Motivationsansatz
Der allgemein akzeptierte Ansatz für Computer-Vision-Aufgaben besteht darin, Bilder als 3D-Array (Höhe, Breite, Anzahl der Kanäle) zu verwenden und Windungen auf sie anzuwenden. Dieser Ansatz hat mehrere Nachteile:
- Nicht alle Pixel sind gleich. Wenn wir beispielsweise eine Klassifizierungsaufgabe haben, ist das Objekt selbst für uns wichtiger als der Hintergrund. Es ist interessant, dass die Autoren nicht sagen, dass Aufmerksamkeit bereits bei Computer-Vision-Aufgaben verwendet wird.
- Faltungen funktionieren mit Pixeln, die weit voneinander entfernt sind, nicht gut genug. Es gibt Ansätze mit erweiterten Windungen und globalem Durchschnittspooling, aber sie lösen das Problem selbst nicht.
- Faltungen sind in sehr tiefen neuronalen Netzen nicht effizient genug.
Infolgedessen schlagen die Autoren Folgendes vor: Konvertieren Sie Bilder in visuelle Token und senden Sie sie an den Transformator.

- Zunächst wird ein reguläres Backbone verwendet, um Feature-Maps abzurufen
- Als Nächstes wird die Feature-Map in visuelle Token konvertiert
- Token werden Transformatoren zugeführt
- Der Transformatorausgang kann für Klassifizierungsprobleme verwendet werden
- Wenn Sie den Ausgang des Transformators mit einer Feature-Map kombinieren, können Sie Vorhersagen für Segmentierungsaufgaben erhalten
Unter den Arbeiten in ähnlichen Richtungen erwähnen die Autoren immer noch Aufmerksamkeit, beachten jedoch, dass Aufmerksamkeit normalerweise auf Pixel angewendet wird, was die Rechenkomplexität erheblich erhöht. Sie sprechen auch über Arbeiten zur Verbesserung der Effizienz neuronaler Netze, glauben jedoch, dass sie in den letzten Jahren immer weniger Verbesserungen erzielt haben, weshalb nach anderen Ansätzen gesucht werden muss.
Visueller Transformator
Schauen wir uns nun genauer an, wie das Modell funktioniert.
Wie oben erwähnt, verfügen die Backbone-Abrufe über Karten, die an die visuellen Transformatorschichten übergeben werden.
Jeder visuelle Transformator besteht aus drei Teilen: einem Tokenizer, einem Transformator und einem Projektor.
Tokenizer

Der Tokenizer ruft visuelle Token ab. Tatsächlich nehmen wir eine Feature-Map, führen eine Umformung in (H * W, C) durch und daraus erhalten wir Token. Die

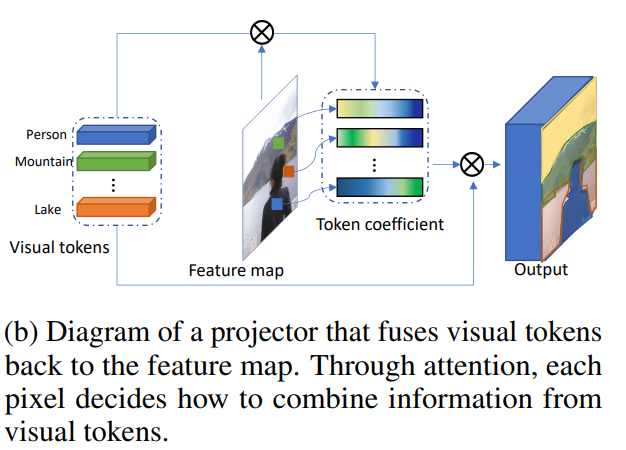
Visualisierung der Koeffizienten für Token sieht folgendermaßen aus:

Positionscodierung
Wie üblich benötigen Transformatoren nicht nur Token, sondern auch Informationen über ihre Position.

Zuerst machen wir ein Downsample, dann multiplizieren wir mit den Trainingsgewichten und verketten mit Token. Um die Anzahl der Kanäle anzupassen, können Sie eine 1D-Faltung hinzufügen.
Transformator
Schließlich der Transformator selbst.

Kombinieren von visuellen Token und Feature-Map
Das macht Projektor.

Dynamische Tokenisierung
Nach der ersten Schicht von Transformatoren können wir nicht nur neue visuelle Token extrahieren, sondern auch diejenigen verwenden, die aus den vorherigen Schritten extrahiert wurden. Trainierte Gewichte werden verwendet, um sie zu kombinieren:

Verwenden visueller Transformatoren zum Erstellen von Computer-Vision-Modellen
Darüber hinaus beschreiben die Autoren, wie das Modell auf Computer-Vision-Probleme angewendet wird. Transformatorblöcke haben drei Hyperparameter: die Anzahl der Kanäle in der Merkmalskarte C, die Anzahl der Kanäle im visuellen Token Ct und die Anzahl der visuellen Token L.
Wenn sich die Anzahl der Kanäle beim Umschalten zwischen den Blöcken des Modells als ungeeignet herausstellt, werden 1D- und 2D-Faltungen verwendet, um die erforderliche Anzahl von Kanälen zu erhalten.
Verwenden Sie Gruppenfaltungen, um Berechnungen zu beschleunigen und die Größe des Modells zu verringern.
Die Autoren fügen dem Artikel ** Pseudocode ** -Blöcke hinzu. Der vollwertige Code wird voraussichtlich in Zukunft veröffentlicht.
Bildklassifizierung
Wir nehmen ResNet und erstellen darauf basierend Visual-Transformator-ResNets (VT-ResNet).
Wir verlassen die Stufe 1-4, setzen aber anstelle der letzten visuelle Transformatoren ein.
Backbone-Exit - 14 x 14 Feature Map, Anzahl der Kanäle 512 oder 1024 je nach VT-ResNet-Tiefe. Aus der Feature-Map werden 8 visuelle Token für 1024 Kanäle erstellt. Der Ausgang des Transformators geht zur Klassifizierung an den Kopf.

Semantische Segmentierung
Für diese Aufgabe wird das panoptische Feature-Pyramid-Netzwerk (FPN) als Basismodell verwendet.
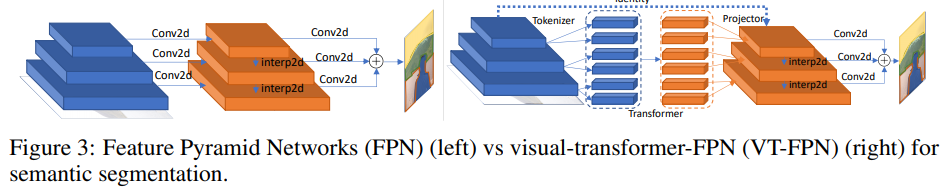
In FPN arbeiten Faltungen mit hochauflösenden Bildern, sodass das Modell schwer ist. Die Autoren ersetzen diese Operationen durch einen visuellen Transformator. Wieder 8 Token und 1024 Kanäle.
Experimente
ImageNet-Klassifizierung
Trainieren Sie 400 Epochen mit RMSProp. Sie beginnen mit einer Lernrate von 0,01, steigen während 5 Aufwärmphasen auf 0,16 und multiplizieren dann jede Epoche mit 0,9875. Chargennormalisierung und Chargengröße 2048 werden verwendet: Etikettenglättung, AutoAugment, stochastische Tiefenüberlebenswahrscheinlichkeit 0,9, Ausfall 0,2, EMA 0,99985.
So viele Experimente musste ich durchführen, um all dies zu finden ...
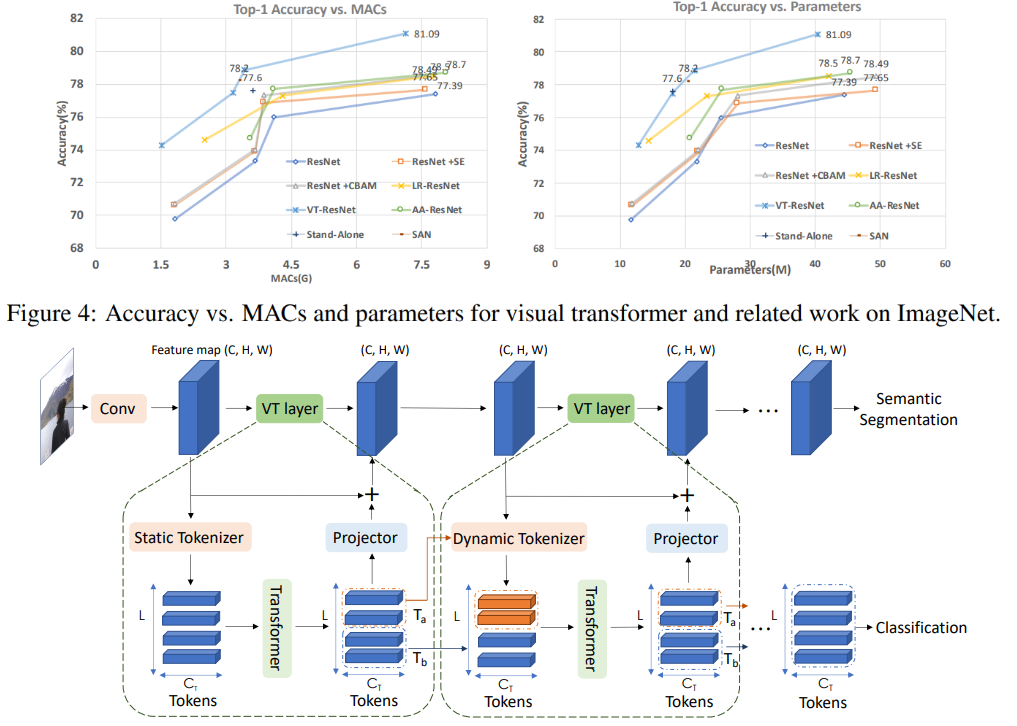
In dieser Grafik sehen Sie, dass der Ansatz eine höhere Qualität mit einer reduzierten Anzahl von Berechnungen und der Größe des Modells ergibt. Artikeltitel
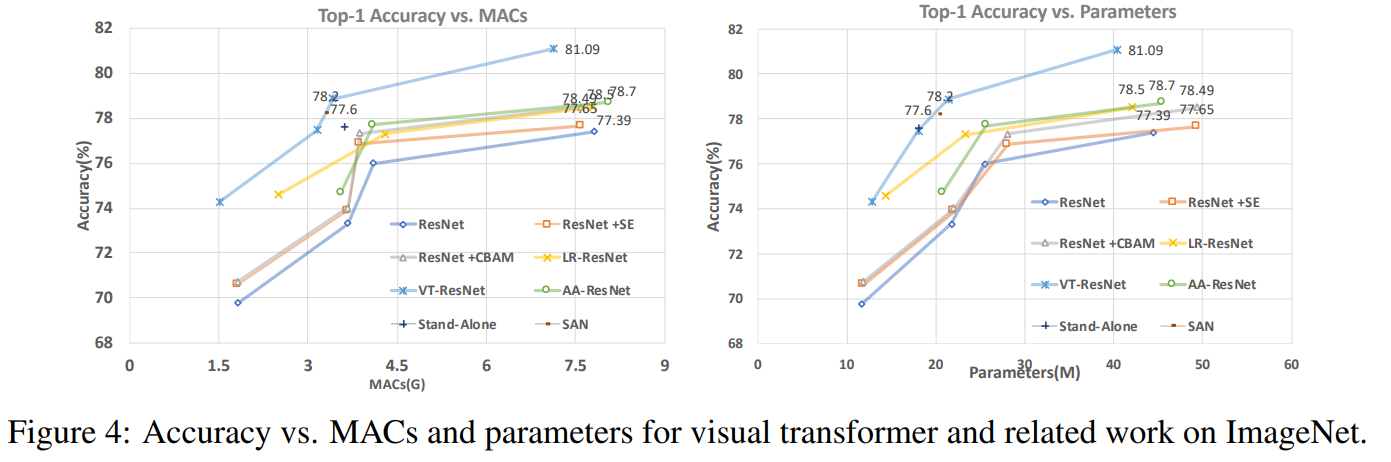
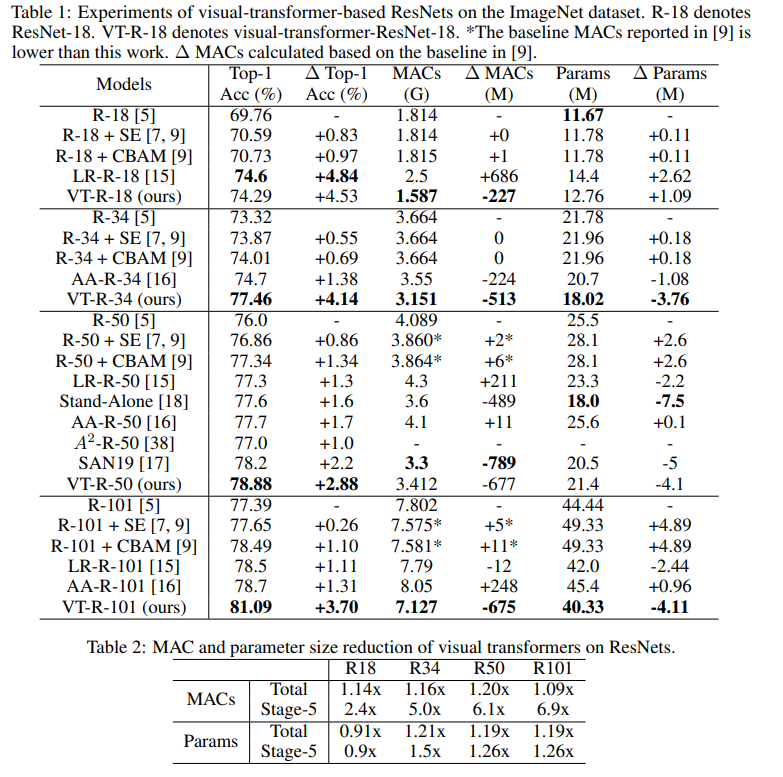
für verglichene Modelle:
ResNet + CBAM - Faltungsblock-Aufmerksamkeitsmodul
ResNet + SE - Quetsch- und Anregungsnetzwerke
LR-ResNet - Lokale Beziehungsnetzwerke zur Bilderkennung
StandAlone - Eigenständige Selbstaufmerksamkeit in
Bildverarbeitungsmodellen AA-ResNet - Aufmerksamkeitsverstärkte Faltungsnetzwerke
SAN - Erkundung der Selbstaufmerksamkeit für die Bilderkennung
Ablationsstudie
Um die Experimente zu beschleunigen, haben wir VT-ResNet- {18, 34} genommen und 90 Epochen trainiert.
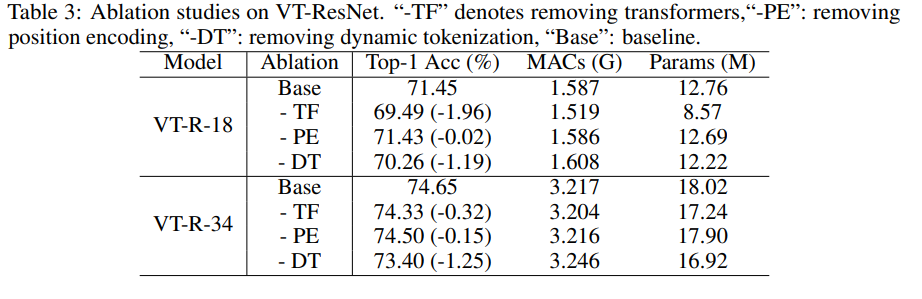
Die Verwendung von Transformatoren anstelle von Windungen bietet den größten Gewinn. Die dynamische Tokenisierung anstelle der statischen Tokenisierung gibt ebenfalls einen großen Schub. Die Positionscodierung verbessert sich nur geringfügig.
Segmentierungsergebnisse

Wie Sie sehen können, ist die Metrik nur geringfügig gewachsen, aber das Modell verbraucht 6,5-mal weniger MAC.
Mögliche Zukunft des Ansatzes
Experimente haben gezeigt, dass der vorgeschlagene Ansatz es ermöglicht, effizientere Modelle (in Bezug auf die Rechenkosten) zu erstellen, die gleichzeitig eine bessere Qualität erzielen. Die vorgeschlagene Architektur funktioniert erfolgreich für verschiedene Aufgaben der Computer Vision, und es besteht die Hoffnung, dass ihre Anwendung dazu beitragen wird, Systeme mit Comuter Vision zu verbessern - AR / VR, autonome Autos und andere.
Die Überprüfung wurde von Andrey Lukyanenko, dem führenden Entwickler von MTS, vorbereitet.