In diesem Artikel werde ich Ihnen die wichtigsten BigQuery-Funktionen erläutern und ihre Funktionen anhand konkreter Beispiele zeigen. Sie können grundlegende Abfragen schreiben und diese an Demo-Daten ausprobieren.
Was ist SQL und welche Dialekte hat es?
SQL (Structured Query Language) ist eine strukturierte Abfragesprache für die Arbeit mit Datenbanken. Mit seiner Hilfe können Sie große Datenmengen empfangen, zur Datenbank hinzufügen und ändern. Google BigQuery unterstützt zwei Dialekte: Standard SQL und Legacy SQL.
Welchen Dialekt Sie wählen, hängt von Ihren Vorlieben ab. Google empfiehlt jedoch die Verwendung von Standard SQL aufgrund einer Reihe von Vorteilen:
- Flexibilität und Funktionalität beim Arbeiten mit verschachtelten und sich wiederholenden Feldern.
- Unterstützung für DML- und DDL- Sprachen , mit denen Sie Daten in Tabellen ändern sowie Tabellen und Ansichten in GBQ bearbeiten können.
- Die Verarbeitung großer Datenmengen ist schneller als bei Legasy SQL.
- Unterstützung für alle aktuellen und zukünftigen BigQuery-Updates.
Weitere Informationen zum Unterschied zwischen Dialekten finden Sie in der Hilfe .
Standardmäßig werden Google BigQuery-Abfragen für Legacy SQL ausgeführt.
Es gibt verschiedene Möglichkeiten, zu Standard SQL zu wechseln:
- Wählen Sie in der BigQuery-Oberfläche im Abfragebearbeitungsfenster "Optionen anzeigen" und deaktivieren Sie das Kontrollkästchen neben der Option "Legacy-SQL verwenden"

- Fügen Sie die Zeile #standardSQL vor der Abfrage hinzu und starten Sie die Abfrage in einer neuen Zeile

Wo soll ich anfangen?
Damit Sie das Ausführen von Abfragen parallel zum Lesen des Artikels üben können, habe ich eine Tabelle mit Demodaten für Sie vorbereitet . Laden Sie die Daten aus der Tabelle in Ihr Google BigQuery-Projekt.
Wenn Sie noch kein GBQ-Projekt haben, erstellen Sie eines. Dazu benötigen Sie ein aktives Abrechnungskonto in der Google Cloud Platform . Sie müssen die Karte verknüpfen, aber ohne Ihr Wissen wird kein Geld von ihr abgebucht. Außerdem erhalten Sie bei der Registrierung 12 Monate lang 300 US-Dollar , die Sie für die Speicherung und Verarbeitung von Daten ausgeben können.
Google BigQuery-Funktionen
Die am häufigsten verwendeten Funktionsgruppen beim Erstellen von Abfragen sind die Aggregatfunktion, die Datumsfunktion, die Zeichenfolgenfunktion und die Fensterfunktion. Nun mehr zu jedem von ihnen.
Aggregatfunktion
Mit Aggregationsfunktionen können Sie Zusammenfassungswerte für die gesamte Tabelle abrufen. Berechnen Sie beispielsweise den durchschnittlichen Scheck, das monatliche Gesamteinkommen oder markieren Sie das Segment der Benutzer, die die maximale Anzahl von Einkäufen getätigt haben.
Hier sind die beliebtesten Funktionen aus diesem Abschnitt:
| Legacy SQL | Standard SQL | Was die Funktion macht |
|---|---|---|
| AVG (Feld) | AVG ([DISTINCT] (Feld)) | Gibt den Durchschnitt der Feldspalte zurück. In Standard SQL wird beim Hinzufügen der DISTINCT-Klausel der Durchschnitt nur für Zeilen mit eindeutigen (nicht doppelten) Werten aus der Feldspalte berechnet |
| MAX (Feld) | MAX (Feld) | Gibt den Maximalwert aus der Feldspalte zurück |
| MIN (Feld) | MIN (Feld) | Gibt den Mindestwert aus der Feldspalte zurück |
| SUMME (Feld) | SUMME (Feld) | Gibt die Summe der Werte aus der Feldspalte zurück |
| COUNT (Feld) | COUNT (Feld) | Gibt die Anzahl der Zeilen im Spaltenfeld zurück |
| EXACT_COUNT_DISTINCT (Feld) | COUNT ([DISTINCT] (Feld)) | Gibt die Anzahl der eindeutigen Zeilen in der Feldspalte zurück |
Eine Liste aller Funktionen finden Sie in der Hilfe: Legacy SQL und Standard SQL .
Lassen Sie uns sehen, wie die aufgelisteten Funktionen mit einer Beispieldatendemo funktionieren. Berechnen wir das durchschnittliche Einkommen aus Transaktionen, Einkäufen mit dem höchsten und niedrigsten Betrag, das Gesamteinkommen und die Anzahl aller Transaktionen. Um zu überprüfen, ob Einkäufe doppelt vorhanden sind, berechnen wir auch die Anzahl der eindeutigen Transaktionen. Dazu schreiben wir eine Abfrage, in der wir den Namen unseres Google BigQuery-Projekts, des Datensatzes und der Tabelle angeben.
#legasy SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
EXACT_COUNT_DISTINCT(transactionId) as unique_transactions
FROM
[owox-analytics:t_kravchenko.Demo_data]#standard SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
COUNT(DISTINCT(transactionId)) as unique_transactions
FROM
`owox-analytics.t_kravchenko.Demo_data`Als Ergebnis erhalten wir die folgenden Ergebnisse:
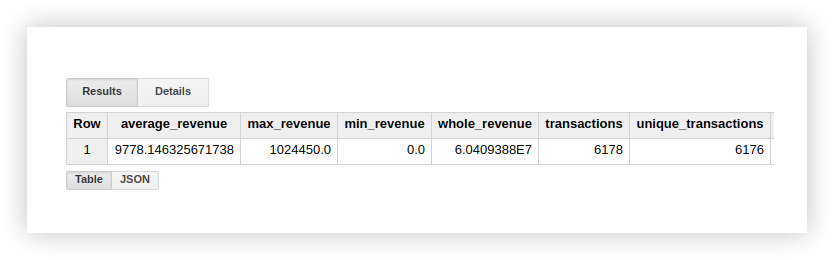
Sie können die Berechnungsergebnisse in der Originaltabelle mit Demo-Daten überprüfen, indem Sie Standardfunktionen von Google Sheets (SUM, AVG und andere) oder Pivot-Tabellen verwenden.
Wie Sie dem obigen Screenshot entnehmen können, ist die Anzahl der Transaktionen und eindeutigen Transaktionen unterschiedlich.
Dies deutet darauf hin, dass unsere Tabelle zwei Transaktionen mit einer doppelten Transaktions-ID enthält:
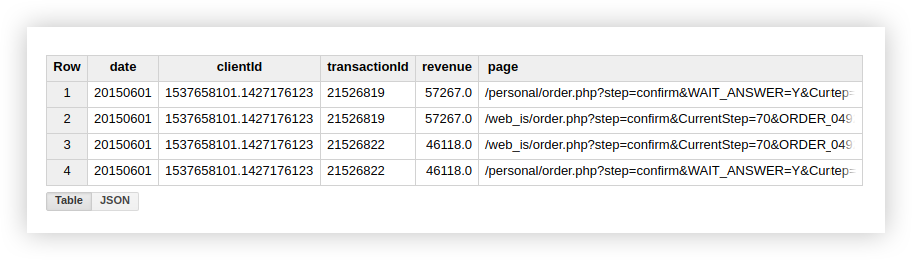
Wenn Sie an eindeutigen Transaktionen interessiert sind, verwenden Sie daher die Funktion, die eindeutige Zeilen zählt. Alternativ können Sie die Daten mithilfe einer GROUP BY-Klausel gruppieren, um Duplikate zu entfernen, bevor Sie die Aggregationsfunktion verwenden.
Funktionen zum Arbeiten mit Datumsangaben (Datumsfunktion)
Mit diesen Funktionen können Sie Datumsangaben verarbeiten: Ändern Sie das Format, wählen Sie das gewünschte Teil (Tag, Monat oder Jahr) aus und verschieben Sie das Datum um ein bestimmtes Intervall.
Sie können in folgenden Fällen hilfreich sein:
- Beim Einrichten von End-to-End-Analysen - um Datum und Uhrzeit aus verschiedenen Quellen in ein einziges Format zu bringen.
- Beim Erstellen automatisch aktualisierter Berichte oder ausgelöster Mailings. Zum Beispiel, wenn Sie Daten für die letzten 2 Stunden, eine Woche oder einen Monat benötigen.
- Bei der Erstellung von Kohortenberichten, bei denen Daten im Kontext von Tagen, Wochen, Monaten abgerufen werden müssen.
Am häufigsten verwendete Datumsfunktionen:
| Legacy SQL | Standard SQL | Was die Funktion macht |
|---|---|---|
| AKTUELLES DATUM () | AKTUELLES DATUM () | Gibt das aktuelle Datum im Format% JJJJ-% MM-% TT zurück |
| DATUM (Zeitstempel) | DATUM (Zeitstempel) | Konvertiert ein Datum aus dem Format% JJJJ-% MM-% TT% H:% M:% S. im Format% JJJJ-% MM-% TT |
| DATE_ADD (Zeitstempel, Intervall, Intervalleinheiten) | DATE_ADD(timestamp, INTERVAL interval interval_units) | timestamp, interval.interval_units.
Legacy SQL YEAR, MONTH, DAY, HOUR, MINUTE SECOND, Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
| DATE_ADD(timestamp, — interval, interval_units) | DATE_SUB(timestamp, INTERVAL interval interval_units) | timestamp, interval |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | timestamp1 timestamp2.
Legacy SQL , Standard SQL — date_part (, , , , ) |
| DAY(timestamp) | EXTRACT(DAY FROM timestamp) | timestamp. 1 31 |
| MONTH(timestamp) | EXTRACT(MONTH FROM timestamp) | timestamp. 1 12 |
| YEAR(timestamp) | EXTRACT(YEAR FROM timestamp) | timestamp |
Eine Liste aller Funktionen finden Sie in der Legacy SQL- und Standard SQL- Hilfe .
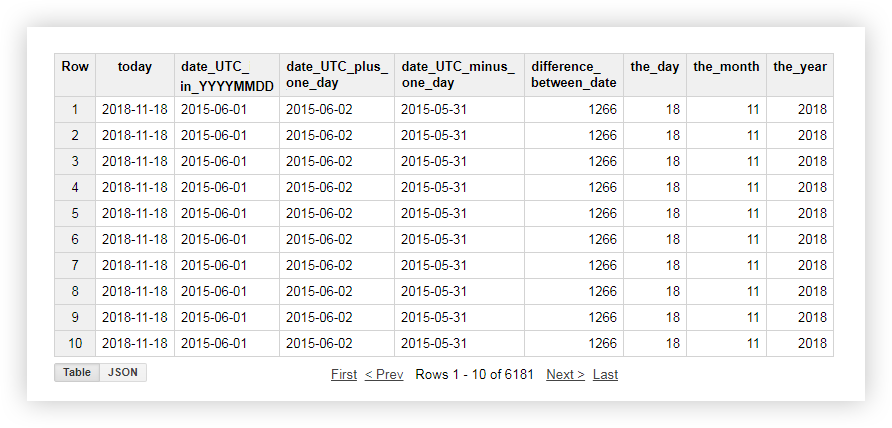
Schauen wir uns eine Demo der Daten an, wie jede der oben genannten Funktionen funktioniert. Zum Beispiel erhalten wir das aktuelle Datum, bringen das Datum aus der Originaltabelle in das Format% JJJJ-% MM-% TT, subtrahieren und addieren einen Tag dazu. Dann berechnen wir die Differenz zwischen dem aktuellen Datum und dem Datum aus der Originaltabelle und teilen das aktuelle Datum getrennt in Jahr, Monat und Tag auf. Dazu können Sie die folgenden Beispielabfragen kopieren und den Namen des Projekts, des Datensatzes und der Datentabelle durch Ihren eigenen ersetzen.
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
#standard SQL
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)
Nach Beantragung der Anfrage erhalten Sie folgenden Bericht:
Funktionen zum Arbeiten mit Strings (String-Funktion)
Mit String-Funktionen können Sie einen String bilden, Teilzeichenfolgen hervorheben und ersetzen, die Länge der Zeichenfolge und den Ordnungsindex der Teilzeichenfolge in der ursprünglichen Zeichenfolge berechnen.
Mit ihrer Hilfe können Sie beispielsweise:
- Erstellen Sie im Bericht Filter nach UTM-Tags, die an die Seiten-URL übergeben werden.
- Bringen Sie die Daten in ein einheitliches Format, wenn die Namen der Quellen und Kampagnen in verschiedenen Registern geschrieben sind.
- Ersetzen Sie beispielsweise falsche Daten im Bericht, wenn der Kampagnenname mit einem Tippfehler gesendet wurde.
Die beliebtesten Funktionen zum Arbeiten mit Strings:
| Legacy SQL | Standard SQL | Was die Funktion macht |
|---|---|---|
| CONCAT ('str1', 'str2') oder 'str1' + 'str2' | CONCAT ('str1', 'str2') | Verkettet mehrere Zeichenfolgen 'str1' und 'str2' zu einer |
| 'str1' ENTHÄLT 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )
CHARACTER_LENGTH('str' ) |
'str' ( ) |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | max_len, index 'str' |
| LOWER('str') | LOWER('str') | 'str' |
| UPPER(str) | UPPER(str) | 'str' |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Gibt den Index des ersten Vorkommens der Zeichenfolge 'str2' in der Zeichenfolge 'str1' zurück, andernfalls - 0 |
| ERSETZEN ('str1', 'str2', 'str3') | ERSETZEN ('str1', 'str2', 'str3') | Ersetzt in der Zeichenfolge 'str1' Teilzeichenfolge 'str2' durch Teilzeichenfolge 'str3' |
Weitere Details in der Hilfe: Legacy SQL und Standard SQL .
Lassen Sie uns am Beispiel von Demodaten analysieren, wie die beschriebenen Funktionen verwendet werden. Angenommen, wir haben 3 separate Spalten, die die Werte von Tag, Monat und Jahr enthalten: Die
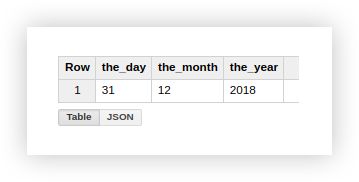
Arbeit mit einem Datum in diesem Format ist nicht sehr praktisch, daher werden wir es in einer Spalte kombinieren. Verwenden Sie dazu die folgenden SQL-Abfragen und vergessen Sie nicht, den Namen Ihres Projekts, des Datasets und der Google BigQuery-Tabelle anzugeben.
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
#standard SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
Nach dem Ausführen der Anforderung erhalten wir das Datum in einer Spalte:

Beim Laden einer bestimmten Seite auf der Site enthält die URL häufig die Werte der Variablen, die der Benutzer ausgewählt hat. Dies kann eine Zahlungs- oder Liefermethode, eine Transaktionsnummer, ein Index eines physischen Geschäfts sein, in dem ein Kunde einen Artikel abholen möchte usw. Mithilfe einer SQL-Abfrage können Sie diese Parameter aus der Seitenadresse extrahieren.
Schauen wir uns zwei Beispiele an, wie und warum dies zu tun ist.
Beispiel 1 . Angenommen, wir möchten wissen, wie viele Einkäufe Benutzer bei physischen Geschäften abholen. Dazu müssen Sie die Anzahl der Transaktionen zählen, die von Seiten gesendet wurden, deren URL die Teilzeichenfolge shop_id (Index des physischen Speichers) enthält. Wir tun dies mit den folgenden Abfragen:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
#standard SQL
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
Aus der resultierenden Tabelle geht hervor, dass 5502 Transaktionen von den Seiten gesendet wurden, die die shop_id enthalten (check = true):
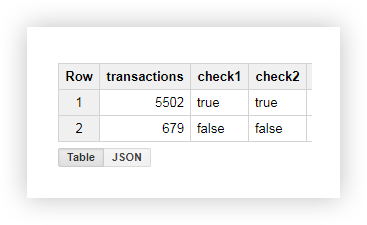
Beispiel 2 . Angenommen, Sie haben jeder Übermittlungsmethode Ihre Zustell-ID zugewiesen und den Wert dieses Parameters in die Seiten-URL geschrieben. Um herauszufinden, welche Übermittlungsmethode der Benutzer ausgewählt hat, wählen Sie Delivery_id in einer separaten Spalte aus.
Wir verwenden hierfür die folgenden Abfragen:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
#standard SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASC
Als Ergebnis erhalten wir die folgende Tabelle in Google BigQuery:

Funktionen zum Arbeiten mit Teilmengen von Daten oder Fensterfunktionen (Fensterfunktion)
Diese Funktionen ähneln den oben diskutierten Aggregationsfunktionen. Der Hauptunterschied besteht darin, dass Berechnungen nicht für den gesamten Datensatz durchgeführt werden, der mit einer Abfrage ausgewählt wurde, sondern für einen Teil davon - eine Teilmenge oder ein Fenster.
Mithilfe von Fensterfunktionen können Sie Daten nach Gruppen zusammenfassen, ohne den JOIN-Operator zum Kombinieren mehrerer Abfragen zu verwenden. Berechnen Sie beispielsweise das durchschnittliche Einkommen durch Werbekampagnen und die Anzahl der Transaktionen pro Gerät. Wenn Sie dem Bericht ein weiteres Feld hinzufügen, können Sie beispielsweise den Anteil der Einnahmen aus einer Werbekampagne am Black Friday oder den Anteil der Transaktionen mit einer mobilen Anwendung leicht ermitteln.
Zusammen mit jeder Funktion muss ein OVER-Ausdruck in die Anforderung geschrieben werden, der die Fenstergrenzen definiert. OVER enthält 3 Komponenten, mit denen Sie arbeiten können:
- PARTITION BY - Definiert das Attribut, mit dem Sie die Quelldaten in Teilmengen aufteilen, z. B. PARTITION BY clientId, DayTime.
- ORDER BY - Definiert die Reihenfolge der Zeilen in der Teilmenge, z. B. ORDER BY hour DESC.
- FENSTERRAHMEN - Ermöglicht die Verarbeitung von Zeilen innerhalb einer Teilmenge gemäß einem bestimmten Merkmal. Beispielsweise können Sie die Summe nicht aller Zeilen im Fenster berechnen, sondern nur der ersten fünf vor der aktuellen Zeile.
Diese Tabelle fasst die am häufigsten verwendeten Fensterfunktionen zusammen:
| Legacy SQL | Standard SQL | Was die Funktion macht |
|---|---|---|
| AVG (Feld)
COUNT (Feld) COUNT (DISTINCT-Feld) MAX () MIN () SUM () |
AVG ([DISTINCT] (Feld))
COUNT (Feld) COUNT ([DISTINCT] (Feld)) MAX (Feld) MIN (Feld) SUM (Feld) |
, , , field .
DISTINCT , () |
| 'str1' CONTAINS 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| DENSE_RANK() | DENSE_RANK() | |
| FIRST_VALUE(field) | FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAST_VALUE(field) | LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAG(field) | LAG (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
| LEAD(field) | LEAD (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
Eine Liste aller Funktionen finden Sie in der Hilfe zu Legacy SQL und Standard SQL: Aggregierte Analysefunktionen , Navigationsfunktionen .
Beispiel 1. Angenommen, wir möchten die Aktivität von Kunden während der Arbeits- und Nichtarbeitszeit analysieren. Dazu müssen Sie Transaktionen in zwei Gruppen aufteilen und die Metriken berechnen, an denen wir interessiert sind:
- Gruppe 1 - Einkäufe während der Geschäftszeiten von 9:00 bis 18:00 Uhr.
- Gruppe 2 - Einkäufe außerhalb der Arbeitszeit von 00:00 bis 9:00 Uhr und von 18:00 bis 00:00 Uhr.
Neben der Arbeitszeit und der Nichtarbeitszeit ist clientId ein weiteres Zeichen für die Bildung eines Fensters, dh für jeden Benutzer haben wir zwei Fenster:
| Teilmenge (Fenster) | Kunden ID | Tageszeit |
|---|---|---|
| 1 Fenster | clientId 1 | Arbeitszeit |
| 2 Fenster | clientId 2 | Arbeitsfreie Zeit |
| 3 Fenster | clientId 3 | Arbeitszeit |
| 4 Fenster | clientId 4 | Arbeitsfreie Zeit |
| N Fenster | clientId N. | Arbeitszeit |
| N + 1 Fenster | clientId N + 1 | Arbeitsfreie Zeit |
Berechnen wir das durchschnittliche, maximale, minimale und Gesamteinkommen, die Anzahl der Transaktionen und die Anzahl der eindeutigen Transaktionen für jeden Benutzer während der Arbeits- und Nichtarbeitszeit anhand der Demodaten. Die folgenden Fragen helfen uns dabei.
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
#standard SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
Lassen Sie uns am Beispiel eines Benutzers mit clientId = '102041117.1428132012' sehen, was als Ergebnis passiert ist. In der ursprünglichen Tabelle für diesen Benutzer hatten wir die folgenden Daten:
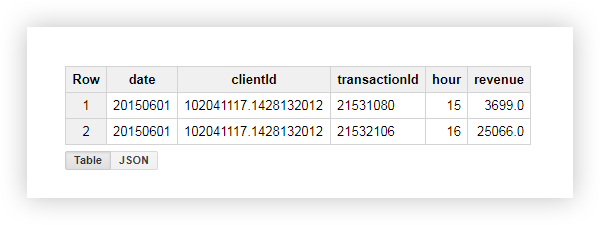
Durch Anwenden der Abfrage haben wir einen Bericht erhalten, der das durchschnittliche, minimale, maximale und Gesamteinkommen dieses Benutzers sowie die Anzahl der Transaktionen enthält. Wie Sie im folgenden Screenshot sehen können, hat der Benutzer beide Transaktionen während der Geschäftszeiten ausgeführt:

Beispiel 2 . Lassen Sie uns die Aufgabe nun etwas komplizieren:
- Lassen Sie uns die Sequenznummern für alle Transaktionen im Fenster abhängig vom Zeitpunkt ihrer Ausführung notieren. Denken Sie daran, dass wir ein Fenster nach Benutzer und Arbeits- / Nichtarbeitszeit definieren.
- Lassen Sie uns die Einnahmen der nächsten / vorherigen Transaktion (relativ zur aktuellen) im Fenster anzeigen.
- Lassen Sie uns die Einnahmen der ersten und letzten Transaktion im Fenster anzeigen.
Hierzu verwenden wir folgende Abfragen:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
#standard SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
Lassen Sie uns die Berechnungsergebnisse am Beispiel eines Benutzers überprüfen, der uns bereits mit clientId = '102041117.1428132012' vertraut ist:

Aus dem obigen Screenshot sehen wir Folgendes :
- Die erste Transaktion war um 15:00 Uhr und die zweite um 16:00 Uhr.
- Nach der aktuellen Transaktion um 15:00 Uhr gab es um 16:00 Uhr eine Transaktion mit einem Einkommen von 25066 (Spalte lead_revenue).
- Vor der aktuellen Transaktion um 16:00 Uhr gab es um 15:00 Uhr eine Transaktion mit einem Umsatz von 3699 (Spalte lag_revenue).
- Die erste Transaktion innerhalb des Fensters war eine Transaktion um 15:00 Uhr, deren Einkommen 3699 beträgt (Spalte first_revenue_by_hour).
- Die Anforderung verarbeitet die Daten zeilenweise, sodass sie für die betreffende Transaktion die letzte im Fenster sind und die Werte in den Spalten last_revenue_by_hour und Revenue gleich sind.
Schlussfolgerungen
In diesem Artikel haben wir die beliebtesten Funktionen aus den Abschnitten Aggregatfunktion, Datumsfunktion, Zeichenfolgenfunktion, Fensterfunktion behandelt. Google BigQuery bietet jedoch viele weitere nützliche Funktionen, zum Beispiel:
- Casting-Funktionen - Ermöglichen das Casting von Daten in ein bestimmtes Format.
- Platzhalterfunktionen für Tabellen - Ermöglichen den Zugriff auf mehrere Tabellen aus einem Dataset.
- Funktionen für reguläre Ausdrücke - Mit dieser Funktion können Sie das Modell einer Suchabfrage und nicht den genauen Wert beschreiben.
Schreiben Sie in die Kommentare, wenn es sinnvoll ist, im gleichen Detail darüber zu schreiben.