Ich möchte die Erfahrungen mit der Implementierung modischer neuronaler Netze in unserem Unternehmen teilen. Alles begann, als wir beschlossen, einen eigenen Service Desk zu bauen. Warum und warum Sie selbst, können Sie meinen Kollegen Alexei Volkov lesen (cface) hier .
Ich erzähle Ihnen von einer jüngsten Innovation im System: einem neuronalen Netzwerk, das dem Disponenten der ersten Unterstützungslinie hilft. Bei Interesse herzlich willkommen bei cat.

Klärung der Aufgabe
Kopfschmerzen für jeden Helpdesk-Manager sind eine schnelle Entscheidung, eine eingehende Kundenanfrage zuzuweisen. Hier sind die Anfragen:
Guten Tag.
Ich verstehe richtig: Um einen Kalender für einen bestimmten Benutzer freizugeben, müssen Sie den Zugriff auf Ihren Kalender auf dem PC des Benutzers öffnen, der den Kalender freigeben möchte, und die E-Mail des Benutzers eingeben, auf den er Zugriff gewähren möchte.
Gemäß den Vorschriften muss der Dispatcher innerhalb von zwei Minuten antworten: einen Antrag registrieren, die Dringlichkeit bestimmen und eine verantwortliche Einheit ernennen. In diesem Fall wählt der Dispatcher aus 44 Unternehmensbereichen.
Die Anweisungen des Dispatchers beschreiben eine Lösung für die häufigsten Anfragen. Das Bereitstellen des Zugriffs auf ein Rechenzentrum ist beispielsweise eine einfache Anforderung. Serviceanfragen umfassen jedoch viele Aufgaben: Installieren von Software, Analysieren einer Situation oder Netzwerkaktivität, Herausfinden von Details zur Preisgestaltung von Lösungen, Überprüfen aller Arten von Zugriff. Manchmal ist es schwierig zu verstehen, an wen der Verantwortliche die Frage senden soll:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
Es gab Situationen, in denen die Anwendung auf die falsche Einheit ging. Die Anfrage wurde zur Arbeit gebracht und dann anderen Darstellern zugewiesen oder an den Dispatcher zurückgeschickt. Dies erhöhte die Geschwindigkeit der Lösung. Die Zeit für die Lösung von Anfragen ist in der Vereinbarung mit dem Kunden (SLA) festgelegt, und wir sind für die Einhaltung der Fristen verantwortlich.
Innerhalb des Systems haben wir beschlossen, einen Assistenten für Disponenten zu erstellen. Das Hauptziel bestand darin, Eingabeaufforderungen hinzuzufügen, mit denen der Mitarbeiter schneller eine Entscheidung über die Anwendung treffen kann.
Vor allem wollte ich dem neuen Trend nicht erliegen und den Chatbot in die erste Zeile der Unterstützung stellen. Wenn Sie jemals versucht haben, an einen solchen technischen Support zu schreiben (der damit bereits nicht sündigt), verstehen Sie, was ich meine.
Erstens versteht er Sie sehr schlecht und antwortet überhaupt nicht auf atypische Anfragen, und zweitens ist es sehr schwierig, eine lebende Person zu erreichen.
Im Allgemeinen hatten wir definitiv nicht vor, Disponenten durch Chat-Bots zu ersetzen, da wir möchten, dass Kunden weiterhin mit einer lebenden Person kommunizieren.
Zuerst dachte ich daran, billig und fröhlich auszusteigen und versuchte es mit dem Keyword-Ansatz. Wir haben manuell ein Wörterbuch mit Schlüsselwörtern zusammengestellt, aber das war nicht genug. Die Lösung kam nur mit einfachen Anwendungen zurecht, mit denen es keine Probleme gab.
Während der Arbeit unseres Service Desk haben wir eine solide Historie von Anfragen gesammelt, auf deren Grundlage wir ähnliche eingehende Anfragen erkennen und diese sofort den richtigen Ausführenden zuweisen können. Mit Google und einiger Zeit bewaffnet, beschloss ich, tiefer in meine Optionen einzutauchen.
Lerntheorie
Es stellte sich heraus, dass meine Aufgabe eine klassische Klassifizierungsaufgabe ist. Bei der Eingabe empfängt der Algorithmus den Primärtext der Anwendung, bei der Ausgabe ordnet er ihn einer der zuvor bekannten Klassen zu, dh den Unternehmensbereichen.
Es gab sehr viele Lösungen. Dies ist ein "neuronales Netzwerk" und ein "naiver Bayes'scher Klassifikator", "nächste Nachbarn", "logistische Regression", "Entscheidungsbaum", "Boosten" und viele, viele andere Optionen.
Es würde keine Zeit geben, alle Techniken auszuprobieren. Deshalb habe ich mich für neuronale Netze entschieden (ich wollte schon lange versuchen, mit ihnen zu arbeiten). Wie sich später herausstellte, war diese Wahl völlig gerechtfertigt.
Also begann ich von hier aus mit dem Eintauchen in neuronale Netze . Studierte LernalgorithmenNeuronale Netze: mit einem Lehrer (überwachtes Lernen), ohne Lehrer (unbeaufsichtigtes Lernen), mit teilweiser Beteiligung eines Lehrers (halbüberwachtes Lernen) oder „verstärkendes Lernen“.
Als Teil meiner Aufgabe kam die Unterrichtsmethode mit einem Lehrer auf. Es gibt mehr als genug Daten für das Training: über 100.000 gelöste Anwendungen.
Wahl der Implementierung
Ich habe die Encog Machine Learning Framework- Bibliothek für die Implementierung ausgewählt . Es wird mit einer zugänglichen und verständlichen Dokumentation mit Beispielen geliefert . Außerdem Implementierung für Java, die mir sehr nahe steht.
Kurz gesagt, die Mechanik der Arbeit sieht folgendermaßen aus:
- Das Framework des neuronalen Netzwerks ist vorkonfiguriert: mehrere Schichten von Neuronen, die durch Synapsenverbindungen verbunden sind.

- Ein Satz von Trainingsdaten mit einem vorbestimmten Ergebnis wird in den Speicher geladen.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
Ich habe verschiedene Beispiele des Frameworks ausprobiert und festgestellt, dass die Bibliothek mit Zahlen am Eingang mit einem Knall zurechtkommt. Das Beispiel mit der Definition einer Klasse von Iris durch die Größe der Schale und der Blütenblätter ( Fisher's Irises ) hat also gut funktioniert .
Aber ich habe einen Text. Das bedeutet, dass die Buchstaben irgendwie in Zahlen umgewandelt werden müssen. Also ging ich zur ersten Vorbereitungsphase über - der "Vektorisierung".
Die erste Option für die Vektorisierung: per Buchstabe
Der einfachste Weg, Text in Zahlen umzuwandeln, besteht darin, das Alphabet auf der ersten Ebene des neuronalen Netzwerks zu verwenden. Es stellt sich heraus, 33 Buchstaben-Neuronen: ABVGDEOZHZYKLMNOPRSTUFHTSCHSHSCHYEYUYA.
Jedem wird eine Ziffer zugewiesen: Das Vorhandensein eines Buchstabens in einem Wort wird als Eins angenommen, und das Fehlen wird als Null betrachtet.
Dann hat das Wort "Hallo" in dieser Codierung einen Vektor:

Ein solcher Vektor kann dem neuronalen Netzwerk bereits zum Training gegeben werden. Immerhin ist diese Zahl 001001000100000011010000000000000 = 1216454656 Nachdem
ich mich mit der Theorie befasst hatte, wurde mir klar, dass es keinen besonderen Sinn gibt, Buchstaben zu analysieren. Sie haben keine semantische Bedeutung. Beispielsweise steht der Buchstabe "A" in jedem Text des Vorschlags. Bedenken Sie, dass dieses Neuron immer eingeschaltet ist und keinen Einfluss auf das Ergebnis hat. Wie alle anderen Vokale. Und im Text der Bewerbung werden die meisten Buchstaben des Alphabets enthalten sein. Diese Option ist nicht geeignet.
Die zweite Variante der Vektorisierung: nach Wörterbuch
Und wenn Sie nicht Buchstaben, sondern Wörter nehmen? Sagen wir Dahls erklärendes Wörterbuch. Und um als 1 bereits das Vorhandensein eines Wortes im Text und die Abwesenheit - als 0 zu zählen.
Aber hier bin ich auf die Anzahl der Wörter gestoßen. Der Vektor wird sich als sehr groß herausstellen. Ein Neuron mit 200.000 Eingangsneuronen wird ewig dauern und viel Speicher und CPU-Zeit benötigen. Sie müssen Ihr eigenes Wörterbuch erstellen. Darüber hinaus gibt es eine IT-Spezifität in den Texten, die Vladimir Ivanovich Dal nicht kannte.
Ich wandte mich wieder der Theorie zu. Verwenden Sie die Mechanismen von N-Gramm - eine Folge von N Elementen, um das Vokabular bei der Verarbeitung von Texten zu verkürzen .
Die Idee ist, den Eingabetext in einige Segmente aufzuteilen, daraus ein Wörterbuch zu erstellen und das neuronale Netzwerk mit dem Vorhandensein oder Fehlen einer Phrase im Originaltext als 1 oder 0 zu versorgen. Das heißt, anstelle eines Buchstabens, wie im Fall des Alphabets, wird nicht nur ein Buchstabe, sondern eine ganze Phrase als 0 oder 1 angenommen.
Am beliebtesten sind Unigramme, Bigramme und Trigramme. Am Beispiel des Ausdrucks "Willkommen bei DataLine" werde ich Ihnen die einzelnen Methoden erläutern.
- Unigramm - Der Text ist in die Wörter "gut", "willkommen", "v", "DataLine" unterteilt.
- Bigram - wir teilen es in Wortpaare auf: "Willkommen", "Willkommen bei", "bei DataLine".
- Trigramm - ähnlich 3 Wörter: "Willkommen bei", "Willkommen bei DataLine".
- N-Gramm - Sie haben die Idee. Wie viele N, so viele Wörter hintereinander.
- N-. , . 4- N- : «»,« », «», «» . . .
Ich beschloss, mich auf das Unigramm zu beschränken. Aber nicht nur ein Unigramm - die Worte erwiesen sich immer noch als zu viel.
Der Algorithmus "Porter's Stemmer" kam zur Rettung , mit dem bereits 1980 Wörter vereinheitlicht wurden.
Das Wesentliche des Algorithmus: Entfernen Sie Suffixe und Endungen aus dem Wort und lassen Sie nur den grundlegenden semantischen Teil übrig. Zum Beispiel werden die Wörter "wichtig", "wichtig", "wichtig", "wichtig", "wichtig", "wichtig" auf die Basis "wichtig" gebracht. Das heißt, anstelle von 6 Wörtern gibt es eines im Wörterbuch. Und das ist eine deutliche Reduzierung.
Außerdem habe ich alle Zahlen, Satzzeichen, Präpositionen und seltenen Wörter aus dem Wörterbuch entfernt, um kein "Rauschen" zu verursachen. Als Ergebnis haben wir für 100.000 Texte ein Wörterbuch mit 3.000 Wörtern erhalten. Damit können Sie bereits arbeiten.
Neuronales Netzwerktraining
Also habe ich schon:
- Wörterbuch mit 3k Wörtern.
- Vektorisierte Wörterbuchdarstellung.
- Die Größen der Eingabe- und Ausgabeschichten des neuronalen Netzwerks. Gemäß der Theorie wird ein Wörterbuch auf der ersten Schicht (Eingabe) bereitgestellt, und die letzte Schicht (Ausgabe) ist die Anzahl der Lösungsklassen. Ich habe 44 davon - nach Anzahl der Unternehmensbereiche.
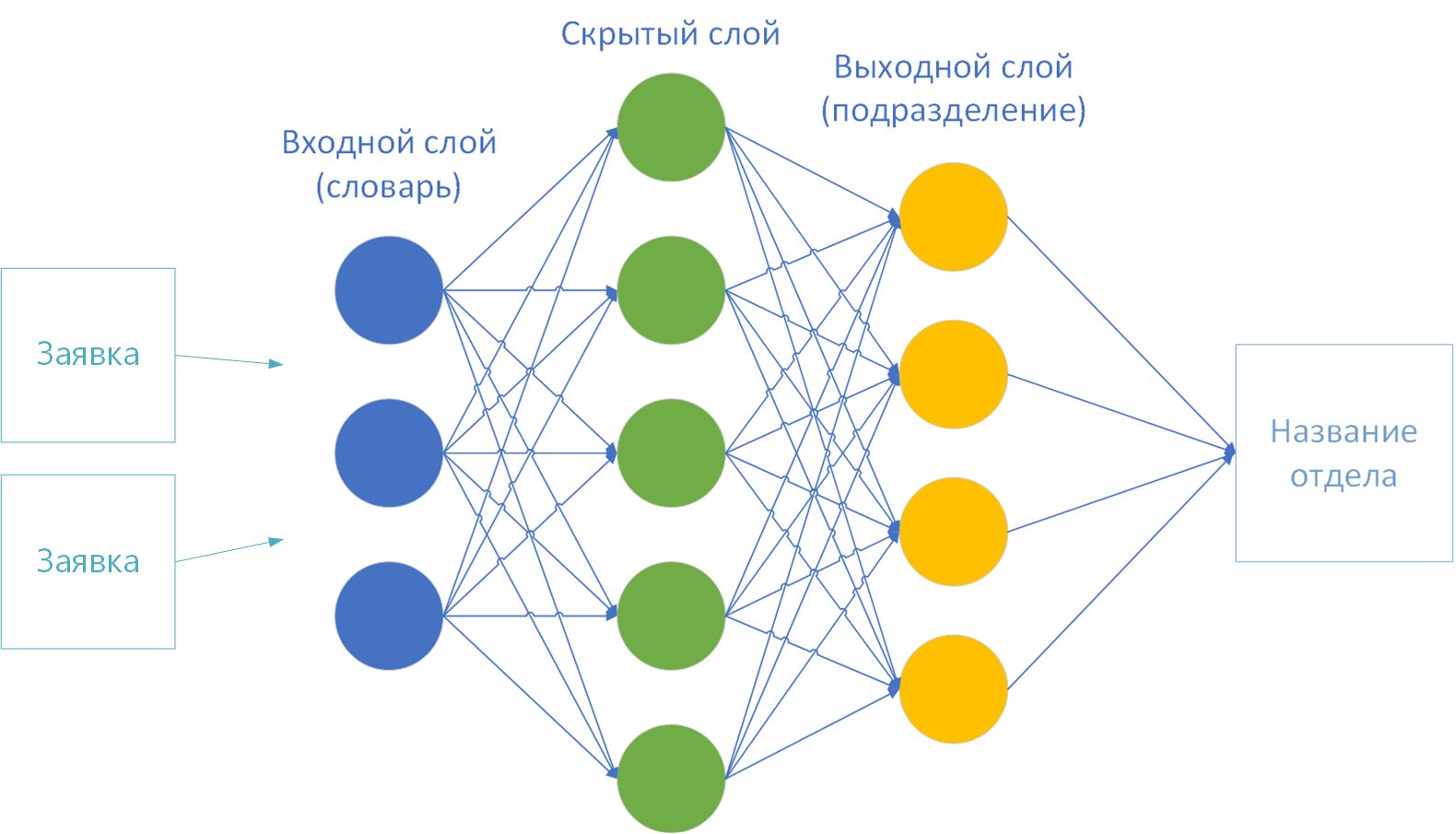
Um ein neuronales Netzwerk zu trainieren, bleibt nur noch sehr wenig zu wählen:
- Lehrmethode.
- Aktivierungsfunktion.
- Die Anzahl der ausgeblendeten Ebenen.
Wie ich die Parameter ausgewählt habe . Die Parameter werden immer empirisch für jede spezifische Aufgabe ausgewählt. Dies ist der längste und langwierigste Prozess, da viel experimentiert werden muss.
Also nahm ich eine Referenzprobe von 11k-Anwendungen und berechnete ein neuronales Netzwerk mit verschiedenen Parametern:
- Bei 10k trainierte ich ein neuronales Netzwerk.
- Bei 1k habe ich das bereits trainierte Netzwerk getestet.
Das heißt, bei 10k bauen wir einen Wortschatz auf und lernen. Und dann zeigen wir dem trainierten neuronalen Netzwerk 1k unbekannte Texte. Das Ergebnis ist der Prozentsatz des Fehlers: das Verhältnis der erratenen Einheiten zur Gesamtzahl der Texte.
Infolgedessen erreichte ich bei unbekannten Daten eine Genauigkeit von ca. 70%.
Empirisch fand ich heraus, dass das Training unbegrenzt fortgesetzt werden kann, wenn die falschen Parameter gewählt werden. Ein paar Mal ging das Neuron in einen endlosen Berechnungszyklus und hängte die Arbeitsmaschine für die Nacht auf. Um dies zu verhindern, habe ich das Limit von 100 Iterationen akzeptiert oder bis der Netzwerkfehler nicht mehr abnimmt.
Hier sind die Parameter:
Lehrmethode . Encog bietet verschiedene Optionen zur Auswahl: Backpropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
Dies sind verschiedene Methoden zur Bestimmung der Gewichte an Synapsen. Einige der Methoden arbeiten schneller, andere sind präziser, es ist besser, mehr in der Dokumentation zu lesen. Resilient Propagation hat bei mir gut funktioniert .
Aktivierungsfunktion . Es ist erforderlich, den Wert des Neurons am Ausgang in Abhängigkeit vom Ergebnis der gewichteten Summe der Eingänge und des Schwellenwerts zu bestimmen.
Ich habe aus 16 Optionen gewählt . Ich hatte nicht genug Zeit, um alle Funktionen zu überprüfen. Daher habe ich das beliebteste betrachtet: Sigmoid und hyperbolische Tangente in verschiedenen Implementierungen.
Am Ende habe ich mich für ActivationSigmoid entschieden .
Anzahl der ausgeblendeten Ebenen... Theoretisch ist die Berechnung umso länger und schwieriger, je mehr verborgene Schichten vorhanden sind. Ich habe mit einer Ebene begonnen: Die Berechnung war schnell, aber das Ergebnis war ungenau. Ich entschied mich für zwei versteckte Schichten. Mit drei Schichten wurde es als viel länger angesehen, und das Ergebnis unterschied sich nicht wesentlich von einem zweischichtigen.
Damit habe ich die Experimente beendet. Sie können das Werkzeug für die Produktion vorbereiten.
Zur Produktion!
Weiter eine Frage der Technik.
- Ich habe Spark vermasselt, damit ich über REST mit dem Neuron kommunizieren kann.
- Es wurde gelehrt, die Berechnungsergebnisse in einer Datei zu speichern. Nicht jedes Mal neu zu berechnen, wenn der Dienst neu gestartet wird.
- Es wurde die Möglichkeit hinzugefügt, tatsächliche Daten für das Training direkt vom Service Desk zu lesen. Zuvor in CSV-Dateien geschult.
- Es wurde die Möglichkeit hinzugefügt, das neuronale Netzwerk neu zu berechnen, um die Neuberechnung an den Scheduler anzuhängen.
- Sammelte alles in einem dicken Glas.
- Ich habe meine Kollegen nach einem Server gefragt, der leistungsfähiger ist als eine Entwicklungsmaschine.
- Zaploil und Zadulil erzählen einmal pro Woche.
- Ich schraubte den Knopf an die richtige Stelle im Service Desk und schrieb meinen Kollegen, wie man dieses Wunder einsetzt.
- Ich habe Statistiken darüber gesammelt, was das Neuron auswählt und was die Person ausgewählt hat (Statistiken unten).
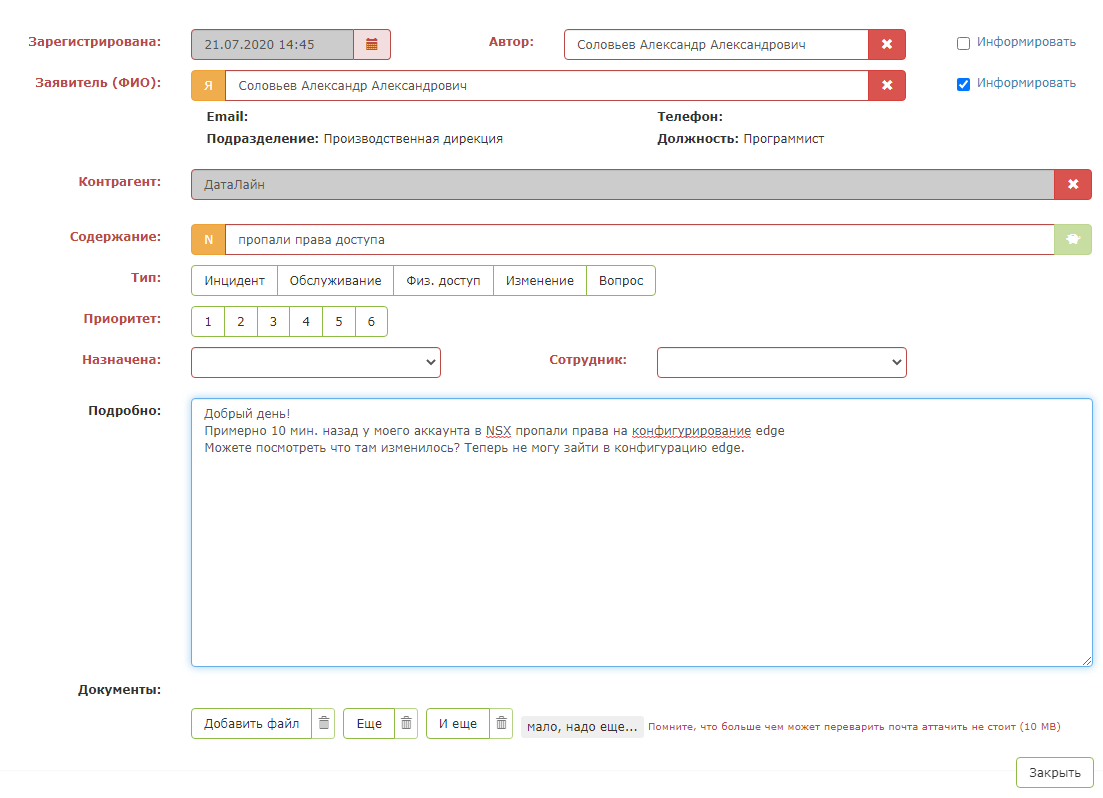
So sieht die Testanwendung aus:
Sobald Sie jedoch den "magischen grünen Knopf" drücken, geschieht die Magie: Die Felder der Karte werden ausgefüllt. Der Dispatcher muss nur sicherstellen, dass das System korrekt auffordert, und die Anforderung speichern.
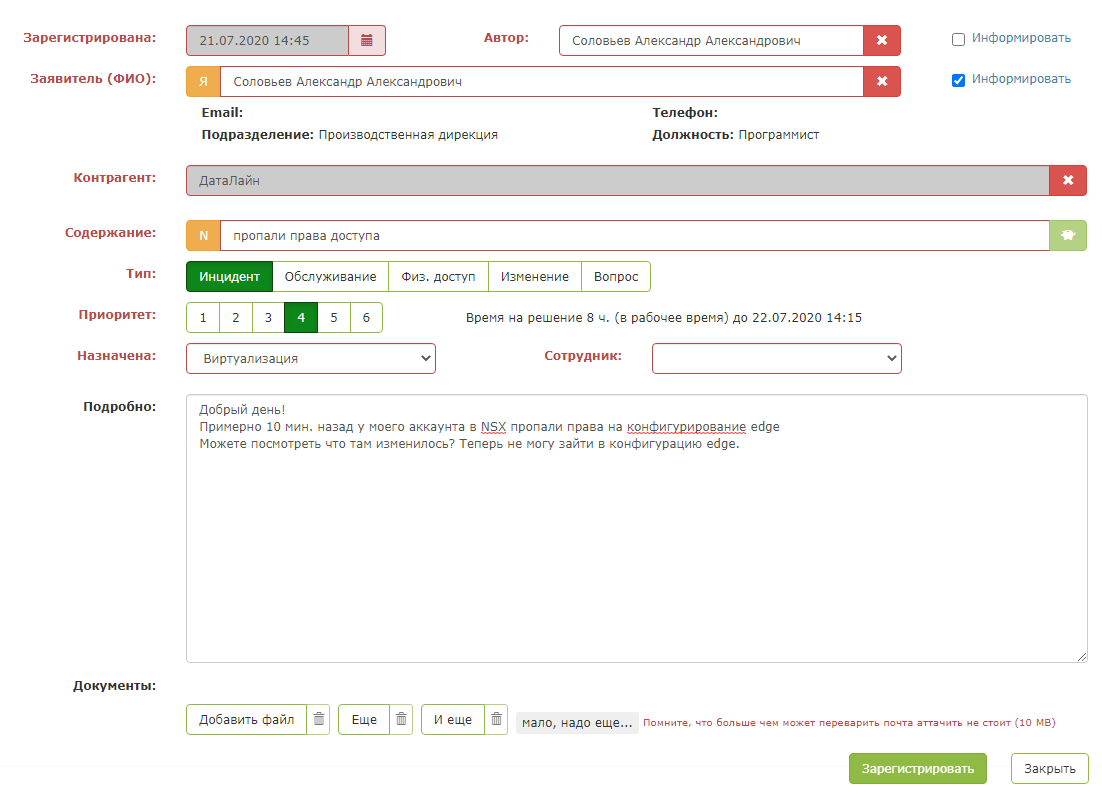
Das Ergebnis ist ein so intelligenter Assistent für den Disponenten.
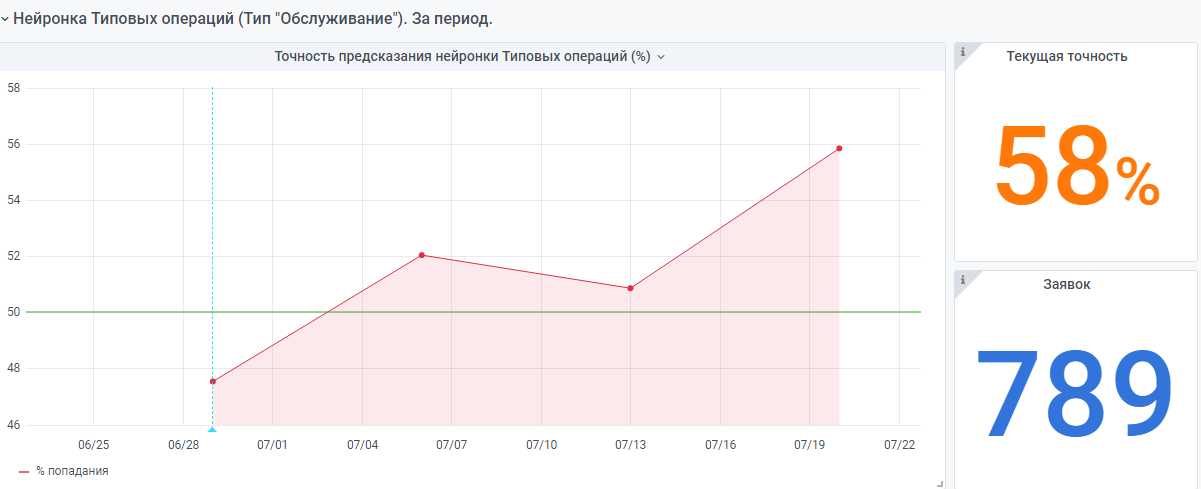
Zum Beispiel Statistiken vom Jahresbeginn.
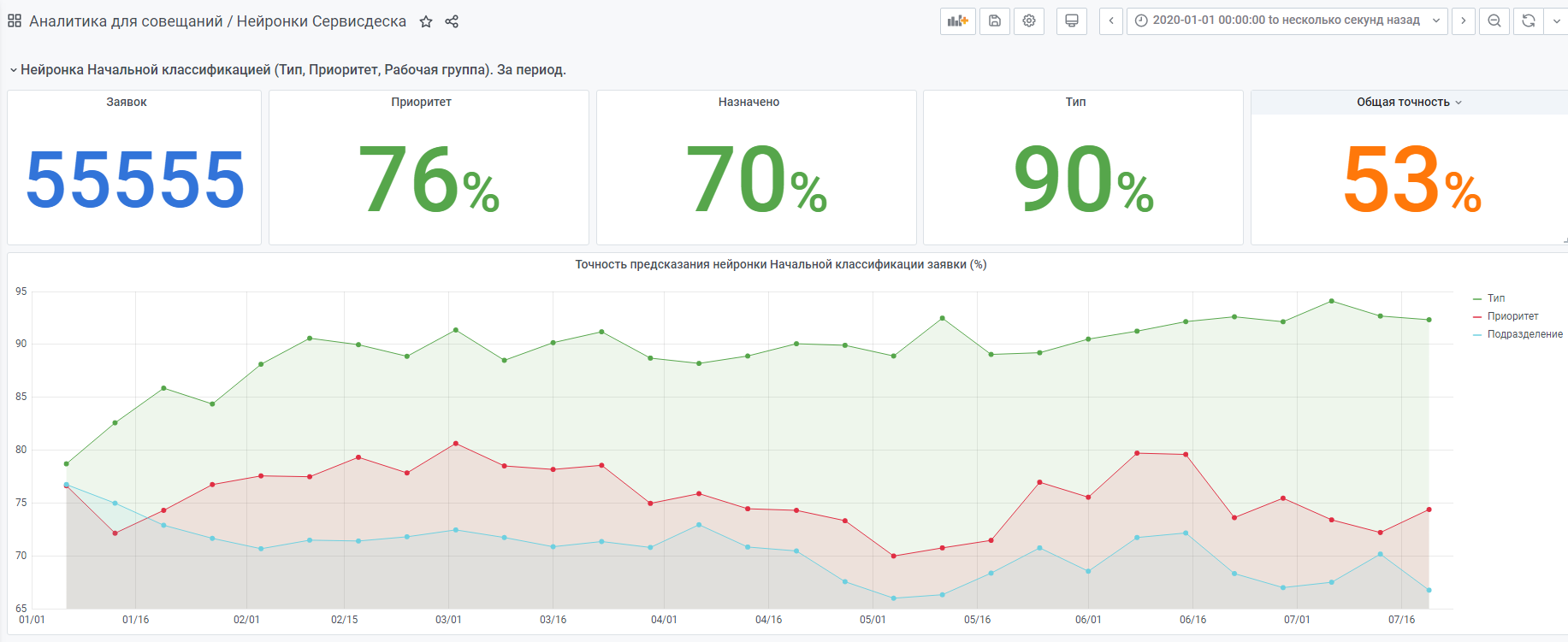
Es gibt auch ein "sehr junges" neuronales Netzwerk, das nach dem gleichen Prinzip aufgebaut ist. Aber es gibt immer noch wenig Daten, sie sammelt immer noch Erfahrungen.
Ich würde mich freuen, wenn meine Erfahrung jemandem helfen würde, sein eigenes neuronales Netzwerk aufzubauen.
Bei Fragen stehe ich Ihnen gerne zur Verfügung.