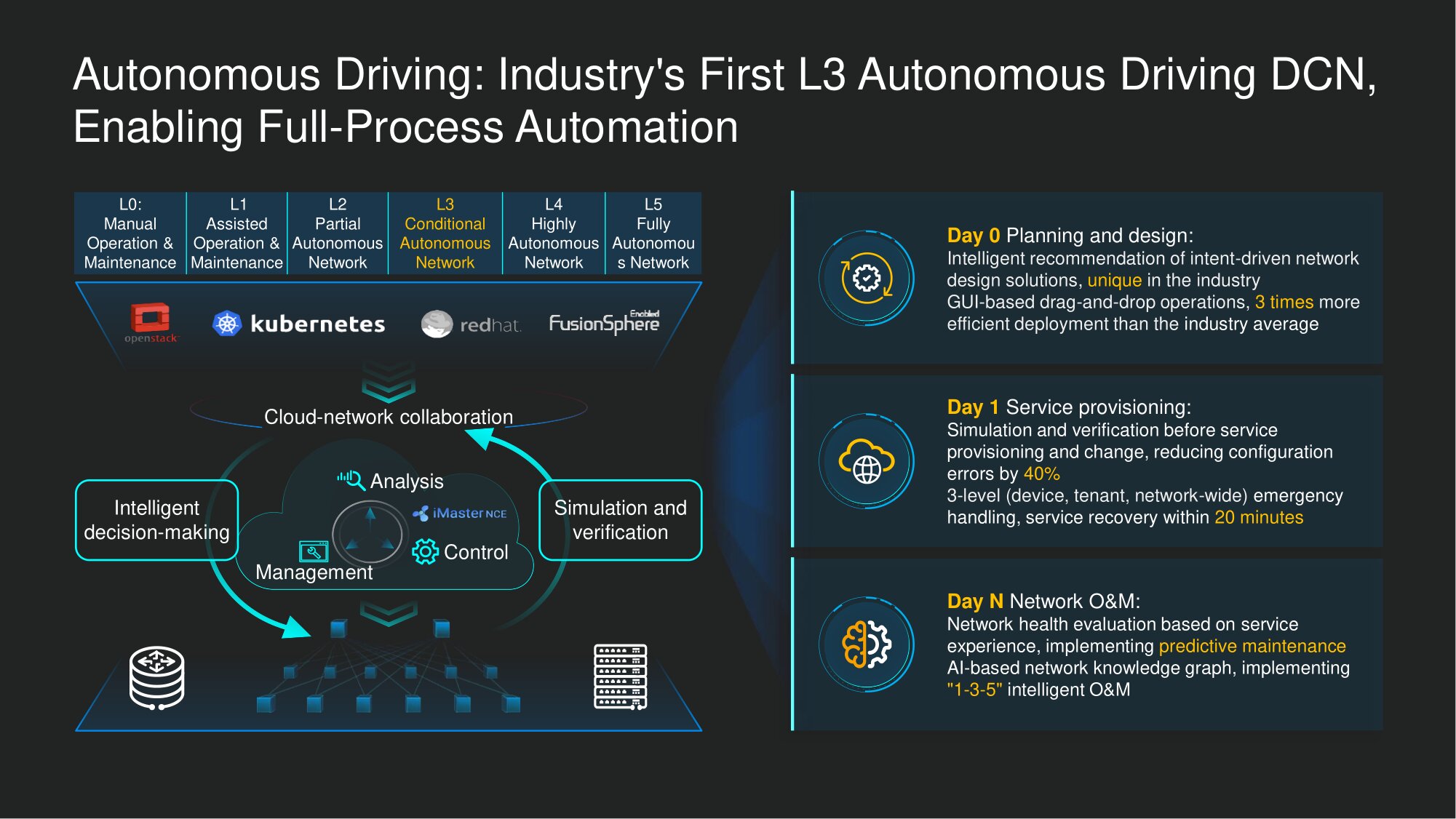
Im Moment haben wir in der Autonomie der Verwaltung von Netzwerken für Rechenzentren erreichtStufe L3 (bedingte Automatisierung). Dies bedeutet einen hohen Grad an Automatisierung von Rechenzentren, bei dem ein menschliches Eingreifen punktuell und nur unter bestimmten Bedingungen erforderlich ist.
In einigen Szenarien ist inzwischen auch eine vollständige Automatisierung möglich. Wir arbeiten bereits mit unseren Kunden im Rahmen eines gemeinsamen Innovationsprogramms zur umfassenden Automatisierung von Rechenzentrumsnetzwerken nach dem ADN-Konzept zusammen, vor allem im Zusammenhang mit der Behebung von Netzwerkproblemen, und in Bezug auf die dringendsten und zeitaufwändigsten von ihnen haben wir Erfolg erzielt: zum Beispiel mit Hilfe unserer Intelligente Technologien schaffen es automatisch, etwa 85% der am häufigsten auftretenden Fehlerszenarien in Rechenzentrumsnetzwerken zu schließen .
Diese Funktionalität wird im Rahmen unseres O & M 1-3-5-Konzepts implementiert: eine Minute, um festzustellen, ob ein Fehler aufgetreten ist, oder um das Risiko eines Fehlers zu erkennen, drei Minuten, um die Grundursache zu ermitteln, und fünf Minuten, um vorzuschlagen, wie beseitigen Sie es. Natürlich ist vorerst eine menschliche Beteiligung erforderlich, um endgültige Entscheidungen zu treffen - insbesondere um eine der möglichen Entscheidungen zu treffen und den Befehl zu geben, sie auszuführen. Jemand muss die Verantwortung für die Wahl übernehmen. Ausgehend von der Praxis glauben wir jedoch, dass das System auch in seiner derzeitigen Implementierung hochqualifizierte und geeignete Lösungen bietet.
Kurz gesagt, hier sind die größten Herausforderungen für Architekten intelligenter Rechenzentren im Jahr 2020, mit denen wir uns tatsächlich befasst haben. Beispielsweise ist in CloudFabric 2.0 bereits eine Funktion zum Übertragen von Anforderungen von der Serviceschicht zur Netzwerkschicht und zur automatischen Überprüfung von Einstellungen enthalten.

Wir freuen uns, dass unsere Leistungen für den CloudEngine 16800 Switch anerkannt wurden - und dieses Jahr erhielten wir den Gartner Peer Insights Customer Choice Award sowie den F & S Global Data Center Switch Technology Leadership Award -, der für seinen herausragenden Durchsatz ausgezeichnet wurde , die höchste Dichte von 400-Gigabit-Schnittstellen und die Gesamtskalierbarkeit des Systems sowie intelligente Technologien, mit denen insbesondere der Verlust von Datenpaketen auf Null reduziert werden kann.