
Foto von der Unsplash- Website . Von Sasha • Geschichten
Scikit-learn ist eine der am häufigsten verwendeten Python-Bibliotheken für maschinelles Lernen. Die einfache Standardschnittstelle ermöglicht die Vorverarbeitung, Schulung, Optimierung und Modellbewertung von Daten.
Dieses Projekt wurde von David Cournapeau entworfen, wurde im Rahmen des Google Summer of Code-Programms geboren und 2010 veröffentlicht. Seit ihrer Gründung hat sich die Bibliothek zu einer umfassenden Infrastruktur für die Erstellung von Modellen für maschinelles Lernen entwickelt. Mit den neuen Funktionen können Sie noch mehr Aufgaben lösen und die Benutzerfreundlichkeit verbessern. In diesem Artikel werde ich zehn der interessantesten Funktionen vorstellen, die Sie möglicherweise nicht kennen.
1. Integrierte Datensätze
In der Scikit-Learn-API finden Sie integrierte Datensätze, die sowohl generierte als auch tatsächliche Daten enthalten . Sie können sie mit nur einer Codezeile verwenden. Solche Daten sind äußerst nützlich, wenn Sie gerade lernen oder einfach nur schnell etwas testen möchten.
Mithilfe eines speziellen Tools können Sie außerdem selbst synthetische Daten für Regressions-
make_regression(), Clustering- make_blobs()und Klassifizierungsaufgaben generieren make_classification().
Jede Methode erzeugt Daten, die bereits in X (Features) und Y (Zielvariable) unterteilt sind, sodass sie direkt zum Trainieren des Modells verwendet werden können.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Zugriff auf öffentliche Datensätze von Drittanbietern
Wenn Sie direkt über scikit-learn auf eine Vielzahl öffentlicher Datensätze zugreifen möchten, sehen Sie sich die praktische Funktion an, mit der Sie Daten direkt von openml.org importieren können . Diese Site enthält über 21.000 verschiedene Datensätze, die in Projekten für maschinelles Lernen verwendet werden können.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Bereiten Sie Klassifikatoren für das Training von Basismodellen vor
Wenn Sie ein Modell für maschinelles Lernen für ein Projekt erstellen, ist es ratsam, zuerst ein Basismodell zu erstellen. Es ist ein Dummy-Modell, das immer die häufigste Klasse vorhersagt. Auf diese Weise erhalten Sie Benchmarks für das Benchmarking Ihres komplexeren Modells. Darüber hinaus können Sie sich der Qualität seiner Arbeit sicher sein, dass beispielsweise mehr als nur ein Satz zufällig ausgewählter Daten erzeugt wird.
Die Scikit-Learn-Bibliothek bietet eine
DummyClassifier()für Klassifizierungsprobleme und DummyRegressor()für die Arbeit mit Regression.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. Eigene API zur Visualisierung
Scikit-learn verfügt über eine integrierte Visualisierungs-API , mit der Sie die Funktionsweise Ihres Modells visualisieren können, ohne andere Bibliotheken importieren zu müssen. Es bietet die folgenden Optionen: Abhängigkeitsdiagramme, Fehlermatrix, ROC-Kurven und Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()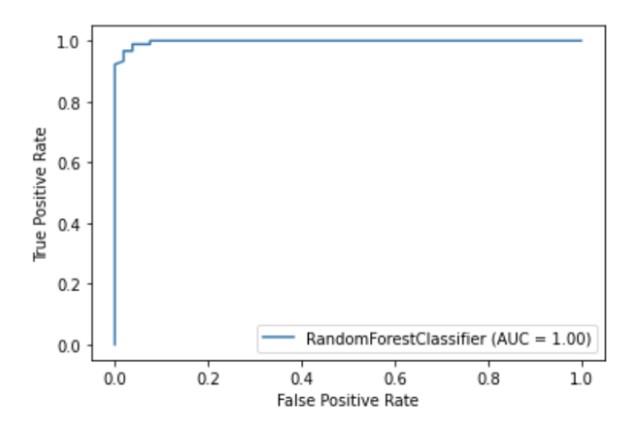
Illustration des Autors
5. Integrierte Methoden zur Funktionsauswahl
Eine Möglichkeit, die Qualität des Modells zu verbessern, besteht darin, nur die nützlichsten Funktionen für das Training zu verwenden oder die am wenigsten informativen zu entfernen. Dieser Vorgang wird als Funktionsauswahl bezeichnet.
Scikit-learn verfügt über eine Reihe von Methoden zur Durchführung der Feature-Auswahl , von denen eine ist
SelectPercentile(). Diese Methode wählt das X-Perzentil der informativsten Merkmale basierend auf der angegebenen statistischen Schätzmethode aus.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Pipelines zum Verbinden von Phasen des maschinellen Lernens
Scikit-learn kann nicht nur eine große Liste von Algorithmen für maschinelles Lernen verwenden, sondern bietet auch eine Reihe von Funktionen für die Vorverarbeitung und Datentransformation. Um die Reproduzierbarkeit und Zugänglichkeit im Prozess des maschinellen Lernens in Scikit-Learn zu gewährleisten, wurde eine Pipeline erstellt , die die verschiedenen Schritte und die Vorverarbeitungsphase des Trainingsmodells zusammenführt.
Die Pipeline speichert alle Phasen des Workflows als ein einziges Objekt, das von den Anpassungs- und Vorhersagemethoden aufgerufen werden kann. Wenn Sie die Anpassungsmethode für ein Pipeline-Objekt ausführen, werden Vorverarbeitungs- und Modellschulungsschritte automatisch ausgeführt.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer zum Variieren der Vorverarbeitungsmethoden für verschiedene Funktionen
Viele Datensätze enthalten verschiedene Arten von Features, für deren Vorverarbeitung mehrere verschiedene Phasen erforderlich sind. Beispielsweise könnten Sie mit einer Mischung aus kategorialen und numerischen Daten konfrontiert sein, und Sie möchten möglicherweise numerische Spalten skalieren und kategoriale Features mithilfe einer One-Hot-Codierung in numerische konvertieren.
Die Scikit-Learn-Pipeline ist mit einer ColumnTransformer- Funktion ausgestattet , mit der Sie auf einfache Weise die am besten geeignete Vorverarbeitungsmethode für bestimmte Spalten durch Indizierung oder Angabe der Spaltennamen angeben können.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Holen Sie sich einfach ein HTML-Bild Ihrer Pipeline
Pipelines werden oft sehr komplex, insbesondere wenn mit realen Daten gearbeitet wird. Daher ist es sehr praktisch, dass Sie mit scikit-learn ein HTML-Diagramm Ihrer Pipeline-Schritte ausgeben können .
from sklearn import set_config
set_config(display='diagram')
lr
Illustration des Autors
9. Plotfunktion zur Visualisierung von Entscheidungsbäumen
Mit dieser Funktion
plot_tree()können Sie ein Diagramm der im Entscheidungsbaummodell vorhandenen Schritte erstellen.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. Viele Bibliotheken von Drittanbietern, die Scikit-Lernfunktionen erweitern
Es gibt viele Bibliotheken von Drittanbietern, die mit scikit-learn kompatibel sind und dieses erweitern.
Zum Beispiel die Category Encoders- Bibliothek , die eine größere Auswahl an Vorverarbeitungsmethoden für kategoriale Features bietet, oder die ELI5- Bibliothek für eine detailliertere Modellinterpretation.
Auf beide Ressourcen kann auch direkt über die Scikit-Learn-Pipeline zugegriffen werden.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))Vielen Dank für Ihre Aufmerksamkeit!