
Ich möchte von Anfang an klarstellen, dass Oracle in diesem Fall als kollektive SQL-Sprache dargestellt wird. Die Gruppierungen und ihre Anwendung gelten für die gesamte SQL-Familie (hier als strukturierte Abfragesprache verstanden) und gelten für alle Abfragen mit Korrekturen für die Syntax jeder Sprache.
Ich werde versuchen, alle notwendigen Informationen in zwei Teilen kurz und einfach zu erklären. Der Beitrag wird höchstwahrscheinlich für Anfänger nützlich sein. Wen kümmert es - willkommen bei Katze.
Teil 1: Angebote Bestellen nach, Gruppieren nach, Haben
Hier sprechen wir über Sortieren - Sortieren nach, Gruppieren - Gruppieren nach, Filtern - Haben und Abfragen von Plänen. Aber das Wichtigste zuerst.
Sortieren nach
Der Operator "Sortieren nach" sortiert die Ausgabewerte, d. H. sortiert den abgerufenen Wert nach einer bestimmten Spalte. Die Sortierung kann auch über einen Spaltenalias angewendet werden, der mit einem Operator definiert wird.
Der Vorteil von Order by besteht darin, dass es sowohl auf numerische als auch auf Zeichenfolgenspalten angewendet werden kann. Zeichenfolgenspalten werden normalerweise alphabetisch sortiert.
Aufsteigende Sortierung wird standardmäßig angewendet. Wenn Sie die Spalten in absteigender Reihenfolge sortieren möchten, verwenden Sie den zusätzlichen DESC-Operator.
Syntax:
SELECT Spalte1, Spalte2, … (gibt den Namen an)
FROM Tabellenname
ORDER BY Spalte1, Spalte2 … ASC | DESC ;
Schauen wir uns alles mit Beispielen an:
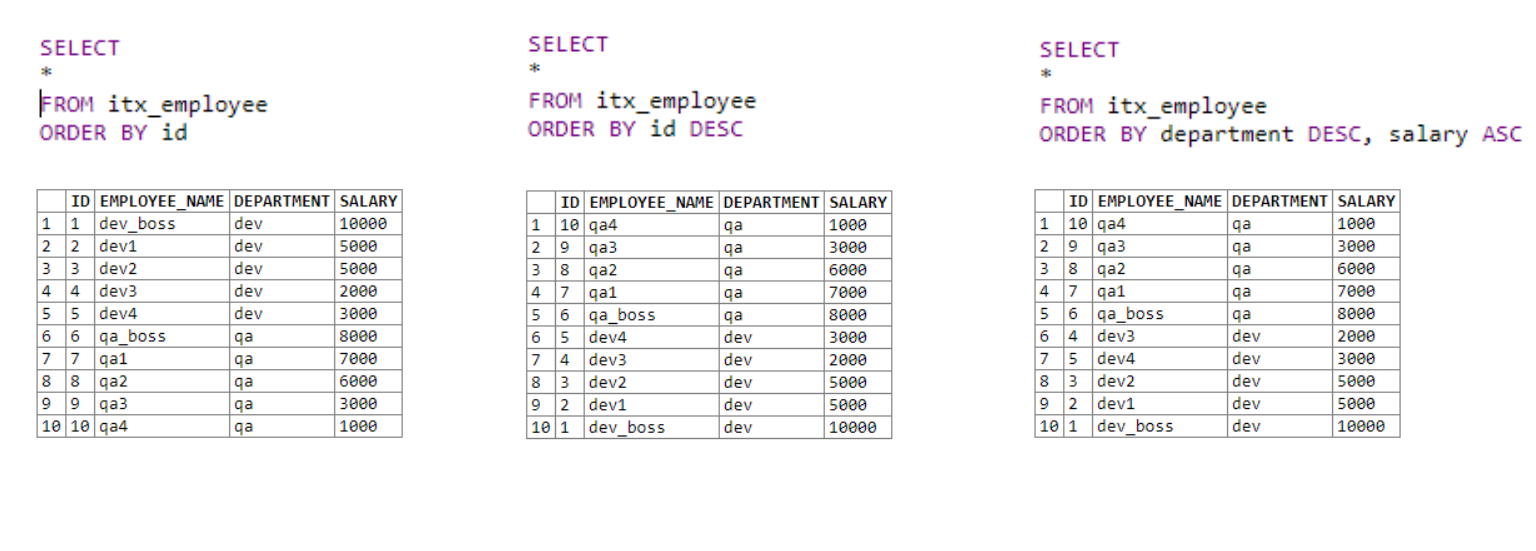
In der ersten Tabelle erhalten wir alle Daten und sortieren sie in aufsteigender Reihenfolge nach der ID-Spalte.
Im zweiten erhalten wir auch alle Daten. Sortieren Sie nach der ID-Spalte in absteigender Reihenfolge mit dem Schlüsselwort DESC .
Die dritte Tabelle verwendet mehrere Sortierfelder. Zuerst kommt die Sortierung nach Abteilungen. Wenn der erste Operator für Felder mit derselben Abteilung gleich ist, wird die zweite Sortierbedingung angewendet. In unserem Fall ist dies das Gehalt.
Es ist ziemlich einfach. Wir können mehr als eine Sortierbedingung festlegen, wodurch wir die Ausgabelisten intelligenter sortieren können.
Gruppiere nach
In SQL sammelt die Group by-Klausel Daten, die aus einer Datenbank in bestimmten Gruppen abgerufen wurden. Durch die Gruppierung werden alle Daten in logische Sätze unterteilt, sodass statistische Berechnungen in jeder Gruppe separat durchgeführt werden können.
Dieser Operator wird verwendet, um die Ergebnisse einer Auswahl durch eine oder mehrere Spalten zu kombinieren. Nach der Gruppierung gibt es nur einen Eintrag für jeden in der Spalte verwendeten Wert.
Die Verwendung der SQL Group by-Anweisung hängt eng mit der Verwendung von Aggregatfunktionen und der SQL Have-Anweisung zusammen. Eine Aggregatfunktion in SQL ist eine Funktion, die einen einzelnen Wert über eine Reihe von Spaltenwerten zurückgibt. Beispiel: COUNT (), MIN (), MAX (), AVG (), SUM ()
Syntax:
SELECT Spaltenname (n)
FROM Tabellenname
WHERE- Bedingung
GROUP BY Spaltenname (n)
ORDER BY Spaltenname (n);
Gruppieren nach wird nach der bedingten WHERE-Klausel in der SELECT- Abfrage angezeigt . Optional können Sie ORDER BY verwenden , um die Ausgabewerte zu sortieren.
Basierend auf der Tabelle aus dem vorherigen Beispiel müssen wir also das maximale Gehalt für die Mitarbeiter jeder Abteilung ermitteln. Die endgültige Stichprobe sollte den Namen der Abteilung und das maximale Gehalt enthalten.
Lösung 1 (ohne Gruppierung):
SELECT DISTINCT
ie.department
ie.slary
FROM itx_employee ie
WHERE ie.salary = (
SELECT
max(ie1.salary)
FROM itx_employee ie1
WHERE ie.department = ie1.department
)
Lösung 2 (unter Verwendung der Gruppierung):
SELECT
department,
max(salary)
FROM itx_employee
GROUP BY department
Im ersten Beispiel lösen wir das Problem ohne Gruppierung, aber mit einer Unterauswahl, d.h. Setzen Sie die zweite in eine Auswahl. In der zweiten Lösung verwenden wir die Gruppierung.
Das zweite Beispiel ist kürzer und besser lesbar, obwohl es dieselben Funktionen wie das erste ausführt.
So funktioniert Group by für uns: Zunächst werden zwei Abteilungen in Qa- und Dev-Gruppen aufgeteilt. Dann sucht er nach dem Höchstgehalt für jeden von ihnen.
Haben
Haben ist ein Filterwerkzeug. Es zeigt das Ergebnis der Ausführung von Aggregatfunktionen an. Die Have-Klausel wird in SQL verwendet, wo WHERE nicht verwendet werden kann.
Wenn die WHERE-Klausel ein Prädikat zum Filtern von Zeilen definiert, wird Have nach dem Gruppieren verwendet, um ein logisches Prädikat zu definieren, das die Gruppe nach den Werten der Aggregatfunktionen filtert. Die Klausel ist erforderlich, um Werte zu testen, die mit Aggregatfunktionen aus Zeilengruppen erhalten wurden.
Syntax:
SELECT Spaltenname (n)
FROM Tabellenname
WHERE- Bedingung
GROUP BY Spaltenname (n)
HAVING- Bedingung
Zuerst werden die Abteilungen mit einem Durchschnittsgehalt von mehr als 4000 angezeigt. Anschließend wird das maximale Gehalt mithilfe der Filterung angezeigt.
Lösung 1 (ohne Verwendung von GROUP BY und HAVING):
SELECT DISTINCT
ie.department AS "DEPARTMENT",
(
(SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department)
) AS "AVG SALARY"
FROM itx_employee ie
where (SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department) > 4000
Lösung 2 (mit GROUP BY und HAVING):
SELECT
department,
AVG(salary)
FROM itx_employee
GROUP BY department
HAVING AVG(salary) > 4000
Im ersten Beispiel werden zwei Unterauswahlen verwendet, eine zum Ermitteln des Maximalgehalts und die andere zum Filtern des Durchschnittsgehalts. Das zweite Beispiel war wiederum viel einfacher und prägnanter.
Plan anfordern
Sehr oft gibt es Situationen, in denen eine Anforderung über einen längeren Zeitraum ausgeführt wird und erhebliche Ressourcen an Speicher und Festplatten verbraucht. Um zu verstehen, warum eine Abfrage lange und ineffizient ausgeführt wird, können wir uns den Abfrageplan ansehen.
Ein Abfrageplan ist der beabsichtigte Ausführungsplan für eine Abfrage, d. H. wie das DBMS es ausführen wird. Das DBMS schreibt alle Operationen auf, die innerhalb der Unterabfrage ausgeführt werden. Nachdem wir alles analysiert haben, können wir verstehen, wo sich die Schwachstellen in der Anfrage befinden, und mithilfe des Abfrageplans können wir sie optimieren.
Die Ausführung einer SQL-Anweisung in Oracle ruft den sogenannten "Ausführungsplan" ab. Dieser Abfrageausführungsplan beschreibt, wie Oracle Daten gemäß der ausgeführten SQL-Anweisung abruft. Ein Plan ist ein Baum, der die Reihenfolge der Schritte und die Beziehung zwischen ihnen enthält.
Zu den Tools, mit denen Sie den geschätzten Ausführungsplan einer Abfrage abrufen können, gehören Toad, SQL Navigator, PL / SQL Developer usw. Sie geben eine Reihe von Indikatoren für den Ressourcenverbrauch einer Abfrage an, darunter die wichtigsten: Kosten - Ausführungskosten und Kardinalität (oder Zeilen ) - Kardinalität (oder Menge) Linien).
Je höher der Wert dieser Indikatoren ist, desto weniger effizient ist die Abfrage.
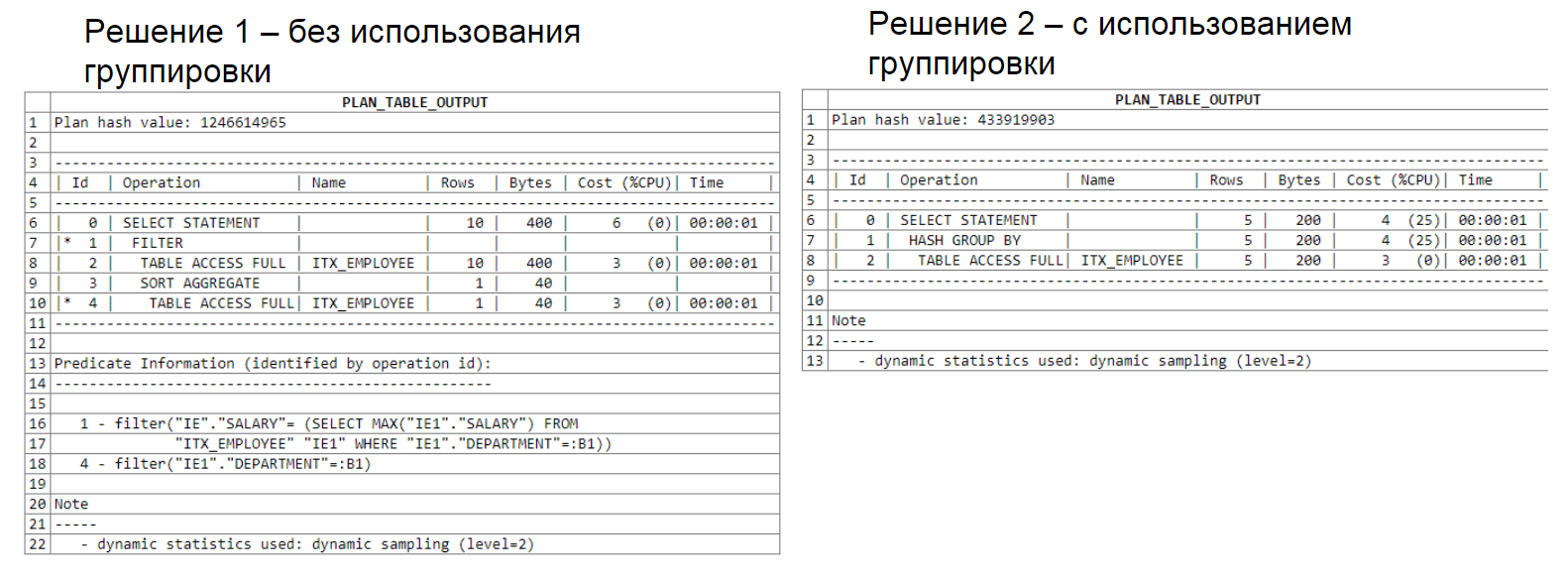
Unten sehen Sie die Analyse des Abfrageplans. Die erste Lösung verwendet eine Unterauswahl, die zweite eine Gruppierung. Beachten Sie, dass die erste Lösung 22 Zeilen und die zweite 15 Zeilen verarbeitet hat. Abfrageplananalyse
:
Eine weitere Abfrageplananalyse, die zwei Unterauswahlen verwendet:
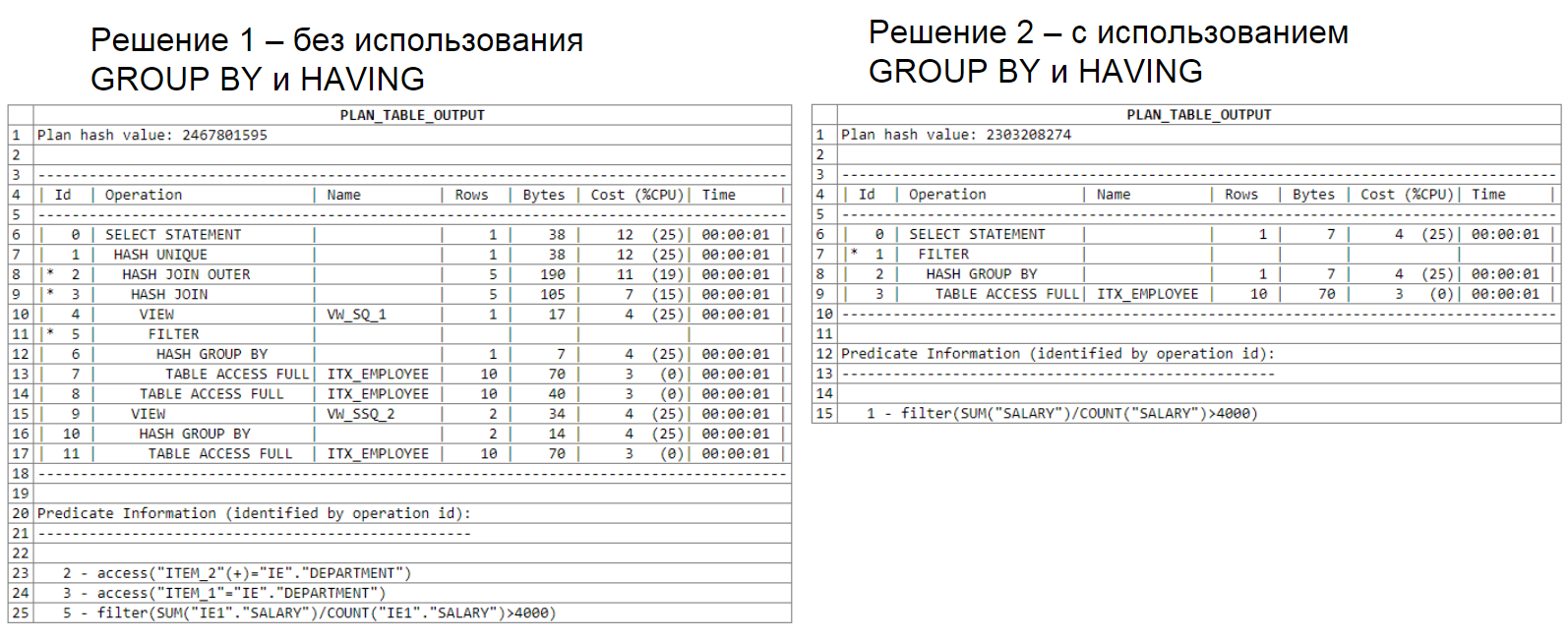
Dieses Beispiel wird als Variante der ineffizienten Verwendung von SQL-Tools dargestellt. Ich empfehle nicht, es in Ihren Abfragen zu verwenden.
Alle oben genannten Funktionen erleichtern Ihnen das Schreiben von Abfragen und verbessern die Qualität und Lesbarkeit Ihres Codes.
Teil 2: Fensterfunktionen
Fensterfunktionen stammen aus Microsoft SQL Server 2005. Sie führen Berechnungen für einen bestimmten Zeilenbereich innerhalb einer Select-Klausel durch. Kurz gesagt, ein "Fenster" ist eine Reihe von Zeilen, innerhalb derer eine Berechnung stattfindet. Mit "Fenster" können Sie die Daten reduzieren und besser verarbeiten. Mit dieser Funktion können Sie das gesamte Dataset in Fenster aufteilen.
Fensterung hat einen großen Vorteil. Es ist nicht erforderlich, einen Datensatz für Berechnungen zu erstellen, mit dem Sie alle Zeilen des Satzes mit ihrer eindeutigen ID speichern können. Das Ergebnis der Fensterfunktionen wird der resultierenden Auswahl in einem weiteren Feld hinzugefügt.
Syntax:
SELECT Spaltenname (n)
Aggregatfunktion (zu berechnende Spalte)
OVER ([ PARTITION BYSäule zur Gruppe]
FROM Tabellenname
[ ORDER BY Spalte zu sortieren]
[ ROWS oder RANGE Ausdruck Reihen innerhalb einer Gruppe zu beschränken])
OVER PARTITION BY ist eine Eigenschaft für die Einstellung der Fenstergröße. Hier können Sie zusätzliche Informationen angeben, Servicebefehle erteilen, z. B. eine Zeilennummer hinzufügen. Die Fensterfunktionssyntax passt genau in die Spaltenauswahl.
Schauen wir uns alles anhand eines Beispiels an: Eine weitere Abteilung wurde zu unserer Tabelle hinzugefügt, jetzt enthält die Tabelle 15 Zeilen. Wir werden versuchen, die Mitarbeiter, ihr Gehalt sowie das maximale Gehalt der Organisation abzuziehen.
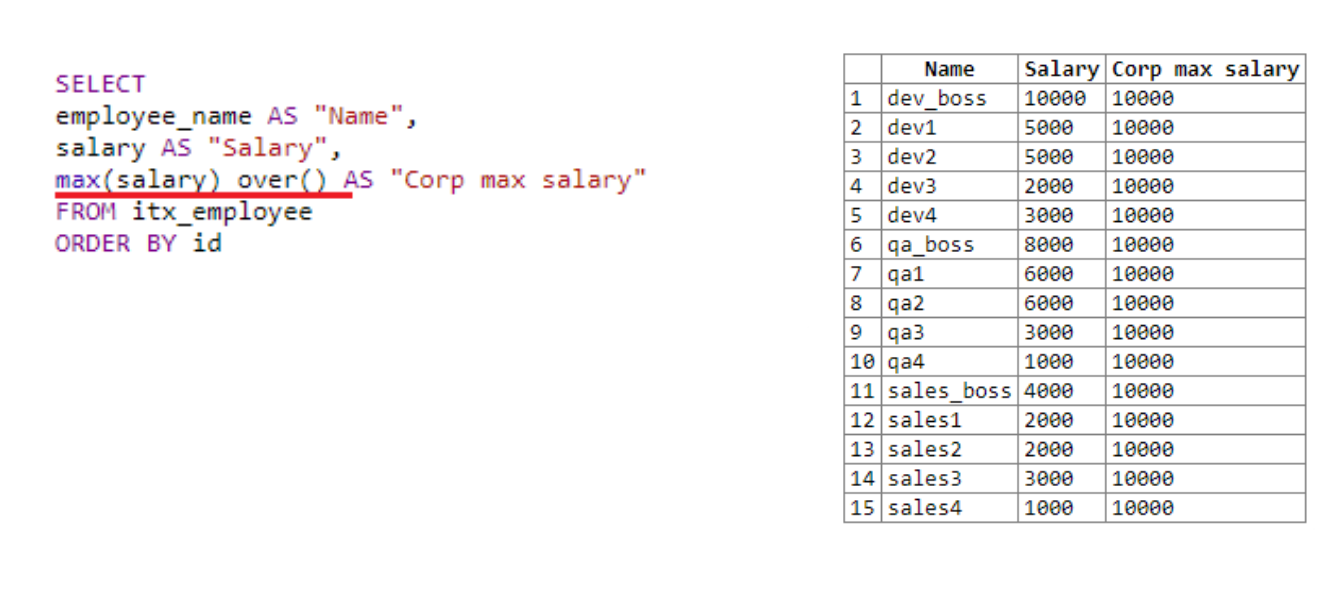
Im ersten Feld nehmen wir den Namen, im zweiten das Gehalt. Als nächstes verwenden wir die Fensterfunktion over ()... Wir verwenden es, um das maximale Gehalt in der gesamten Organisation zu erhalten, da die Größe des "Fensters" nicht angegeben ist. Over () mit leeren Klammern gilt für die gesamte Auswahl. Daher beträgt das maximale Gehalt überall 10.000. Das Ergebnis der Aktion der Fensterfunktion wird zu jeder Zeile hinzugefügt.
Wenn wir die Erwähnung der Fensterfunktion aus der vierten Zeile der Abfrage entfernen, d.h. es bleibt nur max (Gehalt) übrig , die Anfrage funktioniert nicht. Das Höchstgehalt konnte einfach nicht berechnet werden. Da die Daten zeilenweise verarbeitet würden und zum Zeitpunkt des Anrufs von max (Gehalt) nur eine Nummer in der aktuellen Zeile vorhanden wäre, d. H. aktueller Angestellter. Hier sehen Sie den Vorteil der Fensterfunktion. Zum Zeitpunkt des Anrufs funktioniert es mit dem gesamten Fenster und mit allen verfügbaren Daten.
Schauen wir uns ein anderes Beispiel an, in dem Sie das maximale Gehalt jeder Abteilung anzeigen müssen:
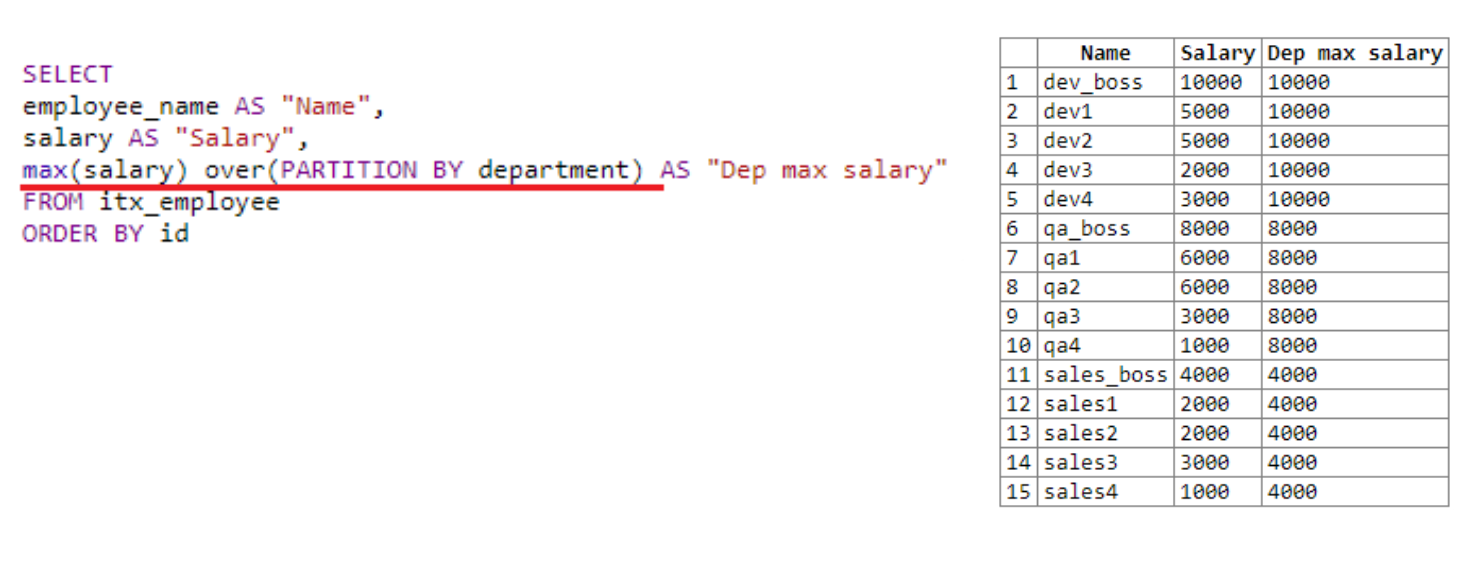
Tatsächlich legen wir den Rahmen für das "Fenster" fest und unterteilen es in Abteilungen. Wir verwenden die Abteilung als Ranking-Beispiel. Wir haben drei Abteilungen: dev, qa und sales.
"Fenster" findet das maximale Gehalt für jede Abteilung. Als Ergebnis der Auswahl sehen wir, dass das maximale Gehalt zuerst für Entwickler, dann für QA und dann für Verkäufe ermittelt wurde. Wie oben erwähnt, wird das Ergebnis der Fensterfunktion in das Abrufergebnis jeder Zeile geschrieben.
Im vorherigen Beispiel wurden die Klammern nach over nicht angegeben. Hier haben wir PARTITION BY verwendet, mit dem wir die Größe unseres Fensters einstellen konnten. Hier können Sie einige zusätzliche Informationen angeben, Servicebefehle senden, z. B. Zeilennummer.
Fazit
SQL ist nicht so einfach, wie es auf den ersten Blick scheint. Alles, was oben beschrieben wurde, ist die Grundfunktionalität von Fensterfunktionen. Mit ihrer Hilfe können wir unsere Anfragen „vereinfachen“. In ihnen steckt jedoch noch viel mehr Potenzial: Es gibt Dienstprogrammoperatoren (z. B. ROWS oder RANGE), die kombiniert werden können, um Abfragen mehr Funktionalität hinzuzufügen.
Ich hoffe, der Beitrag war für alle nützlich, die sich für dieses Thema interessieren.