Hallo! Es ist schwierig, einen Mikrocontroller-Programmierer zu finden, der noch nie einen schweren Fehler hatte. Sehr oft wird es in keiner Weise verarbeitet, sondern bleibt einfach in einer Endlosschleife des Handlers hängen, die in der Startdatei des Herstellers enthalten ist. Gleichzeitig versucht der Programmierer intuitiv, den Grund für den Fehler zu finden. Meiner Meinung nach ist dies nicht der beste Weg, um das Problem zu lösen.
In diesem Artikel möchte ich eine Technik zur Analyse schwerwiegender Fehler gängiger Mikrocontroller mit einem Cortex M3 / M4-Kern beschreiben. Obwohl "Technik" vielleicht ein zu lautes Wort ist. Ich nehme nur ein Beispiel dafür, wie ich das Auftreten schwerwiegender Fehler analysiere und zeige, was in einer ähnlichen Situation getan werden kann. Ich werde IAR-Software und das STM32F4DISCOVERY-Debugboard verwenden, da viele angehende Programmierer über diese Tools verfügen. Dies ist jedoch völlig irrelevant. Dieses Beispiel kann für jeden Prozessor der Familie und jede Entwicklungsumgebung angepasst werden.

Fallen Sie in HardFault
Bevor Sie versuchen, HatdFault zu analysieren, müssen Sie sich damit befassen. Es gibt viele Möglichkeiten, dies zu tun. Mir kam sofort der Gedanke, den Prozessor vom Thumb-Zustand in den ARM-Zustand zu versetzen, indem ich die Adresse des bedingungslosen Sprungbefehls auf eine gerade Zahl setzte.
Ein kleiner Exkurs. Wie Sie wissen, verwenden Mikrocontroller der Cortex M3 / M4-Familie den Thumb-2-Montageanweisungssatz und arbeiten immer im Thumb-Modus. Der ARM-Modus wird nicht unterstützt. Wenn Sie versuchen, den Wert der bedingungslosen Sprungadresse (BX reg) mit dem niedrigstwertigen gelöschten Bit festzulegen, tritt die UsageFault-Ausnahme auf, da der Prozessor versucht, seinen Status auf ARM umzuschalten. Weitere Informationen hierzu finden Sie in [1] (Abschnitte 2.8 THE INSTRUCTION SET; 4.3.4 Assembler-Sprache: Call and Unconditional Branch).
Zunächst schlage ich vor, einen bedingungslosen Sprung zu einer geraden Adresse in C / C ++ zu simulieren. Dazu erstelle ich die Funktion func_hard_fault und versuche, sie per Zeiger aufzurufen, nachdem ich die Zeigeradresse um eins verringert habe. Dies kann wie folgt erfolgen:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
Mal sehen, was ich mit dem Debugger gemacht habe.

In rot habe ich den aktuellen Sprungbefehl an der Adresse in ROZ R1 hervorgehoben, die eine gerade Sprungadresse enthält. Als Ergebnis:

Dieser Vorgang kann noch einfacher mit Assembler-Einsätzen ausgeführt werden:
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
Hurra, wir sind in HardFault eingestiegen, Mission abgeschlossen!
HardFault-Analyse
Wo sind wir zu HardFault gekommen?
Meiner Meinung nach ist es am wichtigsten herauszufinden, woher wir zu HardFault gekommen sind. Dies ist nicht schwer zu tun. Schreiben wir zunächst unseren eigenen Handler für die HardFault-Situation.
extern "C"
{
void HardFault_Handler(void)
{
}
}Lassen Sie uns nun darüber sprechen, wie wir herausfinden können, wie wir hierher gekommen sind. Der Cortex M3 / M4-Prozessorkern hat so etwas Wunderbares wie die Kontexterhaltung [1] (Abschnitt 9.1.1 Stapeln). In einfachen Worten, wenn eine Ausnahme auftritt, wird der Inhalt der Register R0-R3, R12, LR, PC, PSR auf dem Stapel gespeichert.

Hier ist das für uns wichtigste Register das PC-Register, das Informationen über den aktuell ausgeführten Befehl enthält. Da der Registerwert zum Zeitpunkt der Ausnahme auf den Stapel verschoben wurde, enthält er die Adresse des zuletzt ausgeführten Befehls. Der Rest der Register ist für die Analyse weniger wichtig, aber etwas Nützliches kann ihnen entzogen werden. LR ist die Rücksprungadresse des letzten Übergangs, R0-R3, R12 sind Werte, die angeben können, in welche Richtung bewegt werden soll. PSR ist nur ein allgemeines Register des Programmstatus.
Ich schlage vor, die Werte der Register im Handler herauszufinden. Zu diesem Zweck habe ich den folgenden Code geschrieben (ich habe einen ähnlichen Code in einer der Dateien des Herstellers gesehen):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
Als Ergebnis haben wir die Werte aller gespeicherten Register:
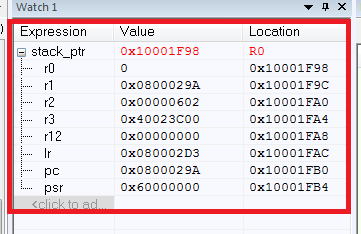
Was ist hier passiert? Zuerst haben wir den Stapelzeiger stack_ptr, hier ist alles klar. Beim Einfügen des Assemblers treten Schwierigkeiten auf (wenn die Assembler-Anweisungen für Cortex verstanden werden müssen, empfehle ich [2]).
Warum haben wir den Stack nicht einfach über MRS stack_ptr, MSP gespeichert? Tatsache ist, dass die Cortex M3 / M4-Kerne zwei Stapelzeiger [1] haben (Punkt 3.1.3 Stapelzeiger R13) - den Haupt-MSP-Stapelzeiger und den PSP-Prozessstapelzeiger. Sie werden für verschiedene Prozessormodi verwendet. Ich werde nicht näher darauf eingehen, wofür dies getan wird und wie es funktioniert, aber ich werde eine kleine Erklärung geben.
Um den Prozessorbetriebsmodus (der in diesem MSP oder PSP verwendet wird) herauszufinden, müssen Sie das dritte Bit des Kommunikationsregisters überprüfen. Dieses Bit bestimmt, welcher Stapelzeiger verwendet wird, um von einer Ausnahme zurückzukehren. Wenn dieses Bit gesetzt ist, ist es MSP, wenn nicht, dann PSP. Im Allgemeinen verwenden die meisten in C / C ++ geschriebenen Anwendungen nur MSPs, und diese Prüfung kann weggelassen werden.
Was ist das Endergebnis? Mit einer Liste gespeicherter Register können wir leicht feststellen, woher das Programm in HardFault aus dem PC-Register stammt. Der PC zeigt auf die Adresse 0x0800029A, die die Adresse unserer Anweisung "Brechen" ist. Vergessen Sie auch nicht, wie wichtig die Werte der anderen Register sind.
Ursache von HardFault
Tatsächlich können wir auch die Ursache des HardFault herausfinden. Zwei Register helfen uns dabei. Hard-Fehlerstatusregister (HFSR) und konfigurierbares Fehlerstatusregister (CFSR; UFSR + BFSR + MMFSR). Das CFSR-Register besteht aus drei Registern: Nutzungsfehlerstatusregister (UFSR), Busfehlerstatusregister (BFSR), Speicherverwaltungsfehleradressregister (MMFSR). Sie können darüber beispielsweise in [1] und [3] lesen.
Ich schlage vor zu sehen, was diese Register in meinem Fall erzeugen:

Zuerst wird das HFSR FORCED-Bit gesetzt. Dies bedeutet, dass ein Fehler aufgetreten ist, der nicht verarbeitet werden kann. Zur weiteren Diagnose sollten die verbleibenden Fehlerstatusregister untersucht werden.
Zweitens wird das CFSR INVSTATE-Bit gesetzt. Dies bedeutet, dass ein UsageFault aufgetreten ist, weil der Prozessor versucht hat, eine Anweisung auszuführen, die EPSR illegal verwendet.
Was ist EPSR? EPSR - Statusregister des Ausführungsprogramms. Dies ist ein internes PSR-Register - ein spezielles Programmstatusregister (das, wie wir uns erinnern, auf dem Stapel gespeichert ist). Das vierundzwanzigste Bit dieses Registers zeigt den aktuellen Status des Prozessors (Thumb oder ARM) an. Dies kann unseren Grund für den Fehler bestimmen. Versuchen wir es zu zählen:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
Als Ergebnis der Ausführung erhalten wir den Wert EPSR = 0.

Es stellt sich heraus, dass das Register den Status von ARM anzeigt und wir die Ursache des Fehlers gefunden haben. Nicht wirklich. Nach [3] (S. 23) gibt das Lesen dieses Registers mit einem speziellen MSR-Befehl immer Null zurück. Mir ist nicht sehr klar, warum es so funktioniert, da dieses Register bereits schreibgeschützt ist, aber hier nicht vollständig gelesen werden kann (nur einige Bits können über xPSR verwendet werden). Vielleicht sind dies einige architektonische Einschränkungen.
Leider geben all diese Informationen einem gewöhnlichen MK-Programmierer praktisch nichts. Deshalb betrachte ich alle diese Register nur als Ergänzung zur Analyse des gespeicherten Kontexts.
Wenn der Fehler beispielsweise durch Division durch Null verursacht wurde (dieser Fehler wird durch Setzen des DIV_0_TRP-Bits des CCR-Registers zugelassen), wird das DIVBYZERO-Bit im CFSR-Register gesetzt, was uns den Grund für diesen Fehler anzeigt.
Was weiter?
Was kann getan werden, nachdem wir die Fehlerursache analysiert haben? Das folgende Verfahren scheint eine gute Option zu sein:
- Drucken Sie die Werte aller analysierten Register in die Debug-Konsole (printf). Dies ist nur möglich, wenn Sie über einen JTAG-Debugger verfügen.
- Speichern Sie die Fehlerinformationen im internen oder externen (falls verfügbar) Flash. Es ist auch möglich, den Wert des PC-Registers auf dem Gerätebildschirm anzuzeigen (falls verfügbar).
- Laden Sie den Prozessor NVIC_SystemReset () neu.

Quellen
- Joseph Yiu. Die endgültige Anleitung zum ARM Cortex-M3.
- Allgemeines Benutzerhandbuch für Cortex-M3-Geräte.
- STM32 Cortex-M4 MCUs und MPUs Programmierhandbuch.