
Dateneditor
Großwerteditor
Wir haben den Zellen einen vollwertigen Editor hinzugefügt. Wenn eine Zelle einen langen Wert enthält, z. B. XML oder JSON, können Sie ihn bequem in einem separaten Bereich öffnen. Klicken Sie dazu im Kontextmenü auf
Maximieren .
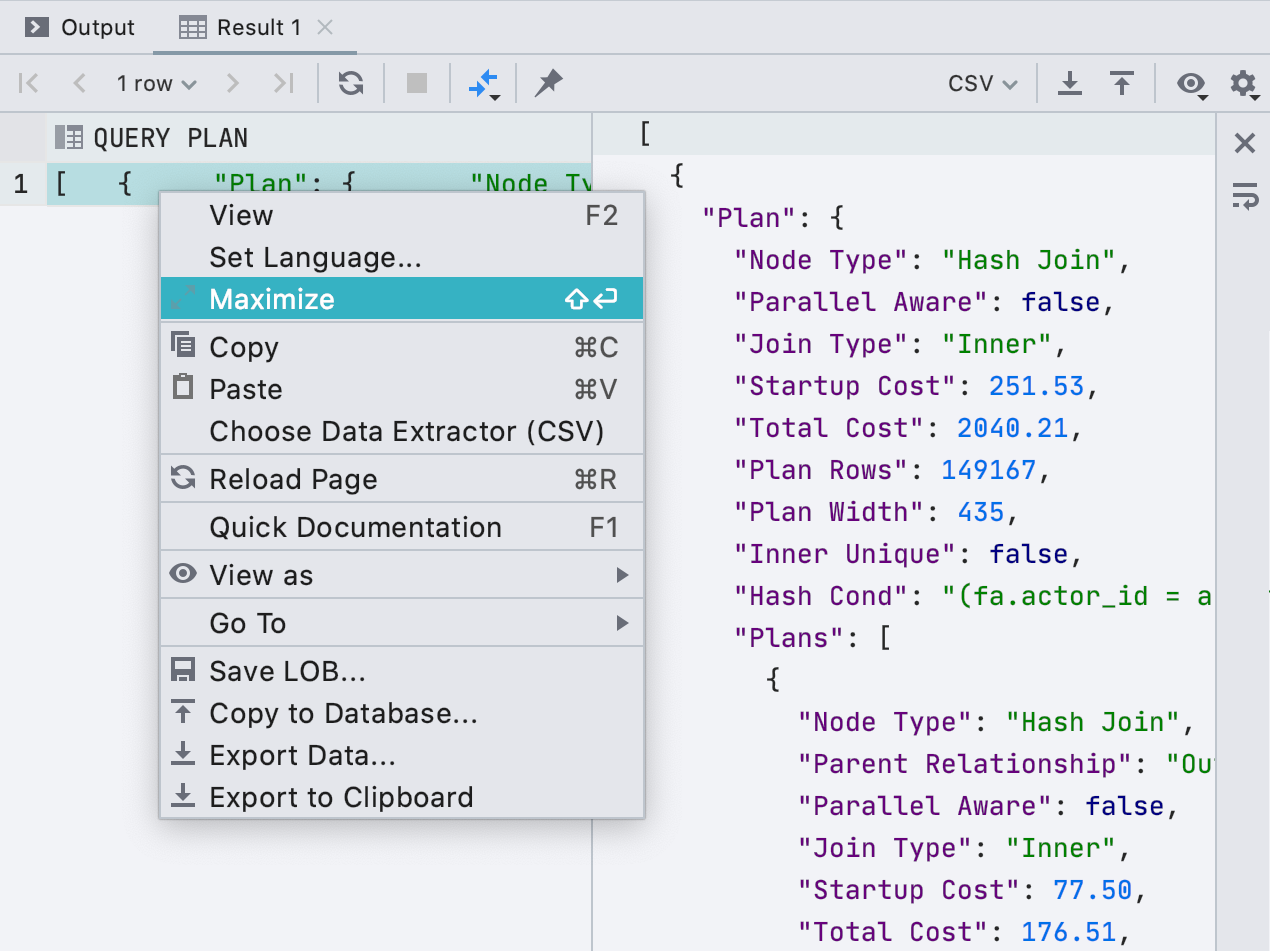
Vorschau einer Abfrage während der Bearbeitung
Bevor Sie neue Werte in den Dateneditor schreiben, können Sie sehen, welche Abfrage ausgeführt wird. Klicken Sie dazu in der Symbolleiste auf die Schaltfläche DML .
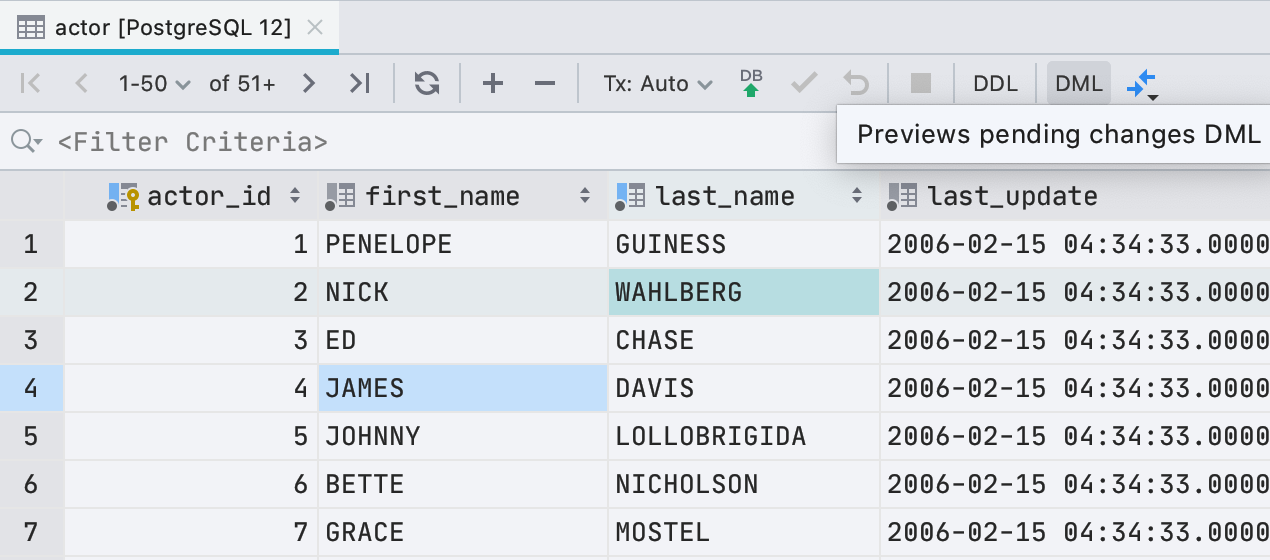
Um ehrlich zu sein, führen wir nicht nur die Abfrage aus, da DataGrip zum Bearbeiten von Daten den JDBC-Treiber verwendet. In den meisten Fällen stimmt das, was wir zeigen, mit dem überein, was tatsächlich beginnt.
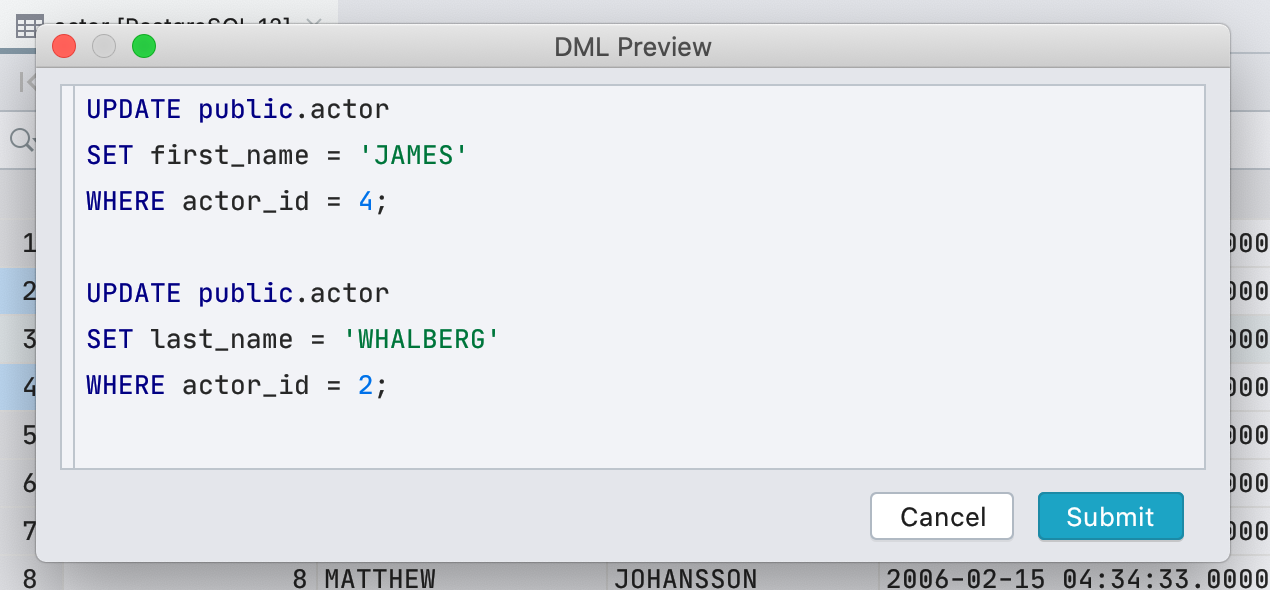
Neue Anzeige logischer Zellen
Bisher haben wir ein Kontrollkästchen verwendet , um Zellen mit dem booleschen Typ anzuzeigen . Dies war unpraktisch: Nicht jeder verstand es, null von falsch zu unterscheiden , und Standard, berechnet und null wurden überhaupt gleich angezeigt. Wir haben uns entschieden, nicht schlau zu sein und die Bedeutung in Text zu schreiben.
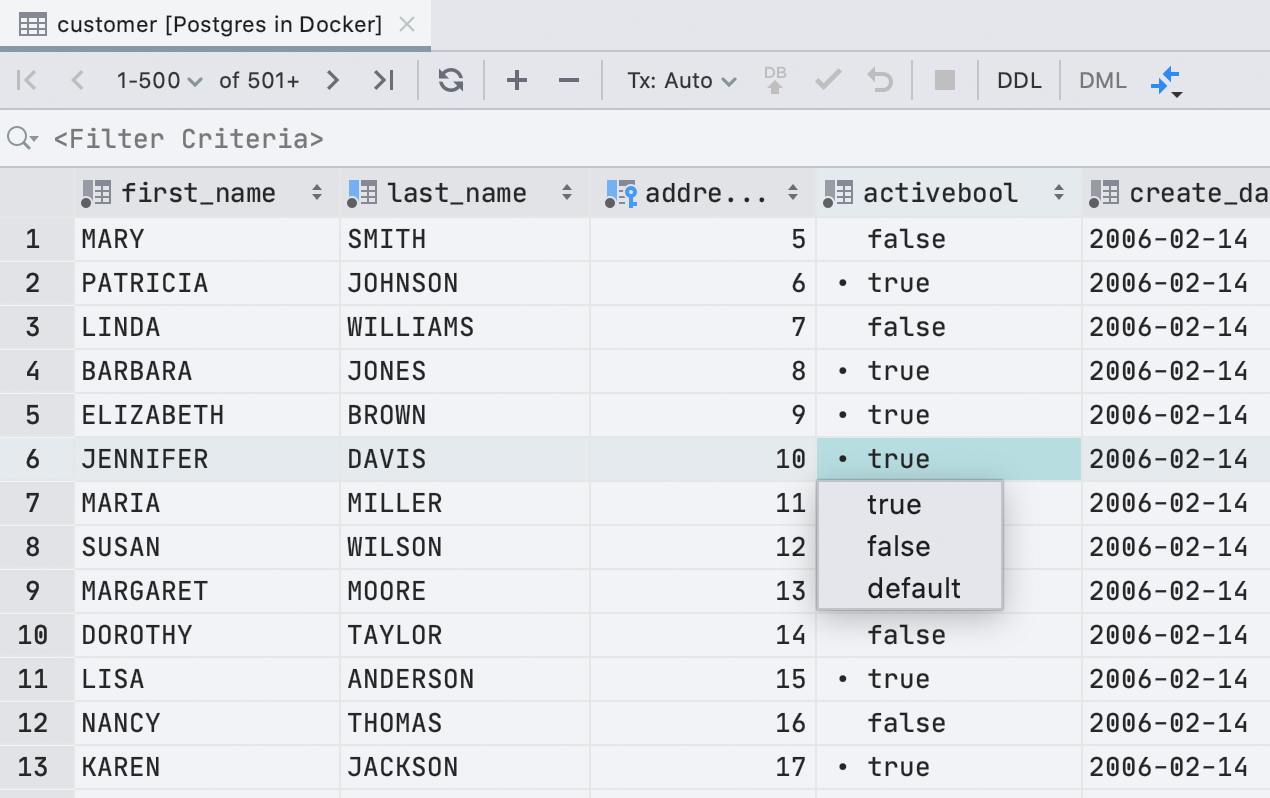
Das Kontrollkästchen hatte ein Plus: Es ist einfach, wahre Werte visuell zu finden . In der neuen Schnittstelle führt der Punkt diese Aufgabe aus.
Wir haben Glück: Auf Englisch beginnen alle möglichen Bedeutungen mit unterschiedlichen Buchstaben. Drücken Sie zum Bearbeiten einfach den ersten Buchstaben des gewünschten Werts: f, t, d, n, g oder c.Wenn wir etwas anderes drucken, wird eine Dropdown-Liste angezeigt. Die Leertaste wechselt zwischen den verfügbaren Werten.
Automatischer Dateneditor für CSV-Dateien
Bisher mussten Sie den Dateneditor über das Kontextmenü aufrufen, und in einer kleinen gelben Leiste wurde beim Öffnen von CSV-Dateien ein Plugin eines Drittanbieters angekündigt. Jetzt finden wir heraus, was wir selbst sind, und zeigen die Registerkarte Daten für CSV-Dateien an.
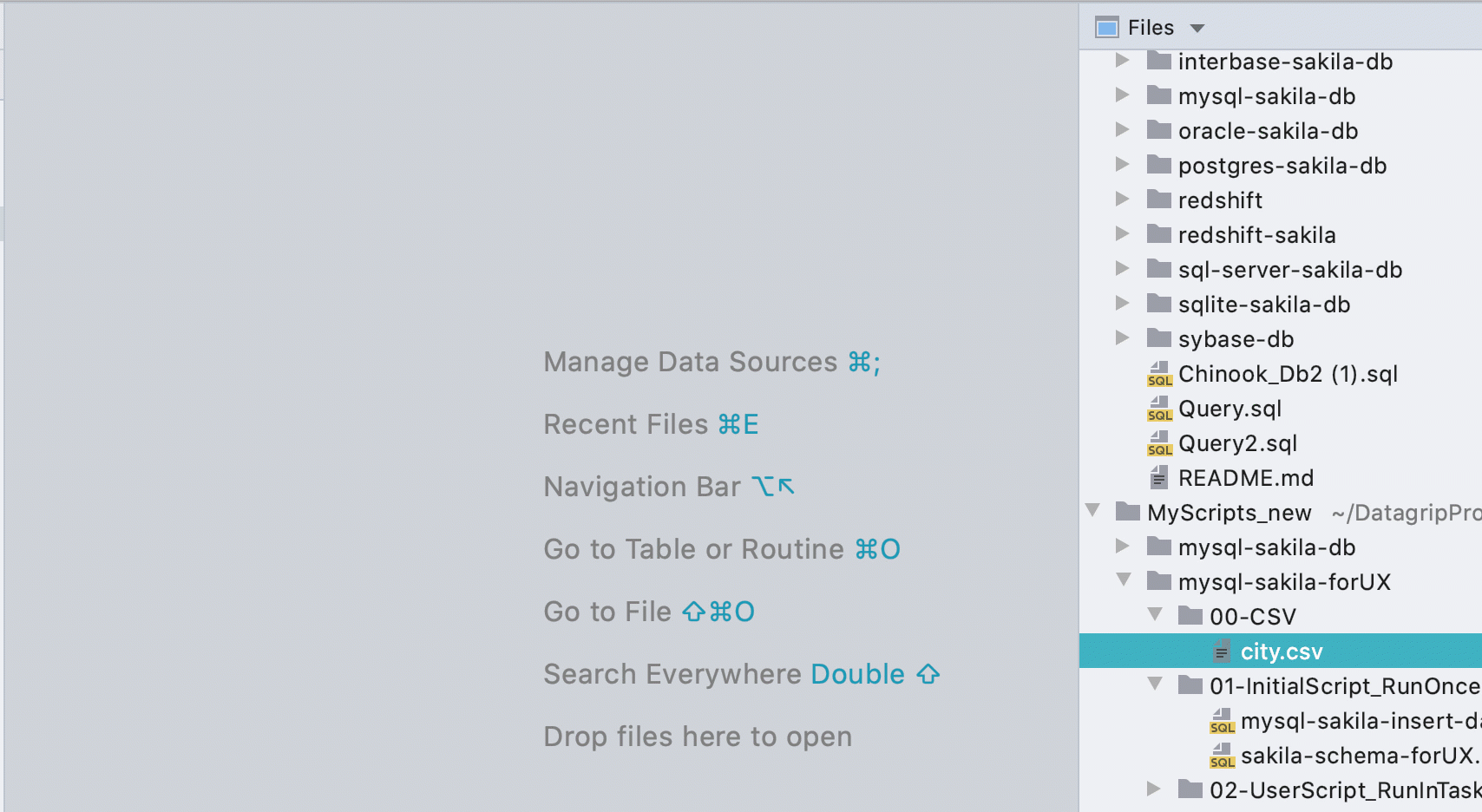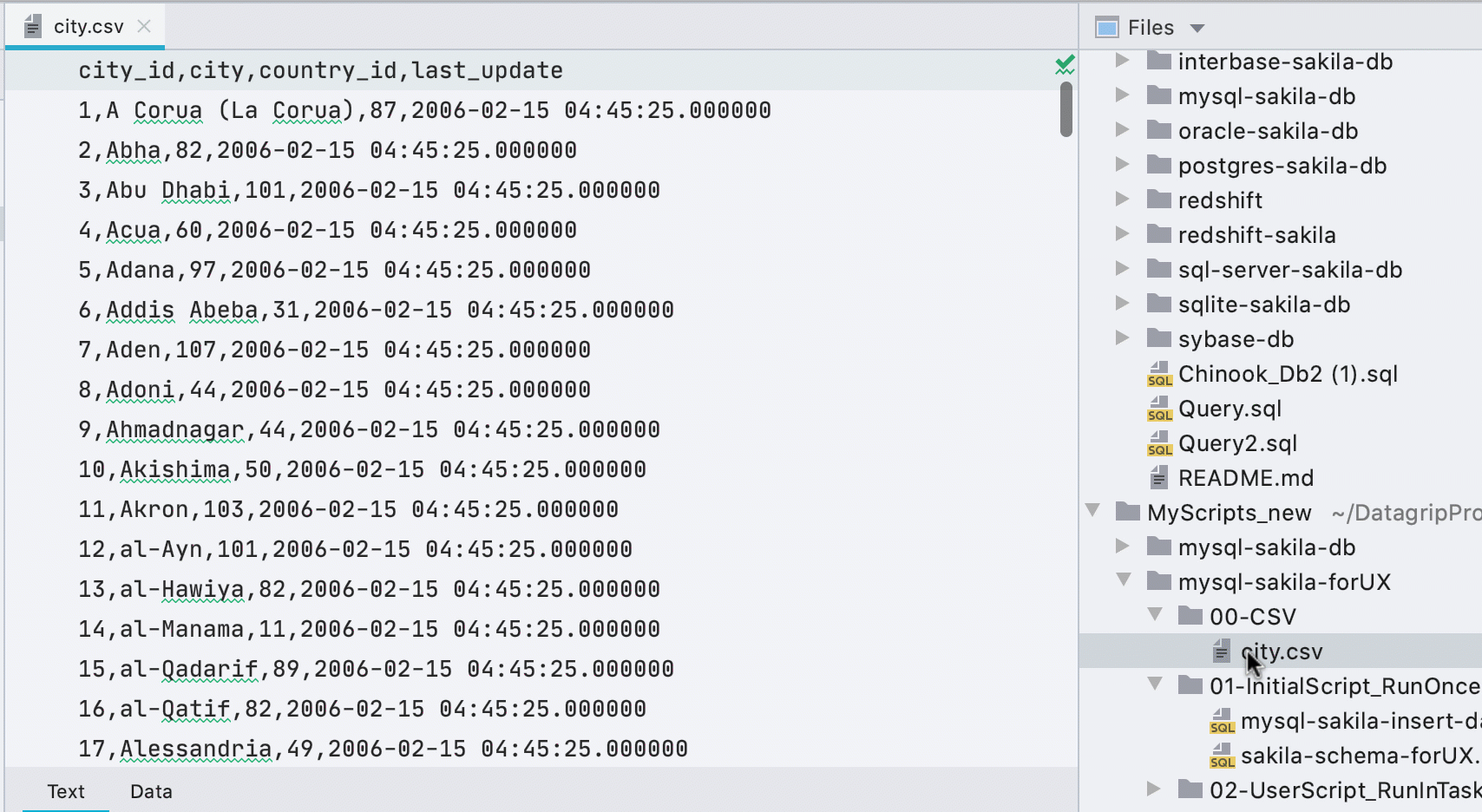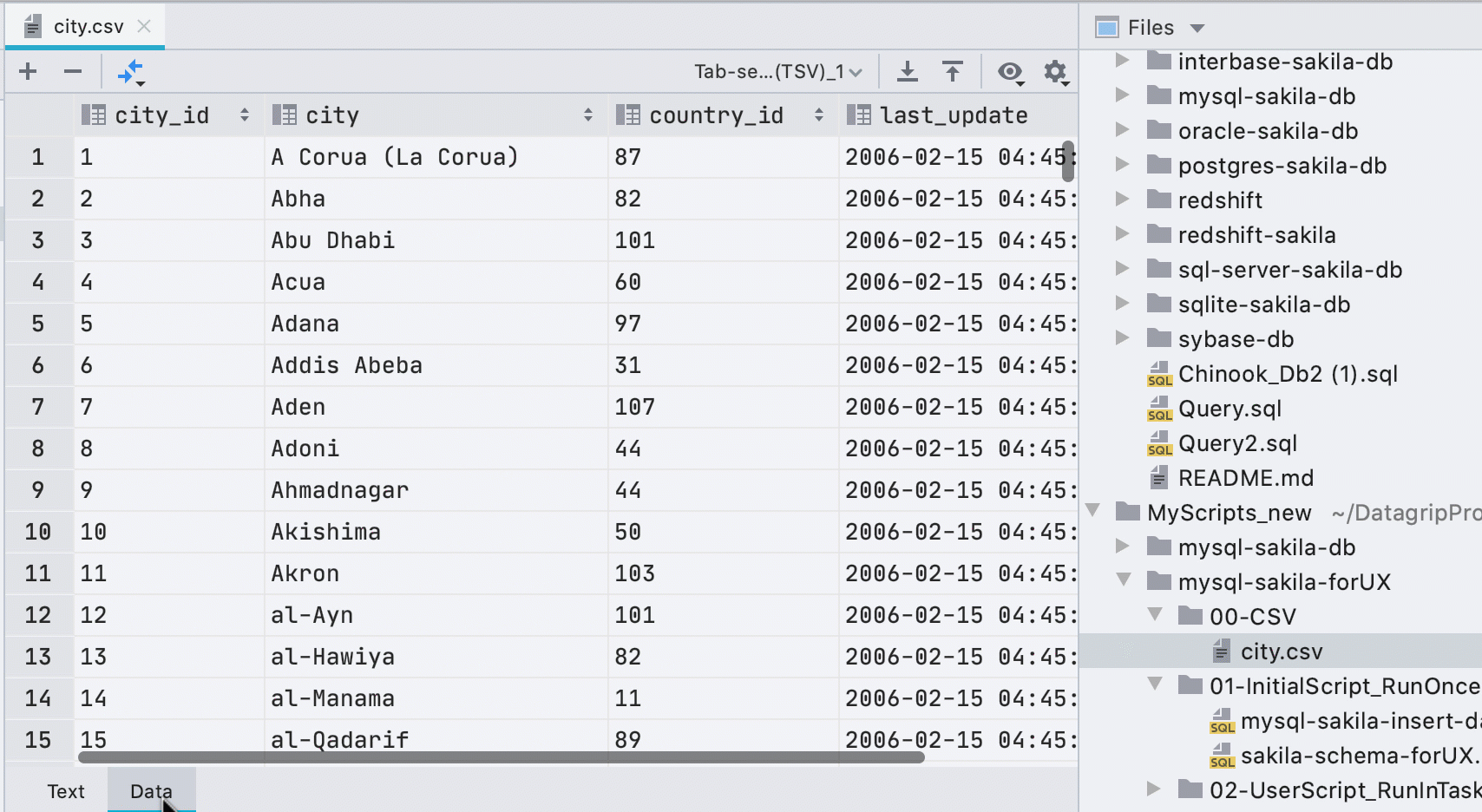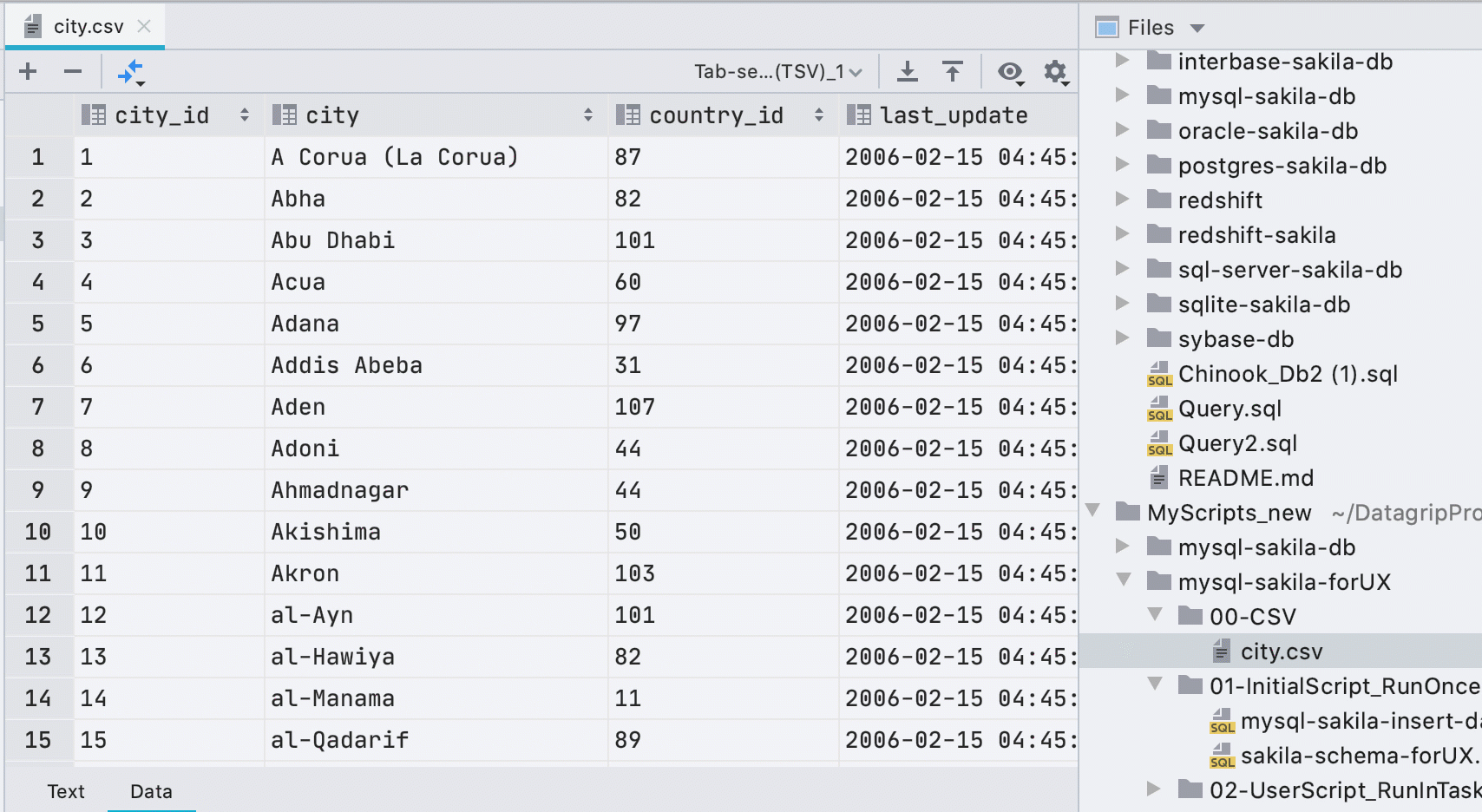
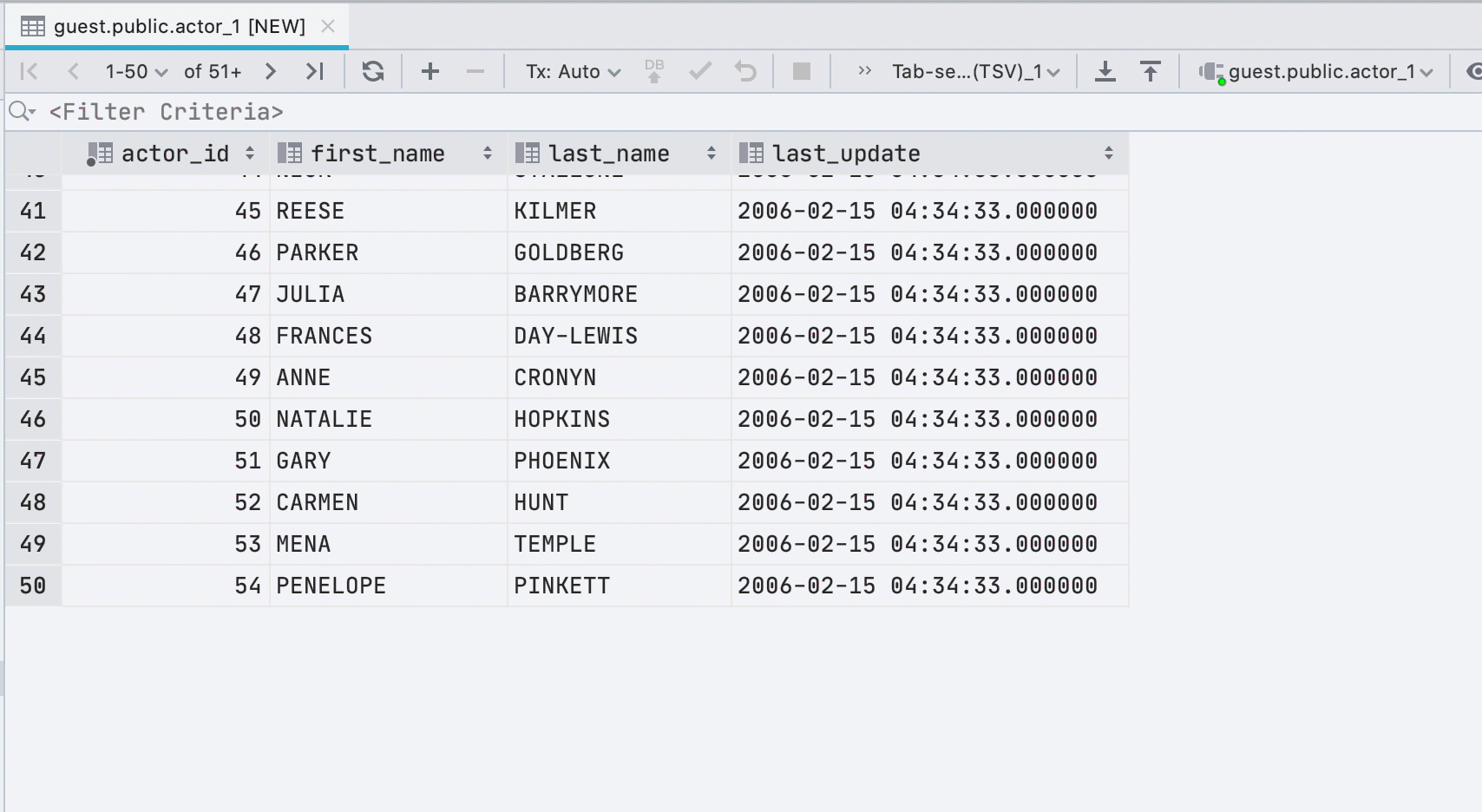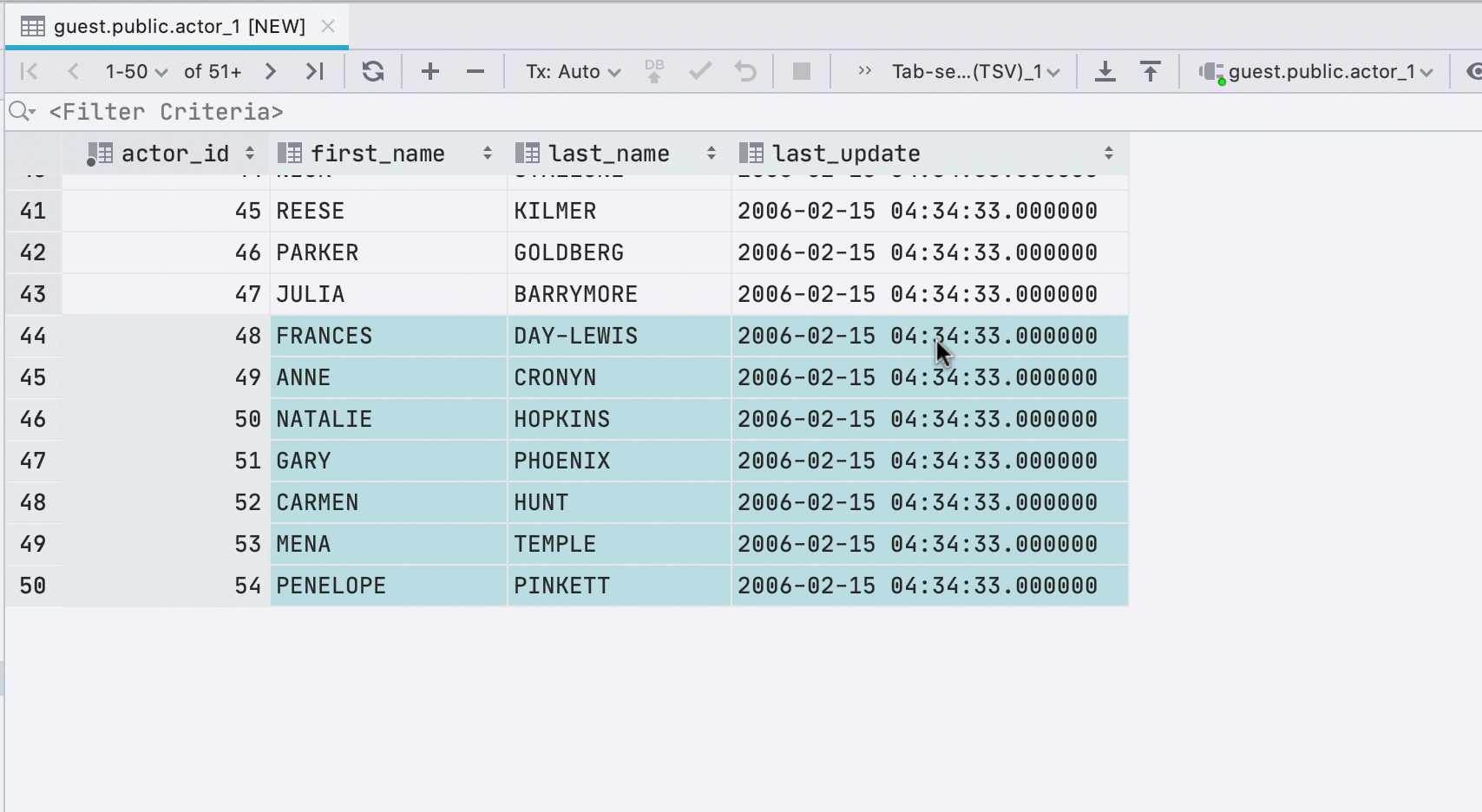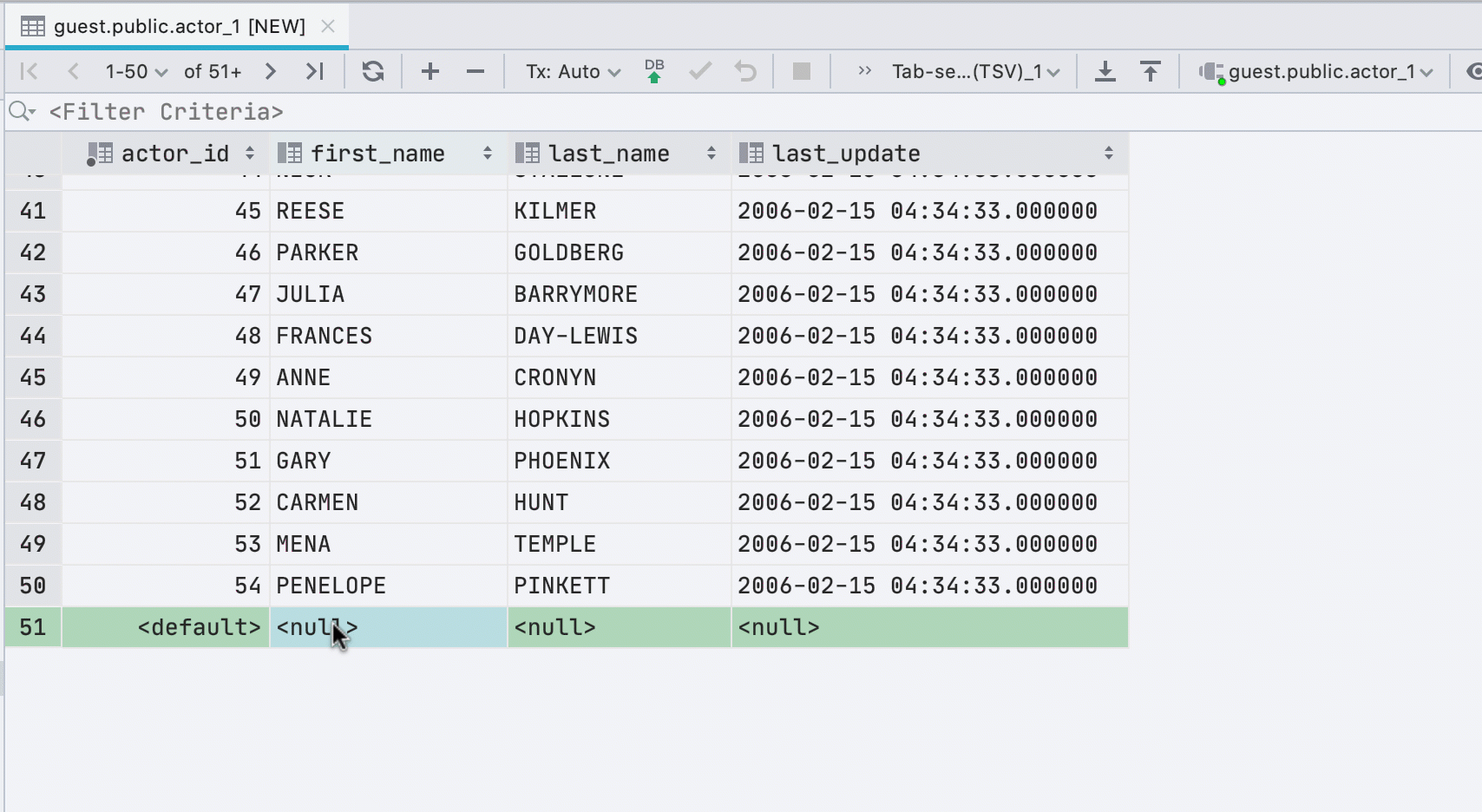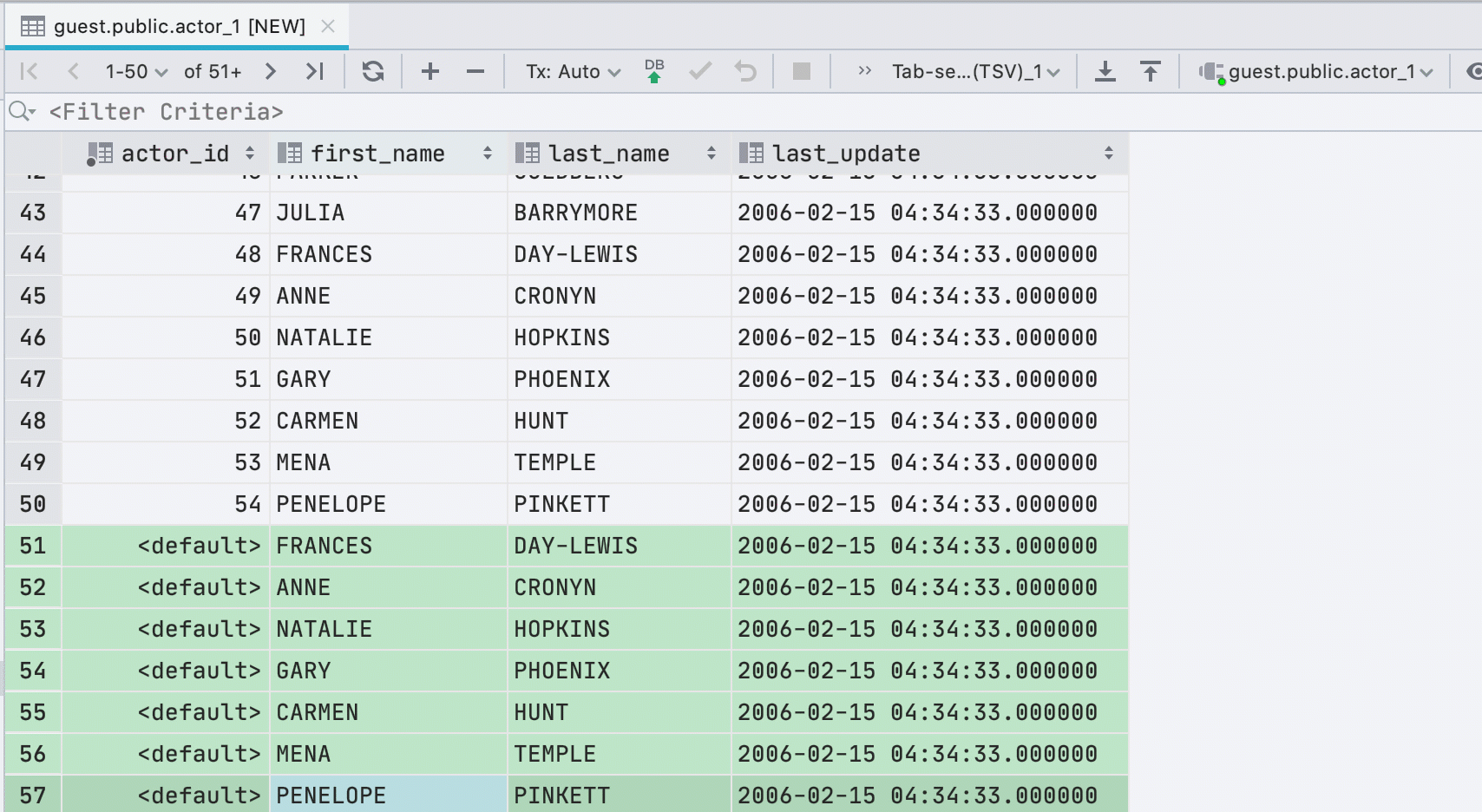
Neue Zeilen beim Einfügen von Werten
Wenn Sie Daten aus der Zwischenablage in eine Tabelle einfügen, erstellen wir automatisch die erforderliche Anzahl neuer Zeilen.
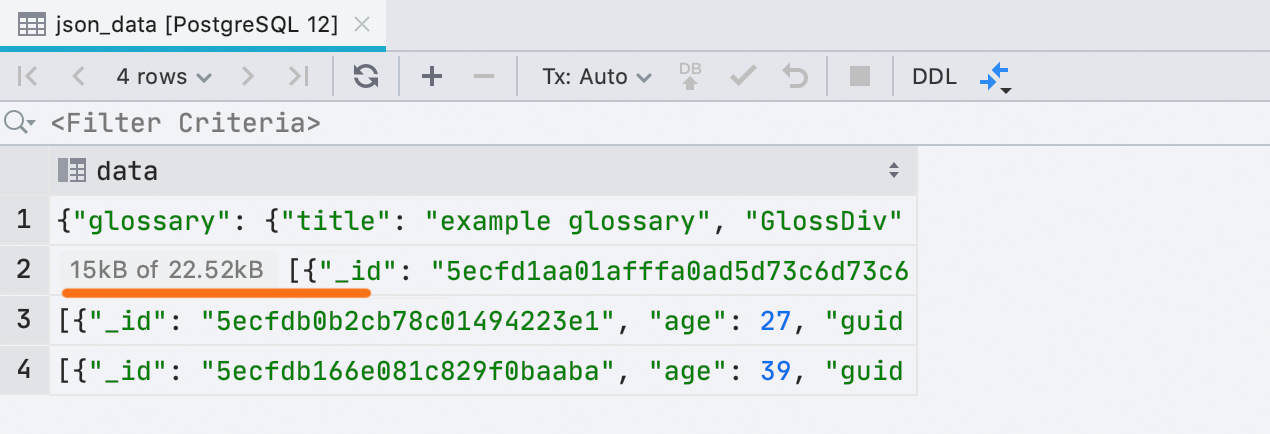
Neue Schnittstelle für unterlastete Daten
Manchmal kann DataGrip nicht alle Daten in eine Zelle laden, wenn es viel Speicher beansprucht. Dies wird durch die Datenbank | bestimmt Datenansichten | Maximale LOB-Länge.Zuvor haben wir Text dazu direkt in den Zellenwert eingefügt, was unpraktisch ist. Jetzt ist es eine kleine separate Platte:
Exportieren in die Zwischenablage aus dem Kontextmenü
In der letzten Version haben wir ein Dialogfeld für den Export erstellt, wobei ein kleiner Fall weggelassen wurde: Es wurde weniger bequem, das gesamte Ergebnis mit der Maus in die Zwischenablage zu kopieren. Dies kann nun über das Kontextmenü erfolgen.

Denken Sie daran, dass diese Aktion das gesamte Ergebnis oder die gesamte Tabelle kopiert. Und Strg / Befehlstaste + C oder die Aktion
Kopieren kopiert nur die Auswahl. Filterverbesserungen
für MongoDB
Neben ObjectId und ISODate können Sie jetzt nach UUID , NumberDecimal , NumberLong filternund
BinData . Wenn Sie einen geeigneten Wert für UUID / ObjectId / ISODate in Ihrer Zwischenablage haben, bietet DataGrip an, ihn zum Filtern zu verwenden.
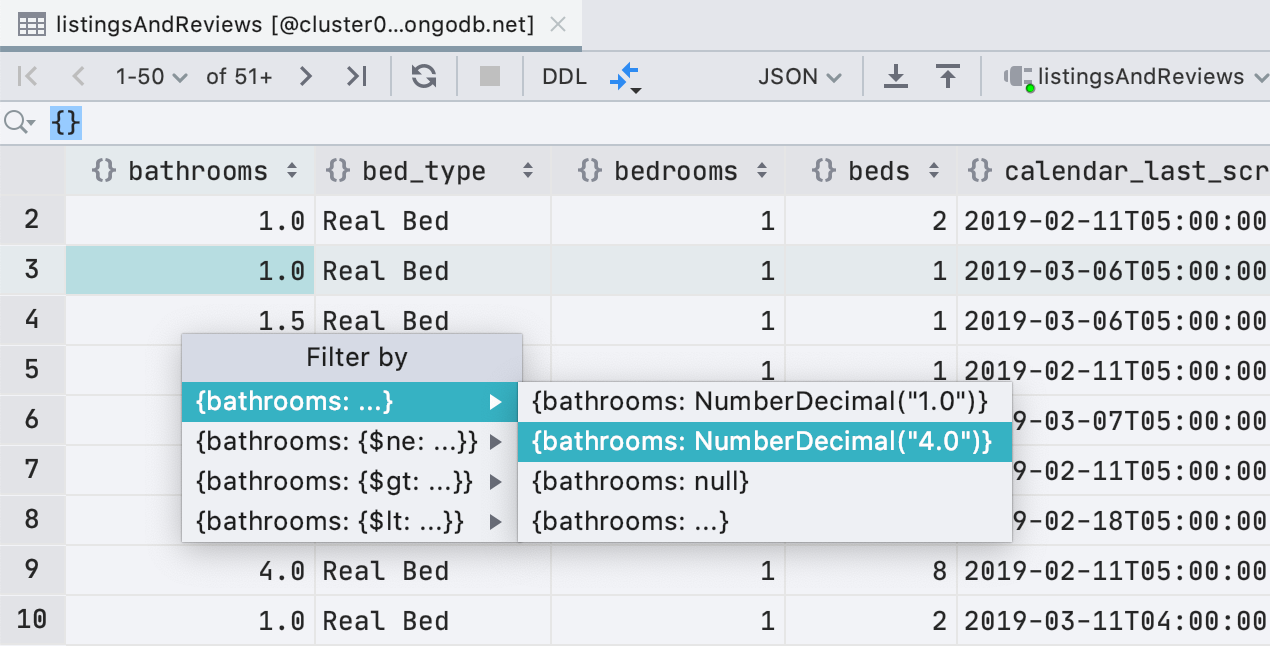
Wir haben den Filterbedingungen auch reguläre Ausdrücke hinzugefügt, damit Sie in relationalen Datenbanken nicht zu viel
LIKE aus dem Filter verpassen .

SQL-Editor
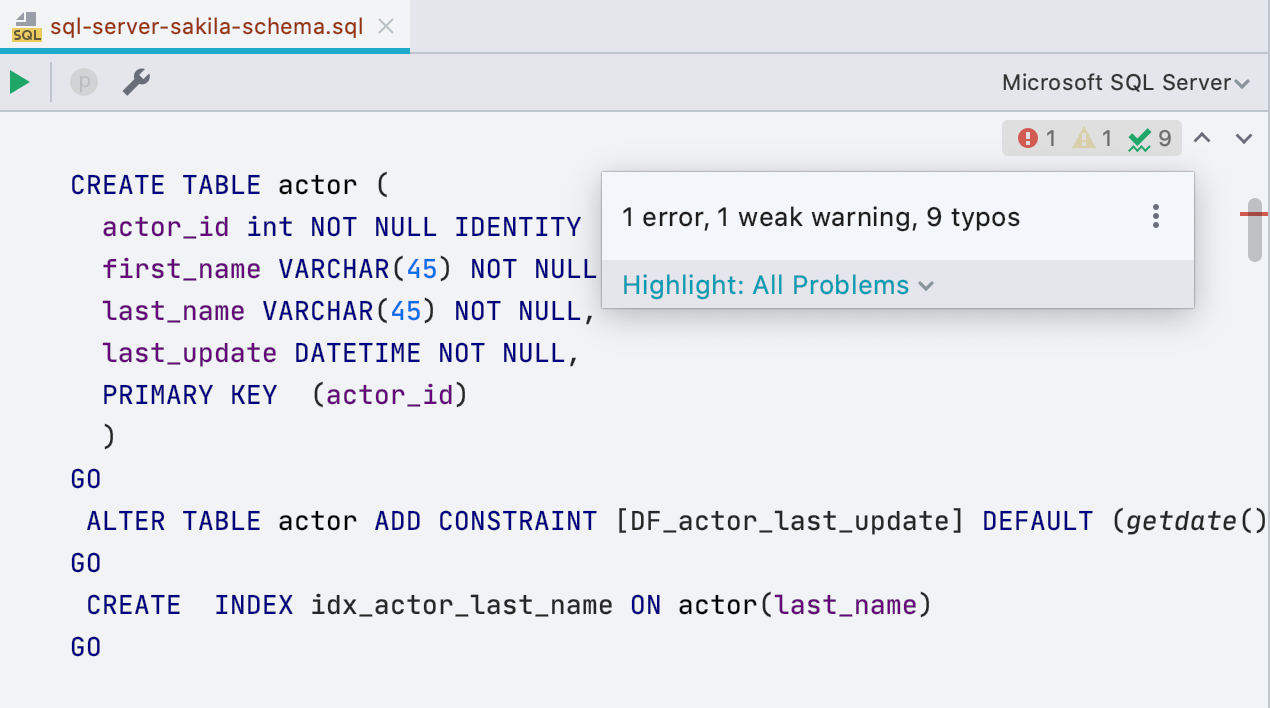
Neues Widget mit Inspektionen
Rechts neben dem Editor wird ein kleines Fenster angezeigt, in dem angezeigt wird, wie viele Fehler im Skript und an wie vielen Stellen verdächtig sind. Von dort aus können Sie navigieren oder auswählen, was hervorgehoben werden soll und was nicht. Die Tastenkombination F2 funktioniert immer noch für dieselbe.
Vorschlag zum Umbenennen
Dies wurde in vielen unserer IDEs angezeigt: Wenn Sie etwas umbenannt haben, das kein integriertes Refactoring verwendet, aber den Namen im Code geändert hat, werden Sie aufgefordert, das System umzugestalten und umzubenennen. So funktioniert es beispielsweise mit Aliasen: Die

JOIN-Vervollständigung ist jetzt noch besser.
Damit wir eine vollständige JOIN-Bedingung anbieten konnten, mussten wir dieses Schlüsselwort eingeben. Jetzt verstehen wir, was benötigt wird, sobald Sie getippt haben
'J'.

Wir haben auch gelernt, doppelte Bedingungen anzubieten, wenn Tabellenschlüssel so eingestellt sind.

Datenbankinformationen
aktualisieren Wenn DataGrip aus Ihren Abfragen nichts über Objekte weiß, werden Sie darüber informiert. Manchmal passiert dies, wenn Sie sich nur versiegelt haben. Es kommt auch vor, dass die Datei der falschen Datenquelle zugeordnet wurde. Ein weiterer Grund für ein solches Ereignis ist, dass das Objekt bereits angezeigt wurde, DataGrip jedoch keine Informationen darüber aus der Datenbank erhalten hat. Zu diesem Zweck haben wir die Möglichkeit hinzugefügt, die Datenbankstruktur über den Editor zu aktualisieren, wenn das Objekt unbekannt ist.

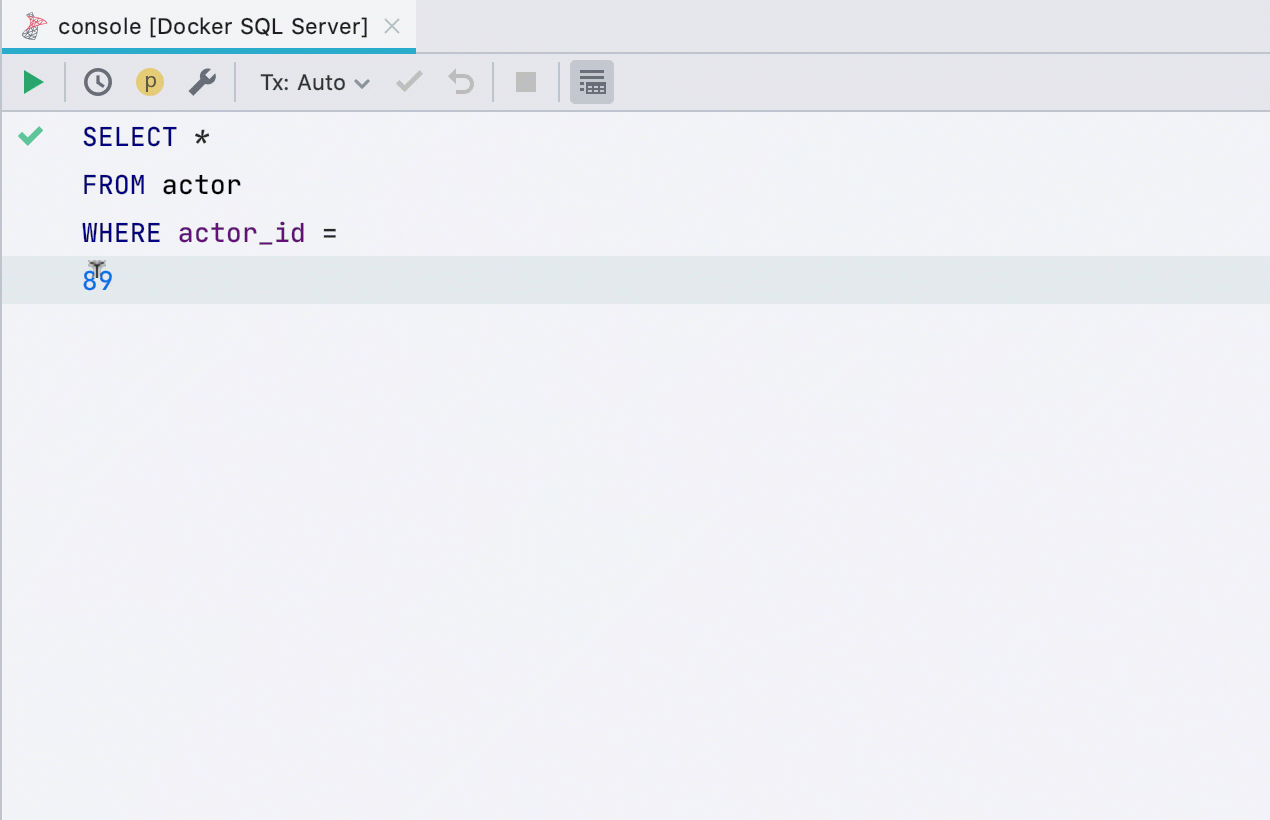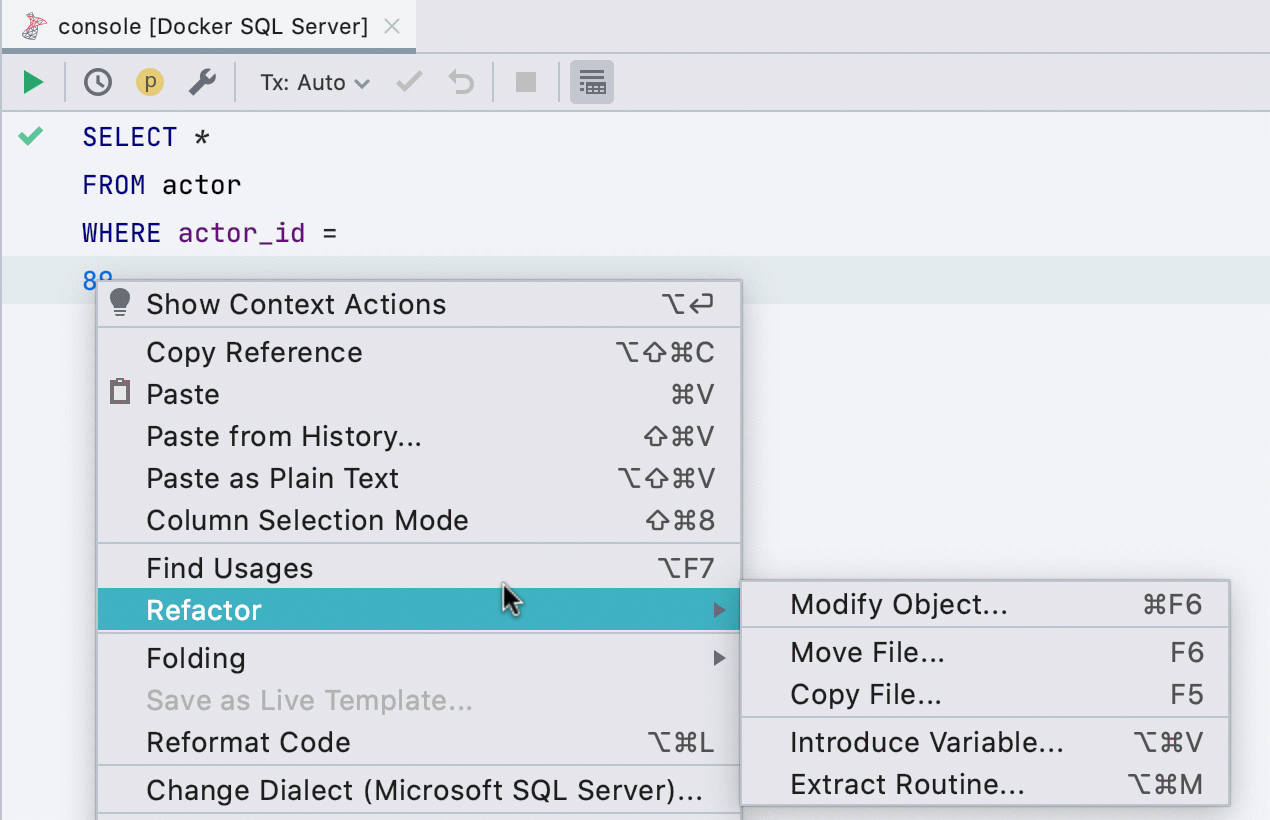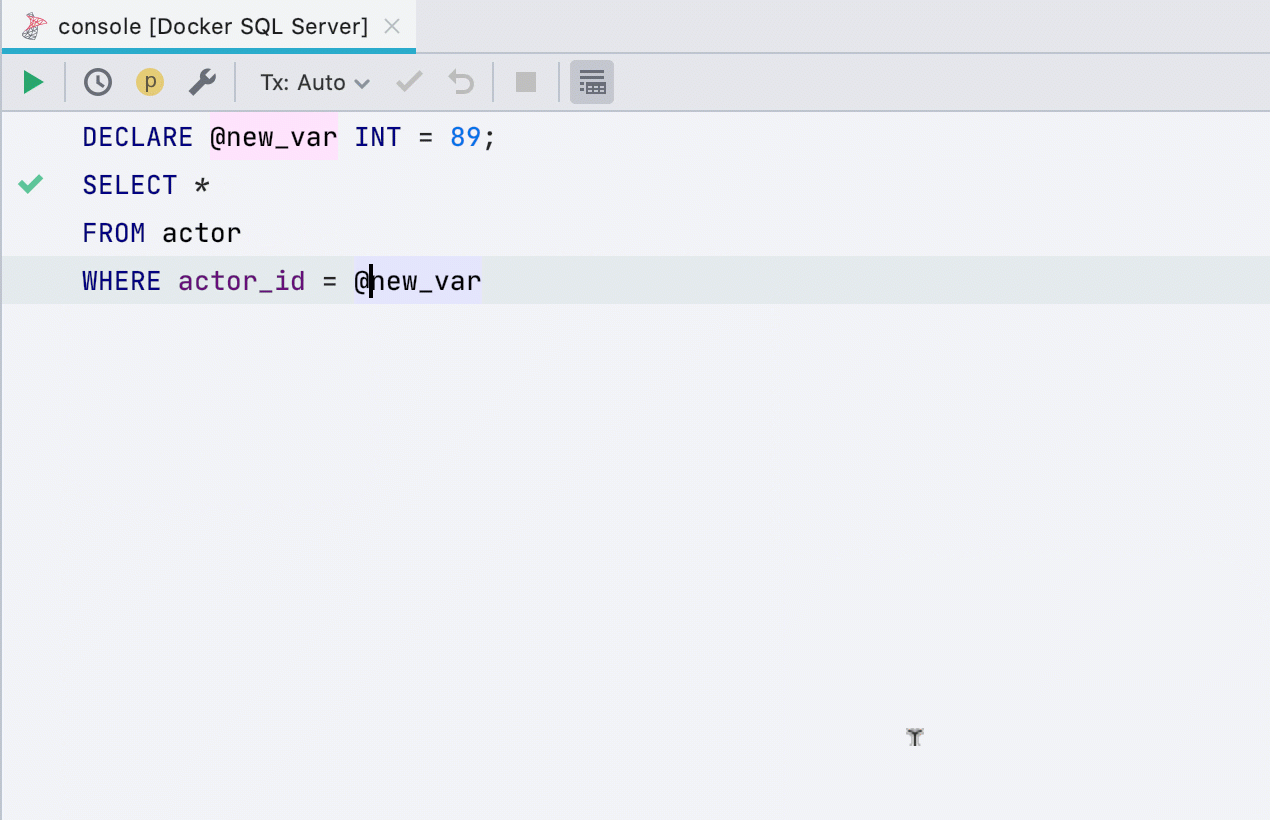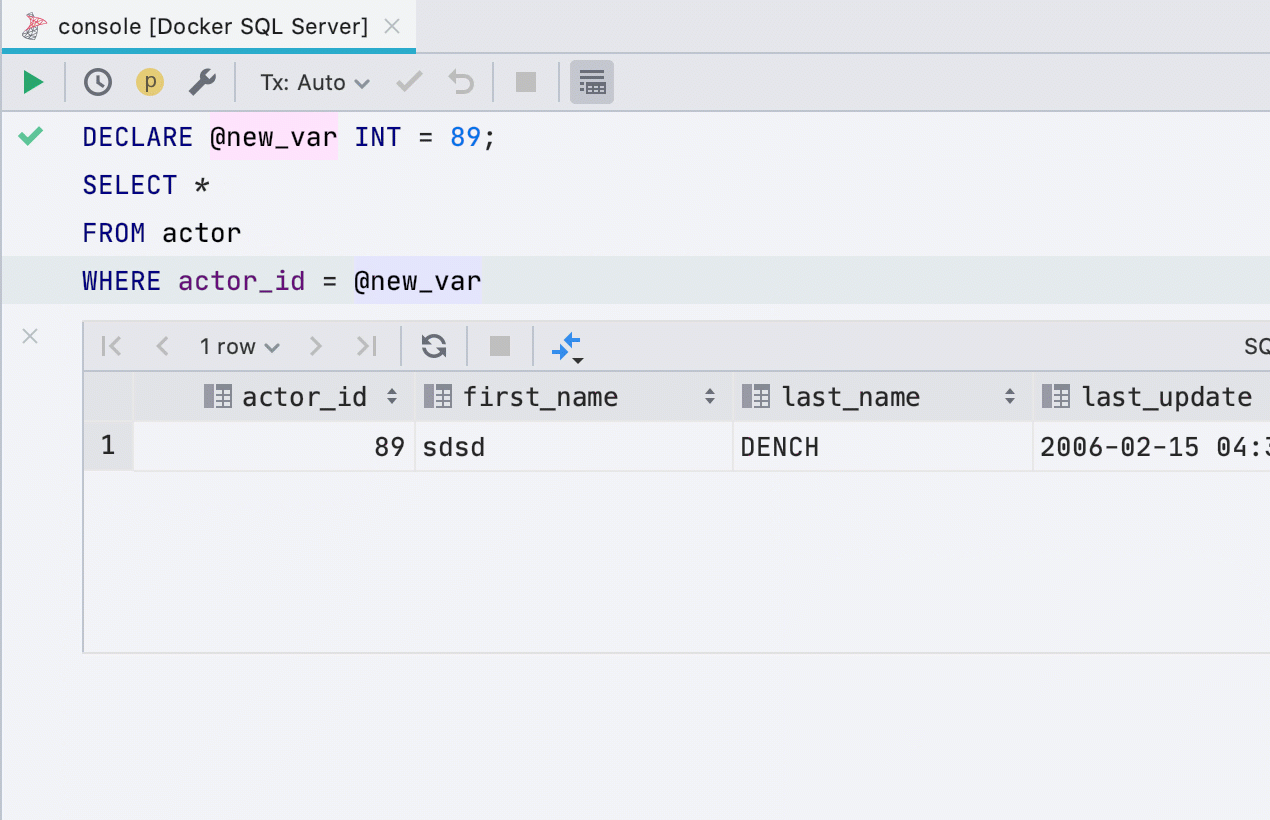
Variable hervorheben
Dieses Refactoring funktionierte zuvor nicht für alle Datenbanken, funktioniert jetzt in SQL Server, Db2, Exasol, HSQL, Redshift und Sybase .
Google BigQuery-Hervorhebung
Neue Dialekte hinzugefügt: Google BigQuery. Bisher ist dies keine vollständige Datenbankunterstützung, sondern nur eine korrekte Code-Hervorhebung. Dementsprechend müssen Sie keinen Code auswählen, um Abfragen auszuführen. Wir bestimmen selbst, was ausgeführt werden soll.

Hervorheben von TextMate
Wie unsere anderen IDEs kann DataGrip jetzt Code mithilfe des TextMate-Plugins hervorheben. Es kann nützlich sein, wenn Sie Skripte in Python, Lua, Javascript haben. Eine vollständige Liste der Sprachen finden Sie unter Einstellungen / Einstellungen | Editor | TextMate-Bundles .

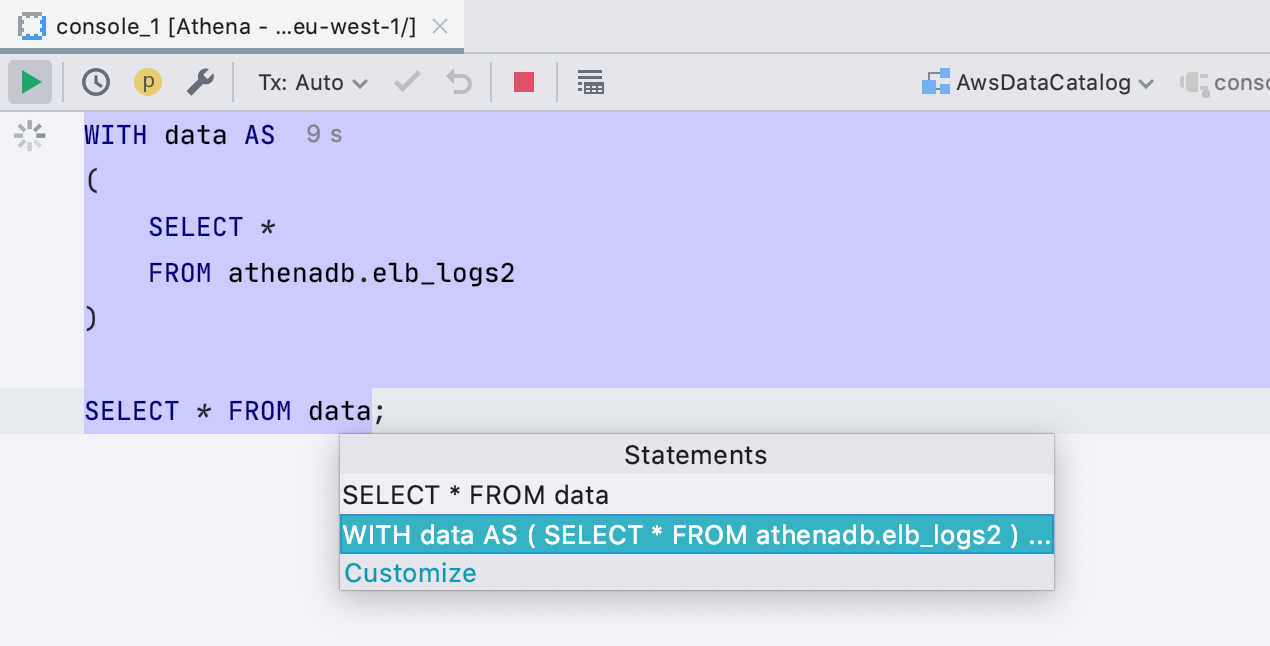
SQL 2016 als <Generic> -Dialekt
Wenn Sie mit einer Datenbank arbeiten, die wir nicht unterstützen, werden Abfragen analysiert und mit dem < Generic > -Dialekt hervorgehoben . Früher war es SQL 92, jetzt SQL 2016. Das Wichtigste ist, dass wir jetzt Abfragen mit einem WITH- Block korrekt verarbeitenSie werden nicht nur korrekt hervorgehoben, sondern Sie können sie auch ausführen, ohne den Code hervorzuheben. Groß- und Kleinschreibung
von Objektnamen bei der Formatierung
In den Formatierungseinstellungen gab es drei Einstellungen für die Namen von Datenbankobjekten: Groß- , Klein- oder Nichtänderung . Es stellte sich jedoch heraus, dass es einen vierten Fall gibt: Benutzer möchten den Fall verwenden, der beim Erstellen des Objekts im Skript verwendet wurde. Wir haben dies unterstützt.

Im Beispiel wurde die Actor- Tabelle mit dem ersten Großbuchstaben erstellt, und im Gebrauch haben wir den Tabellennamen in denselben Fall konvertiert.

Wir suchen nur nach Erstellungsskripten in derselben Datei, in der die Formatierung stattfindet. Wenn der Formatierer die Objektdeklaration in einer benachbarten Datei finden soll, erstellen Sie aus Ihren Dateien eine DDL-basierte Datenquelle .
Mehrere Wagen in einer Auswahl
Jetzt können Sie ein Code-Snippet auswählen und in jede Zeile ein Caret einfügen. Verwenden Sie dazu die Aktion Carets an den Enden ausgewählter Zeilen hinzufügen oder die Tastenkombination Umschalt + Alt + G.

Datenbank-Explorer
Alle Basen und Schemata im Baum
Standardmäßig werden im Baum nur die Basen und Schemata angezeigt, die Sie selbst ausgewählt haben. Der Baum ist nicht faul und alle Metainformationen zu den Objekten werden für die weitere Arbeit der IDE verwendet. Daher laden wir nur das herunter, was benötigt wird, um nicht versehentlich an einer riesigen Basis zu hängen.
Viele sind jedoch an Werkzeuge gewöhnt, die immer alle Objekte anzeigen, und Personen, die mit unserem Konzept nicht vertraut sind, verlieren möglicherweise die Grundlagen und Diagramme aus den Augen. Aus diesem Grund haben wir die Einstellung Alle Namespaces anzeigen vorgenommen . Wenn diese Einstellung aktiviert ist, werden alle Datenbanken und Schemata in der Baumstruktur angezeigt, auch wenn keine Informationen zu ihren Objekten geladen sind. Solche Schemata und Basen sind grau markiert.

Schnittstelle zum Erstellen von Ansichten
Wir sagen normalerweise, dass die Codegenerierung im Editor funktioniert (Alt + Ins oder Cmd + N ) decken viele der Anforderungen des Entwicklers zum Erstellen von Objekten ab, aber manchmal ist es immer noch weniger bequem. Aus diesem Grund haben wir Schnittstellen zum Erstellen von Objekten hinzugefügt: In der neuen Version können Sie Ansichten erstellen.

Skriptdateien im Bereich "Dateien"
Wenn Sie eine DDL-basierte Datenquelle erstellt haben, werden diese Dateien automatisch in den Bereich "
Dateien" verschoben . So können Sie sie bequem anzeigen und bearbeiten.

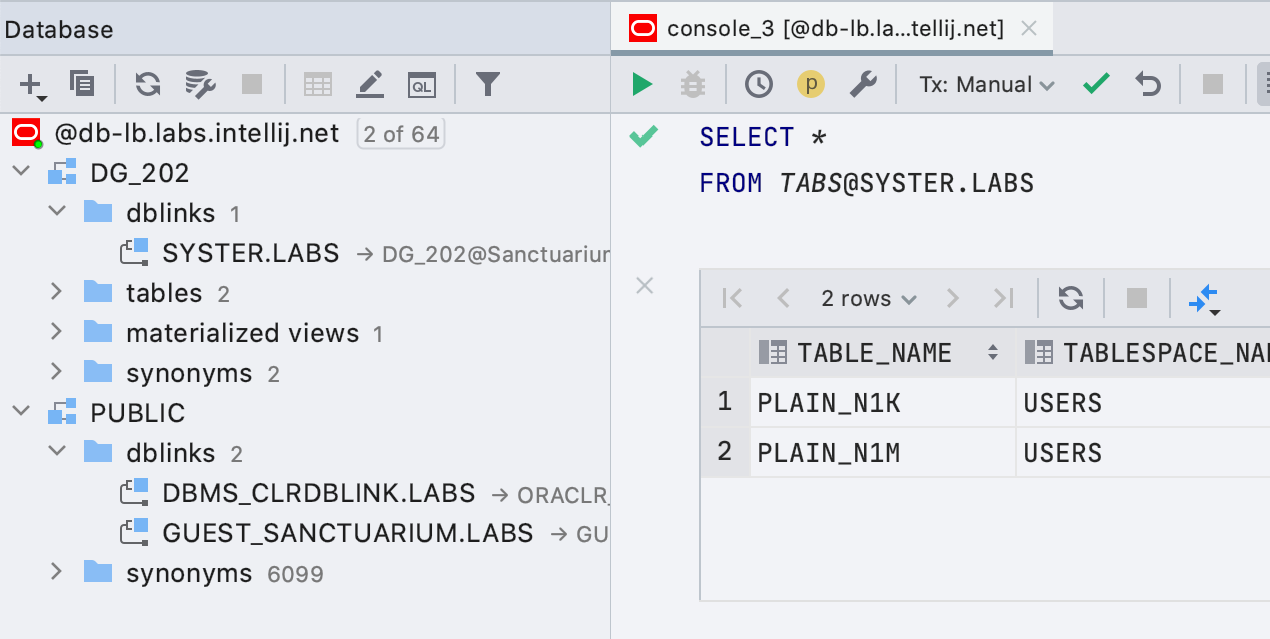
Unterstützung für einfache Oracle-Datenbankverknüpfungen Datenbankverknüpfungen
werden jetzt im Explorer angezeigt und Abfragen, die sie verwenden, werden korrekt hervorgehoben.
Allgemeines
Keine langen Tab-Namen mehr
Sie haben sich oft darüber beschwert, dass Tabs außer Kontrolle geraten .

Von jetzt an:
- Database | General | Always show qualified names for database objects , , .
- 20 , .
- , .
- — 36 , .
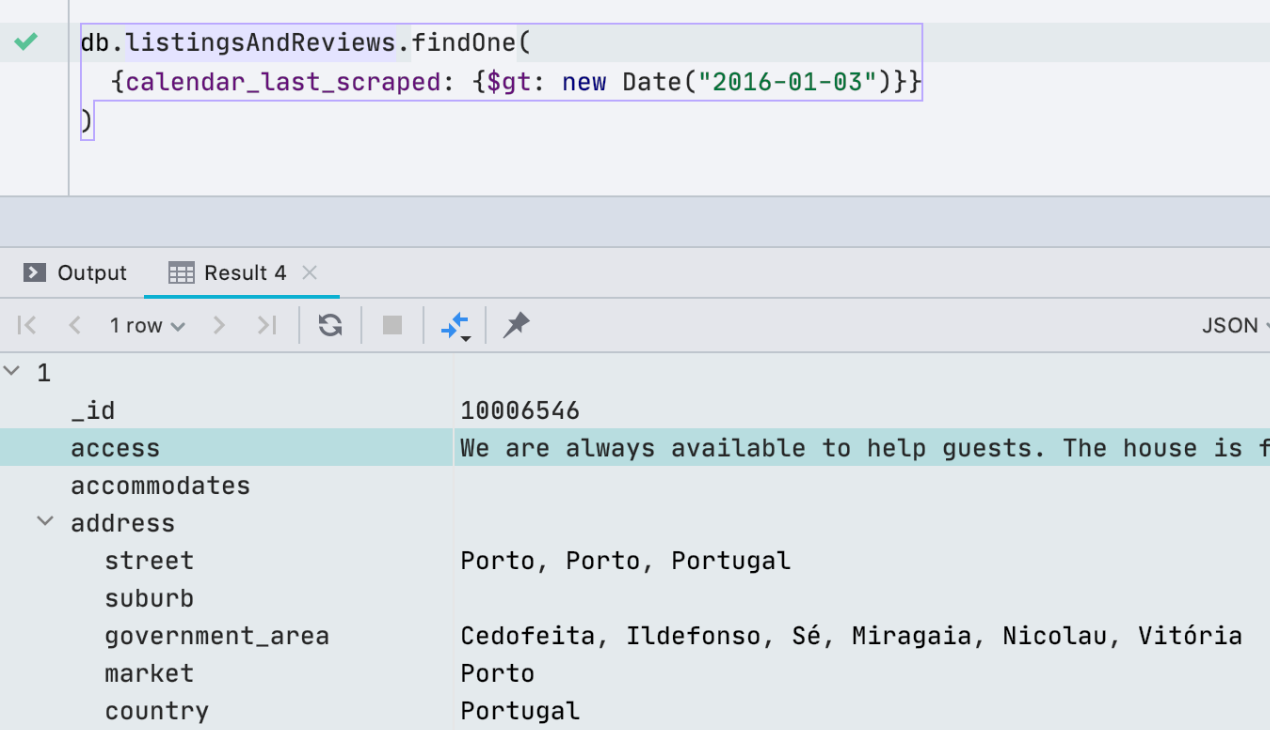
Unterstützung der MongoDB-Shell
Vor einem Monat haben wir den Treiber aktualisiert, mit dem wir eine Verbindung zu MongoDB herstellen, um die MongoDB-Shell zu unterstützen. Dies bedeutet, dass neue Befehle und Methoden funktioniert haben, z. B. help, db.getCollectionInfos (), db.getCollectionNames (), db.collection.remove () und andere. Ein ausführlicher englischer Artikel über die Unterstützung der MongoDB-Shell ist hier .
Native Bibliotheken in
den Treibereinstellungen Jetzt können Sie den Pfad zur nativen Bibliothek angeben, den der Treiber benötigt. Hier sind einige der Zeiten, in denen Sie es möglicherweise benötigen.

- SQL Server mssql-jdbc_auth-<version>-<arch>.dll SSO, . , SSO .
- Oracle ocijdbc, OCI .
- SQLite, ,
, , .
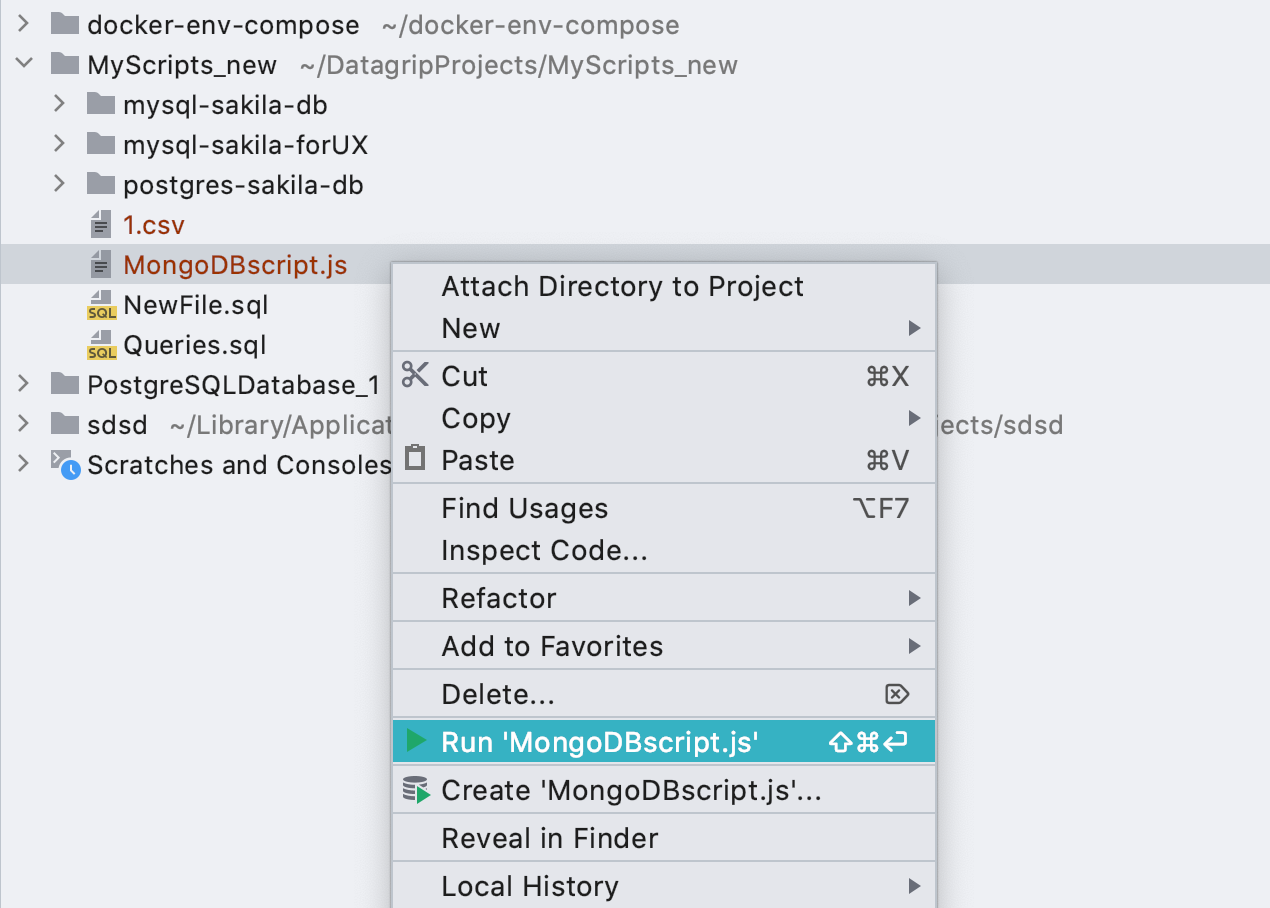
Konfigurationen für * .js-Dateien
starten Jetzt funktionieren Startkonfigurationen auch für MongoDB- Skripte .
Die Integration mit Git und Github funktioniert sofort.
Unsere Umfrage ergab, dass einige Leute Skripte in Versionskontrollsystemen speichern. Daher haben wir uns entschlossen, zwei der beliebtesten Plugins in diesem Bereich zu verpacken.

Vielen Dank für Ihre Aufmerksamkeit! Wir möchten Sie daran erinnern, dass wir in Telegram einen eigenen Kanal haben, in dem Sie Fragen stellen und Erfahrungen austauschen können. Wenn Sie jedoch einen Fehler finden, ist es besser, sofort in den Tracker zu schreiben, damit dieser nicht verloren geht. Naja, hier schreibe natürlich auch Kommentare :)
Das ist alles!
DataGrip-Team