
Hallo Khabrovites. Heute werden wir über RxJava sprechen. Ich weiß, dass ein Wagen und ein kleiner Karren über sie geschrieben wurden, aber es scheint mir, dass ich ein paar interessante Punkte habe, die es wert sind, geteilt zu werden. Zunächst werde ich Ihnen erklären, wie wir RxJava zusammen mit der VIPER-Architektur für Android-Anwendungen verwenden, und einen Blick auf die "klassische" Art der Verwendung werfen. Lassen Sie uns danach die Hauptfunktionen von RxJava durchgehen und detaillierter auf die Funktionsweise der Scheduler eingehen. Wenn Sie sich bereits mit Snacks eingedeckt haben, sind Sie unter Katze willkommen.
Eine Architektur, die jedem passt
RxJava ist eine Implementierung des ReactiveX-Konzepts und wurde von Netflix erstellt. Ihr Blog enthält eine Reihe von Artikeln darüber, warum sie es getan haben und welche Probleme sie gelöst haben. Links (1, 2) finden Sie am Ende des Artikels. Netflix verwendete RxJava auf der Serverseite (Backend), um die Verarbeitung einer großen Anfrage zu parallelisieren. Obwohl sie eine Möglichkeit vorgeschlagen haben, RxJava im Backend zu verwenden, eignet sich diese Architektur zum Schreiben verschiedener Arten von Anwendungen (Mobil, Desktop, Backend und viele andere). Die Netflix-Entwickler haben RxJava in der Service-Schicht so verwendet, dass jede Methode der Service-Schicht eine Observable zurückgibt. Der Punkt ist, dass Elemente in einem Observable synchron und asynchron geliefert werden können. Auf diese Weise kann die Methode selbst entscheiden, ob der Wert sofort synchron zurückgegeben werden soll (z. B.falls im Cache verfügbar) oder rufen Sie diese Werte zuerst ab (z. B. aus einer Datenbank oder einem Remotedienst) und geben Sie sie asynchron zurück. In jedem Fall kehrt die Steuerung sofort nach dem Aufruf der Methode zurück (entweder mit oder ohne Daten).
/**
* , ,
* , ,
* callback `onNext()`
*/
public Observable<T> getProduct(String name) {
if (productInCache(name)) {
// ,
return Observable.create(observer -> {
observer.onNext(getProductFromCache(name));
observer.onComplete();
});
} else {
//
return Observable.<T>create(observer -> {
try {
//
T product = getProductFromRemoteService(name);
//
observer.onNext(product);
observer.onComplete();
} catch (Exception e) {
observer.onError(e);
}
})
// Observable IO
// /
.subscribeOn(Schedulers.io());
}
}
Mit diesem Ansatz erhalten wir eine unveränderliche API für den Client (in unserem Fall den Controller) und verschiedene Implementierungen. Der Client interagiert immer auf die gleiche Weise mit dem Observable. Es spielt überhaupt keine Rolle, ob die Werte synchron empfangen werden oder nicht. Gleichzeitig können API-Implementierungen von synchron zu asynchron wechseln, ohne die Interaktion mit dem Client in irgendeiner Weise zu beeinträchtigen. Mit diesem Ansatz können Sie überhaupt nicht darüber nachdenken, wie Sie Multithreading organisieren und sich auf die Implementierung von Geschäftsaufgaben konzentrieren können.
Der Ansatz ist nicht nur auf die Service-Schicht im Backend anwendbar, sondern auch auf die Architekturen MVC, MVP, MVVM usw. Für MVP können wir beispielsweise eine Interactor-Klasse erstellen, die für den Empfang und das Speichern von Daten in verschiedenen Quellen verantwortlich ist, und alles erstellen seine Methoden gaben Observable zurück. Sie werden ein Vertrag für die Interaktion mit Model sein. Auf diese Weise kann Presenter auch die volle Leistung der in RxJava verfügbaren Operatoren nutzen.
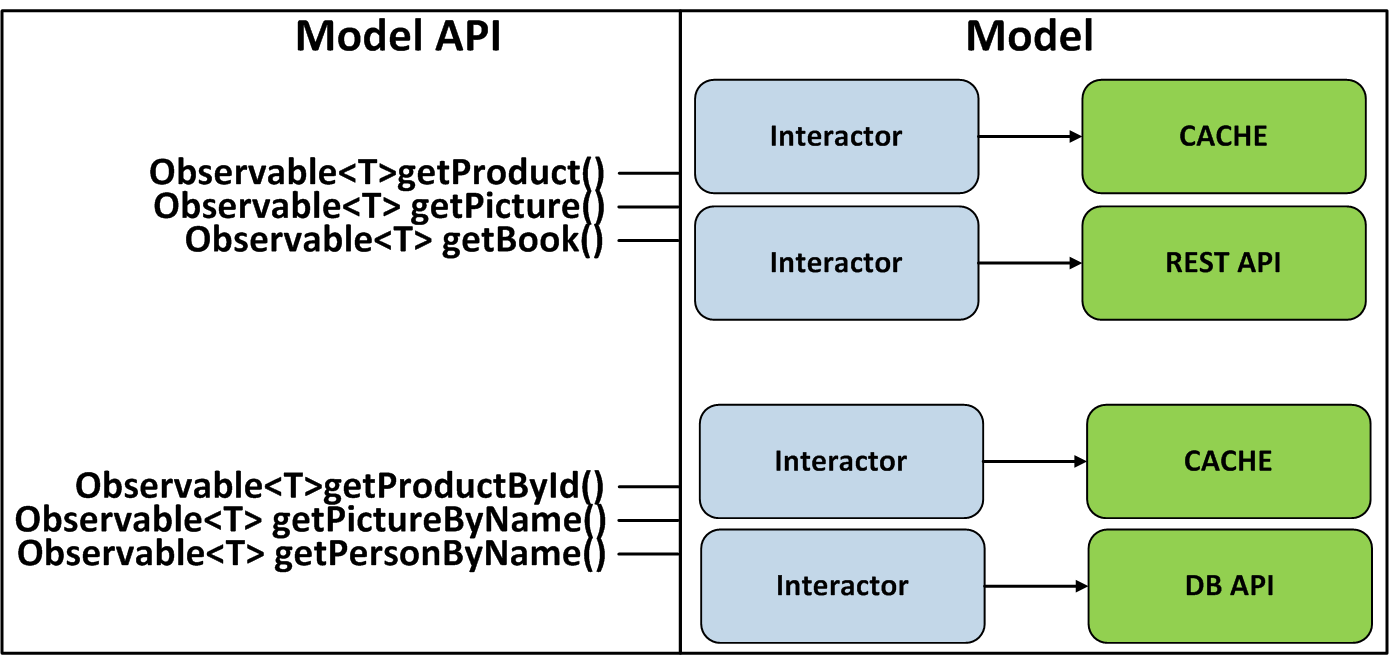
Wir können noch weiter gehen und den Presenter zu einer reaktiven API machen, aber dafür müssen wir den Abmeldemechanismus korrekt implementieren, der es allen Ansichten ermöglicht, sich gleichzeitig vom Presenter abzumelden.
Schauen wir uns als nächstes ein Beispiel an, wie dieser Ansatz für die VIPER-Architektur angewendet wird, bei der es sich um ein erweitertes MVP handelt. Beachten Sie auch, dass Sie keine Observable-Singleton-Objekte erstellen können, da Abonnements für solche Observable Speicherlecks verursachen.
Erfahrung in Android und VIPER
In den meisten aktuellen und neuen Android-Projekten verwenden wir die VIPER-Architektur. Ich traf sie, als ich mich einem der Projekte anschloss, in denen sie bereits eingesetzt wurde. Ich erinnere mich, dass ich überrascht war, als ich gefragt wurde, ob ich auf iOS schaue. "IOS in einem Android-Projekt?", Dachte ich. In der Zwischenzeit kam VIPER aus der iOS-Welt zu uns und ist in der Tat eine strukturiertere und modularere Version von MVP. VIPER ist in diesem Artikel (3) sehr gut geschrieben.
Zuerst schien alles in Ordnung zu sein: richtig geteilte, nicht überladene Schichten, jede Schicht hat ihren eigenen Verantwortungsbereich, klare Logik. Aber nach einiger Zeit trat ein Nachteil auf, und als das Projekt wuchs und sich veränderte, begann es sogar zu stören.
Tatsache ist, dass wir Interactor genauso verwendet haben wie unsere Kollegen in unserem Artikel. Interactor implementiert einen kleinen Anwendungsfall, z. B. "Produkte aus dem Netzwerk herunterladen" oder "Ein Produkt anhand der ID aus der Datenbank übernehmen" und führt Aktionen im Workflow aus. Intern führt der Interactor Operationen mit einem Observable aus. Um den Interactor "auszuführen" und das Ergebnis zu erhalten, implementiert der Benutzer die ObserverEntity-Schnittstelle zusammen mit den Methoden onNext, onError und onComplete und übergibt sie zusammen mit den Parametern an die Methode execute (params, ObserverEntity).
Sie haben das Problem wahrscheinlich bereits bemerkt - die Struktur der Schnittstelle. In der Praxis benötigen wir selten alle drei Methoden, oft werden eine oder zwei davon verwendet. Aus diesem Grund werden in Ihrem Code möglicherweise leere Methoden angezeigt. Natürlich können wir alle Methoden der Schnittstelle als Standard markieren, aber solche Methoden werden eher benötigt, um den Schnittstellen neue Funktionen hinzuzufügen. Außerdem ist es seltsam, eine Schnittstelle zu haben, in der alle Methoden optional sind. Wir können zum Beispiel auch eine abstrakte Klasse erstellen, die eine Schnittstelle erbt und die benötigten Methoden überschreibt. Oder erstellen Sie schließlich überladene Versionen der Methode execute (params, ObserverEntity), die ein bis drei Funktionsschnittstellen akzeptieren. Dieses Problem ist schlecht für die Lesbarkeit des Codes, aber zum Glück ist es recht einfach zu lösen. Sie ist jedoch nicht die einzige.
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
// ,
//
}
@Override
public void onError(Throwable throwable) {
//
// -
}
@Override
public void onComplete() {
//
// -
}
});
Neben leeren Methoden gibt es ein ärgerlicheres Problem. Wir verwenden Interactor, um eine Aktion auszuführen, aber fast immer ist diese Aktion nicht die einzige. Zum Beispiel können wir ein Produkt aus einer Datenbank nehmen, dann Bewertungen und ein Bild darüber erhalten, dann alles an einem anderen Ort speichern und schließlich zu einem anderen Bildschirm wechseln. Hier hängt jede Aktion von der vorherigen ab, und bei Verwendung von Interactors erhalten wir eine große Kette von Rückrufen, deren Nachverfolgung sehr mühsam sein kann.
private void checkProduct(int id, Locale locale) {
getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale), new ObserverEntity<Product>() {
@Override
public void onNext(Product product) {
getProductInfo(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void getProductInfo(Product product) {
getReviewsByProductIdInteractor.execute(product.getId(), new ObserverEntity<List<Review>>() {
@Override
public void onNext(List<Review> reviews) {
product.setReviews(reviews);
saveProduct(productInfo);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
// -
}
});
getImageForProductInteractor.execute(product.getId(), new ObserverEntity<Image>() {
@Override
public void onNext(Image image) {
product.setImage(image);
saveProduct(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void saveProduct(Product product) {
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
goToSomeScreen();
}
});
}
Wie gefällt dir diese Makkaroni? Gleichzeitig haben wir eine einfache Geschäftslogik und eine einfache Verschachtelung, aber stellen Sie sich vor, was mit komplexerem Code passieren würde. Es macht es auch schwierig, die Methode wiederzuverwenden und verschiedene Scheduler für den Interactor anzuwenden.
Die Lösung ist überraschend einfach. Haben Sie das Gefühl, dass dieser Ansatz versucht, das Verhalten eines Observablen nachzuahmen, aber er macht es falsch und erzeugt selbst seltsame Einschränkungen? Wie ich bereits sagte, haben wir diesen Code aus einem bestehenden Projekt erhalten. Bei der Korrektur dieses Legacy-Codes werden wir den Ansatz verwenden, den uns die Jungs von Netflix hinterlassen haben. Anstatt jedes Mal eine ObserverEntity implementieren zu müssen, lassen Sie den Interactor einfach eine Observable zurückgeben.
private Observable<Product> getProductById(int id, Locale locale) {
return getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale));
}
private Observable<Product> getProductInfo(Product product) {
return getReviewsByProductIdInteractor.execute(product.getId())
.map(reviews -> {
product.set(reviews);
return product;
})
.flatMap(product -> {
getImageForProductInteractor.execute(product.getId())
.map(image -> {
product.set(image);
return product;
})
});
}
private Observable<Product> saveProduct(Product product) {
return saveProductInteractor.execute(product);
}
private doAll(int id, Locale locale) {
//
getProductById (id, locale)
//
.flatMap(product -> getProductInfo(product))
//
.flatMap(product -> saveProduct(product))
//
.ignoreElements()
//
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
//
.subscribe(() -> goToSomeScreen(), throwable -> handleError());
}
Voila! So haben wir nicht nur diesen umständlichen und unhandlichen Horror beseitigt, sondern auch die Kraft von RxJava zu Presenter gebracht.
Konzepte im Herzen
Ich habe ziemlich oft gesehen, wie sie versucht haben, das Konzept von RxJava mithilfe der funktionalen reaktiven Programmierung (im Folgenden: FRP) zu erklären. Tatsächlich hat es nichts mit dieser Bibliothek zu tun. Bei FRP geht es mehr um kontinuierliche, sich dynamisch ändernde Bedeutungen (Verhaltensweisen), kontinuierliche Zeit und Denotationssemantik. Am Ende des Artikels finden Sie einige interessante Links (4, 5, 6, 7).
RxJava verwendet reaktive Programmierung und funktionale Programmierung als Kernkonzepte. Reaktive Programmierung kann als sequentielle Übertragung von Informationen vom beobachteten Objekt zum Beobachterobjekt beschrieben werden, so dass das Beobachterobjekt sie automatisch (asynchron) empfängt, wenn diese Informationen entstehen.
Die funktionale Programmierung verwendet das Konzept reiner Funktionen, dh solcher, die den externen Zustand nicht verwenden oder ändern. Sie sind vollständig von ihren Eingaben abhängig, um ihre Ausgaben zu erhalten. Das Fehlen von Nebenwirkungen für reine Funktionen ermöglicht es, die Ergebnisse einer Funktion als Eingabeparameter für eine andere zu verwenden. Dies ermöglicht es, eine unbegrenzte Funktionskette zusammenzustellen.
Wenn Sie diese beiden Konzepte zusammen mit den Observer- und Iterator-Mustern von GoF kombinieren, können Sie asynchrone Datenströme erstellen und diese mit einem riesigen Arsenal sehr praktischer Funktionen verarbeiten. Es macht es auch möglich, Multithreading sehr einfach und vor allem sicher zu verwenden, ohne über seine Probleme wie Synchronisation, Speicherinkonsistenz, Thread-Überlappung usw. nachzudenken.
Drei Wale von RxJava
Die drei Hauptkomponenten, auf denen RxJava basiert, sind Observable, Operatoren und Scheduler.
Observable in RxJava ist für die Implementierung des reaktiven Paradigmas verantwortlich. Observables werden häufig als Streams bezeichnet, da sie sowohl das Konzept von Datenströmen als auch die Weitergabe von Änderungen implementieren. Observable ist ein Typ, der eine reaktive Paradigmenimplementierung erreicht, indem zwei Muster aus der Viererbande kombiniert werden: Observer und Iterator. Observable fügt Observer zwei fehlende Semantiken hinzu, die sich in Iterable befinden:
- Die Fähigkeit des Produzenten, dem Verbraucher zu signalisieren, dass keine Daten mehr verfügbar sind (die foreach-Schleife auf dem Iterable endet und kehrt nur zurück; das Observable ruft in diesem Fall die onCompleate-Methode auf).
- Die Möglichkeit für den Hersteller, den Verbraucher darüber zu informieren, dass ein Fehler aufgetreten ist und das Observable keine Elemente mehr ausgeben kann (Iterable löst eine Ausnahme aus, wenn während der Iteration ein Fehler auftritt; Observable ruft onError bei seinem Beobachter auf und beendet ihn).
Wenn der Iterable den "Pull" -Ansatz verwendet, dh der Verbraucher einen Wert vom Produzenten anfordert und der Thread blockiert, bis dieser Wert eintrifft, ist der Observable sein "Push" -Äquivalent. Dies bedeutet, dass der Hersteller Werte erst dann an den Verbraucher sendet, wenn sie verfügbar sind.
Observable ist nur der Anfang von RxJava. Es ermöglicht Ihnen, Werte asynchron abzurufen, aber die eigentliche Leistung kommt mit "reaktiven Erweiterungen" (daher ReactiveX) - OperatorenHiermit können Sie Sequenzen von Elementen transformieren, kombinieren und erstellen, die von einem Observable ausgegeben werden. Hier tritt das Funktionsparadigma mit seinen reinen Funktionen in den Vordergrund. Die Betreiber nutzen dieses Konzept in vollem Umfang. Sie ermöglichen es Ihnen, sicher mit den Sequenzen von Elementen zu arbeiten, die ein Observable emittiert, ohne Angst vor Nebenwirkungen zu haben, es sei denn, Sie erstellen sie natürlich selbst. Mit Operatoren können Sie Multithreading verwenden, ohne sich um Probleme wie Thread-Sicherheit, Thread-Steuerung auf niedriger Ebene, Synchronisierung, Speicherinkonsistenzfehler, Thread-Overlays usw. kümmern zu müssen. Mit einem großen Arsenal an Funktionen können Sie problemlos mit verschiedenen Daten arbeiten. Dies gibt uns ein sehr mächtiges Werkzeug. Das Wichtigste ist, dass Operatoren die vom Observable ausgegebenen Elemente ändern, nicht das Observable selbst.Observables ändern sich nie, seit sie erstellt wurden. Wenn Sie über Threads und Operatoren nachdenken, denken Sie am besten in Diagrammen. Wenn Sie nicht wissen, wie Sie das Problem lösen können, schauen Sie sich die gesamte Liste der verfügbaren Operatoren an und überlegen Sie es sich noch einmal.
Obwohl das Konzept der reaktiven Programmierung selbst asynchron ist (nicht zu verwechseln mit Multithreading), werden standardmäßig alle Elemente in einer Observable synchron an den Abonnenten über denselben Thread gesendet, auf dem die subscribe () -Methode aufgerufen wurde. Um diese Asynchronität einzuführen, müssen Sie entweder die Methoden onNext (T), onError (Throwable) und onComplete () selbst in einem anderen Ausführungsthread aufrufen oder Scheduler verwenden. Normalerweise analysiert jeder sein Verhalten. Schauen wir uns also seine Struktur an.
Planerabstrahieren Sie den Benutzer von der Quelle der Parallelität hinter seiner eigenen API. Sie garantieren, dass sie unabhängig vom zugrunde liegenden Parallelitätsmechanismus (Implementierung) bestimmte Eigenschaften bereitstellen, z. B. Threads, Ereignisschleife oder Executor. Scheduler verwenden Daemon-Threads. Dies bedeutet, dass das Programm mit der Beendigung des Hauptausführungsthreads beendet wird, selbst wenn eine Berechnung innerhalb des Observable-Operators erfolgt.
RxJava verfügt über mehrere Standard-Scheduler, die für bestimmte Zwecke geeignet sind. Sie alle erweitern die abstrakte Scheduler-Klasse und implementieren ihre eigene Logik für die Verwaltung von Arbeitern. Beispielsweise bildet der ComputationScheduler zum Zeitpunkt seiner Erstellung einen Pool von Workern, deren Anzahl der Anzahl der Prozessorthreads entspricht. Der ComputationScheduler verwendet dann Worker, um ausführbare Aufgaben auszuführen. Sie können die ausführbare Datei mit den Methoden schedDirect () und SchedulePeriodicallyDirect () an den Scheduler übergeben. Bei beiden Methoden nimmt der Scheduler den nächsten Worker aus dem Pool und übergibt die ausführbare Datei an ihn.
Der Worker befindet sich im Scheduler und ist eine Entität, die ausführbare Objekte (Tasks) mithilfe eines von mehreren Parallelitätsschemata ausführt. Mit anderen Worten, der Scheduler empfängt die ausführbare Datei und übergibt sie zur Ausführung an den Worker. Sie können einen Worker auch unabhängig vom Scheduler abrufen und einen oder mehrere Runnable an ihn übertragen, unabhängig von anderen Workern und dem Scheduler selbst. Wenn ein Mitarbeiter eine Aufgabe erhält, stellt er sie in die Warteschlange. Der Mitarbeiter garantiert, dass Aufgaben nacheinander in der Reihenfolge ausgeführt werden, in der sie übermittelt wurden. Die Reihenfolge kann jedoch durch ausstehende Aufgaben gestört werden. Im ComputationScheduler wird der Worker beispielsweise mithilfe eines einzelnen Threads ScheduledExecutorService implementiert.
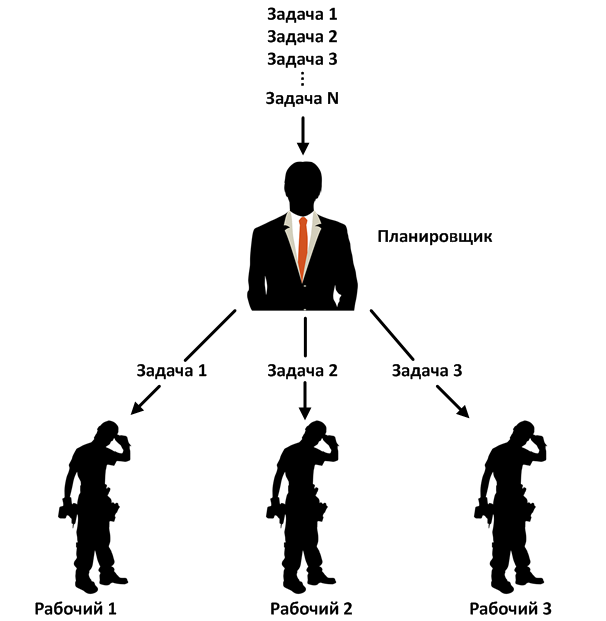
Wir haben also abstrakte Mitarbeiter, die jedes Parallelitätsschema implementieren können. Dieser Ansatz bietet viele Vorteile: Modularität, Flexibilität, eine API, verschiedene Implementierungen. Wir haben einen ähnlichen Ansatz in ExecutorService gesehen. Außerdem können wir Scheduler verwenden, die von Observable getrennt sind.
Fazit
RxJava ist eine sehr leistungsstarke Bibliothek, die auf vielfältige Weise in vielen Architekturen verwendet werden kann. Die Verwendungsmöglichkeiten sind nicht auf vorhandene beschränkt. Versuchen Sie daher immer, sie selbst anzupassen. Denken Sie jedoch an SOLID, DRY und andere Designprinzipien und vergessen Sie nicht, Ihre Erfahrungen mit Kollegen zu teilen. Ich hoffe, Sie konnten aus dem Artikel etwas Neues und Interessantes lernen, wir sehen uns!