
In diesem Artikel wird die Erfahrung beim Erstellen eines neuronalen Netzwerks zur Gesichtserkennung beschrieben, um alle Fotos aus einer VK-Konversation zu sortieren und eine bestimmte Person zu finden. Ohne Erfahrung im Schreiben neuronaler Netze und minimale Kenntnisse in Python.
Einführung
Wir haben einen Freund, der Sergei heißt, der es liebt, sich auf ungewöhnliche Weise zu fotografieren und ein Gespräch zu führen, und der diese Fotos auch mit Firmenphrasen würzt. An einem der Abende der Zwietracht hatten wir eine Idee - ein Publikum in VK zu schaffen, in dem wir Sergey mit seinen Zitaten posten konnten. Die ersten 10 Beiträge in der Verschiebung waren einfach, aber dann wurde klar, dass es keinen Sinn machte, alle Anhänge in einem Gespräch mit Ihren Händen durchzugehen. Daher wurde beschlossen, ein neuronales Netzwerk zu schreiben, um diesen Prozess zu automatisieren.
Planen
- Erhalten Sie Links zu Fotos aus einem Gespräch
- Fotos herunterladen
- Schreiben eines neuronalen Netzwerks
Vor Beginn der Entwicklung
, Python pip. , 0, ,
1. Links zu Fotos erhalten
Damit wir alle Fotos aus der Konversation erhalten möchten, ist die Methode messages.getHistoryAttachments für uns geeignet , die die Materialien des Dialogs oder der Konversation zurückgibt.
Seit dem 15. Februar 2019 hat Vkontakte den Zugriff auf Nachrichten für Anwendungen verweigert , die die Moderation nicht bestanden haben. Als Problemumgehung kann ich vkhost vorschlagen , mit dessen Hilfe Sie ein Token von Messenger von Drittanbietern erhalten
Mit dem empfangenen Token auf vkhost können wir die API-Anforderung, die wir benötigen, mithilfe von Postman erfassen . Sie können natürlich alles ohne Stifte füllen, aber aus Gründen der Übersichtlichkeit werden wir es verwenden.
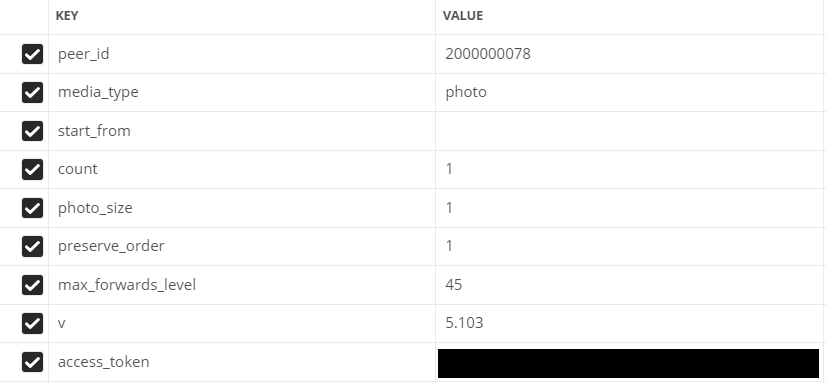
Geben Sie die Parameter ein:
- peer_id - Zielkennung
Für ein Gespräch: 2.000.000.000 + Gesprächs-ID (in der Adressleiste zu sehen).
Für Benutzer: Benutzer-ID. - Medientyp - Medientyp
In unserem Fall Foto
- start_from - Offset zur Auswahl mehrerer Elemente.
Lassen wir es jetzt leer.
- count - Die Anzahl der empfangenen Objekte
Maximal 200, so viel werden wir verwenden
- photo_sizes - Flag, um alle Größen im Array zurückzugeben
1 oder 0. Wir verwenden 1
- erve_order - Flag, das angibt, ob Anhänge in ihrer ursprünglichen Reihenfolge zurückgegeben werden sollen
1 oder 0. Wir verwenden 1
- v - vk api version
1 oder 0. Wir verwenden 1
Gefüllte Felder in Postman
Gehen Sie zum Schreiben von Code
Der Einfachheit halber wird der gesamte Code in mehrere separate Skripte aufgeteilt.
Verwendet das JSON- Modul (um die Daten zu dekodieren) und die Anforderungsbibliothek (um http-Anforderungen zu stellen).
Codeliste, wenn weniger als 200 Fotos in einer Konversation / einem Dialog vorhanden sind
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
Wenn es mehr als 200 Fotos gibt
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()Es ist Zeit, Links herunterzuladen
2. Bilder herunterladen
Zum Herunterladen von Fotos verwenden wir die urllib-Bibliothek
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
Das Herunterladen aller Bilder ist nicht der schnellste, insbesondere wenn 8330 Fotos vorhanden sind. Platz für diesen Fall ist ebenfalls erforderlich. Wenn die Anzahl der Fotos mit meiner oder mehr übereinstimmt, empfehle ich, dafür 1,5 bis 2 GB freizugeben . Die

grobe Arbeit ist abgeschlossen, jetzt können Sie selbst beginnen interessant - ein neuronales Netzwerk schreiben
3. Schreiben eines neuronalen Netzwerks
Nachdem wir viele verschiedene Bibliotheken und Optionen durchgesehen hatten, wurde beschlossen, die Gesichtserkennungsbibliothek zu verwenden
Was kann ich tun?
In der Dokumentation werden die grundlegendsten Funktionen betrachtet.
Finden von Gesichtern in Fotos
Kann eine beliebige Anzahl von Gesichtern in einem Foto finden, sogar mit Unschärfe umgehen.

Identifizierung von Gesichtern in einem Foto.
Kann erkennen, wem ein Gesicht in einem Foto gehört.

Für uns ist die Identifizierung von Gesichtern am besten geeignet
Ausbildung
Von den Anforderungen für die Bibliothek ist Python 3.3+ oder Python 2.7 erforderlich.
In Bezug auf Bibliotheken werden die oben erwähnte Gesichtserkennung und PIL für die Arbeit mit Bildern verwendet.
Die Gesichtserkennungsbibliothek wird unter Windows nicht offiziell unterstützt , hat aber bei mir funktioniert. Alles funktioniert stabil mit MacOS und Linux.
Erklärung, was passiert
Zunächst müssen wir einen Klassifikator festlegen, um nach einer Person zu suchen, von der bereits eine weitere Überprüfung der Fotos erfolgt.
Ich empfehle, das klarste Foto einer Person in Frontalansicht zu wählen.Beim Hochladen eines Fotos zerlegt die Bibliothek die Bilder in die Koordinaten der Gesichtszüge einer Person (Nase, Augen, Mund und Kinn).

Nun, dann ist die Sache klein, es bleibt nur eine ähnliche Methode auf das Foto anzuwenden, für das wir mit unserem Klassifikator vergleichen möchten. Dann lassen wir das neuronale Netzwerk Gesichtsmerkmale anhand von Koordinaten vergleichen.
Nun, der eigentliche Code selbst:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
Es ist auch möglich, alles einer eingehenden Analyse auf einer Grafikkarte zu unterziehen. Dazu müssen Sie den Parameter model = "cnn" hinzufügen und das Codefragment für das Bild ändern, mit dem wir nach der richtigen Person suchen möchten:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Ergebnis
Keine GPU. Mit der Zeit durchlief und sortierte das neuronale Netzwerk 8330 Fotos in 1 Stunde 40 Minuten und fand gleichzeitig 142 Fotos, 62 davon mit dem Bild der gewünschten Person. Natürlich gab es falsch positive Ergebnisse bei Memen und anderen Personen.
C GPU. Die Bearbeitungszeit dauerte viel länger, 17 Stunden und 22 Minuten, und ich fand 230 Fotos, von denen 99 die Leute sind, die wir brauchen.
Abschließend können wir sagen, dass die Arbeit nicht umsonst geleistet wurde. Wir haben das Sortieren von 8330 Fotos automatisiert, was viel besser ist als das Sortieren selbst.
Sie können auch den gesamten Quellcode von github herunterladen